目录
基础回顾
线程池执行任务流程
简单使用
构造函数
execute方法
execute中出现的ctl属性
execute中出现的addWorker方法
addWorker中出现的addWorkerFailed方法
addWorker中出现的Worker类
Worker类中run方法出现的runWorker方法
runWorker中出现的getTask
runWorker中出现的processWorkerExit
项目中如何配置使用线程池
参考
基础回顾
线程池基础不好的还是要先了解线程池大体知识,不要眼高手低❌
ThreadPoolExecutor线程池有关_明天一定.的博客-CSDN博客
我都忘记了我要写线程池源码相关文章了,填个多年前的坑➿
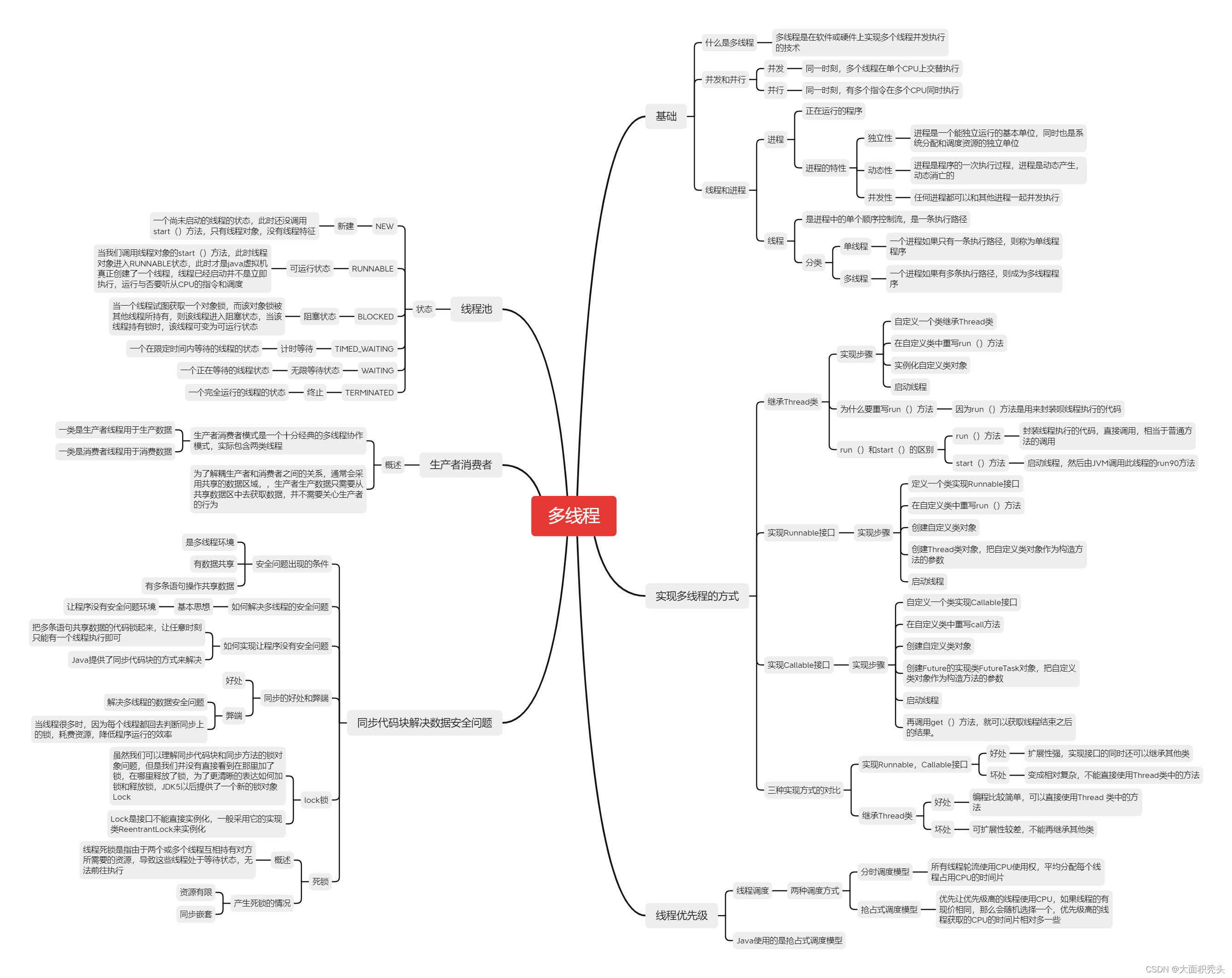
线程池执行任务流程
线程池新增线程过程
简单使用
看源码,当然要先会简单使用:
public static void main(String[] args) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(1, 1, 0, TimeUnit.SECONDS, new LinkedBlockingQueue<>(1),
new ThreadPoolExecutor.CallerRunsPolicy());
executor.execute(() -> {
System.out.println("线程池执行");
});
}我们创建了一个ThreadPoolExecutor对象,然后调用execute方法
构造函数
源码中共有4中构造方法

最终都是调用最后一个构造方法,其他构造都是给出了默认配置,比如默认线程工厂,默认拒绝策略。所以我们只看参数最长的构造
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}可以看出来有两步,第一步判断参数是否合理,第二步给属性赋值。重要字段具体含义不再赘述,不懂的看文章开头那篇文章。比较生疏的是acc这个属性,他是一个三元表达式去赋值,判断检查操作是否有权限执行,如果有权限则拿到权限控制的上下文,源码中属性注释也说了,该属性用来执行finalizer。
execute方法
这个方法分三步:
- 如果运行线程比核心线程数少
- 如果任务可以成功的放入队列
- 如果任务放入队列失败,我们就新增线程,如果失败则执行拒绝策略或是因为线程池关闭了
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();// 获取当前工作线程数和线程池运行状态
if (workerCountOf(c) < corePoolSize) { // 判断工作线程是否比核心线程少
if (addWorker(command, true)) // 新增worker
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) { // 线程池状态是否是running,是的话往阻塞队列加任务
int recheck = ctl.get(); // 双重检查,因为从上次检查到进入此方法,线程池可能改变状态
if (! isRunning(recheck) && remove(command)) // 如果当前线程池状态不是RUNNING则从队列删除任务
reject(command); // 拒绝策略触发
else if (workerCountOf(recheck) == 0) // wc如果是0时,则新增worker执行queue的任务
addWorker(null, false);
}
else if (!addWorker(command, false))// 阻塞队列已满才会走的逻辑
reject(command);
}execute中出现的ctl属性
