文章目录
- 字符串对象方法
- cat和指定字符串进行拼接
- 查看数据
- 不指定参数,所有姓名拼接
- 不指定参数,所有姓名拼接添加分隔符
- 添加数据
- 遇到空值时
- 合并
- split按照指定字符串分隔
- partition 按照指定字符串分割
- get 获取指定位置的字符,只能获取1个
- slice 获取指定范围的字
- slice_replace 筛选之后替换
- join将每个字符之间使用指定字符相连
- contains 判断字符串是否含有指定字串,返回的是bool类型
- startswith 是否某个字串开头
- endswith 判断是否以某个子串结尾
- repeat 重复字符串
- pad将每一个元素都用指定的字符填充,只能是一个字符
- zfill填充,只能是0,从左边填充
- strip 按照指定内容,从两边去除
- get_dummies
- translate 指定部分替换
- find 查找指定字符串第一次出现的位置
- 字母大小写
- 判断【返回T或F】
- match 是否匹配给定的模式
- extract 分组捕捉
字符串对象方法

cat和指定字符串进行拼接
查看数据
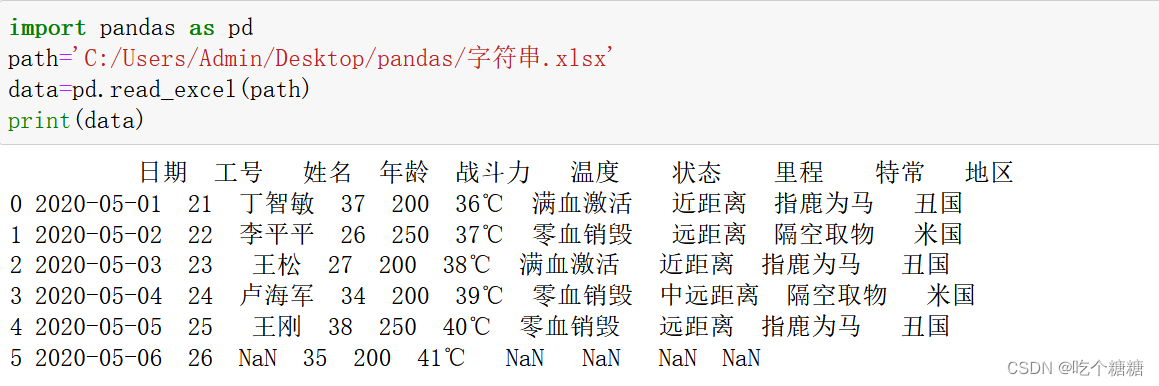
不指定参数,所有姓名拼接
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
print(data['姓名'].str.cat())# 不指定参数,所有姓名拼接

不指定参数,所有姓名拼接添加分隔符
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
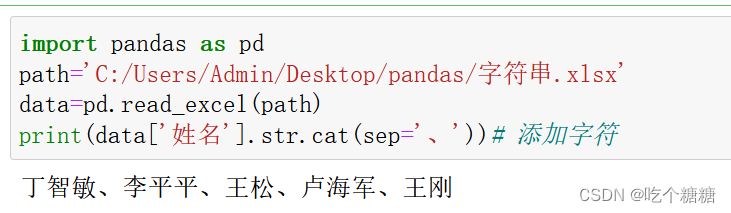
print(data['姓名'].str.cat(sep='、'))# 添加字符
添加数据
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
print(data['姓名'].str.cat(['变身']*len(data)))## ['变身'] * len(data) 相当于 ['变身'] * 6次

遇到空值时
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
print(data['里程'].str.cat(['快跑'] * len(data),sep='^',na_rep='@'))

