“大师级程序员把系统当故事来讲,而不是当做程序来写”
写代码犹如写文章

好的代码应该如好文章一样表达思想,被人读懂。
中心思想: 突出明确
程序是开发者用编程语言写成的一本书,首先应该是记录开发者对业务需求分析、系统分析,最终用软件实现所思所想的知识的记录与传承。然后再是完成程序放在服务器上运行。
目录:脉络清晰
书有目录,目录是书中知识的高度提炼和浓缩,具有极强的概括性,通过阅读目录能提纲挈领地了解全书的主旨和各部分内容,阅读目录可以从整体上把握全书的结构布局,清楚地了解全书各章节及章节与章节之间的逻辑关系,进而能体察作者写作该书的思想和行文脉络。
程序有架构设计,软件架构不仅显示了软件需求和软件结构之间的对应关系,而且指定了整个软件系统的组织和拓扑结构,提供了一些设计决策的基本原理。
一个项目的软件代码是项目业务逻辑的具体描述,是公司全体开发者共同智慧的结晶。应该如书一样结构清晰可以被人读懂,项目团队的老人写的代码能够被新人按照清晰的目录(系统架构)读懂是项目可维护的基础。一个项目源码随着业务变化、需求增加原有代码可维护、可扩展他就是好的源码。
这些都是常识性的东西,但实际项目中总会有项目在做这推翻原代码重写新版本的需求,也有新人看着老人写的类代码内心一万只羊驼路过,不知道这个类到底是完成什么工作,也不知道类中的某个方法到底是要返回什么结果,因为你发现那些不好的代码一个方法竟然会根据传入参数返回不同类型的值。这样的代码不是要告诉别人自己的想法,而是要别人猜自己的想法。
至于如何让别人读懂自己的代码其实具体到细节还是有许多需要注意的,毕竟编程语言不是自然语言,变量命名、注释、分层等等,各位新手朋友们具体在应用中体会吧。
作为一个开发者,项目进入编码环节之前,所制定的一切规则都可以叫做软件架构,代码分层、设计模式,每一个类的职责,对其的理解与应用是构成了代码实现的整体脉络。进入编码环节之后,合理的代码分层,即将不同的代码放到合适的层,类的单一职责原则像极了一篇文章的中心思想,方法的单一职责原则也像极了文章的段落,一个是文章中最基本的单位。内容上它具有一个相对完整的意思,在文章中用于体现作者的思路发展或全篇文章的层次。
其实写书是要难于写代码的,因为每本书的章节目录都不同,而软件架构设计是可以一样或者大体一样的,不同的只是具体业务需求实现的代码有差异,我们知道有些函数、类都是可以复用的,甚至我们可以肆无忌惮的参考别人的代码应用到自己的coding中,这本身就给写代码降低了难度,如果抛去如何使用框架、扩展包等等,我们编码所作的主要工作就只剩下具体业务逻辑的书写,而这部分coding如果细算实际上占整个项目的比例并不高,业务逻辑代码的编写在实际开发中占的比例并不高,软件架构设计的不合理,编码中不遵循架构既定的原则,都会导致大量的时间都耗费在了已写代码的维护与重构上了。
软件架构师可以通过出色的系统分析来构建可演进的软件架构,就像给一本书制定大纲,按照其内容设定章节目录,软件工程师则通过良好的设计和编程风格来完成任务。软件架构、设计原则本身都是为了更好的服务于代码的可维护、可扩展性,否则也不会牺牲代码运行效率而被广泛接受与运用。
优雅的代码风格:
代码简单:不隐藏设计者的意图,抽象干净利落,控制语句直截了当。
接口清晰:类型接口表现力直白,字面表达含义,API 相互呼应以增强可测试性。
依赖项少:依赖关系越少越好,依赖少证明内聚程度高,低耦合利于自动测试,便于重构。
没有重复:重复代码意味着某些概念或想法没有在代码中良好的体现,及时重构消除重复。
解耦分层:代码分层清晰,隔离明确,减少间接依赖,划清名空间,理清目录。
性能最优:局部代码性能调至最优,减少后期因性能问题修改代码的机会。
自动测试:测试与产品代码同等重要,自动测试覆盖 80% 的代码,剩余 20% 选择性测试。
https://baijiahao.baidu.com/s?id=1639149189737005850
如何才能写出整洁代码?
