作者 | 太子长琴
整理 | NewBeeNLP
大家好,这里是NewBeeNLP。
今天分享一种简单的方法来提升语言模型的 Zero-Shot 能力——指示(或指令)微调(instruction tuning) ,在一组通过指示描述的数据集上对语言模型微调,大大提高了在未见过任务上的 Zero-Shot 能力。
模型 137B,在超过 60 个使用描述模板描述的数据集上微调。FLAN 在 20/25 个任务上超过了 175B 的 GPT3,Few-Shot 能力也大部分超过了 GPT3。消融实结果发现,微调的数据集数量、模型规模、指示,这三个因素是指示微调的关键。

Paper:Finetuned Language Models Are Zero-Shot Learners
Code:https://github.com/google-research/flan
背景
PLM 在 Few-Shot 上表现一般都很好,但是在 Zero-Shot 上就很一般了,一个潜在的原因是模型很难执行和预训练不一样格式的 prompt。FLAN(Fine-tuned Language Net)却通过「指示微调」实现了不错的效果,如下图所示:
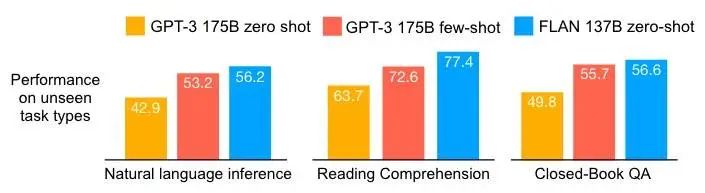
它具体是怎么做的呢,如下图所示:
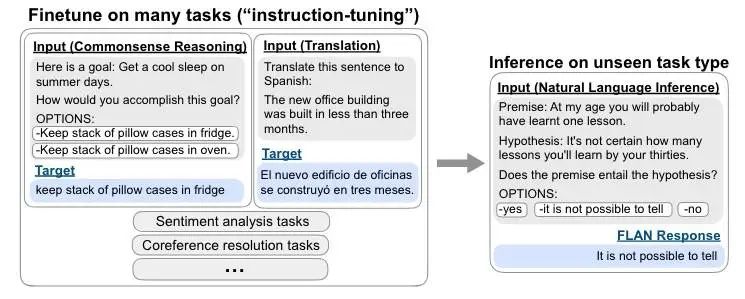
FLAN 在一组短语为指示的混合任务上微调预训练模型,比如上面的:Translate this sentence to Spanish。在推理时,对没见过的任务(上面的 NLI)使用 FLAN 进行实验。
那么「指示微调」和 T5/BERT 的微调,以及 Prompt 微调有啥区别呢,如下图所示:
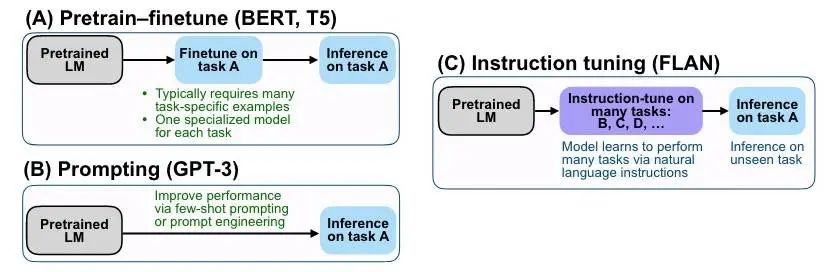
A 我们很熟悉,预训练模型最开始就是这么用的,当然现在很多时候也是这么用的。B 是需要语言模型给个 prompt 提示的。C 是 FLAN 的做法,主要是通过对多种任务的糅合学习 Zero-Shot 能力。
这里的「指示」和 GPT3 或 T5 的 Prompt 又有啥区别呢,我们看看下面这个例子:
T5 prompt:
cb hypothesis: At my age you will probably have learnt one lesson.
premise: It’s not certain how many lessons you’ll learn by your thirties.
GPT-3 prompt:
At my age you will probably have learnt one lesson.
question: It’s not certain how many lessons you’ll learn by your thirties. true, false, or neither?
answer:
FLAN prompt:
Premise: At my age you will probably have learnt one lesson.
Hypothesis: It’s not certain how many lessons you’ll learn by your thirties.
