一,定义:
可以在logN时间内实现区间修改,单点修改,区间查询等操作的工具
二,思路(修改无乘法时):
1,建树
通过把区间不断二分建立一颗二叉树
我们以维护一个数组a={1,2,3,4,5}为例子
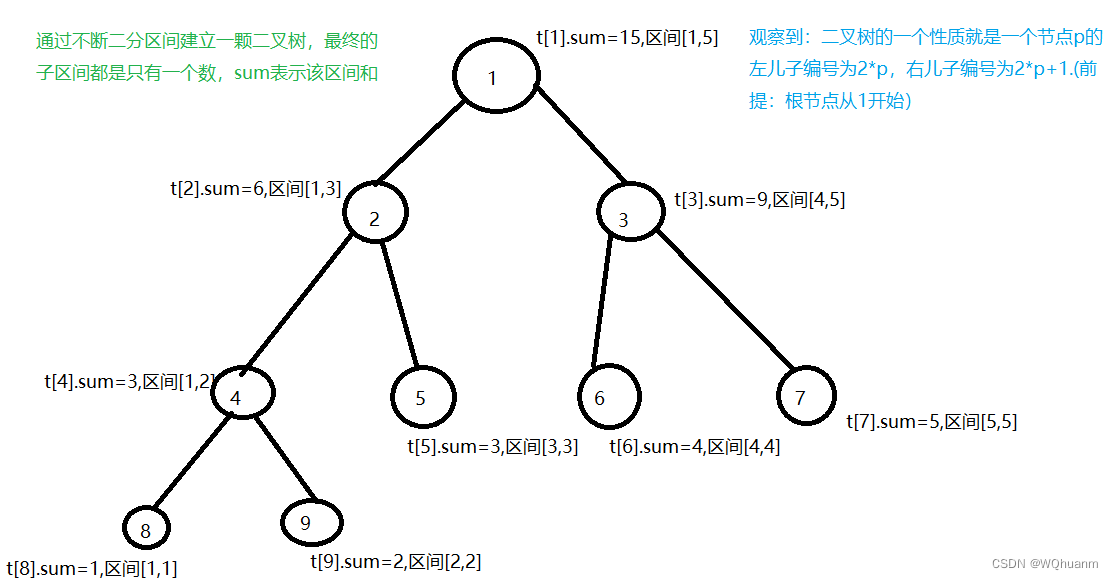
int a[N];
struct tree//我们以结构体来存储一颗树
{
int l, r;//l,r表示该节点的区间
ll sum, add;//sum表示区间和,add为懒惰标记
} t[N * 4 + 2]; //如果维护n个节点的区间,建立完整的二叉树大概需要4*n个树节点
void build(int l, int r, int p)
{
t[p].l = l, t[p].r = r; //首先存储节点p的区间
if (l == r)//如果区间只有一个点
{
t[p].sum = a[l];//sum就是这个点的值
return;
}
//否则继续二分遍历
int mid = l + ((r - l) >> 1);// 移位运算符的优先级小于加减法,所以加上括号, // 如果写成 (l + r) >> 1 可能会超出 int 范围
build(l, mid, 2 * p);
build(mid + 1, r, 2 * p + 1);
t[p].sum = t[2 * p].sum + t[2 * p + 1].sum;//回来后区间和就等于儿子们的区间和之和
}2,区间修改与懒惰标记
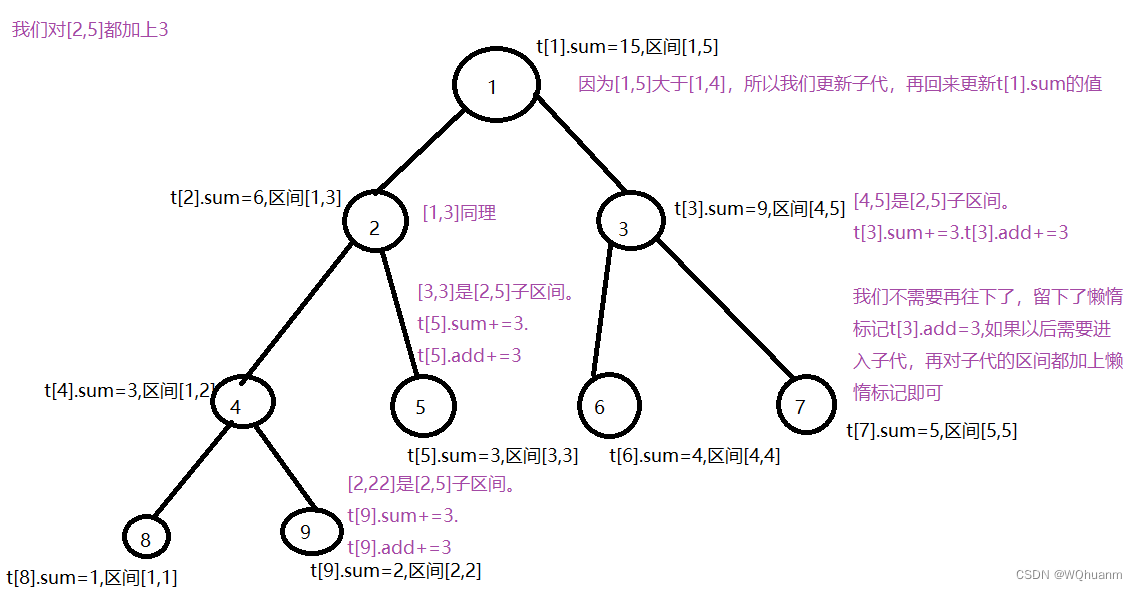
我们思考,如果我们给区间[2,5]都加上3,后面查询的时候只查询过[3,5]。那么请问,我们有没有必要花时间去更新[2,2]有加上3这件事呢。
显然没有必要,所以我们想要偷懒,我可以对你的修改标记一下,只有到我需要用到你时,才去修改他。
方法就是当我们更新一个区间时,我们就对这个区间进行标记(记录其修改的记录),如果后面我们要访问他的子代,我们首先先询问是否这个区间有标记,有则先更新他的子代,才可以去访问子代。
有了懒惰标记,我们每次深入只要深入到当前区间是目标区间子集就可以不用深入了,然后留下懒惰标记即可
void lazy(int p)
{
if (t[p].l == t[p].r)t[p].add = 0;//如果该区间只有一个点,毫无疑问他没有儿子,直接删除他的懒惰标记
if (t[p].add)//如果懒惰区间不为0,更新儿子信息
{
//对儿子们的区间和更新
t[2 * p].sum += t[p].add * (t[2 * p].r - t[2 * p].l + 1);
t[2 * p + 1].sum += t[p].add * (t[2 * p + 1].r - t[2 * p + 1].l + 1);
//每次更新区间就更新这个区间的懒惰标记,这样儿子访问子代时其懒惰区间才可以正常使用
t[2 * p].add += t[p].add;
t[2 * p + 1].add += t[p].add;
//最后重置p的懒惰标记(他就是为子代存在的,而我们已经更新完子代了)
t[p].add = 0;
}
}
void addupdate(int l, int r, int p, ll z)
{
if (l <= t[p].l && t[p].r <= r)//如果当前p的区间是目标区间的子集,更新其区间值和懒惰标记就可以返回了
{
t[p].sum += z * (t[p].r - t[p].l + 1);
t[p].add += z;
return;
}
//如果不是全部属于目标区间,访问子代前先更新子代,清空自己的懒惰标记
lazy(p);
int mid = t[p].l + ((t[p].r - t[p].l) >> 1);
if (l <= mid)addupdate(l, r, 2 * p, z);//如果[t[p].l,mid]有一部分属于目标区间,更新[l,mid]
if (r > mid)addupdate(l, r, 2 * p + 1, z);//[mid+1,t[p].r]同理
t[p].sum = t[2 * p].sum + t[2 * p + 1].sum;//回来后重新更新t[p].sum(因为子代已经更新)
}3,查询区间(单点值)
和修改的思考差不多,当前区间为目标区间子集就直接访问。否则就更新子代后深入子代
