目录
退出码
终止进程
进程等待
进程程序替换
自己实现简易shell命令行
内建命令
退出码
在编写代码时main函数内部我们通常都使用return 0;结尾,以此标识正常退出。这里的return 0就是所谓的退出码,Linux下也是一样:

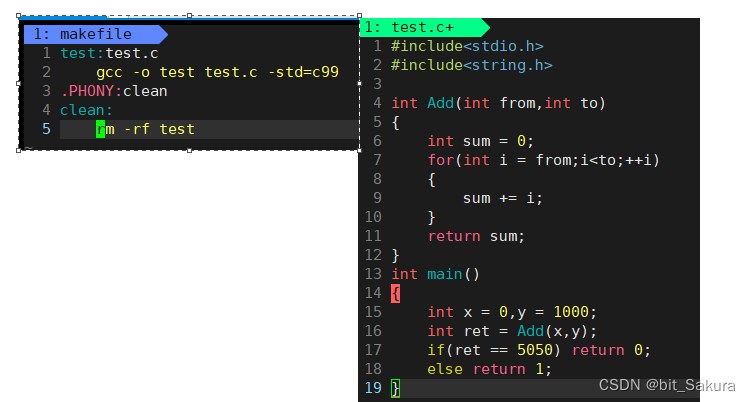
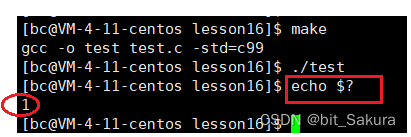
看这个小程序,当Add函数返回值是5050时return 0正常退出,当返回值是其它值时return 1标志程序有错误异常退出。
Linux下可以通过 $? 获取退出码。echo $?得到退出码为1.
$?:记录最近一个进程的退出码(注意是进程)。所以第一次echo $?得到的是1,再 echo $? 得到的是0:
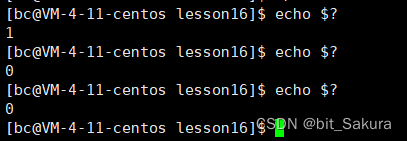
如果返回值为0标识正常退出没必要说明原因,但异常退出的话要说明原因哪里有错误。
return 0:正常; return 其它:异常。
退出码必须有对应的文字描述,可以是自定义的,也可以使用系统映射的(不太频繁)。
之前学习C语言的时候就有一个可以打印错误码的函数strerror。
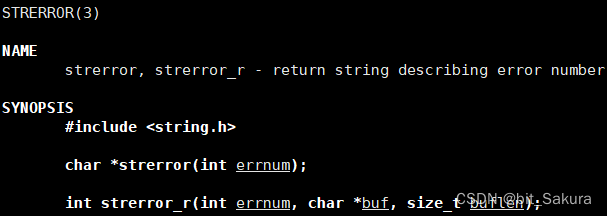
我们来看看Linux系统映射的错误有哪些:
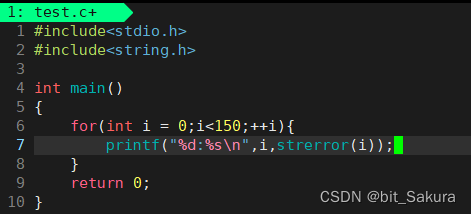

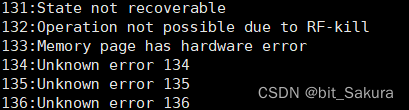
Linux下一共有133条错误返回信息。
终止进程
程序在系统中一般是3种状态:
1、代码运行完结果正确,return 0;
2、代码运行完结果错误,return !0;退出码在这个时候起效果。
3、代码没运行完程序异常,此时退出码无意义。
终止进程的3种方法:
1、main函数中return 终止进程。
2、exit() 可以在任意位置终止进程。
3、_exit(), 是库函数exit的底层。
方法一上面已经说过了,先来看一下exit():

