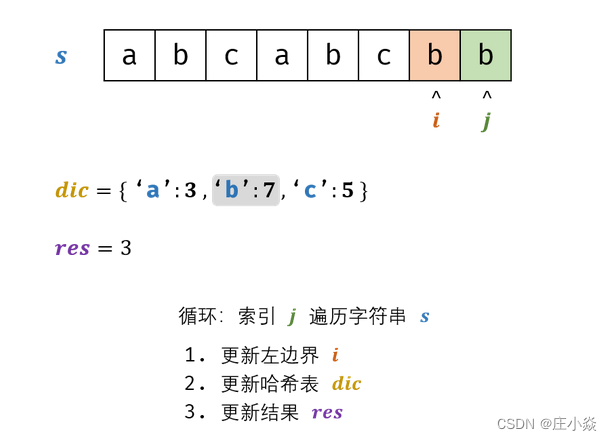
机器学习可分为两大类,分别为监督学习与非监督学习
监督学习
监督学习是机器学习的类型,其中机器使用“标记好”的训练数据进行训练,并基于该数据,机器预测输出。标记的数据意味着一些输入数据已经用正确的输出标记。
在监督学习中,提供给机器的训练数据充当监督者,教导机器正确预测输出。它应用了与学生在老师的监督下学习相同的概念。
监督学习是向机器学习模型提供输入数据和正确输出数据的过程。监督学习算法的目的是找到一个映射函数来映射输入变量(x)和输出变量(y)。
在现实世界中,监督学习可用于风险评估、图像分类、欺诈检测、垃圾邮件过滤等
非监督学习
在上一个主题中,我们学习了监督机器学习,其中模型在训练数据的监督下使用标记数据进行训练。但是在很多情况下,我们没有标记数据,需要从给定的数据集中找到隐藏的模式。因此,要解决机器学习中的此类案例,我们需要无监督学习技术。
监督学习也包括线性回归学习
线性回归
回归分析中,变量与因变量存在线性关系
回归分析:根据数据,确定两种或两种以上变量间相互依赖的定量关系。
y=f(x1,x2)
回归:变量数(一元回归,多元回归(f(x1,x2)))
函数关系(线性回归,ax+b) (非线性回归,ax^2+b)
scikit-learn:机器学习应用而发展的一款开源框架,可实现数据预处理,分类,回归,降维
机器学习相关函数的使用
数据读取
import pandas as pd
data=pd.read_csv(r'C:\Users\yangh\Desktop\test.csv')
print(type(data))
print(data)
坐标数据读取
x=data.loc[:,'x']
print(x)
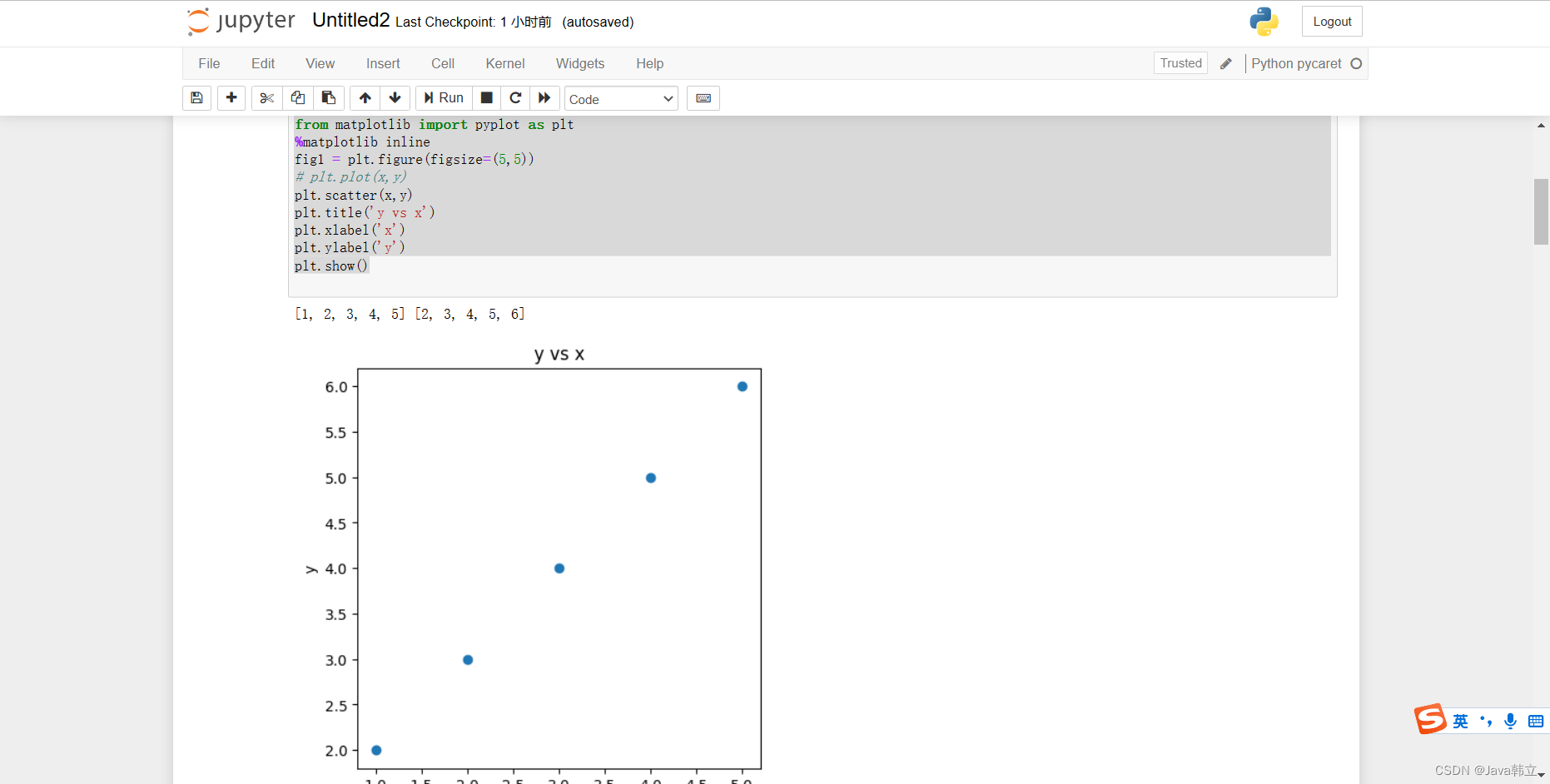
可视化
x=[1,2,3,4,5]
y=[2,3,4,5,6]
print(x,y)
from matplotlib import pyplot as plt
%matplotlib inline
fig1 = plt.figure(figsize=(5,5))
# plt.plot(x,y)
plt.scatter(x,y)
plt.title('y vs x')
plt.xlabel('x')
plt.ylabel('y')
plt.show()