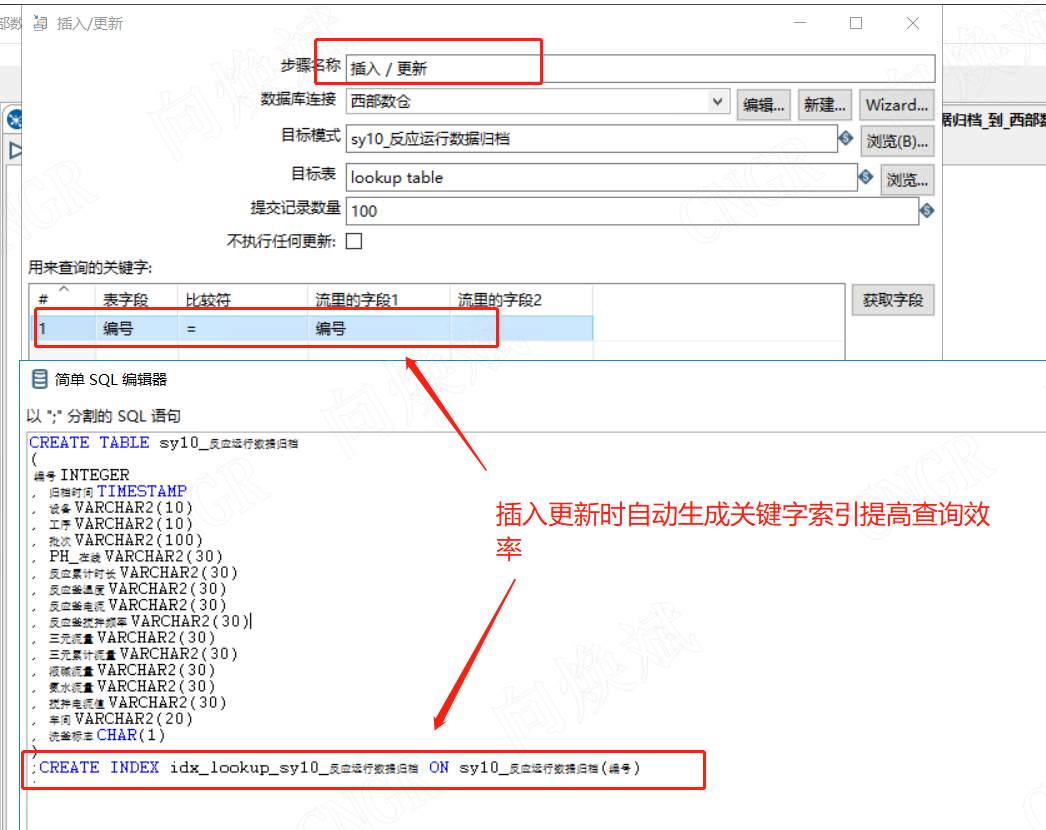
项目难点
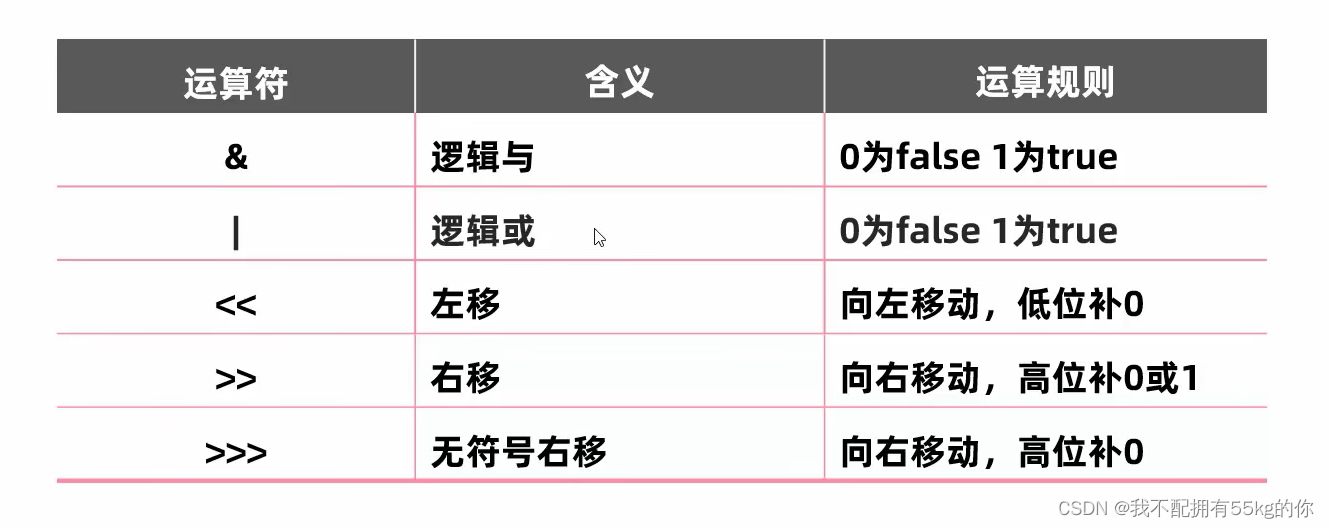
- 主要通过聚类算法 kmeans 进行调整 .
