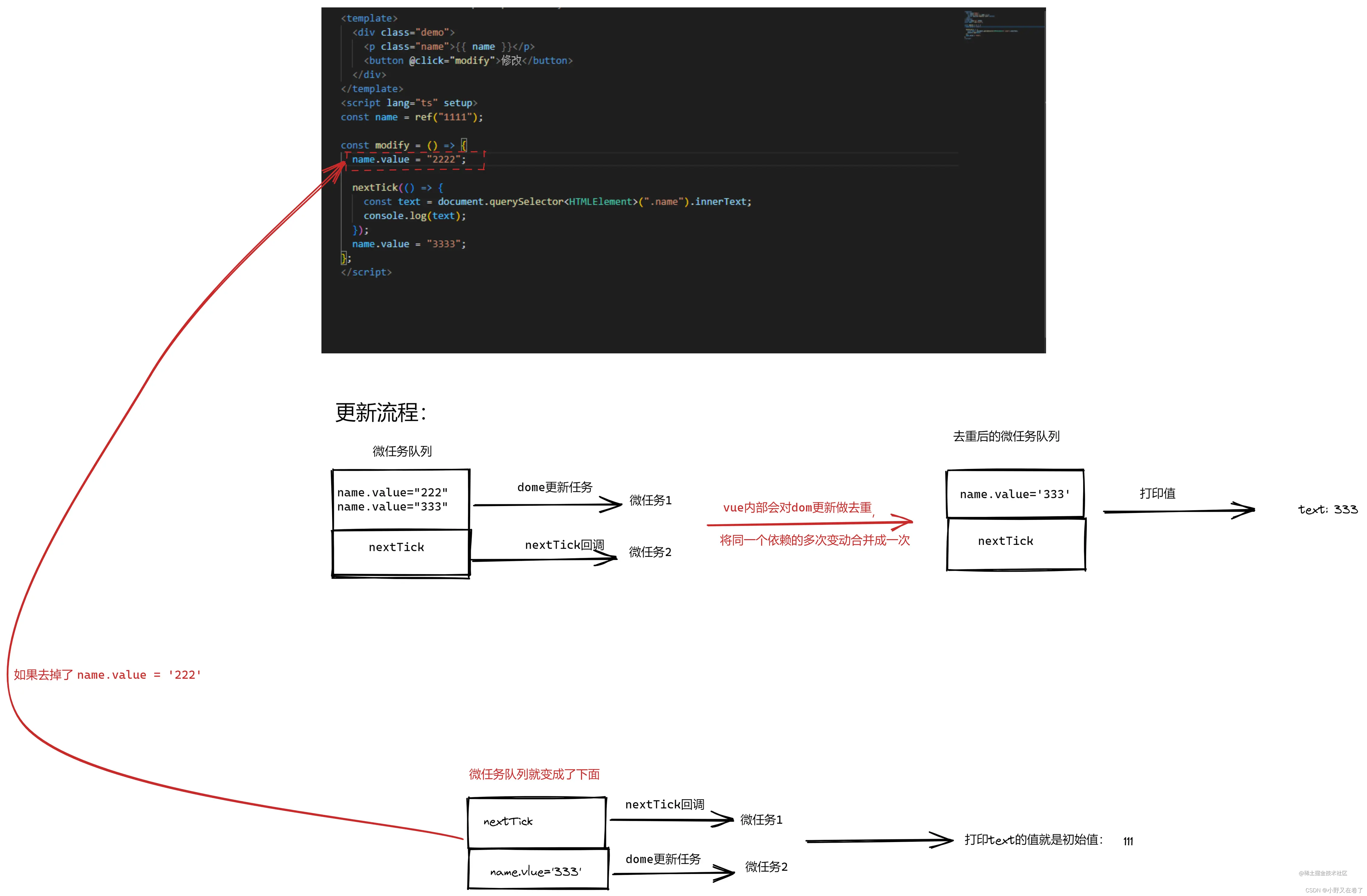
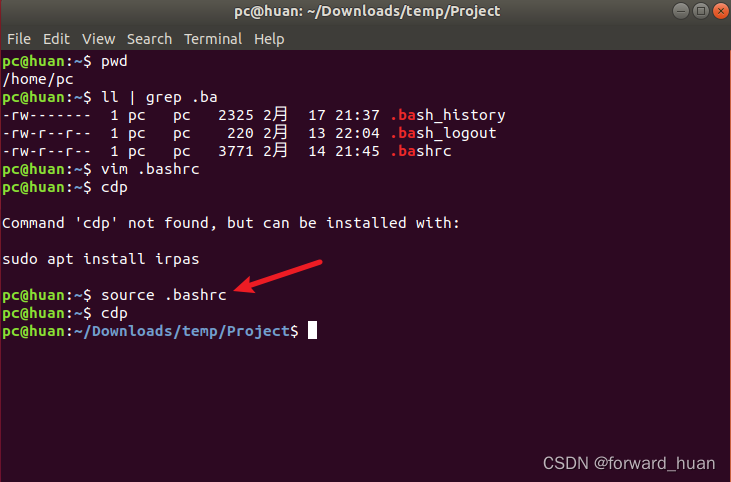
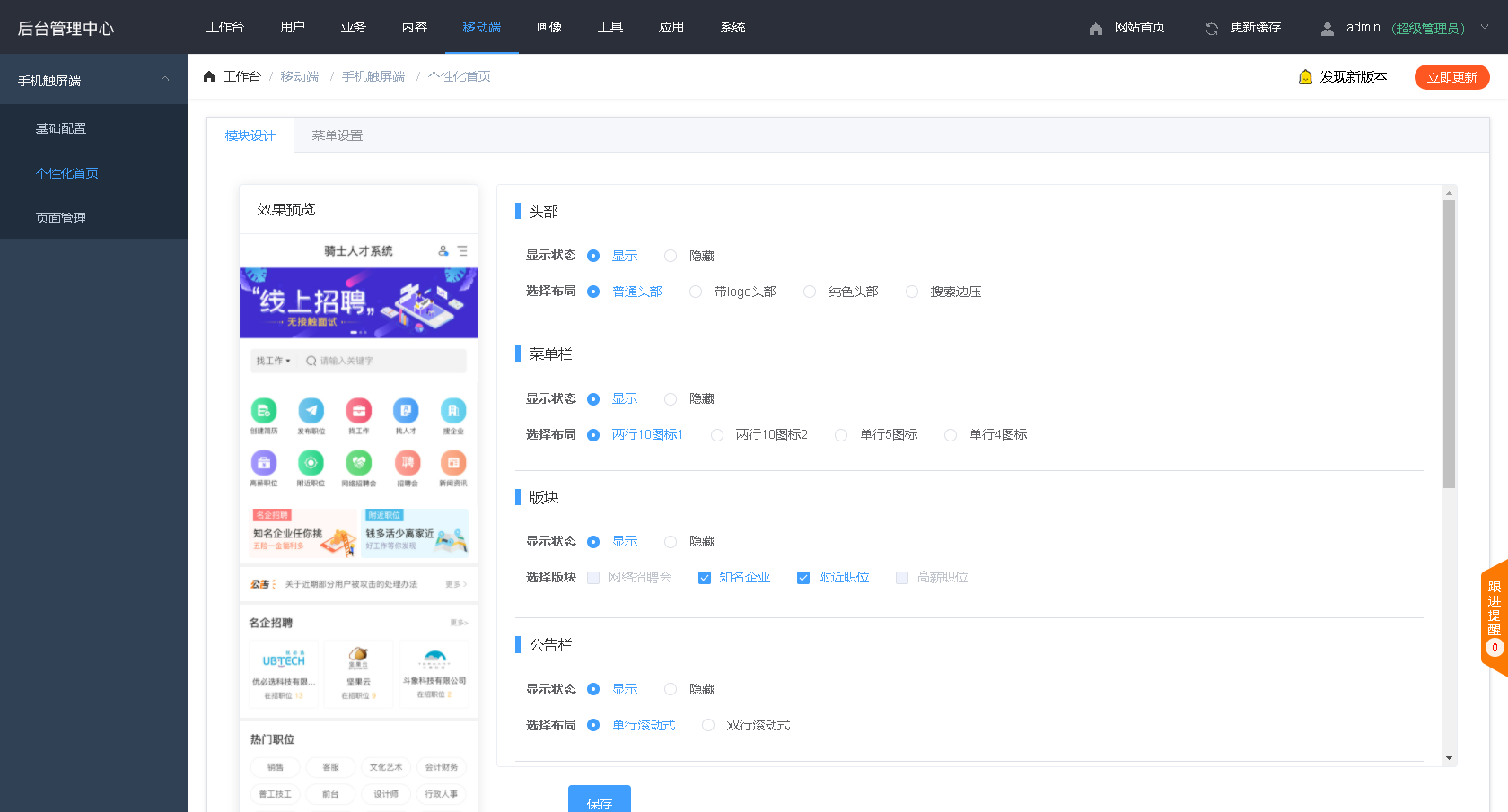
Python-第八天 Python文件操作
- 一、文件的编码
- 1. 什么是编码?
- 2. 为什么需要使用编码?
- 二、文件操作
- 1.文件的操作步骤
- 2. 打开文件
- 3.mode常用的三种基础访问模式
- 4.关闭文件
- 三、文件的读取
- 1.文件对象有如下读取方法:
- 2.练习:单词计数
- 三、文件的写入
- 1. 写入文件使用open函数的”w”模式进行写入
- 2. 写入的方法
- 3. 注意事项
- 四、文件的追加
- 1. 写入文件使用open函数的”a”模式进行追加
- 2.追加的方法
- 3. 注意事项
- 五、文件操作综合案例
一、文件的编码
1. 什么是编码?
编码就是一种规则集合,记录了内容和二进制间进行相互转换的逻辑。
编码有许多中,我们最常用的是UTF-8编码
2. 为什么需要使用编码?
计算机只认识0和1,所以需要将内容翻译成0和1才能保存在计算机中。
同时也需要编码, 将计算机保存的0和1,反向翻译回可以识别的内容。
二、文件操作
1.文件的操作步骤
想想我们平常对文件的基本操作,大概可以分为三个步骤(简称文件操作三步走):
① 打开文件
② 读写文件
③ 关闭文件
注意:可以只打开和关闭文件,不进行任何读写
2. 打开文件
需要通过open函数打开文件得到文件对象
在Python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件,语法如下
open(name, mode, encoding)
- name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)。
- mode:设置打开文件的模式(访问模式):只读、写入、追加等。
- encoding:编码格式(推荐使用UTF-8)