Does the premise entail the hypothesis?T5 的 prompt 更像是数据集的一个 Tag(上面的 cb hypothesis 和 premise),在 Zero-Shot 下由于是没见过的任务,所以模型并没有学到这种模式。
GPT3 的 prompt 看起来好像数据好像被训练过,模型来完成剩下的部分,这其实是 In-Context Learning。
FLAN 的 prompt 看起来好像是让模型去执行某个任务,它被形式化为对「指示」做出回应,所以如果不微调没法工作。这也算是对 MTL 无法 Zero-Shot 的一种增强补充。
FLAN
指示微调的初衷是提升语言模型对自然语言指示的响应能力。这个 idea 是使用监督信号来教语言模型执行通过指示描述的任务,语言模型学会通遵循指示后,即使对看不见的任务也可以响应。
任务和模板
FLAN 使用的任务和数据集如下:
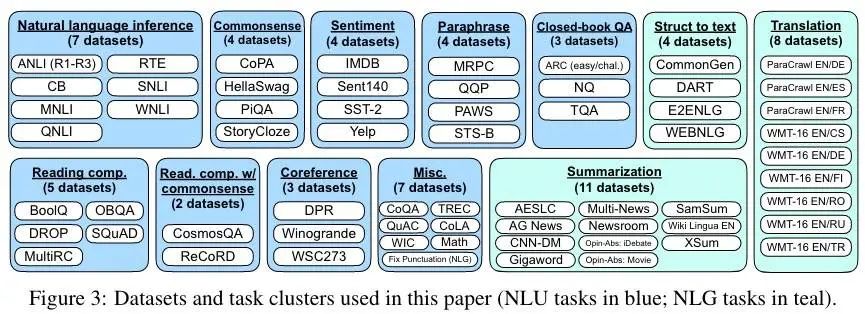
一共 62 个数据集,分成 12 个任务集。人工搞了 10 个模板,使用自然语言指示来描述数据集的任务。10 个模板大部分都描述了原始任务,但为了增加多样性,对每个数据集还包括最多三个「扭转任务」的模板(比如情感分类,包括要求生成电影评论的模板)。
下面是用于 NLI 数据集的多指示模板的例子:
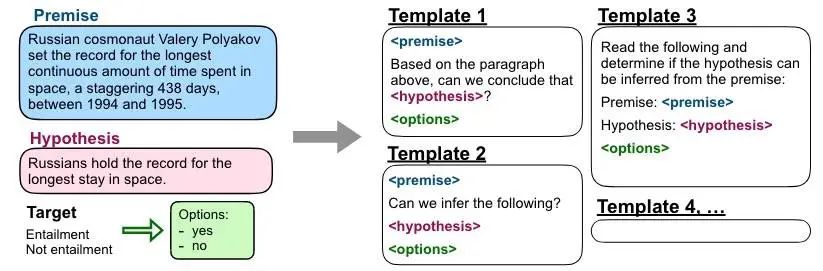
评估划分
这里采用了保守的做法,在 Figure3 中,数据集不属于同一个任务集的才算未见过。
分类任务
因为是生成结果,所以对分类任务要额外处理一下。有用 rank classification 方法(就是看哪个选项生成的概率高)的,但问题是有时候对某个选项的表达可能不止一种,导致实际选项的那个值概率很低。比如选项是「是/否」,但表达「是」的方式可能是「好/可以/没问题」等等。
FLAN 使用了 OPTION 后缀,将 OPTION 和输出的标签依次排在后面,让模型在响应分类任务时知道需要哪些选项。具体可以看本文第二张图中右边部分的例子。
训练细节
模型架构:
采用 LaMDA-PT,只有 decoder 的 transformer 模型,137B 参数。
指示微调:
为了平衡不同数据集大小,每个数据集样本数量限制在 30k,并使用 examples-proportional 混合方案,混合比例最高 3000,这里的 3000 意思是对超过 3000 个的样本,数据集不会收到额外的采样权重。
