系列文章目录
- LearnOpenGL 笔记 - 入门 01 OpenGL
- LearnOpenGL 笔记 - 入门 02 创建窗口
- LearnOpenGL 笔记 - 入门 03 你好,窗口
- LearnOpenGL 笔记 - 入门 04 你好,三角形
文章目录
- 系列文章目录
- 1. 前言
- 2. 渲染管线的入口 - 顶点着色器
- 2.1 顶点着色器处理过程
- 2.2 输入更多数据
- 3. VBO 顶点缓冲对象
- 3.1 顶点属性数据的存放方式
- 3.2 从 VBO 中获取数据
- 3.3 更进一步
- 4.VAO 与 VBO 之间的关系
- 5. 理解代码
- 6. 总结
1. 前言
在上一章 LearnOpenGL 笔记 - 入门 04 你好,三角形 中引入了很多很多概念,VBO、VAO、EBO、Shader 等等。密集的知识点向你轰炸而来,让这一章的难度陡然上升。说实话,这一章相当的劝退我。我心中有太多的困惑没有得到解答,文章虽然对 VBO、VAO 等做了解释,但其解释没有能让我这个入门者理解。以至于让阅读者相当的挫败。
今天我尝试将本章概念「幼儿园」化,站在入门菜鸟的角度,以伪代码的形式来理解 VAO、VBO 等概念。
2. 渲染管线的入口 - 顶点着色器
我们用 OpenGL 渲染一个三角形也好,渲染一个复杂的模型也好,无非就是输入一些顶点数据,得到一张图片。

Rendering pipeline 包含了多个阶段(这部分上一章有详细的说明),包括顶点着色器、几何着色器、片段着色器等等。
2.1 顶点着色器处理过程
其中,顶点着色器位于整个 Pipeline 的第一个阶段,所有顶点数据首先发送到顶点着色器中。它接收顶点坐标、颜色、纹理坐标等数据,并对这些数据进行变换,例如旋转、缩放、平移等,最终将处理后的顶点数据传递给后续的渲染步骤。
以渲染一个三角形为例,它的顶点着色器代码非常简单:
const char *vertexShaderSource = R"(
#version 330
layout (location = 0) in vec3 aPos;
void main()
{
gl_Position = vec4(aPos.x, aPos.y, aPos.z, 1.0);
}
)";
float vertices[] = {
-0.5f, -0.5f, 0.0f,
0.5f, -0.5f, 0.0f,
0.0f, 0.5f, 0.0f
};
