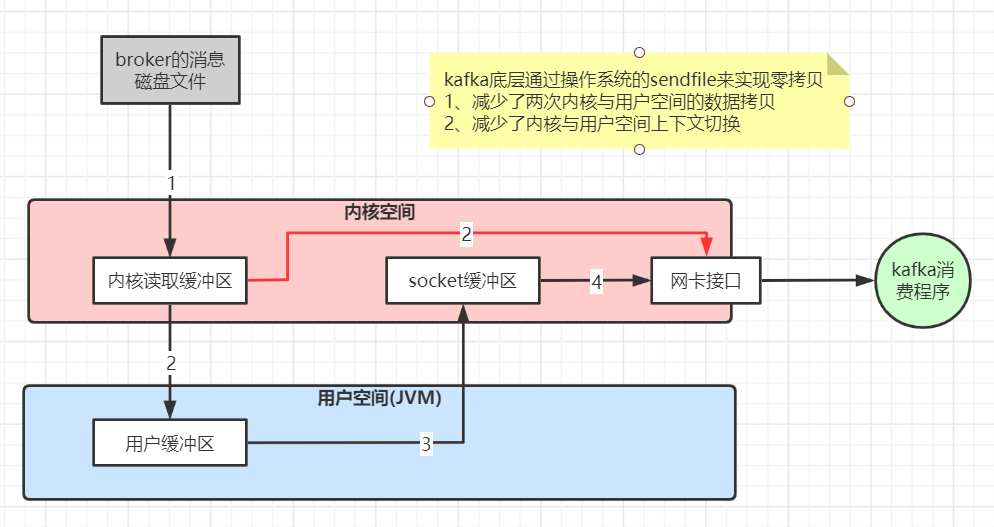
model
- 1、Backbone
- 1)ResNet-50
- 2)截取 ResNet-50 的前半部分作为 backbone
- 2、Module
- 3、Loss Function
- 1)location loss
- 2)confidence loss
- 3)整体 loss
- 4)loss 代码
1、Backbone
这里介绍使用 ResNet-50 作为 backbone (原论文使用的 backbone 是 VGG-16)
1)ResNet-50
https://blog.csdn.net/weixin_37804469/article/details/111773914
2)截取 ResNet-50 的前半部分作为 backbone
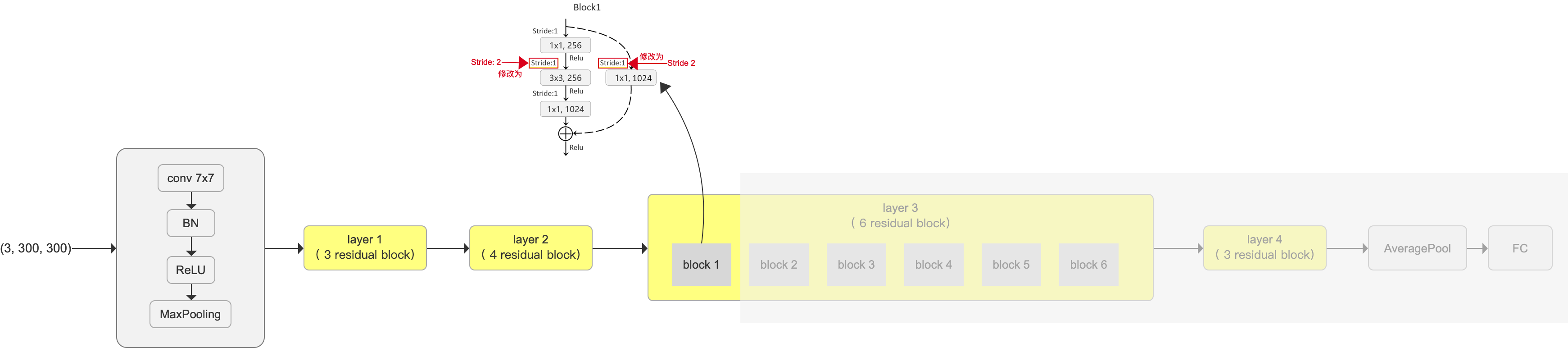
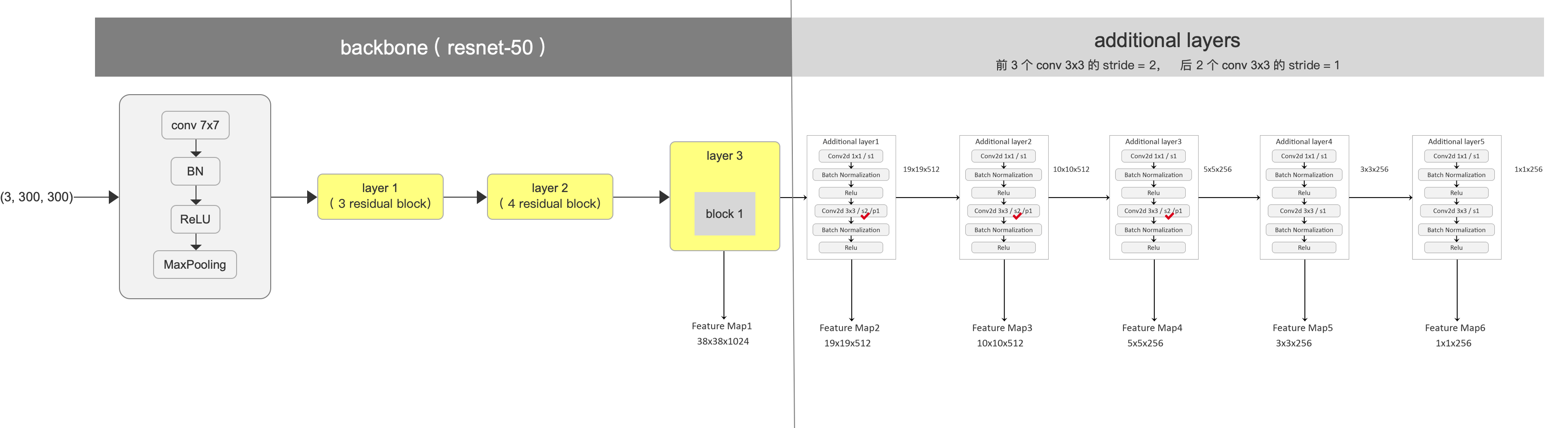
- 截取到 layer 3 的 block 1 ,后面的丢弃不用
- layer 3 的 block 1 要稍做修改,resnet-50 这里原本要做 downsample 的(图片尺寸减小一倍),要修改成不做downsample了。也就是 stride由之前的2 修改为 1, 如图
- 按照原文,输入图片为 (3,300,300),那么,到 layer 3 的 block 1这里,输出的 feature map 尺寸为 (1024, 38, 38)。这个 feature map 会做为 多个特征层中的第一层。
class Backbone(nn.Module):
def __init__(self, pretrain_path=None):
super(Backbone, self).__init__()
net = resnet50()
self.out_channels = [1024, 512, 512, 256, 256, 256]
if pretrain_path is not None:
net.load_state_dict(torch.load(pretrain_path))
self.feature_extractor = nn.Sequential(*list(net.children())[:7])
conv4_block1 = self.feature_extractor[-1][0]
# 修改conv4_block1的步距,从2->1
conv4_block1.conv2.stride = (1, 1)
conv4_block1.downsample[0].stride = (1, 1)
def forward(self, x):
x = self.feature_extractor(x)
return x
到此,我们的backbone 就构建好了,backbone 就是 resent-50 前半截,下面我们在backbone 的基础上,继续搭建起 model
2、Module
在 backbone 的基础上,重新设计后半截的网络,构成完整的网络,用于特征层的输出,如下图
后面几层的特征层输出分别为 (512,19,19)、(512,10,10)、(256,5,5)、(256,3,3)(256,1,1)
def _build_additional_features(self, channels):
additional_blocks = []
# channels = [1024, 512, 512, 256, 256, 256]
middle_channels = [256, 256 ,128, 128, 128]
for i, (input_ch, output_ch, middle_ch) in enumerate(zip(channels[:-1], channels[1:], middle_channels)):
padding, stride = (1, 2) if i < 3 else (0, 1)
layer = nn.Sequential(
nn.Conv2d(input_ch, middle_ch, kernel_size=1, bias=False),
nn.BatchNorm2d(middle_ch),
nn.ReLU(inplace=True),