ll ask(int l, int r, int p)
{
if (l <= t[p].l && t[p].r <= r)return t[p].sum;//属于子集直接返回
lazy(p);//如果不是全部属于目标区间,访问子代前先更新子代,清空自己的懒惰标记
int mid = t[p].l + ((t[p].r - t[p].l) >> 1);
ll ans = 0;//ans累积属于目标区间的和
if (l <= mid)ans += ask(l, r, 2 * p);
if (r > mid)ans += ask(l, r, 2 * p + 1);
return ans;
}三:模板题1:P3372 【模板】线段树 1
#include <bits/stdc++.h>
using namespace std;
#define ll long long
#define int ll
const int N = 1e5 + 10;
int a[N];
struct tree//我们以结构体来存储一颗树
{
int l, r;//l,r表示该节点的区间
ll sum, add;//sum表示区间和,add为懒惰标记
} t[N * 4 + 2]; //如果维护n个节点的区间,建立完整的二叉树大概需要4*n个树节点
void build(int l, int r, int p)
{
t[p].l = l, t[p].r = r; //首先存储节点p的区间
if (l == r)//如果区间只有一个点
{
t[p].sum = a[l];//sum就是这个点的值
return;
}
//否则继续二分遍历
int mid = l + ((r - l) >> 1);// 移位运算符的优先级小于加减法,所以加上括号, // 如果写成 (l + r) >> 1 可能会超出 int 范围
build(l, mid, 2 * p);
build(mid + 1, r, 2 * p + 1);
t[p].sum = t[2 * p].sum + t[2 * p + 1].sum;//回来后区间和就等于儿子们的区间和之和
}
void lazy(int p)
{
if (t[p].l == t[p].r)t[p].add = 0;//如果该区间只有一个点,毫无疑问他没有儿子,直接删除他的懒惰标记
if (t[p].add)//如果懒惰区间不为0,更新儿子信息
{
//对儿子们的区间和更新
t[2 * p].sum += t[p].add * (t[2 * p].r - t[2 * p].l + 1);
t[2 * p + 1].sum += t[p].add * (t[2 * p + 1].r - t[2 * p + 1].l + 1);
//每次更新区间就更新这个区间的懒惰标记,这样儿子访问子代时其懒惰区间才可以正常使用
t[2 * p].add += t[p].add;
t[2 * p + 1].add += t[p].add;
//最后重置p的懒惰标记(他就是为子代存在的,而我们已经更新完子代了)
t[p].add = 0;
}
}
void addupdate(int l, int r, int p, ll z)
{
if (l <= t[p].l && t[p].r <= r)//如果当前p的区间是目标区间的子集,更新其区间值和懒惰标记就可以返回了
{
t[p].sum += z * (t[p].r - t[p].l + 1);
t[p].add += z;
return;
}
//如果不是全部属于目标区间,访问子代前先更新子代,清空自己的懒惰标记
lazy(p);
int mid = t[p].l + ((t[p].r - t[p].l) >> 1);
if (l <= mid)addupdate(l, r, 2 * p, z);//如果[t[p].l,mid]有一部分属于目标区间,更新[l,mid]
if (r > mid)addupdate(l, r, 2 * p + 1, z);//[mid+1,t[p].r]同理
t[p].sum = t[2 * p].sum + t[2 * p + 1].sum;//回来后重新更新t[p].sum(因为子代已经更新)
}
ll ask(int l, int r, int p)
{