其中 vertices[] 中存放了三个顶点的位置,而观察顶点着色器的代码,却发现它只处理了一个顶点。这是我的第一个困惑:OpenGL 是如何渲染多个顶点的?
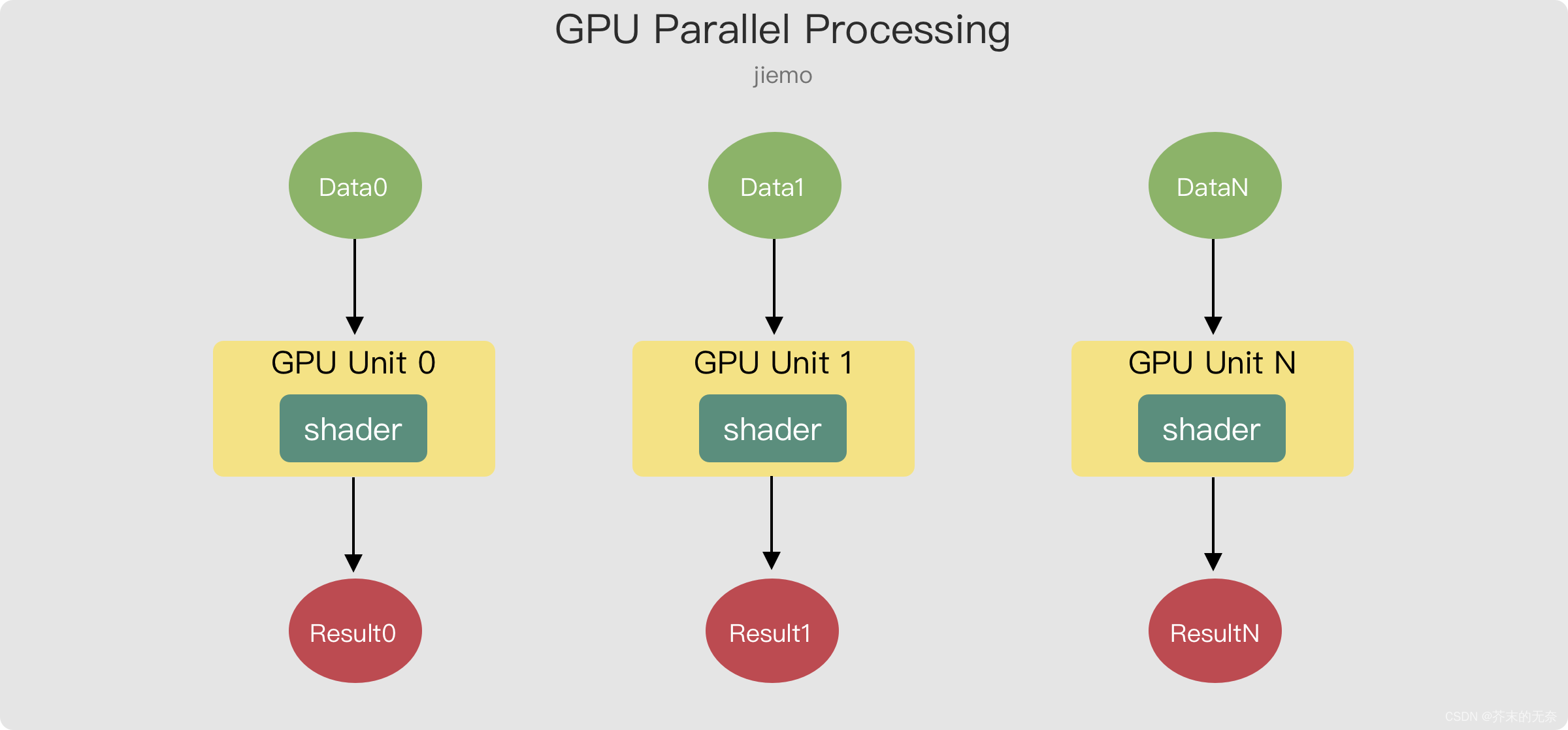
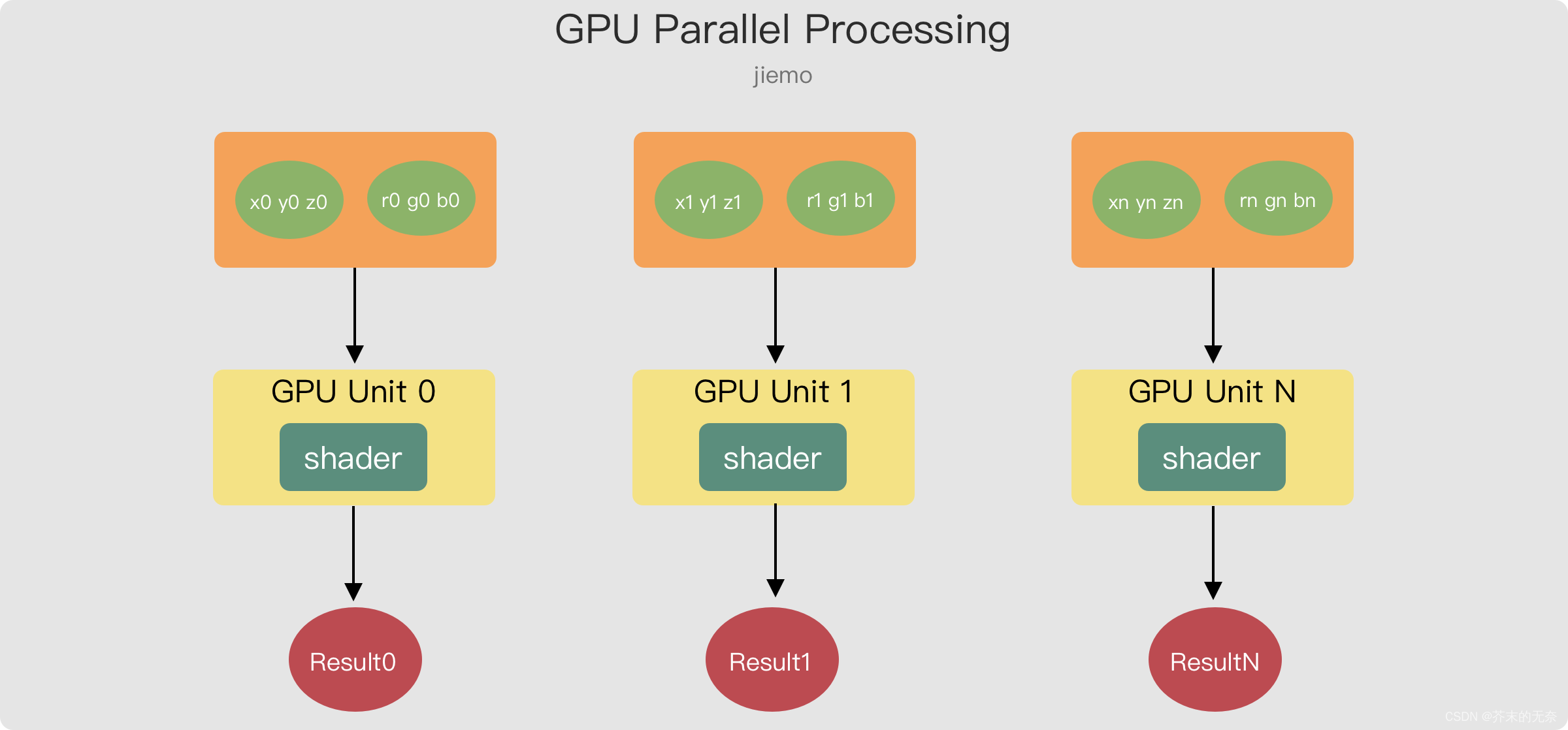
实际上,顶点着色器可以在图形处理单元(GPU)上并行运行,这意味着它可以同时处理多个顶点数据。在 GPU 中,存在大量的简单处理单元,可以同时处理顶点数据。
举例,假设现在有 100 个顶点数据,GPU 上有 10 个处理单元,那么顶点着色器处理的过程大概是
- 数据分配:100个顶点数据被分配给GPU上的10个处理单元。每个处理单元分到的顶点数据数量可能不同。
- 数据处理:每个处理单元都独立地处理分配给它的顶点数据。在Vertex shader中定义的变换(例如旋转、缩放、平移等)被应用到每个顶点数据上。
- 结果合并:每个处理单元处理后的结果被合并到一起。最终的结果是100个顶点数据的处理结果。
- 传递结果:处理后的顶点数据被传递给后续的渲染步骤,以完成3D图形的渲染。
这是一个简化的过程描述,实际的处理过程可能更加复杂。但是,通过上述过程,100个顶点数据可以高效地处理,从而实现高效的3D图形渲染。
我们使用伪代码来描述上面的过程:
#define NUM_VERTICES 100
#define NUM_UNITS 10
vector<vec3> vertex_data(NUM_VERTICES); // 有 100 个顶点数据
// 1. 数据分配
vector<vec3> processing_unit_data[NUM_UNITS]; // 有 10 个处理单元,每个单元处理 10 个顶点
const int num_vertices_per_unit = NUM_VERTICES / NUM_UNITS;
for (int i = 0; i < NUM_UNITS; i++) {
processing_unit_data[i].assign(vertex_data.begin() + i * num_vertices_per_unit,
vertex_data.begin() + (i + 1) * num_vertices_per_unit);
}
// 2. 数据处理
for (int i = 0; i < NUM_UNITS; i++) {
for (int j = 0; j < processing_unit_data[i].size(); j++) {
