目录
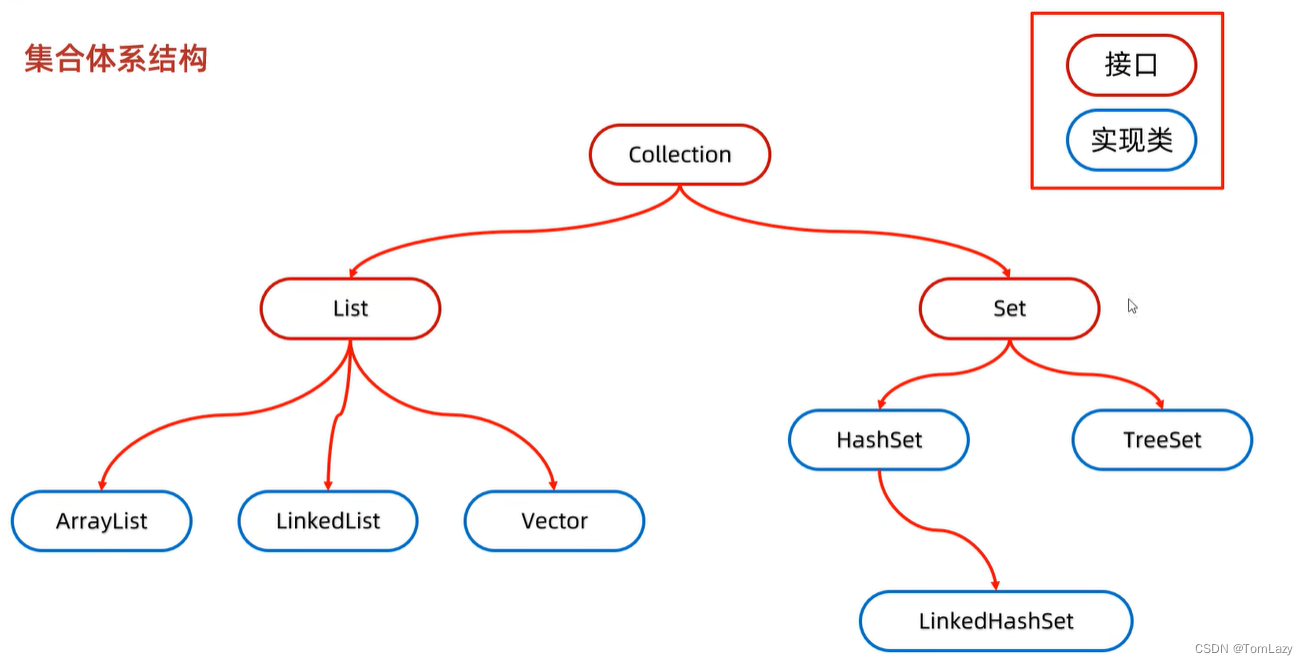
一、集合的体系结构
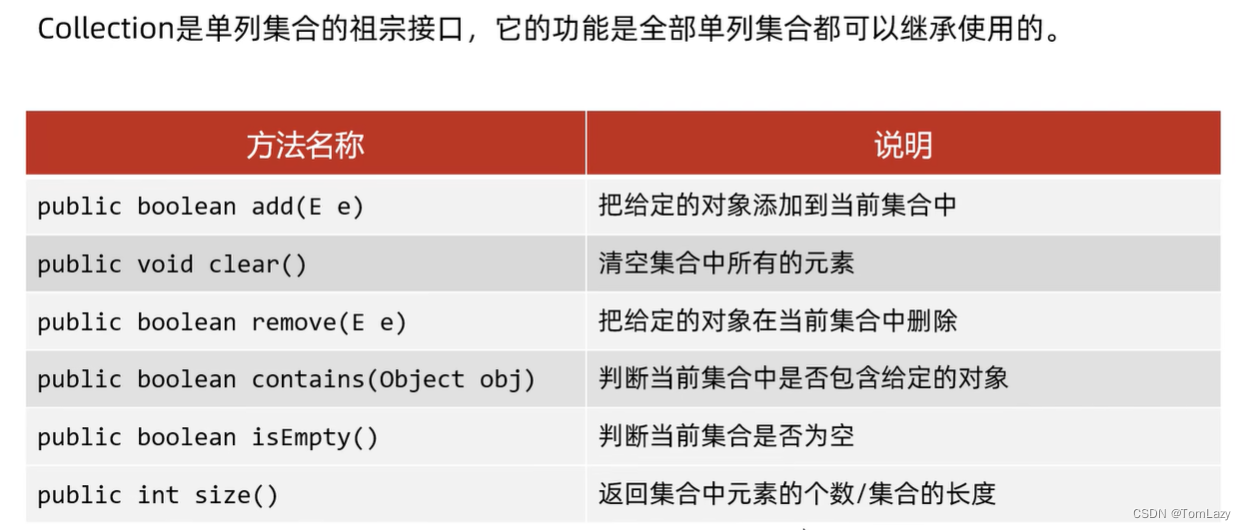
1、单列集合(Collection)
二、Collection集合
1、Collection常见方法
①、代码实现:
②、contains方法重写equals方法示例:(idea可自动重写)
2、Collection的遍历方式(3种)
①、迭代器遍历
②、增强for遍历
③、Lambda表达式遍历
3、小结
三、List集合
1、List集合特有的方法(操作索引的4个方法)
2、List集合的遍历方式(5种)
①、示例代码
②、小结
四、数据结构(常见有8种)
1、什么是数据结构呢?
2、数据结构概述
3、栈(后进先出,先进后出)
4、队列(先进先出,后进后出)
5、栈与队列小结
6、数组
7、链表(与数组相对)
小结
五、ArrayList集合
1、ArrayList集合底层原理
2、ArrayList源码分析
六、LinkedList集合
1、LinkedList特有方法
2、LinkedList源码分析
3、迭代器的底层源码
七、泛型深入
1、没有泛型时的集合如何存储数据?
2、泛型的好处
3、知识点:Java中的泛型是伪泛型
4、泛型的细节
5、泛型可以在很多地方进行定义
①、泛型类
②、泛型方法
③、泛型接口
6、泛型的继承和通配符
①、泛型的继承示例代码
②、泛型的通配符练习
7、小结
八、树(Tree)
1、集合起名的艺术
2、树的基本结构
3、二叉树
4、二叉查找树
①、添加节点
②、查找节点
③、二叉查找树的弊端
5、二叉树的遍历方式
①、前序遍历(根、左、右)
②、中序遍历(左、根、右)
③、后序遍历(左、右、根)
④、层序遍历(一层一层遍历)
⑤、小结
6、平衡二叉树
①、平衡二叉树的旋转机制
②、左旋
③、右旋
④、平衡二叉树需要旋转的四种情况(左左、左右、右右、右左)
⑤、小结
7、树的演变
8、红黑树(一种特殊的二叉查找树,而不是平衡二叉树)【★★】
①、红黑树的红黑规则
②、红黑树添加节点的规则
③、小结(能看懂即可)
九、Set系列集合
1、练习:利用Set系列的集合,添加字符串,并使用多种方式遍历
①、示例代码
②、小结
2、HashSet底层原理
①、哈希值
②、对象的哈希值特点
3、HashSet JDK8 以前的底层原理
①、HashSet完整创建过程
②、HashSet创建的细节
4、HashSet的三个问题
①、HashSet为什么存和取的顺序不一样?
②、HashSet为什么没有索引?
③、HashSet是利用什么机制保证数据去重的?
④、问题回答
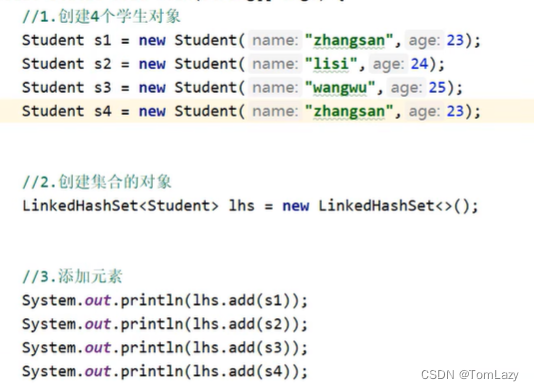
5、练习:利用HashSet集合去除重复元素
十、LinkedHashSet
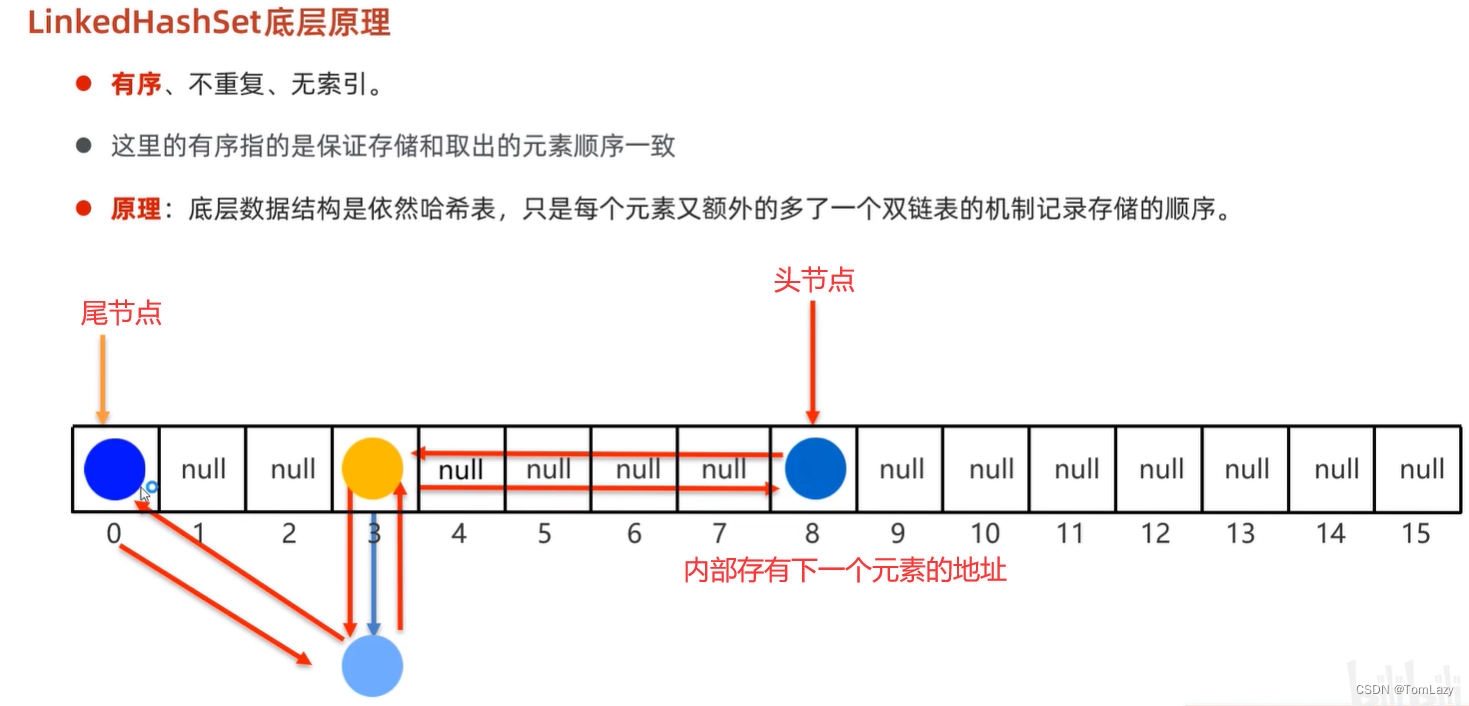
1、LinkedHashSet底层原理
①、示例代码:(LinkedHashSet可以保证数据的存储顺序)
②、小结
十一、TreeSet(自动排序)
1、TreeSet的基本应用
①、TreeSet的特点
②、练习:利用TreeSet存储整数并进行排序
2、TreeSet集合默认的规则
①、TreeSet对象排序练习题
②、示例代码理解
3、TreeSet的两种比较方式
①、方式一:JavaBean类实现Comparable接口指定比较规则
②、方式二:比较器排序,创建TreeSet对象时,传递比较器Comparator指定规则
③、扩展:TreeSet对象排序练习题
4、小结
5、Set集合源码分析
①、HashSet
②、LinkedHashSet
③、TreeSet
十二、集合的使用场景
一、集合的体系结构

1、单列集合(Collection)

二、Collection集合
1、Collection常见方法
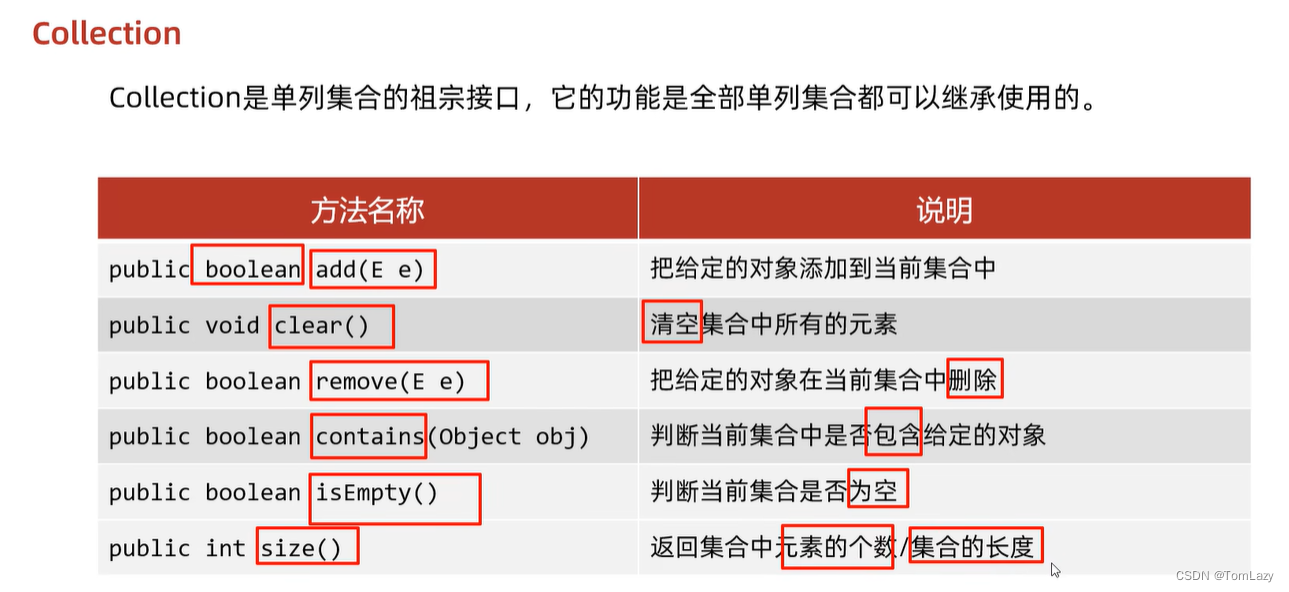
①、代码实现:

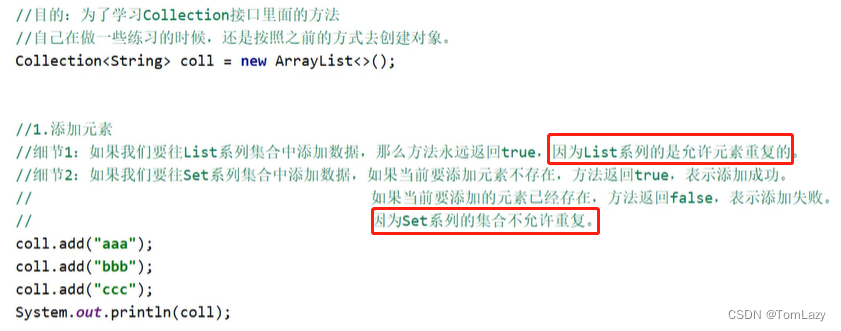

②、contains方法重写equals方法示例:(idea可自动重写)


2、Collection的遍历方式(3种)

①、迭代器遍历
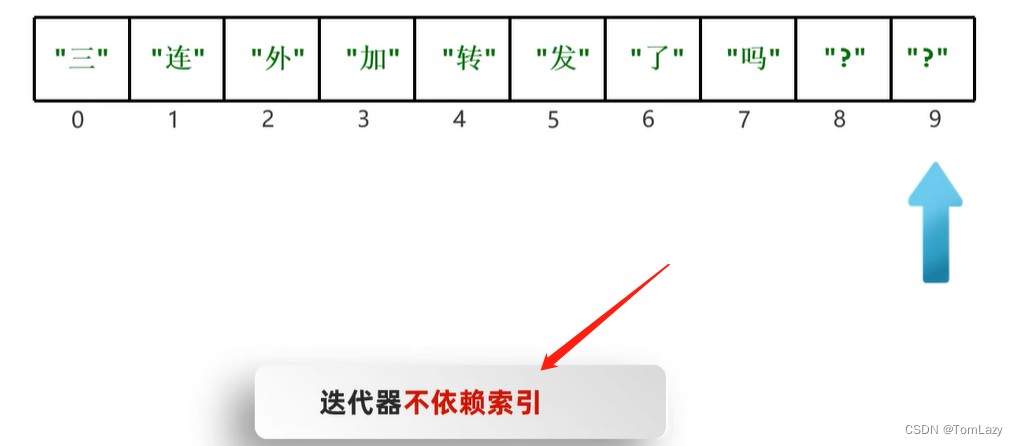

示例:

循环遍历:

示例代码:(不依赖索引,而是通过指针移动的方式)

迭代器书写的小细节:


示例代码:


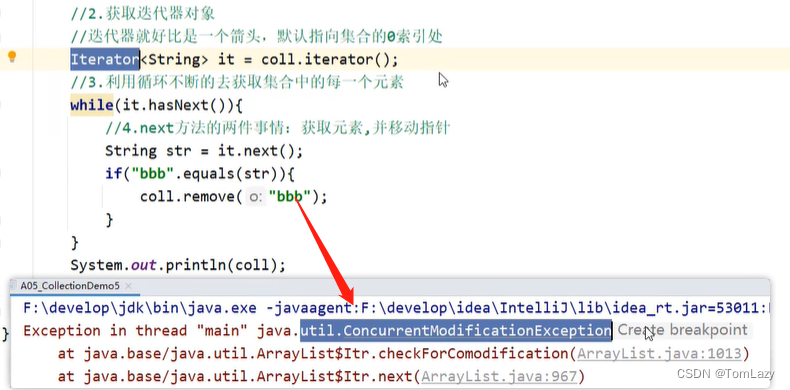
小结:

②、增强for遍历
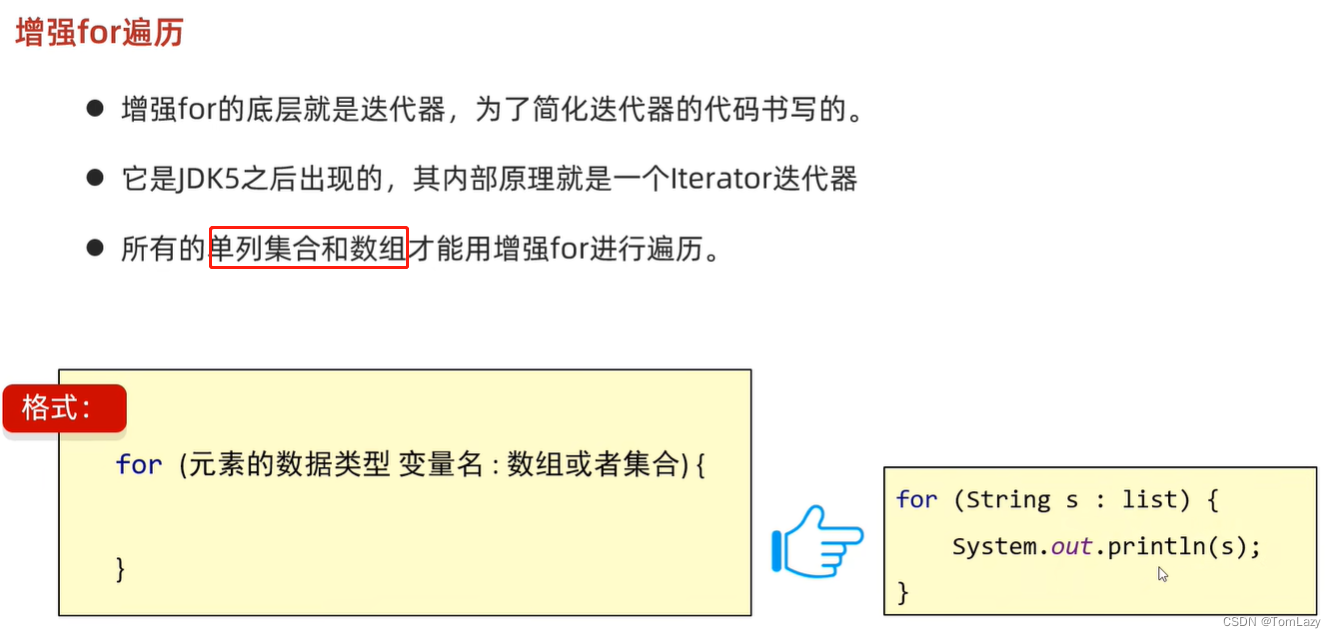
示例代码:
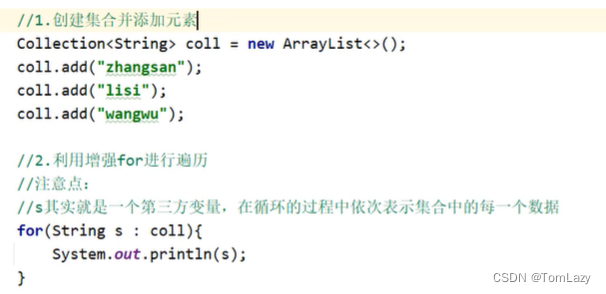
增强for的细节:

③、Lambda表达式遍历

示例代码:

Lambda表达式形式:

3、小结

三、List集合

1、List集合特有的方法(操作索引的4个方法)

示例代码:

add方法:
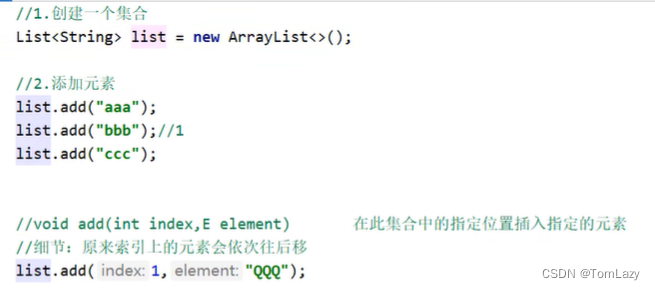
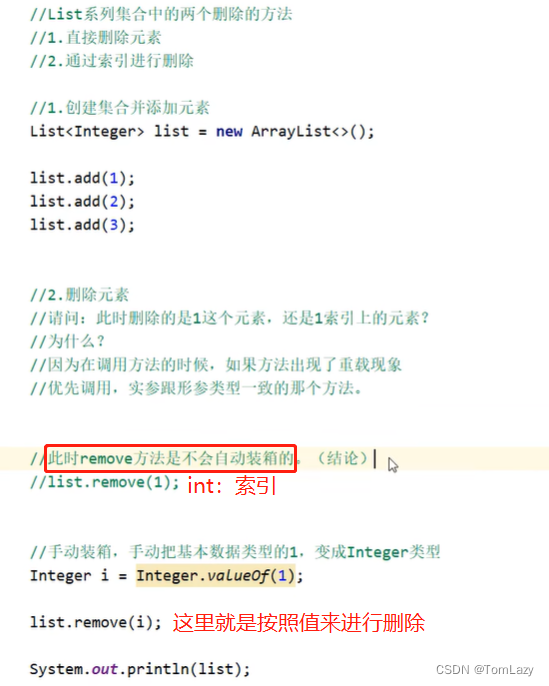
remove方法:

List删除的小细节:
set & get方法:

2、List集合的遍历方式(5种)

①、示例代码
1、迭代器遍历:
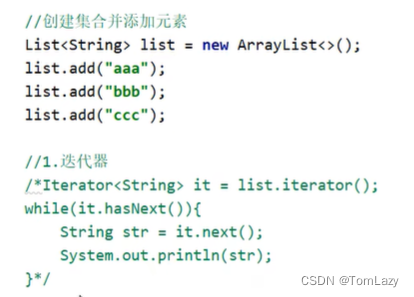
2、增强for:

3、Lambda表达式

4、普通for循环

5、列表迭代器(ListIterator,继承于Iterator)

但迭代器默认指向0索引,想要使用previous方法需要先移动到后面

②、小结

四、数据结构(常见有8种)
1、什么是数据结构呢?
数据结构就是计算机存储、组织数据的方式


2、数据结构概述


3、栈(后进先出,先进后出)

栈内存:

4、队列(先进先出,后进后出)

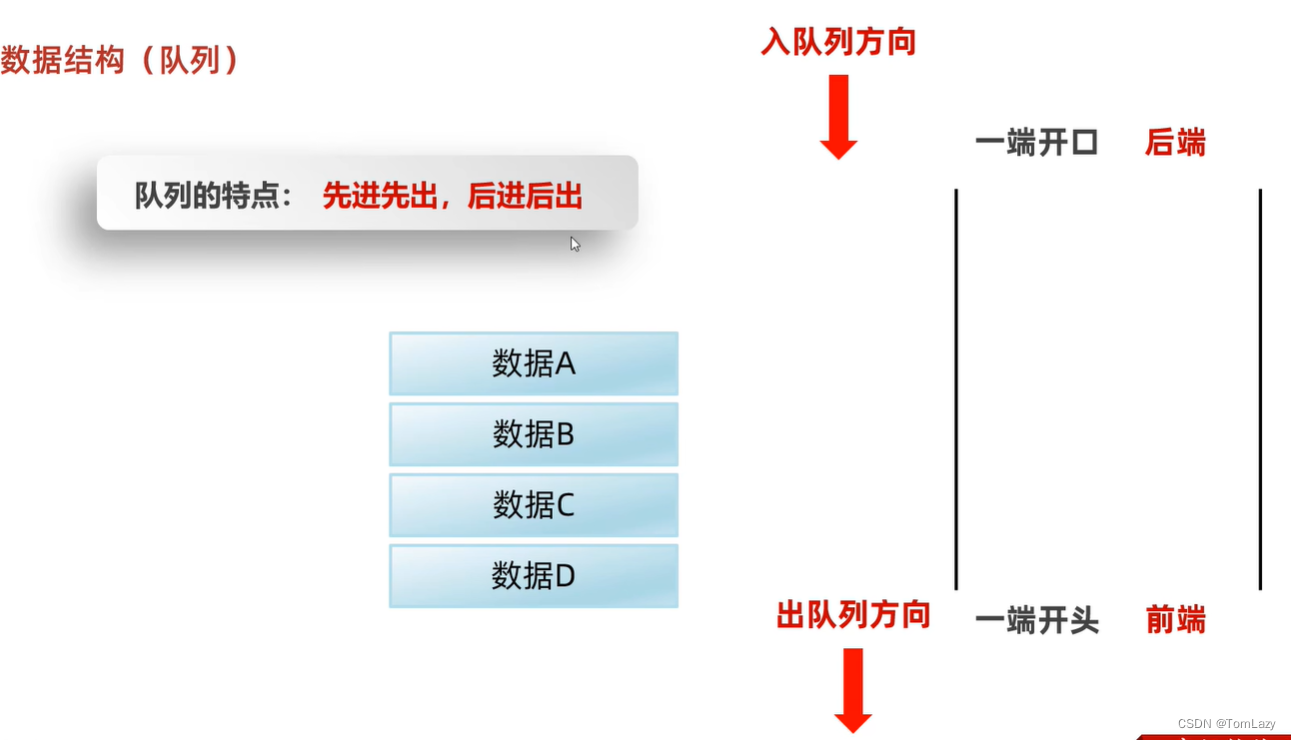
5、栈与队列小结


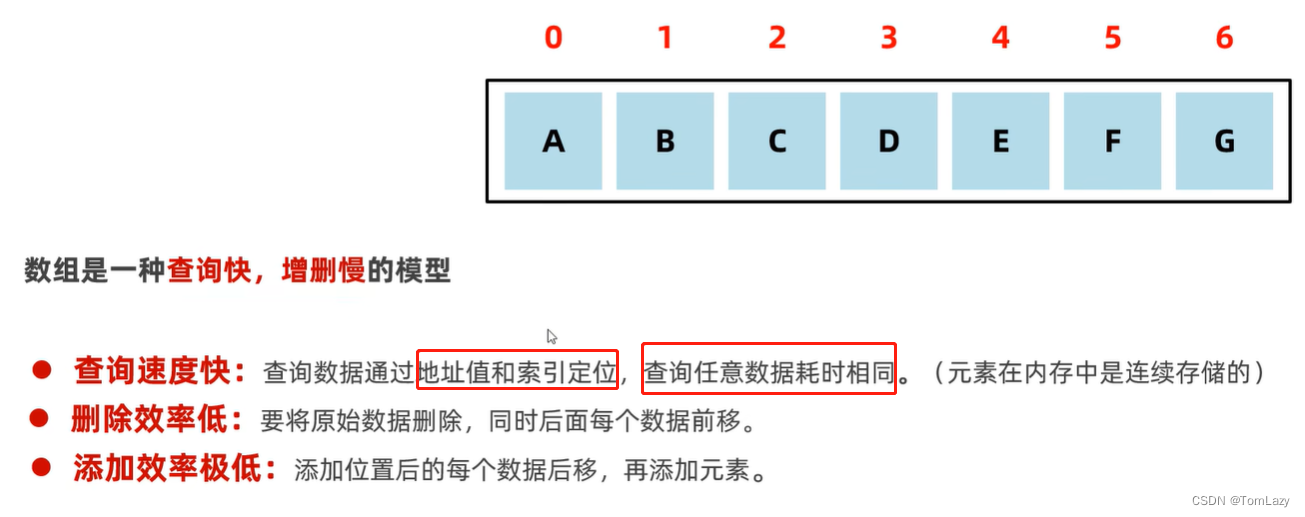
6、数组
7、链表(与数组相对)
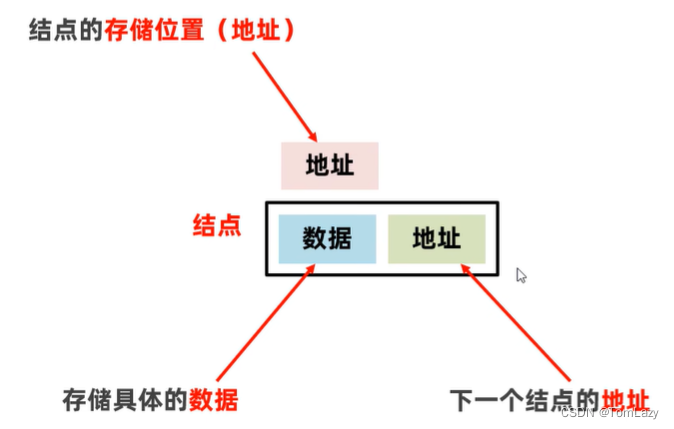
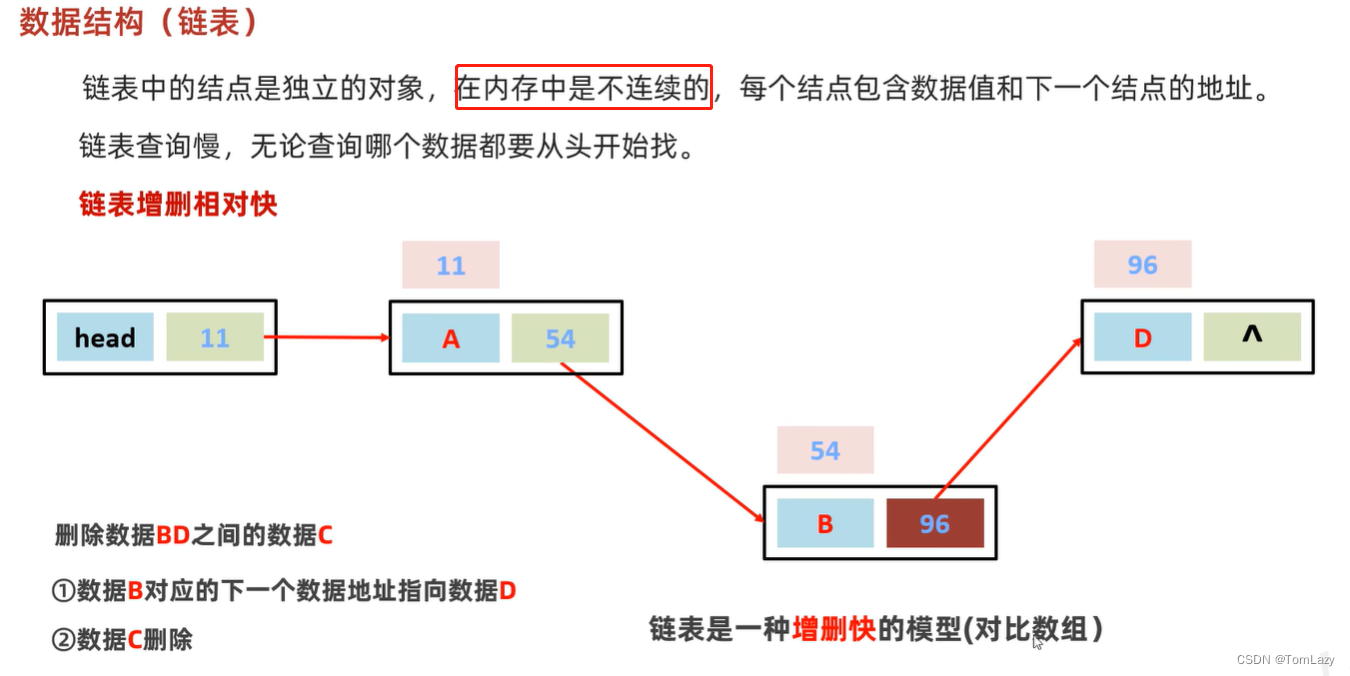
双向链表可以提高查询效率:
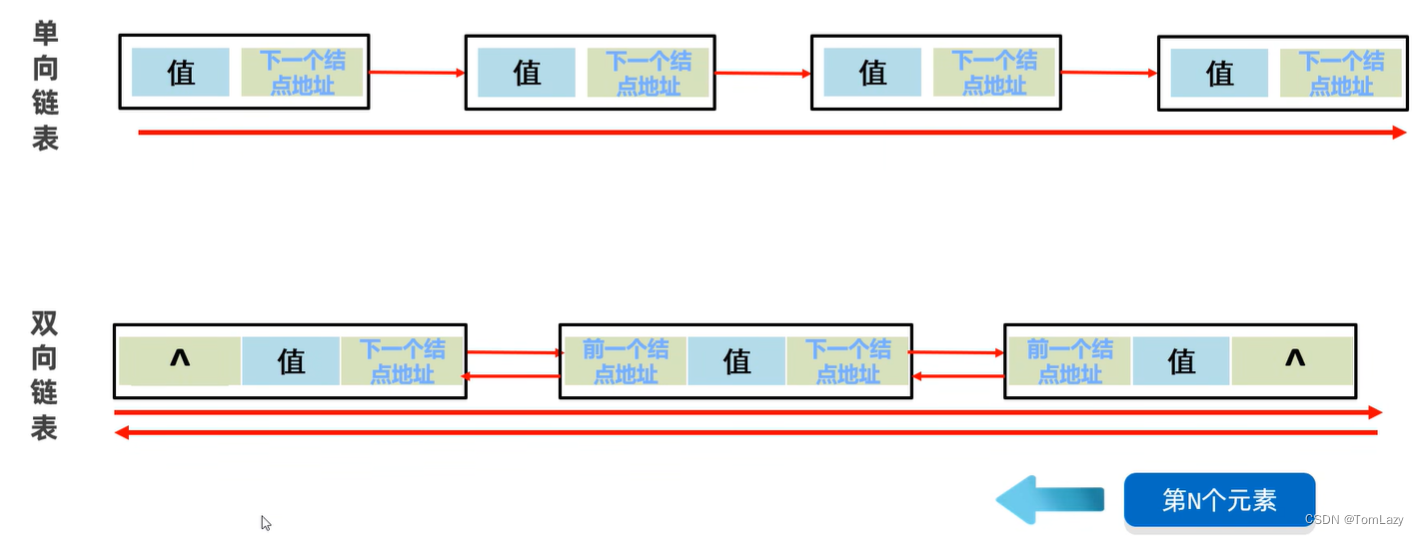
小结

五、ArrayList集合
1、ArrayList集合底层原理

2、ArrayList源码分析
idea快捷键:Alt+7:列出方法大纲
添加的数据长度不超过10:

一次添加多个,超过10,但不超过15:

六、LinkedList集合

1、LinkedList特有方法
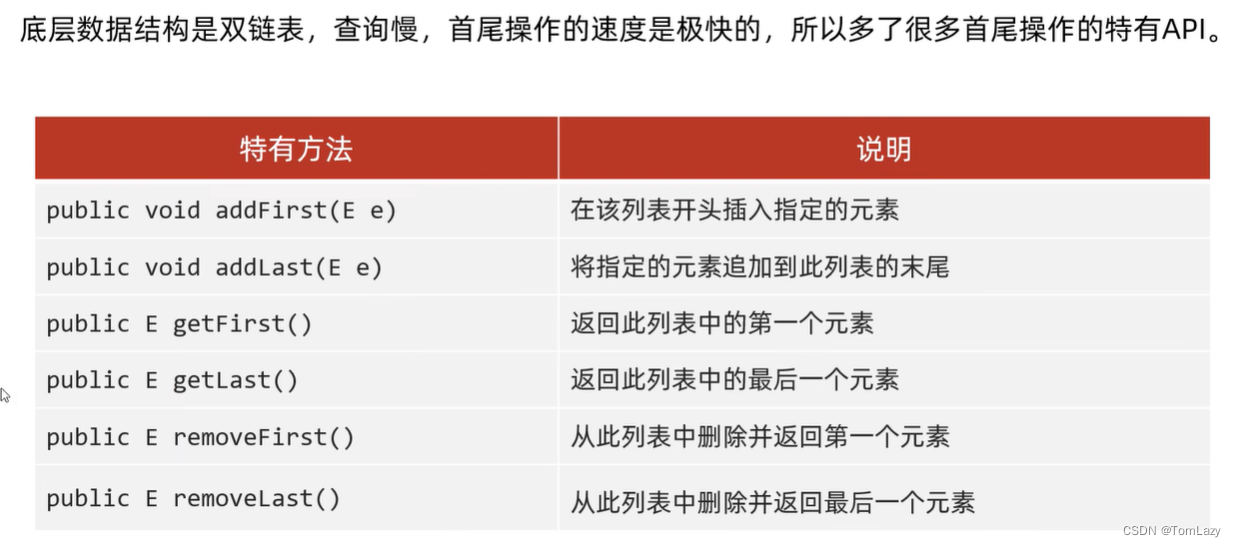
2、LinkedList源码分析
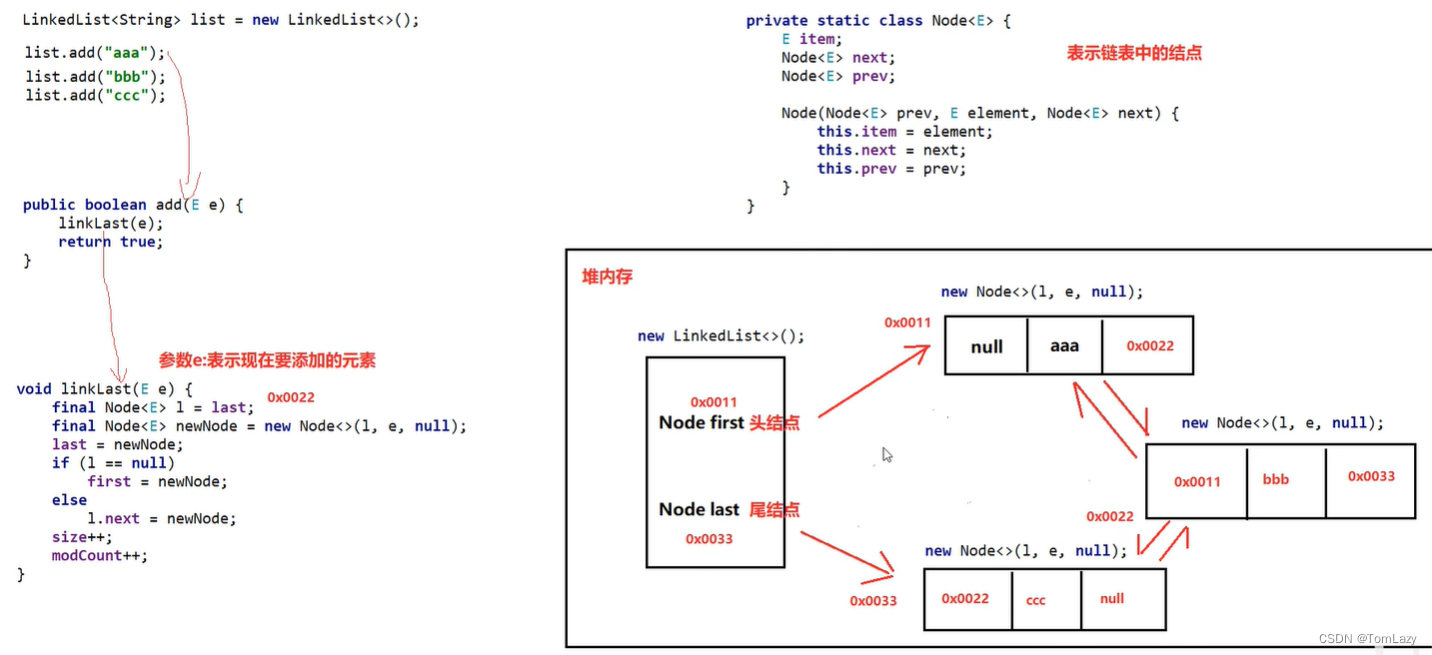
3、迭代器的底层源码