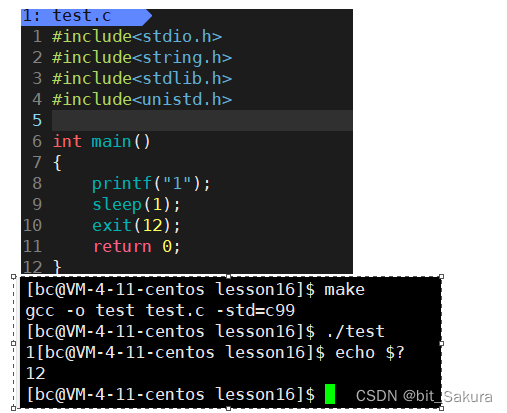
exit() 参数是status状态。在Linux操作系统中以整数代表状态,对应终止进程信息。
exit是库函数,而_exit是系统调用,exit调用的就是底层的_exit,那么两者还有什么区别呢?
来看上面的程序,因为打印的时候没用\n,数据先加载到缓冲区,过了一秒后程序终止打印到显示器上。
如果换成_exit:
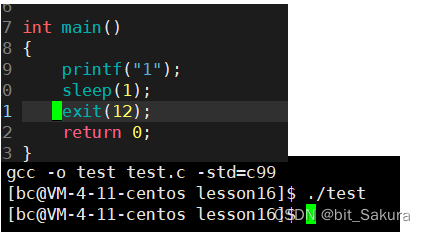
我们发现没有任何打印,所以得出结论:
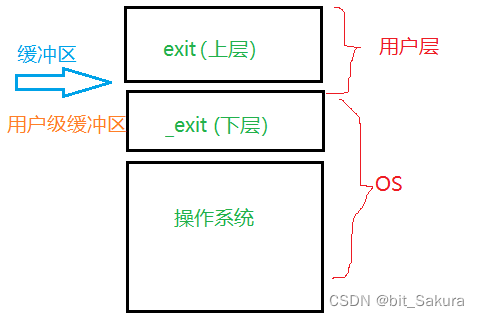
exit函数终止进程,主动刷新缓冲区;_exit 函数终止进程,不会刷新缓冲区。
那么缓冲区在哪也可以大致明确了,既然exit 在上层,而_exit 在下层,并且前者可以刷新后者不能,那么缓冲区就介于两者之间。
进程等待
我们知道僵尸进程对操作系统是有危害的,会长时间占用内存。今天我们来解决一下这个问题,就是用到进程等待。
那么进程等待的原因是:回收子进程资源,获取子进程退出信息。
回收子进程资源
先来看一下操作系统是如何回收子进程资源的:
这里要介绍一个系统调用函数wait:
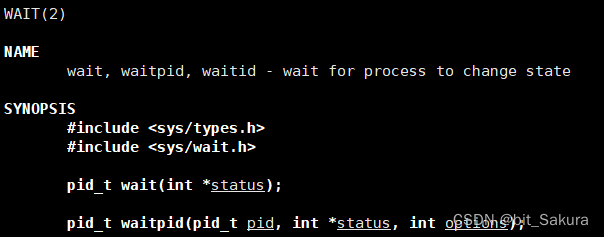
通过wait接口让父进程等待子进程就能回收子进程资源。
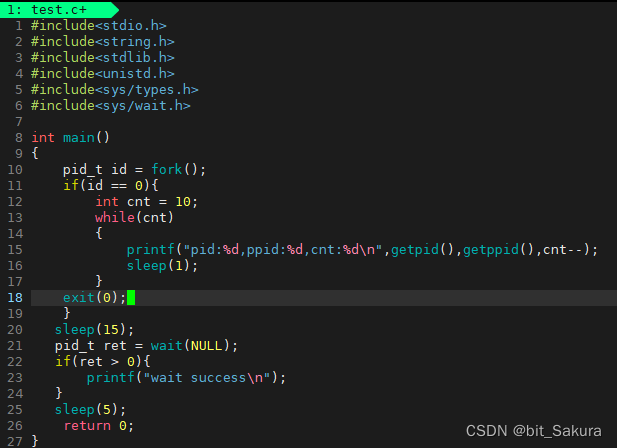
写完程序make编译,分屏,左侧运行可执行程序,右侧执行下面监督脚本:
while :; do ps ajx | head -1 && ps ajx | grep test | grep -v grep; sleep 1; done

在子进程运行期间,父子进程都处于S+状态。

子进程退出后,变为僵尸状态,此时由于父进程在休眠,还没有回收子进程。

然后wait 函数等待子进程,将其资源回收,子进程的僵尸状态就结束了,只剩下父进程在运行。
以上就是wait 的回收过程。
获取子进程退出信息
获取子进程退出信息也有对应的系统调用接口waitpid:
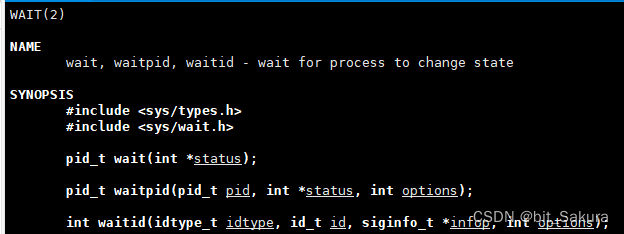
waitpid头文件和wait一样有两个:#include<sys/types.h> #include<sys/wait.h>
参数有3个,第一个是要获取的对应进程pid,你传谁那就等待获取谁,第二个是status,获取退出信息(重点谈论),第三个是option,现在我们默认设为0,表示阻塞等待。
返回值pid_t > 0 则返回的是等待的进程的pid,如果为-1则表示等待失败。
下面我们来看一下waitpid的实际应用,还是以上面的代码为例:
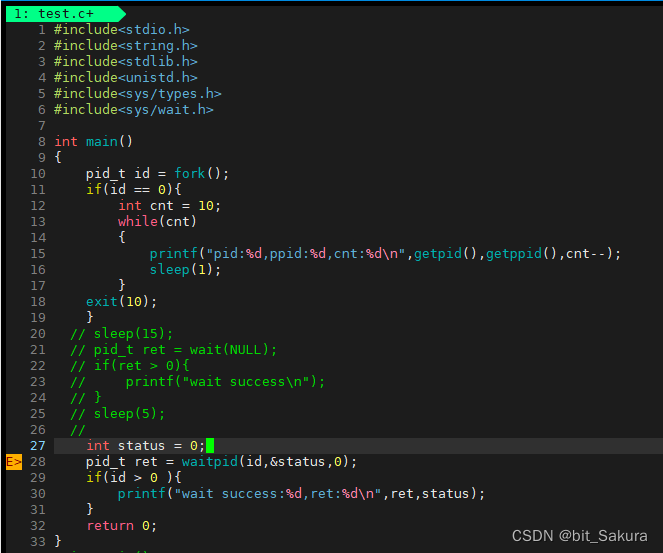
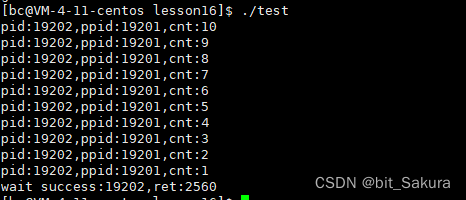
waitpid的返回值没问题,就是子进程pid,但是status的退出信息不对。
这是因为status不是被整体使用的,有自己的位图结构。听起来比较抽象,画个图理解一下:
上面说了,进程退出有3种情况:
1、代码跑完,结果正确;
2、代码跑完,结果错误;
3、代码没跑完,异常。
status就用来表示这三种状态,下图是status的二进制结构:
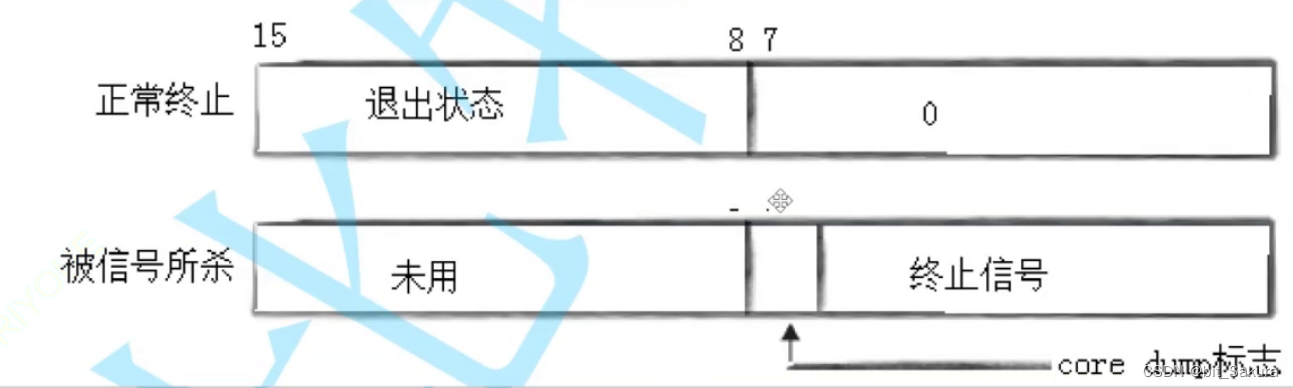
整数status有32个比特位,我们只关心它的低16个比特位。低位0~6表示进程终止的信号,如果信号是0就表示正常退出,非0就表示异常终止。kill -l 可以查看终止信号:
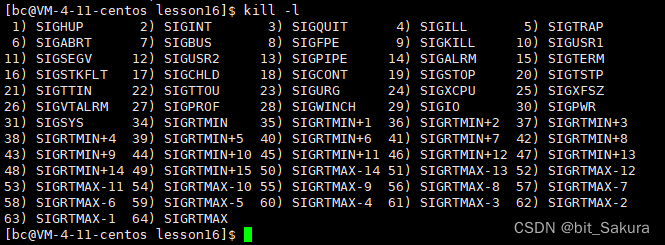
次低位8~15表示子进程退出状态。如果终止信号为0(正常退出)再对应到子进程退出状态.
下面我们再改一下刚刚写的程序,将进程终止信息和子进程退出状态打印出来。