合并

split按照指定字符串分隔
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
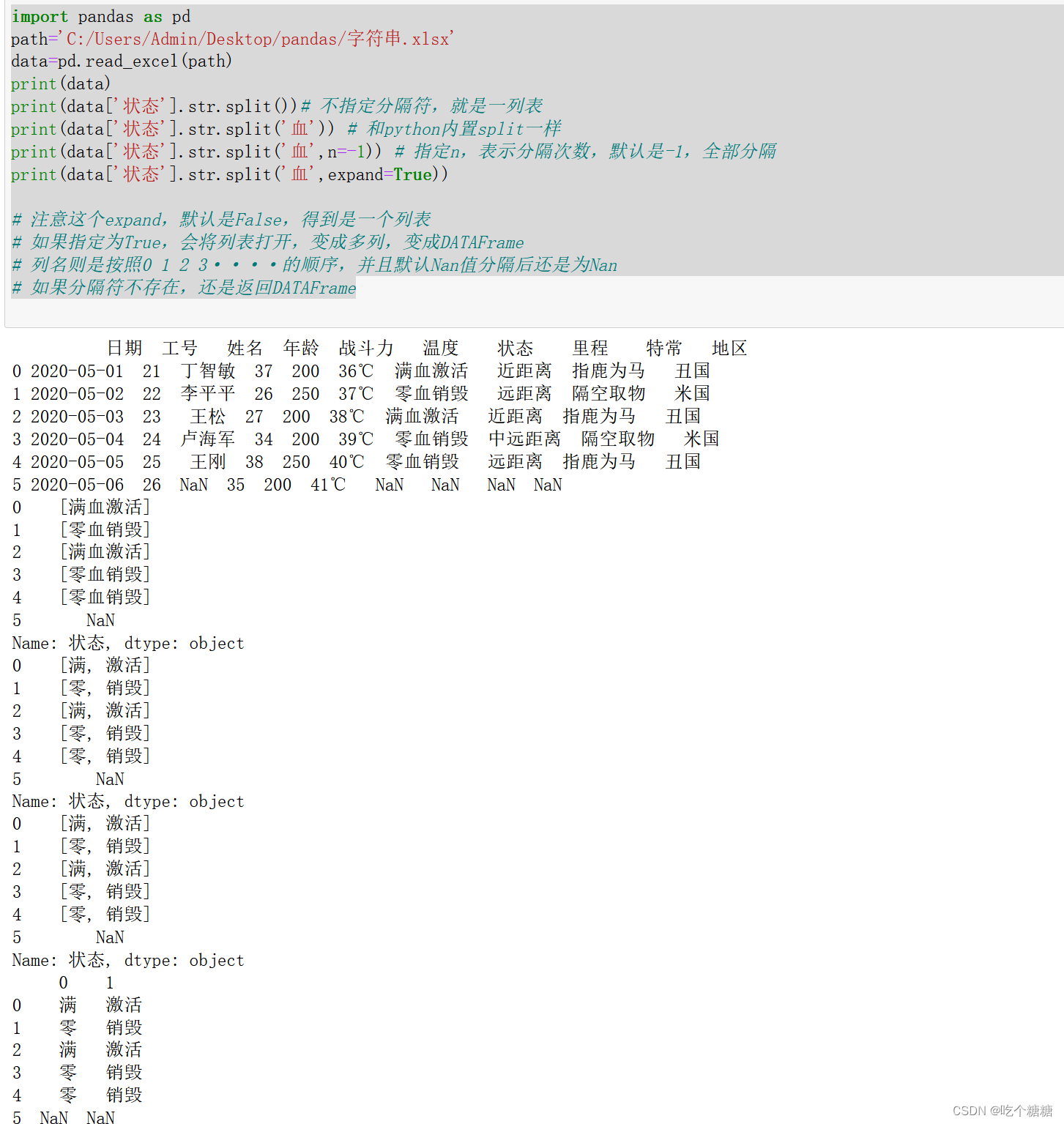
print(data)
print(data['状态'].str.split())# 不指定分隔符,就是一列表
print(data['状态'].str.split('血')) # 和python内置split一样
print(data['状态'].str.split('血',n=-1)) # 指定n,表示分隔次数,默认是-1,全部分隔
print(data['状态'].str.split('血',expand=True))
# 注意这个expand,默认是False,得到是一个列表
# 如果指定为True,会将列表打开,变成多列,变成DATAFrame
# 列名则是按照0 1 2 3····的顺序,并且默认Nan值分隔后还是为Nan
# 如果分隔符不存在,还是返回DATAFrame
partition 按照指定字符串分割
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
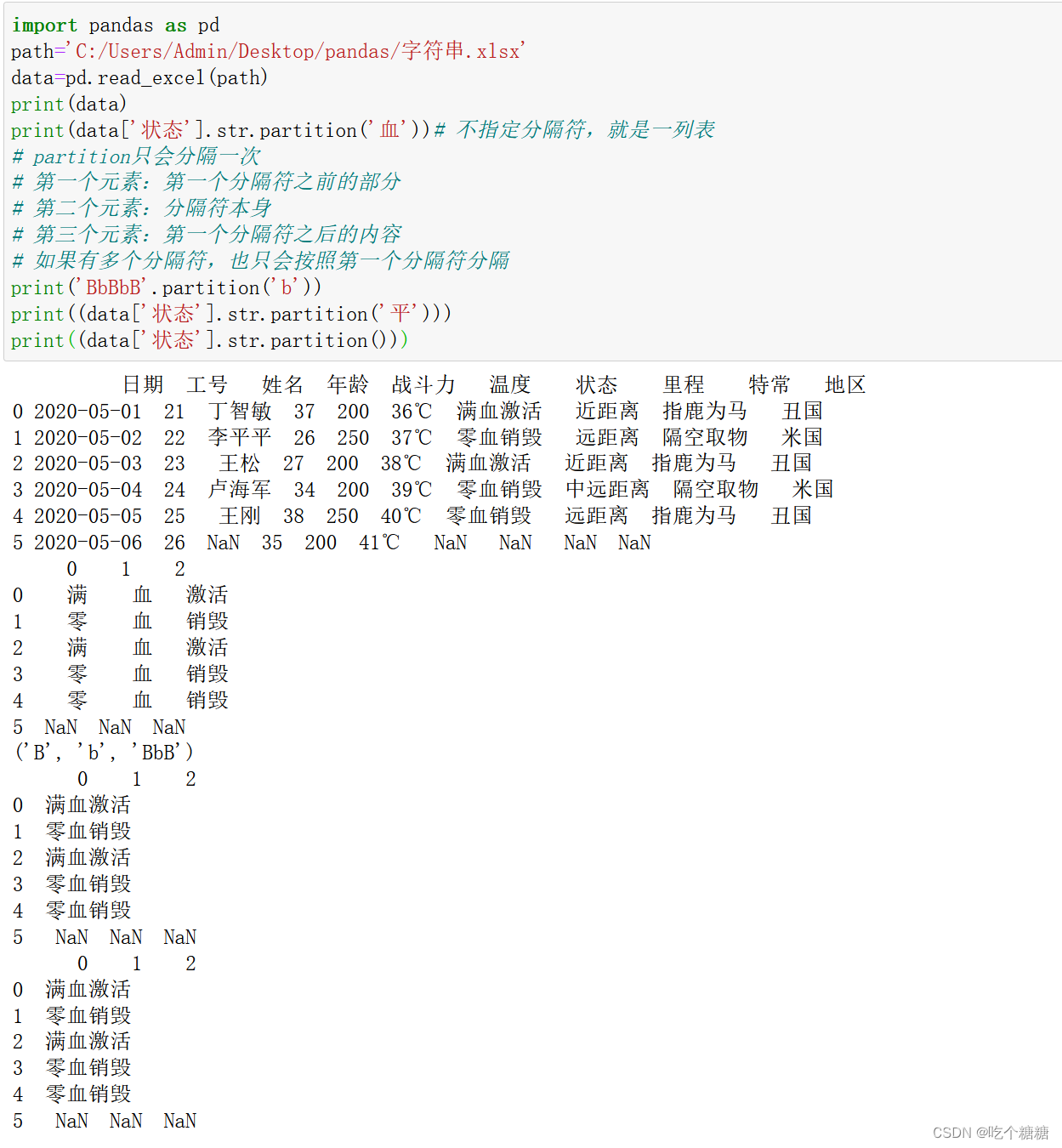
print(data)
print(data['状态'].str.partition('血'))# 不指定分隔符,就是一列表
# partition只会分隔一次
# 第一个元素:第一个分隔符之前的部分
# 第二个元素:分隔符本身
# 第三个元素:第一个分隔符之后的内容
# 如果有多个分隔符,也只会按照第一个分隔符分隔
print('BbBbB'.partition('b'))
print((data['状态'].str.partition('平')))
print((data['状态'].str.partition()))
get 获取指定位置的字符,只能获取1个
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
print(data)
print(data['状态'].get(2))
# 如果全部越界,那么None也为NaN,并且整体是float64类型
# 如果pandas用的时间比较长的话,一定会遇见该问题
# 像数据库、excel、csv等等,原来的类型明明为整型,但是读成DataFrame之后变成浮点型了
# 就是因为含有空值,变成float了。
"""
如果是object类型(或者理解为str),空值可以是None,也可以是NaN,但不可以是NaT
对于整型来说,如果含有空值,那么空值为NaN。
对于时间类型来说,如果含有空值,那么空值为NaT。
即使你想转化也是没用的,如果想把NaN或者NaT变成None,只有先变成object(str)类型,才可以转化
"""