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));private static int ctlOf(int rs, int wc) { return rs | wc; }
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; } private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS; private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;可以看出来ctl的类型是原子整数,初始值是状态或上工作线程数。cti共同记录了运行状态和工作线程数。ctl的组成前三位是状态,后29位是表示线程数。
善用位运算可以节省空间(复合值),而在这里我认为是想可以保证状态和数量的统一变化。
顺便补一下线程池的状态和生命周期的转换:

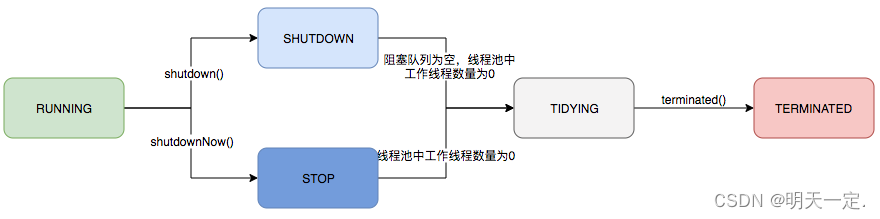
execute中出现的addWorker方法
该方法主要分为两步:
- cas自旋新增线程
- 创建线程实例并且执行任务
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 线程池状态不是running;线程池状态为SHUTDOWN,且要执行的任务不为空;线程池状态为SHUTDOWN,且任务队列为空;都返回失败
if (rs >= SHUTDOWN && ! (rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
// 工作线程数>=线程池容量 || 工作线程数>=(核心线程数||最大线程数)
if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c)) // 线程新增自旋成功
break retry; // 退出外层循环
c = ctl.get(); // Re-read ctl
// 重新获取状态和之前状态对比,若一样则内层循坏,否则外循环
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false; // 工作线程调用start()方法标志
boolean workerAdded = false; // 工作线程被添加标志
Worker w = null;
try {
w = new Worker(firstTask); // 创建工作线程实例
final Thread t = w.thread; // 获取工作线程持有的线程实例
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int rs = runStateOf(ctl.get());
// 线程池状态为RUNNING或者(线程池状态为SHUTDOWN并且没有新任务时)
if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // 预检查该线程状态
throw new IllegalThreadStateException();
workers.add(w); // 线程加入到存放工作线程的HashSet容器,workers全局唯一并被mainLock持有。方便索引出线程
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;// 工作线程被添加标志置为true
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start(); // 调用该线程执行任务
workerStarted = true; // 工作线程调用start()方法标志置为true
}
}
} finally {
