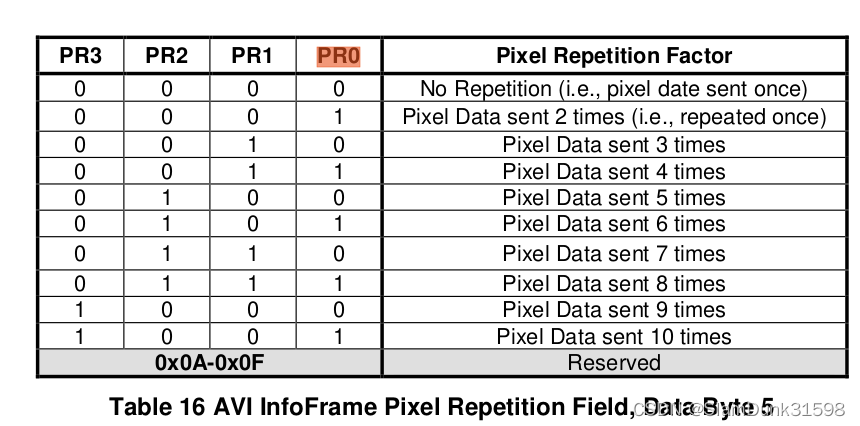
在开始这部分内容之前需要先说一下复制功能,因为这是Redis实现主从数据同步的实现方式。
复制功能
如果存在两台服务器的话,我们可以使用redis的复制功能,让一台服务器去同步另一台服务器的数据。现在我启动了两台redis服务器,一个端口是6379,一个端口是6380。
我们在6380的客户端执行命令: slaveof 127.0.0.1 6379
让80服务器去复制79的数据:在6380这台服务器去复制6379的数据(后面将6379称为主服务器,6380称为从服务器);
127.0.0.1:6380> slaveof 127.0.0.1 6379
OK
=============在6379新增一条数据========
127.0.0.1:6379> set hello 6380
OK
=============在6380取这条数据========
127.0.0.1:6380> get hello
"6380"复制功能的实现:
在以前的Redis版本中复制功能主要是通过同步和命令传播两个动作来完成的。
同步操作就是从服务器向主服务器发送SYNC命令,主服务器收到SYNC命令后执行BGSAVE命令(前面持久化文章讲过),就会在后台生成一个RDB文件,然后使用一个缓冲区记录从现在开始执行所有的些命令,执行完BGSAVE命令之后主服务器就把RDB文件发个从服务器,然后将缓冲区命令发送给从服务器,从服务器收到之后就会执行这个文件的命令,同步状态;
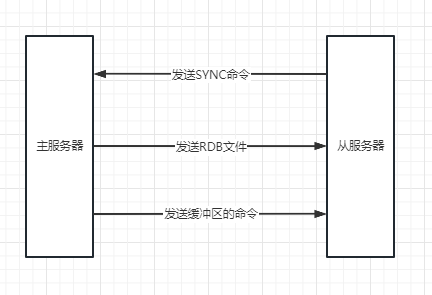
在执行完同步操作之后,两个服务器的状态基本一致了,但是在这过程中可能会存在数据不一致的情况,比如说它们刚刚执行完同步,那么这时候主服务器删除了某个键,这时候两个服务器的状态就不一致了;为了解决这个问题主服务器就需要对从服务器执行 命令传播 操作,主服务器会将自己的些命令(就是造成数据不一致的那条命令),发送给从服务器执行,这样两个服务器的命令就会一致了。
刚刚讲的是以前老版Redis的复制实现,这样的复制方式存在一定的缺陷,比如说主服务器在命令传播的过程中突然断线了,从服务器去重新同步主服务器的状态效率是非常低的,还有就是SYNC命令是一个非常消耗资源的操作。
在Redis2.8版本之后,开始使用PSYNC命令代替原来的SYNC命令,这个命令可以实现完全同步和部分重同步,就解决了SYNC命令的断线后重复复制的低效率问题;部分重同步就是断线后重连只需要同步它们存在差异的数据,不用全部去重新同步。
2.Sentinel(哨兵模式)
哨兵模式是Redis高可用性的解决方案,我们前面讲的主从复制存在一个问题就是当主服务器挂了之后需要人为的干预才能恢复Redis的正常使用,Sentinel系统可以监视我们的这些主从服务器,当主服务器下线的时候,Sentinel系统会从主服务器下的某个服务器升级升级为新的主服务器,然后会由新的服务器来提供服务。