if (l <= t[p].l && t[p].r <= r)return t[p].sum;//属于子集直接返回
lazy(p);//如果不是全部属于目标区间,访问子代前先更新子代,清空自己的懒惰标记
int mid = t[p].l + ((t[p].r - t[p].l) >> 1);
ll ans = 0;//ans累积属于目标区间的和
if (l <= mid)ans += ask(l, r, 2 * p);
if (r > mid)ans += ask(l, r, 2 * p + 1);
return ans;
}
int32_t main()
{
std::ios::sync_with_stdio(0), cin.tie(0), cout.tie(0);
int n, m;
cin >> n >> m;
for (int i = 1; i <= n; ++i)cin >> a[i];
build(1, n, 1);//每次都从根节点p=1建树
int b, l, r, k;
while (m--)
{
cin >> b >> l >> r;
if (b == 1)
{
cin >> k;
addupdate(l, r, 1, k);//更新,查询也都成根节点p=1开始
}
else if (b == 2)
{
cout << ask(l, r, 1) << endl;//更新,查询也都成根节点p=1开始
}
}
return 0;
}四,思考(如果区间修改同时存在加法和乘法怎么办)
1,我们清楚,乘法就是把当前的区间都*一个值(当然,这个区间是更新过的,因为每次都是更新完这个区间才进入)。
2,我们考虑使用乘法的影响,当我们对当前p的区间乘z时,t[p].sum*=z,那么更新他的懒惰标记
,以子代2*p为例子,他的子代目前是(t[2p]*t[p].mul+t[p].add*size(2p)),我们*z<-->t[2p]*z*t[p].mul*z+t[p].add*z,所以我们一次要更新t[p].mul,t[p].add。
3,我们考虑进入子代前对懒惰标记的处理,我们发现,t[p].add是可以不断用加法与乘法叠加的,而mul一直都是被乘没有加(在进入这一层之前都是这样)。所以我们更新这一层,首先一定要先乘mul在加add。这对t[2*p].sum与t[2*p].add都是一样的,都是先*t[p].mul再加t[p].add
直接上模板题:P3373 【模板】线段树 2
#include <bits/stdc++.h>
using namespace std;
#define ll long long
#define int ll
typedef unsigned long long ull;
typedef pair<long long, long long> pll;
typedef pair<int, int> pii;
//double 型memset最大127,最小128
//std::ios::sync_with_stdio(0), cin.tie(0), cout.tie(0);
const int INF = 0x3f3f3f3f; //int型的INF
const ll llINF = 0x3f3f3f3f3f3f3f3f;//ll型的llINF
const int N = 1e5 + 10;
int a[N];
int n, m, mod;
struct tree
{
int l, r;
ll sum, add, mul;
} t[4 * N + 2];
void build(int l, int r, int p)
{
t[p].l = l, t[p].r = r, t[p].mul = 1; //这里多更新了一个mul的初始值是1
if (l == r)
{
t[p].sum = a[l] % mod;
return;
}
int mid = l + ((r - l) >> 1);
build(l, mid, 2 * p);
build(mid + 1, r, 2 * p + 1);
t[p].sum = (t[2 * p].sum + t[2 * p + 1].sum) % mod;
}
void lazy(int p)
{
if (t[p].l == t[p].r)t[p].add = 0, t[p].mul = 1;