如何才能写出整洁代码呢?总的原则无非是KISS(Keep It Simple Stupid):让代码简单直接,让阅读者可以很容易地看出设计者的意图。<代码整洁之道> 这本书中给出了很多方法与规范,遵循这些规则可以帮你写出更加的整洁代码。
第一章 整洁代码
1,整洁代码力求集中,每个函数、每个类和每个模块都全神贯注于一件事。
2,整洁代码简单直接,从不隐藏设计者的意图。
3,整洁代码应当有单元测试和验收测试。它使用有意义的命名,代码通过其字面表达含义。
4,消除重复代码,提高代码表达力。
5,时时保持代码整洁。
第二章 有意义的命名
1,使用体现本意的命名能让人更容易理解和修改代码。
2,编程本来就是一种社会活动。
3,尽力写出易于理解的代码
第三章 函数
1,一个函数应该只做一件事(高内聚),无副作用。
2,自顶向下阅读代码,如同是在阅读报刊文章。
3,长而具有描述性的函数名称,好过描述性的长注释。
4,少用输出参数。
5,拒绝boolean型标识参数。
例:CopyUtil.copyToDB(isWorkDB) --> CopyUtil.copyToWorkDB(), CopyUtil.copyToLiveDB()
6,使用异常代替返回错误码,错误处理代码就能从主路径代码中分离出来得到简化。
7,写代码很像是写文章。先想怎么写就怎么写,然后再打磨:分解函数、修改名称、消除重复。
8,编程其实是一门语言设计艺术,大师级程序员把程序系统当做故事来讲。使用准确、清晰、富有表达力的代码来帮助你讲故事。
第四章 注释
1,别给糟糕的代码加注释----重写吧。
2,把力气花在写清楚明白的代码上,直接保证无需编写注释。
3,好的注释:
法律信息
提供信息
解释意图
警示
TODO注释
第五章 格式
1,代码格式很重要。代码格式关乎沟通,而沟通是专业开发者的头等大事。
2,向报纸格式学习代码编写。
第六章 对象和数据结构
1,对象把数据隐藏于抽象之后,只提供操作数据的函数。
数据结构暴露其数据,没有提供有意义的函数。
2,The Law of Demeter:模块不应去了解它所操作的对象内部细节。
第七章 错误处理
1, 使用异常而非返回错误码.
2, try-catch-finally, log出错信息.
3, 不要返回null,不要传递null。
NULL Object模式, 例:Collections.emptyList();
第十章 类
1,自顶向下原则:让程序读起来就像是一篇报纸文章。
2,method可以是protected,以便于单元测试。
3,SRP:类或模块应有且仅有一个加以修改的原因。类名应准确描述其职责。高内聚。
4,开放闭合原则OCP、依赖倒置原则DIP
5,变量名、方法名、类名都是给代码添加注释的一种手段。
第十二章 迭代前进
1, 紧耦合的代码难以编写单元测试。
2,单元测试消除了对清理代码会破坏代码的恐惧。
3,写出自己能理解的代码很容易,软件项目的主要成本在于长期维护。
4,代码应当清晰表达其作者的意图;测试代码可以通过实例起到文档作用。
第十四章 逐步改进
1,编程是一种技艺。要编写整洁代码,必须先容忍脏代码,然后清理!
2,写出好文章就是一个逐步改进的过程。
相关阅读:
《重构--改善既有代码的设计》
《代码大全》
《敏捷软件开发》
https://book.douban.com/review/5199308/
复杂业务设计与代码开发
凭借一句话获得图灵奖的Pascal之父——Nicklaus Wirth让他获得图灵奖的这句话就是他提出的著名公式:
“算法+数据结构=程序”
这个公式对计算机科学的影响程度足以类似物理学中爱因斯坦的“E=mc^2”——一个公式展示出了程序的本质。
首先分析数据结构,也就是通常意义上的表结构。最重要的是区分是不是同一种需求,如果不是,数据结构要尽量分开。数据结构打好一个很好的基础,上层的接口设计就会顺畅很多。
其次是定义内部接口,越复杂的功能,对于外界的接口定义往往越容易,而内部的接口设计往往最容易被忽略。做到以下几点,写起代码来就能更加得心应手。
第一,根据对外提供的接口list,列出自己的内部接口list。因为对外接口往往承载着模块的大部分功能,这样能做到简单而有依据。
第二,检查内部接口list,真正的做到接口方法功能单一。不要怕内部接口过多,如果实在过多,可以等到写完代码之后再去压缩,因为功能已经完成,所以压缩起来比刚开始设计起来要简单。
第三,对于接口参数和返回值的定义要简洁,不要过度利用一个“万能的参数”,多生成几个专用的VO。比如:内部接口参数返回值不用过度使用数据库VO。
最后是代码阶段。
减少引用的传递,避免方法层级过深。
不改变引用所指向对象里的值,否则使用的时候不知道之前被改变过而容易踩坑。
控制对象或者参数的使用“边界”,一个对象的范围往往仅在提供方和调用方使用,不要在除了这两个地方之外使用。
减少静态方法的使用,静态的往往代表着全局的意思。
内部数据和接口定义这一块是最容易给自己留“坑”的地方,只有内部的接口设计好了,自己对于业务的理解越深刻,业务变动的时候自己越主动。
作为一名开发人员,要养成分析需求的习惯,不要一有需求,就想着用懒省事的方法解决,如果没有真的理解需求,而用最少的代码凑合着解决了问题,后续维护起来就会有很大的麻烦。
https://blog.csdn.net/a811671856/article/details/51881041
如何书写易于维护的代码
1、流式布局,减少if else for,增加代码美观度,看起来代码是顺序的
2、数据预处理,入参就是函数能用的数据
3、函数行数控制,越短越好
4、函数职责单一,能拆分则拆分。ifsle for可以放到单一函数内部
5、函数名称简洁
阿里高级技术专家方法论:如何写复杂业务代码?
