文章目录
- 一、概述
- 二、设计模式七种原则
- 三、设计模式示例讲解
- 1)创建型模式
- 1、工厂模式(Factory Method)
- 【1】简单工厂模式(不属于GOF设计模式之一)
- 【2】工厂方法模式
- 2、抽象工厂模式(AbstractFactory)
- 3、单例模式(Singleton)
- 4、建造者模式(Builder)
- 5、原型模式(Prototype)
- 2)结构型模式
- 1、适配器模式(Adapter)
- 2、桥接模式(Bridge)
- 3、组合模式(Composite)
- 4、装饰模式(Decorator)
- 5、外观模式(Facade)
- 6、享元模式(Flyweight)
- 7、代理模式(Proxy)
- 3)行为型模式
- 1、职任链模式(Chain of Responsibility)
- 2、命令模式(Command)
- 3、解释器模式(Interpreter)
- 4、迭代器模式(Iterator)
- 5、中介者模式(Mediator)
- 6、备忘录模式(Memento)
- 7、观察者模式(Observer)
- 8、状态模式(State)
- 9、策略模式(Strategy)
- 10、模板方法模式(TemplateMethod)
- 11、访问者模式(Visitor)
一、概述
设计模式(Design Pattern)是一套被广泛接受的、可重复使用的软件设计解决方案。它们是在软件开发过程中对常见问题的反复实践和总结得出的经验和思想的表现。
1995 年,GoF(Gang of Four,四人组/四人帮)合作出版了《设计模式:可复用面向对象软件的基础》一书,共收录了 23 种设计模式,从此树立了软件设计模式领域的里程碑,人称「GoF设计模式」。
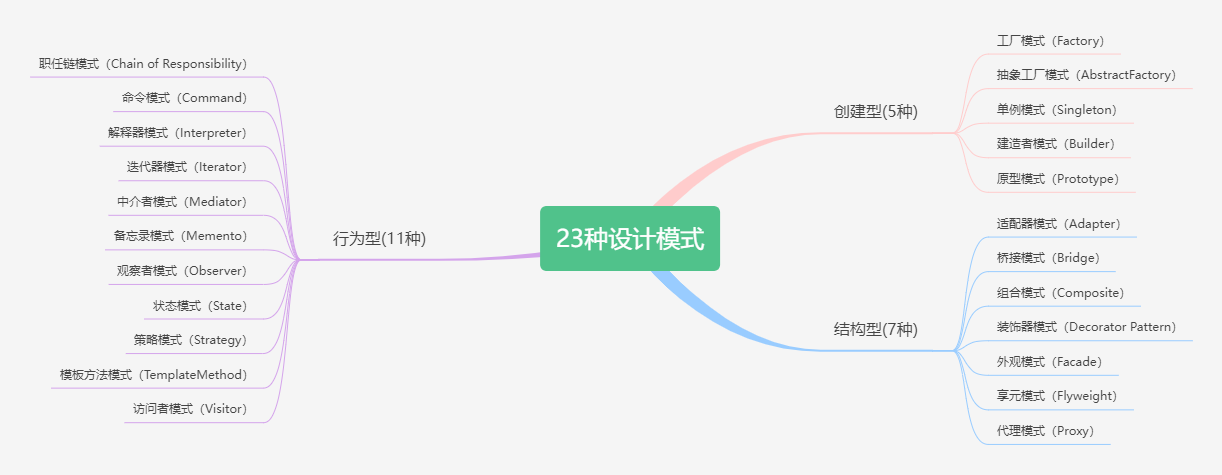
设计模式是一种解决特定问题的经过测试和验证的通用解决方案,它们被广泛应用于软件工程和计算机科学中。下面列出了常见的23种设计模式:
-
工厂模式(Factory Pattern):定义一个创建对象的接口,让子类决定实例化哪一个类。工厂方法使一个类的实例化延迟到其子类。
-
抽象工厂模式(Abstract Factory Pattern):提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们的具体类。
-
单例模式(Singleton Pattern):确保一个类只有一个实例,并提供对该实例的全局访问点。
-
建造者模式(Builder Pattern):将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
-
原型模式(Prototype Pattern):通过复制现有的实例来创建新的对象,而不是使用构造函数。
-
适配器模式(Adapter Pattern):将一个类的接口转换成客户希望的另一个接口。适配器模式可以让原本由于接口不兼容而不能在一起工作的类可以一起工作。
-
桥接模式(Bridge Pattern):将抽象部分与它的实现部分分离,使它们都可以独立地变化。
-
组合模式(Composite Pattern):将对象组合成树形结构以表示部分-整体的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性。
-
装饰器模式(Decorator Pattern):动态地将责任附加到对象上。装饰器模式提供了一种灵活的替代继承的方式。
-
外观模式(Facade Pattern):为子系统中的一组接口提供一个一致的界面,使得子系统更容易使用。
-
享元模式(Flyweight Pattern):运用共享技术来有效地支持大量细粒度对象的复用。
-
代理模式(Proxy Pattern):为其他对象提供一种代理以控制对这个对象的访问。代理对象可以在被代理对象执行操作前后进行一些预处理和后处理。
-
责任链模式(Chain of Responsibility Pattern):为解除请求的发送者和接收者之间耦合,而使多个对象都有机会处理这个请求。
-
命令模式(Command Pattern):将请求封装成一个对象,从而使你可以用不同的请求对客户进行参数化。命令模式也支持撤销操作。
-
解释器模式(Interpreter Pattern):是一种行为型设计模式,它提供了一种方法,可以在运行时解释语言文法中的表达式,并执行相应的操作。
-
迭代器模式(Iterator Pattern):提供一种方法顺序访问一个聚合对象中的各个元素,而又不暴露该对象的内部表示。
-
中介者模式(Mediator Pattern):用一个中介对象来封装一系列的对象交互。中介者使各个对象不需要显式地相互作用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
-
备忘录模式(Memento Pattern):在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。备忘录模式可以在需要时将对象恢复到先前的状态。
-
观察者模式(Observer Pattern):定义对象间的一种一对多的依赖关系,使得每当一个对象状态发生改变时,所有依赖它的对象都会得到通知并自动更新。
-
状态模式(State Pattern):允许对象在其内部状态发生改变时改变它的行为。对象看起来似乎修改了它的类。
-
策略模式(Strategy Pattern):定义一系列算法,将每个算法都封装起来,并使它们之间可以互换。策略模式使得算法可以独立于使用它的客户而变化。
-
模板方法模式 (Template Method Pattern):定义一个算法框架,并将一些步骤延迟到子类中实现,以便在不改变算法结构的情况下,允许子类重定义算法的某些步骤。
-
访问者模式(Visitor Pattern):是一种行为型设计模式,它可以让你在不修改对象结构的前提下,定义作用于这些对象元素的新操作。
这些设计模式可以被分为三个类别:
- 创建型模式:这些模式涉及对象的创建机制,并提供了一种将对象的创建和使用分离的方式。工厂模式、抽象工厂模式、单例模式、建造者模式和原型模式都属于这一类别。
- 结构型模式:这些模式涉及将类或对象组合在一起形成更大的结构,并提供了一种简化设计的方式。适配器模式、桥接模式、组合模式、装饰器模式、外观模式、享元模式和代理模式都属于这一类别。
- 行为型模式:这些模式涉及对象之间的通信和算法的分配,并提供了一种实现松散耦合的方式。责任链模式、命令模式、解释器模式、迭代器模式、中介者模式、备忘录模式、观察者模式、状态模式、策略模式、模板方法模式和访问者模式都属于这一类别。
二、设计模式七种原则
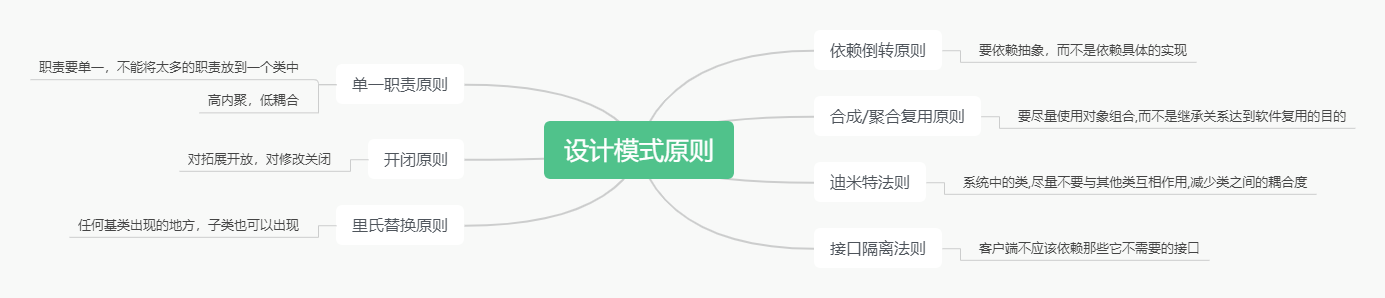
设计模式的七种原则通常被称为“SOLID原则”,是面向对象设计中的基本原则,能够帮助开发人员编写出更加灵活、可扩展、可维护的代码。这七个原则分别是:
-
单一职责原则(Single Responsibility Principle,SRP):一个类只负责一个职责或一个功能。这个原则强调的是高内聚、低耦合,可以降低类的复杂度,提高代码的可读性、可维护性和可重用性。
-
开闭原则(Open-Closed Principle,OCP):一个类的行为应该是可扩展的,但是不可修改。这个原则强调的是代码的可维护性和可扩展性,通过抽象化来避免修改已有代码的风险,从而降低软件维护的成本。
-
里氏替换原则(Liskov Substitution Principle,LSP):子类应该可以替换其父类并且不会影响程序的正确性。这个原则强调的是面向对象的继承和多态特性,通过保证子类的行为和父类一致,从而提高代码的可维护性和可扩展性。
-
接口隔离原则(Interface Segregation Principle,ISP):一个类不应该依赖它不需要的接口,即一个类对其它类的依赖应该建立在最小的接口上。这个原则强调的是接口设计的合理性,避免不必要的接口导致类之间的耦合性过高,从而提高代码的灵活性和可维护性。
-
依赖倒置原则(Dependency Inversion Principle,DIP):依赖于抽象而不是依赖于具体实现。这个原则强调的是代码的可扩展性和可维护性,通过抽象化来减少组件之间的耦合性,从而使得代码更加灵活、易于维护和扩展。
-
迪米特法则(Law of Demeter,LoD):也叫最少知识原则(Least Knowledge Principle,LKP),一个对象应当对其他对象有尽可能少的了解,不需要了解的内容尽量不要去了解。这个原则强调的是组件之间的松耦合,通过减少组件之间的依赖关系,提高代码的可维护性和可重用性。
-
组合/聚合复用原则(Composite/Aggregate Reuse Principle,CARP):尽量使用组合或聚合关系,而不是继承关系来达到代码复用的目的。这个原则强调的是通过组合和聚合的方式来实现代码复用,避免继承带来的一些问题,如父类和子类之间的强耦合性,从而提高代码的灵活性和可维护性。
三、设计模式示例讲解
1)创建型模式
1、工厂模式(Factory Method)
工厂方法模式定义一个用于创建对象的接口,让子类决定实例化哪一个类。工厂方法使一个类的实例化延迟到其子类。可分为简单工厂模式、工厂方法模式。以下分别对两种模式进行介绍。
【1】简单工厂模式(不属于GOF设计模式之一)
简单工厂模式属于创建型模式,又叫做静态工厂方法(Static Factory Method)。简单工厂模式是由一个工厂对象决定创建哪一种产品类实例。在简单工厂模式中,可以根据参数的不同返回不同类的实例。简单工厂模式专门定义一个类来负责创建其他类的实例,被创建的实例通常都具有共同的父类。简单工厂模式是工厂模式家族中最简单实用的模式,可以理解为不同工厂模式的一个特殊实现。
值得注意的是,简单工厂模式并不属于GOF设计模式之一。但是他说抽象工厂模式,工厂方法模式的基础,并且有广泛得应用。
-
在简单工厂模式中,有一个工厂类负责创建多个不同类型的对象。该工厂类通常包含一个公共的静态方法,该方法接受一个参数,用于指示要创建的对象类型,然后根据该参数创建相应的对象并返回给客户端。
-
简单工厂模式可以隐藏对象创建的复杂性,并使客户端代码更加简洁和易于维护。但它也有一些缺点,例如如果需要添加新的对象类型,则必须修改工厂类的代码。同时,该模式也可能破坏了单一职责原则,因为工厂类不仅负责对象的创建,还负责了判断要创建哪个对象的逻辑。
-
简单工厂模式通常被用于创建具有相似特征的对象,例如不同类型的图形对象、不同类型的数据库连接对象等。
下面是一个简单工厂模式的 Python 实现示例:
class Product:
def operation(self):
pass
class ConcreteProductA(Product):
def operation(self):
return "ConcreteProductA"
class ConcreteProductB(Product):
def operation(self):
return "ConcreteProductB"
class SimpleFactory:
@staticmethod
def create_product(product_type):
if product_type == "A":
return ConcreteProductA()
elif product_type == "B":
return ConcreteProductB()
else:
raise ValueError("Invalid product type")
if __name__ == "__main__":
# 客户端代码
product_a = SimpleFactory.create_product("A")
product_b = SimpleFactory.create_product("B")
print(product_a.operation()) # 输出:ConcreteProductA
print(product_b.operation()) # 输出:ConcreteProductB
实现解释:
-
上述代码中,Product 是产品类的基类,ConcreteProductA 和 ConcreteProductB 是具体的产品类,它们都继承自 Product,并实现了 operation 方法。
-
SimpleFactory 是工厂类,它包含一个 create_product 静态方法,用于根据客户端传入的产品类型创建相应的产品对象。
-
在客户端代码中,我们通过调用 SimpleFactory.create_product 方法来创建不同类型的产品对象,并调用其 operation 方法。在此示例中,我们分别创建了一个 ConcreteProductA 和一个 ConcreteProductB 对象,并输出它们的操作结果。
【2】工厂方法模式
**工厂方法模式(Factory Method)**是一种创建型设计模式,它提供了一种将对象的创建过程委托给子类的方式。
通常情况下,工厂方法模式使用一个接口或抽象类来表示创建对象的工厂,然后将具体的创建逻辑委托给子类来实现。这样可以使代码更加灵活,因为在运行时可以选择要实例化的对象类型。
以下是工厂方法模式的基本原理:
- 定义一个接口或抽象类来表示要创建的对象。
- 创建一个工厂类,该类包含一个工厂方法,该方法根据需要创建对象并返回该对象。
- 创建一个或多个具体的子类,实现工厂接口并实现工厂方法来创建对象。
工厂模式的优点:
-
这种方法可以使代码更加灵活,因为在运行时可以选择要实例化的对象类型。例如,可以轻松地添加新的子类来创建不同的对象类型,而无需更改现有的代码。
-
工厂方法模式还提供了一种解耦的方式,因为它将对象的创建逻辑与其使用代码分离。这可以使代码更加可维护和可测试,因为可以独立地测试和修改对象的创建逻辑和使用代码。
-
工厂方法模式常用于框架和库中,因为它可以使用户扩展框架或库的功能,而无需更改框架或库的源代码。
下面是一个在 Python 中实现工厂方法模式的例子:
from abc import ABC, abstractmethod
# 定义抽象产品类
class Product(ABC):
