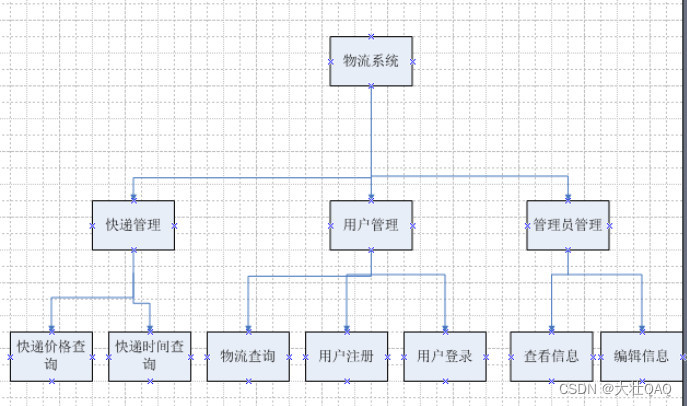
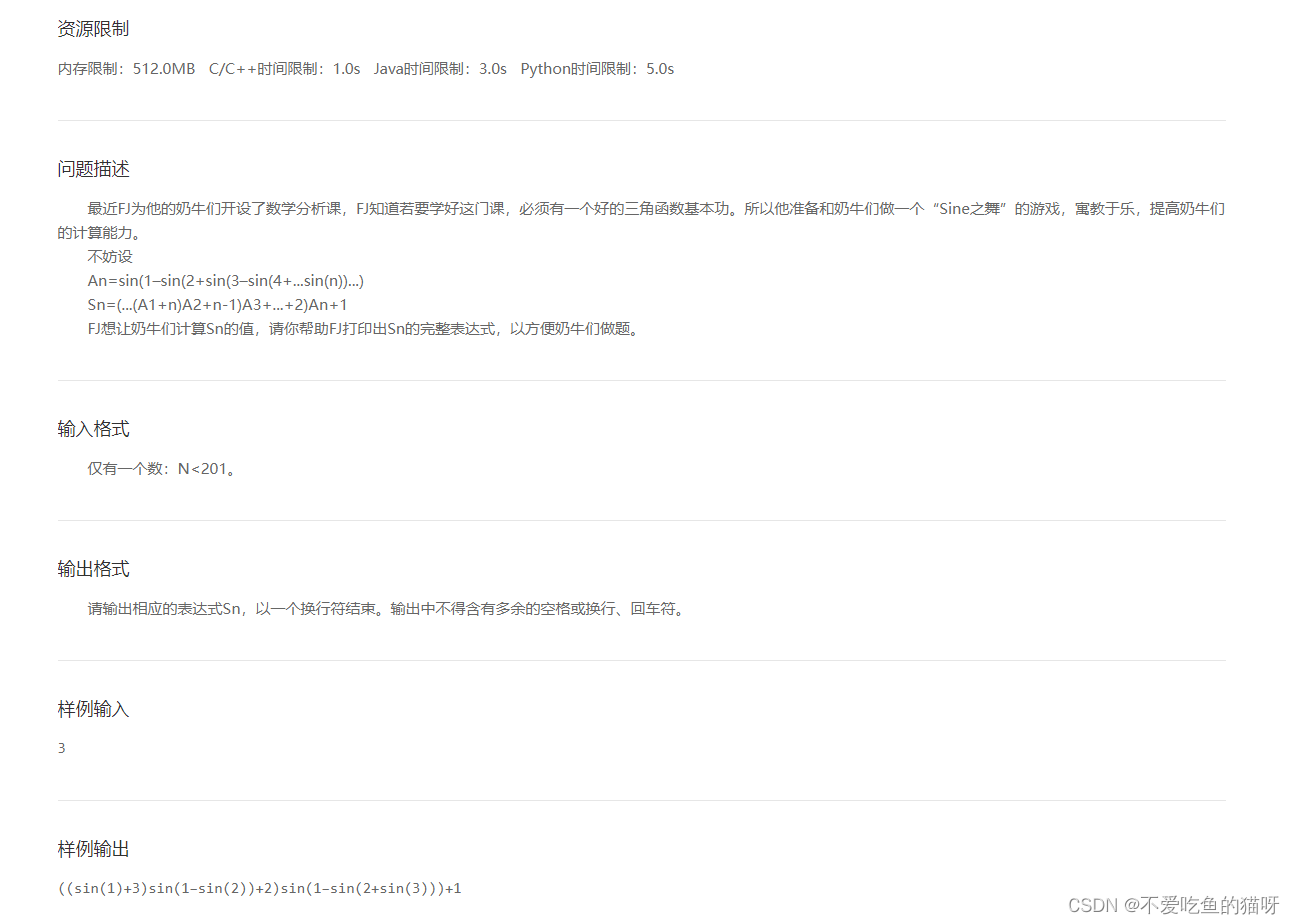
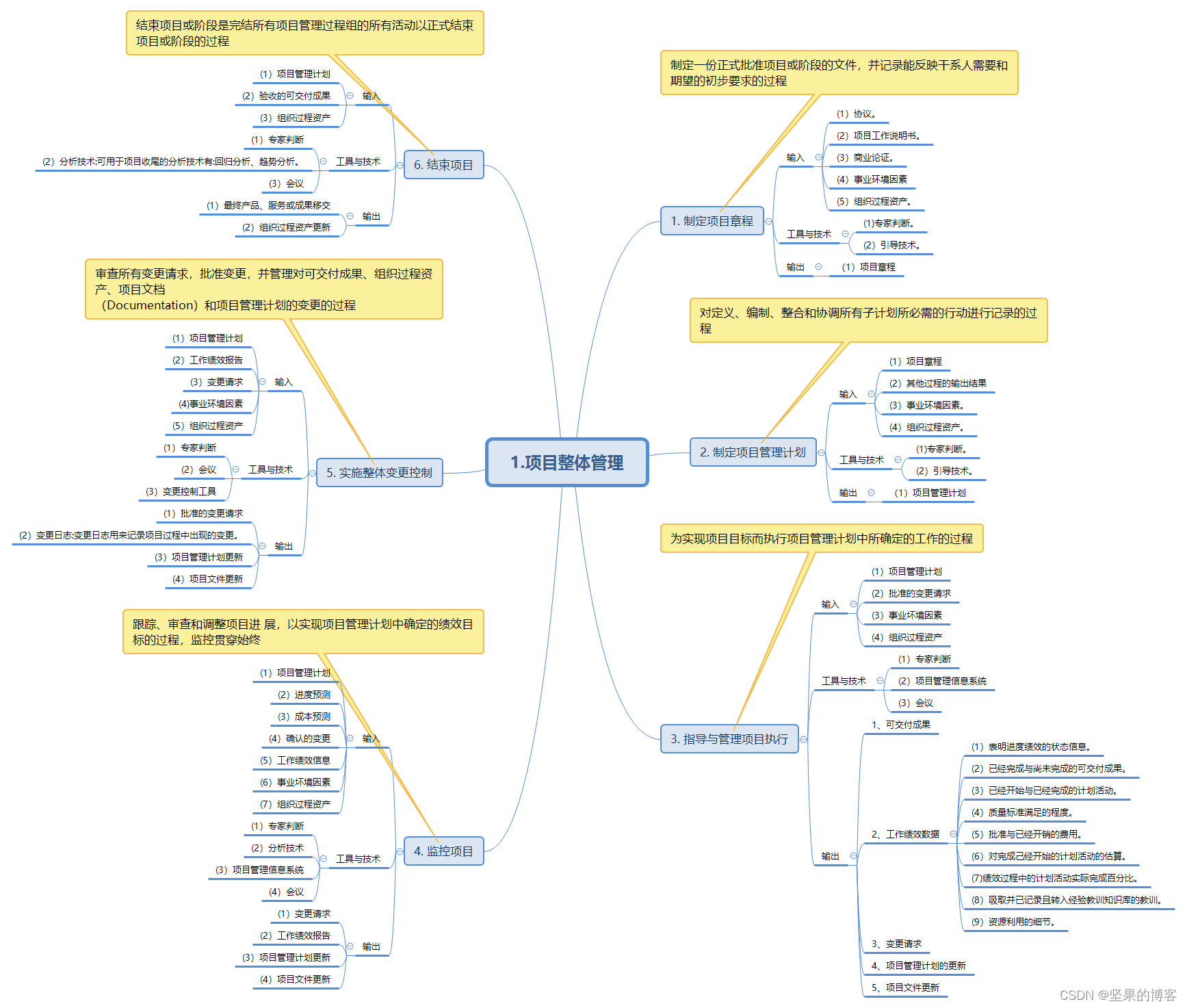
1、海量文本常见
海量文本场景,如何寻找一个doc的topn相似doc,一般存在2个问题,
1)、两两对比时间o(n^2)
2)、高维向量比较比较耗时。
文本集可以看成(doc,word)稀疏矩阵,一般常见的方法是构建到排索引,然后进行归并。
2、常见海量文本处理方法
2.1、minhash
1、构建词和文本的稀疏矩阵,随机重排关键词,计算集合S最小的minhash值,就是在这种顺序下最先出现1的元素。随机重排n次,就能得到某个doc的n维minhash值,将高维的文本空间降到了n维。
实际中,重排比较耗时,会用n个随机hash函数替代。每个集合S就被降维到n维空间的签名,解决了高维向量比较的问题。
2.2、LSH(Locality-Sensitive Hashing)局部敏感hash算法
minhash解决了高维空间向量比较的问题,doc之间两两对比的问题还没解决。
在minhashing 签名的基础上做LSH
- 一个高维向量通过minhashing处理后变成n维低维向量的签名,现在把这n维签名分成b组,每组r个元素。
- 每组通过一个哈希函数,把这组的r个元素组成r维向量哈希到一个桶中。
- 每组可以使用同一个哈希函数,但是每组桶没交集,即使哈希值一样。桶名可以类似:组名+哈希值。
- 在一个桶中的向量才进行相似度计算,相似度计算的向量是minhash的n维向量(不是r维向量)
如果d(x,y) ≤ d1, 则h(x) = h(y)的概率 ≥ p1【距离近的,在同一个桶概率大】; 2)如果d(x,y) ≥ d2, 则h(x) = h(y)的概率 ≤ p2【距离远的,在同一个桶概率小】;
