前言
今天看到论文中用到 Time-distributed CNN,第一次见到 Time-distributed,不理解是什么含义,看到代码实现也很懵。不管什么网络结构,外面都能套一个TimeDistributed。看了几个博客,还是不明白,问了问ChatGPT,终于明白了一点。
解释
直观理解
以下是ChatGPT的解释
“Time-distributed” 是一种用于深度学习处理序列数据的技术,它将神经网络中的层或网络独立地应用于序列的每个时间步长。在典型的前馈神经网络中,输入数据会被馈送到网络中,并且相同的权重会被应用于所有的输入特征。但是,当处理序列数据,如时间序列或自然语言时,我们需要在每个时间步长上应用相同的权重来捕捉时间信息。
“Time-distributed” 技术允许我们独立地应用每个时间步长上的层或网络。这可以通过在 Keras 或 PyTorch 中将层或网络包装在 “TimeDistributed” 层中来实现。
例如,如果我们有一个形状为 (batch_size, timesteps, input_dim) 的三维张量作为输入,应用一个具有 10 个单位的 “TimeDistributed” 密集层将产生一个形状为 (batch_size, timesteps, 10) 的三维张量作为输出。这个包装器可以用于任何模块,例如卷积层、循环神经网络层、全连接层等。 “Time-distributed” 层将相同的密集层应用于每个时间步长,从而使网络能够学习数据中的时间模式。
“Time-distributed” 层通常用于序列到序列模型中,如语言翻译或语音识别,其中输入和输出都是序列。
代码实现角度理解
考虑这样一个问题,将原来代码中的 TimeDistributed 去掉会发生什么?
全连接层
对于全连接层,如果没有 TimeDistributed,代码照样能跑。
import torch
import torch.nn as nn
input = torch.randn(5, 3, 10) # 时间步数是5,batch_size是3,每个时间步的特征维度是10
model = nn.Linear(10, 5)
output = model(input)
print(output.shape)
输出:torch.Size([5, 3, 5])
如果将输入改为 input = torch.randn(5, 3, 2, 2, 10)
输出 torch.Size([5, 3, 2, 2, 5])
可以看到,不管输入有多少维度,都能正常输出。
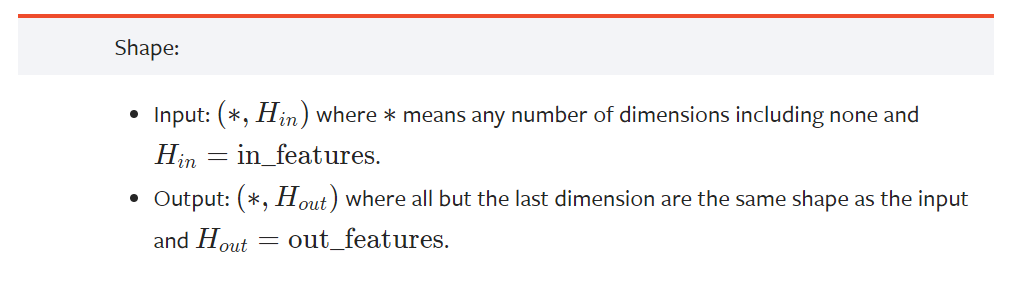
从官方文档也可以看到,输入 * 可以是任意维度。
卷积层
对于全连接层,如果没有 TimeDistributed,代码就会报错。
import torch
import torch.nn as nn
input = torch.randn(5, 3, 3, 256, 256) # 时间步数是5,batch_size是3,通道数是3,图片高宽都是256
model = nn.Conv2d(3, 16, kernel_size=3) # 输入通道是3,输出通道是16,kernel_size=3
output = model(input)
print(output.shape)
报错信息
RuntimeError: Expected 3D (unbatched) or 4D (batched) input to conv2d, but got input of size: [5, 3, 3, 256, 256]
可以看到维度不匹配。如果把时间维度去掉,则可以正常输出。
import torch
import torch.nn as nn
input = torch.randn(3, 3, 256, 256) # batch_size是3,通道数是3,图片高宽都是256
model = nn.Conv2d(3, 16, kernel_size=3) # 输入通道是3,输出通道是16,kernel_size=3
output = model(input)
print(output.shape)
输出:torch.Size([3, 16, 254, 254])
因此如果我想用带时间步数的图片做卷积,那就无法实现了,如何解决这个问题呢?就要用到 Time-distributed。
增加 TimeDistributed 的代码
import torch
import torch.nn as nn
input = torch.randn(5, 3, 3, 256, 256) # 时间步数是5,batch_size是3,通道数是3,图片高宽都是256
model = TimeDistributed(nn.Conv2d(3, 16, kernel_size=3)) # 输入通道是3,输出通道是16,kernel_size=3
output = model(input)
print(output.shape)
输出:torch.Size([5, 3, 16, 254, 254])
具体做法就是让每个时间步的数据也做卷积。
TimeDistributed 代码实现
在 keras 中,自带 TimeDistributed。在 pytorch 中没有实现,需要自己手动实现。
以下是 pytorch 版本的 TimeDistributed 代码实现。
class TimeDistributed(nn.Module):
def __init__(self, module, batch_first=False):
super(TimeDistributed, self).__init__()
self.module = module
self.batch_first = batch_first
def __multi_time(self, size):
size_temp = list(size)
size_temp = [size_temp[0] * size_temp[1]] + size_temp[2:]
return tuple(size_temp)
def __dist_time(self, size, batch, time_dim):
size_temp = list(size)
size_temp = [batch, time_dim] + size_temp[1:]
return tuple(size_temp)
def forward(self, x):
# Squash samples and timesteps into a single axis
x_reshape = x.contiguous().view(self.__multi_time(x.size())) # (samples * timesteps, input_size)
y = self.module(x_reshape)
y = y.contiguous().view(self.__dist_time(y.size(), x.size(0), x.size(1))) # (samples, timesteps, output_size)
return y
chatGPT 对上面代码的解释
这段代码实现了一个 PyTorch 的自定义模块 TimeDistributed,可以将一个其它模块(module)作为输入,将其应用于输入张量(x)的每个时间步上,输出一个相同形状的张量。
具体来说,该模块的 forward 方法接收一个形状为 (samples, timesteps, input_size) 的输入张量 x,其中 samples 表示样本数量,timesteps 表示时间步数,input_size 表示每个时间步的特征维度。然后,该方法将输入张量进行形状变换,将 samples 和 timesteps 两个维度合并为一个维度,变成形状为 (samples * timesteps, input_size) 的张量,即将样本和时间步的信息压缩在了一个维度中。接下来,该方法将这个压缩后的张量输入到 module 模块中,并获取输出张量 y。最后,该方法再将输出张量进行形状变换,将第一个维度还原成 samples,将第二个维度还原成 timesteps,即将样本和时间步的信息重新拆分开,最终输出形状为 (samples, timesteps, output_size) 的张量,其中 output_size 表示每个时间步的输出特征维度,应该与 module 模块的输出维度相同。
此外,该模块还包含两个辅助方法 __multi_time 和 __dist_time,分别用于实现输入和输出张量形状的转换。其中,__multi_time 方法将形状为 (samples, timesteps, input_size) 的张量转换为形状为 (samples * timesteps, input_size) 的张量,即将样本和时间步的信息压缩在一个维度中;__dist_time 方法则将形状为 (samples * timesteps, output_size) 的张量转换为形状为 (samples, timesteps, output_size) 的张量,即将样本和时间步的信息重新拆分开。