@abstractmethod
def use(self):
pass
# 定义具体产品类 A
class ConcreteProductA(Product):
def use(self):
print("Using product A")
# 定义具体产品类 B
class ConcreteProductB(Product):
def use(self):
print("Using product B")
# 定义工厂类
class Creator(ABC):
@abstractmethod
def factory_method(self):
pass
def some_operation(self):
product = self.factory_method()
product.use()
# 定义具体工厂类 A
class ConcreteCreatorA(Creator):
def factory_method(self):
return ConcreteProductA()
# 定义具体工厂类 B
class ConcreteCreatorB(Creator):
def factory_method(self):
return ConcreteProductB()
# 客户端代码
if __name__ == "__main__":
creator_a = ConcreteCreatorA()
creator_a.some_operation()
creator_b = ConcreteCreatorB()
creator_b.some_operation()
代码讲解:
-
在上面的例子中,我们首先定义了一个抽象产品类 Product,它包含了一个抽象方法 use,它将由具体产品类去实现。然后我们定义了两个具体产品类 ConcreteProductA 和 ConcreteProductB,它们实现了 Product 类中定义的抽象方法。
-
接下来,我们定义了一个抽象工厂类 Creator,它包含了一个抽象工厂方法 factory_method,这个方法将由具体工厂类去实现。我们还定义了一个 some_operation 方法,它使用工厂方法创建产品并调用 use 方法。
-
最后,我们定义了两个具体工厂类 ConcreteCreatorA 和 ConcreteCreatorB,它们分别实现了 Creator 类中的 factory_method 方法,返回具体产品类的实例。
-
在客户端代码中,我们首先创建一个 ConcreteCreatorA 对象,并调用 some_operation 方法,它会使用 ConcreteCreatorA 工厂方法创建一个 ConcreteProductA 对象并调用 use 方法。然后我们创建一个 ConcreteCreatorB 对象,同样调用 some_operation 方法,它会使用 ConcreteCreatorB 工厂方法创建一个 ConcreteProductB 对象并调用 use 方法。
还有就是示例中使用abc抽象基类(抽象父类),Python 中的 abc 模块提供了抽象基类的支持,抽象基类是一种不能直接被实例化的类,它的主要作用是定义接口和规范子类的行为。
在 abc 模块中最常用的类是 ABC 和 abstractmethod。
-
ABC是一个抽象基类,它的子类必须实现指定的抽象方法。如果子类没有实现抽象方法,则在实例化子类对象时会抛出 TypeError 异常。 -
abstractmethod是一个装饰器,它用于指定一个抽象方法。抽象方法是一个没有实现的方法,它只是一个接口,需要由子类去实现。
下面是一个使用 abc 模块定义抽象基类的例子:
from abc import ABC, abstractmethod
class Shape(ABC):
@abstractmethod
def area(self):
pass
class Rectangle(Shape):
def __init__(self, width, height):
self.width = width
self.height = height
def area(self):
return self.width * self.height
class Circle(Shape):
def __init__(self, radius):
self.radius = radius
def area(self):
return 3.14 * self.radius ** 2
if __name__ == "__main__":
# 不能直接实例化Shape() ,报错:TypeError: Can't instantiate abstract class Shape with abstract methods area
# shape = Shape()
# 只能实例化子类(派生类)
rectangle = Rectangle(3, 4) # 12
print(rectangle.area())
circle = Circle(5)
print(circle.area()) #78.5
代码讲解:
-
在上面的例子中,我们定义了一个抽象基类 Shape,它有一个抽象方法 area,子类必须实现这个方法。然后我们定义了两个子类 Rectangle 和 Circle,它们分别实现了 Shape 类中的 area 方法。
-
由于 Shape 类是一个抽象基类,不能直接实例化,所以如果我们尝试实例化 Shape 类,就会得到一个 TypeError 异常。
-
但是我们可以实例化 Rectangle 和 Circle 类,并调用它们的 area 方法来计算它们的面积。注意,由于 Rectangle 和 Circle 类都实现了 Shape 类中的 area 方法,所以它们都可以被看作是 Shape 类的子类。
2、抽象工厂模式(AbstractFactory)
抽象工厂模式(Abstract Factory)是一种创建型设计模式,它提供一个接口,用于创建一系列相关或相互依赖的对象,而不需要指定它们的具体类。
抽象工厂模式的主要目的是封装一组具有相似主题的工厂,使客户端能够以一种与产品实现无关的方式创建一组相关的产品。抽象工厂模式提供了一个抽象工厂类和一组抽象产品类,具体工厂和具体产品类由它们的子类来实现。
下面是抽象工厂模式的 UML 类图:
+---------------------+
| AbstractFactory |
+---------------------+
| create_product_A() |
| create_product_B() |
+---------------------+
/ \
/ \
/ \
/ \
+----------------+ +----------------+
| ConcreteFactory1 | | ConcreteFactory2 |
+-----------------+ +-----------------+
| create_product_A()| | create_product_A()|
| create_product_B()| | create_product_B()|
+------------------+ +------------------+
/ \ / \
/ \ / \
/ \ / \
+--------------+ +--------------+ +--------------+ +--------------+
| ProductA1 | | ProductA2 | | ProductB1 | | ProductB2 |
+--------------+ +--------------+ +--------------+ +--------------+
其中,AbstractFactory 是抽象工厂类,它定义了一组用于创建产品的抽象方法;ConcreteFactory1 和 ConcreteFactory2 是具体工厂类,它们分别实现了抽象工厂类中定义的抽象方法,用于创建一组具体产品;ProductA1、ProductA2、ProductB1 和 ProductB2 是抽象产品类,它们定义了一组用于产品的抽象方法。
下面是一个使用抽象工厂模式的例子,假设我们要开发一个跨平台的图形用户界面,包括按钮、文本框和选择框等控件,我们可以先定义一组抽象控件类和抽象工厂类:
from abc import ABC, abstractmethod
class Button(ABC):
@abstractmethod
def paint(self):
pass
class TextBox(ABC):
@abstractmethod
def paint(self):
pass
class CheckBox(ABC):
@abstractmethod
def paint(self):
pass
class GUIFactory(ABC):
@abstractmethod
def create_button(self) -> Button:
pass
@abstractmethod
def create_text_box(self) -> TextBox:
pass
@abstractmethod
def create_check_box(self) -> CheckBox:
pass
然后我们可以定义一组具体的控件类和工厂类,比如 Windows 控件和 Mac 控件:
class WindowsButton(Button):
def paint(self):
print("Painting a Windows style button")
class WindowsTextBox(TextBox):
def paint(self):
print("Painting a Windows style text box")
class WindowsCheckBox(CheckBox):
def paint(self):
print("Painting a Windows style check box")
class WindowsFactory(GUIFactory):
def create_button(self) -> Button:
return WindowsButton()
def create_text_box(self) -> TextBox:
return WindowsTextBox()
def create_check_box(self) -> CheckBox:
return WindowsCheckBox()
class MacButton(Button):
def paint(self):
print("Painting a Mac style button")
class MacTextBox(TextBox):
def paint(self):
print("Painting a Mac style text box")
class MacCheckBox(CheckBox):
def paint(self):
print("Painting a Mac style check box")
class MacFactory(GUIFactory):
def create_button(self) -> Button:
return MacButton()
def create_text_box(self) -> TextBox:
return MacTextBox()
def create_check_box(self) -> CheckBox:
return MacCheckBox()
现在我们可以使用这些类来创建不同操作系统下的 GUI,比如:
def create_gui(factory: GUIFactory):
button = factory.create_button()
text_box = factory.create_text_box()
check_box = factory.create_check_box()
return button, text_box, check_box
windows_gui = create_gui(WindowsFactory())
mac_gui = create_gui(MacFactory())
代码讲解:
- 在这个例子中,抽象工厂类 GUIFactory 定义了一组用于创建控件的抽象方法,具体工厂类 WindowsFactory 和 MacFactory 分别实现了这些方法来创建具有不同样式的 Windows 和 Mac 控件。
- 客户端代码使用不同的工厂类来创建具有不同样式的 GUI,但是它并不知道具体创建了哪些控件类。这就实现了客户端与产品实现之间的解耦。
3、单例模式(Singleton)
单例模式(Singleton)是一种创建型设计模式,其原理是确保一个类只有一个实例,并且提供了一个访问该实例的全局点。
单例模式可以使用多种不同的实现方式,但它们的基本原理是相同的。通常,单例模式使用一个私有构造函数来确保只有一个对象被创建。然后,它提供了一个全局点访问该对象的方法,使得任何代码都可以访问该对象,而不必担心创建多个实例。
具体来说,单例模式通常通过以下几个步骤实现:
- 创建一个私有构造函数,以确保类不能从外部实例化。
- 创建一个私有静态变量,用于存储类的唯一实例。
- 创建一个公共静态方法,用于访问该实例。
在公共静态方法中,如果实例不存在,则创建一个新实例并将其分配给静态变量。否则,返回现有的实例。
优缺点:
-
单例模式可以有效地避免重复的内存分配,特别是当对象需要被频繁地创建和销毁时。另外,单例模式还提供了一种简单的方式来控制全局状态,因为只有一个实例存在,可以确保任何代码都在同一个对象上运行。
-
然而,单例模式可能导致线程安全问题。如果多个线程同时尝试访问单例实例,可能会导致竞争条件。因此,在实现单例模式时需要格外小心,并考虑到线程安全问题。
以下是一个简单的Python示例,实现了单例模式的基本原理:
class Singleton:
__instance = None
def __init__(self):
if Singleton.__instance is not None:
raise Exception("This class is a singleton!")