简介: 面对复杂的业务场景,如何在架构和代码层面进行应对,是一个课题。
业务背景
简单的介绍下业务背景,零售通是给线下小店供货的B2B模式,我们希望通过数字化重构传统供应链渠道,提升供应链效率,为新零售助力。阿里在中间是一个平台角色,提供的是Bsbc中的service的功能。

商品力是零售通的核心所在,一个商品在零售通的生命周期如下图所示:

在上图中红框标识的是一个运营操作的“上架”动作,这是非常关键的业务操作。上架之后,商品就能在零售通上面对小店进行销售了。因为上架操作非常关键,所以也是商品域中最复杂的业务之一,涉及很多的数据校验和关联操作。
针对上架,一个简化的业务流程如下所示:

过程分解
像这么复杂的业务,我想应该没有人会写在一个service方法中吧。一个类解决不了,那就分治吧。
说实话,能想到分而治之的工程师,已经做的不错了,至少比没有分治思维要好很多。我也见过复杂程度相当的业务,连分解都没有,就是一堆方法和类的堆砌。
不过,这里存在一个问题:即很多同学过度的依赖工具或是辅助手段来实现分解。比如在我们的商品域中,类似的分解手段至少有3套以上,有自制的流程引擎,有依赖于数据库配置的流程处理:

本质上来讲,这些辅助手段做的都是一个pipeline的处理流程,没有其它。因此,我建议此处最好保持KISS(Keep It Simple and Stupid),即最好是什么工具都不要用,次之是用一个极简的Pipeline模式,最差是使用像流程引擎这样的重方法。
除非你的应用有极强的流程可视化和编排的诉求,否则我非常不推荐使用流程引擎等工具。第一,它会引入额外的复杂度,特别是那些需要持久化状态的流程引擎;第二,它会割裂代码,导致阅读代码的不顺畅。大胆断言一下,全天下估计80%对流程引擎的使用都是得不偿失的。
回到商品上架的问题,这里问题核心是工具吗?是设计模式带来的代码灵活性吗?显然不是,问题的核心应该是如何分解问题和抽象问题,知道金字塔原理的应该知道,此处,我们可以使用结构化分解将问题解构成一个有层级的金字塔结构:
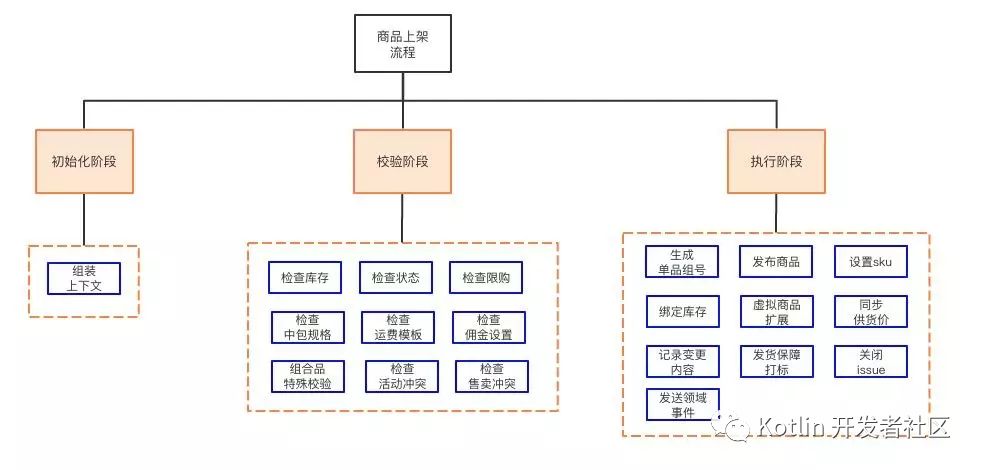
按照这种分解写的代码,就像一本书,目录和内容清晰明了。
以商品上架为例,程序的入口是一个上架命令(OnSaleCommand), 它由三个阶段(Phase)组成。
@Command
public class OnSaleNormalItemCmdExe {
@Resource
private OnSaleContextInitPhase onSaleContextInitPhase;
@Resource
private OnSaleDataCheckPhase onSaleDataCheckPhase;
@Resource
private OnSaleProcessPhase onSaleProcessPhase;
@Override
public Response execute(OnSaleNormalItemCmd cmd) {
OnSaleContext onSaleContext = init(cmd);
checkData(onSaleContext);
process(onSaleContext);
return Response.buildSuccess();
}
private OnSaleContext init(OnSaleNormalItemCmd cmd) {
return onSaleContextInitPhase.init(cmd);
}
private void checkData(OnSaleContext onSaleContext) {
onSaleDataCheckPhase.check(onSaleContext);
}
private void process(OnSaleContext onSaleContext) {