status & ox7F: 拿到低7位(终止信号),(status >>8) &oxFF: 拿到次低位(退出信号)。
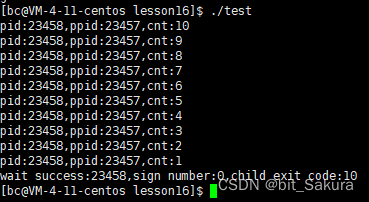
sign number终止信号是0,表示正常退出。child exit code退出信息号是10,错误信息是10(可以自己定义错误信息)。
下面再谈一下僵尸进程。一个子进程退出的时候变成僵尸状态,它的代码和数据是不会被操作系统保留的,但是它的PCB及退出信息会被保留下来,等待被父进程接收。

waitpid是系统调用,系统调用是操作系统级的接口,相当于使用操作系统的代码。status是一个整数,存放子进程的退出信息。父进程检测子进程的退出信息,子进程将保存在PCB中的exit code 和sign number 交给status,通过status拿回来放到&status中。
在获取子进程的退出结果过程中,使用status & ox7F 这样的位操作其实并不方便,操作系统给我们提供了一些宏,下面我们介绍其中两种:

WIFEXITED:当子进程正常退出返回真;
WEXITSTATUS:WIFEXITED返回真,则获取子进程退出码。
下面我们使用这种方式来获取子进程的退出码:
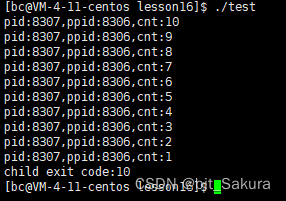
以上是阻塞等待的情况,子进程退出变为僵尸,父进程会一直等待子进程接收它的退出信息,期间不会干其他事情。
还有一种情况是非阻塞等待,父进程会对子进程的状态进行检测,如果子进程没有就绪立即返回不会等待,过一会再检测还是一样,每一次都是一次非阻塞等待,进行多次轮询,期间父进程可以执行其它操作。


非阻塞等待的好处就是不会占用父进程所有资源,期间它可以执行其它操作。
那是不是非阻塞等待比阻塞等待要好呢?————其实这种比较并没有意义,要看具体场景下使用哪一种了,如果父进程没有其它任务就用阻塞等待,现实中往往阻塞等待用的多一点。
进程程序替换
首先问个问题:为什么要创建子进程,有什么目的?
1、想让子进程执行父进程代码的一部分 ------> 执行父进程磁盘代码中的一部分。
2、想让子进程执行一个全新的程序 ------> 让子进程加载磁盘上指定的程序,执行新程序的代码和数据。
其实上述过程就是进程的程序替换。
要么进程的程序替换具体是怎么做到的,我们来看一下。
下面有6个常见函数,可以实现程序替换。

