Kaldi语音识别技术(六) ----- DTW和HMM-GMM
文章目录
- Kaldi语音识别技术(六) ----- DTW和HMM-GMM
- 前言
- 一、语音识别概况
- 二、语音识别基本原理
- 三、DTW(动态时间弯折)算法
- 四、GMM-HMM
前言
前面的内容中我们完成了特征的提取,那么本章节我们主要进行理论部分的笔记。知道自己在干嘛才能更好效率的学习,简单对语音识别进行一个回顾,然后介绍一下语音识别常用的也是最简单的 DTW(动态时间弯折)算法。
一、语音识别概况
时至今日,语音识别已经有了突破性进展。2017年8月20日,微软语音识别系统错误率由5.9%降低到5.1%,可达到专业速记员的水平;国内语音识别行业的佼佼者科大讯飞的语音听写准确率则达到了95%,表现强悍。国内诸如阿里、百度、腾讯等大公司,也纷纷发力语音识别,前景一片看好。
并且,语音识别系统也不只仅仅用于之前提到的手机交互、智能音箱命令,在玩具、家具家居、汽车、司法、医疗、教育、工业等诸多领域,语音识别系统将发挥不可忽视的作用。毕竟在当下人工智能刚刚起步的时代,在设备无法便捷的探知人类想法之前,语音交互都是最高效的人机交互方式。
现在庞大的语言数据库难以放置于移动端,这也是几乎所有手机语音助手使用时需要联网的原因。语音识别发展到现在也不是没有离线版,但我们不难发现,离线版的准确率是要远远低于在线版的。
