4.3 案例:电影评分数据分析
使用电影评分数据进行数据分析,分别使用DSL编程和SQL编程,熟悉数据处理函数及SQL使用,业务需求说明:
对电影评分数据进行统计分析,获取Top10电影(电影评分平均值最高,并且每个电影被评分的次数大于2000)。
数据集ratings.dat总共100万条数据,数据格式如下,每行数据各个字段之间使用双冒号分开:

数据处理分析步骤如下:
第一步、读取电影评分数据,从本地文件系统读取
第二步、转换数据,指定Schema信息,封装到DataFrame
第三步、基于SQL方式分析
第四步、基于DSL方式分析
数据 ETL
读取电影评分数据,将其转换为DataFrame,使用指定列名方式定义Schema信息,代码如下:
// 构建SparkSession实例对象
val spark: SparkSession = SparkSession.builder()
.master("local[4]")
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.getOrCreate()
// 导入隐式转换
import spark.implicits._
// 1. 读取电影评分数据,从本地文件系统读取
val rawRatingsDS: Dataset[String] = spark.read.textFile("datas/ml-1m/ratings.dat")
// 2. 转换数据
val ratingsDF: DataFrame = rawRatingsDS
// 过滤数据
.filter(line => null != line && line.trim.split("::").length == 4)
// 提取转换数据
.mapPartitions{iter =>
iter.map{line =>
// 按照分割符分割,拆箱到变量中
val Array(userId, movieId, rating, timestamp) = line.trim.split("::")
// 返回四元组
(userId, movieId, rating.toDouble, timestamp.toLong)
}
}
// 指定列名添加Schema
.toDF("userId", "movieId", "rating", "timestamp")
/*
root
|-- userId: string (nullable = true)
|-- movieId: string (nullable = true)
|-- rating: double (nullable = false)
|-- timestamp: long (nullable = false)
*/
//ratingsDF.printSchema()
/*
+------+-------+------+---------+
|userId|movieId|rating|timestamp|
+------+-------+------+---------+
| 1| 1193| 5.0|978300760|
| 1| 661| 3.0|978302109|
| 1| 594| 4.0|978302268|
| 1| 919| 4.0|978301368|
+------+-------+------+---------+
*/
//ratingsDF.show(4)
使用 SQL 分析
首先将DataFrame注册为临时视图,再编写SQL语句,最后使用SparkSession执行,代码如下:
// TODO: 基于SQL方式分析
// 第一步、注册DataFrame为临时视图
ratingsDF.createOrReplaceTempView("view_temp_ratings")
// 第二步、编写SQL
val top10MovieDF: DataFrame = spark.sql(
"""
|SELECT
| movieId, ROUND(AVG(rating), 2) AS avg_rating, COUNT(movieId) AS cnt_rating
|FROM
| view_temp_ratings
|GROUP BY
| movieId
|HAVING
| cnt_rating > 2000
|ORDER BY
| avg_rating DESC, cnt_rating DESC
|LIMIT
| 10
""".stripMargin)
//top10MovieDF.printSchema()
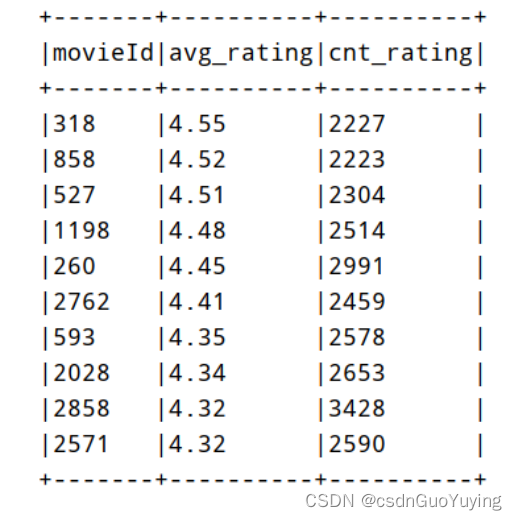
top10MovieDF.show(10, truncate = false)
运行程序结果如下:
使用 DSL 分析
调用Dataset中函数,采用链式编程分析数据,核心代码如下:
// TODO: 基于DSL=Domain Special Language(特定领域语言) 分析
import org.apache.spark.sql.functions._
val resultDF: DataFrame = ratingsDF
// 选取字段
.select($"movieId", $"rating")
// 分组:按照电影ID,获取平均评分和评分次数
.groupBy($"movieId")
.agg( //
round(avg($"rating"), 2).as("avg_rating"), //
count($"movieId").as("cnt_rating") //
)
// 过滤:评分次数大于2000
.filter($"cnt_rating" > 2000)
// 排序:先按照评分降序,再按照次数降序
.orderBy($"avg_rating".desc, $"cnt_rating".desc)
// 获取前10
.limit(10)
//resultDF.printSchema()
resultDF.show(10)
其中使用SparkSQL中自带函数库functions,在org.apache.spark.sql.functions中,包含常用函数,有些与Hive中函数库类似,但是名称不一样。
使用需要导入函数库:import org.apache.spark.sql.functions._
保存结果数据
将分析结果数据保存到外部存储系统中,比如保存到MySQL数据库表中或者CSV文件中。
// TODO: 将分析的结果数据保存MySQL数据库和CSV文件
// 结果DataFrame被使用多次,缓存
resultDF.persist(StorageLevel.MEMORY_AND_DISK)
// 1. 保存MySQL数据库表汇总
resultDF
.coalesce(1) // 考虑降低分区数目
.write
.mode("overwrite")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.jdbc(
"jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnic
ode=true",
"db_test.tb_top10_movies",
new Properties()
)
// 2. 保存CSV文件:每行数据中个字段之间使用逗号隔开
resultDF
.coalesce(1)
.write.mode("overwrite")
