上一章——多分类问题和多标签分类问题
文章目录
- 算法诊断
- 模型评估
- 交叉验证测试
算法诊断

如果你为问题拟合了一个假设函数,我们应当如何判断假设函数是否适当拟合了?我们可以通过观察代价函数的图像,当代价函数达到最低点的时候,此时的拟合状态是最好的,因此我们才需要对其进行梯度下降。
上图的代价函数J是经过了正则化的,假设当前代价函数J的拟合误差较大,如何来减小误差?在过拟合与正则化这一章中,列举了几种方法,在上图中也写出了:
- 增加训练样本
- 尝试减少特征集
- 增加一些额外的特征
- 添加多项式特征
- 试着改变正则化系数λ
有的时候我们的机器学习算法并不能达到想要的效果,那么也许是哪里出问题了,解决问题并不难,关键在于找到问题出在哪里,因此我们需要对神经网络进行诊断。
诊断是一种测试,我们可以运行它来深入算法,了解算法中那些是有效的,那些是无效的,从而提升算法的性能。因此学习算法诊断是必要的,不过在此之前,我们看看应当如何评估我们的算法。
模型评估
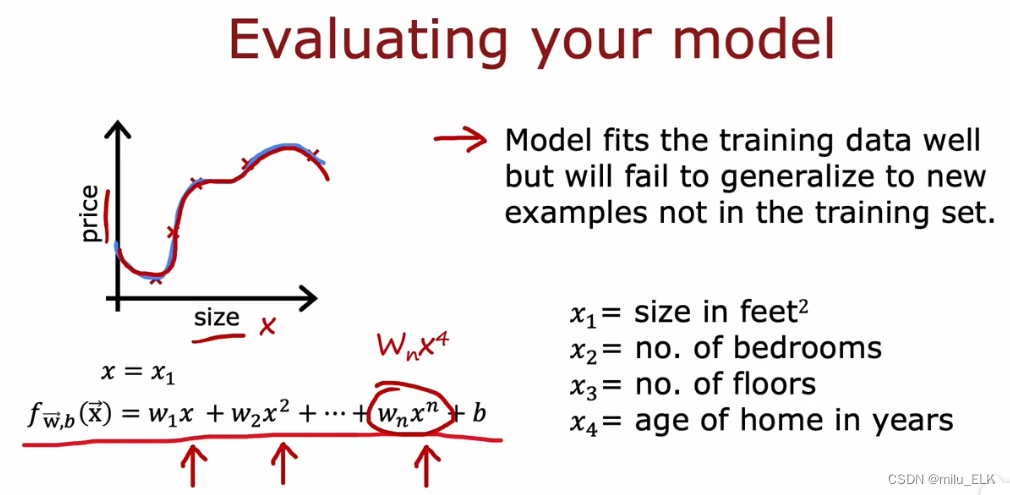
如图是一个四阶多项式的拟合函数,通过观察图像我们知道这个函数的拟合效果很好,但是好到过头了,我们也说过这种过度拟合的状态称为过拟合。如果增加新的数据,这个拟合函数显然是不具有泛化性的,我们认为这样的过拟合的函数不能推广到新的数据集中的数据。并且我们给出了四个特征,而上图中用于函数拟合的只使用了size这一特征,显然只用一个特征拟合也是不适当的。然而哪怕我们想要使用四个特征绘制函数,身为三微生物的我们也无法画出四维图像。
因此上述模型存在两个问题:
- 如何保证拟合其他数据?
- 对于三个以上的特征,我们无法通过图像判断性能,能否更系统地判断模型的性能?
 我们的方法是:将数据集划分为两个子集,其中一个称为训练集(training set),我们取70%,另一个称为测试集,取30%。
我们的方法是:将数据集划分为两个子集,其中一个称为训练集(training set),我们取70%,另一个称为测试集,取30%。
我们用
(
x
,
y
)
(x,y)
(x,y)来表示测试样例,其中
(
x
m
,
y
m
)
(x^m,y^m)
(xm,ym)代表训练集第m项测试样例,
(
x
t
e
s
t
m
,
y
t
e
s
t
m
)
(x^m_{test},y^m_{test})
(xtestm,ytestm)来表示测试集第m项测试样例。

