用户接入了jmx agent进行prometheus监控后,在某个时间点出现cpu飙高
排查思路:
1、top,找到java进程ID
2、top -Hp 进程ID,找到java进程下占用高CPU的线程ID
3、jstack 进程ID,找到那个高CPU的线程ID的堆栈。
4、分析堆栈信息
通过排查思路,找到了是jmx prometheus的线程:
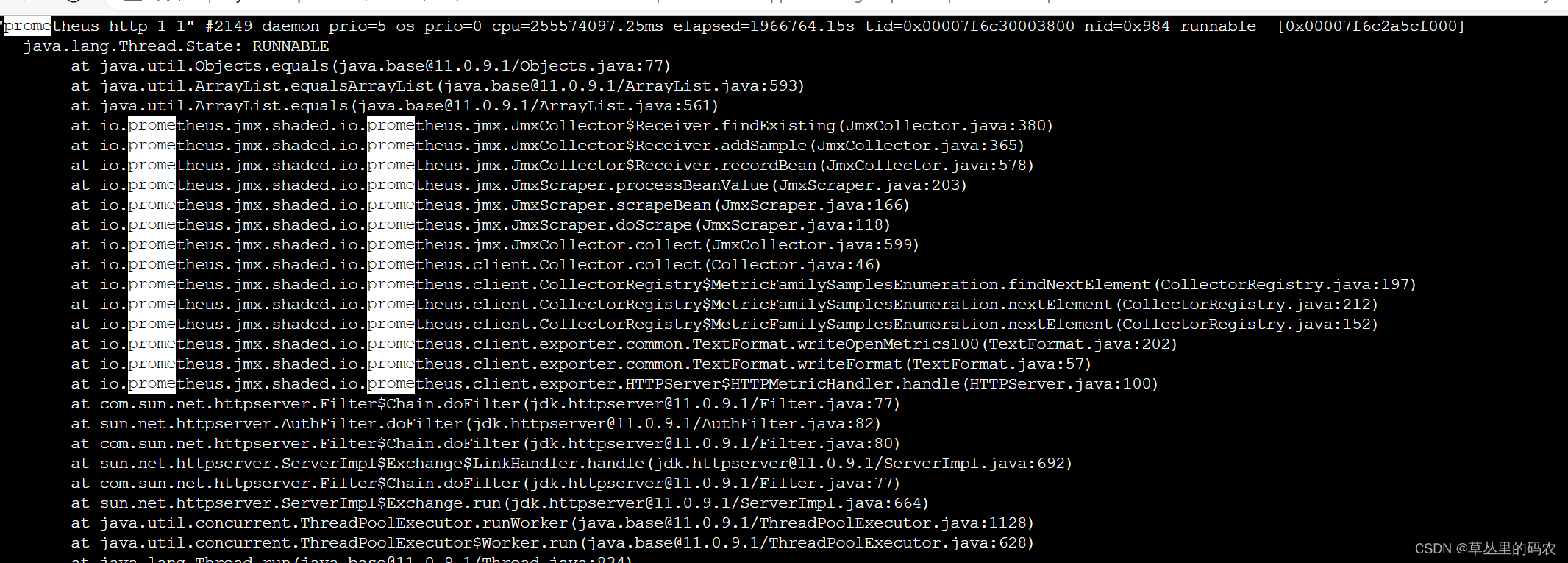
jmx prometheus的源码:

这里只有for循环,很简单的逻辑,所以我们在思考会不会数据量太多了。
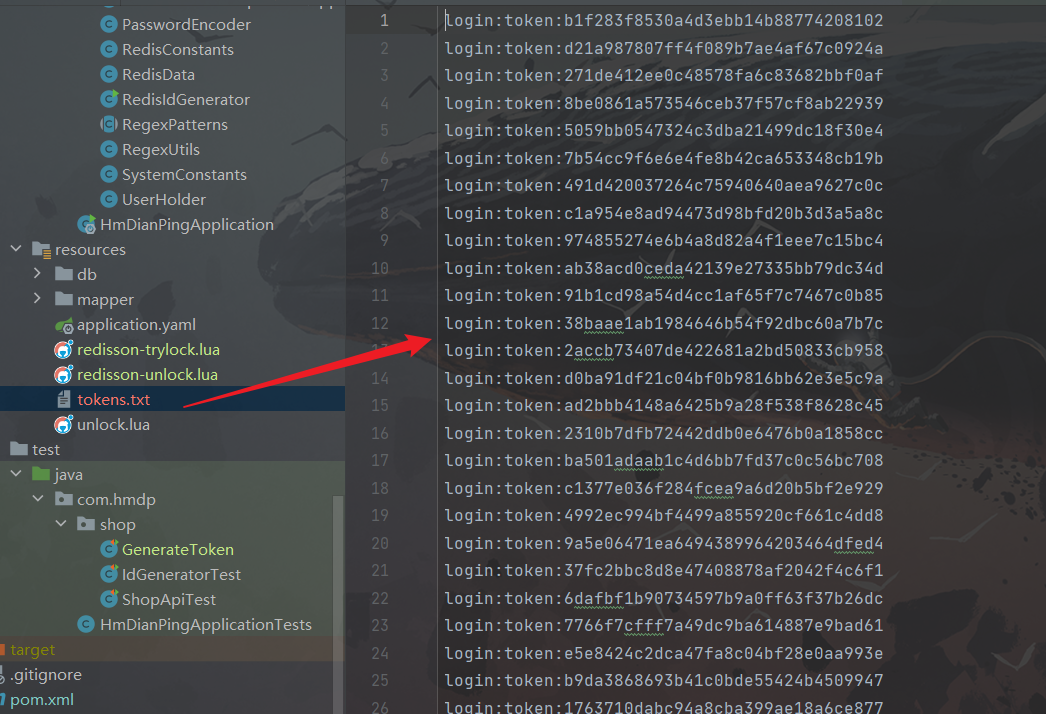
通过arthas查看方法返回数据:
watch io.prometheus.jmx.$ findExisting ‘{params,returnObj,throwExp}’ -n 5 -x 3
查看meban数据大小

