背景
环境
相关环境配置:
-
SpringBoot+PostGreSQL
-
Spring Data JPA
懒加载现象
首先声明一下 application.yml 文件中关于 JPA 的配置:
spring:
jpa:
show-sql: true
hibernate:
ddl-auto: none
open-in-view: false
properties:
hibernate:
order_by:
default_null_ordering: last
order_inserts: true
order_updates: true
generate_statistics: false
jdbc:
batch_size: 5000
因某些原因,无法直接贴出相关代码,这里就贴一下自己构建的类似代码:
@Entity
@EqualsAndHashCode(callSuper = true, onlyExplicitlyIncluded = true)
@Setter
@Getter
@AllArgsConstructor
@NoArgsConstructor
@SuperBuilder
public class User extends BaseDomain {
private String name;
private Integer age;
private String address;
@OneToMany(cascade = CascadeType.ALL)
@JoinColumn(name = "user_id")
private List<Job> jobs = new ArrayList<>();
}
@Entity
@EqualsAndHashCode(callSuper = true, onlyExplicitlyIncluded = true)
@Setter
@Getter
@AllArgsConstructor
@NoArgsConstructor
@SuperBuilder
public class Job extends BaseDomain {
private String name;
@ManyToOne
@JoinColumn
private User user;
private String address;
}
自定义查询语句如下:
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
@EntityGraph(
attributePaths = {"jobs"}
)
List<User> findByAddress(String address);
}
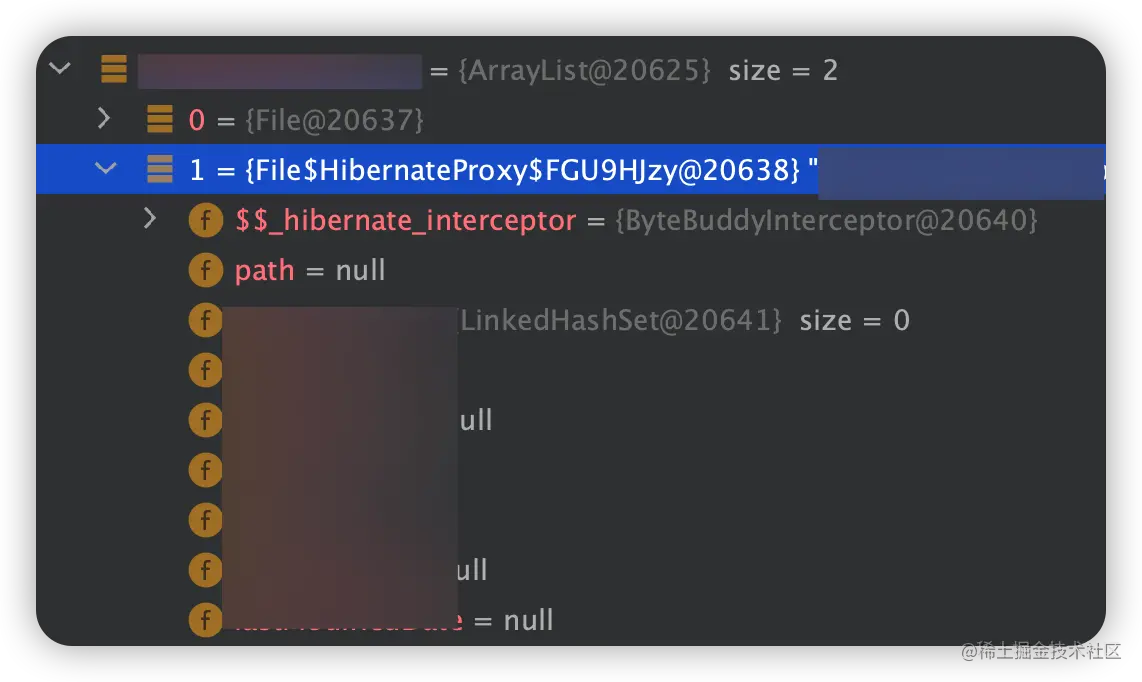
当我们在 Service 服务中调用类似 findByAddress()的查询方法,断点调试发现查询结果有点意思,明明数据已经能拉出来了,但是在 Hibernate Interceptor 中,并未复制给对应的属性。其次,可以看到得到的对象并不是真正的实体对象,而是实体的代理。

我们来对比一个正常的调用:

很明显,这里返回了想要的结果,而异常的则没有,而且这里得到的是真正的实体对象而非代理。异常的多了一个 $$_hibernate_interceptor 属性,该属性内嵌的属性包含了所需要的数据。
本人所遇到的这个现象并不影响程序的执行,不过成功吸引到我去补充 JPA 中懒加载的知识。
懒加载
代码结构如下:

