自监督表征预训练之掩码图像建模
前言
目前,在计算机视觉领域,自监督表征预训练有两个主流方向,分别是对比学习(contrastive learning)和掩码图像建模(masked image modeling)。两个方向在近几年都非常火爆,有许多优秀的工作涌现。对比学习方向,有 MoCo 系列、SimCLR 系列、SWaV、SimSiam、DINO 等;掩码图像建模方向,有 BEIT 系列、MAE、CAE 等。本文主要整理几篇掩码图像建模方向的工作。
在自然语言处理领域,BERT 提出的掩码语言建模(masked language modeling)作为一种表征学习预训练方法,已经取得了巨大的成功。那么,在计算机视觉领域,尤其是在 ViT 的提出证明了 Transformer 在 CV 中同样可用之后,掩码建模的预训练方式是否有效呢?
BEiT
前言
ViT 的提出证明了只要经过图像分块和线性映射嵌入, Transformer 同样可以处理图像数据。然而,相较于 CNN,ViT 不存在针对图像数据的归纳偏置,因此通常需要更大的数据来进行训练。为了节省标注的成本,研究者们探索了如何使用自监督的方式对 ViT 进行预训练。对标 BERT 中的掩码语言建模(MLM)训练目标,BEiT(Bidirectional Encoder representation from Image Transformers)提出了掩码图像建模(MIM),使用大量无标注的图像数据,对 ViT 进行自监督表征学习预训练。
要对图像进行掩码,首先想到的就是选择一些像素进行掩码。然而,由于图像中像素信息的冗余性很高,模型通过简单的插值就能大致恢复出被掩码的像素,很难学习到图像的高层语义。那么。是否可以像 BERT 一样,对 token 进行掩码呢?在自然语言中,文本是一种离散的数据形式,所有的单词都存在于一个单词数量有限的词表(vocab)中,而图像中的像素是一种连续的数据形式,可能的像素排列组合数目极其巨大。这使得 MIM 无法直接照搬 MLM 中使用分类头预测被掩码 token 的方式。借鉴 DALL-E 中 dVAE 的做法,BEiT 的解决方案是对图像块进行离散化,需要设计一种方式来构造一种 “视觉词表”。BEiT 的模型结构如图 1 所示。
方法

图像表示
BEiT 中每张图像有两个视角(view):图像块(image patchs)和离散的视觉 token(visual tokens)。在预训练阶段,它们分别作为 BEiT Encoder 模型的输入和输出。
-
图像块
与标准 ViT 的做法一致,BEiT 将原始图像切分为多个规则的图像块。作为 BEiT Encoder 的输入。
-
视觉token
为了将图像数据离散化,BEiT 通过一个 tokenizer 将图像表示为一个离散的 token 序列。
与 DALL-E 一样,BEiT 使用 dVAE 来对 tokenizer 进行训练。训练时, tokenizer q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x) 将输入图像 x x x 编码为离散的 token 序列 z z z,decoder p ψ ( x ∣ z ) p_\psi(x|z) pψ(x∣z)根据 token 序列 z z z 重构出输入图像 x x x。其中,所有可选的 token 序列保存在码本(codebook)中,这里的码本就相当于 NLP 中的词表 vocab。dVAE 的训练过程的目标函数可表示为: E z ∼ q ϕ ( z ∣ x ) [ log p ψ ( x ∣ z ) ] \mathbb{E}_{z\sim q_\phi(z|x)}[\log p_\psi(x|z)] Ez∼qϕ(z∣x)[logpψ(x∣z)] 。由于视觉 token 是离散的,整个过程不可导,因此 BEiT 中引入 gumble softmax 来解决这一问题。在 dVAE 训练结束后,开始对 BEiT Encoder 进行预训练时,decoder 将被丢弃,仅使用 tokenizer 来为 BEiT Encoder 的训练生成目标 token。
