Map接口
JDK8
Map接口实现子类的特点
- Map和Collection是并列关系,Map用于保存具有映射关系的数据:Key-Value
- Map中的key和value可以是任何引用类型的数据,会封装到HashMap$Node对象中
- Map中的key不允许重复,原因和HashSet一样
- Map中的value可以重复
- Map的key可以为null,value也可以为null,但是key只能有一个null,value可以有多个null只要key不同就行
- 常用String类为Map的key
- key和value之间存在单向一对一关系,即通过key找到对应的value。可以理解为key相当于身份证号,value是对应的人,人可以重复名字样貌等,但是身份证不能重复。
- 当加入一个重复的key和不重复的value时,相当于替换
测试:
public class test1 {
public static void main(String[] args) {
Map map = new HashMap();
map.put("nbo1","张三");
map.put("nbo2","李四");
map.put("nbo3","王五");
map.put("nbo1","李向");
System.out.println(map);
}
}
运行结果:
{nbo2=李四, nbo1=李向, nbo3=王五}
在之前Collection接口实现集合类,都是使用key来直接保存存储的数据。而Map接口实现集合类会使用key和value两个相互映射来保存数据,key可以看作是一个序号或者身份证号,value才是真正保存的数据
理解:Map存放的key-value是放在一个Node中的,又因为Node实现了Entry接口,所以也说一对k-v也是一个Entry**
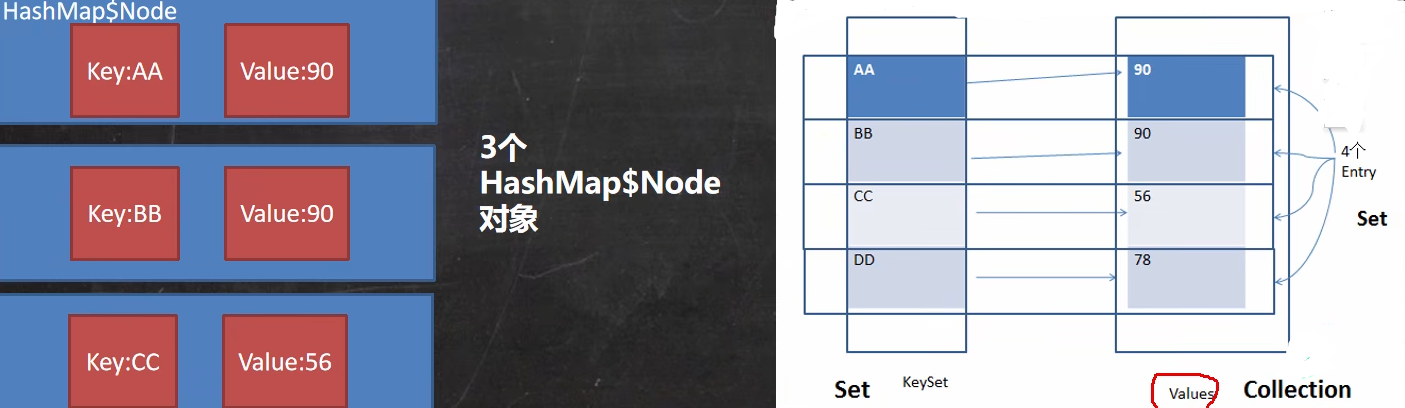
我们知道当使用Map实现集合类存放了一个元素时,会有key和value,也就是键和值,键key可以看作是一个序号,值valuie可以看作是内容,一个序号对应一个内容,而这两个东西是存放在一个Node节点中的。但是因为Map不是Collection接口,Map没有实现iterator接口,所以要遍历不是很方便。因此在添加元素时除了会保存到table数组时,还会做一件事情就是保存到一个EntrySet集合中,EntrySet集合中的保存类型不是Node类型而是Entry类型。
但是这里的意思不是说把table中的数组都复制一份到EntrySet集合中,而是单纯的引用,也就是把EntrySet中的一个个Entry指向的还是table中的一个个Node。而为什么要做这么一件事呢,这是因为在EntrySet集合中保存的key是Set接口类型的value是Collection接口类型的,当然实际运行类型还是Node,只不过这样就可以使用迭代器了。
public class test1 {
public static void main(String[] args) {
Map map = new HashMap();
map.put("nbo1","张三");
map.put("nbo2","李四");
map.put("nbo3","王五");
map.put("nbo1","李向");
Set set = map.entrySet();
for (Object obj:set) {
Map.Entry entry = (Map.Entry) obj;
System.out.println(entry.getClass());
System.out.println(entry.getKey()+"-"+entry.getValue());
}
}
}
运行结果:
class java.util.HashMap
N
o
d
e
n
b
o
2
−
李四
c
l
a
s
s
j
a
v
a
.
u
t
i
l
.