其中d(x,y)表示x和y之间的距离,d1 < d2, h(x)和h(y)分别表示对x和y进行hash变换。
满足以上两个条件的hash functions称为(d1,d2,p1,p2)-sensitive。而通过一个或多个(d1,d2,p1,p2)-sensitive的hash function对原始数据集合进行hashing生成一个或多个hash table的过程称为Locality-sensitive Hashing
2.3、simhash
simhash是解决海量文本去重提出来的。google通过simhash将一篇文本映射为64bits的二进制串。
2.3.1、simhash具体过程
- 文档每个词有个权重。(一般是idf(逆文档数))
- 文档每个词哈希成一个二进制串。
- 文档最终的签名是各个词和签名的加权和(如果该位是1则+weight,如果是0,则-weight),再求签名[>0则变成1,反之变成0]得到一个64位二进制数。
- 如果两篇文档相同,则他们simhash签名汉明距离小于等于3。
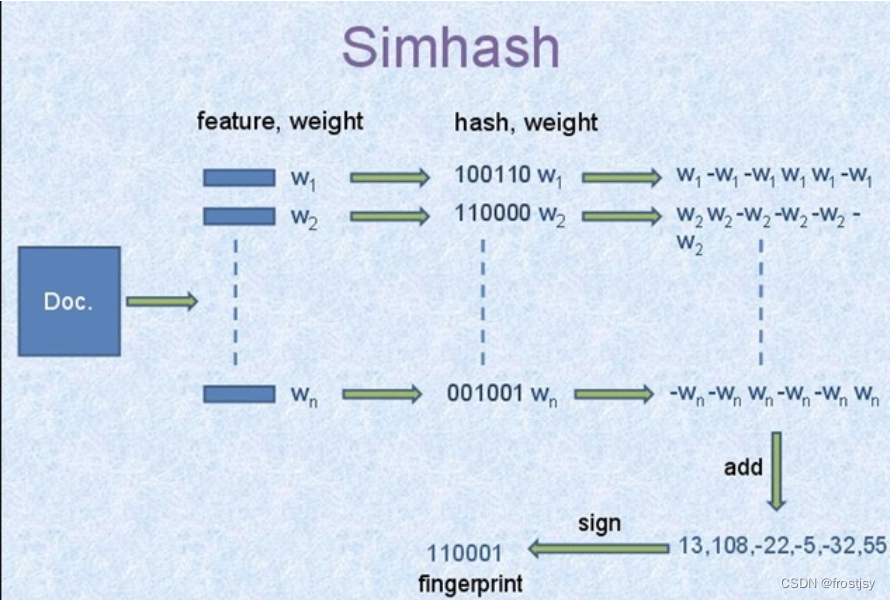
2.3.2、simhash海明距离3以内的构建索引过程
抽屉原理海明距离为3以内的,将hash码分为4份,必有一份完全相同。
- 将64位的二进制串等分成四块
- 调整上述64位二进制,将任意一块作为前16位,总共有四种组合,生成四份table
- 采用精确匹配的方式查找前16位
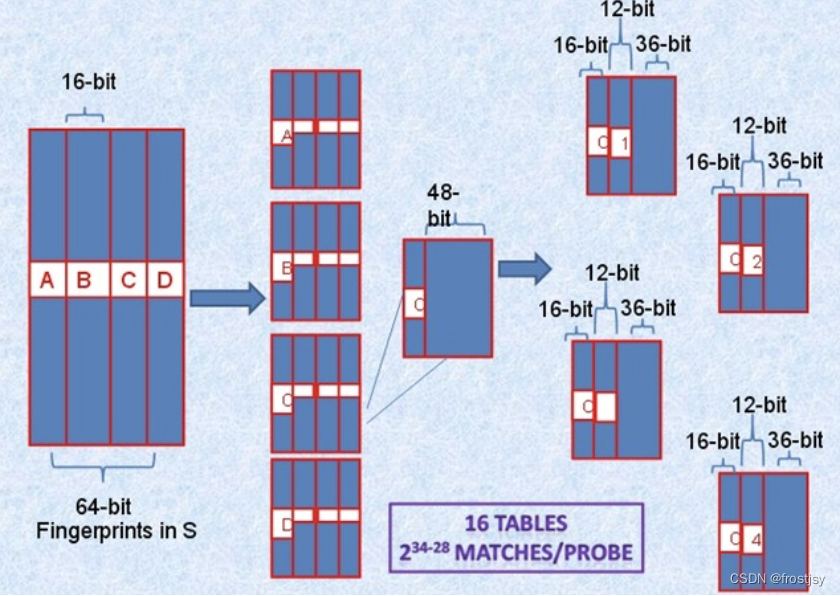
- 如果样本库中存有2^34(差不多10亿)的哈希指纹,则每个table返回2^(34-16)=262144个候选结果(一次分组)