nn.Conv2d(middle_ch, output_ch, kernel_size=3, padding=padding, stride=stride, bias=False),
nn.BatchNorm2d(output_ch),
nn.ReLU(inplace=True)
)
additional_blocks.append(layer)
self.additional_blocks = nn.ModuleList(additional_blocks)
将 6 个 feature map 进一步进行位置提取 和 置信度提取 (location extractor & confidence extractor)
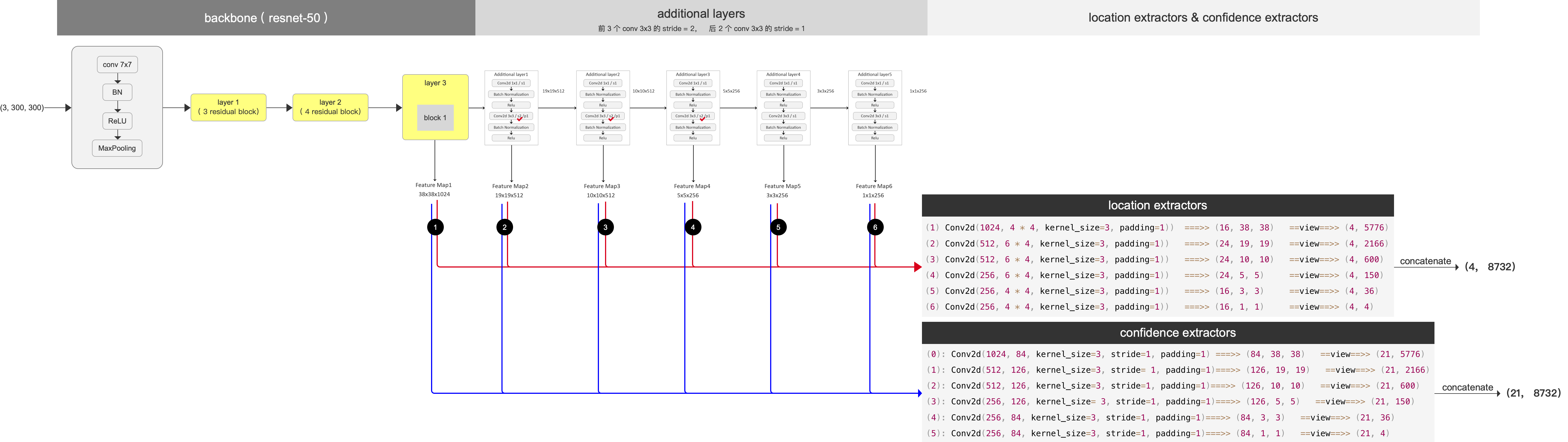
1) location extractor
从 6个 特征层中 提取 对应的 default box 的位置信息,其中 :
- 5776、2166、600、150、36、4 分别表示每个特征层所对应的 default box 的个数
- 4 就代表4个坐标 (ctr_x, ctr_y, width, height)的坐标参数的值
# confidence extractor
(1) Conv2d(1024, 4 * 4, kernel_size=3, padding=1)) ===>> (16, 38, 38) ==view==>> (4, 5776)
(2) Conv2d(512, 6 * 4, kernel_size=3, padding=1)) ===>> (24, 19, 19) ==view==>> (4, 2166)
(3) Conv2d(512, 6 * 4, kernel_size=3, padding=1)) ===>> (24, 10, 10) ==view==>> (4, 600)
(4) Conv2d(256, 6 * 4, kernel_size=3, padding=1)) ===>> (24, 5, 5) ==view==>> (4, 150)
(5) Conv2d(256, 4 * 4, kernel_size=3, padding=1)) ===>> (16, 3, 3) ==view==>> (4, 36)
(6) Conv2d(256, 4 * 4, kernel_size=3, padding=1)) ===>> (16, 1, 1) ==view==>> (4, 4)
====>> concatenate 得 (4, 8732) : 表示所有 8732 个 default box 的位置参数
2)confidence extractor
从 6个 特征层中 提取 对应的 default box 中有object 的置信度,其中 :
- 5776、2166、600、150、36、4 分别表示每个特征层所对应的 default box 的个数
- 21 代表21个分类的置信度
# confidence extractor
(0): Conv2d(1024, 84, kernel_size=3, stride=1, padding=1) ===>> (84, 38, 38) ==view==>> (21, 5776)
(1): Conv2d(512, 126, kernel_size=3, stride= 1, padding=1)===>> (126, 19, 19) ==view==>> (21, 2166)
(2): Conv2d(512, 126, kernel_size=3, stride=1, padding=1)===>> (126, 10, 10) ==view==>> (21, 600)
(3): Conv2d(256, 126, kernel_size= 3, stride=1, padding=1)===>> (126, 5, 5) ==view==>> (21, 150)
(4): Conv2d(256, 84, kernel_size=3, stride=1, padding=1)===>> (84, 3, 3) ==view==>> (21, 36)
(5): Conv2d(256, 84, kernel_size=3, stride=1, padding=1)===>> (84, 1, 1) ==view==>> (21, 4)
====>> concatenate 得 (21, 8732):表示这 8732 个 default box 分别为 21个分类的概率
3、Loss Function
