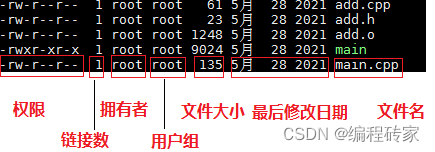
集群里面kafka报错:
Controller 219 epoch 110 failed to change state for partition maxwell_atlas-0 from OfflinePartition to OnlinePartition
kafka.common.stateChangeFailedException: Failed to elect leader for partition maxwell_atlas-0 under strategy OfflinePartitionLeaderElectionStrategy
错误原因:
新增加的副本的offset比leader的新,所以在elecct的时候,报错。
解决办法:
kafka自带平衡topic的脚本,只需要启动一遍即可。来到kafka的bin目录下执行命令:
kafka-preferred-replica-election.sh --bootstrap-server ip:2181然后重启kafka。
然而实际,重启好了不到5分钟,整个集群依然报警了。
再看日志文件,多了些其他报错:
[Controller id=219] Partition __consumer_offsets-8 failed to complete preferred replica leader election to 139. Leader is still 141
而在仔细检查所有kafka的实例,发现现有的Kafka.BrokerId有:140,141,142,143,219,而选举leader的id却是139。都可以盲猜一手,现在的219就是之前的139。
从这儿也可以推断出:
现有的5个节点的partition都不是最新的,所以有主控制器Offline,因为选不出leader
具体选不出leader的原因,应该就是原来有brokerid=139的,现在没了,而replic partitions,isr里还是原来的139,所以现在的140,141,142,143,219里选举不出139的为leader。
解决办法:
将219所在brokerid改为139后,重启kafka。
重启产生新的报错:
Fatal error during KafkaServer startup. Prepare to shutdown.
Configured broker.id 139 doesn't match stored broke.id 219 in meta.properties.If you moved your data, make sure your configured broker.id matches.
问题原因:
启动kafka时,配置文件中的broke.id和元数据里保存的broker.id不一致导致的启动失败。
解决办法:
前去kafka的数据目录下找到meta.properties文件,修改broker.id=219为139,然后重启。再按上面那个报错处理topic。


![String类 [上]](https://img-blog.csdnimg.cn/b8b268ef999044a4b09a861ccce2309a.png)

![[计算机操作系统(慕课版)]第二章 进程的描述与控制(学习笔记)](https://img-blog.csdnimg.cn/e5b8c57be2a9443aa7d09b9562da1e03.png)