modCount:集合变化的次数
expectedModCount:创建对象时,传递过来的次数




七、泛型深入

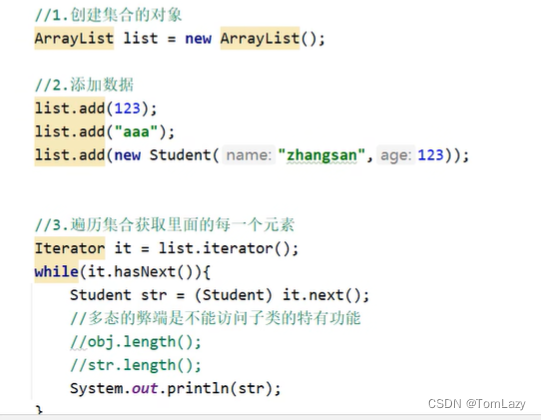
1、没有泛型时的集合如何存储数据?
没有泛型时,集合可以添加任意类型的值,但其弊端也很明显,不能访问子类特有的功能

泛型规范修改:
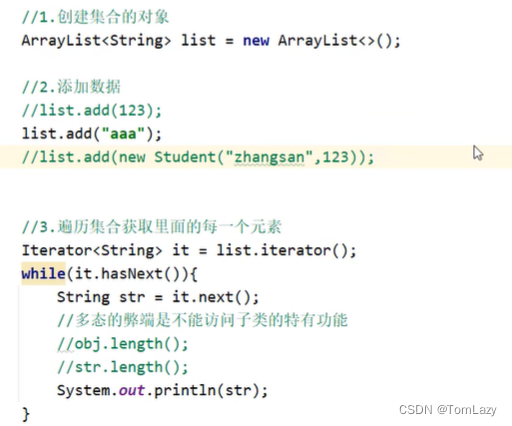
2、泛型的好处

3、知识点:Java中的泛型是伪泛型
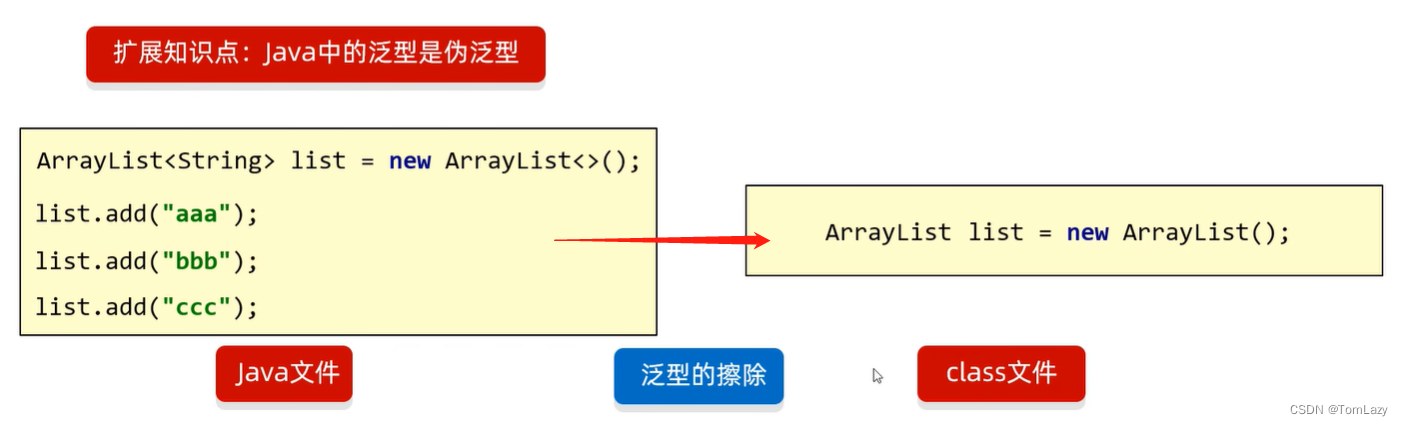
4、泛型的细节

5、泛型可以在很多地方进行定义

①、泛型类

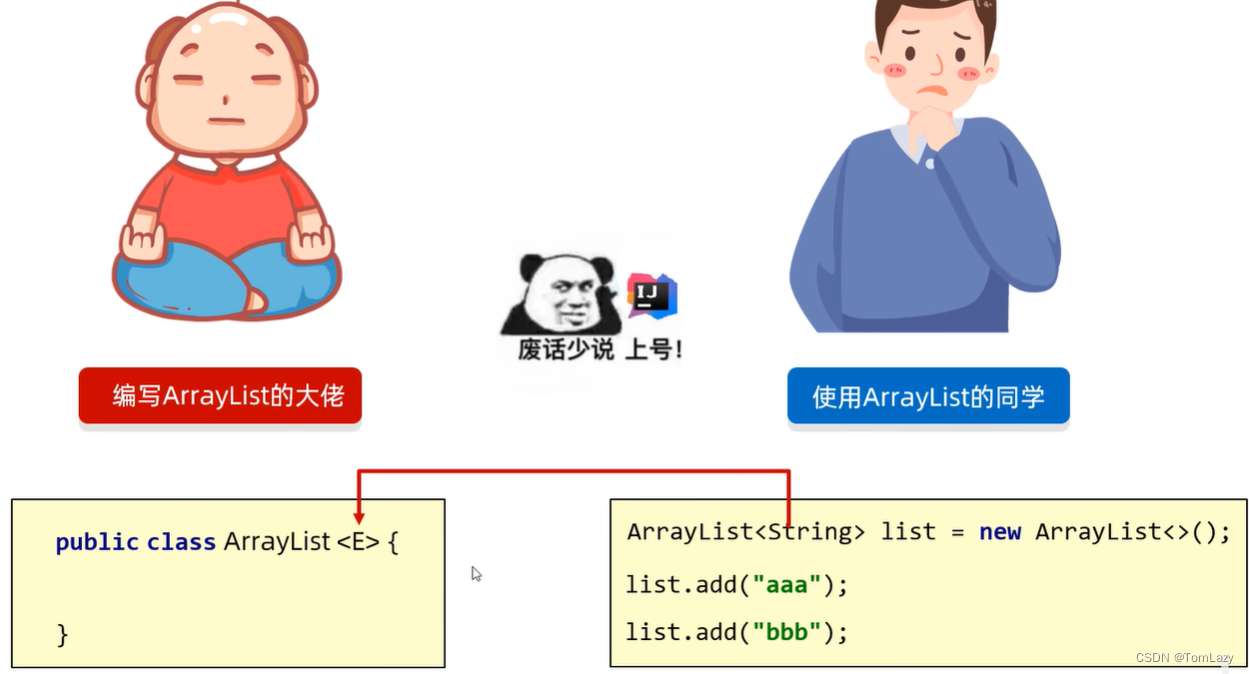
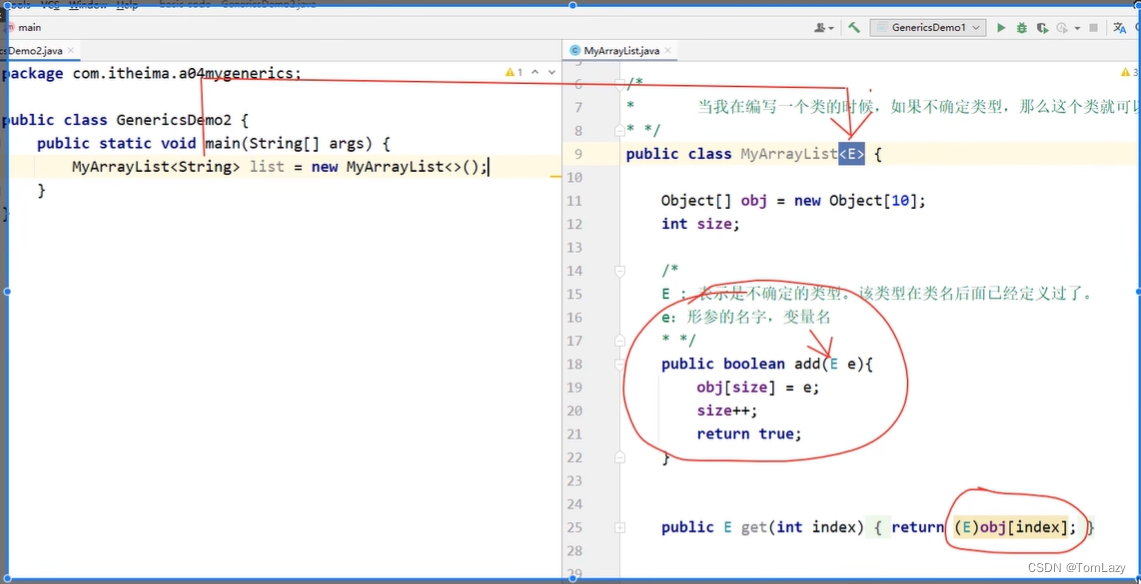
示例代码:

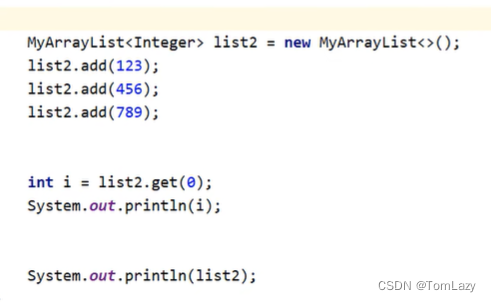
转成Integer:
②、泛型方法
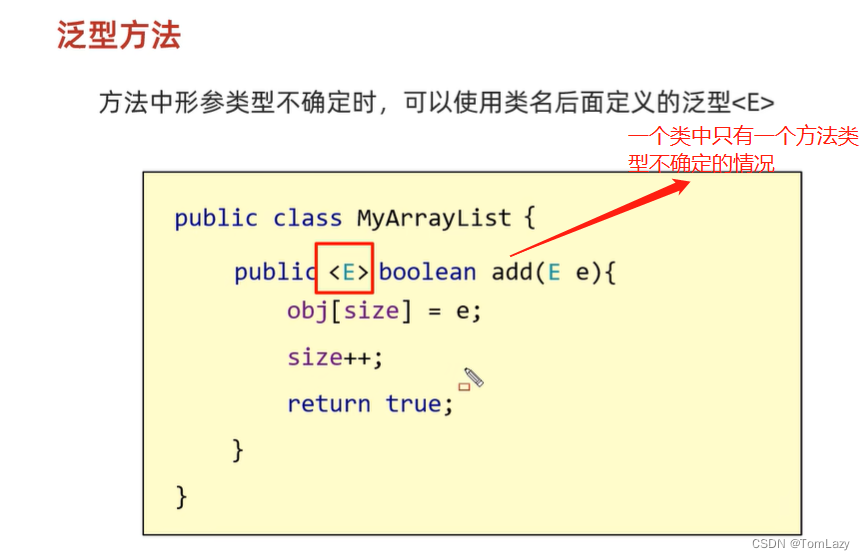

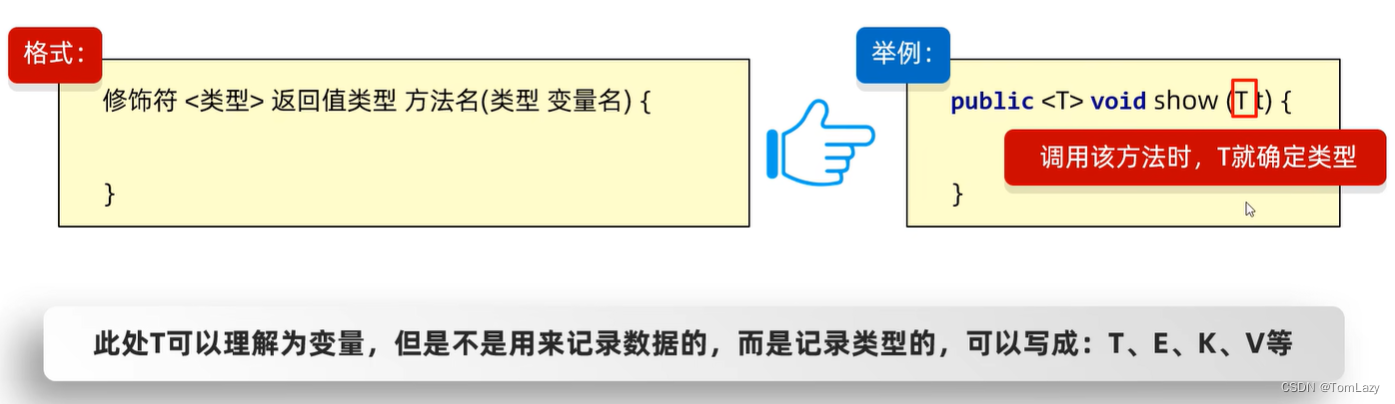
练习:

代码实现:
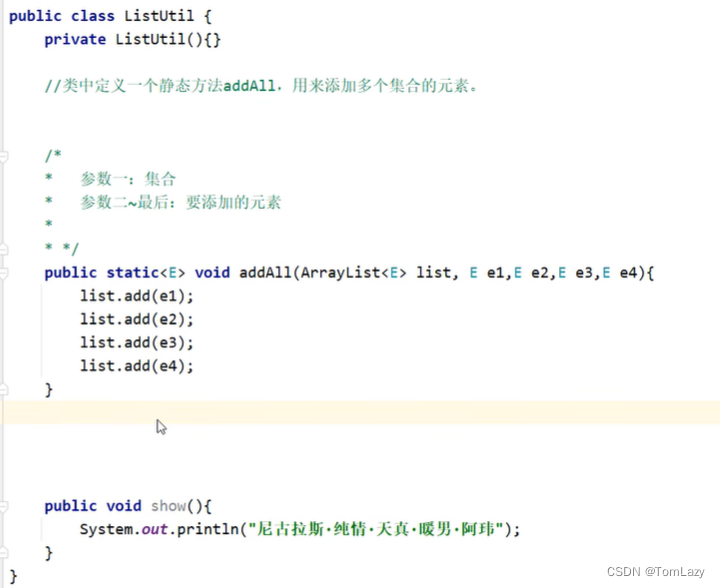
可变参数改进代码:(即 类型… 变量名)

测试类:
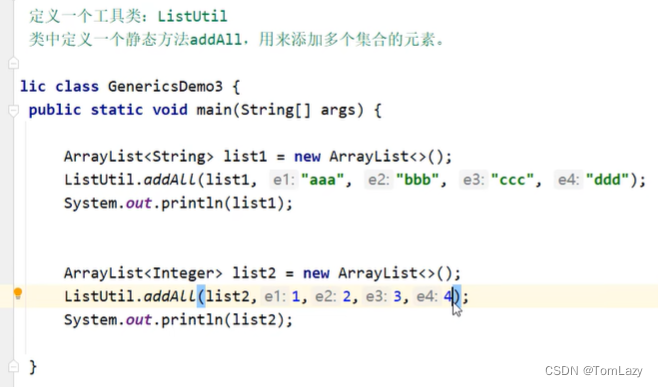
③、泛型接口

方式1:实现类给出具体方法
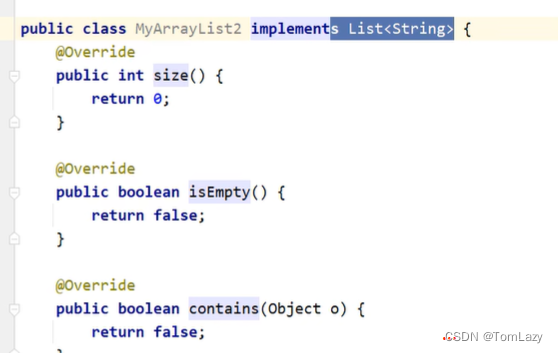

方式2:实现类延续泛型,创建对象时再确定
![]()
6、泛型的继承和通配符

①、泛型的继承示例代码

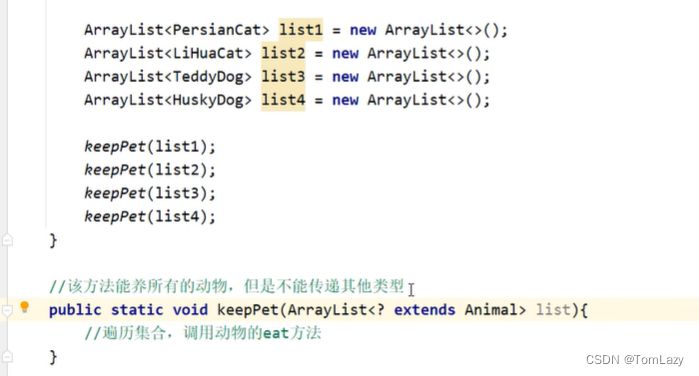
②、泛型的通配符练习

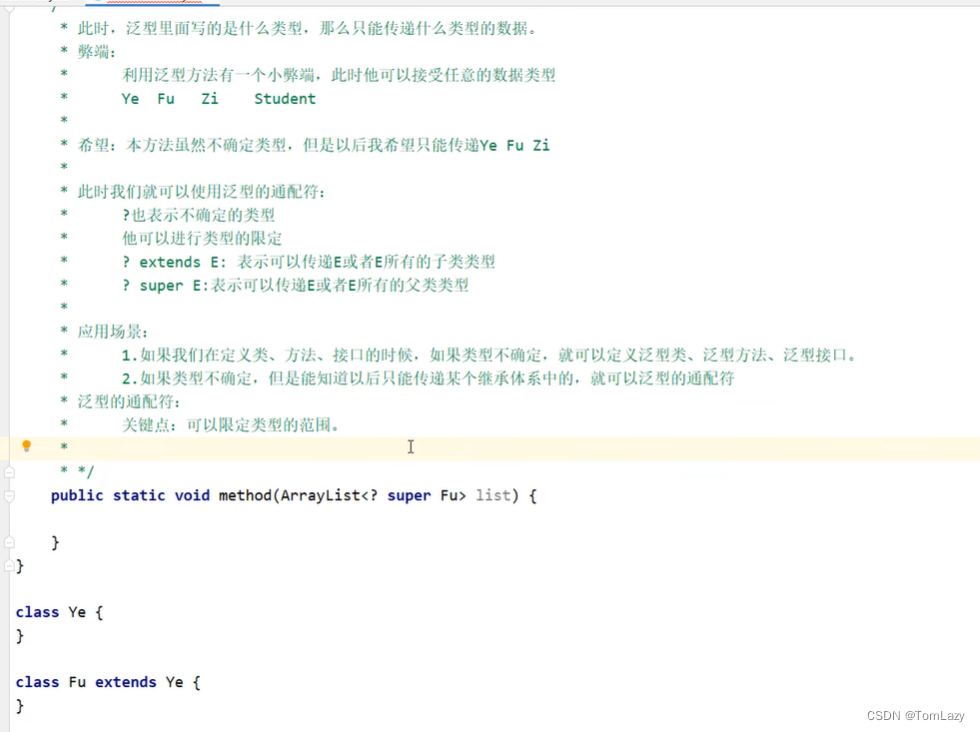
练习:

示例代码:

7、小结


八、树(Tree)
1、集合起名的艺术

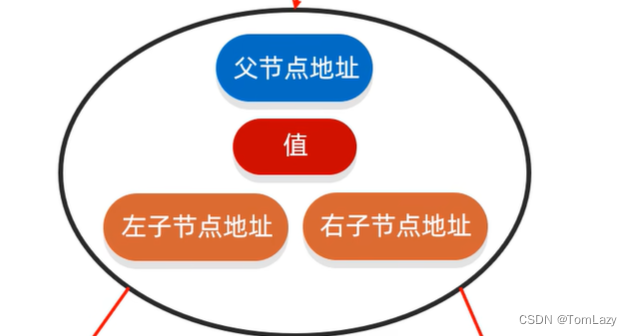
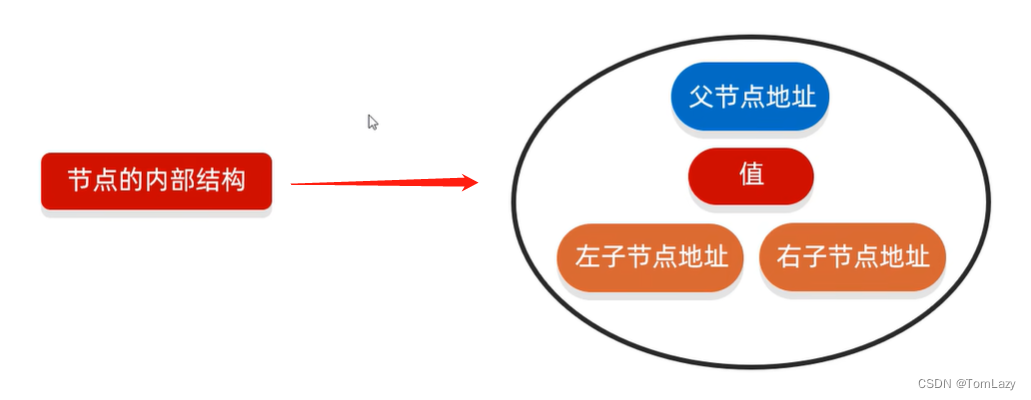
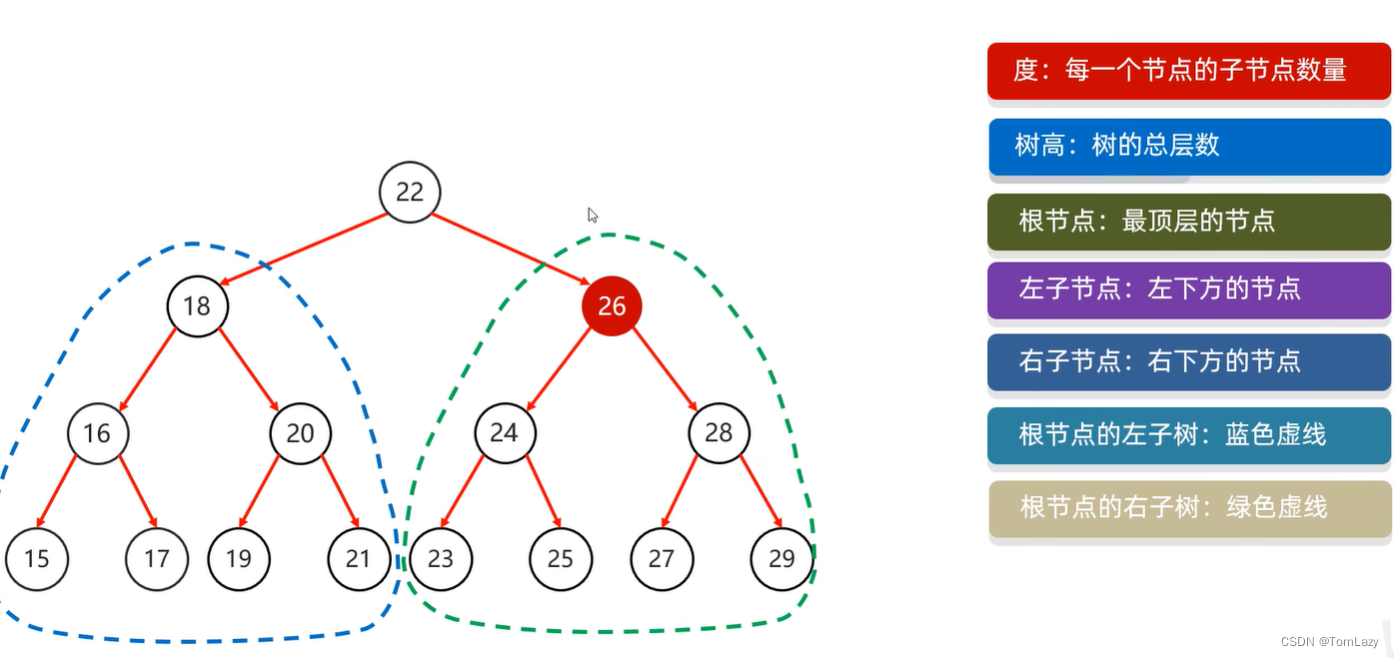
2、树的基本结构
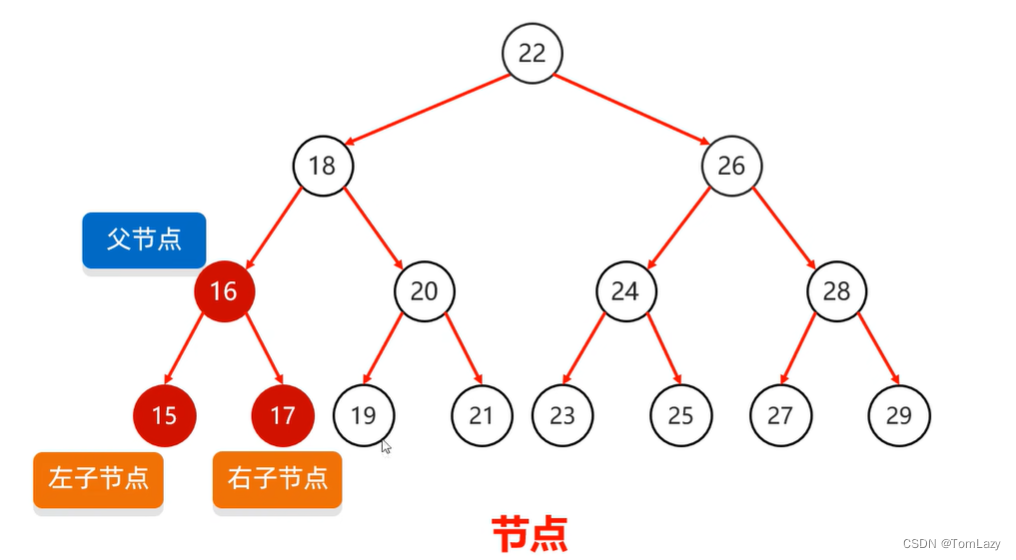
一个树节点的基本结构:
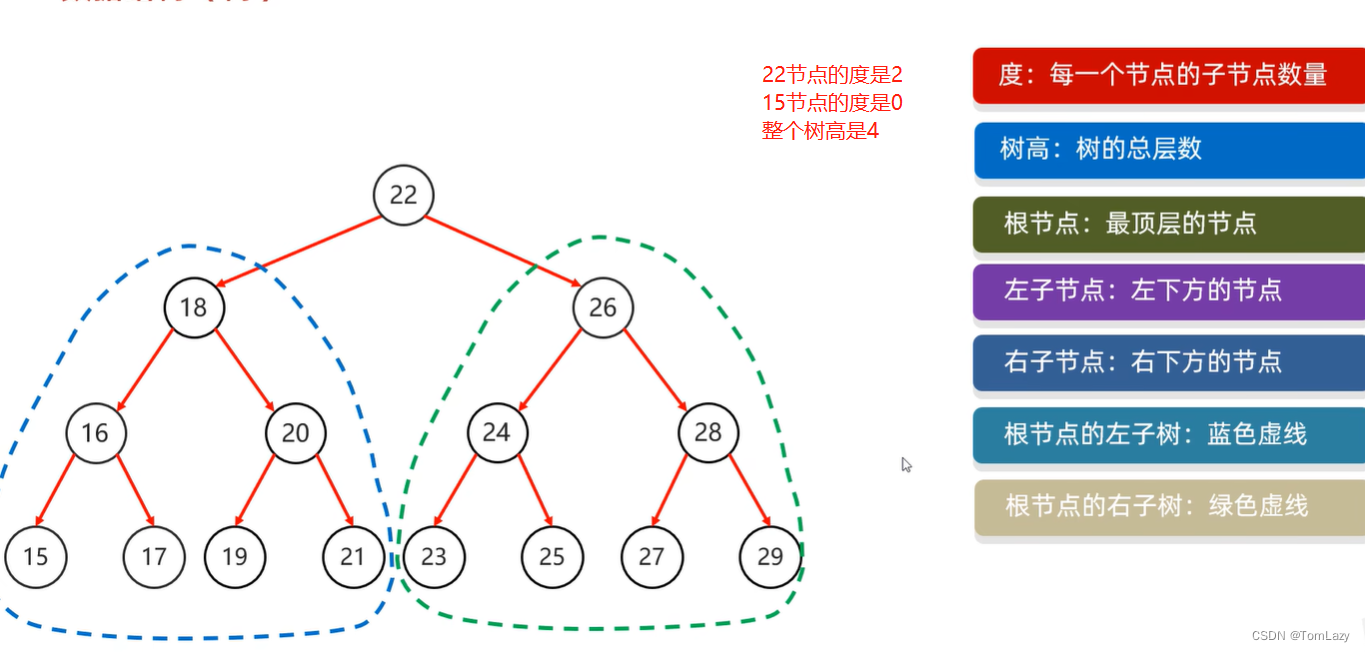
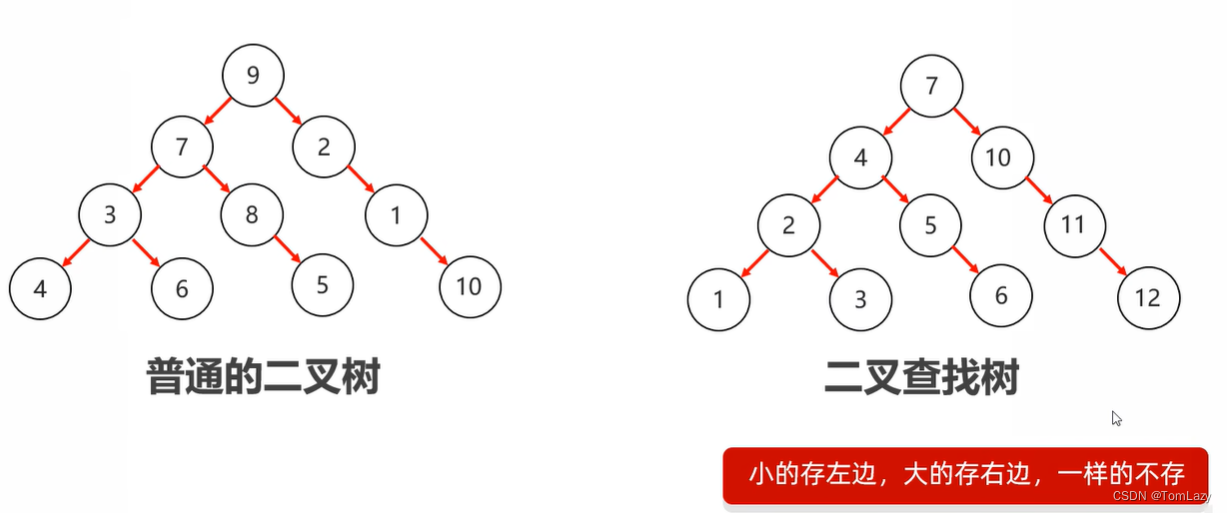
3、二叉树

但数据没什么规则
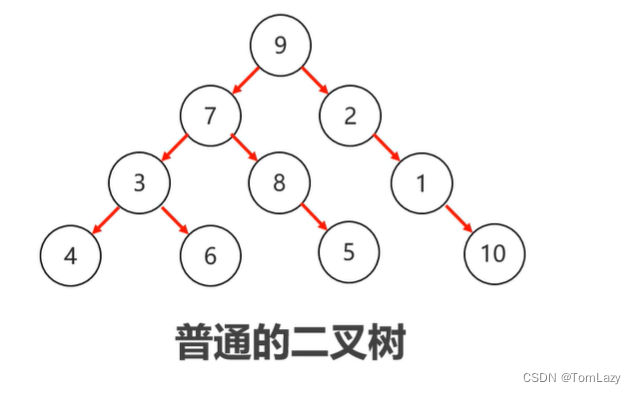
4、二叉查找树

①、添加节点
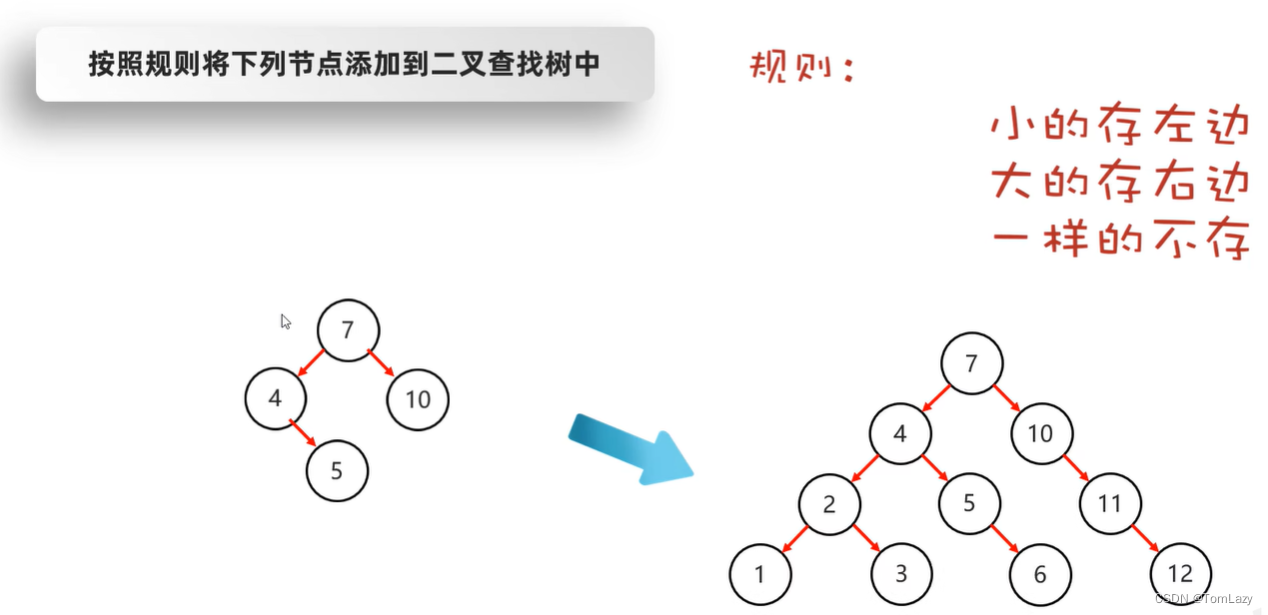
②、查找节点
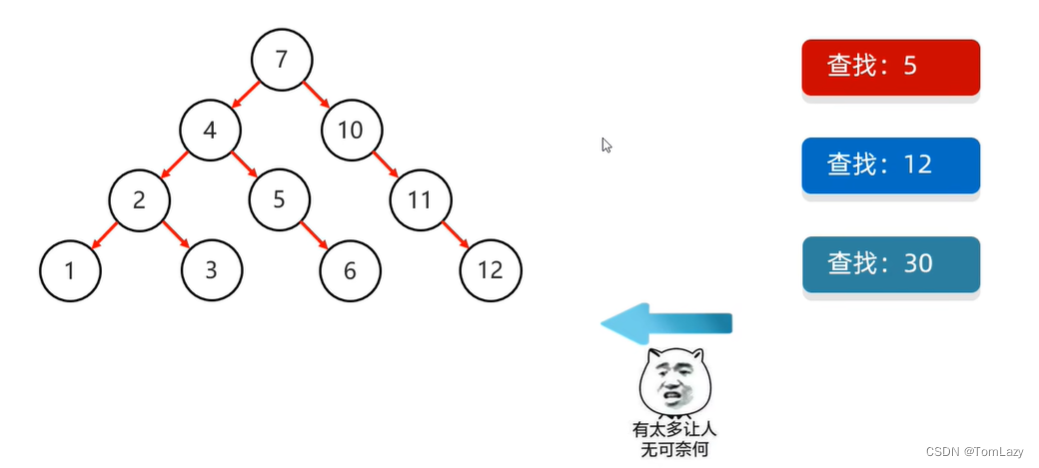
③、二叉查找树的弊端
为了避免长短腿的出现,就出现了平衡二叉树
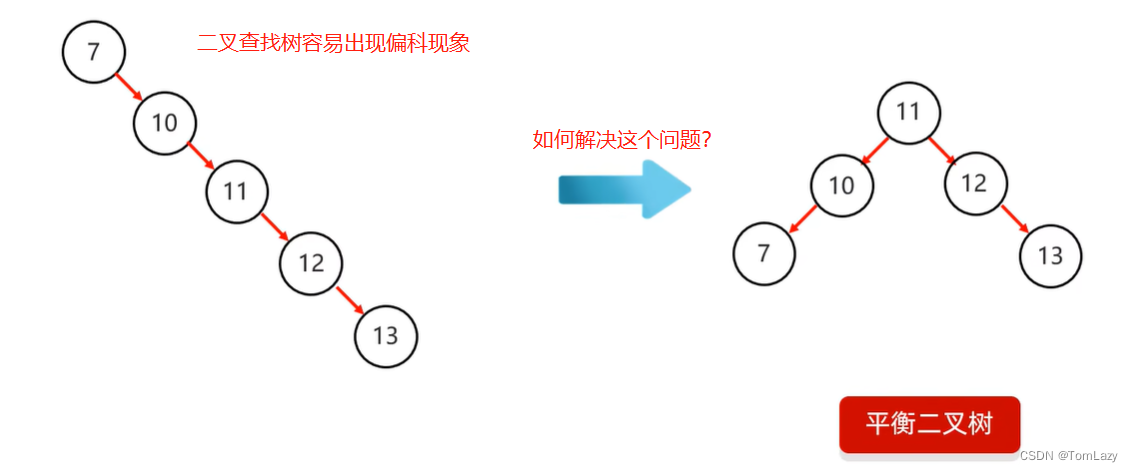
5、二叉树的遍历方式

①、前序遍历(根、左、右)

②、中序遍历(左、根、右)