- 需要找出分为几类时模型参数最佳 . (n_clusters)
- 找出性价比较高的车
- 获取训练数据: train_X = data.drop(['car_ID','CarName'],axis = 1)
- 计算模型的得分和误差: kmeans.inertia_ # inertia簇内误差平方和
from sklearn.cluster import KMeans # 聚类算法
from sklearn.metrics import silhouette_score
kmeans = KMeans(n_clusters= k)
kmeans.fit(train_x)
sse.append(kmeans.inertia_) # inertia簇内误差平方和
# 通过预测值和实际值的对比计算模型的得分
ss.append(silhouette_score(train_x,kmeans.predict(train_x)))-
LabelEncoder: python:sklearn标签编码(LabelEncoder) sklearn.preprocessing.LabelEncoder的使用:在训练模型之前,通常都要对数据进行一定得处理。将类别编号是一种常用的处理方法,比如把类别“电脑”,“手机”编号为0和1,可使用LabelEncoder函数。
-
作用: 将n个类别编码为0~n-1之间的整数(包括0和n-1)
-
- 找出聚类种类最佳参数
sse =[]
ss = []
for k in range(2,11):
kmeans = KMeans(n_clusters= k)
kmeans.fit(train_x)
sse.append(kmeans.inertia_)
ss.append(silhouette_score(train_x,kmeans.predict(train_x)))- kmean 聚类算法模型
kmeans = KMeans(n_clusters=8)
kmeans.fit(train_x)
predict_y = kmeans.predict(train_x) # 预测一 汽车产品聚类分析综合项目
现在人们购车成为稀松平常,你的第一辆车是什么品牌,你打算什么时候更换车辆?汽车品牌多如牛毛,使用数据分析相关知识点,使用机器学习中的聚类算法,进行建模,从而对根据汽车相关属性对汽车进行类别划分,帮你选好车!熟悉算法建模业务流程,掌握机器学习建模的思想和基本操作。
- 数据加载
- 数值编码化
- 归一化操作
- Kmeans算法参数筛选
- 分层聚类使用
- DBSCAN算法使用
- 对比不同算法效果
1 导入模块
# 使用 KMeans 进行聚类,导入库
from sklearn.cluster import KMeans # 聚类算法
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
# 预处理
from sklearn import preprocessing # 归一化
from sklearn.preprocessing import LabelEncoder # 标签编码
import pandas as pd
# 矩阵运算
import numpy as np2 数据加载
data = pd.read_csv('./car_price.csv')
data.shape # (205, 26)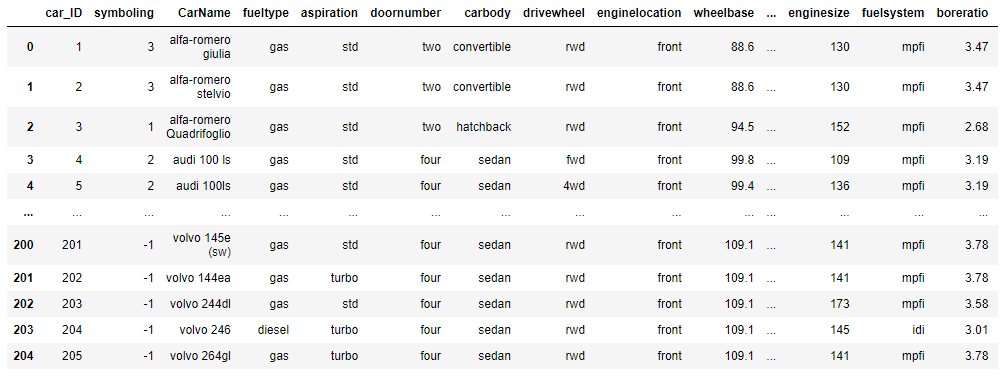