.csv("datas/top10-movies")
// 释放缓存数据
resultDF.unpersist()
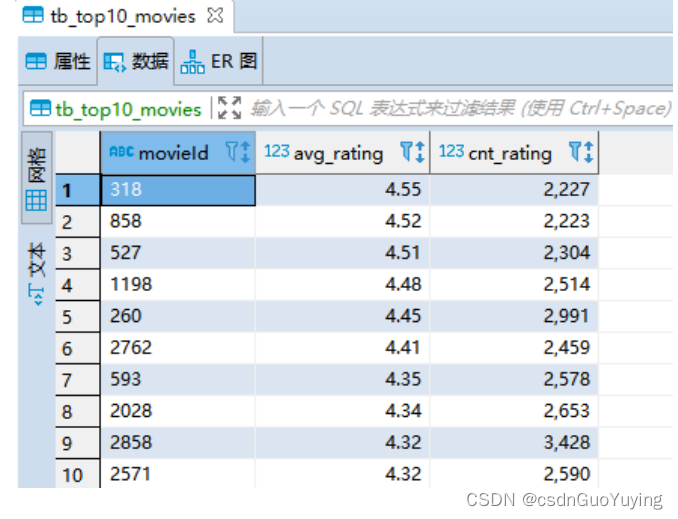
查看数据库中结果表的数据:
案例完整代码
电影评分数据分析,经过数据ETL、数据分析(SQL分析和DSL分析)及最终保存结果,整套数据处理分析流程,其中涉及到很多数据细节,完整代码如下:
import java.util.Properties
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
import org.apache.spark.storage.StorageLevel
/**
* 需求:对电影评分数据进行统计分析,获取Top10电影(电影评分平均值最高,并且每个电影被评分的次数大于2000)
*/
object SparkTop10Movie {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象
val spark: SparkSession = SparkSession.builder()
.master("local[4]")
.appName(this.getClass.getSimpleName.stripSuffix("$"))
// TODO: 设置shuffle时分区数目
.config("spark.sql.shuffle.partitions", "4")
.getOrCreate()
// 导入隐式转换
import spark.implicits._
// 1. 读取电影评分数据,从本地文件系统读取
val rawRatingsDS: Dataset[String] = spark.read.textFile("datas/ml-1m/ratings.dat")
// 2. 转换数据
val ratingsDF: DataFrame = rawRatingsDS
// 过滤数据
.filter(line => null != line && line.trim.split("::").length == 4)
// 提取转换数据
.mapPartitions{iter =>
iter.map{line =>
// 按照分割符分割,拆箱到变量中
val Array(userId, movieId, rating, timestamp) = line.trim.split("::")
// 返回四元组
(userId, movieId, rating.toDouble, timestamp.toLong)
}
}
// 指定列名添加Schema
.toDF("userId", "movieId", "rating", "timestamp")
/*
root
|-- userId: string (nullable = true)
|-- movieId: string (nullable = true)
|-- rating: double (nullable = false)
|-- timestamp: long (nullable = false)
*/
//ratingsDF.printSchema()
/*
+------+-------+------+---------+
|userId|movieId|rating|timestamp|
+------+-------+------+---------+
| 1| 1193| 5.0|978300760|
| 1| 661| 3.0|978302109|
| 1| 594| 4.0|978302268|
| 1| 919| 4.0|978301368|
+------+-------+------+---------+
*/
//ratingsDF.show(4)
// TODO: 基于SQL方式分析
// 第一步、注册DataFrame为临时视图
ratingsDF.createOrReplaceTempView("view_temp_ratings")
// 第二步、编写SQL
val top10MovieDF: DataFrame = spark.sql(
"""
|SELECT
| movieId, ROUND(AVG(rating), 2) AS avg_rating, COUNT(movieId) AS cnt_rating
|FROM
| view_temp_ratings
|GROUP BY
| movieId
|HAVING
| cnt_rating > 2000
|ORDER BY
| avg_rating DESC, cnt_rating DESC
|LIMIT
| 10
""".stripMargin)
//top10MovieDF.printSchema()
top10MovieDF.show(10, truncate = false)
println("===============================================================")
// TODO: 基于DSL=Domain Special Language(特定领域语言) 分析
import org.apache.spark.sql.functions._
val resultDF: DataFrame = ratingsDF
// 选取字段
.select($"movieId", $"rating")
// 分组:按照电影ID,获取平均评分和评分次数
.groupBy($"movieId")
.agg( //
round(avg($"rating"), 2).as("avg_rating"), //
count($"movieId").as("cnt_rating") //
)
// 过滤:评分次数大于2000
.filter($"cnt_rating" > 2000)
// 排序:先按照评分降序,再按照次数降序
.orderBy($"avg_rating".desc, $"cnt_rating".desc)
// 获取前10
.limit(10)
//resultDF.printSchema()
resultDF.show(10)
// TODO: 将分析的结果数据保存MySQL数据库和CSV文件
// 结果DataFrame被使用多次,缓存
resultDF.persist(StorageLevel.MEMORY_AND_DISK)
// 1. 保存MySQL数据库表汇总
resultDF
.coalesce(1) // 考虑降低分区数目
.write
.mode("overwrite")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.jdbc(
"jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnic
ode=true",
"db_test.tb_top10_movies",
new Properties()
)
// 2. 保存CSV文件:每行数据中个字段之间使用逗号隔开
resultDF
.coalesce(1)
.write.mode("overwrite")
.csv("datas/top10-movies")
// 释放缓存数据
resultDF.unpersist()
// 应用结束,关闭资源
Thread.sleep(10000000)
spark.stop()
}
}