else:
Singleton.__instance = self
@staticmethod
def get_instance():
if Singleton.__instance is None:
Singleton()
return Singleton.__instance
if __name__ == "__main__":
s1 = Singleton.get_instance()
s2 = Singleton.get_instance()
print(s1 is s2) # True
实现思路:
-
在上面的示例中,我们创建了一个名为Singleton的类,并使用
__init__()方法确保只有一个实例。在__init__()方法中,我们首先检查是否已经有一个实例存在。如果是这样,我们引发一个异常,否则我们将当前实例分配给__instance属性。 -
接下来,我们创建了一个名为
get_instance()的公共静态方法,以便访问该实例。在get_instance()方法中,我们首先检查是否已经有一个实例存在。如果没有,我们将创建一个新实例,并将其分配给__instance属性。否则,我们将返回现有的实例。
这种方法的主要优点是,只有一个实例被创建,可以避免重复的内存分配。另外,它提供了一个全局点访问该实例。
4、建造者模式(Builder)
建造者模式(Builder)是一种创建型设计模式,它允许我们按照特定顺序组装一个复杂的对象。建造者模式将对象的构造过程分解为多个步骤,每个步骤都由一个具体的构造者来完成。这样,客户端可以根据需要使用不同的构造者来构建不同的对象,而不必知道构造过程的具体细节。
- 在 Python 中,建造者模式通常使用构造者类来封装对象的构造过程,以及指导客户端如何构建对象。
- 具体的构造者类可以继承自一个抽象的构造者类,并实现其定义的构造方法,从而实现具体的构造过程。
- 客户端可以选择任何一个具体构造者类来构建对象,并且也可以自定义构造者类来实现自定义的构造过程。
下面是一个简单的 Python 实现,演示了如何使用建造者模式来构建一个包含多个部件的复杂对象(汽车):
from abc import ABC, abstractmethod
class CarBuilder(ABC):
@abstractmethod
def reset(self):
pass
@abstractmethod
def set_seats(self, number_of_seats):
pass
@abstractmethod
def set_engine(self, engine_power):
pass
@abstractmethod
def set_trip_computer(self):
pass
@abstractmethod
def set_gps(self):
pass
class Car:
def __init__(self):
self.seats = 0
self.engine_power = 0
self.trip_computer = False
self.gps = False
def __str__(self):
return f'Car with {self.seats} seats, {self.engine_power} engine, trip computer: {self.trip_computer}, GPS: {self.gps}'
class SportsCarBuilder(CarBuilder):
def __init__(self):
self.car = Car()
def reset(self):
self.car = Car()
def set_seats(self, number_of_seats):
self.car.seats = number_of_seats
def set_engine(self, engine_power):
self.car.engine_power = engine_power
def set_trip_computer(self):
self.car.trip_computer = True
def set_gps(self):
self.car.gps = True
def get_car(self):
return self.car
class Director:
def __init__(self, builder):
self.builder = builder
def build_sports_car(self):
self.builder.reset()
self.builder.set_seats(2)
self.builder.set_engine(300)
self.builder.set_trip_computer()
self.builder.set_gps()
return self.builder.get_car()
if __name__ == '__main__':
sports_car_builder = SportsCarBuilder()
director = Director(sports_car_builder)
sports_car = director.build_sports_car()
print(sports_car)
代码讲解:
-
在这个例子中,我们定义了一个抽象的 CarBuilder 类,它有五个构造方法,分别用于重置汽车、设置座位数量、设置引擎功率、安装行车电脑和安装 GPS。
-
SportsCarBuilder 类继承自 CarBuilder,实现了这些构造方法,并定义了一个 get_car() 方法,用于获取构建好的汽车对象。
-
Director 类则用来指导汽车的构建过程,它接收一个具体的构造者对象,并根据需要的顺序调用构造方法来构建汽车。
-
在主函数中,我们先创建一个 SportsCarBuilder 对象,然后使用它来构建一辆跑车。
-
构建过程由 Director 对象来指导,并返回构建好的汽车对象。最后,我们打印这辆汽车的信息,即它的座位数量、引擎功率、是否安装行车电脑和是否安装 GPS。
需要注意的是,在实际应用中,建造者模式常常会和其他设计模式一起使用,比如工厂方法模式和单例模式。此外,建造者模式还常常被用于构建复杂的 DOM 结构和 XML 文档。
5、原型模式(Prototype)
原型模式(
Prototype)是一种创建型设计模式,它允许通过复制现有对象来创建新对象,而不是通过实例化类来创建对象。原型模式允许我们创建一个原型对象,然后通过克隆这个原型对象来创建新的对象,从而避免了重复的初始化操作。
- 在 Python 中,可以使用 copy 模块中的
copy()和deepcopy()函数来实现原型模式。 copy()函数执行的是浅复制,它复制对象本身,但不复制对象引用的内存空间,因此如果原型对象中包含可变对象(如列表、字典等),那么新对象和原型对象将共享这些可变对象。deepcopy()函数则执行深复制,它会递归地复制对象及其引用的所有对象,因此新对象和原型对象不会共享任何对象。
下面是一个简单的 Python 实现,演示了如何使用原型模式创建和克隆一个包含可变和不可变成员的对象:
import copy
class Prototype:
def __init__(self, x, y, items):
self.x = x
self.y = y
self.items = items
def clone(self):
return copy.deepcopy(self)
if __name__ == '__main__':
items = ['item1', 'item2', 'item3']
original = Prototype(1, 2, items)
clone = original.clone()
print(f'Original: x={original.x}, y={original.y}, items={original.items}')
print(f'Clone: x={clone.x}, y={clone.y}, items={clone.items}')
items.append('item4')
original.x = 5
original.y = 10
print(f'Original (updated): x={original.x}, y={original.y}, items={original.items}')
print(f'Clone (not updated): x={clone.x}, y={clone.y}, items={clone.items}')
代码讲解:
- 在这个例子中,Prototype 类有三个成员:x、y 和 items。
- clone() 方法使用深度复制来复制对象及其所有成员。
- 客户端代码首先创建一个原型对象,然后克隆它以创建一个新对象。
- 接下来,客户端代码更新原型对象的成员,但是新对象不会受到影响,因为它们共享的是不同的内存空间。
2)结构型模式
1、适配器模式(Adapter)
适配器模式(Adapter)是一种结构型设计模式,用于将一个类的接口转换为另一个类的接口。适配器模式的作用是解决两个不兼容的接口之间的兼容问题,从而使它们能够协同工作。
适配器模式由三个主要组件组成:
- 目标接口(Target Interface):是客户端代码期望的接口。在适配器模式中,它通常由抽象类或接口表示。
- 适配器(Adapter):是实现目标接口的对象。适配器通过包装一个需要适配的对象,并实现目标接口来实现适配的效果。
- 源接口(Adaptee Interface):是需要被适配的接口。在适配器模式中,它通常由一个或多个具体类或接口表示。
适配器模式通常有两种实现方式:
- 类适配器模式:通过继承来实现适配器,从而使适配器成为源接口的子类,并实现目标接口。这种方式需要适配器能够覆盖源接口的所有方法。
- 对象适配器模式:通过组合来实现适配器,从而使适配器持有一个源接口的对象,并实现目标接口。这种方式可以在适配器中自定义需要适配的方法,而无需覆盖源接口的所有方法。
优缺点:
- 适配器模式的优点是能够解决两个不兼容接口之间的兼容问题,并且可以使代码更加灵活和可扩展。
- 它的缺点是需要额外的适配器对象,可能会导致代码的复杂性增加。在设计过程中,需要根据具体的场景和需求,选择最合适的适配器实现方式。
下面是一个类适配器模式的 UML 类图:
+--------------+ +--------------+ +--------------+
| Target | | Adaptee | | Adapter |
+--------------+ +--------------+ +--------------+
| +request() | | +specific_ | | +request() |
| | | request() | | |
+--------------+ +--------------+ +--------------+
| /\
| |
| |
| +------------------+
| | Client |
| +------------------+
| | +execute(Target) |
| +------------------+
| |
| |
| |
+-------------+ +-------------+
| Concrete | | Concrete |
| Target | | Adaptee |
+-------------+ +-------------+
下面是适配器模式的 Python 实现示例:
# 目标接口
class Target:
def request(self):
pass
# 源接口
class Adaptee:
def specific_request(self):
pass
# 类适配器
class Adapter(Target, Adaptee):
def request(self):
self.specific_request()
# 其他逻辑
# 对象适配器
class Adapter2(Target):
def __init__(self, adaptee):
self._adaptee = adaptee
def request(self):
self._adaptee.specific_request()
# 其他逻辑
# 客户端代码
def client_code(target):
target.request()
adaptee = Adaptee()
adapter = Adapter()
adapter2 = Adapter2(adaptee)
client_code(adapter)
client_code(adapter2)
代码解释:
-
在上面的代码中,我们首先定义了目标接口 Target 和源接口 Adaptee,然后实现了两种适配器:类适配器 Adapter 和对象适配器 Adapter2。
-
在类适配器中,我们使用多重继承来同时继承目标接口和源接口,并实现目标接口的 request 方法。在这个方法中,我们调用源接口的 specific_request 方法,并在必要的情况下进行其他逻辑处理。
-
在对象适配器中,我们使用组合来持有一个源接口的对象,并实现目标接口的 request 方法。在这个方法中,我们调用源接口的 specific_request 方法,并在必要的情况下进行其他逻辑处理。
-
最后,我们定义了一个客户端代码 client_code,它接收一个目标接口的实例作为参数,并调用该实例的 request 方法。我们分别用类适配器和对象适配器来适配源接口,并将适配器传递给客户端代码进行测试。
2、桥接模式(Bridge)
桥接模式(Bridge)是一种结构型设计模式,旨在将抽象部分和具体实现部分分离,使它们可以独立地变化。
桥接模式的原理实现基于面向对象的多态特性,其核心思想是将抽象部分和实现部分解耦,使得它们可以独立地变化而互不影响。在桥接模式中,抽象部分和实现部分分别由抽象类和实现类来表示,它们之间通过一个桥梁接口来联系。
具体的实现步骤如下:
-
定义抽象类和实现类:抽象类定义了抽象部分的接口,包含了一些基本的方法。实现类定义了实现部分的接口,包含了一些实现方法。
-
定义桥梁接口:桥梁接口定义了抽象部分和实现部分之间的连接,它包含了一个对实现类的引用,以及一些委托方法。
-
定义具体桥梁类:具体桥梁类继承了桥梁接口,实现了委托方法,将调用转发给实现类的方法。
-
实例化具体桥梁类:在程序运行时,实例化具体桥梁类,并将实现类对象作为参数传递给具体桥梁类的构造函数。
-
调用具体桥梁类的方法:在程序运行时,调用具体桥梁类的方法,具体桥梁类将委托给实现类的方法来完成具体的操作。
下面是一个 Python 示例代码,演示了如何使用桥接模式实现不同形状的颜色填充:
# 抽象类:形状
class Shape:
def __init__(self, color):
self.color = color
def draw(self):
pass
# 实现类:颜色
class Color:
def fill(self):
pass
# 实现类的具体实现:红色
class RedColor(Color):
def fill(self):
return "Red"
# 实现类的具体实现:绿色
class GreenColor(Color):
def fill(self):
return "Green"
# 桥梁接口
class Bridge:
def __init__(self, color):
self.color = color