先看一下第一个函数execl,它可以将指定程序加载到内存,让指定进程来执行。
我们知道,要将程序加载到内存首先要找到该程序的位置,环境变量PATH就是帮助我们找到对应程序位置的,这里由函数的第一个参数path来做;
找到位置后执行,指令后带cmd选项,如ls -l,ls -a....这由第二个参数arg来做;
第三个参数 ... 是可变参数列表,在printf、scanf函数中见到过。它也是决定程序怎么执行的。
下面看段代码来了解一下该函数的具体用法:
一开始进程正在运行,execl函数将/usr/bin/ls 加载到内存,并附带-l 等选项执行。也就是将程序替换成了ls -l 执行。
再来看一下execl函数的参数,const char* path传的是对应要加载到内存的程序路径,const char* arg传的是程序执行方法,在命令行怎么执行这里就怎么传,后面还可以添加选项传进来,最后以NULL结尾,所有exec*系列函数都以NULL结尾表示传参结束。
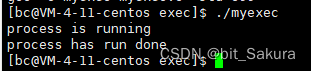
运行结果:
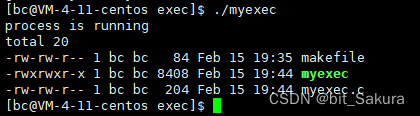
可以看到确实替换了程序,而本来应该在最后打印的process has run done没有打印出来,这是为什么看了下面我们就知道了。
程序替换的原理
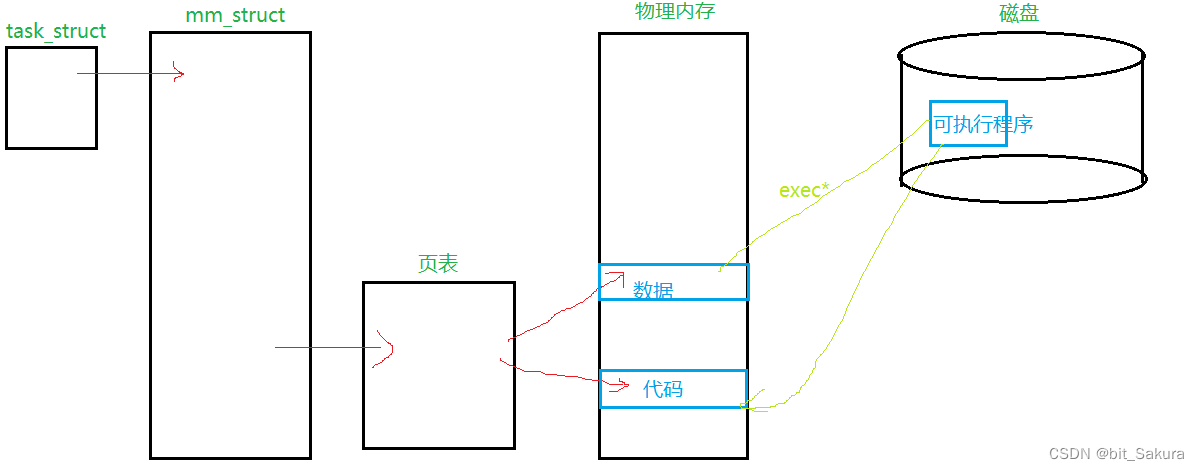
程序替换的本质,就是将指定程序的代码加载到指定的位置,覆盖自己原来的数据和代码。
所以现在就可以解释上面的问题了,最后的printf内容没有打印出来是因为程序替换后,原来的数据和代码被新的覆盖了,因此没有显示出来。
如果我们要替换的程序不存在呢?
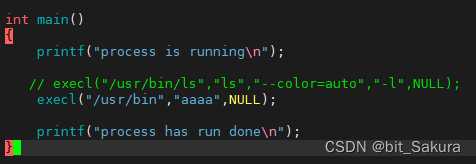
要替换的程序不存在,execl函数执行失败,不会进程程序替换,还是执行原来的程序。
来看一下execl函数的返回值:
![]()
execl 只有在执行错误的时候才有返回值-1,成功的话没有返回值,因为不需要——成功执行会程序替换覆盖后面的代码,那返回值就没有意义了。所以execl函数只要返回了那一定是执行出错了,可以用perror("ececl") 获取错误信息:
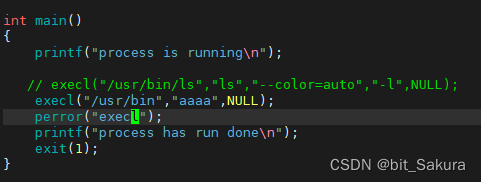
当然,在实际操作中不会像上面那样写,我们一般是创建一个子进程来进行程序替换,因为进程是独立的,子进程不会影响父进程。
程序替换成功:
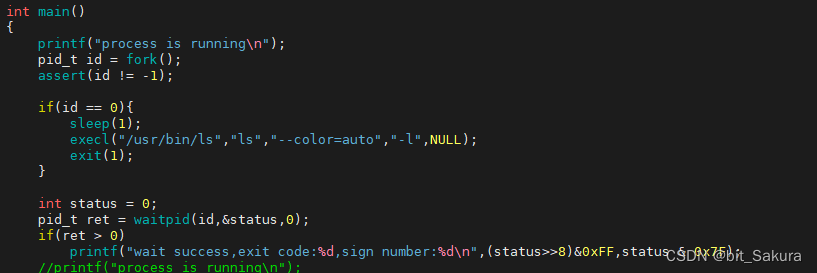

