一、Redis概念
Redis是⼀个⾼性能的key-value数据库,它是完全开源免费的,⽽且redis是⼀个NOSQL类型数据库,是为了解决⾼并发、⾼扩展,⼤数据存储等⼀系列的问题⽽产⽣的数据库解决⽅案,是⼀个⾮关系型的数据库。
二、Redis特点、数据类型及使用场景
(1)Redis基于k-v数据库(本质是一个k-v类型的内存数据库),访问速度快
(2)支持数据的持久化(可以将数据保存在硬盘,重启Redis之后可以重新写入内存)
(3)支持主从数据备份
(4)支持事务
(5)支持丰富的数据类型,主要包括string、list、hash、set、zset五种,Redis5.0以后加入了新的数据类型stream
String
常用命令:
set赋值
get获取指定key的值
mset一次为多个key赋值
mget一次获取多个key的值
setex设置key的有效时间
incr对key的值做加加操作并返回新的值
decr命令将 key 中储存的数字值减一
应用场景:String是最常用的一种数据类型,普通的key/value都可归为此类。
实现方式:String在redis内部存储默认的就是字符串,被redisObject所引用,当遇到incr、decr命令是会转成数值型进行计算,此时redisObject的encoding字段是int。
Hash
常用命令:
hset、hget、
hgetall获取一个key下面的所有filed和value
hkeys获取所有的key
hvals获取某个key下的所有value
hexists测试给定key下的filed是否存在
应用场景:存储一个用户信息对象数据,其中包括用户ID、用户姓名、年龄和生日,通过用户ID我们希望获取该用户的姓名或年龄或生日。
实现方式:
Redis的Hash实际是内部存储的value是一个HashMap,并提供了直接存取这个Map成员的接口。(key是用户ID,value是Map)
这个Map的key是成员的属性名,value是属性值,这样对数据的修改和存取都可以直接通过其内部Map的Key(Redis里称 内部Map的key为filed),也就是通过key用户id+filed属性标签即可操作对应属性数据。
当前HashMap的实现有两种⽅式:当HashMap的成员⽐较少时Redis为了节省内存会采⽤类似⼀维数组的⽅式来紧凑存储,而不会采用真正的HashMap结构,这时对应的value的redisObject的encoding为zipmap,当成员数量增大时会自动转成真正的HashMap,此时RedisObject的encoding字段为int。
List
常用命令:
lpush: 从头(链表左侧)添加元素;
lpop:从list头部获取元素
rpush:从尾部(链表右侧)添加元素;
rpop:从list尾部获取元素
lrange:查看list的所有元素;lrange list名称0 -1
linsert: 在某个元素的前后插入元素linsert list before/after原有元素新元素
lrem:移除元素Irem list 2(移除个数) "key"
rpoplpush: 从原来的list的尾部删除元素,并将其插入到新的Iist的头部
lindex: 返回指定索引的值
llen:返回list的元素 个数
应用场景:Redis list的应用场景非常多,也是Redis最重要的数据结构之一,比如twitter的关注列表,粉丝列表等都可以用Redis的list结构来实现;
实现方式:Redis list的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
Set
常用命令:
sadd:添加元素
smembers:获取集合中所有元素
sismember:判断元素是否在集合中
srem:删除元素
scard:获取元素个数,相当于count
spop:随机返回删除的元素
sdif:差集,返回在第-个set里面而不在后面任何一个set里面的项(谁在前以谁为标准)
sdiffstore:差集并保留结果
sinter:交集,返回多个set里面都有的项
sinterstore:交集并保留结果
sunion:并集
sunionstore:并集并保留结果
smove:移动元素到另一个集合
应用场景:Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供
的;