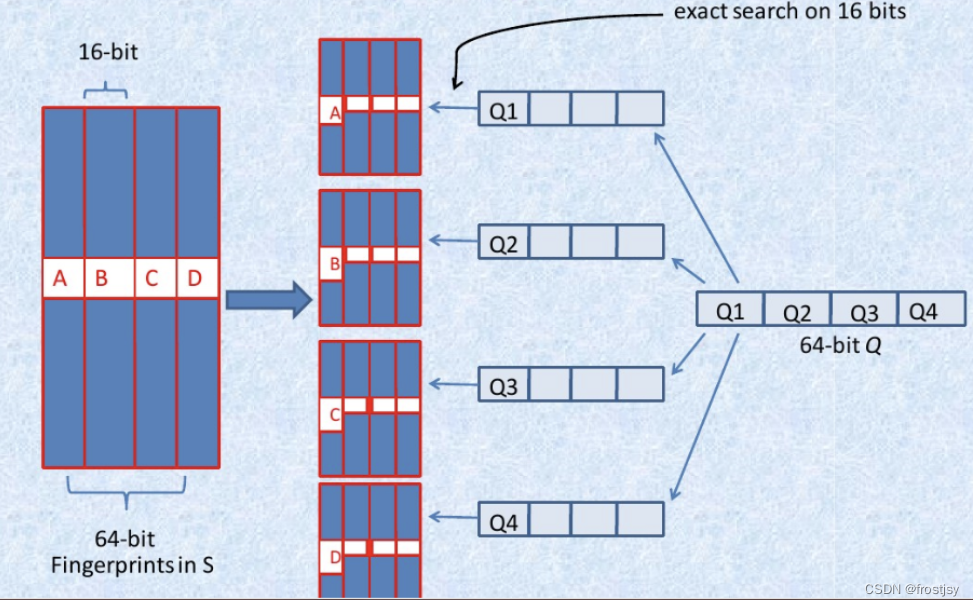
二次分组,将64-bit按照16位划分为4个区间,每个区间剩余的48-bit再按照每个12-bit划分为4个区间,因此总共16个table并行查找,即使三个不同的k-bit落在A、B、C、D中三个不同的区块,此划分方法也不会导致遗漏。
而真正需要比较的是前16+12=28位,所以,如果有2^34个指纹,那么候选将变为2^(34-28)个结果。
2.4、Annoy (稠密向量相似性查找)
Annoy 通过建立一个二叉树来使得每个点查找时间复杂度是O(log n)
2.4.1、建树过程
- 随机选择两个点,以这两个节点为初始中心节点,执行聚类数为2的kmeans过程,最终产生收敛后两个聚类中心点。
- 这两个聚类中心点之间连一条线段(灰色短线),建立一条垂直于这条灰线,并且通过灰线中心点的线(黑色粗线)。这条黑色粗线把数据空间分成两部分。在多维空间的话,这条黑色粗线可以看成等距垂直超平面。
- 在划分的子空间内进行不停的递归迭代继续划分,知道每个子空间最多只剩下K个数据节点。
- 通过多次递归迭代划分的话,最终原始数据会形成类似下面这样一个二叉树结构。二叉树底层是叶子节点记录原始数据节点,其他中间节点记录的是分割超平面的信息。Annoy建立这样的二叉树结构是希望满足这样的一个假设: 相似的数据节点应该在二叉树上位置更接近,一个分割超平面不应该把相似的数据节点分割二叉树的不同分支上。
2.4.2、查询过程
查找的过程就是不断看他在分割超平面的哪一边。从二叉树索引结构来看,就是从根节点不停的往叶子节点遍历的过程。通过对二叉树每个中间节点(分割超平面相关信息)和查询数据节点进行相关计算来确定二叉树遍历过程是往这个中间节点左孩子节点走还是右孩子节点走。通过以上方式完成查询过程。