另外,刚才我们提到不少语音厂商都宣称准确率达到90%以上,这可以说是十分了不起的,不夸张的说,这时候每提升1个百分比的准确率,都是质的飞跃。这不仅要相当完善的数据库,满足这样的准确率还得效率较高的识别提取算法和自学习系统。
但然这样的数据我们要以辨证的眼光来看,俗话说,一句话百样说,汉语言可谓博大精深;而且厂商给出的准确率数据的测试很难具备广泛性,所以有些用户在使用语音识别功能时发现它还很“弱智”,实属正常。
识别提取算法和自学习系统,在这里我们不妨简单了解一下它们的工作过程:首先语音识别系统对收集到的目标语音进行预处理,这个过程就已经十分复杂,包含语音信号采样、反混叠带通滤波、去除个体发音差异和设备、环境引起的噪声影响等等。然后,对处理的语音进行特征提取。
二、语音识别基本原理
声音的本质是震动,它可以由波形表示,识别则需要对波进行分帧,多个帧构成一个状态,三个状态构成一个音素。英语常用音素集是卡内基梅隆大学的一套由39个音素构成的音素集,汉语一般直接用全部声母和韵母作为音素集,另外汉语识别还分有调和无调。之后通过音素系统合成单词或者汉字。
当然,之后的匹配和后期内容处理也需要相应算法来完成。自学习系统则更多的是针对数据库来说。将语音转换成文本的语音识别系统要有两个数据库,一是可与提取出的信息进行匹配的声学模型数据库,二是可与之匹配的文本语言数据库。这两个数据库需要提前对大量数据进行训练分析,也就是所说的自学习系统,从而提取出有用的数据模型构成数据库;