这时终止信号为0,正常退出,退出码为0,程序替换成功。
程序替换失败:
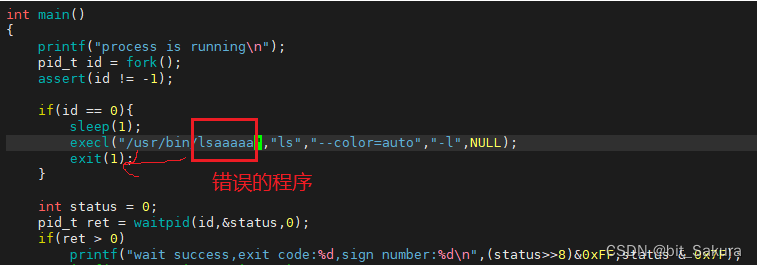
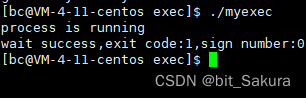
这时终止信号为0,正常退出,退出码为1,程序替换失败。
如何保证子进程程序替换不会影响父进程呢?上面说了是由于进程的独立性保证的,还记得之前说过一个写时拷贝的概念吗?这里是一个道理。
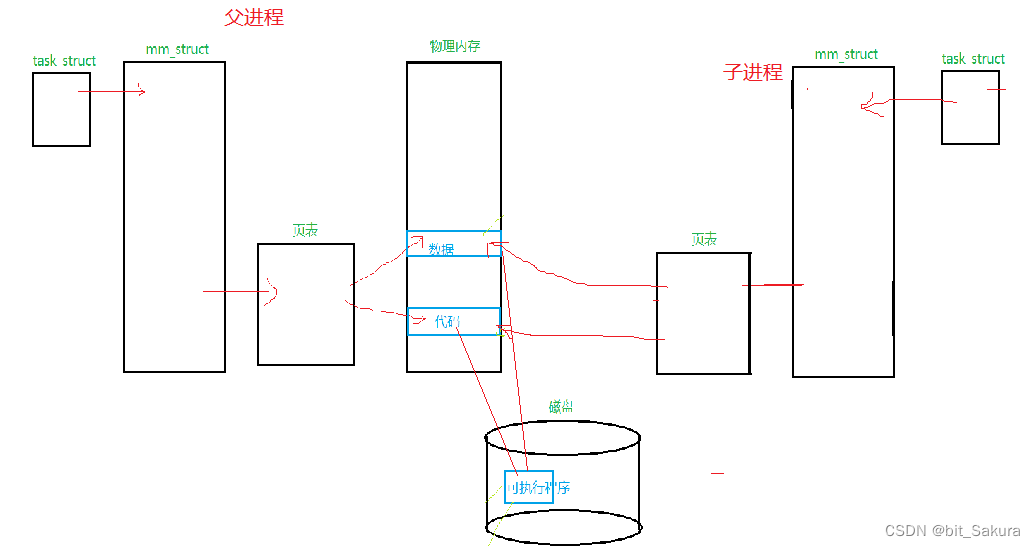
子进程的PCB、代码、数据都是根据父进程拷贝过来的,通过各自的页表映射到物理内存上,对应的数据和代码也都一样。当子进程要改变对应的数据时,操作系统会进行写时拷贝,将对应数据拷贝给另一块空间,让子进程页表指向新的空间,再更改数据,同理代码也是一样,可以写时拷贝,于是这样就保证了进程的独立性,不会互相影响。
其它exec*的函数