从代码可以看出,User 和 Job 是一对多的关系,而且我们在 User 类中使用了 @OneToMany 注解,该注解中有个 fetch 属性默认为 FetchType.LAZY,即懒加载。
懒加载(lazy)又叫做延时加载,就是当在真正需要数据的时候,才真正执行数据加载操作。至于为什么要用懒加载呢,就是当我们要访问的数据量过大时,明显用缓存不太合适,因为内存容量有限 ,为了减少并发量,减少系统资源的消耗,我们让数据在需要的时候才进行加载,这时我们就用到了懒加载。
我们以下面代码为例,查看 SQL 执行过程:
@Transactional
public List<UserResponse> findByAddress(String address) {
List<User> users = userRepository.findByAddress(address);
System.out.println("-----get-----");
User user = users.get(0);
List<Job> jobs = user.getJobs();
return users.stream().map(this::toUserResponse).collect(Collectors.toList());
}
如果是 Lazy,SQL 日志如下:
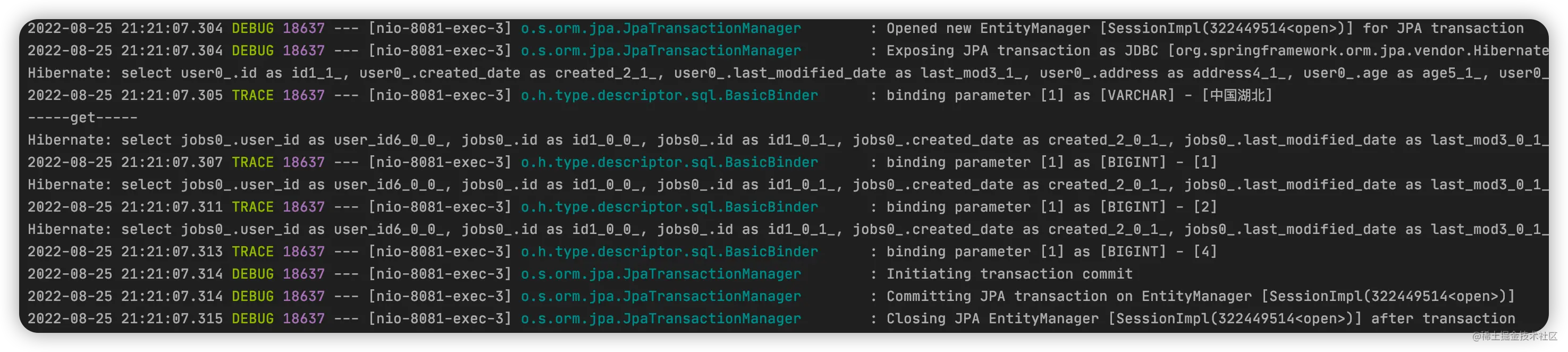
如果是 Eager,SQL 日志如下:

从上述输出的 SQL 日志可以看出,不管是 lazy 还是 eager,在读取数据的时候,都会有 N+1问题。
Spring Data JPA 为了简单地提高查询率,引入了 EntityGraph 的概念,可以解决 N+1条SQL的问题。
修改一下 UserRepository
@EntityGraph(
attributePaths = {"jobs"}
)
List<User> findByAddress(String address);
SQL 输出记录如下所示:

Open Session In View
Open Session In View 简称 OSIV,是为了解决在 mvc 的 controller 中使用了 hibernate 的 lazy load 的属性时 no session 抛出的LazyInitializationException 异常。
关于 LazyInitializationException 异常有四种解决方案,在下文会详细介绍。需要注意的是,通过 OSIV 技术来解决 LazyInitializationException 问题会导致 open 的 session 生命周期过长,它贯穿整个 request,在 view 渲染完之后才能关闭 session 释放数据库连接。另外 OSIV 将 service 层的技术细节暴露到了 controller 层,造成了一定的耦合,因而不建议开启,对应的解决方案就是在 controller 层中使用 response,而非 detached 状态的 entity,所需的数据不再依赖延时加载,在组装 response 的时候根据需要显式查询。
在 SpringBoot 中,配置文件中有这样一个配置:spring.jpa.open-in-view=true,推荐设置为 false。
问题记录
一、Unable to evaluate the expression Method threw 'org.hibernate.LazyInitializationException' exception.