prometheus 数据:kafka的客户端id一直在变,所以猜想是不是数据量越大prometheus就会越大
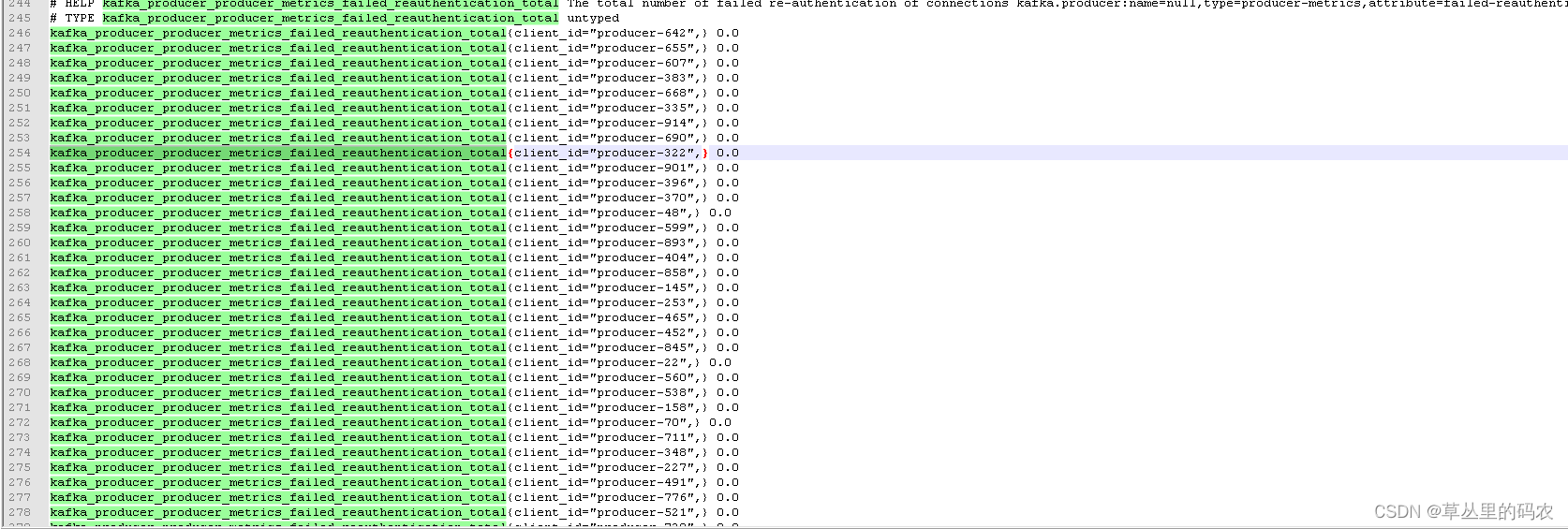
结论:kafaka 消费数据量比较大的时候,jmx 数据就会比较大。jmx prometheus默认的逻辑是会读取全部的java mbean然后转换成prometheus 数据格式,mbean数据比较多的时候,循环就会比较多,cpu计算就会飙高。mbean中的数据有业务客户端的添加进去的,它的数据量是不可控的。
解决方案: 不读取所有的mbean数据,只读取指定的数据格式


![[AI生成图片] 效果最好的Midjourney 的介绍和使用](https://img-blog.csdnimg.cn/2b15ac6ad13043f2a0671a7630de957c.png)
![全网多种方式解决The requested resource [/] is not available的错误](https://img-blog.csdnimg.cn/32f638ced4f74da29fb5177a304cd320.png)