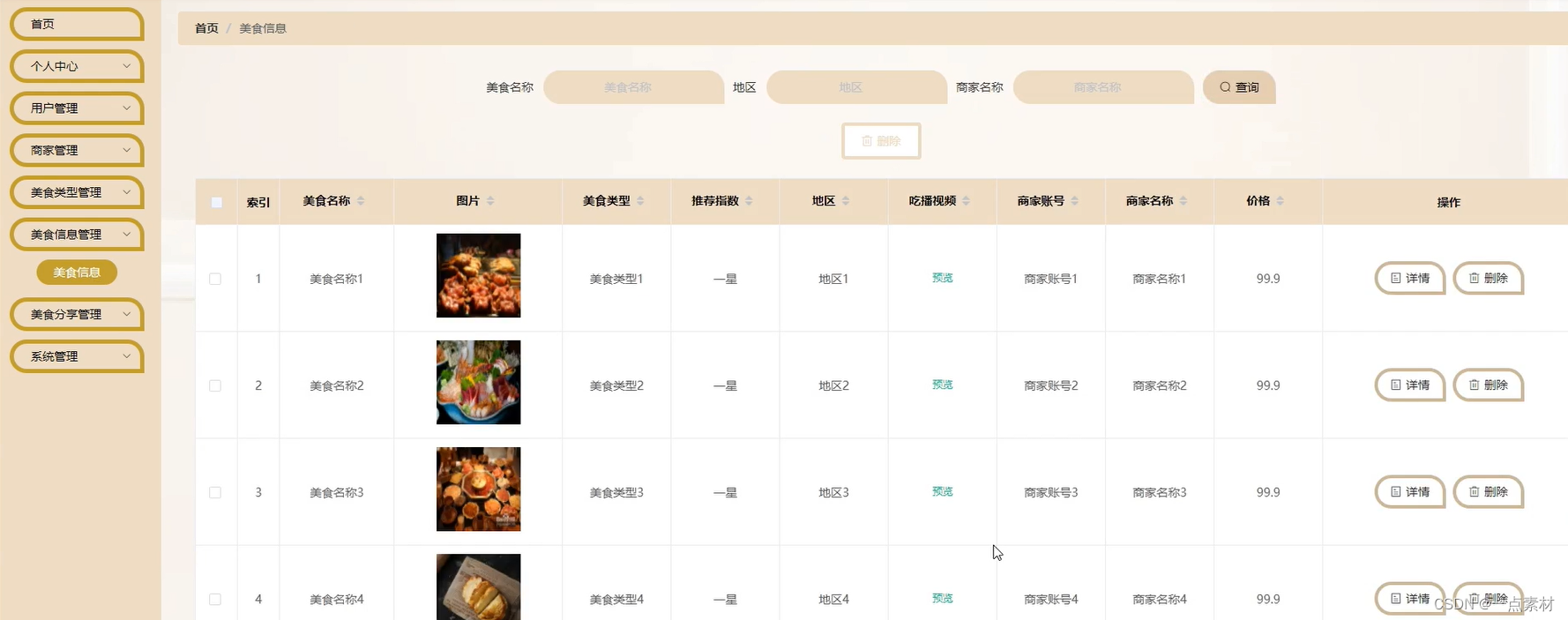
PostgreSQL16-新特性-新增IO统计视图:pg_stat_io
我们DBA常遇到的问题是:如何优化数据库的IO操作?
