多传感器融合相关的理论真的可以非常复杂,而在感知方面,由于可以和深度学习做结合,所以很多工作可以变得简单有效,有时候一个简单的特征融合都会有很好的效果。
本文结合 3D 物体检测,为大家带来两篇工作,一篇是 PointPainting,一篇是Multimodal Virtual Point 3D Detection (后称MVP).
PointPainting
这篇文章并不算久远,但是很适合作为多传感器的入门读物。在当时 3D 物体检测还是以 Lidar-Only 的方式为主,因为融合的算法并不能体现明显的优势,但是很显然,Lidar 的信息有限、检测精度有限。如下图可以看到,在25m远的地方,人和杆子仅根据点云已经很难区分了,但是图像上却很容易区分。

针对Lidar信息有限的问题,解决思路有两个,一个是挖掘更多的信息,但是这条路很难走;另一个思路就是加信息,那么怎么加信息就是我们要关注的点了。
PointPainting的解决思路是为每个点赋上一个语义,这个语义从图像中可以获取,结合论文的流程图加以理解:

在有了带语义的点云之后,再输入到一个现有的点云检测网络当中即可。这是 CVPR 2020 的工作。

工作虽然很简单,但是效果提升很明显。不过我们还是需要有一些思考,虽然这样的方式可以提升性能,但是图像分割不是绝对准确的,如果赋错了怎么办?而且点云依旧是稀疏的,是不是可以像PseudoLidar这类单目3D物体检测的方法,去补一些点呢?我们来看一看 MVP 是怎么思考这些问题的。
MVP
我们首先看一下 3D 物体检测常见的failure case (图像来自MVP github):
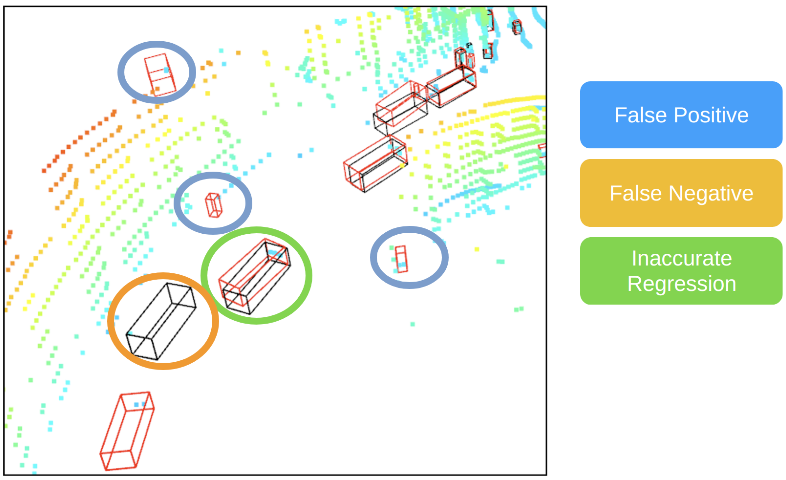
在远处的物体往往会出现误检、漏检以及检测不准确的问题。这是由于雷达过于稀疏:

那么按照 PointPainting 的做法我们会为这些稀疏的点赋上语义,如下图:

但是稀疏的问题仍然存在,所以MVP提出的观点是,应当补充适当的点,使得远处的点稠密,又不至于整理计算开销太大:

方法也很简单,其实深度估计都不需要,我们根据图像得到的 Mask,可以先计算一些 Mask 内有多少 Lidar 点,如果满足一定阈值,比如20个点,我们就不做额外操作,如果不满足,我们就在mask内随机选若干个像素,深度依据最近邻原则补上,然后再投影到3D空间,这样做不仅不会增加很大的开销,而且可以大幅提升性能:

可以看到 MVP 的 performance 是远超 PointPainting 的。
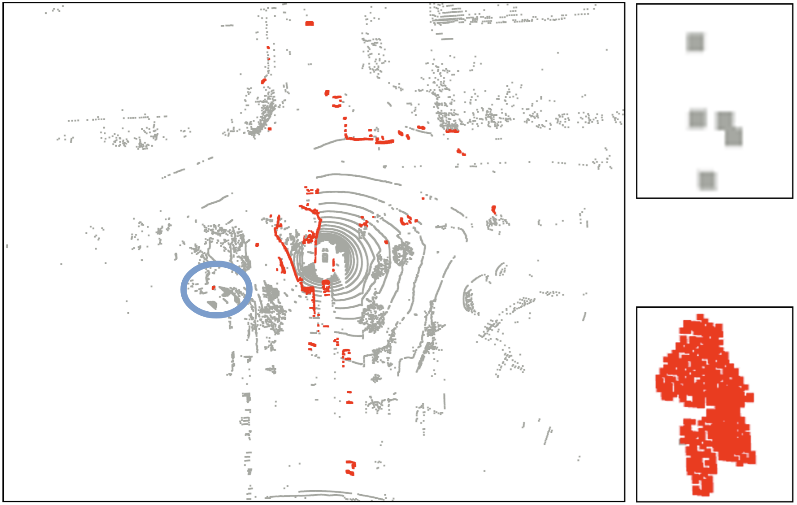
我们在选取一帧补充后的点云做可视化:
总结
所以有些时候思想往往更重要,比如 MAE 其实也十分易懂,但是效果却很惊艳,简洁到不知道怎么修改,当然这是开玩笑了。这两篇工作都是非常简单,但是实验都做得非常充分,MVP 还结合了最新的 MaskFormer 做了一些实验。这也给了我们很大启发,有时候分析清楚问题往往比设计一个复杂又不通用的算法要有意义多。
ABOUT
关于我们
深蓝学院是专注于人工智能的在线教育平台,已有数万名伙伴在深蓝学院平台学习,很多都来自于国内外知名院校,比如清华、北大等。