上面介绍了execl函数,下面的也类似。
先来看一下execlp函数:
![]() exe:可执行程序; l:list列表,将参数一个一个传入exec*; p : path环境变量,带p字符的函数不需要输入程序的路径,只要传入程序是谁,就能自动在环境变量PATH中自动寻找。
exe:可执行程序; l:list列表,将参数一个一个传入exec*; p : path环境变量,带p字符的函数不需要输入程序的路径,只要传入程序是谁,就能自动在环境变量PATH中自动寻找。
演示: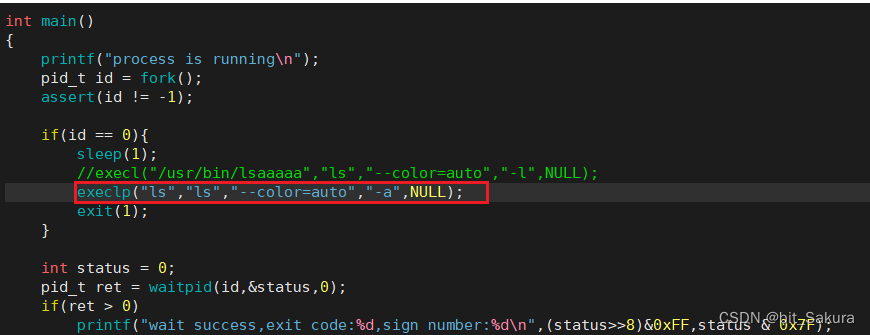
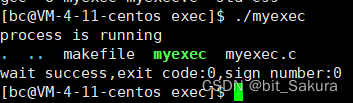
execlv函数
![]()
最后一个v :vector的意思,该函数相较于上面两个,少了一个参数... 也就是可变参数列表,因为vector代替了它,我们可以将本来要传入可变参数列表的选项放进argv[ ]数组中。
演示: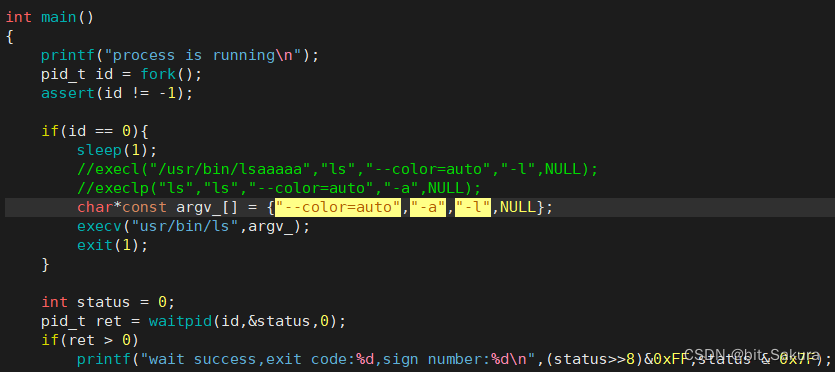
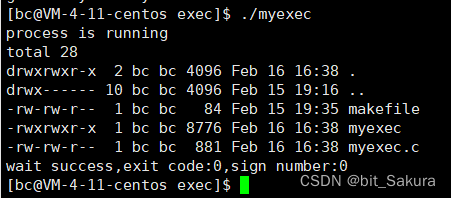
上面char* const argv_[ ]中报了警告,可以强转成char*类型,也可以先不管。
execvp函数:
![]()
显然是上面两者结合,这里演示一种结合main函数的用法。
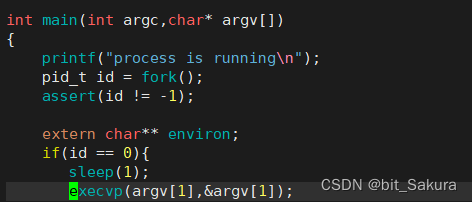
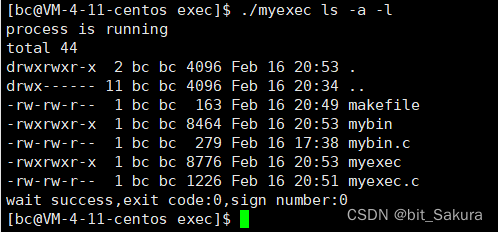
execvp可以直接使用main函数传入的参数,argv[0]就是当前程序,argv[1]就是当前程序的下一条要替换的程序。怎么执行?从argv[1]处开始执行。
./myexec ls -a -l:要执行后面的ls -a -l
execle函数:
![]()
最后一个e:env环境变量,该函数可以自己导入环境变量。
在演示execle之前先来看一下execl函数能不能在调用我们自己写的程序的时候导入自定义环境变量:
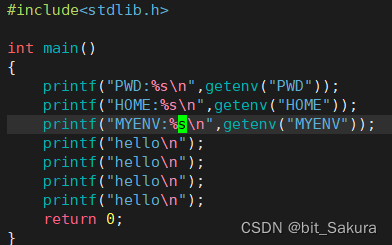
在mybin.c中打印3条语句,其中PWD, HOME是系统环境变量,MYENV是自定义环境变量。
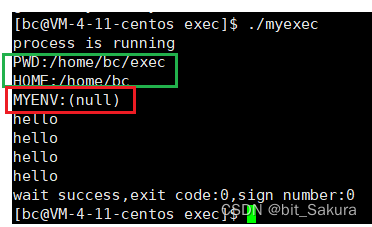
可以看到系统环境变量被打印出来了,自定义环境变量显示为null,此时我们想导入自定义环境变量可以使用execle函数。
它的第4个参数envp[ ] 就是给我们传环境变量的。
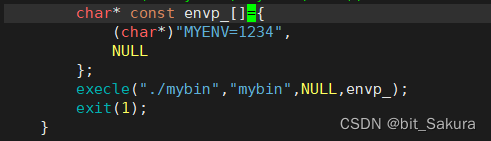
在数组envp_中放入自定义环境变量,再在函数中传入数组名调用。
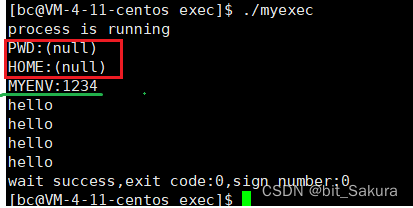
我们发现自定义环境变量确实被导入打印了,但是系统环境变量此时却没有导入。
所以这种传参方式只能导入自定义环境变量,对系统环境变量不适用。
那么如何既导入系统环境变量又导入自定义环境变量呢?
environ可以帮助我们得到系统环境变量:

记得外部声明extern一下,否则会报错。
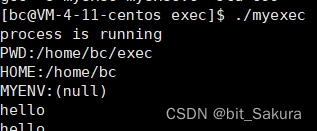
此时系统环境变量是有了,但是自定义环境变量又没了。
我们刚刚不是用envp_[ ]数组导入了吗,那是因为自定义环境变量和系统环境变量没有关系,设置了自定义环境变量里面没有自带系统的,是自己搞出来的一套环境变量。
其实环境变量就算不传,默认子进程也能获取。现在我们既想导入自定义的也想导入系统的,可以使用putenv:
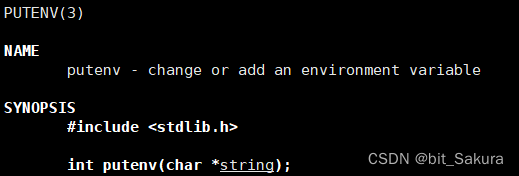
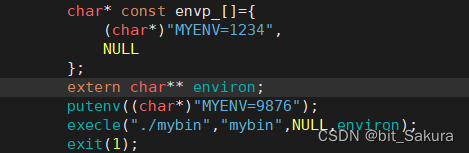
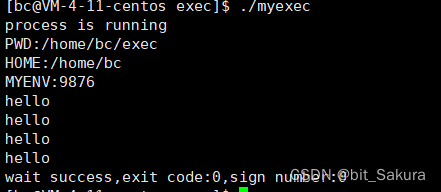
putenv就是将自定义环境变量导入到系统中,environ指向对应的环境变量表。
这样就导入了系统环境变量+自定义环境变量。
execve函数:
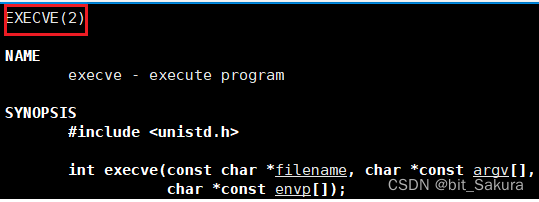
查看man手册发现,execve是2号手册,也就是系统调用接口,而刚刚上面讲的所有exec*函数都是3号手册,也就是库函数。实际上确实只有execve是系统调用,其它都是根据它封装而来的,便于用户选择对应函数使用。
这里再提一点:main函数和execl谁先执行的呢?
————有人说,肯定是main函数呀,它是程序执行的入口。其实不是!
我们的程序在执行前要先加载到内存,是如何加载到内存的呢?liinux下就是用到exec*系列的函数!我们 ./程序能够运行其实就是用到exec*函数帮助加载,也叫加载器。
所以显而易见,这里是execl先于main函数执行。main函数也是函数,也要被调用,也要传参。
传参传的是什么?