onSaleProcessPhase.process(onSaleContext);
}
}每个Phase又可以拆解成多个步骤(Step),以OnSaleProcessPhase为例,它是由一系列Step组成的:
@Phase
public class OnSaleProcessPhase {
@Resource
private PublishOfferStep publishOfferStep;
@Resource
private BackOfferBindStep backOfferBindStep;
//省略其它step
public void process(OnSaleContext onSaleContext){
SupplierItem supplierItem = onSaleContext.getSupplierItem();
// 生成OfferGroupNo
generateOfferGroupNo(supplierItem);
// 发布商品
publishOffer(supplierItem);
// 前后端库存绑定 backoffer域
bindBackOfferStock(supplierItem);
// 同步库存路由 backoffer域
syncStockRoute(supplierItem);
// 设置虚拟商品拓展字段
setVirtualProductExtension(supplierItem);
// 发货保障打标 offer域
markSendProtection(supplierItem);
// 记录变更内容ChangeDetail
recordChangeDetail(supplierItem);
// 同步供货价到BackOffer
syncSupplyPriceToBackOffer(supplierItem);
// 如果是组合商品打标,写扩展信息
setCombineProductExtension(supplierItem);
// 去售罄标
removeSellOutTag(offerId);
// 发送领域事件
fireDomainEvent(supplierItem);
// 关闭关联的待办事项
closeIssues(supplierItem);
}
}看到了吗,这就是商品上架这个复杂业务的业务流程。需要流程引擎吗?不需要,需要设计模式支撑吗?也不需要。对于这种业务流程的表达,简单朴素的组合方法模式(Composed Method)是再合适不过的了。
因此,在做过程分解的时候,我建议工程师不要把太多精力放在工具上,放在设计模式带来的灵活性上。而是应该多花时间在对问题分析,结构化分解,最后通过合理的抽象,形成合适的阶段(Phase)和步骤(Step)上。

过程分解后的两个问题
的确,使用过程分解之后的代码,已经比以前的代码更清晰、更容易维护了。不过,还有两个问题值得我们去关注一下:
领域知识被割裂肢解
什么叫被肢解?因为我们到目前为止做的都是过程化拆解,导致没有一个聚合领域知识的地方。每个Use Case的代码只关心自己的处理流程,知识没有沉淀。
相同的业务逻辑会在多个Use Case中被重复实现,导致代码重复度高,即使有复用,最多也就是抽取一个util,代码对业务语义的表达能力很弱,从而影响代码的可读性和可理解性。
代码的业务表达能力缺失
试想下,在过程式的代码中,所做的事情无外乎就是取数据--做计算--存数据,在这种情况下,要如何通过代码显性化的表达我们的业务呢?说实话,很难做到,因为我们缺失了模型,以及模型之间的关系。脱离模型的业务表达,是缺少韵律和灵魂的。
举个例子,在上架过程中,有一个校验是检查库存的,其中对于组合品(CombineBackOffer)其库存的处理会和普通品不一样。原来的代码是这么写的:
boolean isCombineProduct = supplierItem.getSign().isCombProductQuote();