另外,在识别过程中,自学习系统会归纳用户的使用习惯和识别方式,然后将数据归纳到数据库,从而让识别系统对该用户来说更智能。
更进一步总结一下整个识别过程:
- 对采集的目标语音进行处理,获取包含关键信息的语音部分
- 提取关键信息
- 识别最小单元字词,分析规定语法排列
- 分析整句语义,将关键内容断句排列,调整文字构成
- 根据整体信息修改出现轻微偏差的内容
三、DTW(动态时间弯折)算法
特征怎么转换为音素
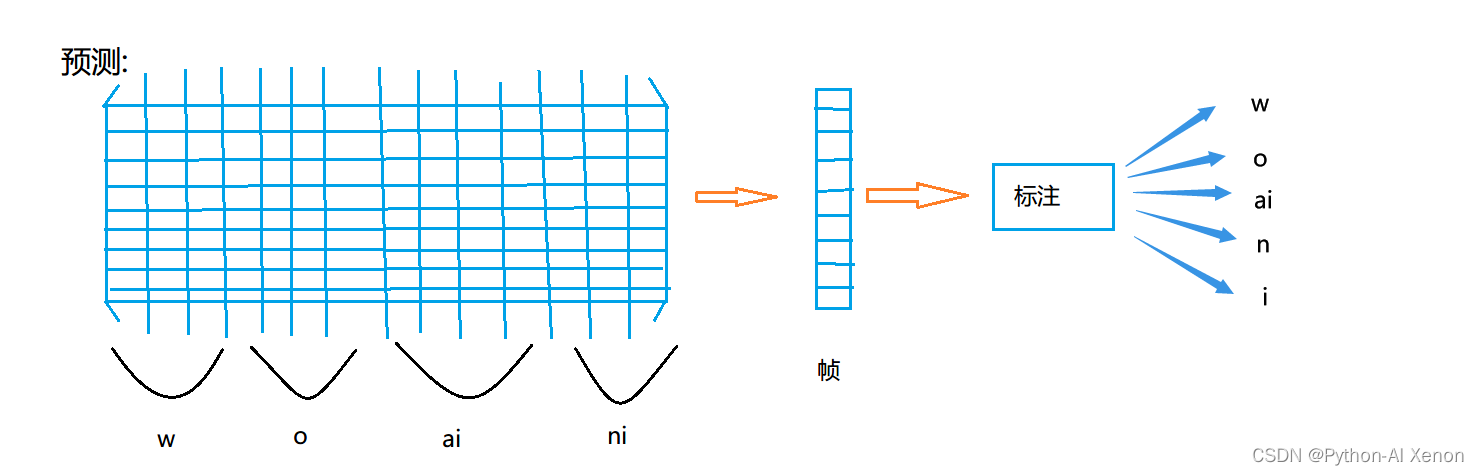
对齐方式
在语音识别中比较简单的是基于DTW算法。DTW(动态时间弯折)算法原理:基于动态规划(DP)的思想,解决发音长短不一的模板匹配问题。相比HMM模型算法,DTW算法的训练几乎不需要额外的计算。所以在孤立词语音识别中,DTW算法仍得到广泛的应用。
在训练和识别阶段,首先采用端点检测算法确定语音的起点和终点。对于参考模板{R(1),R(2),…,R(m),…,R(M)},R(m)为第m帧的语音特征矢量。对于测试模板{T(1),T(2),…,T(n),…,T(N)},T(n)为测试模板的第n帧的语音特征矢量。参考模板与测试模板一般采用类型的特征矢量、相同的帧长、相同的窗函数和相同的帧移。