示例代码:
f = open('python.txt', 'r', encoding='UTF-8')
# encoding的顺序不是第三位,所以不能用位置参数,用关键字参数直接指定
注意:此时的f是open函数的文件对象,对象是Python中一种特殊的数据类型,拥有属性和方法,可以使用对象.属性或对象.方法对其进行访问,后续面向对象课程会给大家进行详细的介绍。
3.mode常用的三种基础访问模式

4.关闭文件
文件读取完成后,要使用文件对象.close()方法关闭文件对象,否则文件会被一直占用。
f = open("python.txt", "r")
f.close()
# 最后通过close,关闭文件对象,也就是关闭对文件的占用
# 如果不调用close,同时程序没有停止运行,那么这个文件将一直被Python程序占用。
三、文件的读取
1.文件对象有如下读取方法:
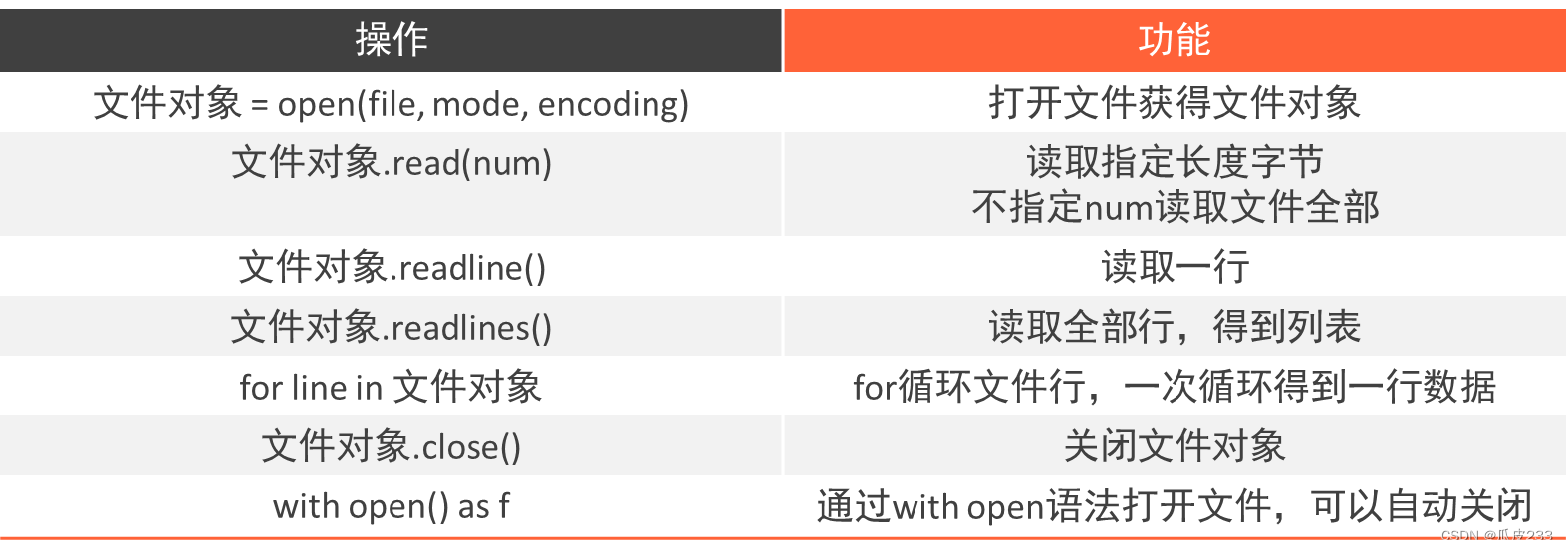
- read()
- readline()
- readlines()
- for line in 文件对象
- with open 语法
#打开文件
f= open(r'D:\vscode_workSpace\Python\day6-数据容器\测试.txt','r',encoding='UTF-8')
# read()方法:
# num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据。
print(f'读取10个字节:\n{f.read(10)}')
print('------------------')
print(f'读取全部:\n{f.read()}')
#打开文件
f= open(r'D:\vscode_workSpace\Python\day6-数据容器\测试.txt','r',encoding='UTF-8')
# readline()方法:一次读取一行内容
print(f'读取一行:\n{f.readline()}')