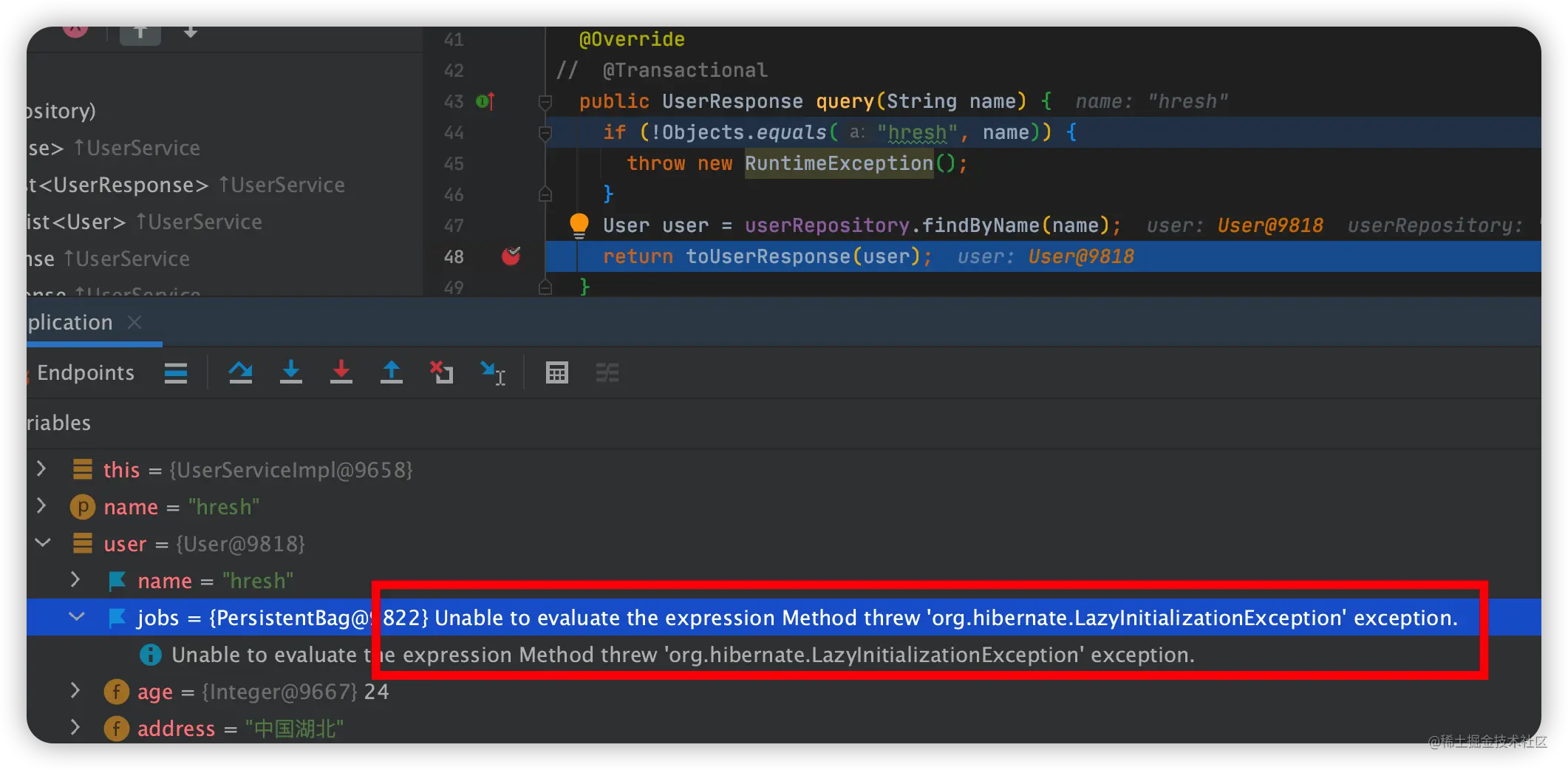
出现场景:使用了懒加载,但没有使用 @EntityGraph,且在配置文件中将 open-in-view 设置为 false。
具体原因为:因为当前不存在会话。Hibernate 打开一个会话并关闭它,但是对于“lazy = true”或“fetch = FetchType.LAZY”,这些字段由代理填充。当您尝试查找此类字段的值时,它将尝试使用活动会话访问数据库以检索数据。如果找不到此类会话,则会出现此异常。
解决方案:
1、@OneToMany 中设置 fetch 为 FetchType.EAGER;
2、增加 @EntityGraph,避免 N+1查询问题;
3、在方法上增加 @Transactional,这样可以保持 seesion,使其不被关掉;
4、将 open-in-view 设置为 true,让 session 不被关掉。
二、Cannot call sendError() after the response has been committed
出现场景:
public class User extends BaseDomain {
private String name;
private Integer age;
private String address;
@OneToMany(cascade = CascadeType.ALL)
@JoinColumn(name = "user_id")
private List<Job> jobs = new ArrayList<>();
}
public class Job extends BaseDomain {
private String name;
@ManyToOne
@JoinColumn
private User user;
private String address;
}
//UserRepository
@EntityGraph(
attributePaths = {"jobs"}
)
List<User> findByAddress(String address);
//UserServiceImpl
public List<User> findByAddress2(String address) {
List<User> users = userRepository.findByAddress(address);
return users;
}
原因:这是双向关系的一个问题,因为 User 和 Job 类互相引用,在反序列化时,双向引用导致无限递归。
解决方法:在@ManyToOne 上方使用@JsonIgnore,@JsonIgnore:直接直接忽略某个属性,以断开无限递归,序列化或反序列化均忽略。