搭建一个Sentinel系统:
当我们安装了一个redis服务器后,在根目录下有一个sentinel.conf文件,编辑这个文件,可以看到这么一行配置:
sentinel monitor mymaster 127.0.0.1 6379 1
sentinel auth-pass mymaster pwd654321 #如果有密码就要输入密码这就是配置我们监听的服务器,最后面这个1的意思是 确认主节点下线的sentinel数量,1表示只要有一台sentinel判断他下线了,就可以确认他下线了。
在src目录下有一个文件:

就是启动哨兵模式:
./redis-sentinel ../sentinel.conf 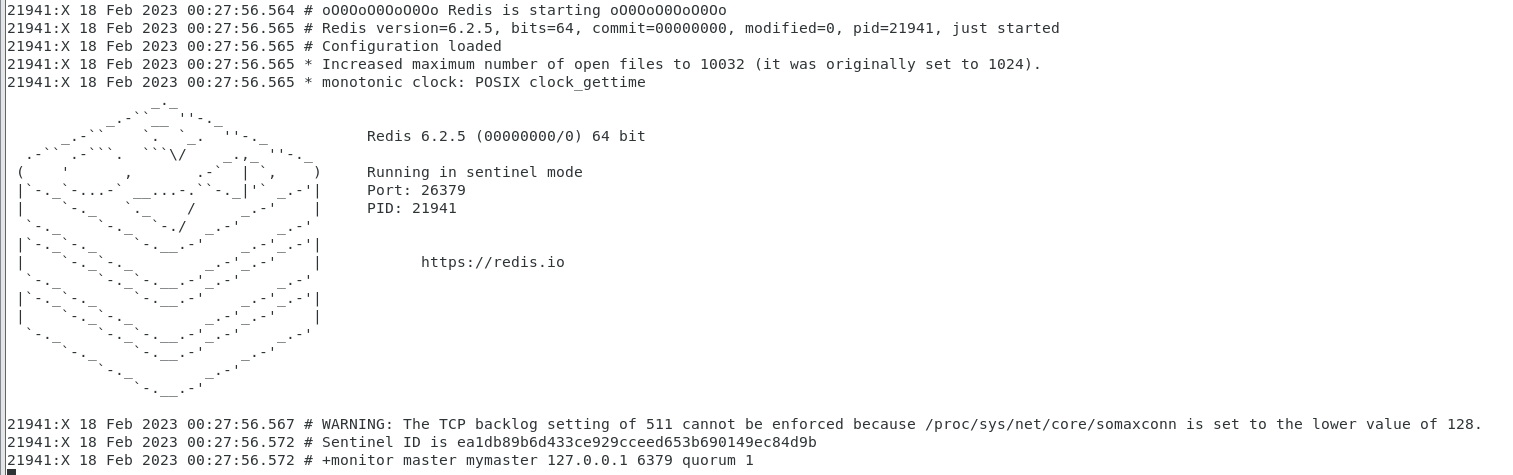
测试:
端口为6379是我搭建的主服务器,端口为6380是我搭建的从服务器,这时候我们把主服务器关闭。

登录从服务器看角色:

可以看到它已经是master了,说明sentinel生效了。
主服务器的竞选规则:
在redis.conf 中的 replica-priority 选项来设置竞选新主节点的优先级,它的默认值是 100,它的最大值也是 100,这个值越小它的权重就越高,例如从节点 A 的 replica-priority 值为 100,从节点 B 的值为 50,从节点 C 的值为 5,那么在竞选时从节点 C 会作为新的主节点。但是当优先级相等的时候就会判断复制偏移量,偏移量大的从节点生效,如果偏移量也相等的话,那就是运行时随机生成ID较小的那个服务器被选为主服务器。
工作原理:
哨兵的工作原理是这样的,首先每个 Sentinel 会以每秒钟 1 次的频率,向已知的主服务器、从服务器和以及其他 Sentinel 实例,发送一个 PING 命令。
如果最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 所配置的值(默认 30s),那么这个实例会被 Sentinel 标记为主观下线。
如果一个主服务器被标记为主观下线,那么正在监视这个主服务器的所有 Sentinel 节点,要以每秒 1 次的频率确认 主服务器的确进入了主观下线状态。
如果有足够数量(quorum 配置值)的 Sentinel 在指定的时间范围内同意这一判断,那么这个主服务器被标记为客观下线。此时所有的 Sentinel 会按照规则协商自动选出新的主节点。
集群
Redis集群是将数据分布在不同的服务器上,来降低系统对主节点的依赖,可以提高服务器的读写性能;Redis把所有的数据分为16384个槽,每个节点都可以负责其中的一部分槽位;
Redis集群是无代理模式去中心化的运行模式,客户端发送的绝大多数命令会直接交给相关的节点运行,这样的话大部分的请求命令都无需转发,或者仅仅转发一次就可以完成请求与响应,所以集群单个节点的性能与单机Redis服务器的性能非常接近,因此当水平扩展一倍的主节点就相当于请求处理的性能也提高了一倍。
搭建Redis集群
在redis源码中提供了集群的快速搭建集群的工具,这种搭建方式比较简单比较轻量适合用来学习和做一些小测试,在正式使用中还是需要手动配置。
在redis安装根目录下,有一个utils的文件夹