骨干网络:Image Transformer
BEiT Encoder 是一个标准的 ViT。图像块输入经过线性映射后,每个图像块对应一个特征嵌入 token,然后拼接一个特殊 token [S],并为所有 token 添加位置编码。与标准 ViT 的输入不同的是,BEiT 的对图像块进行掩码,将被掩码图像块的 token 替换为一个共享的、可学习的 token。经过
L
L
L 层 Transformer Block 提取特征之后,得到图像的特征嵌入。
BEiT 预训练:Masked Image Modeling
经过 BEiT Encoder 图像特征之后,每个被掩码位置的特征经过一个 softmax 分类器,预测该位置的 token。本质上是一个分类任务,候选的类别数即为码本中 token 的个数。整个预训练过程的目标函数可表示为:
max
∑
x
∈
D
E
M
[
∑
i
∈
M
log
p
MIM
(
z
i
∣
x
M
)
]
\max\sum_{x\in\mathcal{D}}\mathbb{E}_\mathcal{M}[\sum_{i\in\mathcal{M}}\log p_{\text{MIM}}(z_i|x^\mathcal{M})]
maxx∈D∑EM[i∈M∑logpMIM(zi∣xM)]
其中
D
\mathcal{D}
D 是全部训练数据,
M
\mathcal{M}
M 表示被随机掩码的位置,
x
M
x^{\mathcal{M}}
xM 是经过掩码的图像,
z
i
z_i
zi 是待预测的视觉 token。
微调
BEiT Encoder 经过预训练之后,可以提取图像的特征。这些特征经过不同的 task specific layer 处理之后,可用于处理不同的下游任务,如图像分类、语义分割等。
其他细节
- BEiT 中的掩码策略不是完全随机的,而是按照 block 进行掩码;
- BEiT 中的掩码率为 40%;
- BEiT 直接使用了 DALL-E 通过 dVAE 训练好的 tokenizer;
- 论文中提供了 BEiT 在 VAE 视角下的 ELBO 数学解释;
- 中间微调,BEiT 在自监督预训练结束之后,可以先在规模稍大的中间数据集(原文中为 ImageNet-1K)上微调,然后再在不同的下游任务上微调。
总结
BEiT 是比较早期的 MIM 算法。它通过先训练一个 tokenizer 并构造离散化码本,使得 ViT 能够通过 MIM 目标进行训练。
MAE
前言
MAE(Masked AutoEncoder)的想法非常直接:将图像中的某些图像块掩码掉,然后要求模型重构出掩码掉的像素。如图 2 所示,MAE 整体上是一个编码器-解码器架构。其中,编码器提取可见图像块的特征,解码器根据这些特征重构出原始图像。MAE 有两个需要注意的关键设计:1) 非对称的编码器-解码器架构, 2) 高掩码率。MAE 的编码器-解码器架构是非对称的,编码器的模型尺寸相对较大,仅接收可见的(未被掩码的)图像块,提取其特征,解码器相对轻量,编码后的图像特征 token 和统一且可学习的掩码 token 作为输入。MAE 中掩码的比率非常高,达到 75%。相对的,在 BERT 中,对文本数据的掩码率为 15%。这体现出图像数据的冗余性和文本数据的高度语义性。得益于这两项设计,MAE 可以高效地训练出强大的模型。模型的强大来自于高掩码率带来的任务难度,高效来自于非对称的架构设计,编码器仅需处理可见图像块。
方法

掩码方法
与 ViT 一致,MAE 将原始图像分为规则的、无重叠的图像块。然后,从这些图像块中随机选择一部分保留,另一部分掩码掉。
编码器
MAE 的编码器是一个标准 ViT 模型,但是只接受可见的、未被掩码的图像块作为输入。与标准 ViT 一致,这些可见的图像块经过线性映射,添加位置嵌入,然后经过数个 Transformer Block 提取图像的特征。由于仅需处理可见的图像块, MAE 的编码器计算非常高效,这使得 MAE 编码器的模型尺寸可以非常大。