在得到了预测的 boxes 的坐标参数 和 置信度(分类概率),我门就要计算 loss 了。 Loss 的计算分为两个部分:
- 坐标回归参数:坐标回归参数的 loss function 用的是 SmoothL1Loss
- 分类:分类的 loss function 用的是 CrossEntropy
\quad
1)location loss
1、将 gt boxes 的 (ctr_x, ctr_y, w, h) 形式的坐标 转换为 其相对于 default boxes 的回归参数
def _location_vec(self, loc):
# (1) self.scale_xy = 10.0 , self.scale_wh = 5.0
gxy = self.scale_xy * (loc[:, :2, :] - self.dboxes[:, :2, :]) / self.dboxes[:, 2:, :] # Nx2x8732
gwh = self.scale_wh * (loc[:, 2:, :] / self.dboxes[:, 2:, :]).log() # Nx2x8732
return torch.cat((gxy, gwh), dim=1).contiguous()
vec_gd = self._location_vec(gloc)
2、计算 预测回归参数:ploc 和 上一步转换出的 ground truth boxes 回归参数: vec_gd 的 SmoothL1 Loss
SmoothL1 Loss 的介绍在这里
vec_gd = self._location_vec(gloc) # vec_gd shape=[N, 4, 8732]
loc_loss = nn.SmoothL1Loss(reduction='none')(ploc, vec_gd) # loc_loss shape=[N, 4, 8732]
3、累加 4个 位置的参数 ,即 将每个 box 的 ctr_x、ctr_y、w、h 的 loss 进行相加
loc_loss = loc_loss.sum(dim=1) # loc_loss shape=[N, 8732]
3、只提取出 正样本的 location loss ,即 只提取前景图的 location loss)
loc_loss = (mask.float() * loc_loss).sum(dim=1) # loc_loss shape=[N]
\quad
\quad
2)confidence loss
选取负样本中 confidence loss 最大的 前k个
- 负样本 :label=0 的背景图
- 前k个指:k 由该图像中正样本的数量决定,要求选取图像中正样本数量3倍 的负样本
- confidence loss 最大的负样本,即 在做 Hard negative mining,挖掘最难分类的负样本
# hard negative mining Tenosr: [N, 8732]
con = self.confidence_loss(plabel, glabel)
# positive mask will never selected
# 获取负样本
con_neg = con.clone()
con_neg[mask] = 0.0
# 按照confidence_loss降序排列 con_idx(Tensor: [N, 8732])
_, con_idx = con_neg.sort(dim=1, descending=True)
_, con_rank = con_idx.sort(dim=1) # 这个步骤比较巧妙
# number of negative three times positive
# 用于损失计算的负样本数是正样本的3倍(在原论文Hard negative mining部分),
# 但不能超过总样本数8732
neg_num = torch.clamp(3 * pos_num, max=mask.size(1)).unsqueeze(-1)
neg_mask = torch.lt(con_rank, neg_num) # (lt: <) Tensor [N, 8732]
# confidence最终loss使用选取的正样本loss+选取的负样本loss
con_loss = (con * (mask.float() + neg_mask.float())).sum(dim=1) # Tensor [N]