processing_unit_data[i][j] = vertex_shader(processing_unit_data[i][j]);
}
}
// 3. 结果合并
vector<vec3> result; // 最终得到 100 个处理后的数据
for (int i = 0; i < NUM_UNITS; i++) {
result.insert(result.end(), processing_unit_data[i].begin(), processing_unit_data[i].end());
}
// 4. 传递结果
render(result);
在伪代码中的 2. 数据处理 部分,使用了一个 for 循环顺序地在每一个 GPU 处理单元上执行一次 shader。但请注意,在实际 GPU 运算中这部分是并行的,GPU 可以并行地处理非常非常多数据。如下图
2.2 输入更多数据
在前面绘制三角形时,我们输入了三角形的顶点位置数据。为了绘制更加精美更加复杂的模型,我们要输入的数据可不单单只有顶点位置,还可能有颜色、纹理坐标、法向量坐标等数据。我们通通称这些为顶点属性,名副其实,它确确实实描述顶点的某些属性。
如果将顶点着色器看成是一个函数的话,如果输入只有顶点位置信息,那么可以理解为该函数参数只有一个;当顶点着色器输入更多其他顶点属性时,例如输入了顶点的颜色,那么该函数输入参数有两个:
void vertex_shader(vec3 pos); // 输入顶点位置数据
void vertex_shader(vec3 pos, vec3 color); // 输入顶点位置数据、顶点颜色数据
多个输入体现在 shader 源码,则以多个 in 变量来表示,例如
const char *vertexShaderSource_one_input = R"(
#version 330
layout (location = 0) in vec3 aPos; // 顶点位置数据
void main()
{
// ...
}
)";
const char *vertexShaderSource_two_input = R"(
#version 330
layout (location = 0) in vec3 aPos; // 顶点位置数据
layout (location = 1) in vec3 aColor; // 顶点颜色数据
void main()
{
// ...