if (t[p].add || t[p].mul != 1)//只要加法或者乘法有一个存在懒惰标记就更新
{
t[2 * p].sum = (t[2 * p].sum * t[p].mul + t[p].add * (t[2 * p].r - t[2 * p].l + 1)) % mod;
t[2 * p + 1].sum = (t[2 * p + 1].sum * t[p].mul + t[p].add * (t[2 * p + 1].r - t[2 * p + 1].l + 1)) % mod;
//更新sum与add都是先乘后加
t[2 * p].add = (t[2 * p].add * t[p].mul + t[p].add) % mod;
t[2 * p + 1].add = (t[2 * p + 1].add * t[p].mul + t[p].add) % mod;
t[2 * p].mul = (t[2 * p].mul * t[p].mul) % mod;
t[2 * p + 1].mul = (t[2 * p + 1].mul * t[p].mul) % mod;
//重置标记
t[p].add = 0, t[p].mul = 1;
}
}
void addupdate(int l, int r, int p, ll z)
{
if (l <= t[p].l && t[p].r <= r)
{
t[p].sum = (t[p].sum + z * (t[p].r - t[p].l + 1)) % mod;
t[p].add = (t[p].add + z) % mod;
return;
}
lazy(p);
int mid = t[p].l + ((t[p].r - t[p].l) >> 1);
if (l <= mid)addupdate(l, r, 2 * p, z);//只有子代有在目标区间才进入
if (r > mid)addupdate(l, r, 2 * p + 1, z);
t[p].sum = (t[2 * p].sum + t[2 * p + 1].sum) % mod;
}
void mulupdate(int l, int r, int p, ll z)
{
if (l <= t[p].l && t[p].r <= r)
{
t[p].sum = (t[p].sum * z) % mod;//乘法需要对p的sum,add,mul都更新
t[p].add = (t[p].add * z) % mod;
t[p].mul = (t[p].mul * z) % mod;
return;
}
lazy(p);
int mid = t[p].l + ((t[p].r - t[p].l) >> 1);
if (l <= mid)mulupdate(l, r, 2 * p, z);//只有子代有在目标区间才进入
if (r > mid)mulupdate(l, r, 2 * p + 1, z);
t[p].sum = (t[2 * p].sum + t[2 * p + 1].sum) % mod;
}
ll ask(int l, int r, int p)
{
if (l <= t[p].l && t[p].r <= r)return t[p].sum % mod;
lazy(p);
int mid = t[p].l + ((t[p].r - t[p].l) >> 1);
ll ans = 0;
if (l <= mid)ans += ask(l, r, 2 * p);
if (r > mid)ans += ask(l, r, 2 * p + 1);
return ans % mod;
}
int32_t main()
{
cin >> n >> m >> mod;
for (int i = 1; i <= n; ++i)cin >> a[i];
build(1, n, 1);
int b, l, r, k;
while (m--)
{
cin >> b >> l >> r;
if (b == 1)
{
cin >> k;
mulupdate(l, r, 1, k);
}
else if (b == 2)
{
cin >> k;
addupdate(l, r, 1, k);
}
else if (b == 3)
{
cout << ask(l, r, 1) << endl;
}
}
return 0;
}