H
a
s
h
M
a
p
Node nbo2-李四 class java.util.HashMap
Nodenbo2−李四classjava.util.HashMapNode
nbo1-李向
class java.util.HashMap$Node
nbo3-王五
Map接口实现类的常用方法
口语说法:key:键 ———— value:值
- put(key,value);添加,当再次添加同一个键,但是值不同时,会对值进行替换
- remove(key);根据键删除这对键和值
- get(key);根据键获取值
- size();获取当前集合的元素个数
- isEmpty():判断当前集合元素个数是否为0
- containsKey(key);查找传入的键是否存在
- clear:清除集合所有元素,归0
使用演示
public class test2 {
public static void main(String[] args) {
Map map = new HashMap();
// 1. put(key,value);添加,当再次添加同一个键,但是值不同时,会对值进行替换
map.put("no1","李青");
map.put("no2","绿意");
map.put("no1","李青");
System.out.println(map);
// 2. remove(key);根据键删除这对键和值
map.remove("no1");
System.out.println(map);
// 3. get(key);根据键获取值
System.out.println(map.get("no2"));
// 4. size();获取当前集合的元素个数
System.out.println(map.size());
// 5. isEmpty():判断当前集合元素个数是否为0
System.out.println(map.isEmpty());
// 6. containsKey(key);查找传入的键是否存在
System.out.println(map.containsKey("no2"));
// 7. clear:清除集合所有元素,归0
map.clear();
System.out.println(map);
}
}
运行结果:
{no2=绿意, no1=李青}
{no2=绿意}
绿意
1
false
true
{}
Map接口实现类的六大遍历方式
上面了解到了map存入的数据还会有一个EntrySet集合指向table数组中的数据,所以遍历也是围绕这个来操作
Map实现接口可以分为三大类:每类有两种方式
1.获取键key,再通过键来获取值value
2.直接获取值value,但是无法通过值value获取key,所以只能输出value
3.通过EntrySet,同时获取到键和值
遍历用到的方法
- KeySet:获取所有键
- entrySet:获取所有键和值k-v
- values:获取所有值
演示:
public class test3 {
public static void main(String[] args) {
Map map = new HashMap();
map.put("no1","淘宝");
map.put("no2","天猫");
map.put("no3","京东");
//第一类:获取所有键,再通过get方法获取值。
//第一种方式:获取键后使用增强for
System.out.println("第一种");
Set set = map.keySet();
for (Object key:set) {
System.out.println(key+"-"+map.get(key));
}
System.out.println("第二种");
//第二种方式:获取键后,使用迭代器
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next+"-"+map.get(next));
}
//第二类:获取所有值
//第三种方式:增强for,直接输出value
System.out.println("第三种");
Collection value = map.values();
for (Object o: value) {
System.out.println(o);
}
//第四种:使用迭代器直接输出
System.out.println("第四种");
Iterator iterator2 = value.iterator();
while (iterator2.hasNext()) {
Object next = iterator2.next();
System.out.println(next);
}
//第三类:获取所有键和值,再向下转型成Entry,使用它的getKey和getValue方法
//第五种:获取所有键和值,增强for操作
System.out.println("第五种");
Set entrySet = map.entrySet();
for (Object e:entrySet) {
Map.Entry entry = (Map.Entry) e;
System.out.println(entry.getKey()+"-"+entry.getValue());
}
//第六种:迭代器操作
System.out.println("第六种");
Iterator iterator1 = entrySet.iterator();
while (iterator1.hasNext()) {
Object next = iterator1.next();
Map.Entry entry = (Map.Entry) next;
System.out.println(entry.getKey()+"-"+entry.getValue());
}
}
}
运行结果:
第一种
no2-天猫
no1-淘宝
no3-京东
第二种
no2-天猫
no1-淘宝
no3-京东
第三种
天猫
淘宝
京东
第四种
天猫
淘宝
京东
第五种
no2-天猫
no1-淘宝
no3-京东
第六种
no2-天猫
no1-淘宝
no3-京东
Map小练习
使用HashMap添加三个员工对象,要求:
键:员工id
值:员工对象
且遍历显示工资18000的员工至少使用两种遍历方式
员工类:姓名,工资,员工id
public class test4 {
@SuppressWarnings({"all"})