实现方式:set的内部实现是一个value永远为null的HashMap,实际就是通过计算hash的方式来快速排重的,这也是set能提供判断一个成员是否在集合内的原因。
Sorted Set
常用命令:
zadd:添加元素
zrange:获取索引区间内的元素
zrangebyscore:获取分数区间内的元素
应用场景:Redis sorted set的使用场景与set类似,区别是set不是自动有序的,而sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。当你需要一个有序的并且不重复的集合列表,那么可以选择sorted set数据结构.比如twitter 的public timeline可以以发表时间作为score来存储,这样获取时就是自动按时间排好序的。
实现方式:Redis sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。

三、Redis和MemCache区别
1.在存储方式方面
Memecache把数据全部存在内存中,不能持久化数据;
Redis支持数据的持久化(RDB和AOF)
RDB:在不同的时间点,将Redis某一时刻的数据生成 快照,并保存在磁盘上。
触发方式:自动触发(在redis.conf文件配置)、手动触发(save命令:执行此命令会阻塞Redis服务器;bgsave命令:执行该命令时,Redis会在后台异步进行快照操作)。
AOF: 只允许追加不允许改写文件,是将 Redis执行过的所有写指令记录下来,在下次redis重启的时候,只需要把这些指令从前到后重复执行一遍,就可以实现数据的恢复。
默认的AOF持久化策略是每秒钟一次同步策略(AOF同步策略有always、no、everysec三种)。
RDB和AOF两种方式可以同时使用,这时如果Redis重启则会优先采用AOF方式进行数据恢复,因为AOF方式的数据恢复完整度更高。
2.在数据类型方面
Memcache所有的值都是简单的字符串;
Redis支持更丰富的数据类型。
3.在底层模型方面
redis在2.0版本后增加了自己的VM特性,突破物理内存的限制;
Memcache可以修改:最大可用内存,采用L RU算法。
4.数据一致性方面
Memcache在并发场景下,用CAS保证一致性;
Redis事务支持比较弱,只能保证事务中的每个操作连续执行。
Memcache的介绍
1. Memcached的优点:
Memcached可以利用多核优势,单实例吞吐量极高,可以达到几十万QPS (取决于key、 value的字节大小以及服务器硬件性能,日常环境中QPS高峰大约在46w左右)。
2. Memcached的局限性:
只支持简单的key/value数据结构,不像Redis可以支持丰富的数据类型。
无法进行持久化,数据不能备份,只能用于缓存使用,且重启后数据全部丢失。
无法进行数据同步,不能将Memcached中的数 据迁移到其他Memcached实例中。
Memcached内存分配采用Slab Allocation机制管理内存,value大小分布 差异较大时会造成内存利用率降低,并引发低利用率时依然出现踢出等问题。
需要用户注重value设计。
四、关于Redis的回收策略,过期机制的相关问题
Redis内存数据集上升到一定大小的时候,会实行数据淘汰策略。
Redis key过期的方式有三种:
1.被动删除: 当读、写一个已经过期的key时,会触发惰性删除策略,直接删除掉过期的key
2.主动删除:由于惰性删除策略无法保证冷数据被及时删掉,所以Redis会定期主动淘汰一批已过期的key
3.当前已用内存超过maxmemory时,触发主动清理策略
当前已用内存超过maxmemory限定时,触发主动清理策略,主动清理策略有6种:
1.vltil-lru:从已设置过期时间的数据集中挑选"最近最少使用"的数据进行淘汰;
2.volitilet:从已设置过期时间的数据集中挑选“将要过期”的数据进行淘汰;
3. volitile random:从已设置过期时间的数据集中"任意挑选数据进行淘汰;
4. alkeys-lru:从数据集中挑选“最近最少使用”的数据进行淘汰
5. allkeys-random:从数据集中"任意选择"数据进行淘汰;
6. no envicition:设置永不过期,禁止驱逐数据;
五、为什么redis需要把所有数据放到内存中?