对于测试和参考模板T和R,它们之间的相似度之间的距离D[T,R],距离越小则相似度越高。在DTW算法中通常采用欧氏距离表示。对于N和M不相同的情况,需要考虑T(n)和R(m)对齐。一般采用动态规划(DP)的方法将实现T到R的映射。
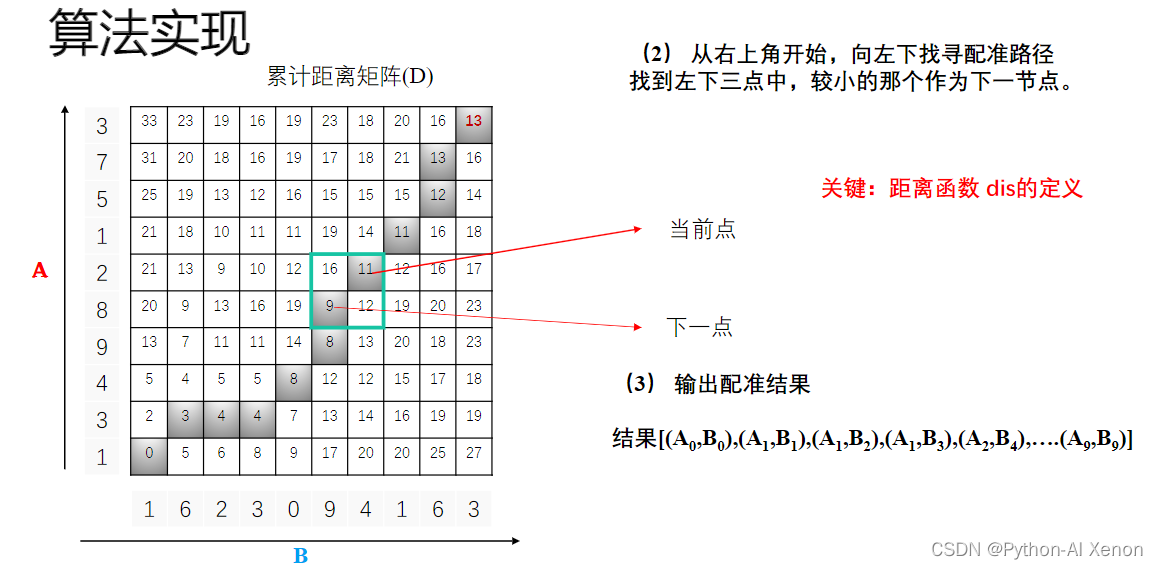
将测试模板的各个帧号n=1,N在一个二维直角坐标系中的横轴上标出,参考模板的各帧号m=1,M在纵轴上标出,通过这些表示帧号的整数坐标画出一些纵横线即可形成一个网格,网格中的每一个交叉点(n,m)表示测试模式中某一帧与训练模式中某一帧的交汇点。DP算法可以归结为寻找一条通过此网格中若干格点的路径,路径通过的格点即为测试和参考模板中进行距离计算的帧号。
DTW( Dynamic Time Warping)
按照距离最近的原则,构建两个序列元素之间的对应的关系,评估两个序列的相似性。
要求
(1)单向对应,不能回头
(2)一一对应,不能有空
(3)对应之后,距离最近(距离越近,匹配度越高)
eg:

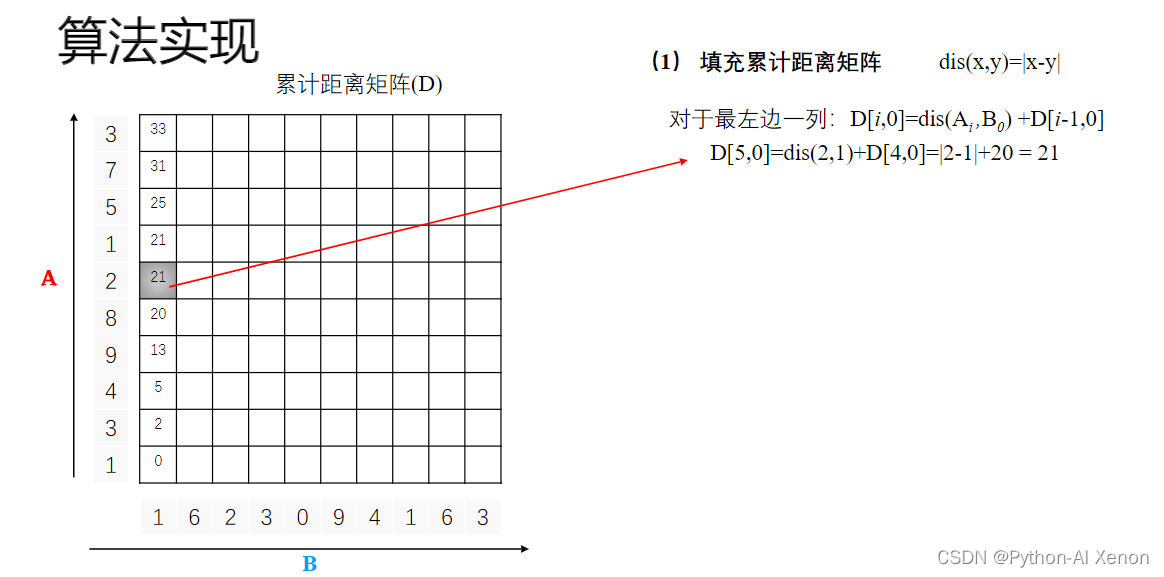
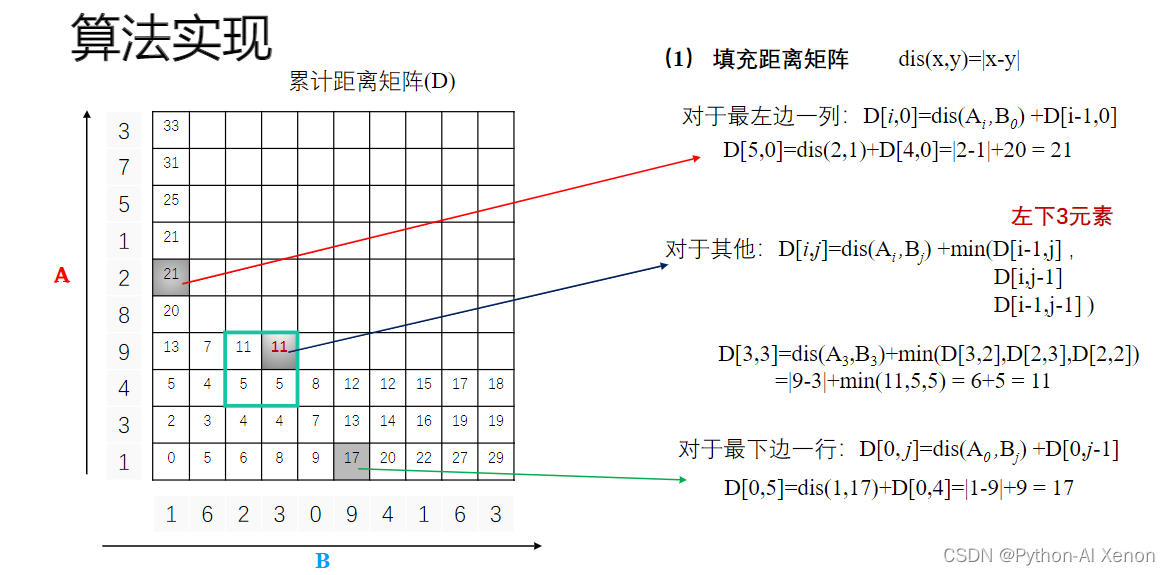
算法实现

DTW的python包
pip install dtw
pip install dtw_c