}
)";
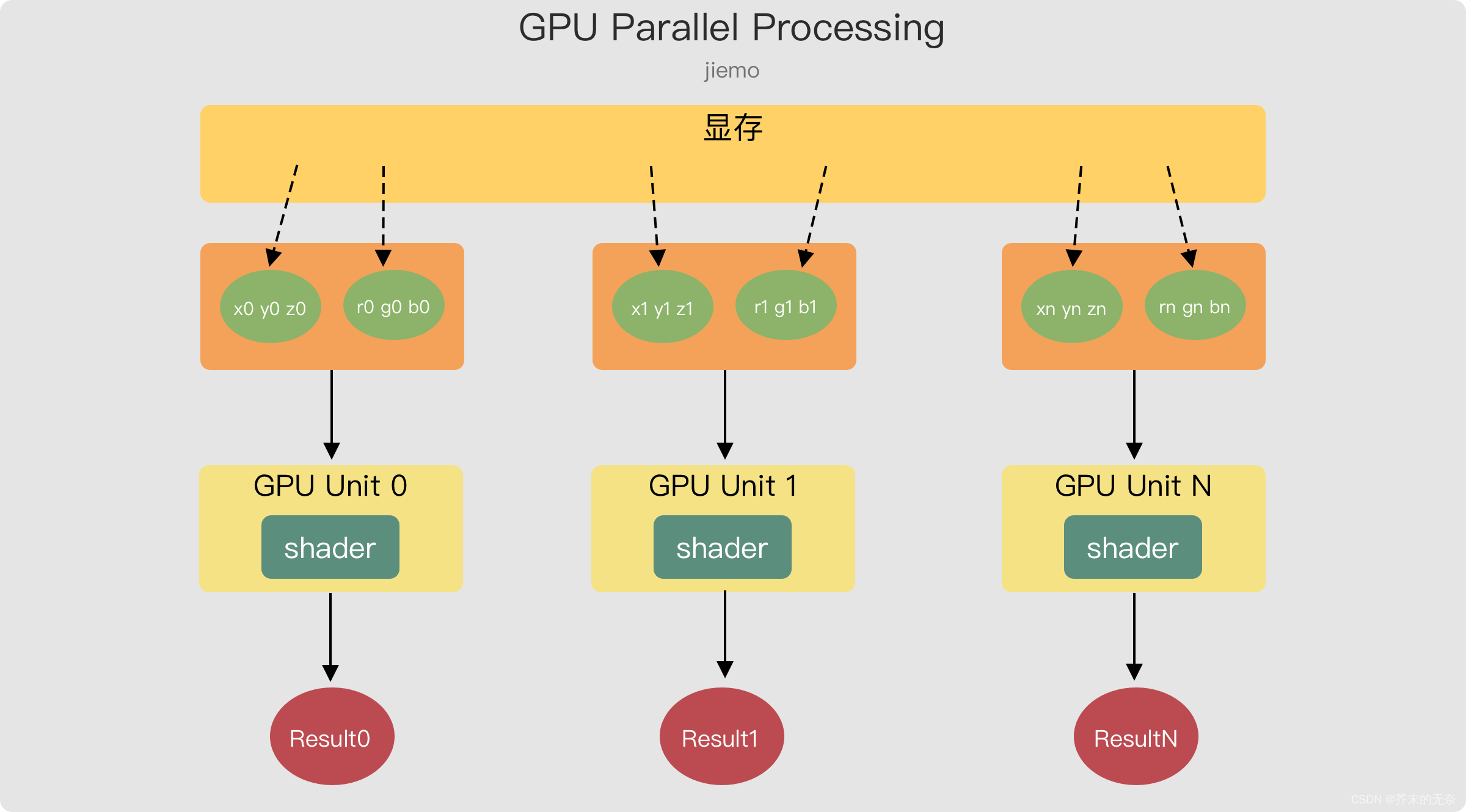
OpenGL 确保至少有 16 个包含 4 分量的顶点属性可用。也就是说我们的 vertex_shader 函数至少可以处理 16 个参数的输入。此时,GPU 执行 shader 时将输入多个数据,如下图:
3. VBO 顶点缓冲对象
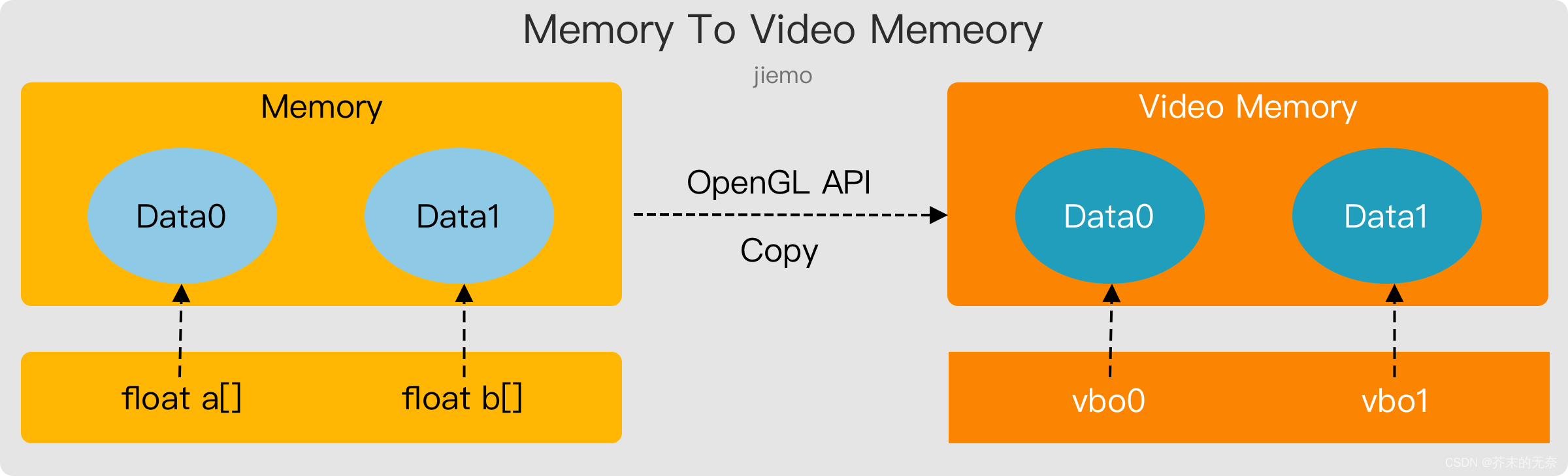
顶点着色器输入的是顶点属性数据,那么这些数据存放在哪里呢?答案是存放在的显存中。
你可能会说:“不对啊,你看前面的 vertices[] 变量,它是存放在代码中的,代码中数据应该是存放在内存中的”。
这么说没错,vertices 确实存放在内存中,但我们需要使用 OpenGL API 将存放在内存的数据拷贝到显存中。在显存中,我们需要一个类似 vertices 对象来表示这块显存,而这样的对象就是 VBO。
3.1 顶点属性数据的存放方式
假设渲染三角形时,除了顶点位置数据外,还有各顶点的颜色信息,那么这两种信息可以怎么摆放呢?
位置和颜色是不同的属性,编程直觉来说,我更倾向使用两个数组来分别存放,例如 3 个 xyz 顶点位置和 3个 rgb 颜色数据:
// xyz
float positions[] = {
-0.5f, -0.5f, 0.0f,
0.5f, -0.5f, 0.0f,
0.0f, 0.5f, 0.0f
};
// rgb
float colors[] = {
1.0f, 0.0f, 0.0f,
0.0f, 1.0f, 0.0f,
0.0f, 0.0f, 1.0f,
}
对应的,你将使用 OpenGL API 创建 2 个 vbo,分别将 positions 和 colors 数据从内存拷贝到显存,代码大致是这样的:
GLuint vbos[2] = {
0,0
};
glGenBuffers(2, vbos);
// copy positions to first vbo
glBindBuffer(GL_ARRAY_BUFFER, vbos[0]);
glBufferData(GL_ARRAY_BUFFER, sizeof(positions), positions, GL_STATIC_DRAW);
// copy colors to second vbo
glBindBuffer(GL_ARRAY_BUFFER, vbos[1]);