Redis为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘。所以redis具有快速和数据持久化的特征。如果不将数据放在内存中,磁盘I/O速度为严重影响redis的性能。在内存越来越便宜的今天,redis将会越来越受欢迎。
如果设置了最大使用的内存,则数据已有记录数达到内存限值后不能继续插入新值。
六、Redis是单进程单线程的
Redis利用队列技术将并发访问变为串行访问,消除了传统数据库串行控制的开销。
七、Redis的并发竞争问题如何解决?
Redis为单进程单线程模式,采用队列模式将并发访问变为串行访问。Redis本身没有锁的概念,Redis对于多个客户端连接并不存在竞争,但是在Jedis客户端对Redis进行并发访问时,会发生连接超时、数据转换错误、阻塞、客户端关闭连接等问题,这些问题均是由于客户端连接混乱造成。
对此有2种解决方法:
(1)客户端角度,为保证每个客户端间正常有序与Redis进行通信,对连接进行池化,同时对客户端读写Redis操作采用内部锁synchronized。
(2)服务器角度,利用setnx实现锁。
注:对于第一种,需要应用程序自己处理资源的同步,可以使用的方法比较通俗,可以使用synchronized也可以使用lock;第二种需要用到Redis的setnx命令,但是需要注意一些问题。
八、Redis缓存的三大问题及其解决方案
8.1、缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求。如发起 id 为-1 的数据或者特别大的不存在的数据。有可能是黑客利用漏洞攻击从而去压垮应用的数据库。
解决方案:
(1)如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果(null)进行缓存,设置空结果的过期时间会很短,最长不超过五分钟,这样可以防止攻击用户反复用同一个id暴力攻击。(简单粗暴)
(2)设置可访问的名单(白名单):使用bitmaps类型定义一个可以访问的名单,名单id作为bitmaps的偏移量,每次访问和bitmap里面的id进行比较,如果访问id不在bitmaps里面,进行拦截,不允许访问。
(3)采引入布隆过滤器,在访问Redis之前判断数据是否存在。将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。(布隆过滤器是一种比较独特数据结构,有一定的误差。当它指定一个数据存在时,它不一定存在,但是当它指定一个数据不存在时,那么它一定是不存在的。)
(4)进行实时的数据监控,发现Redis在命中率急速降低时,排查访问对象和访问数据,设置黑名单。
缓存空数据与布隆过滤器都能有效解决缓存穿透问题,但使用场景有着些许不同;
当一些恶意攻击查询查询的 key 各不相同,而且数量巨多,此时缓存空数据不是一个好的解决方案。因为它需要存储所有的 Key,内存空间占用高。并且在这种情况下,很多 key 可能只用一次,所以存储下来没有意义。所以对于这种情况而言,使用布隆过滤器是个不错的选择;
而对与空数据的 Key 数量有限、Key 重复请求效率较高的场景而言,可以选择缓存空数据的方案。
Copypublic Student getStudentsByID(Long id) {
// 从Redis中获取学生信息Studentstudent= redisTemplate.opsForValue().get(String.valueOf(id));
if (student != null) {
return student;
}
// 从数据库查询学生信息,并存入Redis
student = studentDao.selectByStudentId(id);
if (student != null) {
redisTemplate.opsForValue().set(String.valueOf(id), student, 60, TimeUnit.MINUTES);
} else {
// 即使不存在,也将其存入缓存中
redisTemplate.opsForValue().set(String.valueOf(id), null, 60, TimeUnit.SECONDS);
}
return student;
}8.2、缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),问题在于:如果这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
解决方案:
(1)将热点数据设置为永不过期。这时要注意在value当中包含一个逻辑上的过期时间,然后另起一个线程,定期重建这些缓存。
(2)加载DB的时候,要防止并发。加互斥锁:互斥锁可以控制查询数据库的线程访问,但这种方案会导致系统的吞吐量下降,需要根据实际情况使用。

Copypublic String get(key) {
Stringvalue= redis.get(key);
if (value == null) {
// 代表缓存值过期 // 设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能
load db if(redis.setnx(key_mutex, 1, 3 * 60) == 1) {
// 代表设置成功
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
} else {
// 这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可
sleep(50);
get(key);
// 重试
}
} else {
return value;
}
}8.3、缓存雪崩
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
设置热点数据永远不过期。
【事前】高可用缓存:高可用缓存是防止出现整个缓存故障。即使个别节点,机器甚至机房都关闭,系统仍然可以提供服务,Redis 哨兵(Sentinel) 和 Redis 集群(Cluster) 都可以做到高可用;
【事中】缓存降级(临时支持):当访问次数急剧增加导致服务出现问题时,我们如何确保服务仍然可用。在国内使用比较多的是 Hystrix,它通过熔断、降级、限流三个手段来降低雪崩发生后的损失。只要确保数据库不死,系统总可以响应请求,每年的春节 12306 我们不都是这么过来的吗?只要还可以响应起码还有抢到票的机会;
【事后】Redis 备份和快速预热:Redis 数据备份和恢复、快速缓存预热。
九、Redis的持久化机制
Redis提供了两种不同形式的持久化方式:
RDB(Redis DataBase)
AOF(Append Only File)
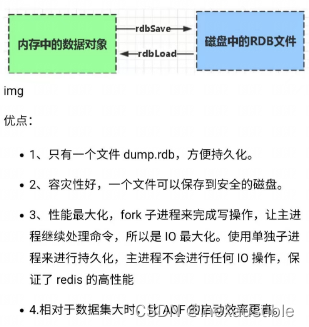
RDB(Redis DataBase)
Redis默认的持久化方式。按照一定的时间将内存中的数据以快照的形式保存到硬盘中,对应产生的数据文件为dump.rdb。通过配置文件中的save参数来定义快照的周期。
恢复的时候将快照文件直接读到内存里。

AOF(Append Only File)
将Redis执行的每次写命令记录到单独的日志文件中,只许追加文件但不可以改写文件,当重启Redis会重新将持久化的日志中文件恢复数据。
当两种方式同时开启的时候,数据恢复Redis会优先选择AOF恢复。

Rewrite
AOF采用文件追加方式,文件会越来越大,为避免出现此种情况,新增了重新机制,当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集,可以使用命令bgrewriteaof。


十、如何保证Redis与数据库的数据一致?
当我们对数据进行修改的时候,到底是先删缓存,还是先写数据库?
1、如果先删缓存,再写数据库: 在高并发场景下,当第一个线程删除了缓存,还没有来得及写数据库,第二个线程来读取数据,会发现缓存中的数据为空,那就会去读数据库中的数据(旧值,脏数据),读完之后,把读到的结果写入缓存(此时,第一个线程已经将新的值写到缓存里面了),这样缓存中的值就会被覆盖为修改前的脏数据。
总结:在这种方式下,通常要求写操作不会太频繁。
解决方案:
1》先操作缓存,但是不删除缓存。将缓存修改为一个特殊值(-999)。客户端读缓存时,发现是默认值,就休眠一小会,再去查一次Redis。 -》 特殊值对业务有侵入。 休眠时间,可能会多次重复,对性能有影响。
2》延时双删。 先删除缓存,然后再写数据库,休眠一小会,再次删除缓存。-》 如果数据写操作很频繁,同样还是会有脏数据的问题。
2、先写数据库,再删缓存: 如果数据库写完了之后,缓存删除失败,数据就会不一致。
总结: 始终只能保证一定时间内的最终一致性。
解决方案:
1》给缓存设置一个过期时间 问题:过期时间内,缓存数据不会更新。
2》引入MQ,保证原子操作。
解决方案:将热点数据缓存设置为永不过期,但是在value当中写入一个逻辑上的过期时间,另外起一个后台线程,扫描这些key,对于已逻辑上过期的缓存,进行删除。
十一、如何设计一个分布式锁?如何对锁性能进行优化?