slice 获取指定范围的字
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
print(data)
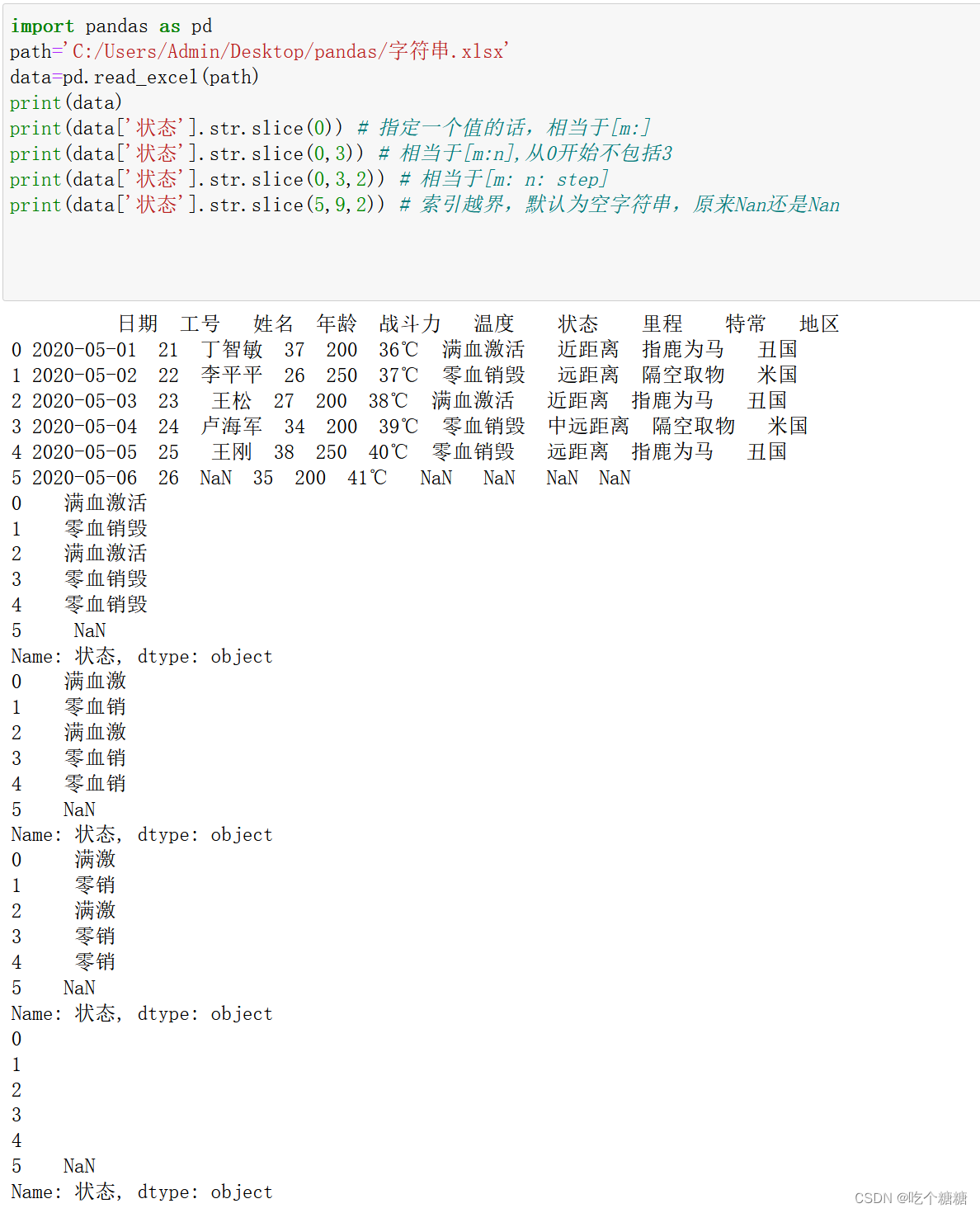
print(data['状态'].str.slice(0)) # 指定一个值的话,相当于[m:]
print(data['状态'].str.slice(0,3)) # 相当于[m:n],从0开始不包括3
print(data['状态'].str.slice(0,3,2)) # 相当于[m: n: step]
print(data['状态'].str.slice(5,9,2)) # 索引越界,默认为空字符串,原来Nan还是Nan
slice_replace 筛选之后替换
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
print(data)
print(data['状态'].str.slice_replace(1,3,"520")) # 指定一个值的话,相当于[m:]