glBufferData(GL_ARRAY_BUFFER, sizeof(colors), colors, GL_STATIC_DRAW);
当然,你可以把所有顶点属性数据放在一个数组和一个 vbo 中,例如
float vertices[] = {
// 位置 // 颜色
0.5f, -0.5f, 0.0f, 1.0f, 0.0f, 0.0f, // 右下
-0.5f, -0.5f, 0.0f, 0.0f, 1.0f, 0.0f, // 左下
0.0f, 0.5f, 0.0f, 0.0f, 0.0f, 1.0f // 顶部
};
GLuint vbo{0}
glGenBuffers(1, vbo);
glBindBuffer(GL_ARRAY_BUFFER, vbo);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
两种方式有何优劣?
将数据存储在单个 VBO 中:
- 优点:
- 简单易用:只需创建一个 VBO 即可存储所有数据。
- 高效:如果所有数据都是一起使用的,则可以减少 CPU/GPU 之间的数据传输次数。
- 缺点:
- 不灵活:如果要修改某些数据,则必须更新整个 VBO。
- 更新时间长:由于数据量较大,因此更新 VBO 时间可能较长。
- 占用内存多:由于数据量较大,因此占用的内存可能较多。
将数据存储在多个 VBO 中:
- 优点:
- 灵活:可以单独修改每个 VBO 中的数据。
- 更新时间短:由于每个 VBO 中的数据量较小,因此更新 VBO 时间可能较短。
- 占用内存少:由于每个 VBO 中的数据量较小,因此占用的内存可能较少。
- 缺点:
- 稍微复杂:需要管理多个 VBO,以确保所有数据都被正确渲染。
- 效率较低:如果所有数据都是一起使用的,则可能增加 CPU/GPU 之间的数据传输次数,导致渲染效率降低。
总体来说,如果所有数据都是一起使用的,则使用单个 VBO 可能更高效。但如果需要灵活地修改数据,则使用多个 VBO 可能更合适。因此,选择使用单个 VBO 或多个 VBO 取决于具体应用的需求。
3.2 从 VBO 中获取数据
VBO 表示了一块显存,里头存放了很多数据。前面提到,顶点着色器的输入来自于显存,其实就是来自与 VBO。
现在思考一个问题:一个 VBO 中可能存放着很多数据,包括位置、颜色等,也有可能在显存中有多个 VBO 分别存放着这些数据。那么 OpenGL 在渲染时,是如何正确地找打这些数据,并将它们喂给 shader 的呢?
