目录
前言
一、题目理解
背景
解析:
要求
二、建模
1.相关性分析
2.相关特征权重
只希望各位以后遇到建模比赛可以艾特认识一下我,我可以提供免费的思路和部分源码,以后的数模比赛只要我还有时间肯定会第一时间写出免费开源思路,你们的关注和点赞就是我写作的动力!!!想要了解更多的欢迎联系博主,免费获取代码和更多细化思路。
前言
千呼万唤始出来啊同学们,不知道各位在上次国赛建模的时候有没有认识我啊哈哈,还是老样子,思路和模型代码都是免费的,纯爱好。作为一个已经退休的数模老学长岂有不参与一下的理由!让俺再感受一下青春竞赛的氛围,博主参与过十余次数学建模大赛,三次美赛获得过二次M奖一次H奖,国赛二等奖。建模的部分后续将会写出,想要了解更多的欢迎联系博主,免费获取代码和更多细化思路,只希望各位以后遇到建模比赛可以艾特认识一下我,我可以提供免费的思路和部分源码,以后的数模比赛只要我还有时间肯定会第一时间写出免费开源思路,你们的关注和点赞就是我写作的动力!!!大家可以参考。
一、题目理解
首先做MCM要从背景入手了解要做的事情,题目背景:
背景
不同种类的植物对压力的反应方式是不同的。例如,草原对干旱非常敏感。 干旱发生的频率和严重程度各不相同。 大量观察表明,不同物种的数量对植物群落在连续几代遭受干旱周期时如何 适应中起着作用。在一些只有一种植物的群落中,随后几代植物或更多种植物群落中的个体植物不再适应干旱条件。这些观察提出了许多问题。例如, 不同类型植物群落从这种局部生物多样性中获益所需的最低物种数量是多少?随着物种数量的增加,这种现象是如何扩大的?这对植物群落的长期生存能力意味着 什么?
解析:
这么来看的话该题需要我们分析干旱适应性与植物物种数量的关系。那么我们先理清楚问题:
此题为因素关联性分析。首先需要了解植物群落这一概念,找到干旱立地植物群落与植物种类数量之间的关系,其中找到能够代表该植物群落是否处于干旱情况的特征,且能够对干旱周期进行分类处理。如果我们研究的更细致一点,会发现题目中有物种最低数量限制,那么该题建立在实际场景上需要找到不同植物群落物种数目以及对应数量在不同干旱条件下面的变化数据。