3 去除无效数据
train_X = data.drop(['car_ID','CarName'],axis = 1)
train_X.shape # 205, 244 特征工程(将属性转换为数值)
# 将非数值特征转换为数值
le = LabelEncoder() # 直接将字符串转换为数值
colums = ['fueltype','aspiration','doornumber','carbody','drivewheel',
'enginelocation','enginetype','cylindernumber','fuelsystem']
for column in colums:
# 训练并将标签转换为归一化的代码
train_X[column] = le.fit_transform(train_X[column])
train_X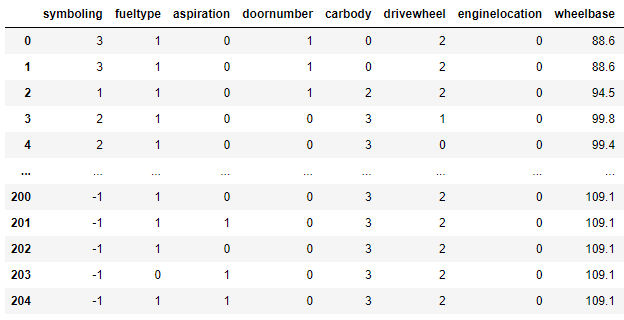
5 归一化 (降维)
# 规范化到[0,1] 空间
min_max_scaler = preprocessing.MinMaxScaler()
# MinMaxscaler( )将每个要素缩放到给定范围,怡合数据,然后进行转换
train_x = min_max_scaler.fit_transform(train_X)
train_x
6 聚类参数选择
6.1 显示所有系统字体
# 查找自己电脑的字体,从中选择
# 本电脑上,选择的STKaiti
from matplotlib.font_manager import FontManager
fm = FontManager()
[font.name for font in fm.ttflist]
6.2 字体设置
plt.rcParams['font.family'] = 'STKaiti'
plt.rcParams['font.size'] = 206.3 SSE(簇惯性)
from sklearn.cluster import KMeans # 聚类算法
from sklearn.metrics import silhouette_score
sse =[]
ss = []
for k in range(2,11):
kmeans = KMeans(n_clusters= k)
kmeans.fit(train_x)
sse.append(kmeans.inertia_) # inertia簇内误差平方和
# 通过预测值和实际值的对比计算模型的得分
ss.append(silhouette_score(train_x,kmeans.predict(train_x)))
plt.figure(figsize=(16,6))
x = range(2,11)
plt.subplot(1,2,1)
plt.plot(x,sse,'o-')
plt.xlabel('K')
plt.ylabel('SSE簇惯性')
plt.subplot(1,2,2)
plt.plot(x,ss,'r*-')
plt.xlabel('K')
plt.ylabel('轮廓系数')
plt.savefig('./1-聚类簇数.png',dpi = 200)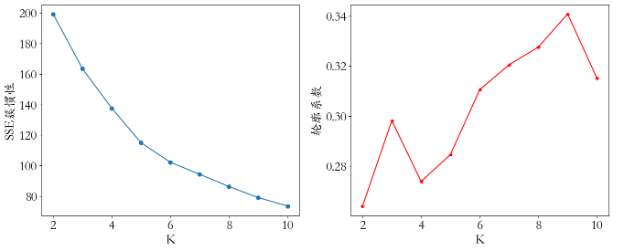
- 当分类增加的时候, 误差逐渐变小, 当分类数为9的时候, 模型得分较高 .
6.4 聚类运算
kmeans = KMeans(n_clusters=8)