print(f'读第二行:\n{f.readline()}')
#打开文件
f= open(r'D:\vscode_workSpace\Python\day6-数据容器\测试.txt','r',encoding='UTF-8')
# readlines()方法:
# readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。
print(f'读取全部行:\n{f.readlines()}')
#打开文件
f= open(r'D:\vscode_workSpace\Python\day6-数据容器\测试.txt','r',encoding='UTF-8')
i = 1
# for循环读取文件行
for line in f:
print(f'每次循环取一行数据,这是第{i}行:{line}')
i+=1
with open(r"C:\Users\Administrator\Desktop\平台账号密码.txt", "r") as f:
lines = f.readlines()
print(lines)
2.练习:单词计数
通过Windows的文本编辑器软件,将如下内容,复制并保存到:word.txt,文件可以存储在任意位置
itheima itcast python
itheima python itcast
beijing shanghai itheima
shenzhen guangzhou itheima
wuhan hangzhou itheima
zhengzhou bigdata itheima
通过文件读取操作,读取此文件,统计itheima单词出现的次数
f = open(r'C:\Users\Administrator\Desktop\word.txt', 'r', encoding='UTF-8')
text = f.read()
count = text.count('itheima')
print(text)
print(count)
f.close()
三、文件的写入
1. 写入文件使用open函数的”w”模式进行写入
