模型学习
1 随机森林
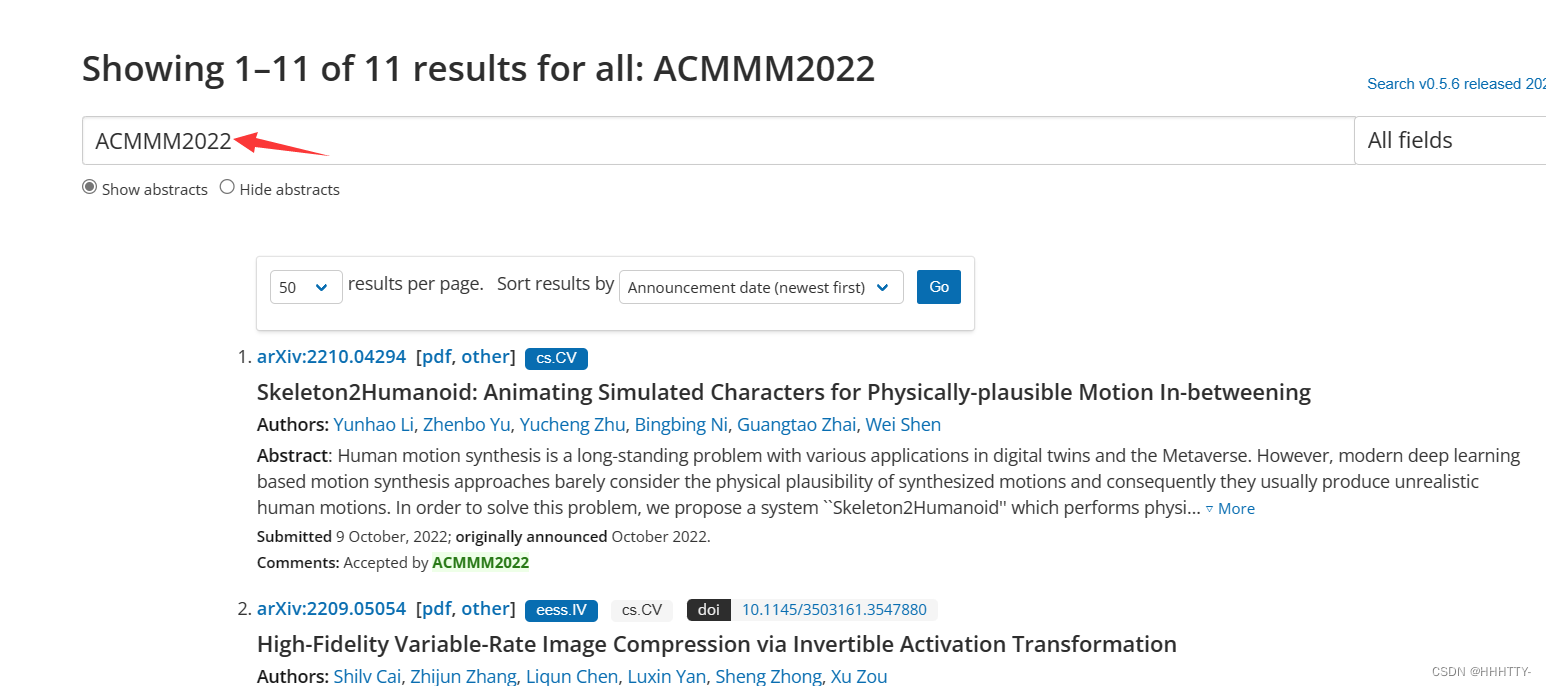
https://blog.csdn.net/weixin_35770067/article/details/107346591?
森林就是建立了很多决策树,把很多决策树组合到一起就是森林。
这些决策树都是为了解决同一任务建立的,最终的目标也都是一致的,最后将其结果来平均即可。
随机:因为输入一样建模的决策树也一样求平均后的结果就一样,这就没有意义了,所以需要随机,需要二重随机性,一重是输入数据随机,另一重是建模选择的特征随机。
随机森林的目的就是要通过大量的基础树模型找到最稳定可靠的结果。
1.随机森林首先是一种并联的思想,同时创建多个树模型,它们之间是不会有任何影响的,使用相同参数,只是输入不同。
2.为了满足多样性的要求,需要对数据集进行随机采样,其中包括样本随机采样与特征随机采样,目的是让每一棵树都有个性。
3.将所有的树模型组合在一起。在分类任务中,求众数就是最终的分类结果;在回归任务中,直接求平均值即可。
**随机森林袋外误差:**进行特征的重要性度量,选择重要性较高的特征。
- 对每一棵决策树,选择相应的袋外误差数据(out of bag,OOB)计算袋外误差,记为errOOB1
- 随机对袋外数据OOB所有样本的特征X加入噪声干扰(可以随机改变样本在特征X处的值),再次计算袋外数据误差,记为errOOB2。
- )假设森林中有N棵树,则特征X的重要性=∑(errOOB2-errOOB1)/N。这个数值之所以能够说明特征的重要性是因为,如果加入随机噪声后,袋外数据准确率大幅度下降(即errOOB2上升),说明这个特征对于样本的预测结果有很大影响,进而说明重要程度比较高。
2 LESS模型
定量遥感中建立了很多模型,主要服务于遥感的反演,从遥感观测的一些信号反过去推算一些植被特征,这就需要建立地表参量与遥感参量的关系式。
植被是很复杂
LESS模型是一个三维辐射传输模型,原理是基于光线追踪的
一维将叶片假想成水平分布的这些场景,几何光学模型把它简化成规则的图形
和真实的模型有很大的偏差,然后就有了三维辐射传输模型,它有了美篇叶子的形状和朝向。

咱们用的最多的一维模型,将1入射与观测、光学属性和一些结构参数输入到模型中,就得到遥感信号
而三维模型输入的是一种三维结构,能够更精确的表达场景,甚至可以对每片叶子和每个枝干的详细结构进行表达。三维模型可以有更丰富的输出。

OBJECT,是一个物体,也可以说是一个对象,然后这个对象,有很多不同的组分,也就是Componet,分别赋予不同的光学属性,如何表达?也就是OBJ格式

如右边的这个三维坐标所示,它与常见的三维坐标轴不一样,Y的方向是向上的,V101代表点,它的X=1,y=0,z=1,在图中就是标1的那个点,同理标出1234四个点,f123(facet平面)代表把123这3个点连接起来组成一个三角形,按照右手螺旋法则,它的法向量向下,f234的法向量向上的。最终构成的是一个四边形。
g代表group组,也就是这边的component
LESS模型基本原理