扩展学习
@OneToMany
这里着重讲解级联操作。
一方在 oneToMany 上设置的级联保存和更新很好理解,多方会随着一方进行保存和更新。但是级联删除其实只是指一方删除时会把关联的多方数据全部删除,并不能删除一方维护的多方list中 remove 掉的数据。
需要额外注意该注解的这个属性:
orphanRemoval=true
该属性设置为 true,则从关联的多方数据中删除指定数据,即可实现删除操作。
User user=userRepository.findById(1L).get();
ContactInfo deletedContact = user.getContactInfos().get(0);
user.getContactInfos().remove(deletedContact);
JPA 和 Spring Data JPA 有什么区别?
Java Persistence API,有时也称为 JPA,是一个 Java 框架,用于管理使用 Java 平台标准版 (JavaSE) 和 Java 平台企业版 (JavaEE) 的应用程序中的关系数据。
JPA 是标准化 Java 对象映射到关系数据库系统的方式的规范。作为一个规范,JPA 由一组接口(如EntityManagerFactory、EntityManager和注释)组成,可帮助您将 Java 实体对象映射到数据库表。
您可以使用多个 JPA 提供程序,例如 Hibernate、EclipseLink 或 Open JPA。
在这方面的持久性包括三个方面:
- API 本身,在
javax.persistence包中定义。 - Java 持久性查询语言 (JPQL)。
- 对象关系元数据。
首先 Spring Data JPA 是 Spring Data 项目的一部分,它可以更轻松地实现基于 JPA 的存储库。
Spring Data JPA 可以与 Hibernate、Eclipse Link 或任何其他 JPA 提供程序一起使用。使用 Spring 或 Java EE 的一个非常有趣的好处是您可以使用@Transactional注解以声明方式控制事务边界。
特征:
- 支持基于 Spring 和 JPA 构建存储库
- 支持 QueryDSL 谓词,因此支持类型安全的 JPA 查询
- 域类的透明审计
- 分页支持、动态查询执行、集成自定义数据访问代码的能力
@Query在引导时验证带注释的查询- 支持基于 XML 的实体映射
- 通过引入基于 JavaConfig 的存储库配置
@EnableJpaRepositories
Java Persistence API 中 FetchType LAZY 和 EAGER 的区别?