# avoid no object detected
# 避免出现图像中没有GTBOX的情况
total_loss = loc_loss + con_loss
# eg. [15, 3, 5, 0] -> [1.0, 1.0, 1.0, 0.0]
num_mask = torch.gt(pos_num, 0).float() # 统计一个batch中的每张图像中是否存在正样本
pos_num = pos_num.float().clamp(min=1e-6) # 防止出现分母为零的情况
ret = (total_loss * num_mask / pos_num).mean(dim=0) # 只计算存在正样本的图像损失
3)整体 loss
整体 loss = location loss + confidence loss
total_loss = loc_loss + con_loss
计算 batch 中 N 张图像的 loss 平均值
(只计算存在正样本的图像损失,即:如果 batch 中存在 没有正样本的图像,则该图像不参与计算)
num_mask = torch.gt(pos_num, 0).float() # 统计一个batch中的每张图像中是否存在正样本
pos_num = pos_num.float().clamp(min=1e-6) # 防止出现分母为零的情况
ret = (total_loss * num_mask / pos_num).mean(dim=0) # 只计算存在正样本的图像损失
4)loss 代码
class Loss(nn.Module):
"""
Implements the loss as the sum of the followings:
1. Confidence Loss: All labels, with hard negative mining
2. Localization Loss: Only on positive labels
Suppose input dboxes has the shape 8732x4
"""
def __init__(self, dboxes):
super(Loss, self).__init__()
# Two factor are from following links
# http://jany.st/post/2017-11-05-single-shot-detector-ssd-from-scratch-in-tensorflow.html
self.scale_xy = 1.0 / dboxes.scale_xy # scale_xy = 1 / 0.1 = 10,
self.scale_wh = 1.0 / dboxes.scale_wh # scale_wh = 1 / 0.2 = 5
self.location_loss = nn.SmoothL1Loss(reduction='none')
# [num_anchors, 4] -> [4, num_anchors] -> [1, 4, num_anchors]
self.dboxes = nn.Parameter(dboxes(order="xywh").transpose(0, 1).unsqueeze(dim=0),
requires_grad=False)
self.confidence_loss = nn.CrossEntropyLoss(reduction='none')
def _location_vec(self, loc):
# type: (Tensor) -> Tensor
"""
Generate Location Vectors
:param :
(1) self.scale_xy = 10.0 , self.scale_wh = 5.0
(2) default 匹配到的 gt box, self.dboxes 就是row default box
:return: ground truth相对anchors的回归参数
"""
gxy = self.scale_xy * (loc[:, :2, :] - self.dboxes[:, :2, :]) / self.dboxes[:, 2:, :] # Nx2x8732
gwh = self.scale_wh * (loc[:, 2:, :] / self.dboxes[:, 2:, :]).log() # Nx2x8732