pip install fastdtw
使用DTW缺点
-
DTW一般只能以单词为单位进行识别(孤立词识别),连续语音识别效果差;
-
运算量大。DTW需要存储所有训练数据,空间占用量和测试耗时随训练数据量都是线性增长;
-
太依赖于说话人的原来发音,不能对样本作动态训练;
-
识别性能过分依赖于端点检测(即特征提取效果)。
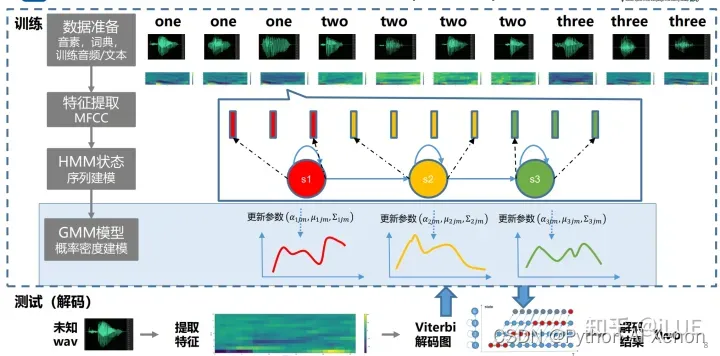
四、GMM-HMM
这是一个成熟的系统,目前我对这掌握的也不是那么的深入,关于该部分内容仅做一个简单的介绍。
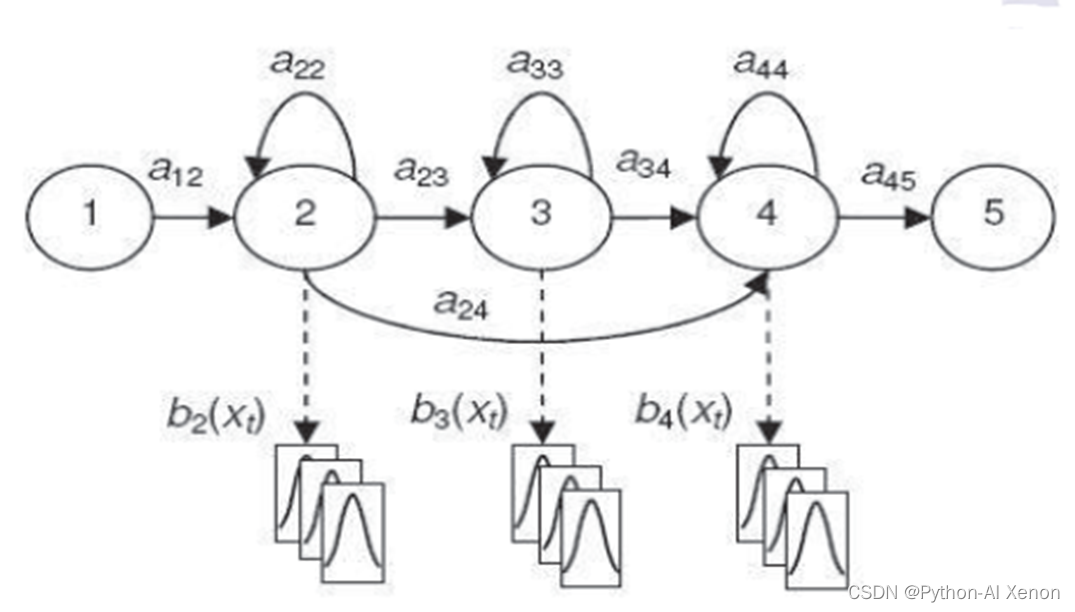
GMM-HMM语音识别系统:

目的:将语音生成表达为概率模型
-
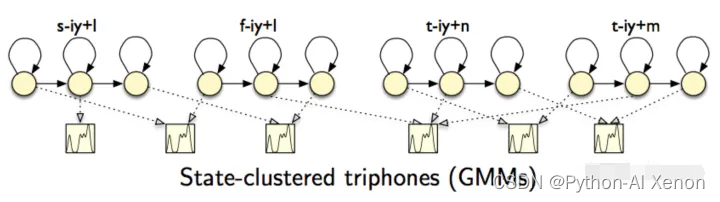
GMM(高斯混合模型)
-
HMM
-
GMM-HMM
参考:
GMM-HMM模型
GMM-HMM声学模型(深度解析)
DTW(动态时间规整)算法原理与应用
肖利君. 基于DTW模型的孤立词语音识别算法实现研究[D]. 中南大学, 2010.

![[软件工程导论(第六版)]第9章 面向对象方法学引论(复习笔记)](https://img-blog.csdnimg.cn/ed8d32fa89a14593a2ae85e4b6a0c608.png)