2.4.3、查询中的问题与解决方法
- 问题1:查询过程最终落到叶子节点的数据节点数小于 我们需要的Top N相似邻居节点数目怎么办?
- 问题2:两个相近的数据节点划分到二叉树不同分支上怎么办?
解决方法:
- 如果分割超平面的两边都很相似,那可以两边都遍历。
- 建立多棵二叉树树,构成一个森林,每个树建立机制都如上面所述那样。
- 采用优先队列机制:采用一个优先队列来遍历二叉树,从根节点往下的路径,根据查询节点与当前分割超平面距离(margin)进行排序。
2.4.4、返回最终近邻节点
每棵树都返回一堆近邻点后,如何得到最终的Top N相似集合呢? 首先所有树返回近邻点都插入到优先队列中,求并集去重, 然后计算和查询点距离,最终根据距离值从近距离到远距离排序,返回Top N近邻节点集合。
2.5、KDTree
kd 树是一种对k维特征空间中的实例点进行存储以便对其快速检索的树形数据结构。
kd树是二叉树,核心思想是对 k 维特征空间不断切分(假设特征维度是768,对于(0,1,2,...,767)中的每一个维度,以中值递归切分)构造的树,每一个节点是一个超矩形,小于结点的样本划分到左子树,大于结点的样本划分到右子树。
树构造完毕后,最终检索时(1)从根结点出发,递归地向下访问kd树。若目标点 x 当前维的坐标小于切分点的坐标,移动到左子树,否则移动到右子树,直至到达叶结点;(2)以此叶结点为“最近点”,递归地向上回退,查找该结点的兄弟结点中是否存在更近的点,若存在则更新“最近点”,否则回退;未到达根结点时继续执行(2);(3)回退到根结点时,搜索结束。
kd树在维数小于20时效率最高,一般适用于训练实例数远大于空间维数时的k近邻搜索;当空间维数接近训练实例数时,它的效率会迅速下降,几乎接近线形扫描。
2.5、HNSW