这个问题的答案其实就是 VAO,但在解释这个问题之前,让我们来看看 GPU 为了正确地获取数据,要知道哪些信息。
仍然是绘制三角形,vertex shader 输入顶点信息和颜色信息,其源代码大致是这样的:
const char *kVertexShaderSource = R"(
#version 330
layout (location = 0) in vec3 aPos;
layout (location = 1) in vec3 aColor;
out vec3 ourColor;
void main()
{
gl_Position = vec4(aPos, 1.0);
ourColor = aColor;
}
)";
假设现在顶点数据包括位置和颜色,全部放在一个 VBO 中,那么你可能这么放,先存放全部 xyz,再放全部 rgb,给它一个方便记忆的名字,就叫平面型:
x0 y0 z0 x1 y1 z1 x2 y2 z2 r0 g0 b0 r1 g1 b1 r2 g2 b2
也有可能存放第一个点的 xyz 和 rgb,接着第二个点,以此类推,这种也给它取个名字,就叫交织型:
x0 y0 z0 r0 g0 b0 x1 y1 z1 r1 g1 b1 x2 y2 z2 r2 g2 b2
这两种存放数据都是合理的,你希望提供一个接口,它足够灵活,可以支持这两种布局。
如果你是 GPU,那么从 VBO 中获取顶点属性的伪代码大致是这样的:
void* vbo = some_address;
const int num_vertex = 3;
const int vertex_pos_index = 0;
const int vertex_rgb_index = 1;
for(int i = 0; i < num_vertex; ++i)
{
vec3_float xyz = getDataFromVBO(vbo, i, ...);
vec3_float rgb = getDataFromVBO(vbo, i, ...);
auto result = vertex_shader(xyz, rgb);
}
// ...
其中:
vbo指向一个显存的地址,把它看成是我们熟悉的 C 指针即可vertex_pos_index = 0和vertex_rgb_index = 1,对应 shader 源码中的layout (location = 0) in vec3 aPos和layout (location = 1) in vec3 aColor。表明想要第几个顶点属性- 通过
getDataFromVBO从 vbo 中获取地i顶点的位置信息和颜色信息 vertex_shader输入两个参数,分别是顶点位置信息和颜色信息
现在,你要思考如何实现 getDataFromVBO 函数,简单起见假设 vbo 存放的都是 float 类型的数据,返回的都是 vec3_float 数据(看成是 大小为 3 的 std::vector)。为了兼容前面提到的两种数据布局,我们引入 stride 和 offset 参数,getDataFromVBO 实现大概是这样的:
vec3_float getDataFromVBO(VBO vbo, int vertex_index, int stride, int offset)
{
const int num_float_in_vec3 = 3;
float* begin = (float*)(vbo) + offset; // 起始位置偏移
const int vertex_offset = vertex_index * stride; // 第 i 个顶点属性的获取位置
vec3_float result = vec3_float{begin + vertex_offset, begin + vertex_offset + num_float_in_vec3}
return result;
}
offset 参数很好理解,即偏移量。下表列举了不同类型获取顶点位置信息(xyz)和颜色信息(rgb)所需的 offset
| 位置数据 | 颜色数据 | |
|---|---|---|
| 平面型 | 0 | 9 |
| 交织型 | 0 | 3 |
- 平面型时,第一个顶点位置(x0)偏移量为 0;第一个顶点颜色(r0)偏移量为 9
- 交织型时,第一个顶点位置(x0)偏移量为 0;第一个顶点颜色(r0)偏移量为 3
stride 参数意为“步长”,指的是为了拿到下一个数据,我需要跨域多少个单位。下表列举了不同类型获取顶点位置信息(xyz)和颜色信息(rgb)所需的 stride
| 位置数据 | 颜色数据 | |
|---|---|---|
| 平面型 | 3 | 3 |
| 交织型 | 6 | 6 |
- 平面型时,当前顶点位置到一下个顶点位置需要跨域 3 个单位,例如 x0 到 x1,中间隔了 3 个数据;颜色数据的
stride同理。 - 交织型时,当前顶点位置到一下个顶点位置需要跨域 6 个单位,例如 x0 到 x1,中间隔了 6 个数据;颜色数据的
stride同理。
非常好,有了 stride 和 offset 参数我们已经能够很好的处理两种不同的排列了。现在,根据我们要获取的是顶点位置还是颜色,设置不同的参数,就可以顺利地从 vbo 中拿到数据了。伪代码更新为:
void* vbo = some_address;
const int num_vertex = 3;
const int vertex_pos_index = 0;
const int vertex_index_0_offset = 0; // 平面型为 0,交织型为 0
const int vertex_index_0_stride = 3; // 平面型为 3,交织型为 6
const int vertex_rgb_index = 1;
const int vertex_index_1_offset = 9 // 平面型为 9,交织型为 3
const int vertex_index_1_stride = 3; // 平面型为 3,交织型为 6
for(int i = 0; i < num_vertex; ++i)
{
vec3_float xyz = getDataFromVBO(vbo, i,
vertex_index_0_stride,
vertex_index_0_offset);
vec3_float rgb = getDataFromVBO(vbo, i,
vertex_index_1_stride,
vertex_index_1_offset);
auto result = vertex_shader(xyz, rgb);
}
3.3 更进一步
或许你感觉到了,我在前面讲解的其实是 glVertexAttribPointer 函数的参数部分。让我们接着完善,让伪代码更加接近 glVertexAttribPointer。