获取PG服务产生的所有IO情况历来都是一个挑战。首先,PG将IO行为范围内为写WAL和读写数据目录(也就是数据文件)。真正的挑战是:理解围绕写入的二阶效应:通常数据的写入发生在事务提交后,即异步刷写,这就对理解哪个进程实际写入数据目录(以及何时)带来困难。
当面临预分配的IOPS或者像Amazon Aurora付费单独的IO时,在云中这种情况更具挑战。通常情况下解决方案是查看系统中具有检测功能的部分(例如单个查询),从而至少了解活动发生的位置。
上周末,由Andres Freund提交 Melanie Plageman的patch:对IO活动可见性的重大改进。Samay Sharma提供了文档。我的同事 Maciek Sakrejda 和我已经通过各种迭代审查了这个补丁,我们对它给 Postgres 可观察性带来的影响感到非常兴奋。下面是commit记录:感兴趣可查看:
https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=a9c70b46dbe152e094f137f7e6ba9cd3a638ee25
欢迎pg_stat_io,我们一起看下:
1、在 Postgres 中查询系统范围的 I/O 统计信息
从开发分支编译个新的版本。PG16仍旧在开发中,甚至还没到beta阶段,绝对不应在生产环境中适应。
可以从查询开始,看看pg_stat_io都跟踪了哪些信息:
SELECT * FROM pg_stat_io WHERE reads <> 0 OR writes <> 0 OR extends <> 0;| writes | extends | op_bytes | evictions | reuses | fsyncs | stats_reset
---------------------+-----------+------------+----------+---------+---------+----------+-----------+----------+--------+-------------------------------
autovacuum launcher | relation | normal | 19 | 5 | | 8192 | 13 | | 0 | 2023-02-13 11:50:27.583875-08
autovacuum worker | relation | normal | 15972 | 2494 | 2894 | 8192 | 17430 | | 0 | 2023-02-13 11:50:27.583875-08
autovacuum worker | relation | vacuum | 5754853 | 3006563 | 0 | 8192 | 2056 | 5752594 | | 2023-02-13 11:50:27.583875-08
client backend | relation | bulkread | 25832582 | 626900 | | 8192 | 753962 | 25074439 | | 2023-02-13 11:50:27.583875-08
client backend | relation | bulkwrite | 4654 | 2858085 | 3259572 | 8192 | 998220 | 2209070 | | 2023-02-13 11:50:27.583875-08
client backend | relation | normal | 960291 | 376524 | 159497 | 8192 | 1103707 | | 0 | 2023-02-13 11:50:27.583875-08
client backend | relation | vacuum | 128710 | 0 | 0 | 8192 | 1221 | 127489 | | 2023-02-13 11:50:27.583875-08
background worker | relation | bulkread | 39059938 | 590896 | | 8192 | 802939 | 38253662 | | 2023-02-13 11:50:27.583875-08
background worker | relation | normal | 257533 | 118972 | 0 | 8192 | 256437 | | 0 | 2023-02-13 11:50:27.583875-08
background writer | relation | normal | | 243142 | | 8192 | | | 0 | 2023-02-13 11:50:27.583875-08
checkpointer | relation | normal | | 390141 | | 8192 | | | 18812 | 2023-02-13 11:50:27.583875-08
standalone backend | relation | bulkwrite | 0 | 0 | 8 | 8192 | 0 | 0 | | 2023-02-13 11:50:27.583875-08
standalone backend | relation | normal | 689 | 983 | 470 | 8192 | 0 | | 0 | 2023-02-13 11:50:27.583875-08
standalone backend | relation | vacuum | 10 | 0 | 0 | 8192 | 0 | 0 | | 2023-02-13 11:50:27.583875-08
(14 rows)大致上,此信息可以解释为:
1)跟踪给定后台类型、IO对象类型(是否是临时表)和IO上下文
2)主要统计数据是计数IO操作:读、写和extend(特殊类型的写,扩展数据文件)
3)对于每个IO操作,以字节为单位解释统计信息(目前是块大小,默认8KB)
4)对shared buffer的驱逐次数、ring buffer重用次数和fsync调用次数进行了追踪
PG16中系统范围的信息将始终可用。可以在PG手册中查看每个字段详细信息。