// supplier.usc warehouse needn't check
if (WarehouseTypeEnum.isAliWarehouse(supplierItem.getWarehouseType())) {
// quote warehosue check
if (CollectionUtil.isEmpty(supplierItem.getWarehouseIdList()) && !isCombineProduct) {
throw ExceptionFactory.makeFault(ServiceExceptionCode.SYSTEM_ERROR, "亲,不能发布Offer,请联系仓配运营人员,建立品仓关系!");
}
// inventory amount check
Long sellableAmount = 0L;
if (!isCombineProduct) {
sellableAmount = normalBiz.acquireSellableAmount(supplierItem.getBackOfferId(), supplierItem.getWarehouseIdList());
} else {
//组套商品
OfferModel backOffer = backOfferQueryService.getBackOffer(supplierItem.getBackOfferId());
if (backOffer != null) {
sellableAmount = backOffer.getOffer().getTradeModel().getTradeCondition().getAmountOnSale();
}
}
if (sellableAmount < 1) {
throw ExceptionFactory.makeFault(ServiceExceptionCode.SYSTEM_ERROR, "亲,实仓库存必须大于0才能发布,请确认已补货.\r[id:" + supplierItem.getId() + "]");
}
}然而,如果我们在系统中引入领域模型之后,其代码会简化为如下:
return;
}
if (backOffer.isNonInWarehouse()){
throw new BizException("亲,不能发布Offer,请联系仓配运营人员,建立品仓关系!");
}
if (backOffer.getStockAmount() < 1){
throw new BizException("亲,实仓库存必须大于0才能发布,请确认已补货.\r[id:" + backOffer.getSupplierItem().getCspuCode() + "]");
}有没有发现,使用模型的表达要清晰易懂很多,而且也不需要做关于组合品的判断了,因为我们在系统中引入了更加贴近现实的对象模型(CombineBackOffer继承BackOffer),通过对象的多态可以消除我们代码中的大部分的if-else。

过程分解+对象模型
通过上面的案例,我们可以看到有过程分解要好于没有分解,过程分解+对象模型要好于仅仅是过程分解。对于商品上架这个case,如果采用过程分解+对象模型的方式,最终我们会得到一个如下的系统结构:
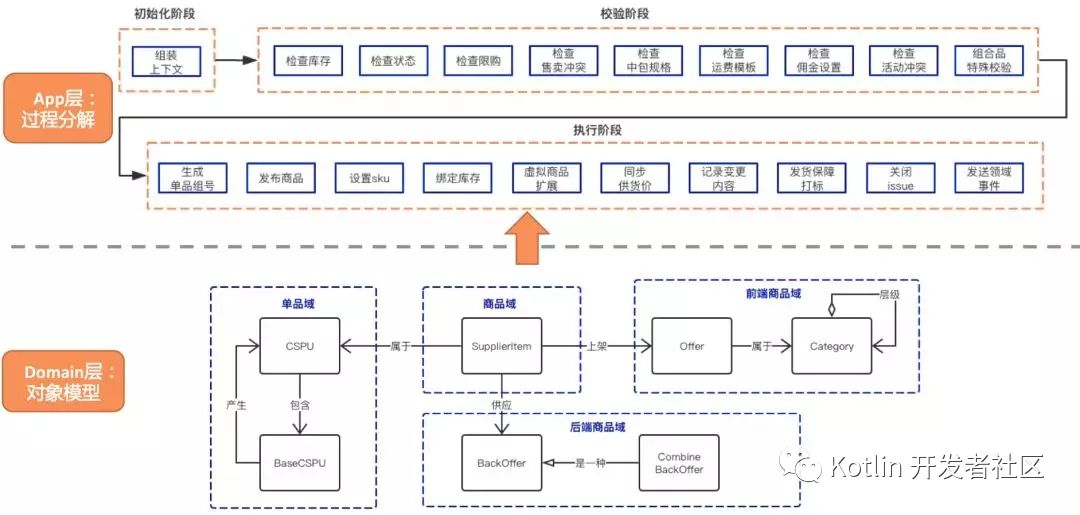
写复杂业务的方法论
通过上面案例的讲解,我想说,我已经交代了复杂业务代码要怎么写:即自上而下的结构化分解+自下而上的面向对象分析。
接下来,让我们把上面的案例进行进一步的提炼,形成一个可落地的方法论,从而可以泛化到更多的复杂业务场景。
上下结合
所谓上下结合,是指我们要结合自上而下的过程分解和自下而上的对象建模,螺旋式的构建我们的应用系统。这是一个动态的过程,两个步骤可以交替进行、也可以同时进行。