和前几种算法不同,HNSW(Hierarchcal Navigable Small World graphs)是基于图存储的数据结构。
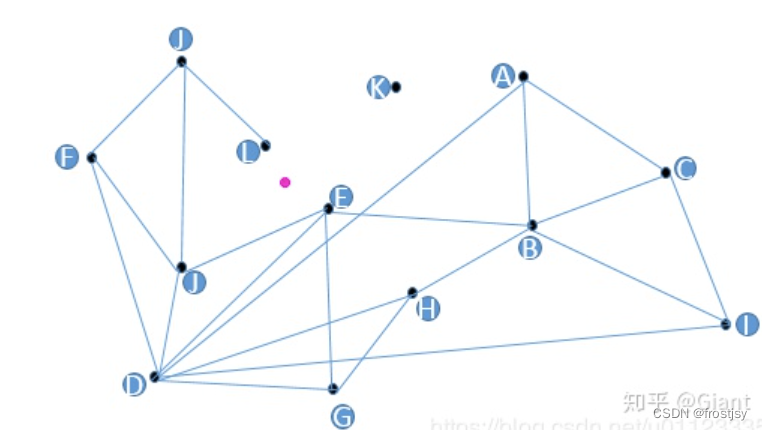
假设我们现在有13个2维数据向量,我们把这些向量放在了一个平面直角坐标系内,隐去坐标系刻度,它们的位置关系如上图所示。
朴素查找法:不少人脑子里都冒出过这样的朴素想法,把某些点和点之间连上线,构成一个查找图,存储备用;当我想查找与粉色点最近的一点时,我从任意一个黑色点出发,计算它和粉色点的距离,与这个任意黑色点有连接关系的点我们称之为“友点”(直译),然后我要计算这个黑色点的所有“友点”与粉色点的距离,从所有“友点”中选出与粉色点最近的一个点,把这个点作为下一个进入点,继续按照上面的步骤查找下去。如果当前黑色点对粉色点的距离比所有“友点”都近,终止查找,这个黑色点就是我们要找的离粉色点最近的点。
HNSW算法就是对上述朴素思想的改进和优化。为了达到快速搜索的目标,hnsw算法在构建图时还至少要满足如下要求:1)图中每个点都有“友点”;2)相近的点都互为“友点”;3)图中所有连线的数量最少;4)配有高速公路机制的构图法。
2.6、faiss
Faiss全称(Facebook AI Similarity Search)是Facebook AI团队开源的针对聚类和相似性搜索库,为稠密向量提供高效相似度搜索和聚类,支持十亿级别向量的搜索,是目前较成熟的近似近邻搜索库。
Faiss核心原理就两个,倒排索引 IVF和乘积量化 PQ,这两个方法是Faiss实现高速,少内存以及精确检索的主要手段。
2.6.1、倒排索引IVF(Inverted File System)