if (! workerStarted) // 如果线程启动失败
addWorkerFailed(w);
}
return workerStarted;
}流程辅助查看
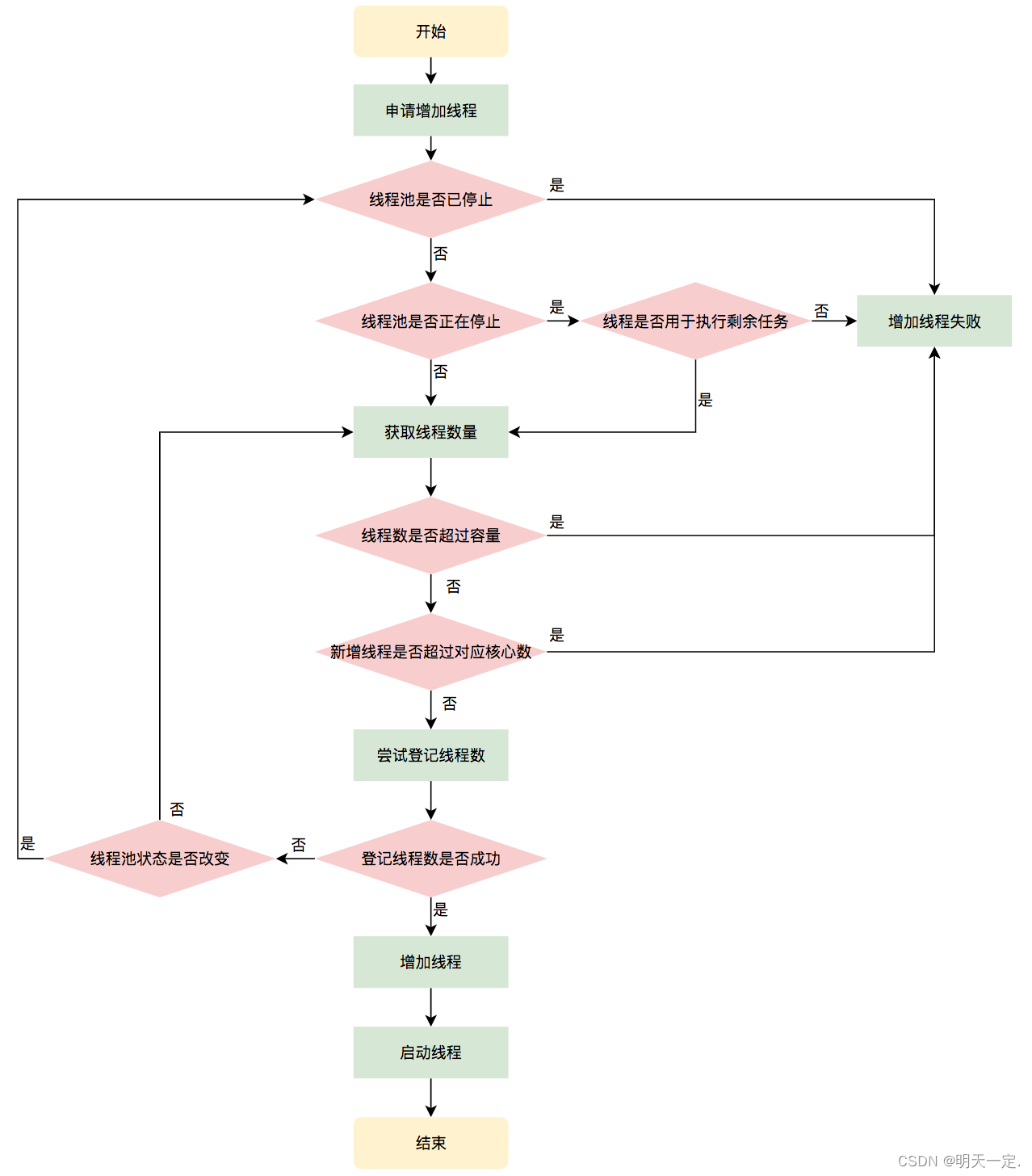
addWorker中出现的addWorkerFailed方法
回滚工作线程的创建
private void addWorkerFailed(Worker w) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (w != null)
workers.remove(w);// 从hash表移除
decrementWorkerCount(); // ctl减1
tryTerminate(); // 尝试把线程池状态变为Terminate
} finally {
mainLock.unlock();
}
}addWorker中出现的Worker类
它是ThreadPoolExecutor的内部类,继承了AQS实现了Runnable接口,我们主要关注它的run方法
public void run() {
runWorker(this);
}
Worker类中run方法出现的runWorker方法
真正执行任务的方法,通过getTask从队列拿任务
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask; // 获取工作线程中用来执行任务的线程实例
w.firstTask = null;
w.unlock(); // 允许中断
boolean completedAbruptly = true; // 线程意外终止标志
try {
// 如果当前任务不为空,则直接执行;否则调用getTask()从任务队列中取出一个任务执行
while (task != null || (task = getTask()) != null) {
w.lock();
// 如果状态值大于等于STOP且当前线程还没有被中断,则主动中断线程
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task); // 任务执行前的回调,空实现,可以在子类中自定义
Throwable thrown = null;
try {
task.run(); // 执行线程任务
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown); // 任务执行后的回调,空实现,可以在子类中自定义
}
} finally {
task = null; // 将循环变量task设置为null,表示已处理完成
w.completedTasks++; // 当前已完成的任务数+1
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly); // 工作线程退出
}
}runWorker流程图如下

runWorker中出现的getTask
根据配置,对任务进行阻塞或超时等待。
private Runnable getTask() {
boolean timedOut = false; // // 通过timeOut变量表示拿出的线程是否超时了
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 检查线程池状态以及阻塞队列的大小
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// 当前线程是否允许超时销毁的标志
// 允许超时销毁:当线程池允许核心线程超时 或 工作线程数>核心线程数
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
// 如果(当前线程数大于最大线程数 或 (允许超时销毁 且 当前发生了空闲时间超时))