2. 写入的方法
- wirte(),写入内容
- flush(),刷新内容到硬盘中
# f.write('需写入内容')
# 1. 打开文件
f = open(r'C:\Users\Administrator\Desktop\ceshi.txt', 'w', encoding='UTF-8')
# 2.文件写入
f.write('hello world')
# 3. 内容刷新
f.flush()
# 4.关闭文件
f.close()
直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
当调用flush的时候,内容会真正写入文件
这样做是避免频繁的操作硬盘,导致效率下降(攒一堆,一次性写磁盘)
3. 注意事项
- w模式,文件不存在,会创建新文件
- w模式,文件存在,会清空原有内容
- close()方法,带有flush()方法的功能
四、文件的追加
1. 写入文件使用open函数的”a”模式进行追加
2.追加的方法
- wirte(),写入内容
- flush(),刷新内容到硬盘中
# f.write('需写入内容')
# 1. 打开文件
f = open(r'C:\Users\Administrator\Desktop\ceshi.txt', 'a', encoding='UTF-8')
# 2.文件写入
f.write('hello world123')
# 3. 内容刷新
f.flush()
# 4.关闭文件
f.close()
3. 注意事项
- a模式,文件不存在会创建文件
- a模式,文件存在会在最后,追加写入文件
- 可以使用”\n”来写出换行符
五、文件操作综合案例
完成文件备份案例
需求:有一份账单文件,记录了消费收入的具体记录,内容如下:
name,date,money,type,remarks
周杰轮,2022-01-01,100000,消费,正式
周杰轮,2022-01-02,300000,收入,正式
周杰轮,2022-01-03,100000,消费,测试