首先,之前的伪代码中,我们默认获取的是一个 vec3。在实际使用场景,不一定所有顶点属性都是 vec3,或许是 vec4 或者 vec2,甚至是单个 float。因此我们将属性的个数抽象为 size 这个参数,得到:
vecn_float getDataFromVBO(VBO vbo, int vertex_index, int size, int stride, int offset)
{
float* begin = (float*)(vbo) + offset; // 起始位置偏移
const int vertex_offset = vertex_index * stride; // 第 i 个顶点属性的获取位置
vecn_float result = vec3_float{begin + vertex_offset, begin + vertex_offset + size}
return result;
}
接着,顶点属性也不一定是 float 类型的,有可能是 int、bool 类型。将类型抽象出来作为一个新的参数,type
enum DataType
{
GL_BYTE,
GL_SHORT,
GL_INT,
GL_FLOAT,
}
vecn getDataFromVBO(VBO vbo, int vertex_index, int size, DataType type, int stride, int offset)
{
type* begin = (type*)(vbo) + offset; // 起始位置偏移
const int vertex_offset = vertex_index * stride; // 第 i 个顶点属性的获取位置
vecn result = vecn{begin + vertex_offset, begin + vertex_offset + size}
return result;
}
最后,为了更加通用一些,我们将 stride 和 offset 都以 byte 为单位:
vecn getDataFromVBO(VBO vbo, int vertex_index, int size, DataType type, int stride, int offset)
{
void* begin = vbo + offset; // 起始位置偏移
const int vertex_offset = vertex_index * stride; // 第 i 个顶点属性的获取位置
const int vertex_size = sizeof(tpye) * size;
vecn result = vecn{begin + vertex_offset, begin + vertex_offset + vertex_size}
return result;
}
经过上述的调整,从 vbo 获取顶点数据的的伪代码更新为:
void* vbo = some_address;
const int num_vertex = 3;
const int vertex_pos_index = 0;
const int vertex_index_0_size = 3;
const int vertex_index_0_type = GL_FLOAT;
const int vertex_index_0_offset = 0;
const int vertex_index_0_stride = 3 * sizeof(float);
const int vertex_rgb_index = 1;
const int vertex_index_1_size = 3;
const int vertex_index_1_type = GL_FLOAT;
const int vertex_index_1_offset = 9 * sizeof(float)
const int vertex_index_1_stride = 3 * sizeof(float);
for(int i = 0; i < num_vertex; ++i)
{
vec3_float xyz = getDataFromVBO(vbo, i,
vertex_index_1_size,
vertex_index_1_type,
vertex_index_0_stride,
vertex_index_0_offset
);
vec3_float rgb = getDataFromVBO(vbo, i,
vertex_index_1_size,
vertex_index_1_type,
vertex_index_1_stride,
vertex_index_1_offset
);
auto result = vertex_shader(xyz, rgb);
}
4.VAO 与 VBO 之间的关系
前面三章,我们对从 vbo 中获取顶点属性数据,进而送给 shader 进行渲染的过程进行梳理,发现如果要从显存中顺利拿到数据,需要给定一系列的参数,包括 size、stride 等等,还要指定从哪个 vbo 里拿。
有的时候,我们要渲染的模型很多,如果在使用模型前都进行一遍参数的设置,那这个过程会非常的繁琐。人们就想,能不能用一个对象来存放这些东西,于是就出现了 VAO(Vertex Array Object)。
在 OpenGL 中我们使用 glVertexAttribPointer 来设置顶点属性数组属性和位置,它将顶点属性数组的数据格式和位置存储在当前绑定的 VAO 中,以便在渲染时使用。
如果用伪代码描述 glVertexAttribPointer 做了哪些事情,可能是这样的:
// 定义一个glVertexAttribPointer函数
function glVertexAttribPointer(index, size, type, normalized, stride, offset) {
// 获取当前绑定的VAO和VBO
vao = glGetVertexArray();
vbo = glGetBuffer();
// 检查参数的有效性
if (index < 0 or index >= MAX_VERTEX_ATTRIBS) {
return GL_INVALID_VALUE;
}
if (size < 1 or size > 4) {
return GL_INVALID_VALUE;
}
if (type not in [GL_BYTE, GL_UNSIGNED_BYTE, GL_SHORT, GL_UNSIGNED_SHORT, GL_INT, GL_UNSIGNED_INT, GL_FLOAT]) {
return GL_INVALID_ENUM;
}
if (stride < 0) {
return GL_INVALID_VALUE;
}
// 将顶点属性数组的数据格式和位置存储在VAO中