接下来,我们可以通过式子①最小化代价函数来找到拟合参数 w , b w,b w,b,因为假设函数是包括了多个特征的多项式,因此我们会采取正则化来减小拟合误差。
式子②称为测试误差,通过式子①我们找到了拟合参数 w , b w,b w,b,现在将其带入到假设函数,并用式子②算出测试集的测试误差,我们并不是在拟合函数,而是计算测试误差的大小,因此该式子是不用正则化的,最后计算的结果即为测试误差。
式子③与式子②同理。注意,式子① J ( w , b ) J(w,b) J(w,b)是代价函数,而式子②③中的 J t e s t ( w , b ) J_{test}(w,b) Jtest(w,b)和 J t r a i n ( w , b ) J_{train}(w,b) Jtrain(w,b),是计算误差的函数,从本质上来讲误差函数(损失函数)和代价函数是一个东西,但是它们的功能并不相同,理解概念并注意区分。
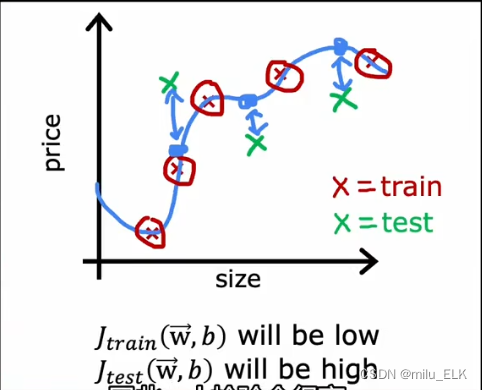
现在让我们看看拟合图像,如果数据点如上图所示(红点代表训练集数据,绿点代表测试集数据),我们会发现一个问题:
J t r a i n ( w , b ) J_{train}(w,b) Jtrain(w,b)较低,代表了训练误差低,这是必然的,因为我们是基于训练集的数据来最小化代价函数进行参数选择的,因此拟合出来的函数的训练误差一定是较小的。(与训练集的误差在于正则化)
然而如果测试集的数据点如图所示,就会发现 J t r a i n ( w , b ) J_{train}(w,b) Jtrain(w,b)较高,这代表着测试误差较大,这意味着对于测试集,这个拟合函数的拟合状态并不是很好,因此我们可以认为这个函数并不具有泛化性,这个模型是有问题的。

那么分类问题也是同样的道理,把我们使用分类问题的代价函数(损失函数)来进行计算,
不过在分类问题中,我们对于误差的定义有点不同

在二分问题里,通常我们将0.5作为阈值,当>阈值分类为1,<阈值分类为0,我们将代价函数的预测值称为
y
^
\hat y
y^,分类问题中的误差,指的是对于同一个输入样例,有多少个预测值
y
^
\hat y
y^与实际值
y
y
y不同,这个误差指的是这些被错误分类的
y
^
\hat y
y^的数量比例。
通过训练集和测试集,你可以系统地对模型误差进行评估,从而创建更好的模型。
交叉验证测试

那么假如,我们按照刚才的模型评估的步骤来建立一个拟合函数,我们首先通过训练集的数据的正则化最小化代价函数,找到了合适的
w
和
b
w和b
w和b,我们将当前的拟合出来的多次项的项数记为
d
=
n
d=n
d=n,把对应项数的参数记为
w
<
n
>
,
b
<
n
>
w^{<n>},b^{<n>}
w<n>,b<n>,最后计算的测试误差记为
J
t
e
s
t
(
w
<
n
>
,
b
<
n
>
)
J_{test}(w^{<n>},b^{<n>})
Jtest(w<n>,b<n>),现在我们要做的就是找到最小的测试误差
J
t
e
s
t
J_{test}
Jtest所对应的
w
,
b
和
d
w,b和d
w,b和d,现在假设找到了最小测试误差是在当
d
=
5
d=5
d=5时,我们是否可以认为现在选择的模型是最适宜的?
实际上,答案是否定的,因为我们的估计流程依然存在着问题,导致了 J t e s t J_{test} Jtest很可能乐观估计了泛化误差,也就是说虽然我们计算出来的测试误差与实际的泛化误差相比可能偏小了,实际误差将会比计算结果要大。原因在于多项式的次数d,因为d是在测试集上确定的,用测试集确定的d来检验测试集的误差,那必然能得到一个较小的误差,就像我给我自己监考,这显然是不公平的。

我们解决问题的方法是:将数据集分为三个子集,训练集60%,交叉验证集20%,测试集20%。其中新加入的交叉验证集(cross validation set)的作用是用于检查不同验证集合的准确性,你也可以叫他验证集(validation set)或者开发集(development set 或dev set)。
 w
,
b
w,b
w,b还是用最小化代价函数计算,现在我们要计算的误差总共有三个,它们的公式是一样的,交叉验证集的误差被称为验证误差或者开发误差。
w
,
b
w,b
w,b还是用最小化代价函数计算,现在我们要计算的误差总共有三个,它们的公式是一样的,交叉验证集的误差被称为验证误差或者开发误差。