// 且(当前线程数大于1 或 阻塞队列为空)
// 则减少worker计数并返回null
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
// 根据线程是否允许超时判断用poll还是take(会阻塞)方法从任务队列头部取出一个任务
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}runWorker中出现的processWorkerExit
private void processWorkerExit(Worker w, boolean completedAbruptly) {
if (completedAbruptly) // 如果中断,调整减少worker的数量
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
completedTaskCount += w.completedTasks;
workers.remove(w); // 从工作线程集合中移除该工作线程
} finally {
mainLock.unlock();
}
tryTerminate(); // 尝试把线程状态变为terminate
int c = ctl.get();
// 如果是RUNNING 或 SHUTDOWN状态
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
// 如果允许核心线程超时则最小线程数是0,否则最小线程数等于核心线程数
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
// 如果阻塞队列非空,则至少要有一个线程继续执行剩下的任务
if (min == 0 && ! workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
return; // replacement not needed
}
addWorker(null, false); // 重新创建一个worker来代替被销毁的线程
}
}项目中如何配置使用线程池
用过线程池的都知道,那些核心参数是真的不好确定,需要做大量修改、发布、验证这套工作。市面上常说的是分io密集型和cpu密集型,但是具体参数不是那么好确定的,比如线程池设置为 2*CPU 核心数,有点像是把任务都当做 IO 密集型去处理了。而且一个项目里面一般来说不止一个自定义线程池吧?比如有专门处理数据上送的线程池,有专门处理查询请求的线程池,这样去做一个简单的线程隔离。但是如果都用这样的参数配置的话,显然是不合理的。
所以我们需要一个可动态配置的线程池,可以自己写一个模块,也可以用已经开源的dynamic-tp或者hippo4j。具体实现还是利用ThreadPoolExecutor中的一些set方法
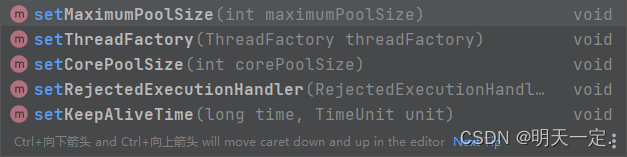
关于队列的动态调整:美团他们有一个名字为 ResizableCapacityLinkedBlockIngQueue 的队列:很明显,这是一个自定义队列了。我们也可以按照这个思路自定义一个队列,让其可以对 Capacity 参数进行修改即可。把 LinkedBlockingQueue 粘贴一份出来,修改个名字,然后把 Capacity 参数的 final 修饰符去掉,并提供其对应的 get/set 方法。然后在程序里面把原来的队列换掉即可。
不过比较好的是开源项目自带监控告警和配置文件配置会比较全面一点。具体配置还是得做大量修改、发布、验证。不过也可以从网上常说的理论值入手去尝试。
参考
【超详细】Java线程池源码解析 - 掘金 (juejin.cn)
Java线程池实现原理及其在美团业务中的实践 - 美团技术团队 (meituan.com)