vao.vertexAttribs[index].enable = true;
vao.vertexAttribs[index].size = size;
vao.vertexAttribs[index].type = type;
vao.vertexAttribs[index].normalized = normalized;
vao.vertexAttribs[index].stride = stride;
vao.vertexAttribs[index].offset = offset;
vao.vertexAttribs[index].buffer = vbo;
}
- 首先,从 OpenGL Context 中获取当前绑定的 vao 和 vbo
- vao 中有一个
vertexAttribs数组,将当前index的属性设置到这个数组中
是的,vao 与 vbo 之间的关系就是这么简单:vao 里纪录如何从 vbo 中拿数据的参数。
5. 理解代码
让我们回到代码层面,看看当初那让我不知所云的代码片段,vao 与 vbo 的使用:
GLuint VBO{0};
GLuint VAO{0};
glGenVertexArrays(1, &VAO);
glGenBuffers(1, &VBO);
glBindVertexArray(VAO);
glBindBuffer(GL_ARRAY_BUFFER, VBO);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void *)0);
glEnableVertexAttribArray(0);
glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void *)(9 * sizeof(float)));
glEnableVertexAttribArray(1);
这段代码每个函数我都认识,但函数与函数之间的关系却捋不清。例如 glVertexAttribPointer 其实用到之前绑定的 vao 和 vbo,但函数参数中却没有任何体现,导致这段代码在理解上是“断层”的。主要原因是 OpenGL API 后面隐藏着对 OpengGL Context 属性的修改和访问,这部分是如何实现的,我们是未知的。
现在,为了更好的理解这段代,尝试使用伪代码的形式来说明每个函数都干了啥。
class OpenGLContext
{
public:
const int max_num_vao = 256;
const int max_num_buffers = 256;
std::vector<Buffer> buffers(256);
std::vector<VAO> vaos(256);
VAO* current_vao;
VBO* current_vbo;
}
// 全局的 OpenGL Context 对象
OpenGLContext context;
void glGenBuffers(GLsizei n, GLuint * buffers)
{
static int count = 0;
GLuint* index = new GLuint[n];
for(int i = 0; i < n; ++i){
index[i] = ++count;
}
for(int i = 0; i < n; ++i){
// create_new_vao 创建一个新的 vao 对象
context.buffers[index[i]] = create_new_buffer_ojbect();
}
buffers = index;
}
void glGenVertexArrays( GLsizei n, GLuint * arrays)
{
static int count = 0;
GLuint* index = new GLuint[n];
for(int i = 0; i < n; ++i){
index[i] = ++count;
}
for(int i = 0; i < n; ++i){
// create_new_vao 创建一个新的 vao 对象
context.vaos[index[i]] = create_new_vao();
}
arrays = index;
}
void glBindBuffer(GLenum target,GLuint buffer)
{
if(target == GL_ARRAY_BUFFER){
context.current_vbo = &context.buffers[buffer];
}
//....
}
void glBufferData(GLenum target,GLsizeiptr size, const void * data, GLenum usage)
{
if(target == GL_ARRAY_BUFFER){
copy_data_to_vbo(size, data, context.current_vbo);
}
}
void glVertexAttribPointer(GLuint index,
GLint size,
GLenum type,
GLboolean normalized,
GLsizei stride,
const void * pointer)
{
VBO* vbo = context.current_vbo;
VAO* vao = context.current_vao;
// 将顶点属性数组的数据格式和位置存储在VAO中
vao.vertexAttribs[index].enable = true;
vao.vertexAttribs[index].size = size;
vao.vertexAttribs[index].type = type;
vao.vertexAttribs[index].normalized = normalized;
vao.vertexAttribs[index].stride = stride;
vao.vertexAttribs[index].offset = offset;
vao.vertexAttribs[index].buffer = vbo;
}
通过上述伪代码,你应该可以大致了解 OpenGL API 做哪些事情,它们之间有什么联系。写到这里也写累了,更多解释和说明就不写了,聪明的你应该可以理解的。
6. 总结
本文尝试去向刚入门 OpenGL 的新手解释 VAO 和 VBO 之间的关系,从顶点着色器出发解释了渲染过程中顶点是如何送给 GPU 的;接着引出 vbo 概念,vbo 其实就是指向显存的指针;为了从内存中拷贝数据到显存,我们需要指定很多参数,如果每次渲染一个模型都要重新指定一遍参数,会让整个过程变得很繁琐,由于是引入 vao 对象来存放这些参数,使得只需要设置参数一次就能都重复使用;最后,利用伪代码来解释刚开始那些令人困惑的 OpenGL 函数。