现在再让我们回到之前的步骤,我们首先通过训练集的数据的正则化最小化代价函数计算不同次数的 w , b w,b w,b,我们带入验证误差来计算对应次数的 J c v J_{cv} Jcv,假设现在我们找到了 d = 4 d=4 d=4时的验证误差最小,那么我们就可以用 d , w < 4 > , b < 4 > d,w^{<4>},b^{<4>} d,w<4>,b<4>去计算测试误差 J t e s t J_{test} Jtest,因为 w , b w,b w,b是训练集确定的, d d d是交叉验证集确定的,因此没有一个参数与测试集有关,这样就保证我们的误差计算结果相对公平。
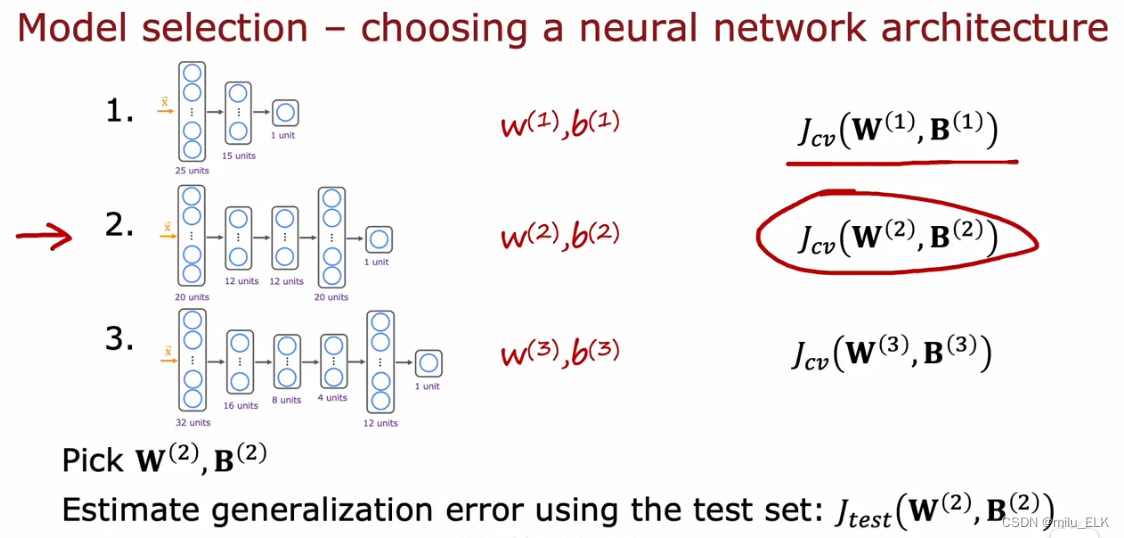 在整个神经网络模型的选择上我们也是这样测试的,例如这三个模型的隐藏层,我们计算得到二号模型的参数对应的验证误差较小,那么我们就可以使用第二个神经网络训练的参数,如果想要得到泛化误差的估计值,我们就可以用这个参数带入计算测试误差
J
t
e
s
t
J_{test}
Jtest来判断神经网络的性能,使用交叉验证集来选择模型也是目前最佳的决定方法。不过想要作出决定只需要训练集和交叉验证集来确定参数即可,在确定参数之后我们可以在测试集进行评估。这种方法可以确保测试集的公平估计,而非对泛化误差的乐观估计。一个重要原则就是:在未决定模型之前,千万不要使用测试集的数据,来保证估计的公平性。
在整个神经网络模型的选择上我们也是这样测试的,例如这三个模型的隐藏层,我们计算得到二号模型的参数对应的验证误差较小,那么我们就可以使用第二个神经网络训练的参数,如果想要得到泛化误差的估计值,我们就可以用这个参数带入计算测试误差
J
t
e
s
t
J_{test}
Jtest来判断神经网络的性能,使用交叉验证集来选择模型也是目前最佳的决定方法。不过想要作出决定只需要训练集和交叉验证集来确定参数即可,在确定参数之后我们可以在测试集进行评估。这种方法可以确保测试集的公平估计,而非对泛化误差的乐观估计。一个重要原则就是:在未决定模型之前,千万不要使用测试集的数据,来保证估计的公平性。