join将每个字符之间使用指定字符相连
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
print(data)
print(data['状态'].str.join('a'))

contains 判断字符串是否含有指定字串,返回的是bool类型
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
print(data)
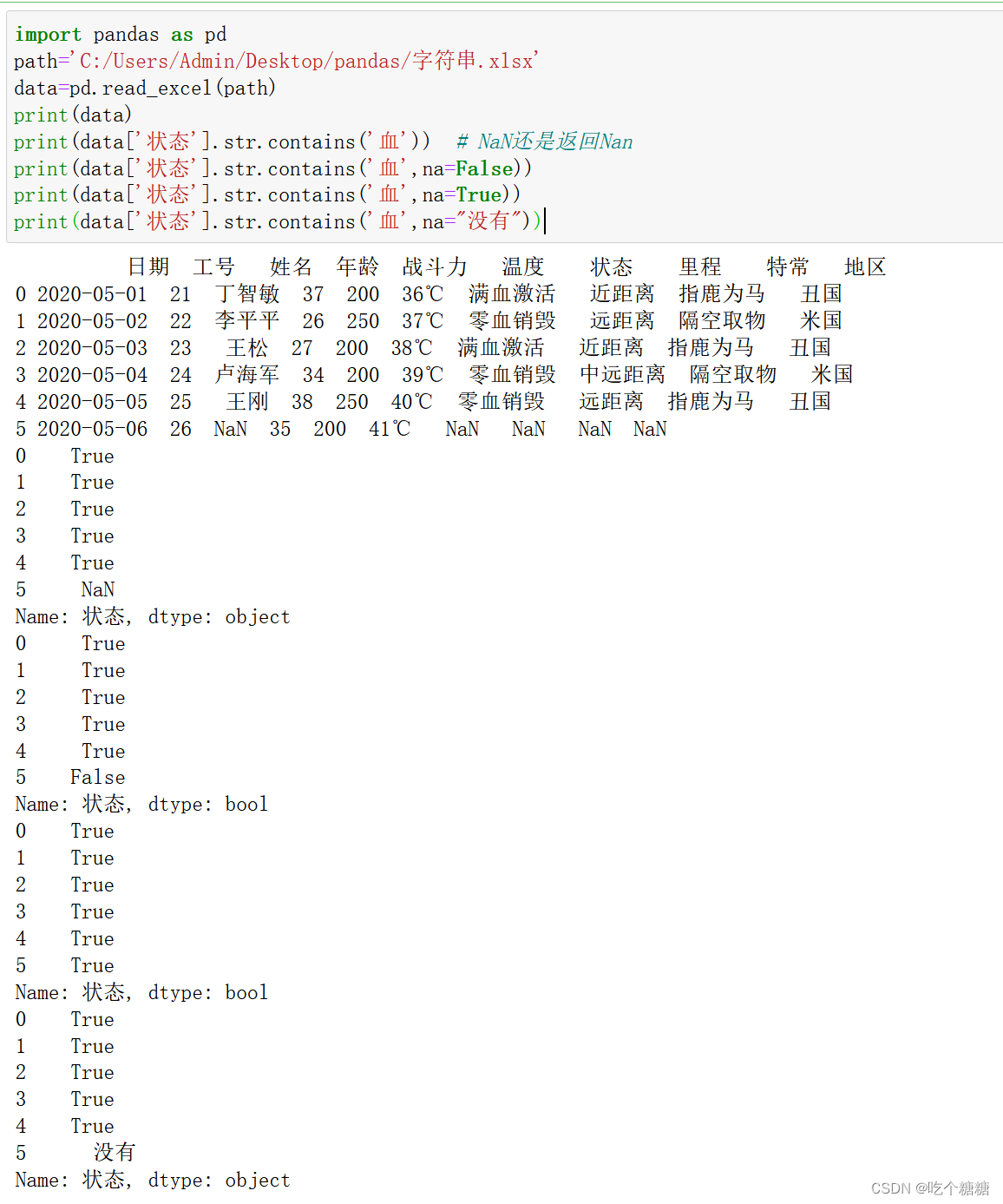
print(data['状态'].str.contains('血')) # NaN还是返回Nan
print(data['状态'].str.contains('血',na=False))
print(data['状态'].str.contains('血',na=True))
print(data['状态'].str.contains('血',na="没有"))
startswith 是否某个字串开头
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
print(data)
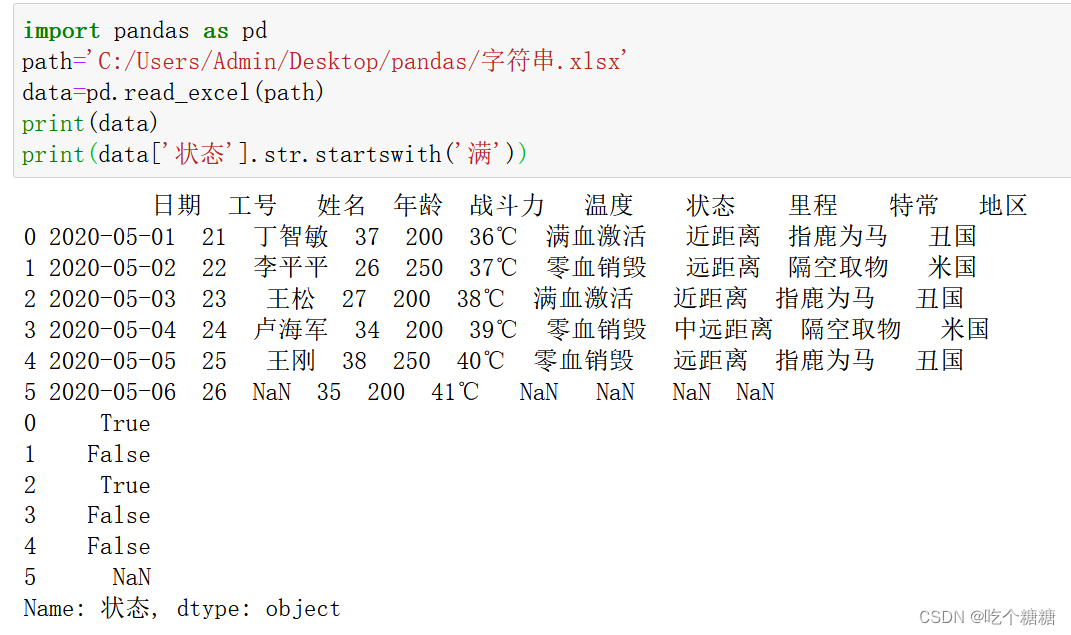
print(data['状态'].str.startswith('满'))
endswith 判断是否以某个子串结尾
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
print(data)
print(data['状态'].str.endswith('满'))