③、后序遍历(左、右、根)
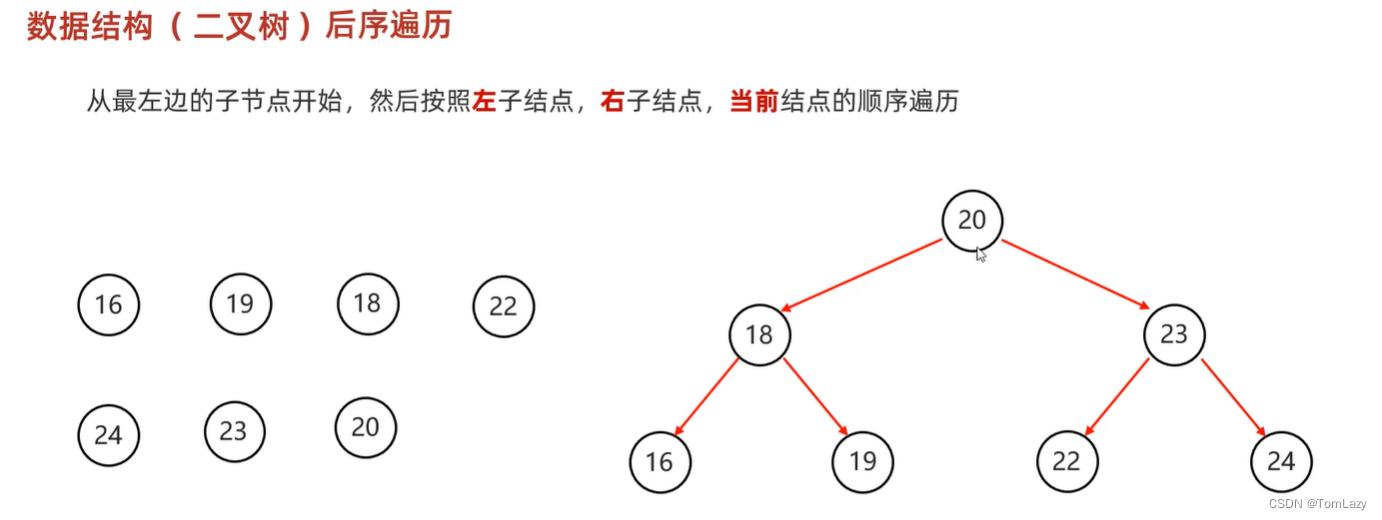
④、层序遍历(一层一层遍历)
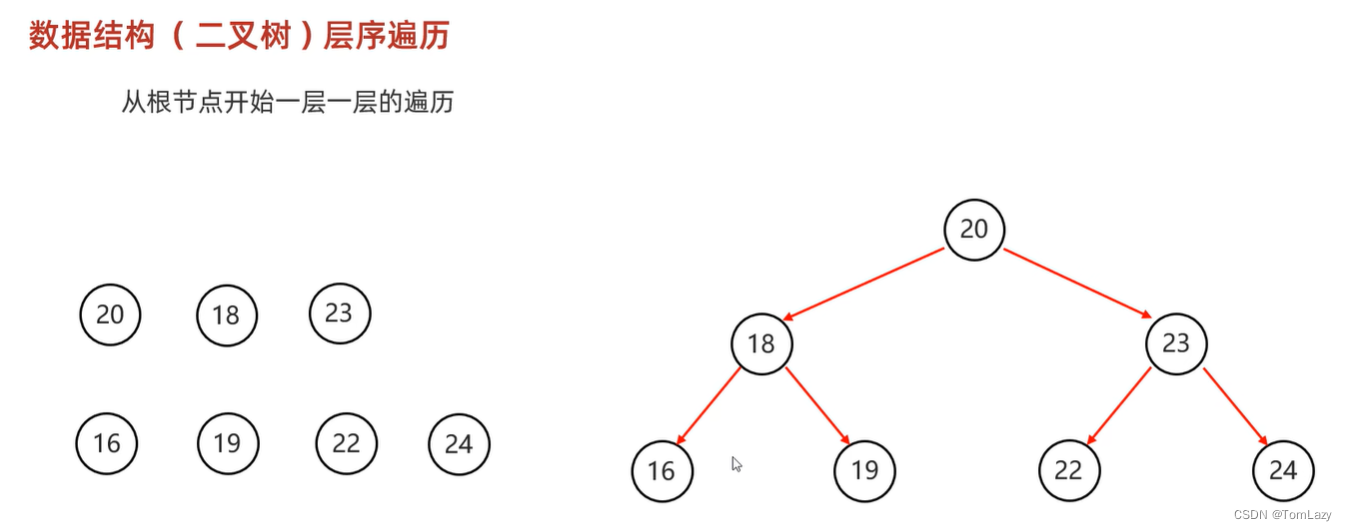
⑤、小结

6、平衡二叉树

①、平衡二叉树的旋转机制

②、左旋
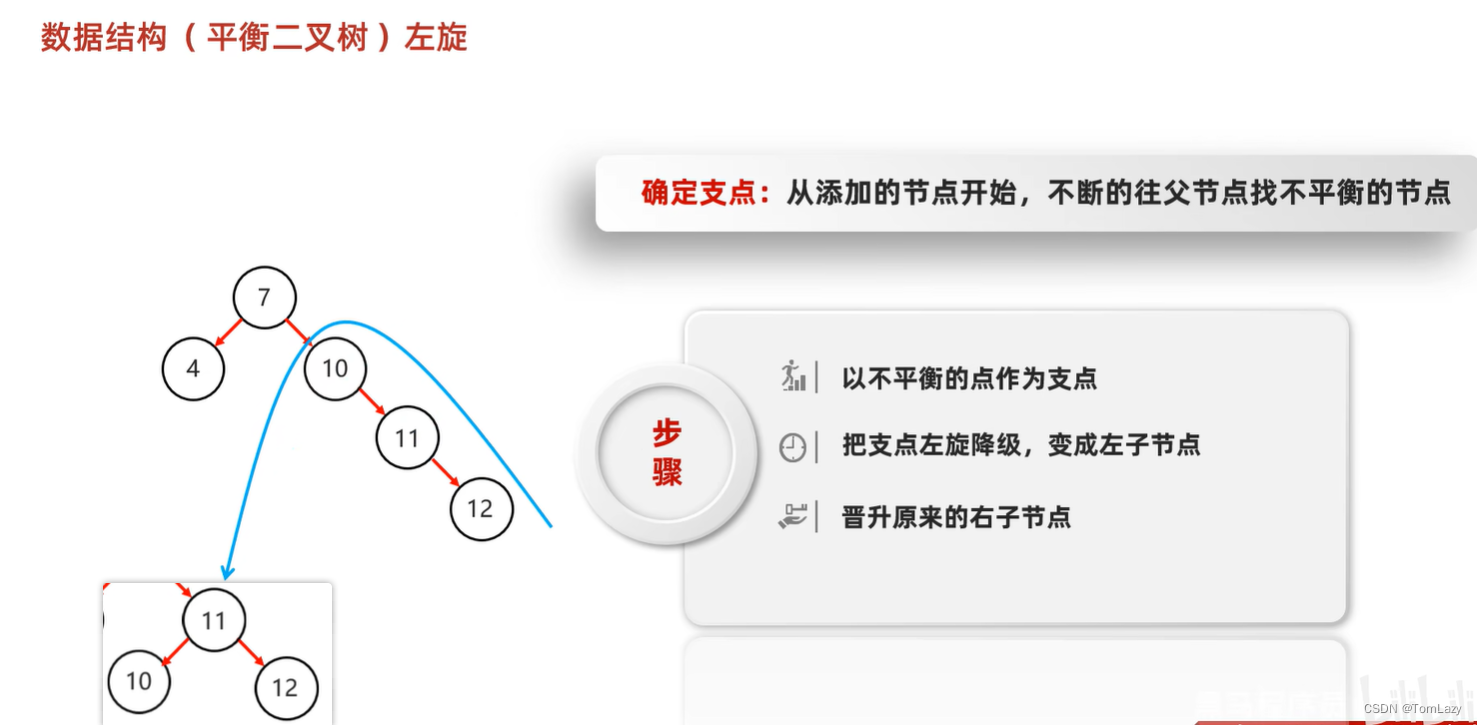
当根节点是支点时:
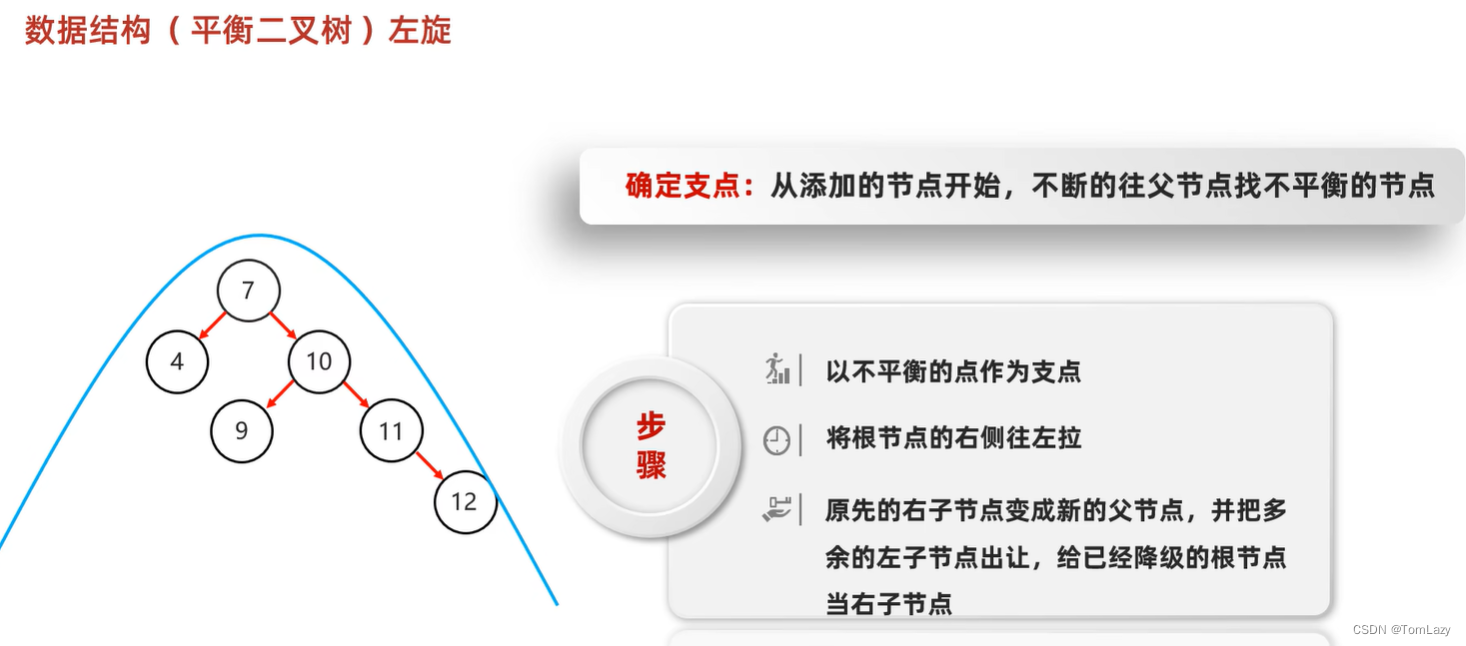
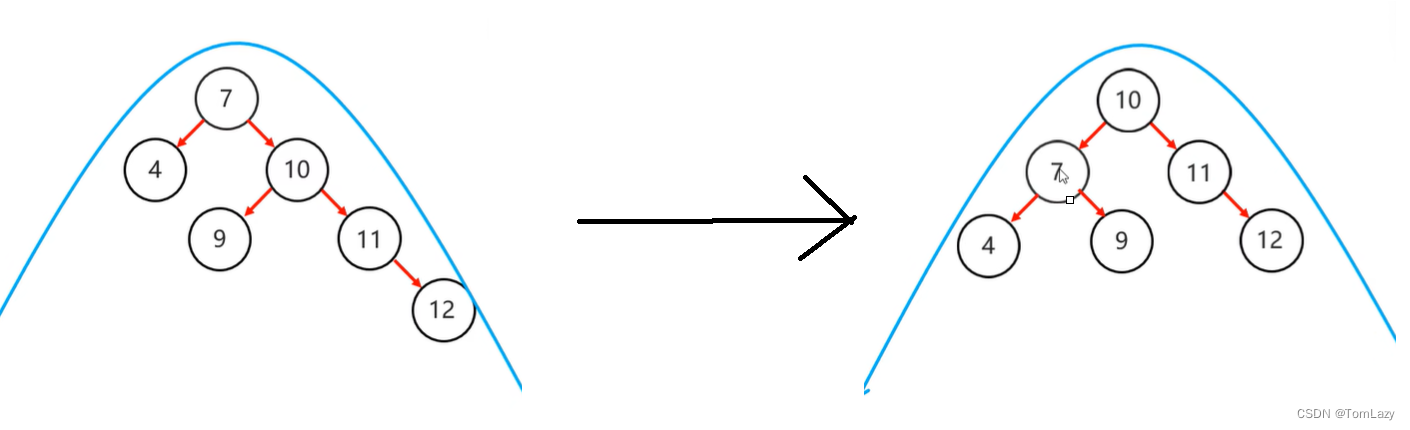
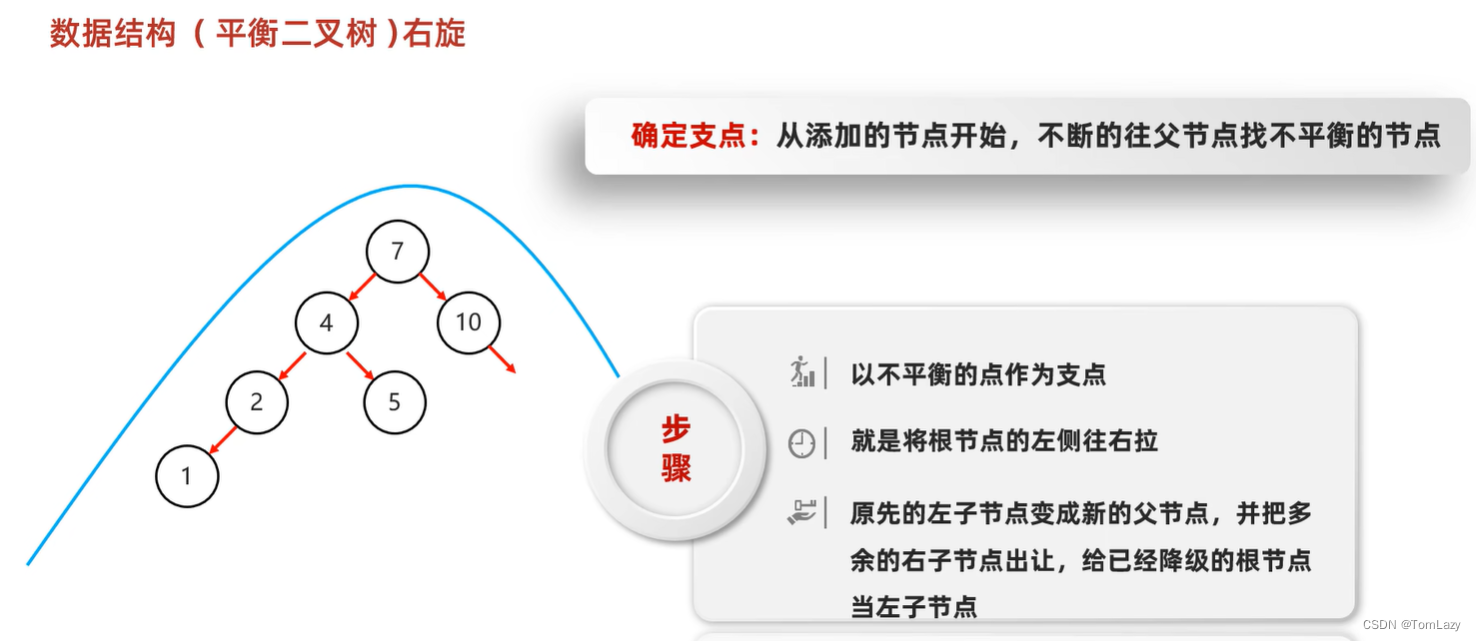
③、右旋
普通情况:

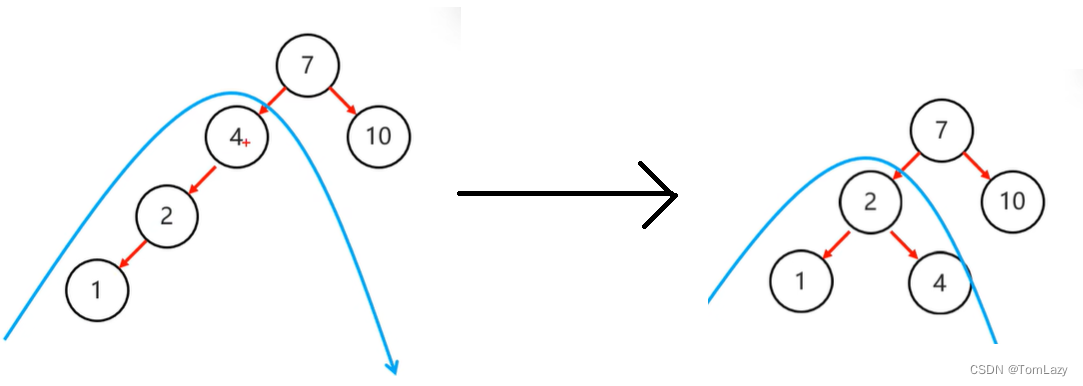
当根节点是支点时:
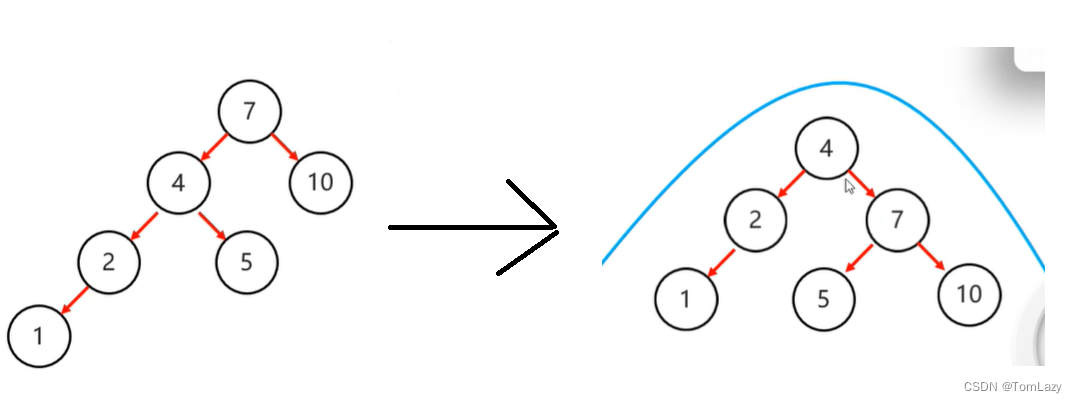
④、平衡二叉树需要旋转的四种情况(左左、左右、右右、右左)