我们直接执行这个文件夹下的create-cluster:
[root@localhost create-cluster]# ./create-cluster start
Starting 30001
Starting 30002
Starting 30003
Starting 30004
Starting 30005
Starting 30006接下来需要把以上创建的 6 个节点通过 create 命令组成一个集群,执行如下:
./create-cluster create 在执行的过程中会询问你是否通过把 30001、30002、30003 作为主节点,把 30004、30005、30006 作为它们的从节点,输入 yes 后会执行完成。
创建完成后就可以使用客户端连接了
[root@localhost create-cluster]# redis-cli -c -p 30001
127.0.0.1:30001> cluster nodes
5cb57688027850bfe3e4ea624b93c3ac94c85be7 127.0.0.1:30005@40005 slave d1402bfe3bc06d6b54b627570911bacd785f9fd4 0 1676725685276 2 connected
c6be86f41ce5e4dd83a8c712757882853153e487 127.0.0.1:30003@40003 master - 0 1676725685276 3 connected 10923-16383
d1402bfe3bc06d6b54b627570911bacd785f9fd4 127.0.0.1:30002@40002 master - 0 1676725685072 2 connected 5461-10922
3ddc1b69166c62a041fa55c2f52f7b4c730ad5d6 127.0.0.1:30004@40004 slave a26f8956893115813849bdcc795403f7f2a8cd35 0 1676725685276 1 connected
a26f8956893115813849bdcc795403f7f2a8cd35 127.0.0.1:30001@40001 myself,master - 0 1676725685000 1 connected 0-5460
375512950f3a13179217ab3524d8ee8ff3bbb0b0 127.0.0.1:30006@40006 slave c6be86f41ce5e4dd83a8c712757882853153e487 0 1676725685276 3 connected
127.0.0.1:30001> 可以看出 30001、30002、30003 都为主节点,30001 对应的槽位是 0~5460,30002 对应的槽位是 5461~10922,30003 对应的槽位是 10923~16383,总共有槽位 16384 个(0~16383)。
create-cluster 搭建的方式虽然速度很快,但是该方式搭建的集群主从节点数量固定以及槽位分配模式固定,并且安装在同一台服务器上,所以只能用于测试环境。
槽定位算法:
Redis集群工作的槽位是16384个,每一个主节点负责维护一部分槽以及槽所映射的键值数据,Redis集群默认会对要存储的key值使用CRC16算法进行hash得到一个整数,然后对槽位个数进行取模来得到具体槽位:slot =CRC16(key)%16383
总结
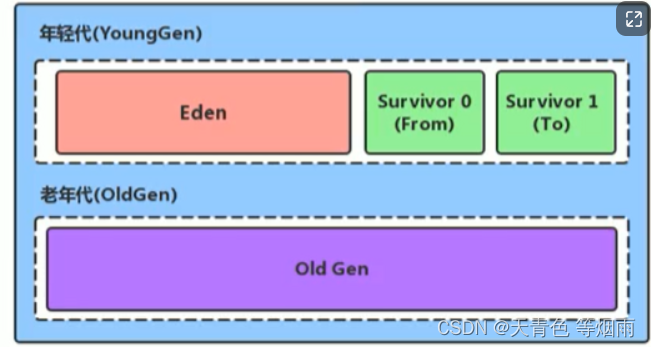
首先介绍了Redis的复制功能,然后讲了Redis的两种高可用方案哨兵模式和集群模式,之前我刚进公司实习那会,我们架构师会让我们每个月写总结嘛,具体就是我们所在项目的使用的中间件,其中就跟我说的是你要去看看我们项目中用了那些中间件,比如说用了Redis你就要看看用的什么模式,什么持久化方案、以及项目中怎么使用的等等,那个时候开始我才真正的去买书网上找资料来看,学完之后对我现在的工作帮助非常大。









![[架构之路-110]-《软考-系统架构设计师》-软件架构设计-3-架构描述语言ADL与UML](https://img-blog.csdnimg.cn/img_convert/b201118048b68b678cecb7f56f530af0.png)