解码器
MAE 的解码器接收一组完整的 token,包括经过编码器编码的可见图像块的 token,以及 mask token。MAE 中的 mask token 是一个可学习的、共享的向量,表示此位置图像块缺失,需要重构。解码器同样需要给全部 token 添加位置嵌入,然后经过数个 Transformer Block,得到重构结果。注意,解码器仅在预训练时需要,在预训练完成之后,在下游任务上进行微调时,可将解码器丢弃。另外,相较于编码器,解码器模型尺寸较小,MAE 论文中默认解码器对于每个 token 的计算量是编码器的 1/10。
重构目标
BEiT 中,模型的重构目标是 token,不同于此,MAE 是直接重构图像的像素。MAE 中,解码器的最后一层是一个线性层,将每个 token 映射为对应图像块的像素。损失函数为 MSE,只在掩码掉的图像块上计算损失。
另外,MAE 中的关于重构目标的一个小 trick 是对图像块内像素进行标准化(normalization),先计算图像块内所有像素的均值和标准差,然后根据它们对图像块内的所有像素进行标准化。实验显示,进行标准化可以提高表征的质量。
总结
MAE 与 BEiT 不同,它的重构目标是原始像素。MAE 训练高效,表征能力强,它的核心创新点有两个:非对称的编码器-解码器架构和高掩码率。
BEiTv2
前言
当时已有的 MIM 方法的重构目标有三种:原始像素、手工特征和视觉 tokens。这些重构目标都是 low-level 的图像元素,而自监督表征预训练实际更想得到关于高层语义的图像特征。因此,BEiTv2 试图构建语义感知的监督信号,为此,BEiT 有两点主要的创新。首先是提出了向量化知识蒸馏(Vector Quantised Knowledge Distillation,VQ-KD),为 MIM 预训练提供语义层面的监督信号。另外是提出一种块聚合策略(patch aggregation strategy),鼓励模型聚合所有块的信息,提取图像的全局特征,而不是仅关注图像块的重构。
方法
BEiTv2 是在 BEiTv1 的基础上进行改进。前文已经介绍,BEiTv1 分为两个阶段,分别是 tokenizer 的训练和 BEiT Encoder 的预训练。BEiTv2 中两个阶段与 BEiTv1 是一样的,先训练出 tokenizer,为 BEiT Encoder 的预训练提供重构目标。BEiTv2 的两个创新点分别在这两个阶段中。
训练tokenizer
BEiTv1 的 tokenizer 使用 dVAE 进行训练,如此得到的离散 token 高层语义不够丰富。BEiTv2 中提出 VQ-KD 来训练 tokenizer, 训练流程如图 3 所示。BEiTv2 中,同样有 tokenizer 和decoder 两个模型参与训练。tokenizer 又由 encoder 和 quantizer 组成,encoder 将图像映射为一串视觉 token,quantizer 通过最近邻的方式从码本
V
\mathcal{V}
V 中查找与每个 token 的 L2 距离最接近的 embedding。码本
V
∈
R
K
×
D
\mathcal{V}\in\mathbb{R}^{K\times D}
V∈RK×D ,其中包含
K
K
K 个维度为
D
D
D 的 embedding。这就是 VQ。在得到量化后的视觉 token 之后,将其送入解码器,解码器的输出目标是教师模型(如 CLIP、DINO 等)给出的语义特征。这个训练过程的目标是最大化解码器的输出与教师模型语义特征的余弦相似度。这就是 KD。通过 VQ-KD 的训练方式,BEiTv2 的 tokenizer 能够为 BEiT encoder 的预训练提供含有高层语义特征的重构目标。tokenizer训练的目标函数为:
max
∑
x
∈
D
∑
i
=
1
N
cos
(
o
i
,
t
i
)
−
∣
∣
sg
[
l
2
(
h
i
)
]
−
l
2
(
v
z
i
)
∣
∣
2
2
−
∣
∣
l
2
(
h
i
)
−