其实也就是exec*的参数传给main函数,就算我们不主动传环境变量env,main函数也会默认获取。
自己调用自己的程序
上面我们是在调用系统的指令(程序),下面我想调用一下自己写的程序。
首先,除了刚刚的那个程序(调用者)外还要再写一个小程序(被调用者),在makefile文件中要将依赖关系和方法明确一下,使得两个程序都能被编译运行:
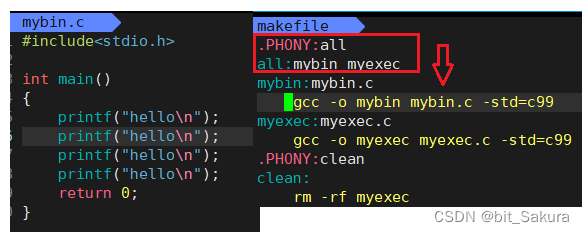
make默认只会执行第一条依赖方法。所以为了让mybin.c和myexec.c都能编译我们在开头加一个依赖关系all,.PHONY特点是总是被执行,所以给出.PHONY:all,再让all依赖于mybin和myexec就能使得两者必定被编译。
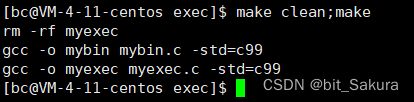
在myexec.c中调用execl函数,执行当前路劲下的 mybin可执行程序:

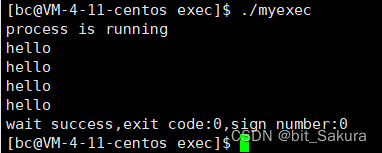
这样就实现了自己调用自己的函数。而且我们不仅可以用execl调用C++写的程序,JAVA、Python也都可以调用。
总之,程序替换可以调用任何后端语言的可执行程序。
自己实现简易shell命令行
结合上面的内容,我们可以自己实现一下shell命令行替换程序的过程。
首先创建makefile和myshell.c文件并建立依赖关系等操作不说了。
vim myshell.c:

首先要打印命令行提示符,因为没有 \n不会立刻刷新缓冲区,所以fflush手动刷新一下。
如何接收输入的命令?————fgets函数:
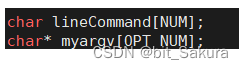
#define NUM 1024
char lineCommand[NUM];

从输入流输入到lineCommand数组中,大小比lineCommand小1,预留空间。获取输入流返回不为NULL,否则失败。
写一个打印查看是否能接收输入命令:
printf("test :%s\n",lineCommand); 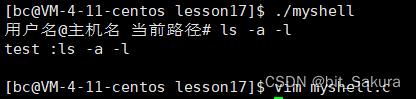
可以接收输入命令,但是多了一条空行,原因是用户输入的时候会按 "回车",系统换行本来就有一个 \n了,这样就多了一个,所以这里我们去掉最后一个 \n:

命令读取后就是解析的过程了。而解析的过程中需要把一整串字符串命令分割,比如 "ls -l -a"需要分割成3个短字符串 "ls","-l","-a"。
这里要用到字符串分割函数strtok.
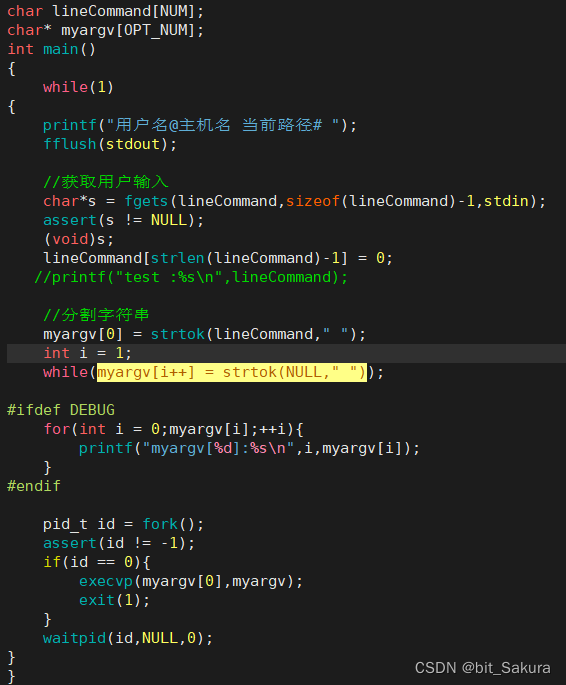
以空格为界,先分割第一部分字串,创建指针数组myargv,将对应字串放入指针数组:
myargv[0] = strtok(lineCommand," ");如果没有字串了,strtok会返回NULL,而myargv[end]也是NULL,所以根据这点就可以用循环实现字符串整体分割:
myargv[0] = strtok(lineCommand," ");
int i = 0;
while(myargv[i++] = strtok(NULL," ");然后我们测试一下,使用条件编译:
#ifdef DEBUG
for(int i = 0;myargv[i]; ++i)
{
printf("myargv[%d]:%s\n",i,myargv[i]);
}
#endif
当不需要测试只保留条件编译时,在-DDEBUG前加 #
最后命令行解释器不会只跑一次,所以将其整个套在死循环中:
完成输入,分析指令后,接下来是执行指令。
这里执行的话用刚刚讲的6个函数进行子进程程序替换。
首先创建进程,如果是子进程就执行程序替换,用exec*系列的哪一个函数呢?
————execvp,该函数第一个参数是const char* file,也就是不需要路径直接说明指令是谁,第二个参数是argv[ ],和我们这里的myargv[ ]正好适配。
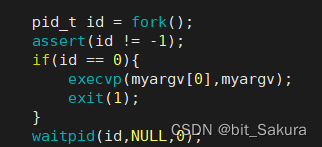
最后父进程等待回收子进程即可,并且不需要关心退出信号。
运行一下:
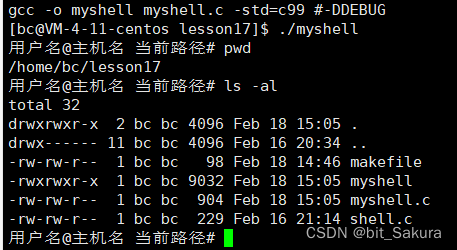
内建命令
在该环境下执行cd命令时,发现路径不会改变:
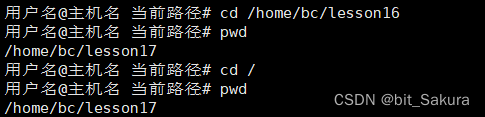
首先要了解一个东西叫当前路径和工作路径:
写一个简单的程序,运行起来查看它的信息:
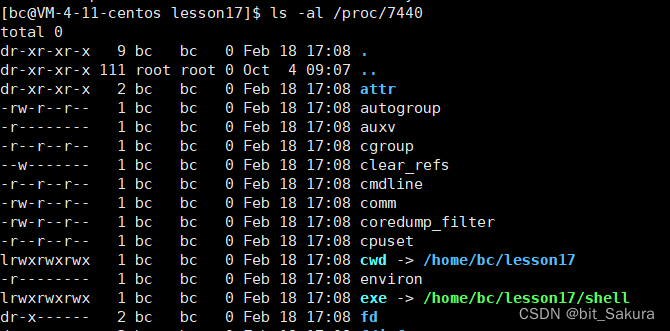
ls -al /proc/7440:proc文件系统是动态从系统内核读出所需信息的,现在查看7440进程系统内存信息,有两个引人注目的文件:cwd 和 exe.
exe我们都知道,是可执行的意思。它告诉用户当前进程执行的是磁盘路径下的哪一个文件。
cwd则是当前工作目录,它就是当前路径。默认在哪个路径下执行某个进程,那它的工作目录就是当前所在路径。并且它可以被修改,用到chdir函数:
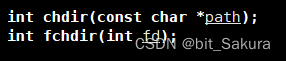
在刚刚写的小程序开头调用chmir函数,修改对应路径:
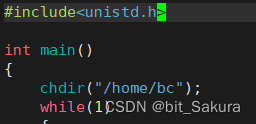
再次ls -al proc/10136:
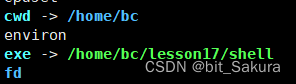
我们发现工作目录确实改变了。
那这和我们简易实现的shell中cd有什么关系呢?
我们fork进程,子进程执行cd命令,子进程有自己的工作目录,cd更改的是子进程的目录,而子进程执行完了就被回收了,shell(父进程)继续运行下去,所以工作目录不会变。
现在我想在myshell.c程序中改变cd的路径:
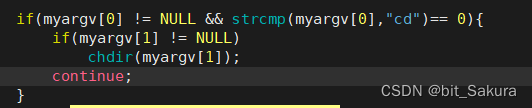
如果输入不为空并且输入指令是cd,cd 目录也不为空,就改变工作目录,改完后继续执行当前程序。
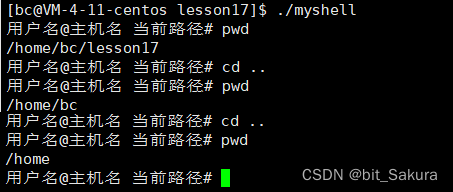
像cd命令,不创建子进程,让shell自己执行对应的命令,本质就是执行系统接口。
像这种不需要我们自己来执行,而是让shell来执行的命令,叫做内建 / 内置命令。
也就是由 Bash 自身提供的命令,而不是文件系统中的某个可执行文件。
比如之前说的echo之所以能打印非系统环境变量,也是因为它是内建命令。
![[软件工程导论(第六版)]第2章 可行性研究(复习笔记)](https://img-blog.csdnimg.cn/ab5c2ac9ee824fe2bb1870872448a125.png)

![[软件工程导论(第六版)]第2章 可行性研究(课后习题详解)](https://img-blog.csdnimg.cn/0c584c9349d84780a21f6ff72fdadddf.png)