kmeans.fit(train_x)
# 预测
predict_y = kmeans.predict(train_x)
predict_y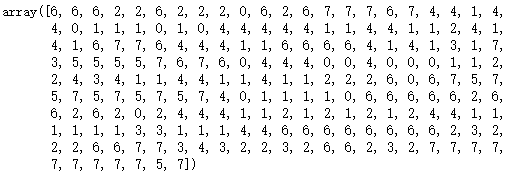
7 结果分析
7.1 结果合并 (将结果分类添加到元素数据集中)
result = pd.concat((data,pd.DataFrame(predict_y)),axis =1) # 增加一列分类数据
result.rename({0:u'聚类结果'},axis = 1,inplace = True)
result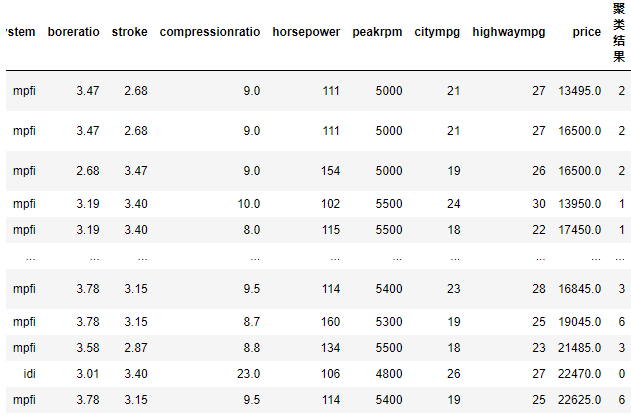
# 分组运算
g1 = result.groupby(by = ['聚类结果','carbody'])[['price']].mean()
g1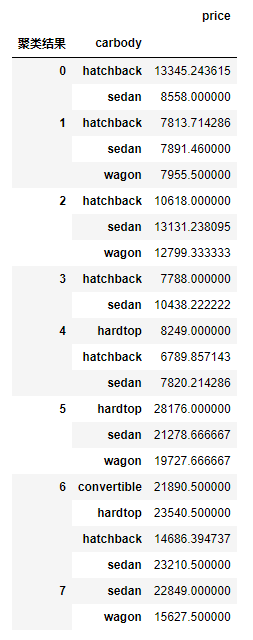
g2 = g1.unstack() # 数据重塑
g2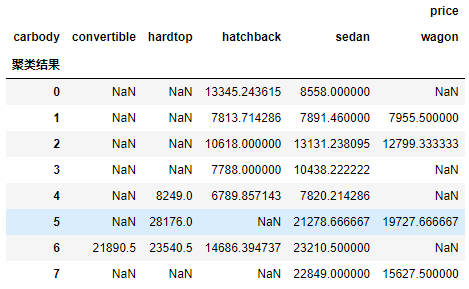
g2.sort_values(by= ('price','sedan'))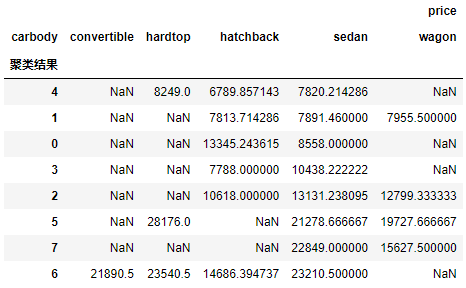
7.2 低端轿车聚类结果
# 查看,类别是1的标准三厢车(具体根据分组运算结果确定)
cond = result.apply(lambda x : x['聚类结果'] == 4 and 'sedan' in x['carbody'] ,axis = 1)
columns = ['CarName','wheelbase','price','horsepower','carbody','fueltype','聚类结果']
# 价格降序排名
result[cond][columns].sort_values('price',ascending= False)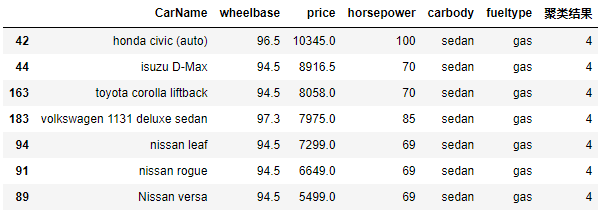
7.3 高端轿车聚类结果
# 根据条件(售价)筛选高端轿车(三厢车)
cond = result.apply(lambda x : x['聚类结果'] == 7 and 'sedan' in x['carbody'], axis =1)
columns = ['CarName','wheelbase','price','horsepower','carbody','fueltype','聚类结果']
# 价格降序排名
result[cond][columns].sort_values('price',ascending= False)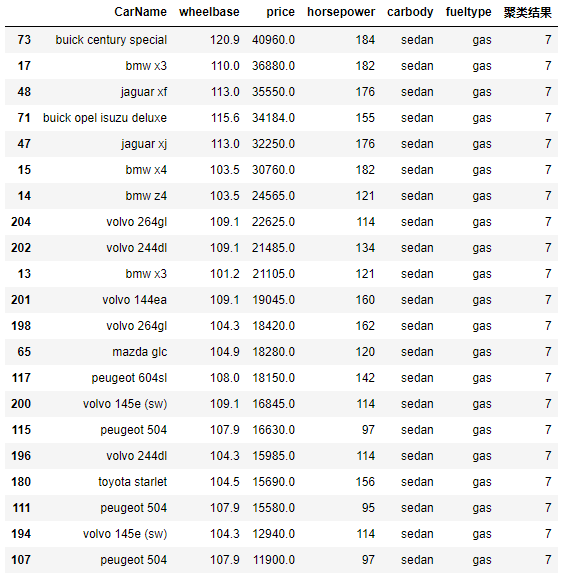
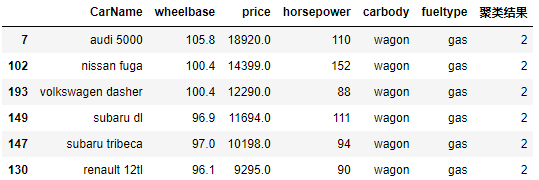
7.4 中端 SUV聚类结果
cond = result.apply(lambda x : x['聚类结果'] == 2 and 'wagon' in x['carbody'], axis =1)
columns = ['CarName','wheelbase','price','horsepower','carbody','fueltype','聚类结果']
# 价格降序排名
result[cond][columns].sort_values('price',ascending= False)