public static void main(String[] args) {
HashMap map = new HashMap();
staff s1 = new staff(01,"李四",16000);
staff s2 = new staff(02,"王五",23000);
staff s3 = new staff(03,"赵三",12000);
staff s4 = new staff(04,"李明",19000);
map.put(s1.id,s1);
map.put(s2.id,s2);
map.put(s3.id,s3);
map.put(s4.id,s4);
//第一种:获取直接获取所有值,判断运行类型是否是staff,如果是就向下转型,再判断薪水决定是否输出
Collection c = map.values();
for (Object value:c) {
if (value instanceof staff){
staff s = (staff) value;
if (s.sal>18000){
System.out.println(s);
}
}
}
//第二种:直接获取所有键和值
Set entrySet = map.entrySet();
for (Object entry:entrySet) {
Map.Entry entry1 = (Map.Entry) entry;
staff s = (staff) entry1.getValue();
if (s.sal>18000){
System.out.println(s);
}
}
}
}
class staff{
String name;
int id;
double sal;
public staff(int id,String name,double sal) {
this.name = name;
this.id = id;
this.sal = sal;
}
@Override
public String toString() {
return "staff{" +
"name='" + name + '\'' +
", id=" + id +
", sal=" + sal +
'}';
}
}
HashMap小结
- Map接口的常用实现类:HashMap,Hashtable,Properties,ThreeMap
- HashMap是Map接口使用频率最高的实现类
- HashMap是以key-value对的方式来存储数据的
- key不能重复,但是值可以重复,运行使用null作为存入的数据
- 如果添加相同的key,则会覆盖原来的key-value,等同于替换
- 与HashSet一样,HashMap不保证映射的顺序,因为底层是以hash表的方式来存储的(jdk8的hashMap底层:数组+链表+红黑树)
- HashMap没有实现同步,因此是线程不安全的,方法没有做同步互斥的操作,没有synchronized
HashMap底层机制及源码刨析
扩容机制
- HashMap底层维护了Node类型的数组table,默认为null
- 当创建对象时,将加载因子(loadfactor)初始化为0.75.也就是当table数组存放的元素数到达整体数组大小的75%时,就会进行扩容
- 当添加k-y时,会先通过key的哈希值得到在table的索引,然后判断该索引是否有元素,如果没有则直接添加,如果有元素就判断该位置的元素key和准备添加的key是否相等,如果相等则直接替换value,如果不相等则判断是树结构还是链表结构,如果是链表结构就直接与下一个元素判断。
- 第一次添加,需要扩容table数组容量为16,扩容临界值(threshold)为12,(16*0.75)
- 非第一次扩容就是扩容table容量为原来的2倍,临界值也为原来的2倍,以此类推
- 在java8中,如果一条链表的元素超过了8个且table的大小>=64就会进行树化,如果链表元素超过8个,但是table数组的大小还未超过64,那么就会先进行数组扩容,直到数组大小到达64才会进行树化
Hashtable
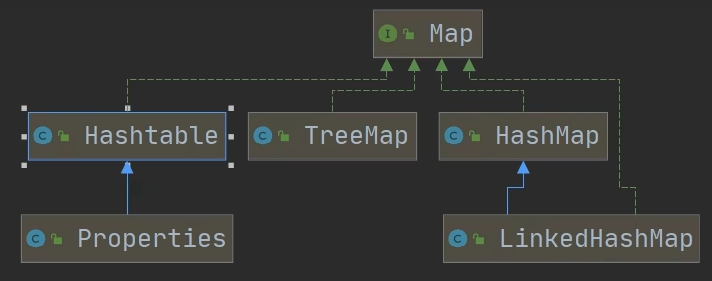
Hashtable也是Map接口的实现类,与HashMap是同级关系
Hashtable基本介绍
- 存放的元素也是键和值:key-value
- Hashtable的k-v都不能存放null,负责会抛出异常
- Hashtable的使用方法基本上和HashMap一致
- Hashtable是线程安全的,HashMap是线程不安全的
Hashtable底层介绍
初始
- 底层由数组Hashtable$Entry[]初始化大小为11
- 初始临界值threeshold 8 = 11*0.75,所以也是到75%就扩容
- Hashtable除了第一次初始化大小,后面扩容机制为 *2+1.
Hashtable和HashMap的选择
| 实现类 | 出现版本 | 线程安全 | 效率 | 是否可以存null |
|---|---|---|---|---|
| HashMap | 1.2 | 不安全 | 高 | 允许 |
| Hashtable | 1.0 | 安全 | 较低 | 不允许 |
Properties
Properties基本介绍
- Properties类继承于Hahstable类,同样实现了Map接口,也是一种键key-值value的形式保存数据
- Properties的使用特点和Hashtable类似
- Properties还可以用于从xxx.properties文件中,加载数据到Properties类对象进行读取和修改(在IO流说明)
Properties的增删改查
public class test5 {
public static void main(String[] args) {
Properties properties = new Properties();
//增加
properties.put("no1",100);
properties.put("no2",200);
//删除,根据key,删除key-value
properties.remove("no1");
System.out.println(properties);
//改(替换)
properties.put("no2",90);
System.out.println(properties);
//查,根据key获取value
System.out.println(properties.get("no2"));
}
}