再看要求:
要求
预测一个植物群落在各种不规则天气周期下如何随时间 变化。包括降水充足的干旱时期。该模型应考虑干旱周期中不同物种之间的 相互作用。
探索植物群落和更大环境的长期相互作用方面,你可以从模型中得出什么结 论。考虑以下问题:
- 植物群落需要多少不同的植物物种才能受益,随着物种数量的增加会发 生什么?
- 植物群落中的物种类型如何影响你的结果?
- 在未来的天气周期中,干旱发生的频率更高、变化范围更广会产生什么 影响?如果干旱发生频率降低,那么物种数量对总族群的影响是否相同?
- 污染和栖息地减少等其他因素如何影响你的结论?
- 你的模型表明应采取哪些措施来确保植物群落的长期生存能力,以及对大环境的影响?
那么建模目标就很明确了,我们可以以不同干旱条件划分维度:
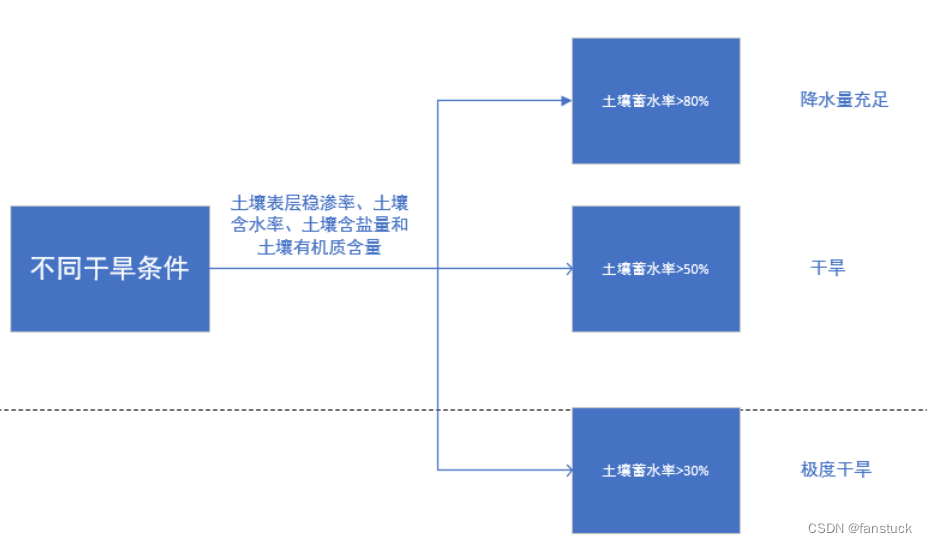
其中干旱直接影响到植被的因素应该从论文或者生物学知识上面寻找,最容易找到的指标也是最直观的反应出干旱情况的指标为干旱强度(SPEI)以及植被NDVI脆弱性指标。其次是植物群落种类和数目:

取同空间时间范围内同地区之间同种类植物群落进行分析:

下图为中亚地区1982-2015年逐次干旱事件的开始时间(年、月)、发生位置(经度、纬度)、持续时间(月)、干旱强度,以及植被响应干旱的脆弱性数据,空间分辨率为1/12°。其中,干旱事件通过12月尺度的标准化降水蒸散指数(SPEI12)<-1.0识别。
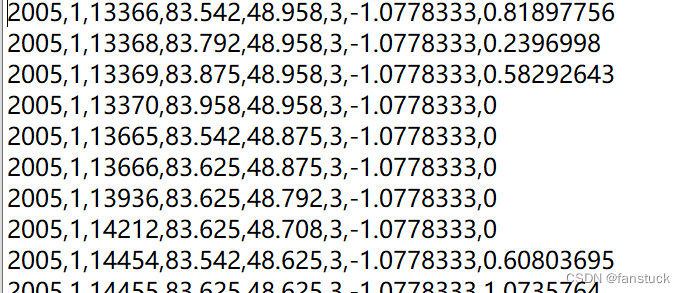
取2015年1月到2016年1月一年内,以月为时间维度,进行相关性分析即可。
二、建模
1.相关性分析
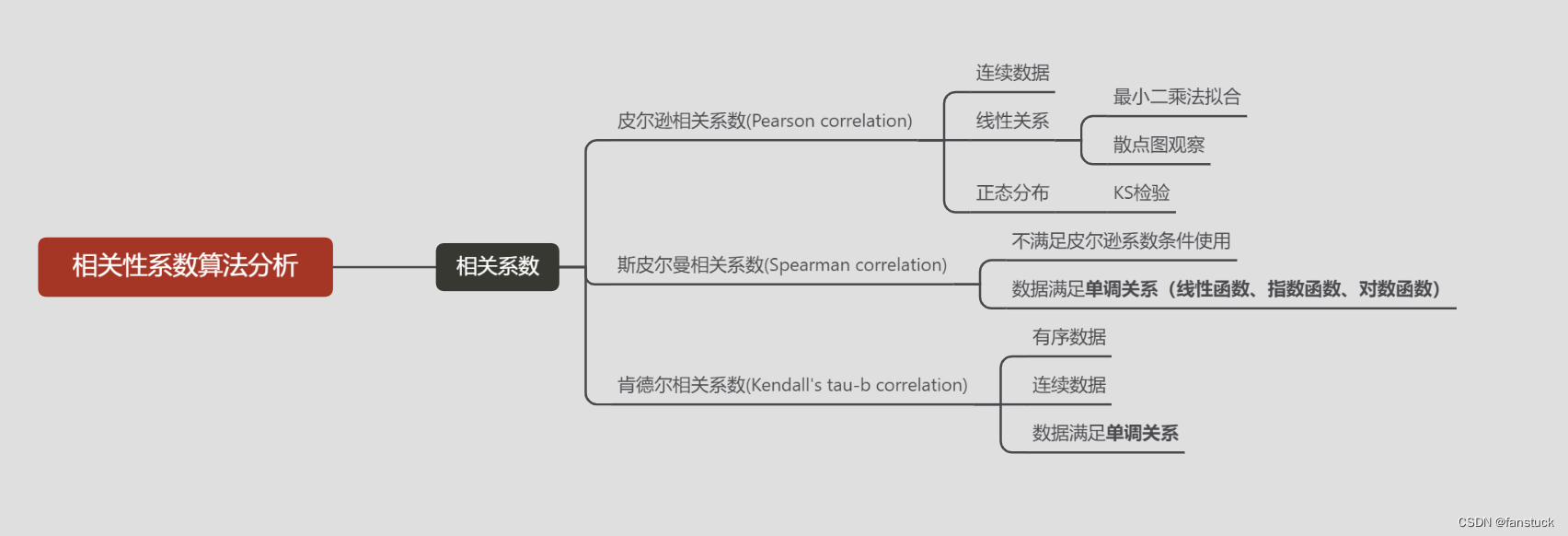
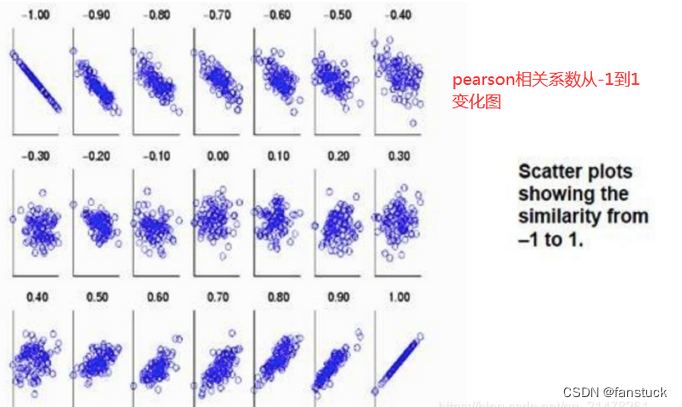
根据数据类型选择不同物种之间相关性系数,这里一定要注意控制变量法:
总结一下对于皮尔逊相关系数的使用场景,有三种必要的特性使用皮尔逊系数最佳:
- 连续数据
- 正态分布
- 线性关系
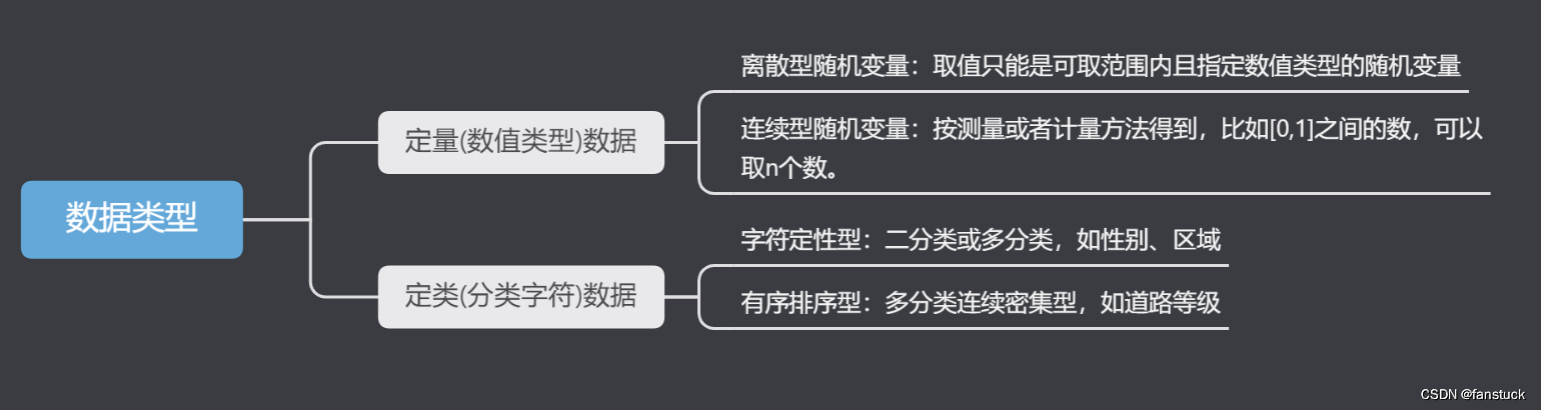
上述三个条件均满足才能使用pearson相关系数,否则就用spearman相关系数。定序数据之间也只用spearman相关系数,不能用pearson相关系数。

只要将数据收集处理完直接套相关性分析即可。
2.相关特征权重
因为题目中有提到污染和栖息地减少等其他因素如何影响你的结论?
那么我们必然要对干旱系数发生变换之后,对空间范围内土壤表层稳渗率、土壤含水率、土壤含盐量和土壤有机质含量的影响。而污染则是对荒漠土壤养分进行影响,主要包含监测指标:有机质、全氮、全磷、全钾、速效氮、有效磷、速效钾、缓效钾、PH值。
| 荒漠植物群落优势植物和凋落物的元素含量与能值 | 荒漠植物群落优势植物和凋落物的元素含量与能值;综合观测场破坏性采样地,每5年采样分析一次;6个重复;根、茎、叶分别测定;测定项目:元素全量含量、热值、灰分。 |

每种土壤微元素的不同含量与同植物物种数量和类型结合,采用熵权法分析即可:
在确定各项评价指标权重的算法中,熵权法在很多评价法作为计算指标权重的一只核心基础算法,如秩和比综合评价法RSR或是优劣解距离法TOPSIS。易于理解的话来讲,熵权法就是看该指标数据是否相对集中或是相对离散,要是基本上都差不多的数据,那么这些数据熵就很小,比较集中。说明在这个指标上面体现不出样本的差异性,导致这个指标并不是那么重要。所以该指标权重就小,相反数据差距很大,权重就大。
熵值法根据信息熵的定义,对于某项指标,可以用熵值来判断某个指标的离散程度,其信息熵值越小,指标的离散程度越大, 该指标对综合评价的影响(即权重)就越大,如果某项指标的值全部相等,则该指标在综合评价中不起作用。因此,可利用信息熵这个工具,计算出各个指标的权重,为多指标综合评价提供依据。
#计算每种指标的信息熵
wi=(1-ej)/np.sum(1-ej)
#计算每种指标的权重首先思路就是这样,大家等我好消息,等我将整个模型以及数据处理好我再发一版全的。