def draw(self):
pass
# 具体桥梁类:圆形
class Circle(Bridge):
def draw(self):
return "Circle filled with " + self.color.fill()
# 具体桥梁类:矩形
class Rectangle(Bridge):
def draw(self):
return "Rectangle filled with " + self.color.fill()
# 使用示例
red = RedColor()
green = GreenColor()
circle = Circle(red)
rectangle = Rectangle(green)
print(circle.draw()) # 输出:Circle filled with Red
print(rectangle.draw()) # 输出:Rectangle filled with Green
代码讲解:
-
在这个示例中,Shape是抽象类,它包含了一个颜色属性和draw方法。Color是实现类,它包含了一个fill方法。RedColor和GreenColor是Color的具体实现类,它们分别实现了fill方法返回红色和绿色。
-
Bridge是桥梁接口,它包含了一个对Color的引用。Circle和Rectangle是具体桥梁类,它们继承了Bridge,实现了draw方法,将调用转发给实现类的fill方法。
-
在示例的最后,实例化了RedColor和GreenColor,并分别传递给Circle和Rectangle作为参数。然后调用了draw方法,输出了Circle和Rectangle的颜色填充。
通过桥接模式,将抽象部分和实现部分分离开来,可以使得它们可以独立地变化而互不影响。这样就可以更加灵活地组合不同的抽象部分和实现部分,从而实现更加复杂的功能。
3、组合模式(Composite)
组合模式(Composite)是一种结构型设计模式,它允许你将对象组合成树形结构来表示整体-部分关系,使得客户端可以统一地处理单个对象和组合对象。
该模式包含以下几个角色:
- 抽象组件(Component):定义了组合中所有对象共有的行为,并规定了管理子组件的方法。
- 叶子组件(Leaf):表示组合中的单个对象,叶子节点没有子节点。
- 容器组件(Composite):表示组合中的容器对象,容器节点可以包含其他容器节点和叶子节点。
- 客户端(Client):通过抽象组件操作组合对象。
优点:
- 使用组合模式可以使得客户端可以像处理单个对象一样处理组合对象。
- 同时也方便了新增或删除子组件。
- 该模式通常应用于处理树形结构数据或者嵌套的对象结构。
以下是一个简单的组合模式的示例,假设我们要处理一些文件和文件夹,文件夹可以包含其他文件和文件夹,我们可以使用组合模式来表示它们之间的整体-部分关系:
from abc import ABC, abstractmethod
class FileComponent(ABC):
@abstractmethod
def list(self):
pass
class File(FileComponent):
def __init__(self, name):
self.name = name
def list(self):
print(self.name)
class Folder(FileComponent):
def __init__(self, name):
self.name = name
self.children = []
def add(self, component):
self.children.append(component)
def remove(self, component):
self.children.remove(component)
def list(self):
print(self.name)
for child in self.children:
child.list()
在上述示例中,FileComponent 类是抽象组件,定义了组合中所有对象共有的行为。File 类是叶子组件,表示文件。Folder 类是容器组件,表示文件夹,它可以包含其他文件和文件夹。
客户端可以通过抽象组件对文件和文件夹进行操作,如列出文件和文件夹:
root = Folder("root")
folder1 = Folder("folder1")
folder2 = Folder("folder2")
file1 = File("file1")
file2 = File("file2")
root.add(folder1)
root.add(folder2)
root.add(file1)
folder1.add(file2)
root.list()
在上述示例中,我们创建了一个根节点root,包含了两个文件夹folder1和folder2以及两个文件file1和file2。客户端通过root节点列出了整个文件树的结构。
4、装饰模式(Decorator)
装饰模式(Decorator)是一种结构型设计模式,它允许你在运行时为对象动态添加功能。装饰模式是一种替代继承的方式,它通过将对象放入包装器对象中来实现这一点。这种模式是开放封闭原则的一种具体实现方式。
- 在装饰模式中,有一个抽象组件(Component)类,它定义了基本的操作方法。
- 有一个具体组件(ConcreteComponent)类,它实现了抽象组件类中定义的操作方法。
- 还有一个装饰器(Decorator)类,它也实现了抽象组件类中定义的操作方法,并且它包含一个指向抽象组件类的引用。
- 此外,还有一个具体装饰器(ConcreteDecorator)类,它扩展了装饰器类,以实现额外的功能。
装饰模式的核心思想是,在不改变原有类的情况下,通过包装原有类来扩展其功能。这使得我们可以在运行时动态地添加功能,而不需要在编译时修改代码。
以下是一个装饰模式的 UML 类图:
+-----------------------+ +------------------+
| Component |<-------| Decorator |
+-----------------------+ +------------------+
| + operation() | | + operation() |
+-----------------------+ | + setComponent() |
| |
+-------------------+
/\
|
+-------|-----------------+
| | |
+---------------------+ +---------------------+
| ConcreteComponent | | ConcreteDecoratorA |
+---------------------+ +---------------------+
| + operation() | | + operation() |
+---------------------+ +---------------------+
| + addedBehavior() |
+---------------------+
Component: 抽象组件类,定义了基本的操作方法。Decorator: 装饰器类,实现了抽象组件类中定义的操作方法,并且它包含一个指向抽象组件类的引用。ConcreteComponent: 具体组件类,实现了抽象组件类中定义的操作方法。ConcreteDecorator: 具体装饰器类,扩展了装饰器类,以实现额外的功能。
温馨提示:
- 在装饰模式中,可以通过组合的方式来添加多个装饰器,从而实现对对象的多次装饰。
- 同时,装饰器对象可以嵌套在其他装饰器对象内部,从而形成一个装饰器对象的树形结构,这种结构称为装饰器链。
- 在执行操作时,装饰器对象会按照一定的顺序递归地调用装饰器链中的操作方法。
下面是一个装饰模式的 Python 实现示例:
from abc import ABC, abstractmethod
# 定义抽象组件
class Component(ABC):
@abstractmethod
def operation(self):
pass
# 定义具体组件
class ConcreteComponent(Component):
def operation(self):
return "ConcreteComponent"
# 定义抽象装饰器
class Decorator(Component):
def __init__(self, component: Component):
self._component = component
@abstractmethod
def operation(self):
pass
# 定义具体装饰器 A
class ConcreteDecoratorA(Decorator):
def operation(self):
return f"ConcreteDecoratorA({self._component.operation()})"
# 定义具体装饰器 B
class ConcreteDecoratorB(Decorator):
def operation(self):
return f"ConcreteDecoratorB({self._component.operation()})"
if __name__ == "__main__":
component = ConcreteComponent()
decoratorA = ConcreteDecoratorA(component)
decoratorB = ConcreteDecoratorB(decoratorA)
print(decoratorB.operation())
代码讲解:
-
在上面的实现中,我们首先定义了一个抽象组件
Component,其中包含了一个抽象方法 operation,用于定义基本操作。 -
接着,我们定义了具体组件
ConcreteComponent,它是Component的一个实现类,实现了operation方法。 -
然后,我们定义了抽象装饰器
Decorator,它也是Component的一个实现类,其中包含了一个指向抽象组件Component的引用。同时,它也是一个抽象类,其中包含了一个抽象方法operation,用于定义装饰器的操作。 -
接着,我们定义了具体装饰器
A和B,它们都继承自Decorator类。在ConcreteDecoratorA和ConcreteDecoratorB中,我们重写了operation方法,并在其中调用了self._component.operation()方法,即对Component进行了包装,以实现对组件的功能扩展。 -
最后,在主函数中,我们创建了一个
ConcreteComponent对象,并用具体装饰器 A 和 B 对它进行了多次包装,从而实现了对组件的多次功能扩展。最终,调用decoratorB.operation()方法时,输出了ConcreteDecoratorB(ConcreteDecoratorA(ConcreteComponent)),即对ConcreteComponent对象进行了两次包装,并返回了最终的结果。
5、外观模式(Facade)
外观模式(Facade)是一种结构型设计模式,它提供了一个简单的接口,隐藏了一个或多个复杂的子系统的复杂性。外观模式可以使得客户端只需要与外观对象进行交互,而不需要与子系统中的每个对象直接交互,从而降低了客户端的复杂性,提高了系统的可维护性。
实现思路:
- 外观模式的核心思想是,提供一个简单的接口,包装一个或多个复杂的子系统,隐藏其复杂性,并向客户端提供一个更简单、更易于使用的接口。
- 在外观模式中,外观对象扮演着客户端和子系统之间的协调者,它负责将客户端的请求转发给子系统中的相应对象,并将其结果返回给客户端。
外观模式的优点包括:
-
简化了客户端的使用:外观模式为客户端提供了一个简单的接口,使得客户端不需要了解子系统中的每个对象及其功能,从而降低了客户端的复杂性。
-
隐藏了子系统的复杂性:外观模式将子系统的复杂性隐藏在外观对象之后,使得客户端只需要与外观对象进行交互,从而提高了系统的可维护性。
-
提高了灵活性:由于客户端只与外观对象进行交互,因此可以在不影响客户端的情况下修改或替换子系统中的对象。
外观模式的缺点包括:
-
不能完全隐藏子系统的复杂性:外观模式只是将子系统的复杂性隐藏在外观对象之后,但仍然需要客户端了解外观对象的接口和使用方式。
-
可能会引入不必要的复杂性:如果外观对象需要处理复杂的逻辑,就会引入额外的复杂性,从而降低系统的可维护性。
以下是一个使用外观模式的示例,假设我们有一个音乐播放器,它可以播放MP3和FLAC两种格式的音乐。不同格式的音乐播放需要不同的解码器,同时还需要加载音乐文件和设置音量等操作。我们可以使用外观模式封装这些复杂的操作,提供一个简单易用的接口给客户端使用:
class MusicPlayer:
def __init__(self):
self.mp3_player = MP3Player()
self.flac_player = FLACPlayer()
def play_mp3(self, file_path, volume):
self.mp3_player.load(file_path)
self.mp3_player.set_volume(volume)
self.mp3_player.play()
def play_flac(self, file_path, volume):
self.flac_player.load(file_path)
self.flac_player.set_volume(volume)
self.flac_player.play()
class MP3Player:
def load(self, file_path):
print(f"Loading MP3 file from {file_path}")
def set_volume(self, volume):
print(f"Setting MP3 volume to {volume}")
def play(self):
print("Playing MP3 music")
class FLACPlayer:
def load(self, file_path):
print(f"Loading FLAC file from {file_path}")
def set_volume(self, volume):
print(f"Setting FLAC volume to {volume}")
def play(self):
print("Playing FLAC music")
代码讲解:
-
在上述示例中,
MusicPlayer类是外观类,它封装了MP3和FLAC播放器对象。play_mp3和play_flac方法是外观类中的简单接口,它们将客户端的请求转发给相应的播放器对象。 -
客户端只需要使用
MusicPlayer类就可以进行MP3和FLAC的播放,而不需要了解播放器的具体实现。如果需要修改或替换播放器中的对象,只需要修改外观类的实现即可,而不会影响客户端的使用。
6、享元模式(Flyweight)
享元模式(
Flyweight)是一种结构型设计模式,它通过共享对象来尽可能减少内存使用和对象数量。在享元模式中,存在两种对象:内部状态(Intrinsic State)和外部状态(Extrinsic State)。内部状态指对象的共享部分,不随环境改变而改变;外部状态指对象的非共享部分,会随环境改变而改变。