林俊节,2022-01-01,300000,收入,正式
林俊节,2022-01-02,100000,消费,测试
林俊节,2022-01-03,100000,消费,正式
林俊节,2022-01-04,100000,消费,测试
林俊节,2022-01-05,500000,收入,正式
张学油,2022-01-01,100000,消费,正式
张学油,2022-01-02,500000,收入,正式
张学油,2022-01-03,900000,收入,测试
王力鸿,2022-01-01,500000,消费,正式
王力鸿,2022-01-02,300000,消费,测试
王力鸿,2022-01-03,950000,收入,正式
刘德滑,2022-01-01,300000,消费,测试
刘德滑,2022-01-02,100000,消费,正式
刘德滑,2022-01-03,300000,消费,正式
同学们可以将内容复制并保存为 bill.txt文件
我们现在要做的就是:
- 读取文件
- 将文件写出到bill.txt.bak文件作为备份
- 同时,将文件内标记为测试的数据行丢弃
实现思路:
- open和r模式打开一个文件对象,并读取文件
- open和w模式打开另一个文件对象,用于文件写出
- for循环内容,判断是否是测试不是测试就write写出,是测试就continue跳过
- 将2个文件对象均close()
fr = open(r'C:\Users\Administrator\Desktop\bill.txt', 'r', encoding='UTF-8')
fw = open(r'C:\Users\Administrator\Desktop\bill.txt.bak', 'w', encoding='UTF-8')
for line in fr:
# print(line)
# print(line.split(',')[4])
if line.strip().split(',')[4] == '测试':
continue
fw.write(line)
fr.close()
fw.close()