注意,pg_stat_io显示了PG发起的逻辑IO操作。这通常会映射到真实的磁盘IO(尤其是写),操作系统由他自己的cache和batching机制,例如经常将8kb的写拆分为两个单独的4kb写入文件系统。通常我们假设这捕获了PG发起的所有IO,除了:
1)WAL的IO
2)特殊场景,比如表在表空间之间移动
3)临时文件(比如排序中使用的,或者像pg_stat_statements扩展使用的)
注意,追踪临时relations(和临时文件不一样):io_object = "temp relation"- 您可能熟悉它们在其他统计视图中被称为“本地缓冲区”
有了这些基础知识,我们可以仔细研究一些用例来了解为什么这很重要。
2、pg_stat_io用例
2.1跟踪PG write IO活动
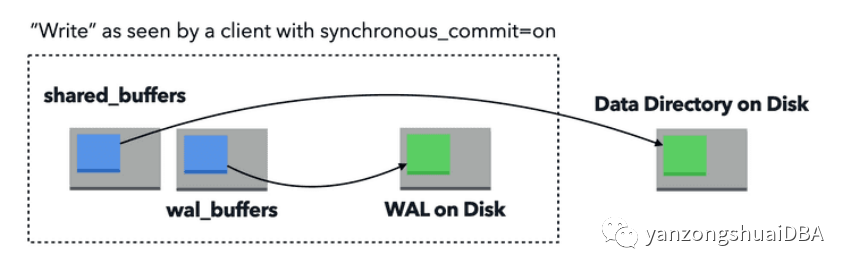
PG中write的生命周期,以及目前在大多数统计中不可见的内容
查看PG write时,需要了解查询运行时客户端看到的或者pg_stat_statement跟踪的东西。PG有一个复杂的机制确保write的持久性,允许客户端立即返回,相信服务已经以crash safe的方式持久化了数据。
首先PG持久化数据左的第一件事是写WAL日志。一旦日志写成功,客户端会接收到写成功的确认。但是之后发生的事情是额外的统计跟踪派上用场的地方。
例如,如果您在pg_stat_statements中查看给定的 INSERT 语句,该shared_blks_written字段通常会告诉您几乎什么都没有,因为对数据目录的实际写入通常发生在稍后的时间,以便批量写入以提高效率并避免 I/O 峰值。
除了写入 WAL 之外,Postgres 还将为写入更新共享(或本地)缓冲区。这样的更新会将有修改的缓冲区页面标记为“脏”。
然后,在大多数情况下,另一个进程负责实际将脏页写入数据目录。需要考虑三种主要的流程类型:
1)后台写进程:在后台持续运行,刷写脏页
2)检查点进程:周期性执行checkpoint,或者WAL写到一定量时,将所有脏页全部刷写
3)所有其他进程类型:包括常规客户端后端,如果他们需要驱逐脏页,则需要将脏页刷写。
需要了解的主要事情是第三种情况的发生:因为他会大大拖慢查询速度。即使一个简单的SELECT也可能不得不突然刷写磁盘,然后才能在共享缓冲区中有足够的空间来读取数据。
你可以从pg_stat_bgwriter视图中看到其中的一些活动,特别是名为buffers_字段。但这些信息不完整,没有明确考虑autovacuum活动,也没有让您了解刷写的根本原因(例如缓冲区驱逐)。
可以观察pg_stat_io的writes字段,查看准确的汇总数据,以及PG中哪个进程实际最终将数据刷写磁盘。
2.2通过监控共享缓冲区逐出提高工作负载稳定性和调整 shared_buffers 大小
pg_stat_io帮助澄清的一个重要的指标是:shared buffer(Shared buffer是固定大小,以页为单位)中一个缓冲页被驱逐的位置。什么内容缓冲在缓冲页中非常重要--尤其当工作集超过shared buffer大小时。
默认情况下shared_buffers为128MB(16000页)。想象下一个差劲的索引扫描耗光了128MB。
当你突然读到完全不同的东西时会发生什么?PG不得不从cache中驱逐一些老数据,也就是驱逐一个buffer page。
驱逐带来两方面主要影响:
1)以前在PG缓冲区中的数据,不在了。当然仍有可能在操作系统cache中。
2)如果页驱逐时被标记为脏,进程驱逐时也会将老页写页磁盘。
这两个方面对于调整共享缓冲区的大小都很重要。pg_stat_io可以通过跟踪系统中每个后端类型的evictions清楚的显示。如果您看到逐出突然激增,然后突然很多reads,它可以帮助您推断被逐出的缓存数据实际上在不久之后再次需要。如果有疑问,您可以使用pg_buffercache扩展来详细查看当前共享缓冲区的内容。
2.3通过autovacuum和手动VACUUM跟踪累积的IO活动
事实上,每个 Postgres 服务器偶尔都需要 VACUUM - 无论您是手动安排它,还是让 autovacuum 为您处理它。它有助于清理死行并使空间可重用,它冻结页面以防止事务 ID 回绕。
但若没有正确调整,VACUUM和autovacuum会对IO产生巨大影响。最好的办法就是查看输出log_autovacuum_min_duration,会提供如下类似信息:
LOG: automatic vacuum of table "mydb.pg_toast.pg_toast_42593": index scans: 0
pages: 0 removed, 13594 remain, 13594 scanned (100.00% of total)
tuples: 0 removed, 54515 remain, 0 are dead but not yet removable
removable cutoff: 11915, which was 6 XIDs old when operation ended
new relfrozenxid: 11915, which is 4139 XIDs ahead of previous value
frozen: 13594 pages from table (100.00% of total) had 54515 tuples frozen
index scan not needed: 0 pages from table (0.00% of total) had 0 dead item identifiers removed
avg read rate: 0.113 MB/s, avg write rate: 0.113 MB/s
buffer usage: 13614 hits, 13602 misses, 13600 dirtied
WAL usage: 40786 records, 13600 full page images, 113072608 bytes
system usage: CPU: user: 0.26 s, system: 0.52 s, elapsed: 939.84 s从中buffer usage您可以确定这个单个 VACUUM 必须读取 13602 页,并将 13600 页标记为脏。但是,如果我们想要获得更完整的画面,并且跨越我们所有的 VACUUM,该怎么办?