分布式锁的本质:就是在所有进程都能访问到的一个地方,设置一个锁资源,让这些进程都来竞争锁资源。数据库、zookeeper, Redis。。通常对于分布式锁,会要求响应快、性能高、与业务无关。
Redis实现分布式锁:SETNX key value:当key不存在时,就将key设置为value,并返回1。如果key存在,就返回0。EXPIRE key locktime: 设置key的有效时长。 DEL key: 删除。 GETSET key value: 先GET,再SET,先返回key对应的值,如果没有就返回空。然后再将key设置成value。
1、最简单的分布式锁: SETNX 加锁, DEL解锁。问题: 如果获取到锁的进程执行失败,他就永远不会主动解锁,那这个锁就被锁死了。
2、给锁设置过期时长: 问题: SETNX 和EXPIRE并不是原子性的,所以获取到锁的进程有可能还没有执行EXPIRE指令,就挂了,这时锁还是会被锁死。
3、将锁的内容设置为过期时间(客户端时间+过期时长),SETNX获取锁失败时,拿这个时间跟当前时间比对,如果是过期的锁,就先删除锁,再重新上锁。 问题: 在高并发场景下,会产生多个进程同时拿到锁的情况。
4、setNX失败后,获取锁上的时间戳,然后用getset,将自己的过期时间更新上去,并获取旧值。如果这个旧值,跟之前获得的时间戳是不一致的,就表示这个锁已经被其他进程占用了,自己就要放弃竞争锁。
public boolean tryLock(RedisnConnection conn){
long nowTime= System.currnetTimeMillis();
long expireTIme = nowTime+1000;
if(conn.SETNX("mykey",expireTIme)==1){
conn.EXPIRE("mykey",1000);
return true;
}else{
long oldVal = conn.get("mykey");
if(oldVal != null && oldVal < nowTime){
long currentVal = conn.GETSET("mykey",expireTime);
if(oldVal == curentVal){
conn.EXPIRE("mykey",1000);
return true;
}
return false;
}
return false;
}
}
DEL5、上面就形成了一个比较高效的分布式锁。分析一下,上面各种优化的根本问题在于SETNX和EXPIRE两个指令无法保证原子性。Redis2.6提供了直接执行lua脚本的方式,通过Lua脚本来保证原子性。redission。
十二、Redis如何配置Key的过期时间?它的实现原理是什么?
redis设置key的过期时间:
1、 EXPIRE 。 2 SETEX
实现原理:
1、定期删除: 每隔一段时间,执行一次删除过期key的操作。
2、懒汉式删除: 当使用get、getset等指令去获取数据时,判断key是否过期。过期后,就先把key删除,再执行后面的操作。
Redis是将两种方式结合来使用。
懒汉式删除
定期删除:平衡执行频率和执行时长。
定期删除时会遍历每个database(默认16个),检查当前库中指定个数的key(默认是20个)。随机抽查这些key,如果有过期的,就删除。
程序中有一个全局变量记录到秒到了哪个数据库。
十三、海量数据下,如何快速查找一条记录?
1、使用布隆过滤器,快速过滤不存在的记录。
使用Redis的bitmap结构来实现布隆过滤器。
2、在Redis中建立数据缓存。 - 将我们对Redis使用场景的理解尽量表达出来。
以普通字符串的形式来存储,(userId -> user.json)。 以一个hash来存储一条记录 (userId key-> username field-> , userAge->)。 以一个整的hash来存储所有的数据,UserInfo-> field就用userId , value就用user.json。一个hash最多能支持2^32-1(40多个亿)个键值对。
缓存击穿:对不存在的数据也建立key。这些key都是经过布隆过滤器过滤的,所以一般不会太多。
缓存过期:将热点数据设置成永不过期,定期重建缓存。 使用分布式锁重建缓存。
3、查询优化。
按槽位分配数据,
自己实现槽位计算,找到记录应该分配在哪台机器上,然后直接去目标机器上找。