sg
[
l
2
(
v
z
i
)
]
∣
∣
2
2
\max\sum_{x\in \mathcal{D}}\sum_{i=1}^N\cos(o_i,t_i)-||\text{sg}[l_2(h_i)]-l_2(v_{z_i})||^2_2-||l_2(h_i)-\text{sg}[l_2(v_{z_i})]||_2^2
maxx∈D∑i=1∑Ncos(oi,ti)−∣∣sg[l2(hi)]−l2(vzi)∣∣22−∣∣l2(hi)−sg[l2(vzi)]∣∣22

预训练 BEiTv2
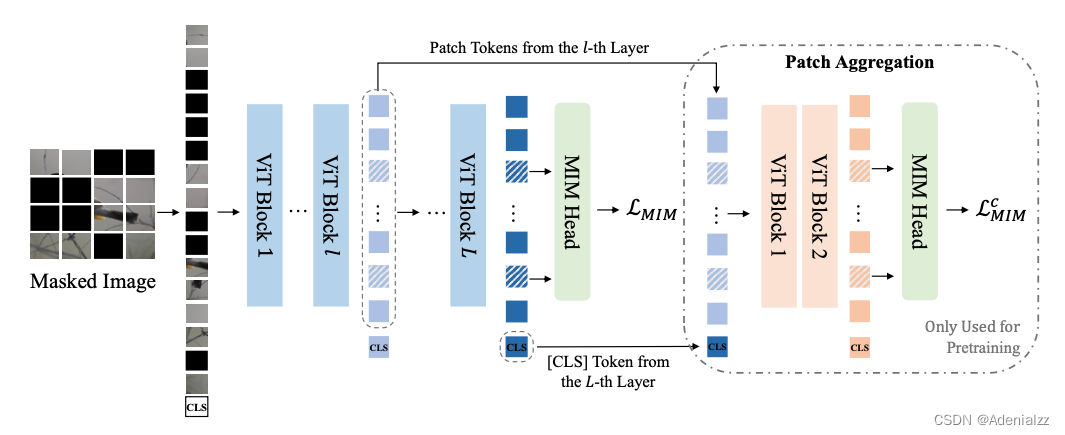
BEiTv2 的预训练与 BEiTv1 大体一致,将图像进行掩码,并分块送入 Transformer,得到的特征通过 softmax 分类器,预测掩码位置上的 token。BEiTv2 的优化之处是提出了块聚合策略,在图像 token 上拼接了一个 [CLS] token,用来鼓励模型聚合各个图像块,提取图像的全局特征。而不是仅仅关注较为底层的图像块重构。配备有块聚合策略的 MIM 训练流程如图 4 所示。BEiTv2 构建了一个瓶颈层来对 <CLS> token 进行预训练,使其尽可能多地汇聚信息。
[CLS] 的预训练网络如图 4 的右半部分的虚线框所示,是一个两层的 ViT。它的输入是由 BEiTv2 Encoder 的第
l
l
l 层的输出向量和第
L
L
L 层的[CLS] 向量拼接而成。这两层 ViT 的输出特征也经过 MIM head (与 BEiT Encoder 的 MIM head 共享权重)预测掩码处的 token。在计算整体 MIM 损失时,添加一项
L
M
I
M
c
\mathcal{L}^c_{MIM}
LMIMc 。
为什么说通过对[CLS]的预训练,我们得到的特征 hCLSLh_\text{CLS}Lh_\text{CLS}L 具有图像的全局信息呢?由于在训练 [CLS] token 时,舍弃了图 4 中最左侧的第
l
+
1
l+1
l+1 层到第
L
L
L 层的,却要求两个不同的 MIM 任务共享同一个MIM输出头,这就迫使 <CLS> token 学习更多的全局信息,以弥补被舍弃的图像所有标志的特征的信息。
其他细节
- 训练 tokenizer 时,由于中间的最近邻查表操作是不可微的,为了梯度反传,可将 decoder 输入的梯度直接拷贝到 encoder 输出。因为 quantizer 查找的是每个编码器输出的最近邻 embedding,码本 embedding 的梯度可以为编码器指示合理的优化方向;
- 为了稳定码本的训练并提高利用率,避免码本坍塌,导致只有一小部分 embedding 会被使用,tokenizer 的训练采用了一些 trick。其中包括使用标准化 l2 距离、降低 embedding 维度到 32 维、滑动指数平均 (EMA);
- 额外的用于预训练
<CLS>token 的两层 ViT Block 在预训练结束后即被丢弃,不用于下游任务。
总结
BEiTv2 针对 BEiT 等已有 MIM 工作中语义特征缺失的问题,提出了 VQ-KD,对 embedding 进行量化并将 CLIP、DINO 等语义特征提取强的模型作为教师模型,生成重构目标。并提出使用 <CLS> token 来聚合图像块,提取全局特征。
Ref
自监督表征预训练之掩码图像建模:CAE 及其与 MAE、BEiT 的联系
MAE 论文逐段精读【论文精读】
如何看待BEIT V2?是否是比MAE更好的训练方式?



![[Java安全]—Shiro回显内存马注入](https://img-blog.csdnimg.cn/65d8d72cb8734d3999f3388cc274848b.png#pic_center)

![【Unity】[入门tips与通用性原则] 一些经验技巧和更好地写出简洁易懂的程序的原则方法](https://img-blog.csdnimg.cn/307203984973441e90784a1c032d4d40.png)