repeat 重复字符串
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
print(data)
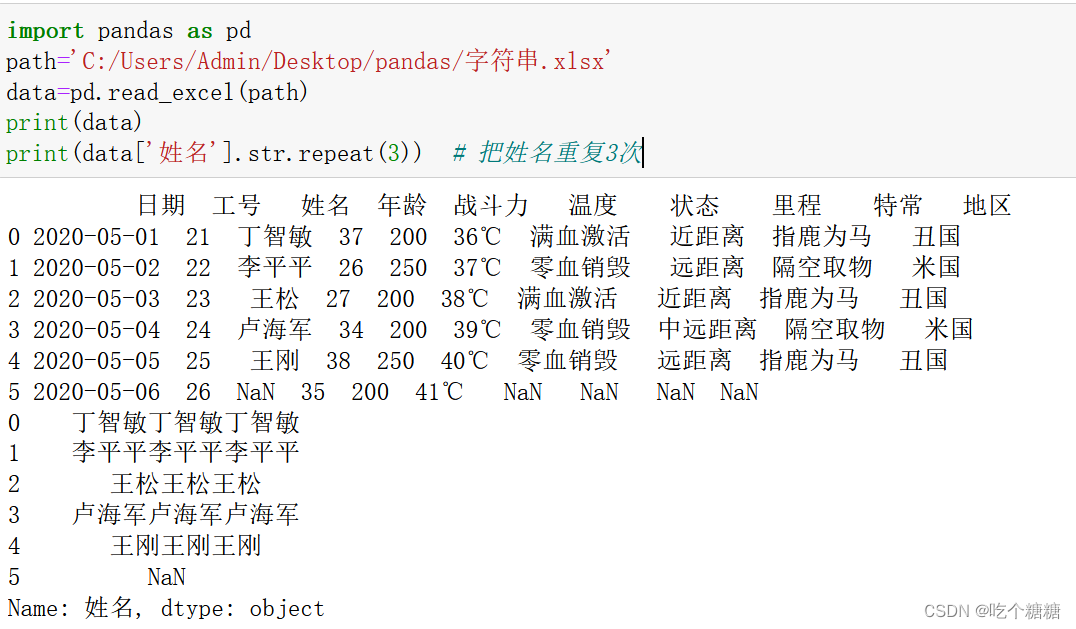
print(data['姓名'].str.repeat(3)) # 把姓名重复3次
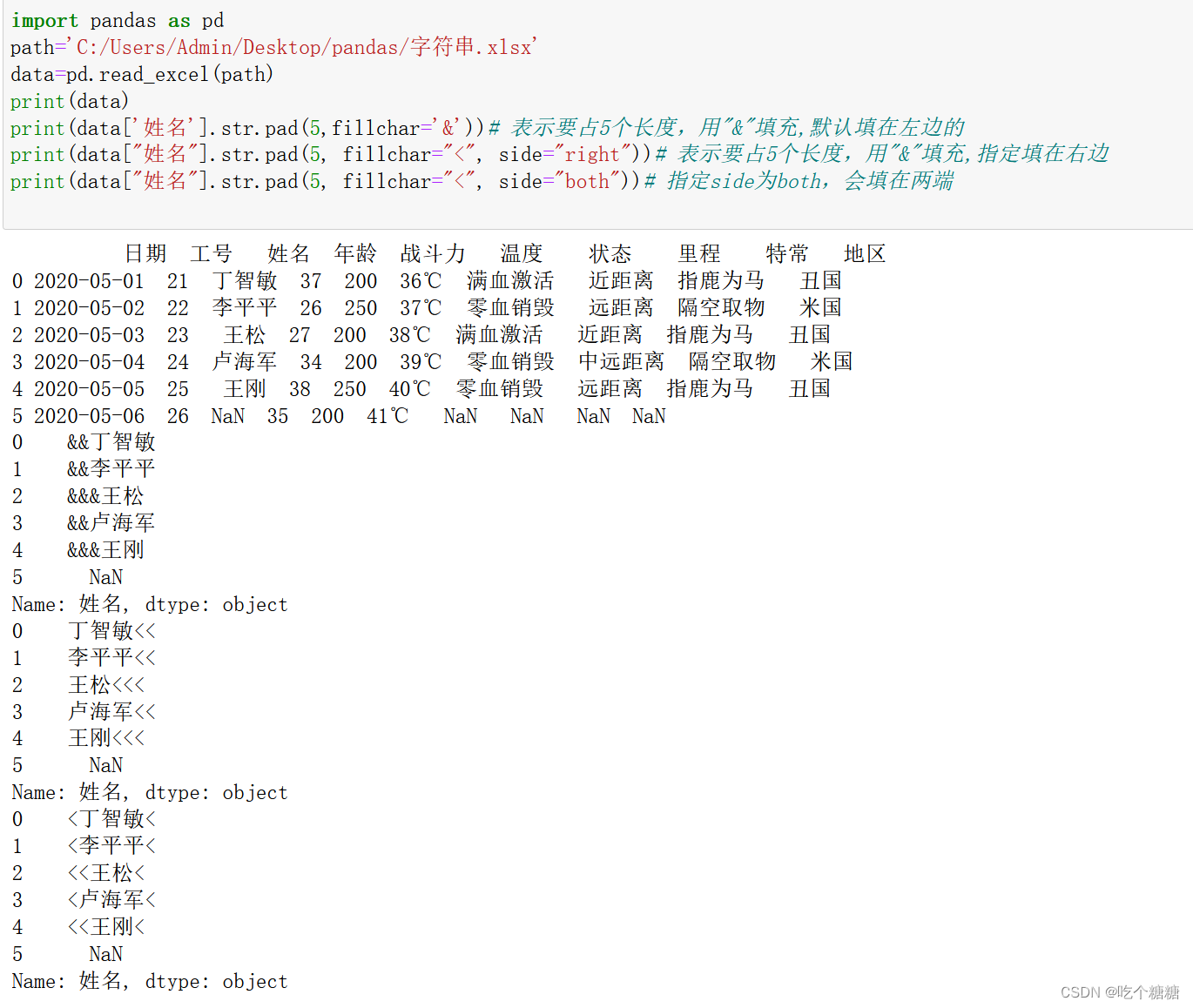
pad将每一个元素都用指定的字符填充,只能是一个字符
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
print(data)
print(data['姓名'].str.pad(5,fillchar='&'))# 表示要占5个长度,用"&"填充,默认填在左边的
print(data["姓名"].str.pad(5, fillchar="<", side="right"))# 表示要占5个长度,用"&"填充,指定填在右边
print(data["姓名"].str.pad(5, fillchar="<", side="both"))# 指定side为both,会填在两端
zfill填充,只能是0,从左边填充
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
print(data)
print(data['姓名'].str.zfill(10))