您现在可以通过查看标记为或与后端类型关联的pg_stat_io所有内容来查看系统范围内对 VACUUM 影响的测量:io_context = 'vacuum'autovacuum worker
SELECT * FROM pg_stat_io WHERE backend_type = 'autovacuum worker' OR (io_context = 'vacuum' AND (reads <> 0 OR writes <> 0 OR extends <> 0));backend_type | io_object | io_context | reads | writes | extends | op_bytes | evictions | reuses | fsyncs | stats_reset
--------------------+-----------+------------+---------+---------+---------+----------+-----------+---------+--------+-------------------------------
autovacuum worker | relation | bulkread | 0 | 0 | | 8192 | 0 | 0 | | 2023-02-13 11:50:27.583875-08
autovacuum worker | relation | normal | 16306 | 2494 | 2915 | 8192 | 17785 | | 0 | 2023-02-13 11:50:27.583875-08
autovacuum worker | relation | vacuum | 5824251 | 3028684 | 0 | 8192 | 2588 | 5821460 | | 2023-02-13 11:50:27.583875-08
client backend | relation | vacuum | 128710 | 0 | 0 | 8192 | 1221 | 127489 | | 2023-02-13 11:50:27.583875-08
standalone backend | relation | vacuum | 10 | 0 | 0 | 8192 | 0 | 0 | | 2023-02-13 11:50:27.583875-08
(5 rows)在此特定示例中,autovacuum worker 总共读取了 44.4 GB 的数据(5,824,251 个缓冲页),并写入了 23.1GB(3,028,684 个缓冲页)。
随着时间的推移跟踪这些统计数据,它将帮助您清楚地了解 autovacuum 是否是工作时间内 I/O 峰值的罪魁祸首。它还将帮助您更自信地进行更改以调整 autovacuum,例如,使 autovacuum 更具侵略性以防止膨胀。
2.4批量读/写策略的可见性(顺序扫描和COPY)
你在 Postgres 中使用过 COPY 加载数据吗?或者使用顺序扫描从表中读取数据?您可能不知道,在大多数情况下,这些数据不会以常规方式通过共享缓冲区。相反,Postgres 使用一个特殊的专用环形缓冲区来确保大多数共享缓冲区不受此类大型活动的干扰。
以前pg_stat_io,几乎不可能理解 Postgres 中的此活动,因为根本没有对其进行跟踪。现在,我们终于可以看到批量读取(通常是大型顺序扫描)和批量写入(通常是 COPY in),以及它们引起的 I/O 活动。
您可以简单地过滤中的新值bulkwrite和值,并查看此活动:bulkreadio_context
SELECT * FROM pg_stat_io WHERE io_context IN ('bulkread', 'bulkwrite') AND (reads <> 0 OR writes <> 0 OR extends <> 0);backend_type | io_object | io_context | reads | writes | extends | op_bytes | evictions | reuses | fsyncs | stats_reset
--------------------+-----------+------------+----------+---------+---------+----------+-----------+----------+--------+-------------------------------
client backend | relation | bulkread | 25900458 | 627059 | | 8192 | 754610 | 25141667 | | 2023-02-13 11:50:27.583875-08
client backend | relation | bulkwrite | 4654 | 2858085 | 3259572 | 8192 | 998220 | 2209070 | | 2023-02-13 11:50:27.583875-08
background worker | relation | bulkread | 39059938 | 590896 | | 8192 | 802939 | 38253662 | | 2023-02-13 11:50:27.583875-08
standalone backend | relation | bulkwrite | 0 | 0 | 8 | 8192 | 0 | 0 | | 2023-02-13 11:50:27.583875-08
(4 rows)在此示例中,有 495 GB 的批量读取活动和 21 GB 的批量写入活动,我们之前没有很好的识别方法。然而,最重要的是,我们不必担心evictions这里的计数——这些都是来自特殊批量读/批量写环形缓冲区的驱逐,而不是来自常规共享缓冲区的驱逐。
3、Postgres 中 I/O 可观察性的未来
pg_stat_io的基础工作在PG15之前就开始做了。PG15之前,统计信息跟踪必须通过统计信息收集器,速度慢且容易出错。这在历史上限制了轻松收集更高级统计数据的能力。随着增加pg_stat_io,现在更容易跟踪有关 Postgres 如何运行的附加信息。
已经讨论的直接改进包括:
1)跟踪系统范围的缓冲区缓存命中(以允许计算准确的缓冲区缓存命中率)
2)累积的系统范围 I/O 时间(不仅仅是当前存在的 I/O 计数pg_stat_io)
3)更好的累积 WAL 统计数据(即超越 pg_stat_wal 提供的)
4)表和索引的附加 I/O 跟踪
4、原文
https://pganalyze.com/blog/pg-stat-io