左左:(一次右旋)
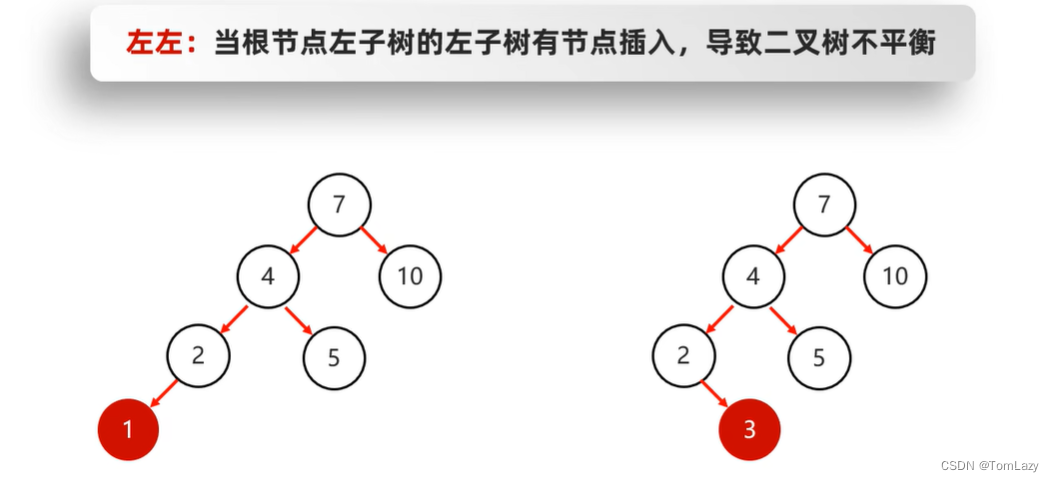
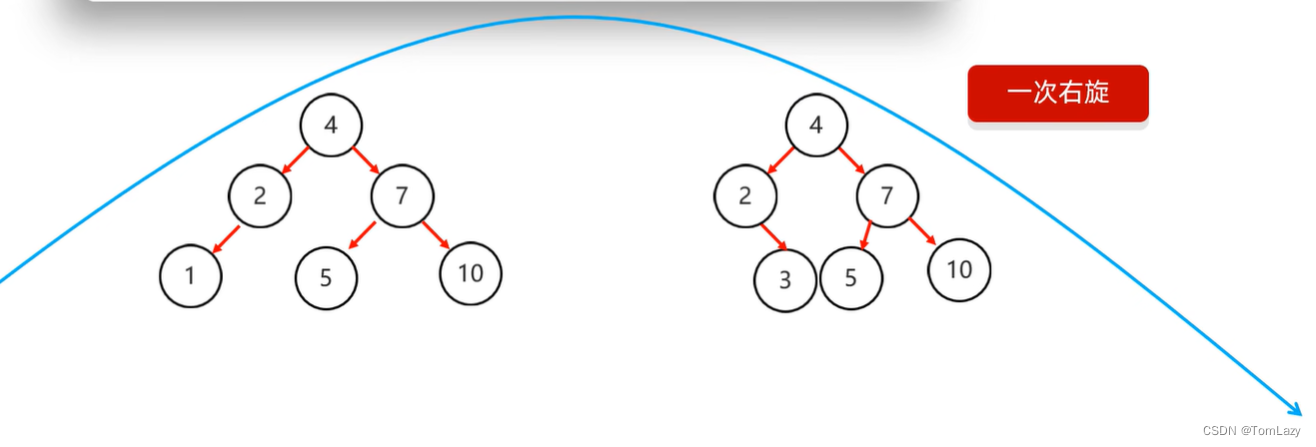
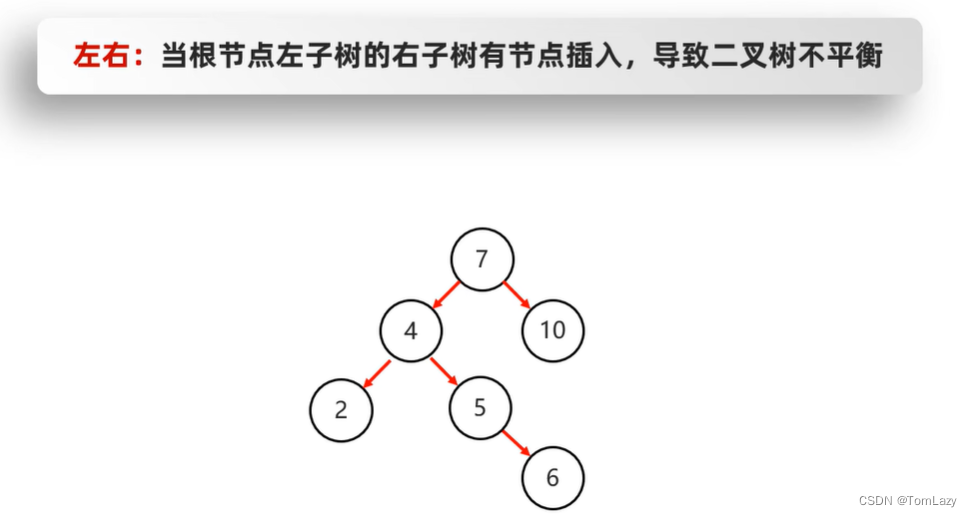
左右:(先局部左旋,再整体右旋)
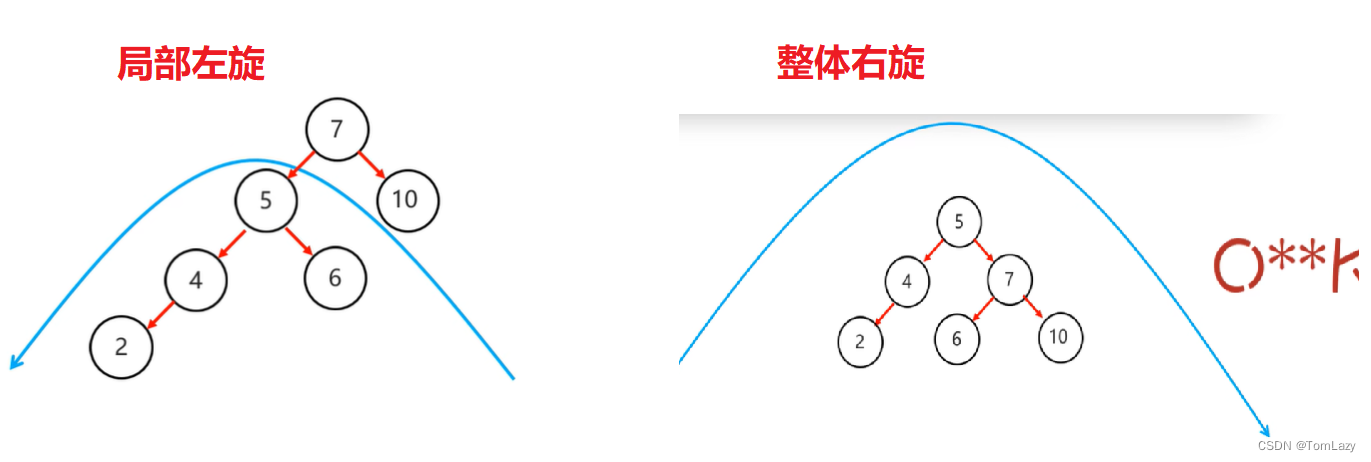
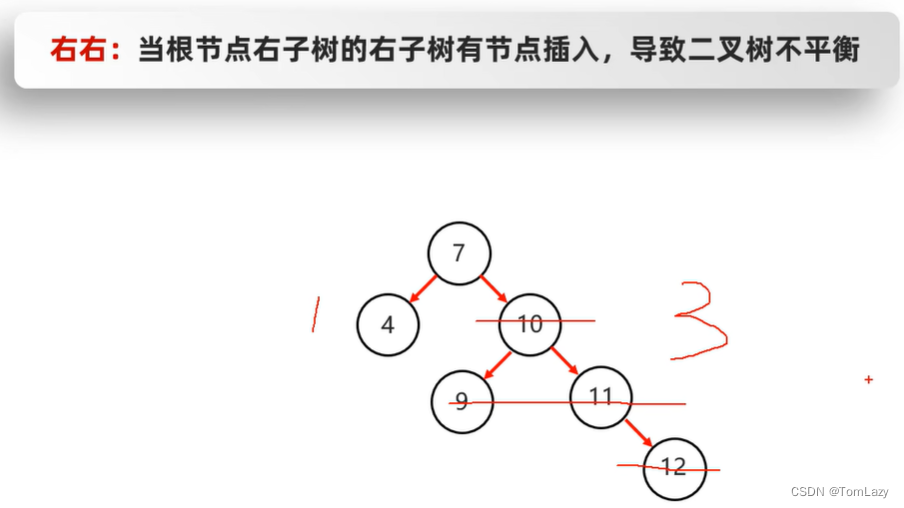
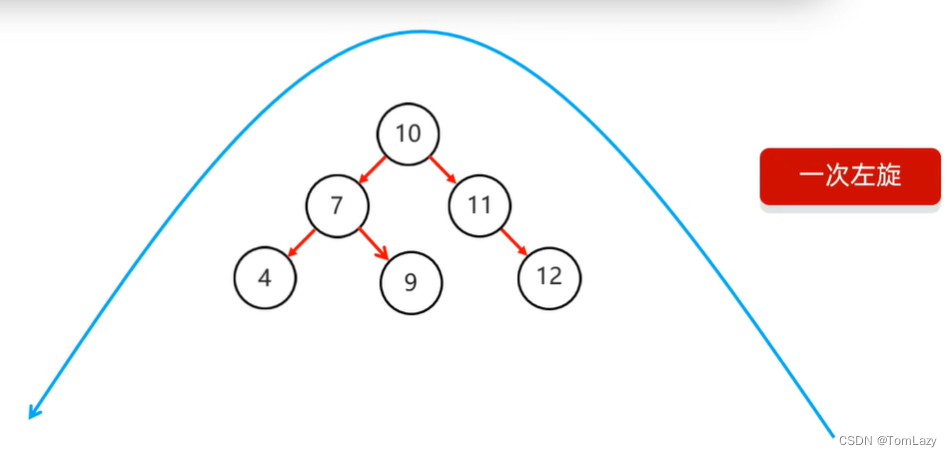
右右:(一次左旋)
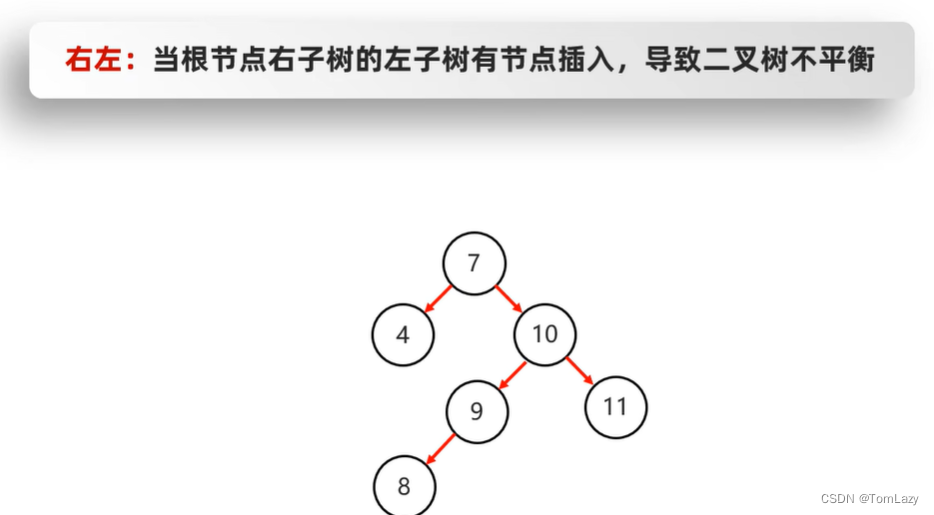
右左:(先局部右旋,再整体左旋)
⑤、小结
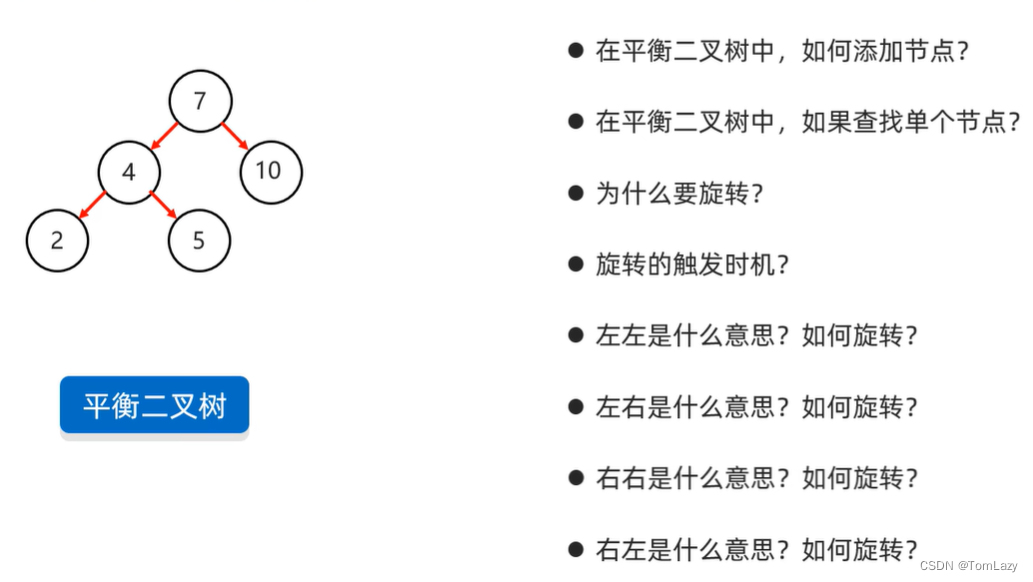
1、在平衡二叉树中,如何添加节点?
A:大的存右边,小的存左边,相等的不存
2、如何查找单个节点?
A:从根节点开始查找,然后逐个比较
3、为什么要旋转?
A:只有平衡二叉树和红黑树才需要旋转;旋转的原因就是在添加一个节点后,导致这个树不平衡了,那么就需要通过旋转让它重新平衡
4、旋转的触发时机?
A:树不平衡了
5、左左是什么意思?
![]()
6、左右是什么意思?

7、右右是什么意思?

8、右左是什么意思?

7、树的演变
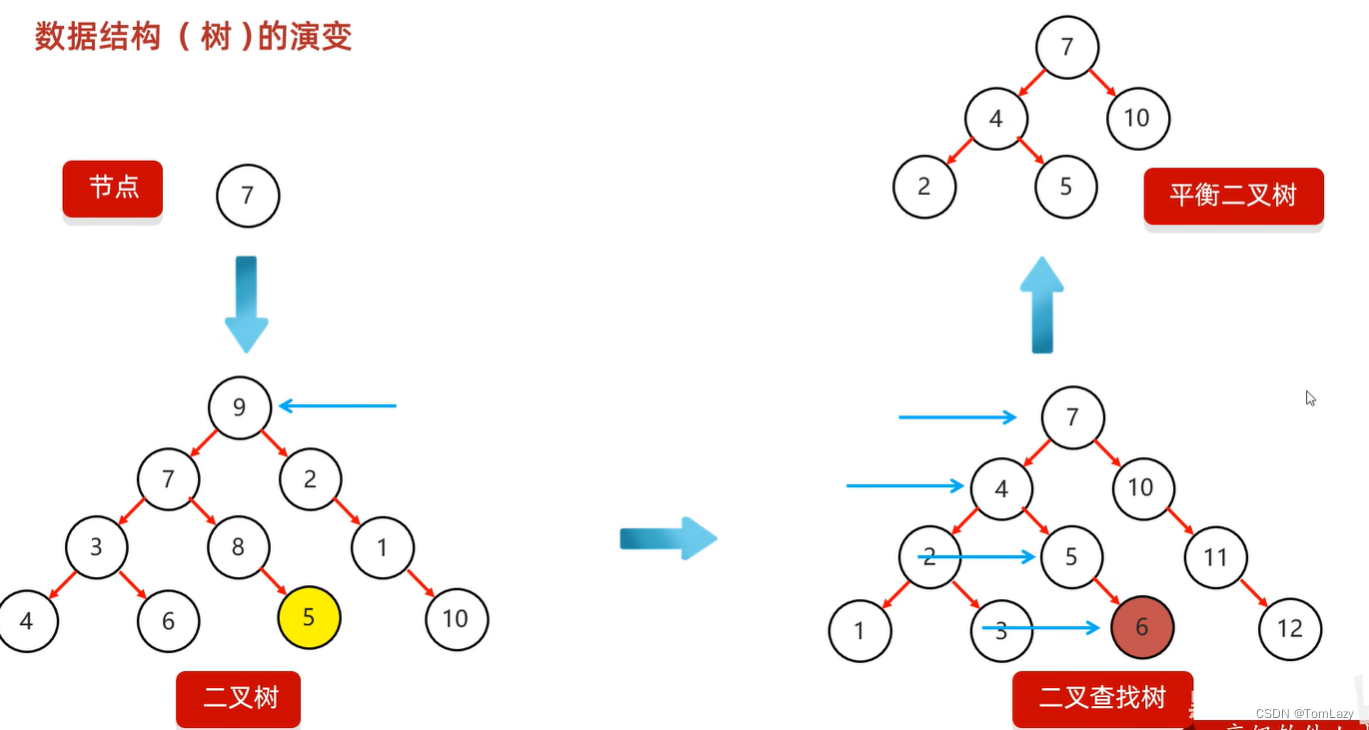
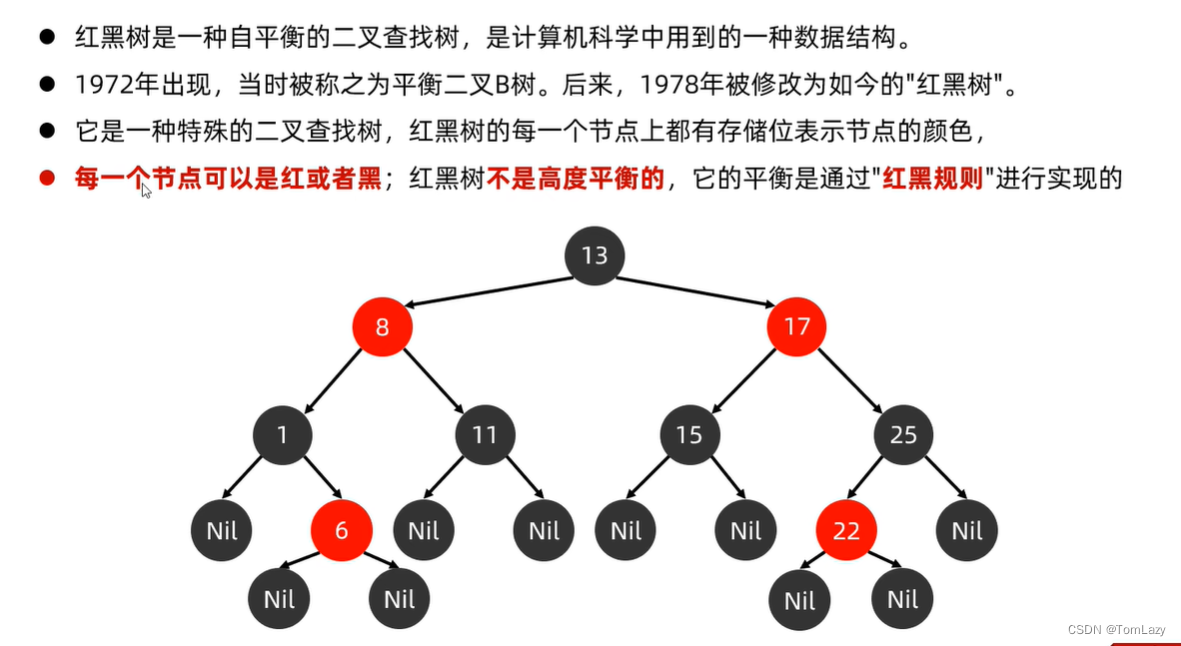
8、红黑树(一种特殊的二叉查找树,而不是平衡二叉树)【★★】
平衡二叉树也有一些弊端:在添加节点是时候,由于旋转次数太多,会导致添加节点的时间浪费。