简单来说就是:
LAZY = fetch when needed
EAGER = fetch immediately
如何将 Hibernate 代理转换为真实的实体对象
如下图所示,从数据集合中筛选出的 metadataFile 不是真正的实体对象,虽然在当前的代码中不影响使用,但是在某些场景下,我们不希望只获取到代理对象。
解决方案:
从 Hibernate ORM 5.2.10开始,您可以这样做:
Object unproxiedEntity = Hibernate.unproxy(proxy);
复制代码
在 Hibernate 5.2.10之前。最简单的方法是使用Hibernate 内部实现提供的unproxy方法:PersistenceContext
Object unproxiedEntity = ((SessionImplementor) session)
.getPersistenceContext()
.unproxy(proxy);
除此之外,还有一种方法,相较于上面稍微复杂了点:
public static <T> T initializeAndUnproxy(T entity) {
if (entity == null) {
throw new
NullPointerException("Entity passed for initialization is null");
}
Hibernate.initialize(entity);
if (entity instanceof HibernateProxy) {
entity = (T) ((HibernateProxy) entity).getHibernateLazyInitializer()
.getImplementation();
}
return entity;
}
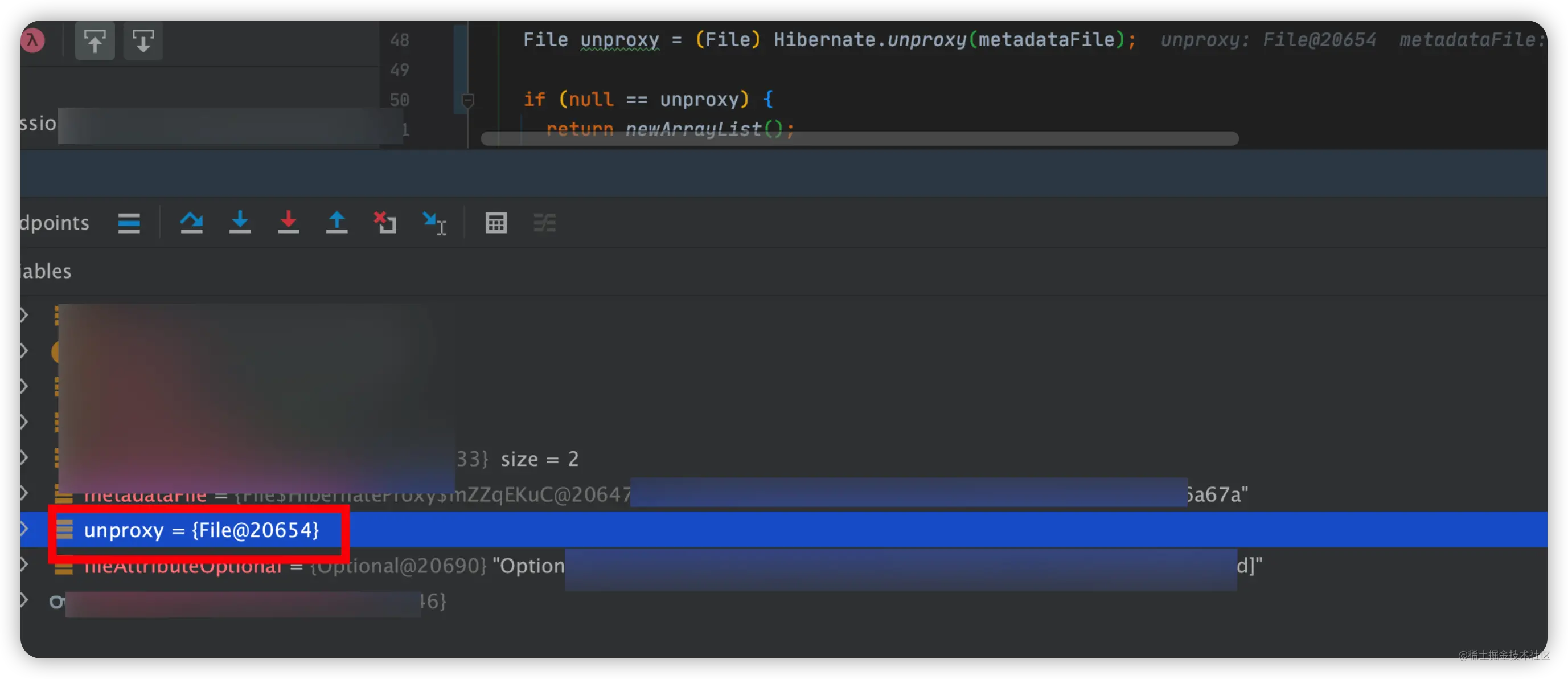
最终的效果如下图所示:
Spring Data JPA 中的 CrudRepository 和 JpaRepository 接口有什么区别?
JpaRepository扩展PagingAndSortingRepository而扩展CrudRepository。
它们的主要功能是:
CrudRepository主要提供CRUD功能。PagingAndSortingRepository提供对记录进行分页和排序的方法。JpaRepository提供一些 JPA 相关的方法,例如刷新持久化上下文和批量删除记录。
由于上面提到的继承, JpaRepository将具有CrudRepository和PagingAndSortingRepository的所有功能。因此,如果您不需要存储库具有 and 提供的功能JpaRepository,请PagingAndSortingRepository使用CrudRepository.







VRPTW常见求解算法--代码解析](https://img-blog.csdnimg.cn/7090a12c5a7e4083a2afc20e6a70d459.png)