微调 30k 步
BatchSize=8192 Tokens
Adafactor Optimizer
LR=3e-5
输入和输出长度为 1024 和 256。
使用
packing将多个样本拼接成一个 sequence,输入和目标之间使用EOS分开。
实验
实验结果如下:
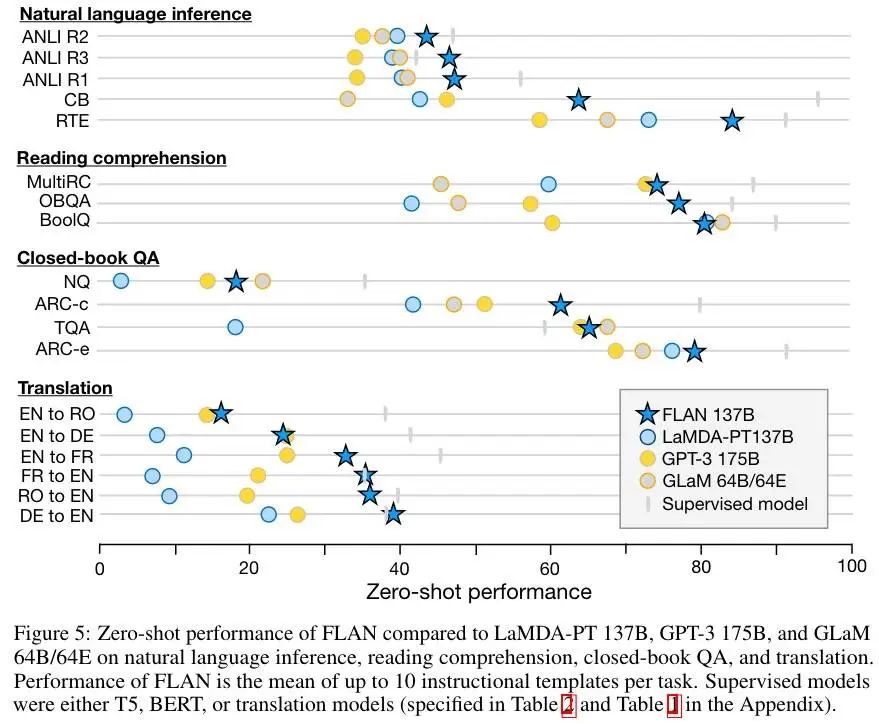
越往右分数越高。虽然在上面的任务集上效果还可以,但有个局限是对很多语言模型任务没有提升,如常识推理、以句子完成形式表示的共指解决任务。这说明,当下游任务与原始语言建模预训练目标相同时(即指示大部分时候是冗余的),指示微调是没用的。
消融
数据集和任务的数量
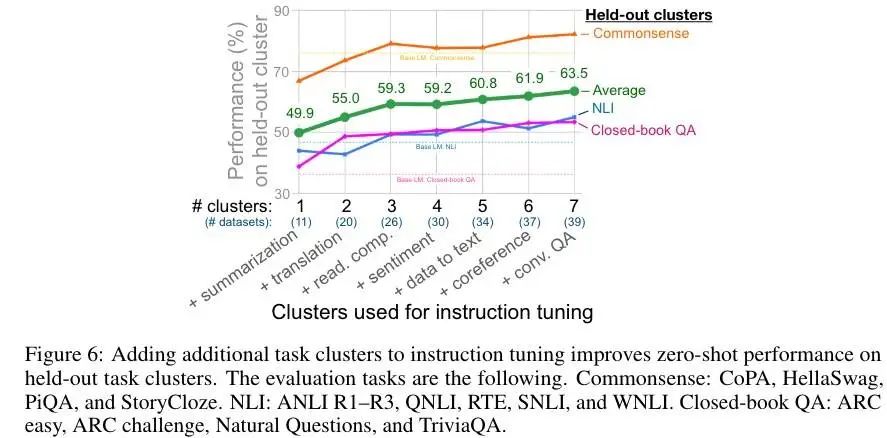
这里需要注意的是,这种消融无法得出哪个集群贡献最大。
模型规模
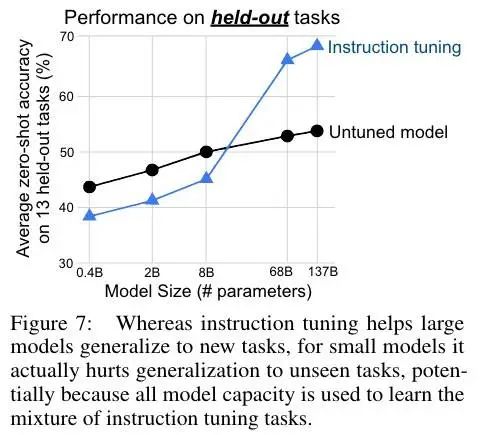
这个结果有意思了,在小模型(其实也不算小了)上居然还不如不微调。一个可能的解释是,对于小规模模型,微调期间使用的大约 40 个任务会填充整个模型的容量,导致这些模型在新任务上表现更差。相反,在大模型上,也会填充模型,但也教会模型如何遵循指示。
指示

使用指示训练是 Zero-Shot 能力的关键。另一方面也看到,简单地使用数据集名也具有一定指示作用,其实这也算是一种 prompt 了。
Few-Shot 作为指示
就是从训练集中选择 16 个样本和 Zero-Shot 的样本拼在一起,结果如下:
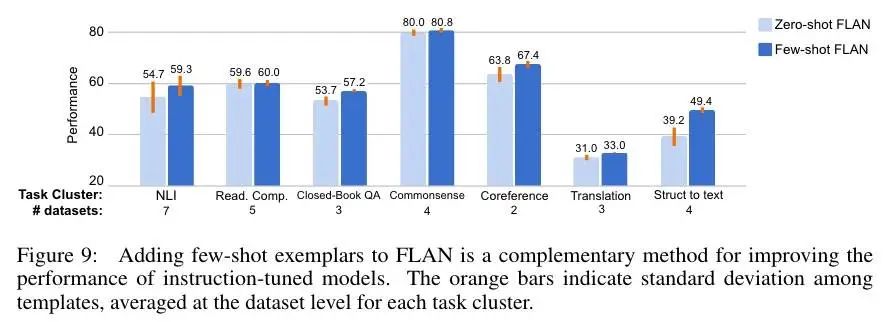
结果都提升了效果,尤其是在大/复杂输出空间的任务上,如 struct to text,翻译,closed-book QA 等,可能是这些样本帮助模型更好地理解输出格式。另外,Few-Shot 不同模板间标准差比较低(柱图上那个短短的竖线),表明对 prompt 的敏感性较低。
小结
本文探索了一个简单的方法来提升语言模型基于指示的 Zero-Shot 能力,FLAN 与 GPT3 相比具有优势,并表明大规模语言模型可以遵循指令的潜在能力。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)