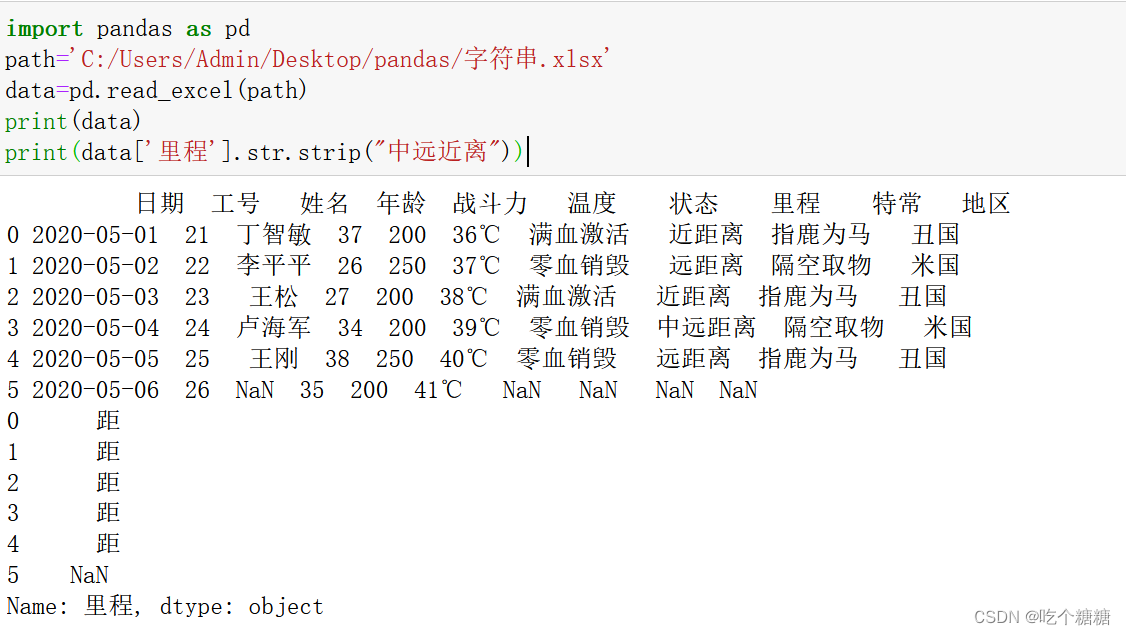
strip 按照指定内容,从两边去除
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
print(data)
print(data['里程'].str.strip("中远近离"))
get_dummies
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
print(data)
print(data['里程'].str.get_dummies('距'))
# 按照"距"进行分割,得到列表
# 所有列表中的元素总共有"中远、近、远、离"四种

translate 指定部分替换
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
print(data)
字典 = str.maketrans({'距':'ju','离':'li'})
print(data['里程'].str.translate(字典))