实现思路:
- 享元模式的核心思想是尽量重用已经存在的对象,减少对象的创建和销毁,从而提高性能和节省内存。
- 它通常适用于需要大量创建对象的场景,但又不能因为对象过多而导致内存不足或性能降低的情况。
下面是一个简单的享元模式的示例,假设我们有一个字符工厂,它可以创建不同的字符对象。在实现字符对象时,我们发现有一些字符会被频繁使用,而且它们的状态是不变的,例如空格、逗号、句号等标点符号。因此,我们可以将这些字符设计为享元对象,通过共享来节省内存。
class CharacterFactory:
def __init__(self):
self.characters = {}
def get_character(self, character):
if character in self.characters:
return self.characters[character]
else:
new_character = Character(character)
self.characters[character] = new_character
return new_character
class Character:
def __init__(self, character):
self.character = character
def render(self, font):
print(f"Rendering character {self.character} in font {font}")
# 创建字符工厂
factory = CharacterFactory()
# 获取不同的字符
char1 = factory.get_character("A")
char2 = factory.get_character("B")
char3 = factory.get_character(" ")
char4 = factory.get_character(",")
char5 = factory.get_character(" ")
char6 = factory.get_character(".")
# 渲染不同的字符
char1.render("Arial")
char2.render("Times New Roman")
char3.render("Arial")
char4.render("Times New Roman")
char5.render("Arial")
char6.render("Times New Roman")
代码讲解:
-
在上述示例中,我们创建了一个CharacterFactory类来管理字符对象。当客户端需要获取一个字符时,可以调用get_character方法。如果该字符已经被创建过了,就直接返回共享的对象;否则,创建一个新的对象并将其保存到工厂中,以备下次使用。
-
字符对象Character有一个render方法,用于渲染该字符。在实际使用中,我们可能需要给不同的字符设置不同的字体,这里只是为了演示方便,用字符串代替了字体对象。
-
通过享元模式,我们可以共享多个相同的字符对象,从而减少内存使用和对象数量。在这个例子中,如果没有使用享元模式,我们可能需要创建多个空格、逗号和句号对象,而这些对象的状态都是不变的,这样就会导致内存浪费。通过使用享元模式,我们可以将这些相同的对象共享起来,避免重复创建对象,从而提高性能和节省内存。
需要注意的是,享元模式并不是万能的,它适用于需要大量创建相同对象的场景。如果对象的数量不大,或者对象状态变化频繁,那么使用享元模式可能会增加代码复杂度,而且也不一定能够带来性能提升。因此,在使用享元模式时需要仔细考虑是否适合当前场景。
7、代理模式(Proxy)
代理模式(Proxy)是一种结构型设计模式,它允许在访问对象时添加一些额外的行为。代理类充当客户端和实际对象之间的中介。客户端通过代理来访问实际对象,代理在访问实际对象前后执行一些额外的操作,例如权限检查、缓存等。
代理模式包含三个角色:抽象主题(Subject)、真实主题(Real Subject)和代理主题(Proxy Subject)。其中,抽象主题定义了真实主题和代理主题的公共接口;真实主题是实际执行操作的对象;代理主题通过实现抽象主题接口,控制对真实主题的访问。
以下是代理模式的 UML 类图:
+-------------+ +-----------------+ +---------------+
| Subject |<----| RealSubject | | ProxySubject |
+-------------+ +-----------------+ +---------------+
| +request()| | +request() | | +request() |
+-------------+ +-----------------+ +---------------+
在上面的类图中,Subject 是抽象主题,定义了客户端和真实主题之间的接口,RealSubject 是真实主题,实现了抽象主题定义的接口,ProxySubject 是代理主题,也实现了抽象主题定义的接口,并且内部持有一个 RealSubject 对象,以便在需要时代理访问 RealSubject 对象。
下面是一个 Python 实现的示例,假设我们有一个邮件服务器,我们需要实现一个邮件客户端程序,但我们不想直接连接到邮件服务器,因为这样可能会存在一些风险,我们想通过代理来连接邮件服务器,以此增加一些安全性:
# 抽象主题
class Email:
def send(self, message):
pass
# 真实主题
class EmailServer(Email):
def send(self, message):
print(f'Sending email: {message}')
# 代理主题
class EmailProxy(Email):
def __init__(self, email_server):
self.email_server = email_server
def send(self, message):
if self.is_allowed_to_send(message):
self.email_server.send(message)
self.log(message)
else:
print('Not allowed to send email')
def is_allowed_to_send(self, message):
# Check if user is allowed to send the email
return True
def log(self, message):
# Log the email to a file
print(f'Logging email: {message}')
# 客户端
if __name__ == '__main__':
email_server = EmailServer()
email_proxy = EmailProxy(email_server)
email_proxy.send('Hello, world!')
代理讲解:
- 在上面的示例中,
Email是抽象主题,定义了发送邮件的方法send()。 EmailServer是真实主题,实现了send()方法来发送邮件。EmailProxy是代理主题,它实现了send()方法,并且内部持有一个EmailServer对象,以便在需要时代理访问EmailServer对象。- 在
send()方法中,它首先检查是否允许发送邮件,然后调用EmailServer对象的send()方法来发送邮件,并在发送完成后记录日志。 - 最后,我们在客户端中创建了一个
EmailServer对象和一个EmailProxy对象,然后通过EmailProxy对象来发送邮件。
需要注意的是,在代理模式中,代理主题和真实主题必须实现同样的接口,因此代理主题必须是抽象主题的子类。此外,代理主题还可以通过实现额外的方法来增加一些附加的功能。
3)行为型模式
1、职任链模式(Chain of Responsibility)
职责链模式(Chain of Responsibility)是一种行为型设计模式,它通过将请求的发送者和接收者解耦,从而使多个对象都有机会处理这个请求。
实现思路:
- 在职责链模式中,我们定义一系列的处理器对象,每个处理器对象都包含一个对下一个处理器对象的引用。
- 当请求从客户端发送到处理器对象时,第一个处理器对象会尝试处理请求,如果它不能处理请求,则将请求传递给下一个处理器对象,以此类推,直到请求被处理或者所有的处理器对象都不能处理请求。
优缺点:
-
职责链模式的优点是它可以灵活地配置处理器对象的顺序和组合,从而满足不同的处理需求。它还可以将请求的发送者和接收者解耦,从而提高系统的灵活性和可扩展性。
-
职责链模式的缺点是如果处理器对象过多或者处理器对象之间的关系过于复杂,可能会导致系统的维护难度增加。
职责链模式通常涉及以下角色:
-
处理器接口(Handler Interface):定义处理器对象的接口,包含处理请求的方法和对下一个处理器对象的引用。
-
具体处理器类(Concrete Handlers):实现处理器接口,处理请求或将请求传递给下一个处理器对象。
-
客户端(Client):创建处理器对象的链,将请求发送给链的第一个处理器对象。
下面是一个简单的 Python 实现示例:
1、定义处理器接口:
class Handler:
def set_next(self, handler):
pass
def handle(self, request):
pass
2、实现具体处理器类:
class AbstractHandler(Handler):
def __init__(self):
self._next_handler = None
def set_next(self, handler):
self._next_handler = handler
return handler
def handle(self, request):
if self._next_handler:
return self._next_handler.handle(request)
return None
class ConcreteHandler1(AbstractHandler):
def handle(self, request):
if request == "request1":
return "Handled by ConcreteHandler1"
else:
return super().handle(request)
class ConcreteHandler2(AbstractHandler):
def handle(self, request):
if request == "request2":
return "Handled by ConcreteHandler2"
else:
return super().handle(request)
class ConcreteHandler3(AbstractHandler):
def handle(self, request):
if request == "request3":
return "Handled by ConcreteHandler3"
else:
return super().handle(request)
3、客户端创建处理器对象的链:
handler1 = ConcreteHandler1()
handler2 = ConcreteHandler2()
handler3 = ConcreteHandler3()
handler1.set_next(handler2).set_next(handler3)
# 发送请求
requests = ["request1", "request2", "request3", "request4"]
for request in requests:
response = handler1.handle(request)
if response:
print(response)
else:
print(f"{request} was not handled")
代码讲解:
-
上面的示例中,我们定义了一个处理器接口 Handler,其中包含 set_next 和 handle 方法。
-
我们还定义了一个抽象处理器类 AbstractHandler,它实现了 set_next 和 handle 方法,其中 handle 方法调用了下一个处理器对象的 handle 方法。
-
我们还实现了三个具体的处理器类 ConcreteHandler1、ConcreteHandler2 和 ConcreteHandler3,它们分别实现了自己的 handle 方法。
-
客户端创建处理器对象的链,将处理器对象按照需要连接起来,然后将请求发送给链的第一个处理器对象,处理器对象将请求进行处理或者将请求传递给下一个处理器对象,直到请求被处理或者没有处理器对象能够处理请求。
-
在这个例子中,当请求为 “request1”、“request2”、“request3” 时,请求会被相应的处理器对象处理;当请求为 “request4” 时,没有处理器对象能够处理该请求,因此该请求未被处理。
总的来说,职责链模式可以使多个对象都有机会处理请求,并且可以灵活地配置处理器对象的顺序和组合,从而提高系统的灵活性和可扩展性。
2、命令模式(Command)
命令模式(Command)是一种行为型设计模式,它将请求封装成一个对象,从而使您可以将不同的请求与其请求的接收者分开。这种模式的目的是通过将请求发送者和请求接收者解耦来实现请求的发送、执行和撤销等操作。
实现思路:
- 在命令模式中,我们定义一个 Command 接口,该接口包含一个 execute 方法,用于执行命令。
- 我们还定义了一个 Invoker 类,它用于发送命令,可以接受一个 Command 对象,并在需要时调用该对象的 execute 方法。
- 我们还定义了一个 Receiver 类,它实际执行命令,包含一些特定于应用程序的业务逻辑。
命令模式涉及以下角色:
-
Command 接口:定义了一个执行命令的方法 execute。
-
具体命令类(Concrete Command):实现了 Command 接口,实现 execute 方法,包含一个接收者对象,执行具体的业务逻辑。
-
Invoker 类:负责发送命令,它包含一个 Command 对象,可以在需要时调用该对象的 execute 方法。
-
Receiver 类:包含一些特定于应用程序的业务逻辑,实际执行命令。
下面是一个简单的 Python 实现示例:
1、定义 Command 接口:
from abc import ABC, abstractmethod
class Command(ABC):
@abstractmethod
def execute(self):
pass
2、实现具体命令类:
class LightOnCommand(Command):
def __init__(self, light):
self.light = light
def execute(self):
self.light.turn_on()
class LightOffCommand(Command):
def __init__(self, light):
self.light = light
def execute(self):
self.light.turn_off()
3、定义 Invoker 类:
class RemoteControl:
def __init__(self):
self.commands = []
def add_command(self, command):
self.commands.append(command)
def execute_commands(self):
for command in self.commands:
command.execute()
4、定义 Receiver 类:
class Light:
def turn_on(self):
print("The light is on")
def turn_off(self):
print("The light is off")
5、创建并使用命令:
light = Light()
remote_control = RemoteControl()
remote_control.add_command(LightOnCommand(light))
remote_control.add_command(LightOffCommand(light))
remote_control.execute_commands()
代码解释:
-
在这个例子中,我们首先定义了一个 Command 接口,该接口包含 execute 方法。然后,我们定义了两个具体命令类 LightOnCommand 和 LightOffCommand,它们实现了 Command 接口,并包含一个接收者对象 Light,实现了执行具体的业务逻辑。
-
我们还定义了一个 Invoker 类 RemoteControl,它包含一个 Command 对象的列表,并提供了一个 add_command 方法用于添加 Command 对象。execute_commands 方法用于在需要时调用 Command 对象的 execute 方法。
-
最后,我们定义了一个 Receiver 类 Light,它包含一些特定于应用程序的业务逻辑,实际执行命令。
-
在客户端代码中,我们创建了一个 Light 对象和一个 RemoteControl 对象。我们将 LightOnCommand 和 LightOffCommand 对象添加到 RemoteControl 对象的命令列表中,然后调用 execute_commands 方法来执行这些命令。
当我们执行这个程序时,它将输出以下内容:
The light is on
The light is off
- 这是因为我们创建了一个 Light 对象,然后使用 LightOnCommand 和 LightOffCommand 对象分别打开和关闭该对象。通过将命令对象和命令的接收者对象分开,我们可以轻松地添加、删除和替换命令,同时也使得程序更加灵活和可扩展。
总的来说,命令模式提供了一种通过将请求封装成对象来实现请求的发送、执行和撤销的方法,从而使得命令对象和命令接收者对象解耦,提高程序的灵活性和可扩展性。
3、解释器模式(Interpreter)
解释器模式(Interpreter Pattern)是一种行为型设计模式,它定义了一种语言文法,以及一个解释器,用于解释该语言中的句子。解释器模式通常用于解决特定类型的问题,例如解释计算器表达式,SQL 查询语句等。
解释器模式包括三个核心角色:
- Context(上下文):它是解释器的运行环境。它存储解释器所需的一些全局信息。
- Abstract Expression(抽象表达式):它是定义所有表达式的接口,通常包含解释方法 interpret()。
- Concrete Expression(具体表达式):它实现抽象表达式接口,用于解释特定类型的表达式。
下面是解释器模式的 Python 实现示例:
class Context:
def __init__(self):
self._variables = {}
def set_variable(self, name, value):
self._variables[name] = value
def get_variable(self, name):
return self._variables.get(name)
class Expression:
def interpret(self, context):
pass
class VariableExpression(Expression):
def __init__(self, name):
self._name = name
def interpret(self, context):
return context.get_variable(self._name)
class ConstantExpression(Expression):
def __init__(self, value):
self._value = value
def interpret(self, context):
return self._value
class AddExpression(Expression):
def __init__(self, left, right):
self._left = left
self._right = right
def interpret(self, context):
return self._left.interpret(context) + self._right.interpret(context)
class SubtractExpression(Expression):
def __init__(self, left, right):
self._left = left
self._right = right
def interpret(self, context):
return self._left.interpret(context) - self._right.interpret(context)
if __name__ =="__main__":
# 测试代码
context = Context()
a = ConstantExpression(1)
b = ConstantExpression(2)
c = ConstantExpression(3)
x = VariableExpression('x')
y = VariableExpression('y')
context.set_variable('x', 10)
context.set_variable('y', 5)
# 1 + 2 + 3 = 6
expression = AddExpression(AddExpression(a, b), c)
result = expression.interpret(context)
print(result)
# 10 - 2 + 5 = 13
expression = AddExpression(SubtractExpression(x, b), y)
result = expression.interpret(context)
print(result)
代码解释:
- 在上面的实现中,我们定义了一个 Context 类来表示解释器的运行环境,它存储解释器所需的一些全局信息。
- Expression 类是抽象表达式类,包含一个 interpret 方法用于解释表达式。VariableExpression 和 ConstantExpression 类是具体表达式类,用于解释变量和常量。
- AddExpression 和 SubtractExpression 类是具体表达式类,用于解释加法和减法表达式。
4、迭代器模式(Iterator)
迭代器模式(Iterator)是一种行为型设计模式,它允许你在不暴露集合底层实现的情况下遍历集合中的所有元素。
实现思路:
- 在迭代器模式中,集合类(如列表、树等)将遍历操作委托给一个迭代器对象,而不是直接实现遍历操作。
- 迭代器对象负责实现遍历操作,以及保存当前遍历位置等状态。
- 这样,集合类就可以将遍历操作与集合底层实现解耦,从而使得集合类更加简单、灵活和易于维护。
迭代器模式通常由以下几个角色组成:
- 迭代器(Iterator):定义了迭代器的接口,包含用于遍历集合元素的方法,如 next()、has_next() 等。
- 具体迭代器(ConcreteIterator):实现了迭代器接口,负责实现迭代器的具体遍历逻辑,以及保存当前遍历位置等状态。
- 集合(Aggregate):定义了集合的接口,包含用于获取迭代器对象的方法,如 create_iterator() 等。
- 具体集合(ConcreteAggregate):实现了集合接口,负责创建具体迭代器对象,以便遍历集合中的元素。
迭代器模式的优缺点包括:
- 将遍历操作与集合底层实现解耦,使得集合类更加灵活和易于维护。
简化了集合类的接口,使得集合类更加简单明了。 - 提供了对不同类型的集合统一遍历的机制,使得算法的复用性更加高。
- 迭代器模式的缺点是,由于迭代器对象需要保存遍历位置等状态,因此它可能会占用比较大的内存。此外,由于迭代器对象需要负责遍历逻辑,因此它可能会变得比较复杂。
以下是迭代器模式的一个简单示例,实现了一个列表类和一个列表迭代器类:
from abc import ABC, abstractmethod
# 抽象迭代器类
class Iterator(ABC):
@abstractmethod
def has_next(self):
pass
@abstractmethod
def next(self):
pass
# 具体迭代器类
class ConcreteIterator(Iterator):
def __init__(self, data):
self.data = data
self.index = 0
def has_next(self):
return self.index < len(self.data)
def next(self):
if self.has_next():
value = self.data[self.index]
self.index += 1
return value
# 抽象聚合类
class Aggregate(ABC):
@abstractmethod
def create_iterator(self):
pass
# 具体聚合类
class ConcreteAggregate(Aggregate):
def __init__(self, data):
self.data = data
def create_iterator(self):
return ConcreteIterator(self.data)
# 测试
if __name__ == "__main__":
data = [1, 2, 3, 4, 5]
aggregate = ConcreteAggregate(data)
iterator = agg
代码解释:
-
以上代码中,我们首先定义了抽象迭代器类 Iterator,其中定义了两个抽象方法 has_next 和 next,分别用于判断是否还有下一个元素和返回下一个元素。然后,我们定义了具体迭代器类 ConcreteIterator,它包含了一个数据列表 data 和一个指针 index,它实现了 has_next 和 next 方法。
-
接着,我们定义了抽象聚合类 Aggregate,其中定义了一个抽象方法 create_iterator,用于创建迭代器对象。然后,我们定义了具体聚合类 ConcreteAggregate,它包含了一个数据列表 data,它实现了 create_iterator 方法,返回一个 ConcreteIterator 对象。
-
最后,在测试代码中,我们创建了一个数据列表 data,然后创建了一个具体聚合对象 aggregate,并通过 create_iterator 方法创建了一个具体迭代器对象 iterator,然后使用 while 循环遍历该聚合对象中的各个元素,打印出每个元素的值。
这样,迭代器模式的基本结构就完成了。我们可以通过定义不同的聚合类和迭代器类来实现不同的聚合对象和迭代方式。这样,迭代器模式可以提高程序的灵活性和可扩展性。
5、中介者模式(Mediator)
中介者模式(Mediator)是一种行为型设计模式,它用于将多个对象之间的交互解耦,从而使得对象之间的通信更加简单和灵活。
实现思路:
- 在中介者模式中,多个对象之间不直接相互通信,而是通过一个中介者对象进行通信。
- 这样,每个对象只需要和中介者对象通信,而不需要知道其他对象的存在。
- 中介者对象负责协调各个对象之间的交互,使得系统更加灵活和易于维护。
中介者模式通常由以下几个角色组成:
- 抽象中介者(Mediator):定义了各个同事对象之间交互的接口,它通常包含一个或多个抽象方法,用于定义各种交互操作。
- 具体中介者(ConcreteMediator):实现了抽象中介者接口,负责协调各个同事对象之间的交互关系。
- 抽象同事类(Colleague):定义了各个同事对象的接口,包含一个指向中介者对象的引用,以便与中介者进行通信。
- 具体同事类(ConcreteColleague):实现了抽象同事类的接口,负责实现各自的行为,并且需要和中介者对象进行通信。
中介者模式的优缺点包括:
- 解耦了各个对象之间的交互关系,使得系统更加灵活和易于维护。
- 降低了系统的复杂度,使得各个对象之间的交互变得简单明了。
- 可以集中管理各个对象之间的交互关系,从而提高系统的可维护性和可扩展性。
- 中介者模式的缺点是,由于中介者对象需要负责协调各个同事对象之间的交互关系,因此它的职责可能会变得非常复杂。另外,由于中介者对象需要了解各个同事对象之间的交互关系,因此它可能会变得比较庞大。
下面是一个简单的中介者模式的 Python 实现,该实现使用一个聊天室作为中介者,多个用户作为同事类:
from typing import List
class User:
def __init__(self, name: str, mediator):
self.name = name
self.mediator = mediator
def send_message(self, message: str):
self.mediator.send_message(message, self)
def receive_message(self, message: str):
print(f"{self.name} received message: {message}")
class ChatRoom:
def __init__(self):
self.users: List[User] = []
def add_user(self, user: User):
self.users.append(user)
def send_message(self, message: str, sender: User):
for user in self.users:
if user != sender:
user.receive_message(f"{sender.name}: {message}")
if __name__ == '__main__':
chat_room = ChatRoom()
alice = User("Alice", chat_room)
bob = User("Bob", chat_room)
charlie = User("Charlie", chat_room)
chat_room.add_user(alice)
chat_room.add_user(bob)
chat_room.add_user(charlie)
alice.send_message("Hi everyone!")