①、红黑树的红黑规则
简单路径:只能往前,不能回头,eg:13 -> 8 -> 1 -> Nil
Nil本身实际上是没有什么含义的,就是在第5条的规则上,要用到它来统计个数的
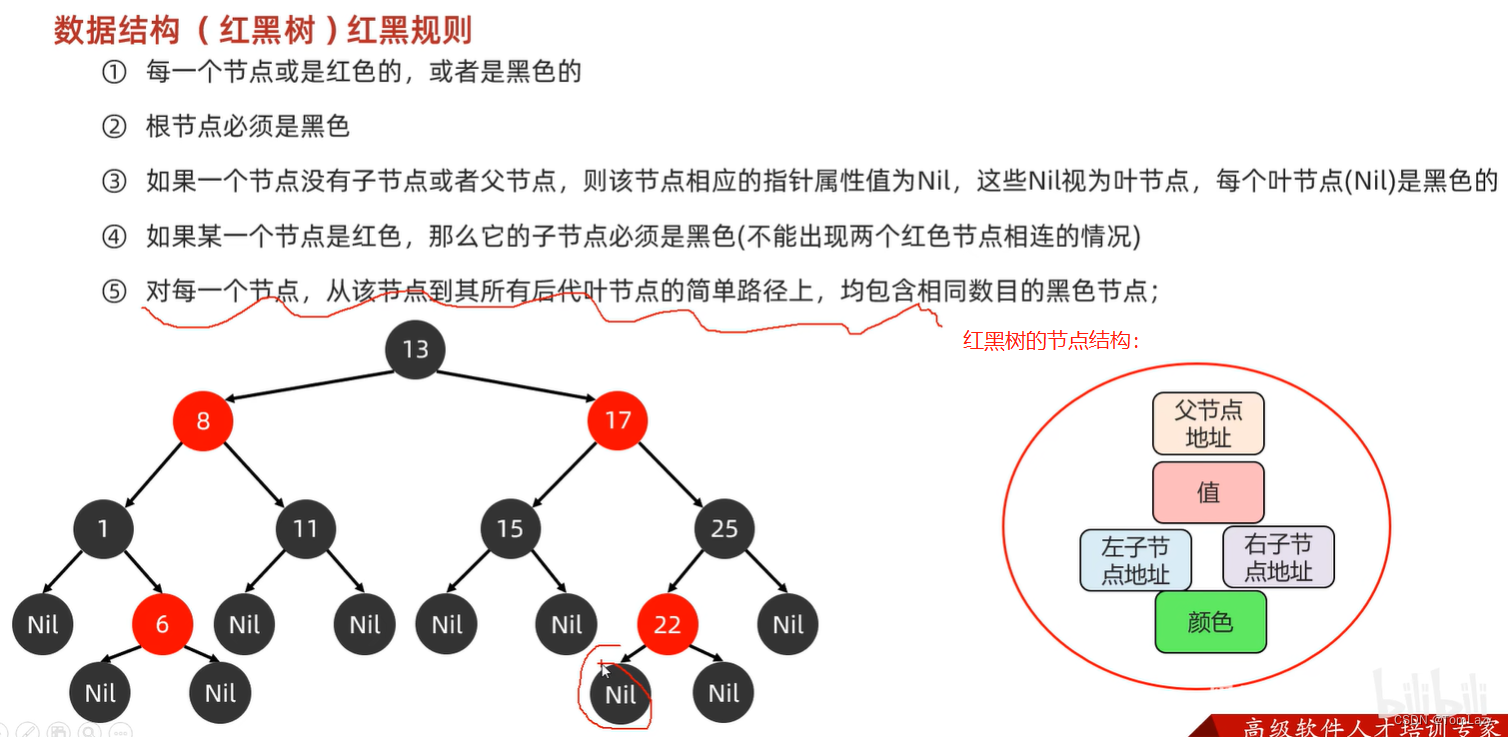
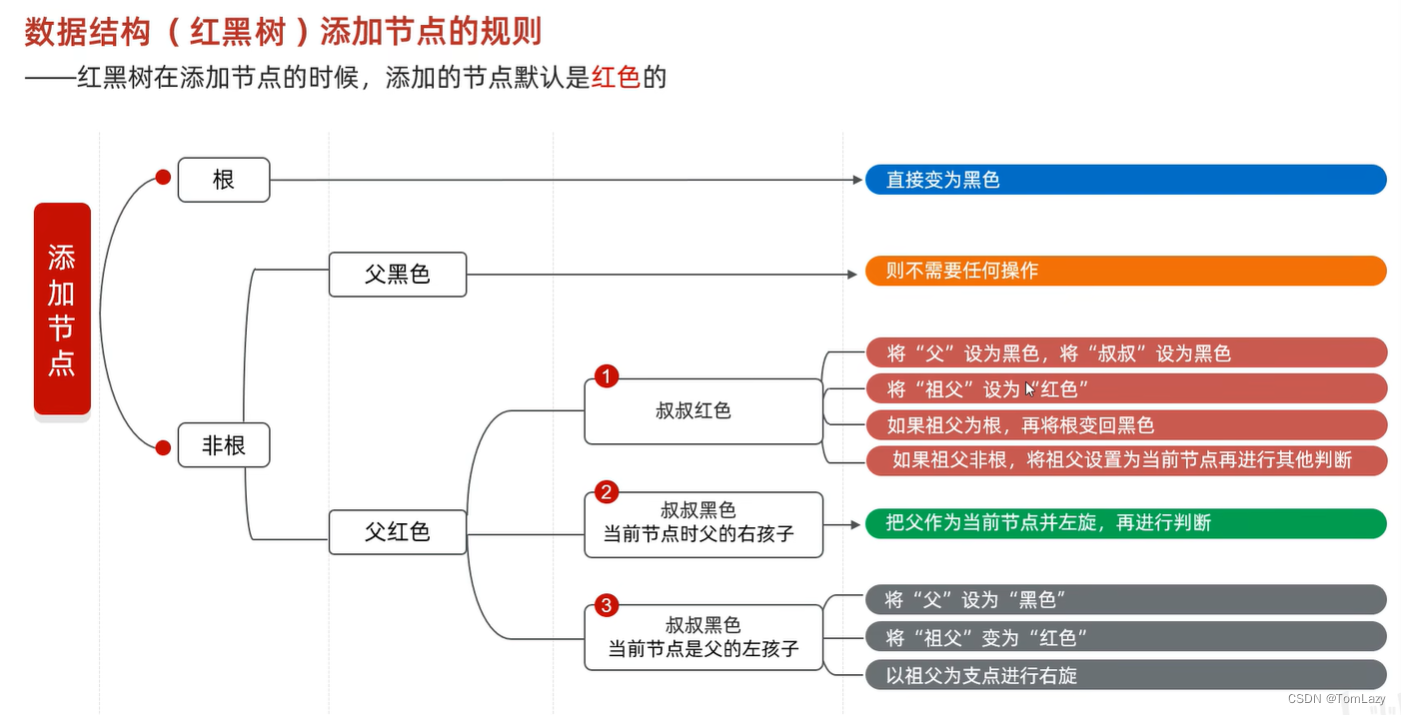
②、红黑树添加节点的规则

如果默认节点颜色为黑色,那么添加三个节点,需要调整两次
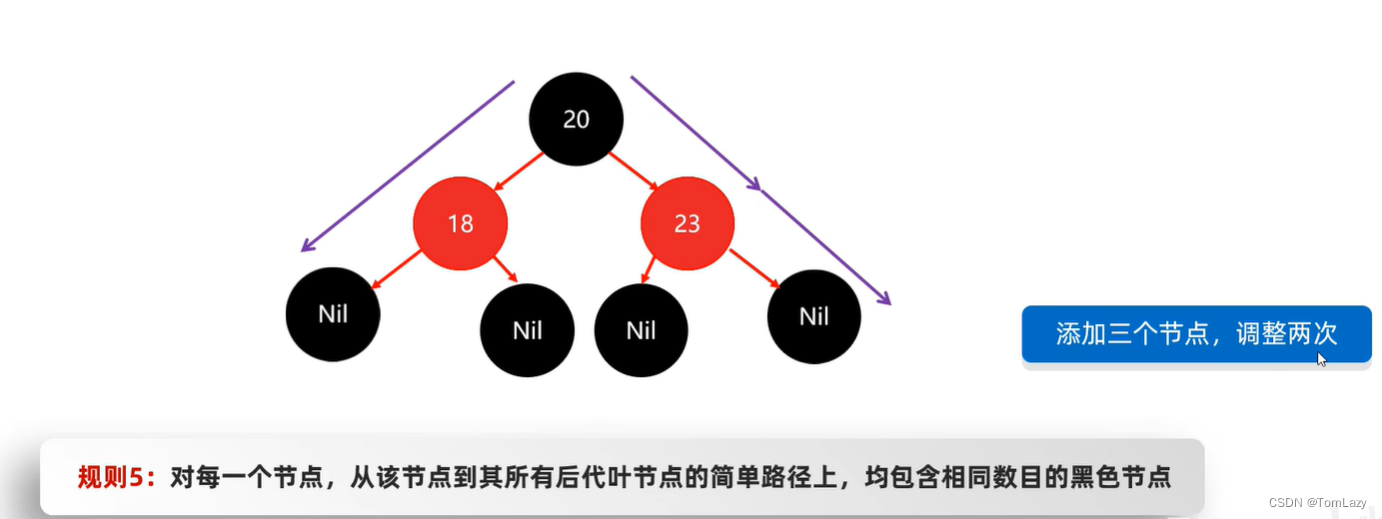
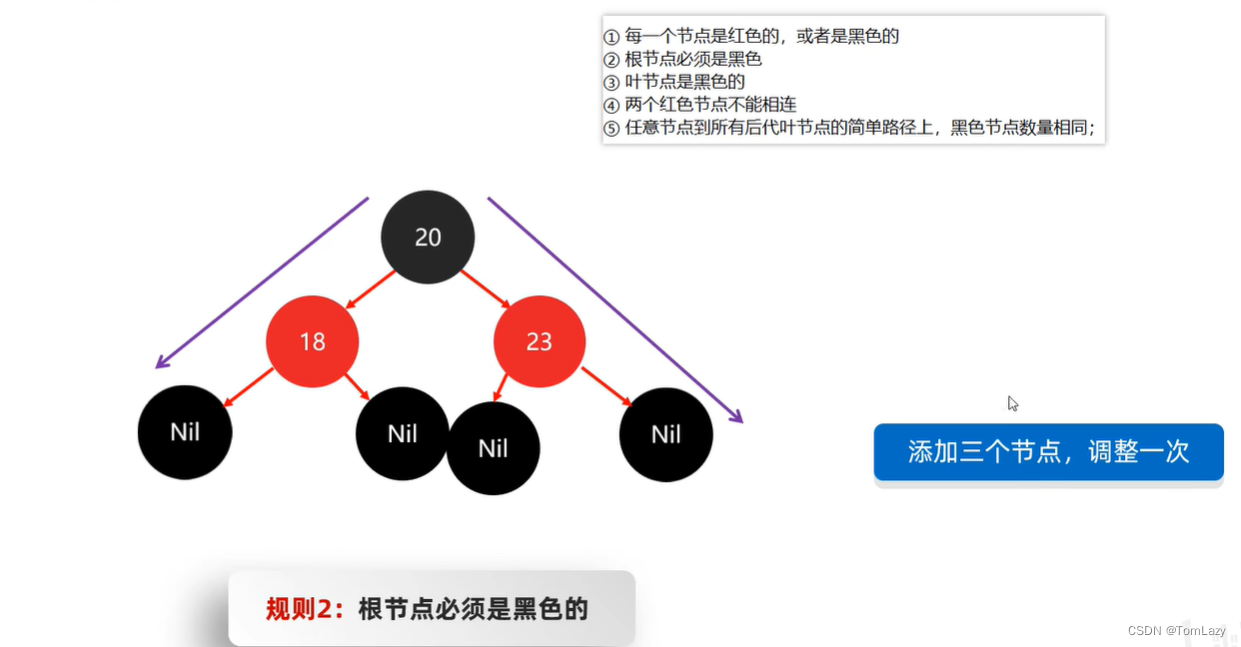
如果默认节点颜色为红色,那么添加三个节点,只需要调整一次
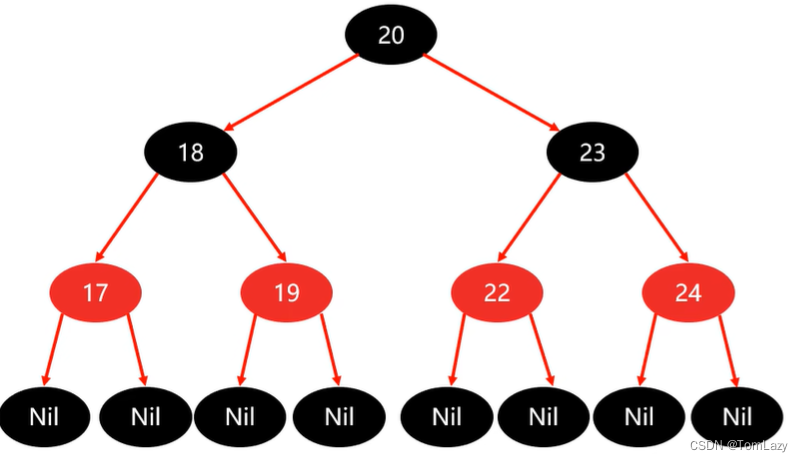
添加节点示例:
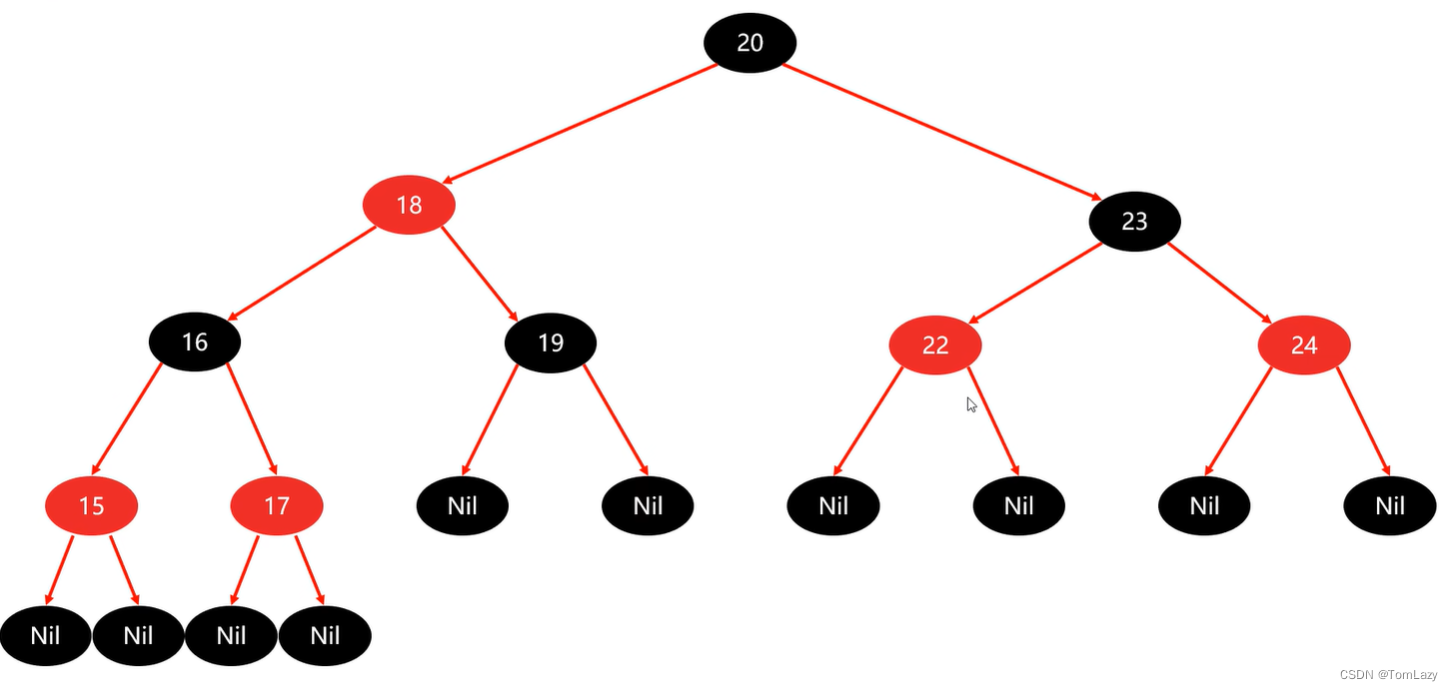
③、小结(能看懂即可)


九、Set系列集合

无序:存取顺序不一致
不重复:可以去除重复
无索引:没有带索引的方法,所以不能使用普通for循环遍历,也不能通过索引来获取元素

1、练习:利用Set系列的集合,添加字符串,并使用多种方式遍历

①、示例代码
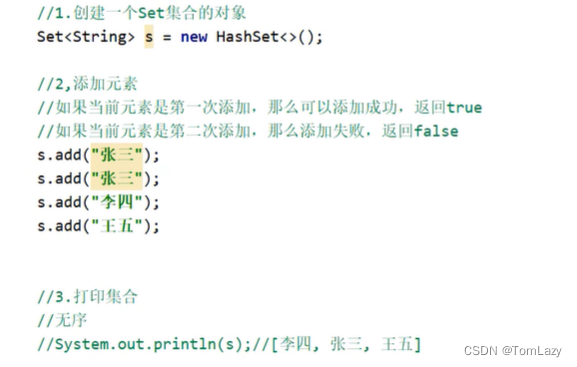
多种方式遍历:

②、小结

2、HashSet底层原理

①、哈希值

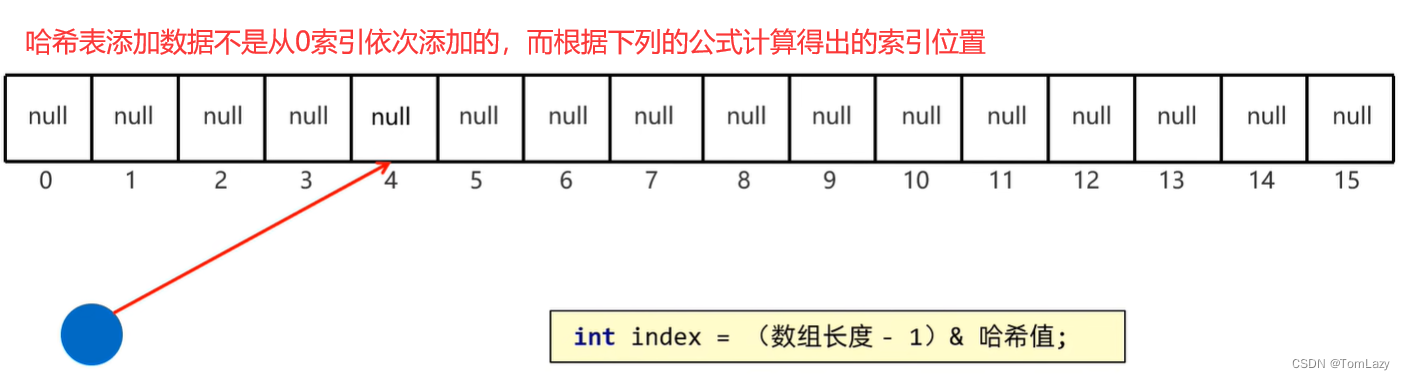

②、对象的哈希值特点
因为地址不同



示例代码:
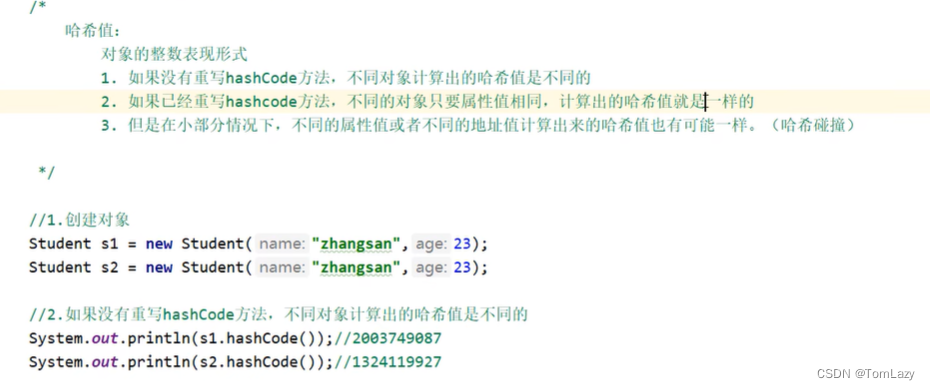
重写hashCode()方法后:

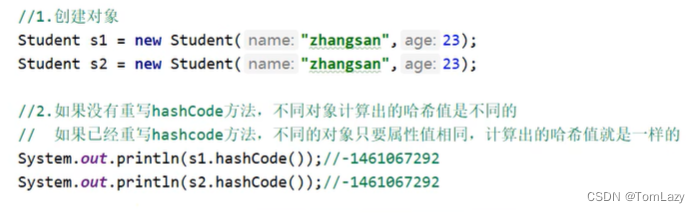
哈希碰撞情况:

3、HashSet JDK8 以前的底层原理
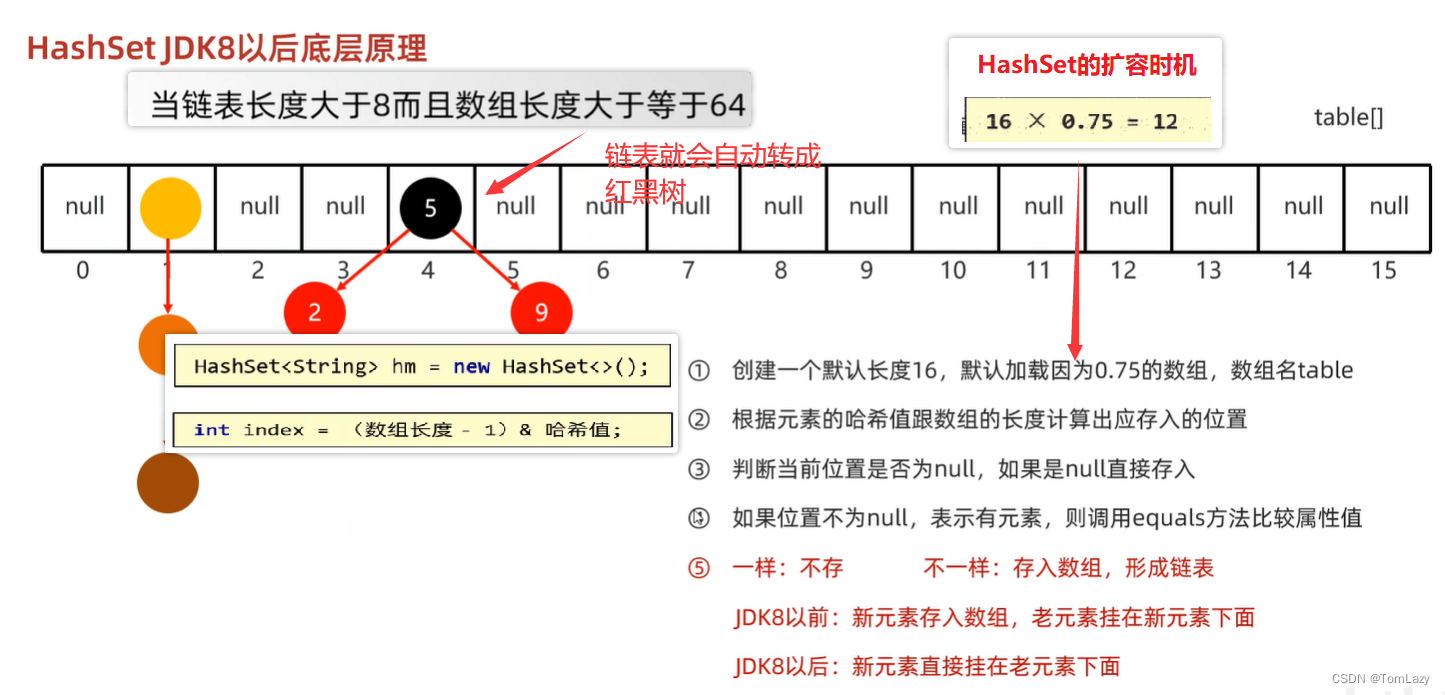
①、HashSet完整创建过程
当我们在创建一个HashSet对象时,在底层会创建一个默认长度为16,默认加载因子为0.75的数组:

②、HashSet创建的细节

4、HashSet的三个问题

①、HashSet为什么存和取的顺序不一样?
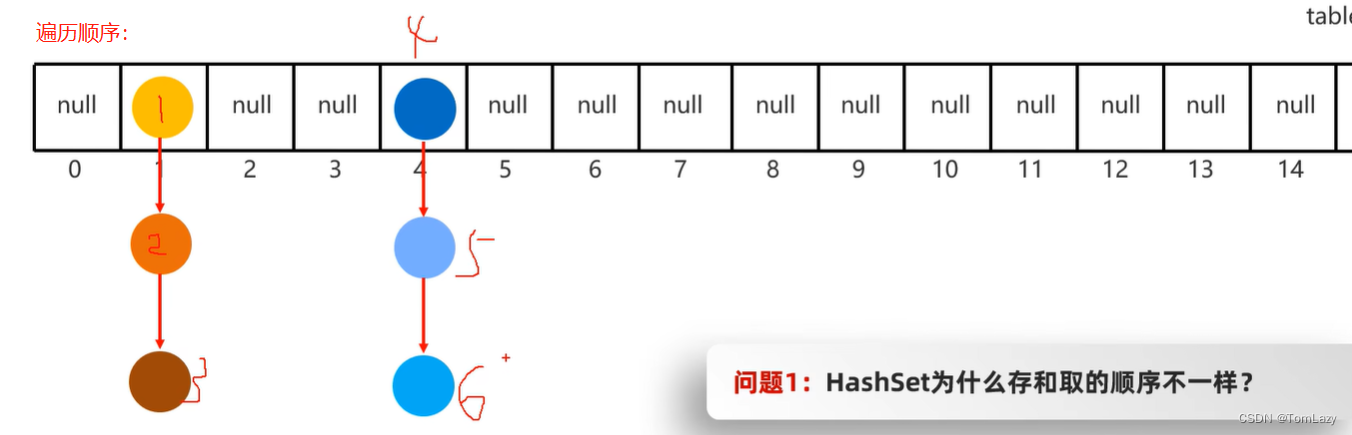
HashSet在遍历的时候,是从数组的0索引开始,一条链表,一条链表的查询
但是黄色小球就是第一个被存入的吗?不见得吧!
②、HashSet为什么没有索引?
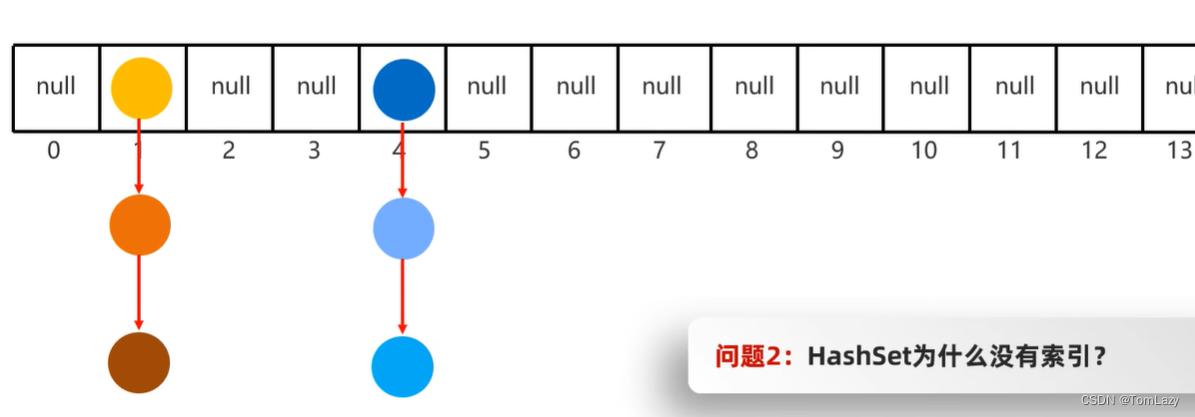
主要原因是因为HashSet不够纯粹,底层是由数组+链表+红黑树构成的,所以不好规定以谁为索引
③、HashSet是利用什么机制保证数据去重的?

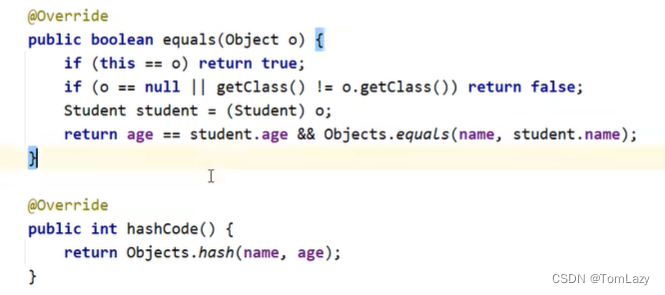
切记:如果HashSet中存储的是自定义对象,那么一定要重写HashCode和equals方法
④、问题回答

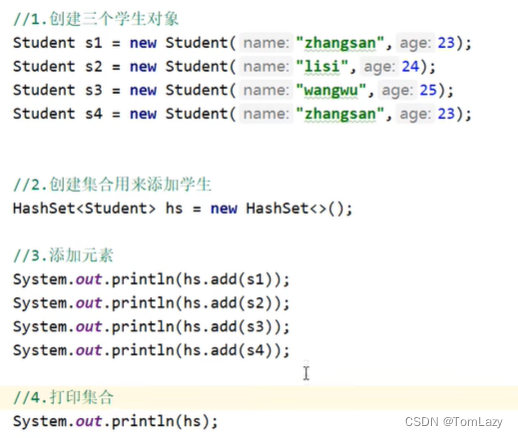
5、练习:利用HashSet集合去除重复元素

示例代码:
在JavaBean中重写hashCode和equals方法

十、LinkedHashSet
1、LinkedHashSet底层原理
①、示例代码:(LinkedHashSet可以保证数据的存储顺序)

②、小结

十一、TreeSet(自动排序)
1、TreeSet的基本应用
①、TreeSet的特点

②、练习:利用TreeSet存储整数并进行排序
直接打印:
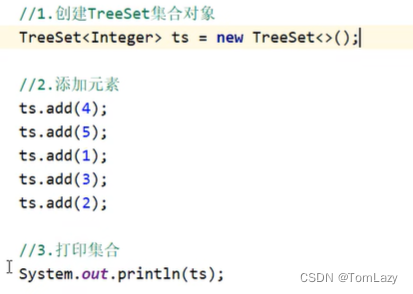
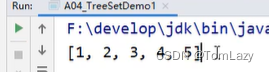
遍历集合:
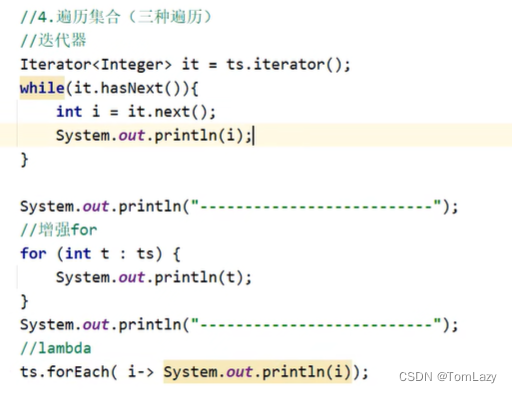
2、TreeSet集合默认的规则

字符串比较:
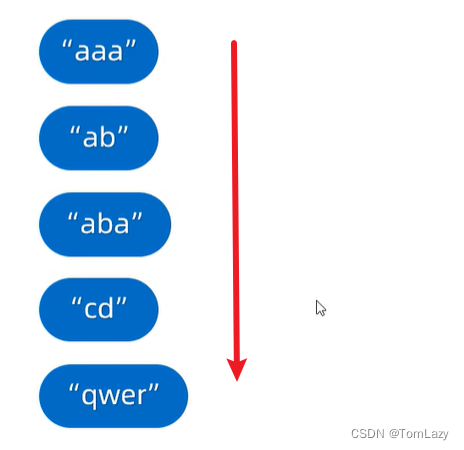
①、TreeSet对象排序练习题

示例代码:
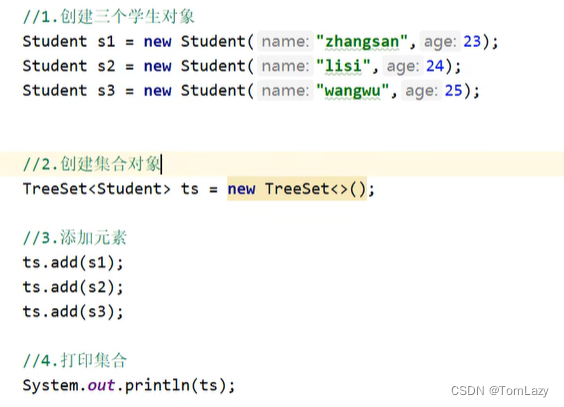
JavaBean:Student.java
测试类:
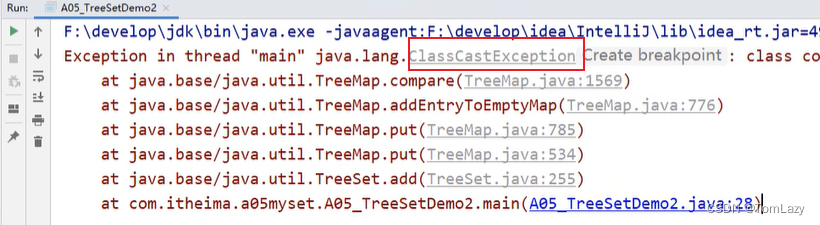
运行程序结构报错了:因为JavaBean是我们自己写的,并没有给它添加一个默认的比较规则,所以TreeSet也不知道应该怎么比
②、示例代码理解
图解:
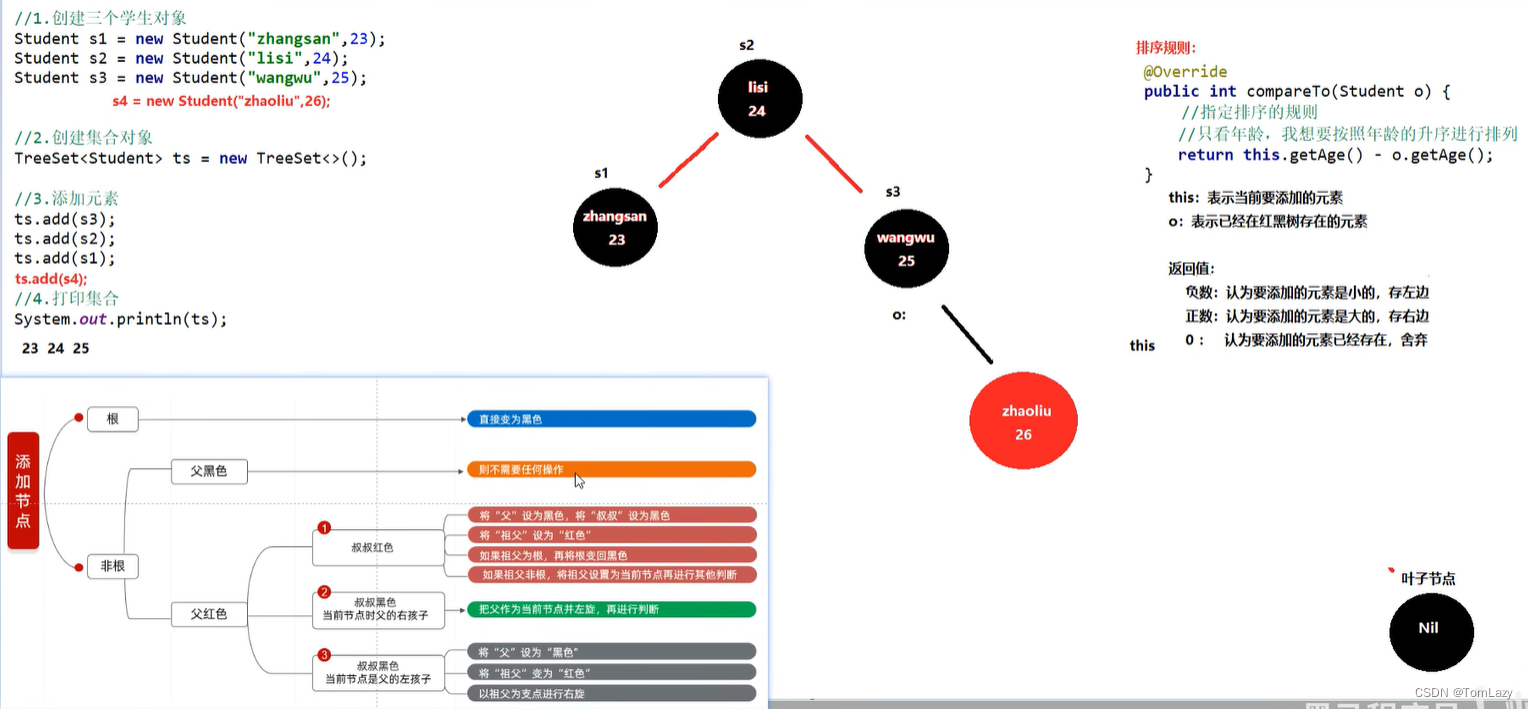
代码理解:
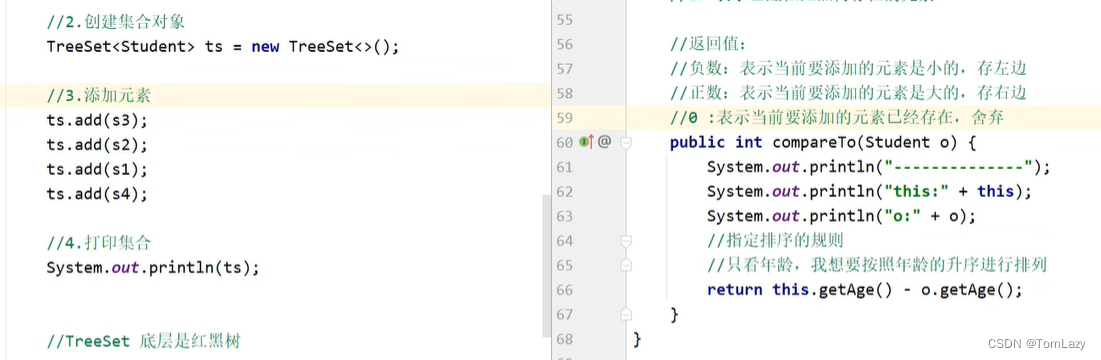
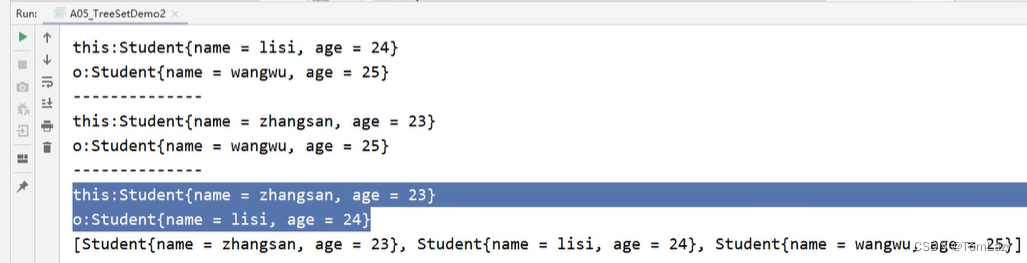
3、TreeSet的两种比较方式
 |
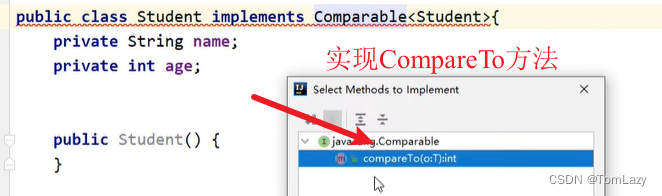
①、方式一:JavaBean类实现Comparable接口指定比较规则


②、方式二:比较器排序,创建TreeSet对象时,传递比较器Comparator指定规则
示例:

因为是String类型,源码中已经定义了排序规则:即以ASCII表升序排序
所以我们就需要使用比较器,重写比较方法

改成lambda表达式:

③、扩展:TreeSet对象排序练习题

idea快捷键:
- Ctrl + D :向下复制一行
示例代码:
JavaBean:Student.java
测试类:
默认排序情况:JavaBean实现Comparable接口,重现CompareTo方法

课堂练习:

在重写方法中加入System.out.println();语句即可
4、小结
如果方式一和方式二同时存在,那么实际上我们以方式二为准


5、Set集合源码分析
①、HashSet

HashSet其实是new了一个HashMap
②、LinkedHashSet

LinkedHashSet其实是new了一个LinkedHashMap
③、TreeSet

new了一个TreeMap
十二、集合的使用场景


![[软件工程导论(第六版)]第2章 可行性研究(复习笔记)](https://img-blog.csdnimg.cn/ab5c2ac9ee824fe2bb1870872448a125.png)