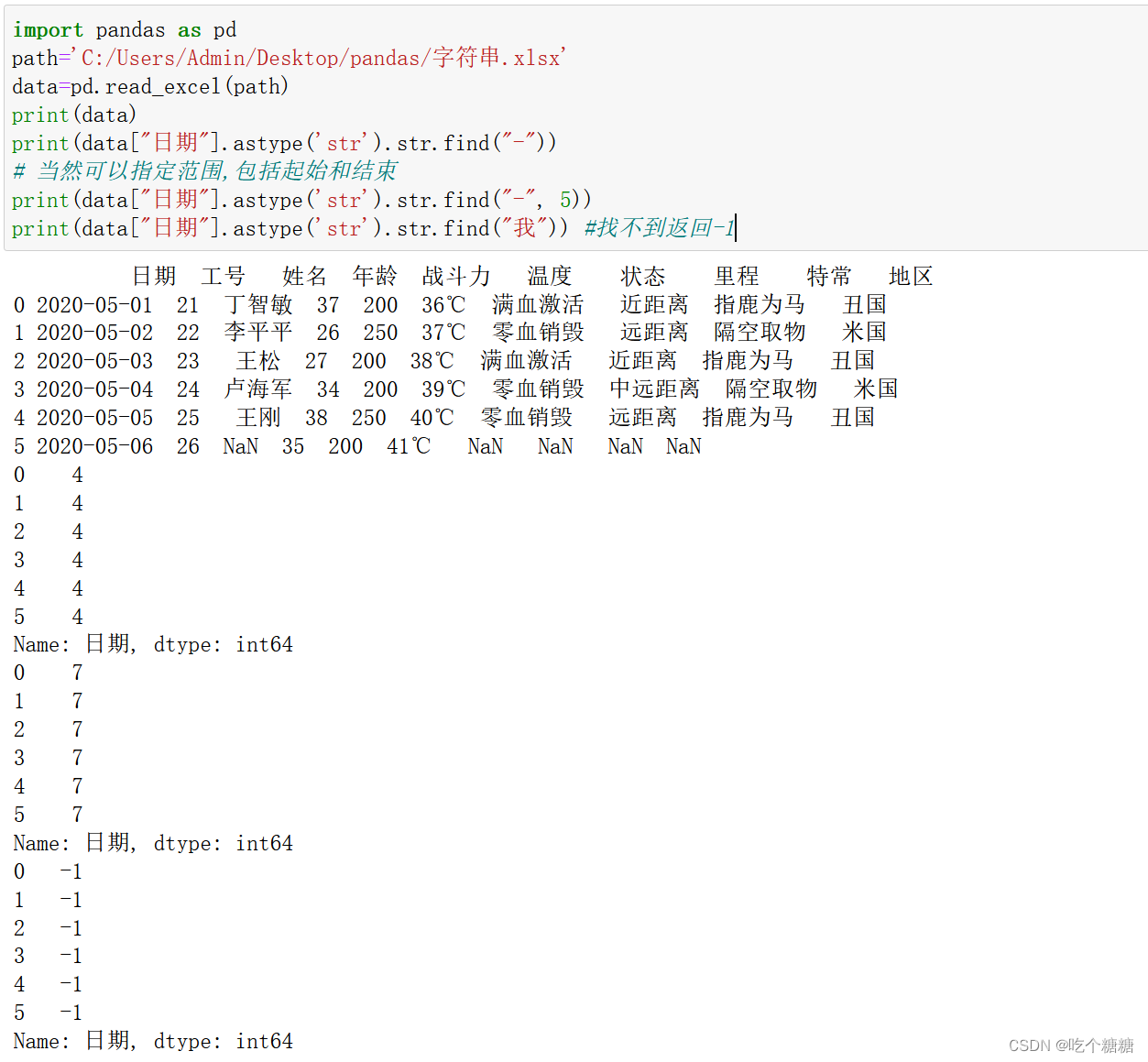
find 查找指定字符串第一次出现的位置
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
print(data)
print(data["日期"].astype('str').str.find("-"))
# 当然可以指定范围,包括起始和结束
print(data["日期"].astype('str').str.find("-", 5))
print(data["日期"].astype('str').str.find("我")) #找不到返回-1

字母大小写

判断【返回T或F】

match 是否匹配给定的模式
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
print(data)
print(data['状态'].str.match(".{2}激"))
# NaN还是返回Nan,可按照 na= False 或 na = True 替换

extract 分组捕捉
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/字符串.xlsx'
data=pd.read_excel(path)
print(data)
print(data["日期"].astype('str').str.extract("\d{4}-(\d{2})-(\d{2})"))