bob.send_message("Hello Alice!")
charlie.send_message("Hey guys, what's up?")
代码解释:
- 在上面的示例中,User 类表示同事类,ChatRoom 类表示中介者。
- 每个 User 对象都有一个指向 ChatRoom 对象的引用,以便与中介者进行通信。
- 当一个用户发送消息时,它会将消息发送到中介者,然后中介者会将消息广播给其他用户。
这个简单的实现演示了中介者模式的基本思想,尽管它没有实现一个完整的中介者模式。实际上,中介者模式通常需要更复杂的实现,以便处理更复杂的交互关系。
6、备忘录模式(Memento)
备忘录模式(Memento)是一种行为型设计模式,它允许在不暴露对象实现细节的情况下保存和恢复对象的内部状态。备忘录模式的核心是备忘录类,它用于存储对象的状态信息,同时提供给其他类访问状态信息的接口。
备忘录模式包括三个核心角色:
- Originator(发起人):它是需要保存状态的对象。它创建备忘录对象来存储内部状态,并可以使用备忘录对象来恢复其先前的状态。
- Memento(备忘录):它是存储发起人对象内部状态的对象。备忘录对象由发起人创建,并由发起人决定何时读取备忘录以恢复其先前的状态。
- Caretaker(管理者):它负责备忘录的安全保管。它只能将备忘录传递给其他对象,不能修改备忘录的内容。
在 Python 中,备忘录模式通常使用 Python 的内置 copy 模块和 dict 属性来实现。下面是一个简单的备忘录模式的 Python 实现:
import copy
# 发起人类
class Originator:
def __init__(self):
self._state = None
def set_state(self, state):
print("设置状态为:", state)
self._state = state
def create_memento(self):
print("创建备忘录")
return Memento(copy.deepcopy(self._state))
def restore_memento(self, memento):
print("恢复备忘录")
self._state = memento.get_state()
def show_state(self):
print("当前状态为:", self._state)
# 备忘录类
class Memento:
def __init__(self, state):
self._state = state
def get_state(self):
return self._state
# 管理者类
class Caretaker:
def __init__(self):
self._mementos = []
def add_memento(self, memento):
self._mementos.append(memento)
def get_memento(self, index):
return self._mementos[index]
# 测试
if __name__ == "__main__":
originator = Originator()
caretaker = Caretaker()
originator.set_state("状态1")
caretaker.add_memento(originator.create_memento())
originator.set_state("状态2")
caretaker.add_memento(originator.create_memento())
originator.set_state("状态3")
originator.show_state()
originator.restore_memento(caretaker.get_memento(1))
originator.show_state()
originator.restore_memento(caretaker.get_memento(0))
originator.show_state()
代码解释:
-
以上代码中,我们首先定义了发起人类 Originator,其中包含一个状态变量 _state,以及用于设置状态、创建备忘录和恢复备忘录的方法。在 create_memento 方法中,我们通过 copy.deepcopy 方法创建了一个状态信息的备忘录对象。在 restore_memento 方法中,我们通过备忘录对象的 get_state 方法获取备忘录中的状态信息,然后将其恢复到当前的状态变量中。在 show_state 方法中,我们打印出当前状态的值。
-
接着,我们定义了备忘录类 Memento,它包含了一个状态信息的属性 _state,以及一个用于获取该属性的方法 get_state。
-
最后,我们定义了管理者类 Caretaker,它包含了一个备忘录列表 _mementos,以及用于添加备忘录和获取备忘录的方法。
7、观察者模式(Observer)
观察者模式(Observer)是一种软件设计模式,它定义了对象之间的一种一对多的依赖关系,使得当一个对象的状态发生改变时,所有依赖它的对象都会收到通知并自动更新。这个模式也被称为发布/订阅模式(Publish/Subscribe),事件模型(Event Model)或消息机制(Message Pattern)。
实现思路:
- 在观察者模式中,有两种类型的对象:观察者和主题(Subject)。
- 主题是被观察的对象,它维护了一个观察者列表,用于记录所有依赖于它的观察者。
- 当主题状态发生变化时,它会自动通知所有观察者,让它们能够及时更新自己的状态。
- 观察者是依赖于主题的对象,当主题状态发生变化时,它们会收到通知并根据新状态更新自己的状态。
优缺点:
-
观察者模式的优点是它实现了松耦合(loose coupling)的设计,因为主题和观察者之间没有直接的依赖关系。这使得程序更加灵活,能够更容易地扩展和修改。观察者模式也使得对象能够以可预测的方式进行通信,因为主题和观察者都遵循了同一种接口。同时,观察者模式也可以提高程序的可维护性,因为它将功能分散到了不同的对象中,使得每个对象都具有清晰的职责。
-
观察者模式的缺点是,它可能会导致过多的细节传递,因为主题在通知观察者时必须传递详细信息。这可能会导致性能问题或安全问题,因为观察者可以访问到主题的私有信息。同时,观察者模式也可能导致循环依赖的问题,因为主题和观察者之间可能会相互依赖。
以下是观察者模式的 Python 实现:
class Subject:
def __init__(self):
self._observers = []
def attach(self, observer):
if observer not in self._observers:
self._observers.append(observer)
def detach(self, observer):
try:
self._observers.remove(observer)
except ValueError:
pass
def notify(self, modifier=None):
for observer in self._observers:
if modifier != observer:
observer.update(self)
class Observer:
def update(self, subject):
pass
class ConcreteSubject(Subject):
def __init__(self):
super().__init__()
self._state = None
@property
def state(self):
return self._state
@state.setter
def state(self, state):
self._state = state
self.notify()
class ConcreteObserver(Observer):
def __init__(self, name):
self._name = name
def update(self, subject):
print(f'{self._name} received an update: {subject.state}')
subject = ConcreteSubject()
observer1 = ConcreteObserver('Observer 1')
observer2 = ConcreteObserver('Observer 2')
subject.attach(observer1)
subject.attach(observer2)
subject.state = 123
subject.detach(observer1)
subject.state = 456
代码讲解:
-
在上面的实现中,Subject 是主题类,Observer 是观察者类,ConcreteSubject 是具体主题类,ConcreteObserver 是具体观察者类。
-
当主题状态发生变化时,它会通过 notify 方法通知所有观察者。
-
观察者可以通过 update 方法接收到主题的状态变化,并进行相应的处理。
-
在上面的例子中,我们创建了一个 ConcreteSubject 对象,然后创建了两个 ConcreteObserver 对象,并将它们添加到主题的观察者列表中。
-
接着,我们改变了主题的状态两次,第一次时两个观察者都收到了通知,第二次时只有一个观察者收到了通知。
-
最后,我们从主题的观察者列表中移除了一个观察者,并再次改变了主题的状态,这时只有一个观察者收到了通知。
8、状态模式(State)
状态模式(State)是一种行为型设计模式,它允许对象在不同的内部状态下改变其行为。在状态模式中,一个对象可以有多个状态,每个状态都对应着一组不同的行为。对象根据自身的状态,选择不同的行为。这种模式将状态抽象成独立的类,使得状态之间可以相互切换,而不影响对象的整体行为。
状态模式由三个核心组件构成:
- 环境(Context):表示当前对象的状态,它维护一个对抽象状态类的引用,以便能够切换状态。
- 抽象状态(State):定义一个接口,用于封装与环境相关的行为。
- 具体状态(ConcreteState):实现抽象状态接口,实现与环境相关的行为。
在状态模式中,当对象的状态发生变化时,它会将状态的处理委托给当前状态对象。状态对象会负责处理相关的操作,并且在必要时会将环境的状态切换到新的状态。
状态模式的优缺点包括:
- 将状态转换的逻辑封装在状态类中,使得状态之间的切换变得简单明了。
增加新的状态非常容易,只需要增加新的状态类即可。 - 可以消除大量的条件分支语句,使得代码更加清晰和易于维护。
- 状态模式的缺点是,由于需要创建多个状态类,因此会增加系统的复杂度。另外,状态之间的转换也需要仔细设计,否则可能会导致系统的不稳定性。
下面是一个简单的使用 Python 实现状态模式的例子。
假设我们有一个电梯,它可以处于三种状态之一:开门状态、关门状态和运行状态。在每种状态下,电梯的行为不同。我们可以使用状态模式来管理电梯的不同状态,从而使电梯的行为更加清晰和易于维护。
首先,我们需要定义一个抽象状态类 State,它包含一个抽象方法 handle,用于处理电梯在不同状态下的行为:
class State:
def handle(self):
pass
接下来,我们定义三个具体状态类 OpenState、CloseState 和 RunState,分别表示电梯的开门状态、关门状态和运行状态。这些类实现了抽象状态类中的 handle 方法:
class OpenState(State):
def handle(self):
print("Opening the door")
class CloseState(State):
def handle(self):
print("Closing the door")
class RunState(State):
def handle(self):
print("Running")
然后,我们定义一个环境类 Lift,它包含一个状态变量 state,表示当前电梯的状态。在 Lift 类中,我们定义了三个方法 open、close 和 run,分别用于切换电梯的状态:
class Lift:
def __init__(self):
self.state = None
def setState(self, state):
self.state = state
def open(self):
self.state.handle()
def close(self):
self.state.handle()
def run(self):
self.state.handle()
最后,我们可以使用这些类来模拟电梯的运行过程。例如,我们可以首先将电梯的状态设置为开门状态,然后依次执行关门和运行操作:
lift = Lift()
lift.setState(OpenState())
lift.open() # Opening the door
lift.setState(CloseState())
lift.close() # Closing the door
lift.setState(RunState())
lift.run() # Running
这样,我们就成功地使用状态模式来管理电梯的不同状态。在实际应用中,我们可以将更复杂的状态和行为加入到电梯系统中,从而使其更加灵活和易于扩展。
9、策略模式(Strategy)
策略模式(Strategy)是一种行为型设计模式,它允许在运行时选择算法的不同实现方式。该模式的基本思想是将算法封装在可互换的策略对象中,使得客户端能够动态地选择算法的实现方式。
实现思路:
- 在策略模式中,通常有一个上下文对象(Context),它持有一个或多个策略对象(Strategy),并将具体的任务委托给其中的某个策略对象来完成。
- 策略对象之间通常是相互独立的,它们之间没有共享状态,客户端可以自由地选择不同的策略对象。
优缺点:
- 策略模式的优点是可以提高代码的可维护性和可扩展性,因为它将算法的实现与上下文对象分离,使得修改或增加新的算法实现变得更加容易。
- 缺点是可能会增加类的数量,同时需要客户端显式地选择不同的策略对象,这可能会使代码变得更加复杂。
下面是一个简单的 Python 实现示例:
1、定义策略接口:
class SortStrategy:
def sort(self, data):
pass
2、实现具体策略类:
class QuickSort(SortStrategy):
def sort(self, data):
# 使用快速排序算法实现排序
pass
class BubbleSort(SortStrategy):
def sort(self, data):
# 使用冒泡排序算法实现排序
pass
3、定义上下文类:
class SortContext:
def __init__(self):
self.strategy = None
def set_sort_strategy(self, strategy):
self.strategy = strategy
def sort_data(self, data):
self.strategy.sort(data)
4、客户端选择算法实现方式:
context = SortContext()
data = [5, 1, 4, 2, 8]
context.set_sort_strategy(QuickSort())
context.sort_data(data) # 使用快速排序算法实现排序
context.set_sort_strategy(BubbleSort())
context.sort_data(data) # 使用冒泡排序算法实现排序
代码解释:
- 在这个例子中,上下文类 SortContext 持有一个策略对象 SortStrategy,客户端通过调用上下文类提供的方法来设置不同的策略对象,从而选择不同的算法实现方式。
- 同时,具体的算法实现方式被封装在具体的策略类 QuickSort 和 BubbleSort 中。
10、模板方法模式(TemplateMethod)
模板方法模式(Template Method)是一种行为设计模式,它定义了一个算法的骨架,而将某些步骤的实现延迟到子类中。该模式主要用于在不改变算法结构的情况下重定义算法的某些步骤,以适应不同的需求。
模板方法模式由抽象类和具体子类组成。抽象类定义了一个算法的骨架,它包含若干个抽象方法和具体方法,其中抽象方法表示子类需要实现的步骤,具体方法则提供了默认实现。子类通过继承抽象类并实现其中的抽象方法来完成算法的实现。
模板方法模式的优点包括:
-
提高代码的复用性:模板方法将算法的核心部分封装在抽象类中,可以使多个子类共享相同的算法实现,避免重复编写相同的代码。
-
提高代码的扩展性:通过将算法中的一部分步骤交由子类来实现,可以使算法更容易扩展和修改,使得系统更具灵活性和可维护性。
-
符合开闭原则:模板方法模式通过将变化的部分延迟到子类中来实现算法的扩展和修改,同时保持算法的整体结构不变,符合开闭原则。
模板方法模式的缺点包括:
-
抽象类和具体子类之间的耦合度较高,一旦抽象类发生修改,所有的子类都需要进行相应的修改。
-
可能会导致代码的复杂性增加,特别是在存在多个变化的步骤时,需要设计好抽象类和具体子类之间的交互关系,避免出现代码混乱和难以维护的情况。
模板方法模式的实现需要抽象类和具体子类的参与,一般包括以下几个步骤:
-
定义抽象类:定义一个抽象类作为算法的骨架,该抽象类中包含了算法的核心部分以及一些抽象方法,抽象方法表示算法中需要子类实现的具体步骤。
-
实现具体子类:根据抽象类定义具体的子类,子类中实现了抽象方法,以完成算法的具体步骤。子类也可以实现一些钩子方法(Hook Method)以影响算法的执行。
-
定义具体方法:抽象类中还可以包含一些具体方法,这些具体方法可以提供算法的默认实现,但也可以被具体子类覆盖。
下面是一个简单的示例代码,实现了一个冲泡咖啡的模板方法模式:
# 抽象类,定义算法的骨架
class CoffeeMaker:
def prepare(self):
self.boil_water()
self.brew()
self.pour_in_cup()
if self.customer_wants_condiments():
self.add_condiments()
def boil_water(self):
print("Boiling water")
def pour_in_cup(self):
print("Pouring into cup")
# 抽象方法,需要子类实现
def brew(self):
pass
# 钩子方法,影响算法的执行
def customer_wants_condiments(self):
return True
# 具体方法,提供默认实现
def add_condiments(self):
print("Adding sugar and milk")
# 具体子类,实现抽象方法和钩子方法
class Coffee(CoffeeMaker):
def brew(self):
print("Brewing coffee")
def customer_wants_condiments(self):
answer = input("Would you like sugar and milk with your coffee? (y/n)")
return answer.lower().startswith('y')
# 使用具体子类冲泡咖啡
if __name__ == '__main__':
coffee = Coffee()
coffee.prepare()
代码解释:
- 在这个示例中,
CoffeeMaker类是一个抽象类,其中包含了 prepare 方法作为算法的骨架,以及 boil_water、brew、pour_in_cup、customer_wants_condiments 和 add_condiments 方法。 - 其中,brew 方法为抽象方法,需要具体子类实现,而 customer_wants_condiments 方法为钩子方法,影响算法的执行。
Coffee类继承自CoffeeMaker类,并实现了 brew 和 customer_wants_condiments 方法,完成了算法的具体步骤。- 最后,通过 coffee.prepare() 方法调用算法的骨架,完成了冲泡咖啡的操作。
11、访问者模式(Visitor)
访问者模式(Visitor)是一种行为型设计模式,它可以将算法与其所作用的对象分离开来。这种模式允许你在不改变现有对象结构的情况下向对象结构中添加新的行为。
实现思路:
- 访问者模式的核心思想是:将算法封装到访问者对象中,然后将访问者对象传递给对象结构中的元素,以便这些元素可以调用访问者对象中的算法。
- 访问者对象可以通过访问元素中的数据和操作来实现算法,从而避免了对元素结构的直接访问。
访问者模式通常由以下几个角色组成:
- 访问者(Visitor):定义了用于访问元素的方法,这些方法通常以不同的重载形式出现,以便针对不同类型的元素采取不同的行为。
- 具体访问者(ConcreteVisitor):实现了访问者接口,提供了算法的具体实现。
- 元素(Element):定义了用于接受访问者的方法,这些方法通常以 accept() 的形式出现,以便元素可以将自己作为参数传递给访问者对象。
- 具体元素(ConcreteElement):实现了元素接口,提供了具体的数据和操作,同时也提供了接受访问者的方法。
- 对象结构(Object Structure):定义了元素的集合,可以提供一些方法以便访问者能够遍历整个集合。
访问者模式的优缺点包括:
- 可以将算法与其所作用的对象分离开来,避免了对元素结构的直接访问。
在访问者中可以实现对元素数据和操作的访问和处理,从而可以方便地扩展新的操作和处理逻辑。 - 可以方便地实现元素结构的复杂算法,而不需要修改元素结构本身。
- 访问者模式的缺点是,它可能会导致访问者对象的复杂性增加。此外,它也可能会导致元素结构的扩展性变得比较差,因为每当添加一个新的元素类型时,都需要修改所有的访问者对象。
下面是一个简单的访问者模式的 Python 实现:
from abc import ABC, abstractmethod
# 抽象元素类
class Element(ABC):
@abstractmethod
def accept(self, visitor):
pass
# 具体元素类A
class ElementA(Element):
def __init__(self, value):
self.value = value
def accept(self, visitor):
visitor.visit_element_a(self)
# 具体元素类B
class ElementB(Element):
def __init__(self, value):
self.value = value
def accept(self, visitor):
visitor.visit_element_b(self)
# 抽象访问者类
class Visitor(ABC):
@abstractmethod
def visit_element_a(self, element_a):
pass
@abstractmethod
def visit_element_b(self, element_b):
pass
# 具体访问者类A
class VisitorA(Visitor):
def visit_element_a(self, element_a):
print("VisitorA is visiting ElementA, value = ", element_a.value)
def visit_element_b(self, element_b):
print("VisitorA is visiting ElementB, value = ", element_b.value)
# 具体访问者类B
class VisitorB(Visitor):
def visit_element_a(self, element_a):
print("VisitorB is visiting ElementA, value = ", element_a.value)
def visit_element_b(self, element_b):
print("VisitorB is visiting ElementB, value = ", element_b.value)
# 对象结构类
class ObjectStructure:
def __init__(self):
self.elements = []
def attach(self, element):
self.elements.append(element)
def detach(self, element):
self.elements.remove(element)
def accept(self, visitor):
for element in self.elements:
element.accept(visitor)
# 测试
if __name__ == "__main__":
object_structure = ObjectStructure()
element_a = ElementA("A")
element_b = ElementB("B")
object_structure.attach(element_a)
object_structure.attach(element_b)
visitor_a = VisitorA()
visitor_b = VisitorB()
object_structure.accept(visitor_a)
object_structure.accept(visitor_b)
代码解释:
-
以上代码中,我们首先定义了抽象元素类 Element,其中定义了一个 accept 方法,该方法接受一个访问者对象作为参数,并调用访问者对象的访问方法。然后,我们定义了两个具体元素类 ElementA 和 ElementB,它们分别实现了 accept 方法。
-
接着,我们定义了抽象访问者类 Visitor,其中定义了两个访问方法 visit_element_a 和 visit_element_b,这两个方法分别用于访问具体的元素类。然后,我们定义了两个具体访问者类 VisitorA 和 VisitorB,它们分别实现了 visit_element_a 和 visit_element_b 方法。
-
最后,我们定义了一个对象结构类 ObjectStructure,它包含了多个元素对象,并提供了 attach、detach 和 accept 方法,其中 accept 方法接受一个访问者对象作为参数,并调用元素对象的 accept 方法。在测试代码中,我们创建了一个对象结构,向其中添加了两个具体元素对象,并创建了两个具体访问者对象。然后,我们先使用 VisitorA 对象访问对象结构中的元素对象,再使用 VisitorB 对象访问对象结构中的元素对象。
-
这样,访问者模式的基本结构就完成了。我们可以通过定义不同的具体访问者类来实现不同的操作,而不需要修改元素类。这样,访问者模式可以提高程序的灵活性和可扩展性。
23种设计模式介绍(Python版本示例讲解)讲解就先到这里,有疑问的小伙伴欢迎给我留言哦,也可关注我的公众号【大数据与云原生技术分享】进行深入交流IT技术~