这两个步骤是相辅相成的,上面的分析可以帮助我们更好的理清模型之间的关系,而下面的模型表达可以提升我们代码的复用度和业务语义表达能力。
其过程如下图所示:
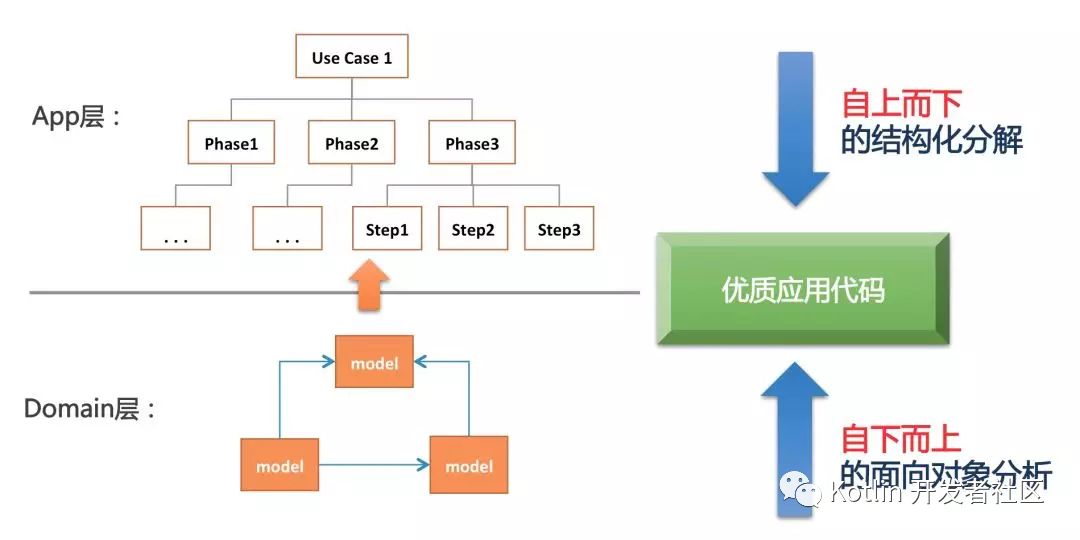
使用这种上下结合的方式,我们就有可能在面对任何复杂的业务场景,都能写出干净整洁、易维护的代码。
能力下沉
一般来说实践DDD有两个过程:
套概念阶段:了解了一些DDD的概念,然后在代码中“使用”Aggregation Root,Bounded Context,Repository等等这些概念。更进一步,也会使用一定的分层策略。然而这种做法一般对复杂度的治理并没有多大作用。
融会贯通阶段:术语已经不再重要,理解DDD的本质是统一语言、边界划分和面向对象分析的方法。
大体上而言,我大概是在1.7的阶段,因为有一个问题一直在困扰我,就是哪些能力应该放在Domain层,是不是按照传统的做法,将所有的业务都收拢到Domain上,这样做合理吗?说实话,这个问题我一直没有想清楚。
因为在现实业务中,很多的功能都是用例特有的(Use case specific)的,如果“盲目”的使用Domain收拢业务并不见得能带来多大的益处。相反,这种收拢会导致Domain层的膨胀过厚,不够纯粹,反而会影响复用性和表达能力。
鉴于此,我最近的思考是我们应该采用能力下沉的策略。
所谓的能力下沉,是指我们不强求一次就能设计出Domain的能力,也不需要强制要求把所有的业务功能都放到Domain层,而是采用实用主义的态度,即只对那些需要在多个场景中需要被复用的能力进行抽象下沉,而不需要复用的,就暂时放在App层的Use Case里就好了。
注:Use Case是《架构整洁之道》里面的术语,简单理解就是响应一个Request的处理过程。
通过实践,我发现这种循序渐进的能力下沉策略,应该是一种更符合实际、更敏捷的方法。因为我们承认模型不是一次性设计出来的,而是迭代演化出来的。
下沉的过程如下图所示,假设两个use case中,我们发现uc1的step3和uc2的step1有类似的功能,我们就可以考虑让其下沉到Domain层,从而增加代码的复用性。
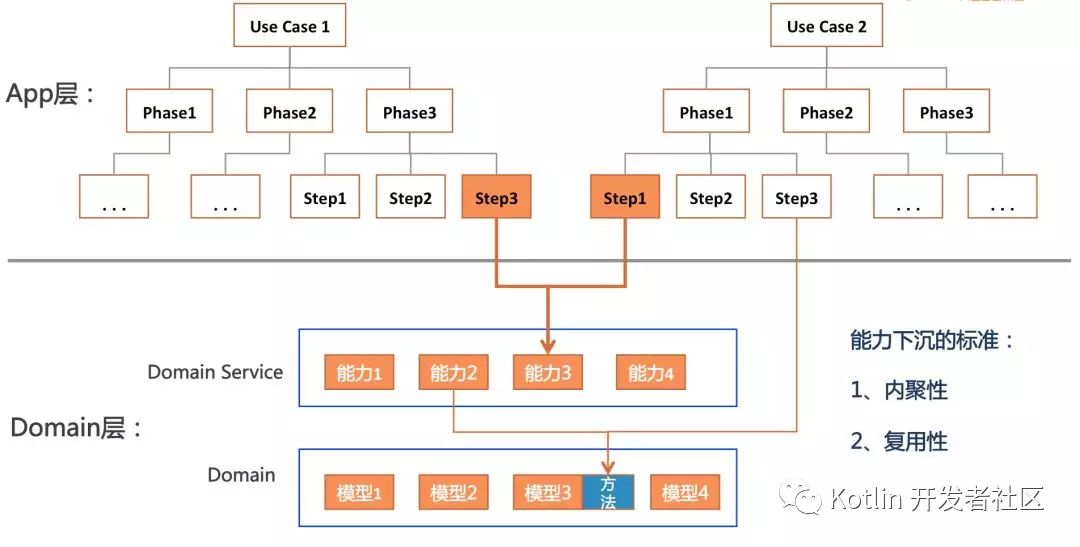
指导下沉有两个关键指标:
复用性
内聚性
复用性是告诉我们When(什么时候该下沉了),即有重复代码的时候。内聚性是告诉我们How(要下沉到哪里),功能有没有内聚到恰当的实体上,有没有放到合适的层次上(因为Domain层的能力也是有两个层次的,一个是Domain Service这是相对比较粗的粒度,另一个是Domain的Model这个是最细粒度的复用)。
比如,在我们的商品域,经常需要判断一个商品是不是最小单位,是不是中包商品。像这种能力就非常有必要直接挂载在Model上。
public class CSPU {
private String code;
private String baseCode;
//省略其它属性
/**
* 单品是否为最小单位。
*
*/
public boolean isMinimumUnit(){
return StringUtils.equals(code, baseCode);
}
/**
* 针对中包的特殊处理
*
*/
public boolean isMidPackage(){
return StringUtils.equals(code, midPackageCode);
}
}之前,因为老系统中没有领域模型,没有CSPU这个实体。你会发现像判断单品是否为最小单位的逻辑是以StringUtils.equals(code, baseCode)的形式散落在代码的各个角落。这种代码的可理解性是可想而知的,至少我在第一眼看到这个代码的时候,是完全不知道什么意思。
业务技术要怎么做
写到这里,我想顺便回答一下很多业务技术同学的困惑,也是我之前的困惑:即业务技术到底是在做业务,还是做技术?业务技术的技术性体现在哪里?