return torch.cat((gxy, gwh), dim=1).contiguous()
def forward(self, ploc, plabel, gloc, glabel):
# type: (Tensor, Tensor, Tensor, Tensor) -> Tensor
"""
ploc, plabel: Nx4x8732, Nxlabel_numx8732
predicted location and labels
gloc, glabel: Nx4x8732, Nx8732
ground truth location and labels
"""
# 获取正样本的mask Tensor: [N, 8732]
mask = torch.gt(glabel, 0) # (gt: >)
# mask1 = torch.nonzero(glabel)
# 计算一个batch中的每张图片的正样本个数 Tensor: [N]
pos_num = mask.sum(dim=1)
# 计算gt的location回归参数 Tensor: [N, 4, 8732]
vec_gd = self._location_vec(gloc)
# sum on four coordinates, and mask
# 计算定位损失(只有正样本)
loc_loss = self.location_loss(ploc, vec_gd).sum(dim=1) # Tensor: [N, 8732]
loc_loss = (mask.float() * loc_loss).sum(dim=1) # Tenosr: [N]
# hard negative mining Tenosr: [N, 8732]
con = self.confidence_loss(plabel, glabel)
# positive mask will never selected
# 获取负样本
con_neg = con.clone()
con_neg[mask] = 0.0
# 按照confidence_loss降序排列 con_idx(Tensor: [N, 8732])
_, con_idx = con_neg.sort(dim=1, descending=True)
_, con_rank = con_idx.sort(dim=1) # 这个步骤比较巧妙
# number of negative three times positive
# 用于损失计算的负样本数是正样本的3倍(在原论文Hard negative mining部分),
# 但不能超过总样本数8732
neg_num = torch.clamp(3 * pos_num, max=mask.size(1)).unsqueeze(-1)
neg_mask = torch.lt(con_rank, neg_num) # (lt: <) Tensor [N, 8732]
# confidence最终loss使用选取的正样本loss+选取的负样本loss
con_loss = (con * (mask.float() + neg_mask.float())).sum(dim=1) # Tensor [N]
# avoid no object detected
# 避免出现图像中没有GTBOX的情况
total_loss = loc_loss + con_loss
# eg. [15, 3, 5, 0] -> [1.0, 1.0, 1.0, 0.0]
num_mask = torch.gt(pos_num, 0).float() # 统计一个batch中的每张图像中是否存在正样本
pos_num = pos_num.float().clamp(min=1e-6) # 防止出现分母为零的情况
ret = (total_loss * num_mask / pos_num).mean(dim=0) # 只计算存在正样本的图像损失
return ret
compute_loss = Loss(default_box)
loss = compute_loss(locs, confs, bboxes_out, labels_out)






![W806(一)模拟IIC驱动0.96OLED[移植]](https://img-blog.csdnimg.cn/img_convert/ec383412f5424165b2a66c1c268cd1ad.jpeg)