暴力搜索的方式是在全空间进行搜索,为了加快查找速度,几乎所有的ANN方法都是通过对全空间进行分割(聚类),将其分割成很多小的子空间,在搜索时,通过某种方式快速锁定在某一(几)个子空间,然后在这几个子空间中进行遍历。IVF先对全空间聚类为k个子空间,先确定子空间,然后进行检索。
2.6.2、乘积量化 PQ
为解决ivf先聚类,每类聚类簇不等,会导致检索时间不稳定的问题,乘积量化被提出。PQ分两个步骤,先聚类,后量化。
聚类
以128维的向量检索为例,乘积量化先将128维拆分为4段,每段32维,然后每段分别聚成256个聚类簇。
量化
拆分为4段的128维向量由每类的中心点编码,一个向量就可以由4段聚类中心表示了,大大减少了存储空间。
3、参考文献
【1】海量数据相似数据查找方法 - daiwk-github博客
【2】HNSW算法(nsmlib/hnswlib)_FSak47的博客-CSDN博客_hnswlib
【3】https://www.cnblogs.com/charlesblc/p/15932792.html
【4】海量数据相似查找系列1 -- Minhashing & LSH & Simhash 技术汇总_范涛的博客-CSDN博客_manku g s,jaina,sarma a d. detecting near-duplicat
【5】K近邻算法哪家强?KDTree、Annoy、HNSW原理和使用方法介绍 - 知乎
【6】 相似向量检索库-Faiss-简介及原理_金色麦田~的博客-CSDN博客_faiss
【7】算法工程-Faiss原理和使用总结_VangSwng的博客-CSDN博客_faiss






![[oeasy]python0086_ASCII_出现背景_1963年_DEC_PDP系列主机_VT系列终端](https://img-blog.csdnimg.cn/img_convert/2bbd6bb51ae22ffed1c0350629a8ada0.jpeg)