通过上面的案例,我们可以看到业务所面临的复杂性并不亚于底层技术,要想写好业务代码也不是一件容易的事情。业务技术和底层技术人员唯一的区别是他们所面临的问题域不一样。
业务技术面对的问题域变化更多、面对的人更加庞杂。而底层技术面对的问题域更加稳定、但对技术的要求更加深。比如,如果你需要去开发Pandora,你就要对Classloader有更加深入的了解才行。
但是,不管是业务技术还是底层技术人员,有一些思维和能力都是共通的。比如,分解问题的能力,抽象思维,结构化思维等等。
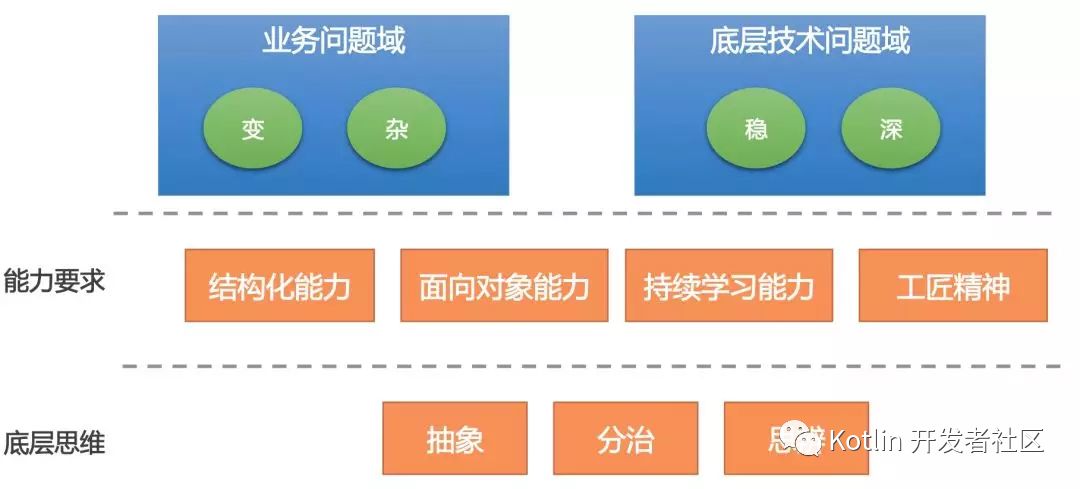
用我的话说就是:“做不好业务开发的,也做不好技术底层开发,反之亦然。业务开发一点都不简单,只是我们很多人把它做“简单”了。
因此,如果从变化的角度来看,业务技术的难度一点不逊色于底层技术,其面临的挑战甚至更大。因此,我想对广大的从事业务技术开发的同学说:沉下心来,夯实自己的基础技术能力、OO能力、建模能力... 不断提升抽象思维、结构化思维、思辨思维... 持续学习精进,写好代码。我们可以在业务技术岗做的很”技术“!。
后记
这篇文章是我最近思考的一些总结,大部分思想是继承自我原来写的COLA架构,该架构已经开源,目前在集团内外都有比较广泛的使用。
这一篇主要是在COLA的基础上,针对复杂业务场景,做了进一步的架构落地。个人感觉可以作为COLA的最佳实践来使用。
另外,本文讨论的问题之大和篇幅之短是不成正比的。原因是我假定你已经了解了一些DDD和应用架构的基础知识。如果觉得在理解上有困难,我建议可以先看下《领域驱动设计》和《架构整洁之道》这两本书。
如果没有那么多时间,也可以快速浏览下我之前的两篇文章应用架构之道 和 领域建模去知晓一下我之前的思想脉络。
【更多阅读】
【企业架构设计实战】0 企业数字化转型和升级:架构设计方法与实践
【企业架构设计实战】1 企业架构方法论
【企业架构设计实战】2 业务架构设计
【企业架构设计实战】3 怎样进行系统逻辑架构?
【企业架构设计实战】4 应用架构设计
【企业架构设计实战】5 大数据架构设计
【企业架构设计实战】6 数据架构
企业数字化转型和升级:架构设计方法与实践
【成为架构师课程系列】怎样进行系统逻辑架构?
【成为架构师课程系列】怎样进行系统详细架构设计?
【企业架构设计实战】企业架构方法论
【企业架构设计实战】业务架构设计
【企业架构设计实战】应用架构设计
【企业架构设计实战】大数据架构设计
【软件架构思想系列】分层架构
【软件架构思想系列】模块化与抽象
软件架构设计的核心:抽象与模型、“战略编程”
企业级大数据架构设计最佳实践
编程语言:类型系统的本质
程序员架构修炼之道:软件架构设计的37个一般性原则
程序员架构修炼之道:如何设计“易理解”的系统架构?
“封号斗罗” 程序员修炼之道:通向务实的最高境界
程序员架构修炼之道:架构设计中的人文主义哲学
Gartner 2023 年顶级战略技术趋势
【软件架构思想系列】从伟人《矛盾论》中悟到的软件架构思想真谛:“对象”即事物,“函数”即运动变化
【模型↔关系思考法】如何在一个全新的、陌生的领域快速成为专家?模仿 + 一万小时定律 + 创新
Redis 作者 Antirez 讲如何实现分布式锁?Redis 实现分布式锁天然的缺陷分析&Redis分布式锁的正确使用姿势!
红黑树、B树、B+树各自适用的场景
你真的懂树吗?二叉树、AVL平衡二叉树、伸展树、B-树和B+树原理和实现代码详解
【动态图文详解-史上最易懂的红黑树讲解】手写红黑树(Red Black Tree)
我的年度用户体验趋势报告——由 ChatGPT AI 撰写
我面试了 ChatGPT 的 PM (产品经理)岗位,它几乎得到了这份工作!!!
大数据存储引擎 NoSQL极简教程 An Introduction to Big Data: NoSQL
《人月神话》(The Mythical Man-Month)看清问题的本质:如果我们想解决问题,就必须试图先去理解它
【架构师必知必会】常见的NoSQL数据库种类以及使用场景
新时期我国信息技术产业的发展【技术论文,纪念长者,2008】
B-树(B-Tree)与二叉搜索树(BST):讲讲数据库和文件系统背后的原理(读写比较大块数据的存储系统数据结构与算法原理)
HBase 架构详解及数据读写流程
【架构师必知必会系列】系统架构设计需要知道的5大精要(5 System Design fundamentals)
《人月神话》8 胸有成竹(Chaptor 8.Calling the Shot -The Mythical Man-Month)
《人月神话》7(The Mythical Man-Month)为什么巴比伦塔会失败?
《人月神话》(The Mythical Man-Month)6贯彻执行(Passing the Word)
《人月神话》(The Mythical Man-Month)5画蛇添足(The Second-System Effect)
《人月神话》(The Mythical Man-Month)4概念一致性:专制、民主和系统设计(System Design)
《人月神话》(The Mythical Man-Month)3 外科手术队伍(The Surgical Team)
《人月神话》(The Mythical Man-Month)2人和月可以互换吗?人月神话存在吗?
在平时的工作中如何体现你的技术深度?
Redis 作者 Antirez 讲如何实现分布式锁?Redis 实现分布式锁天然的缺陷分析&Redis分布式锁的正确使用姿势!
程序员职业生涯系列:关于技术能力的思考与总结
十年技术进阶路:让我明白了三件要事。关于如何做好技术 Team Leader?如何提升管理业务技术水平?(10000字长文)
当你工作几年就会明白,以下几个任何一个都可以超过90%程序员
编程语言:类型系统的本质
软件架构设计的核心:抽象与模型、“战略编程”
【图文详解】深入理解 Hbase 架构 Deep Into HBase Architecture
HBase 架构详解及读写流程原理剖析
HDFS 底层交互原理,看这篇就够了!
MySQL 体系架构简介
一文看懂MySQL的异步复制、全同步复制与半同步复制
【史上最全】MySQL各种锁详解:一文搞懂MySQL的各种锁
腾讯/阿里/字节/快手/美团/百度/京东/网易互联网大厂面试题库
Redis 面试题 50 问,史上最全。
一道有难度的经典大厂面试题:如何快速判断某 URL 是否在 20 亿的网址 URL 集合中?
【BAT 面试题宝库附详尽答案解析】图解分布式一致性协议 Paxos 算法
Java并发多线程高频面试题
编程实践系列: 字节跳动面试题
腾讯/阿里/字节/快手/美团/百度/京东/网易互联网大厂面试题库
[精华集锦] 20+ 互联网大厂Java面试题全面整理总结
【BAT 面试题宝库附详尽答案解析】分布式事务实现原理
……









![[SSD科普之1] PCIE接口详解及应用模式](https://img-blog.csdnimg.cn/img_convert/7316898ce6464d7ca1811808269a4b0d.png)