#pragma once
/*35-更灵活定位内存地址04
不同的寻址方式的灵活应用
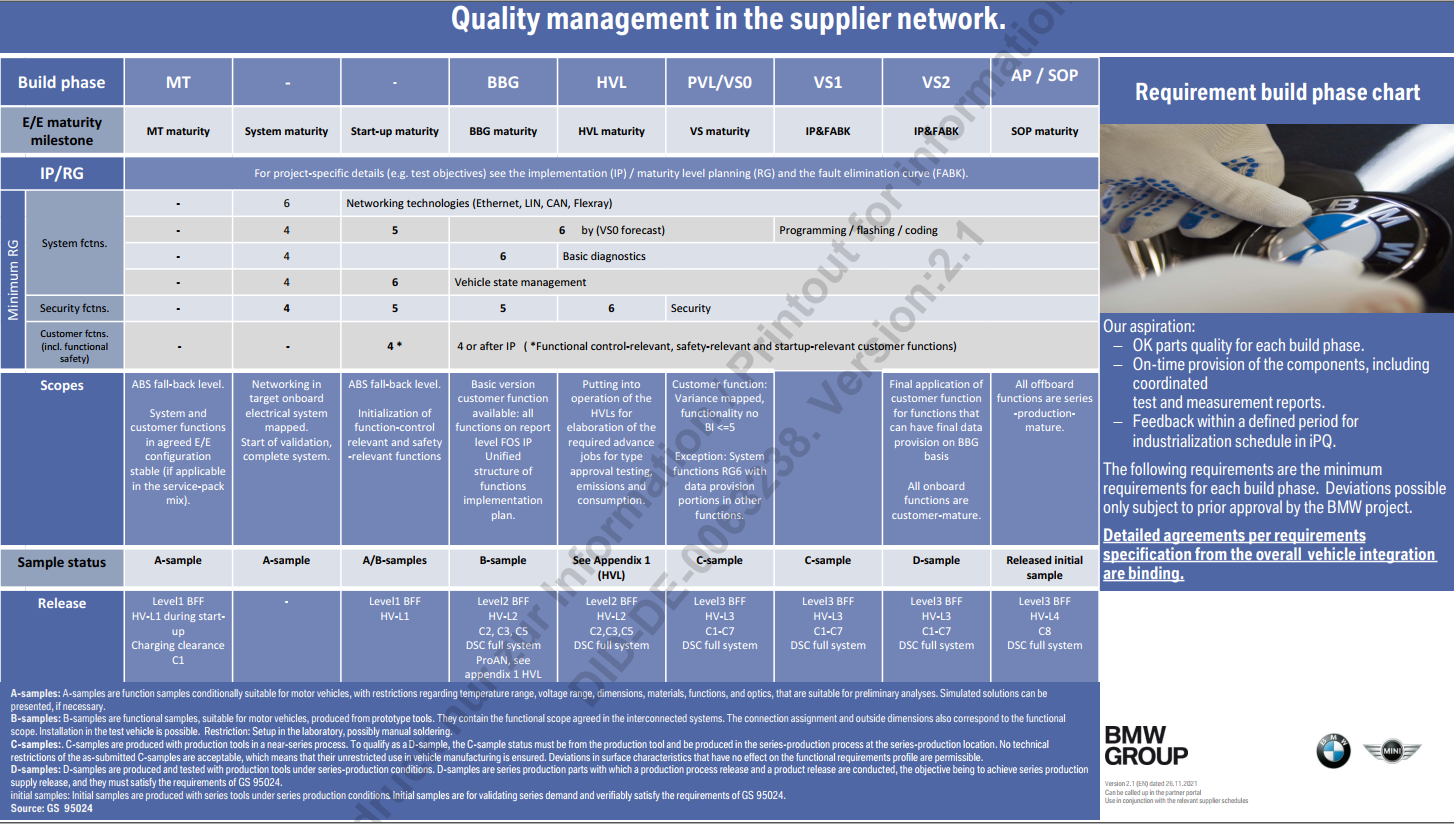
如果我们比较一下前面用到的几种定位内存地址的方法(可称为寻址方式),就可以发现有以下几种方式:
(1)[idata] 用一个常量来表示地址,可用于直接定位一个内存单元; (masm 编译器 需要ds:[idata]这样写)
(2)[bx]用一个变量来表示内存地址,可用于间接定位一个内存单元;
(3)[bx+idata] 用一个变量和常量表示地址,可在一个起始地址的基础上用变量间接定位一个内存单元;
(4)[bx+si]用两个变量表示地址;
(5)[bx+si+idata] 用两个变量和一个常量表示地址。
可以看到:
从[idata]一直到[bx+si+idata],我们可以用更加灵活的方式来定位一个内存单元的地址。
这使我们可以从更加结构化的角度来看待所要处理的数据。
下面我们将通过一系列问题来体会CPU提供多种寻址方式的用意,并学习一些相关的编程技巧。
好了,大家要做好心理准备~
问题
编程,将datasg段中每个单词的头一个字母改为大写字母。
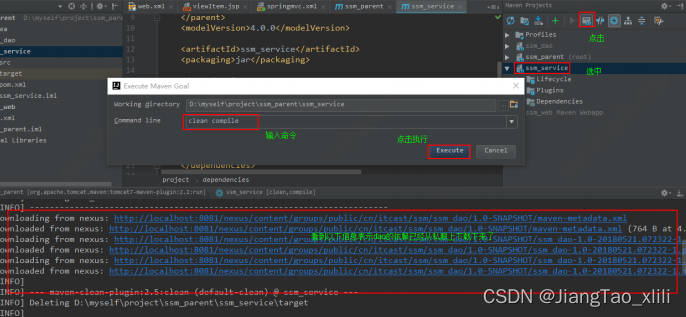
assume cs:codesg,ds:datasg
datasg segment
db '1. file '; 每行16个字节,不够的后面有空格填充.
db '2. edit '
db '3. search '
db '4. view '
db '5. options '
db '6. help '
datasg ends
codesg segment
start:……
codesg ends
end start问题分析
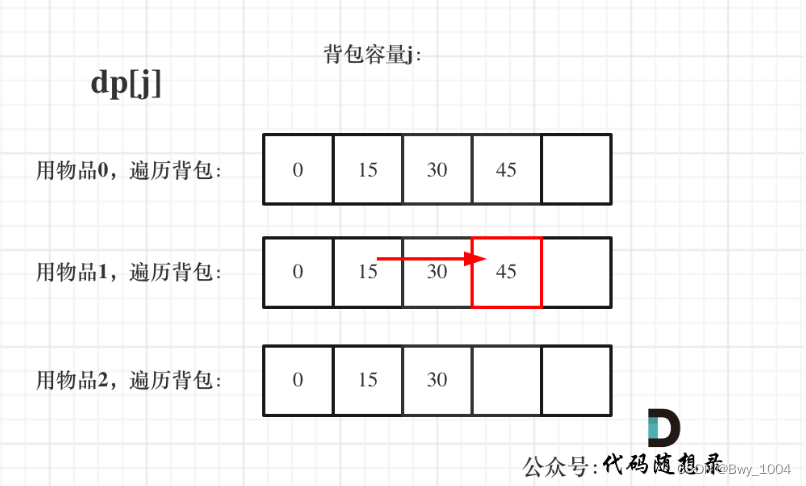
datasg中的数据的存储结构,如图:
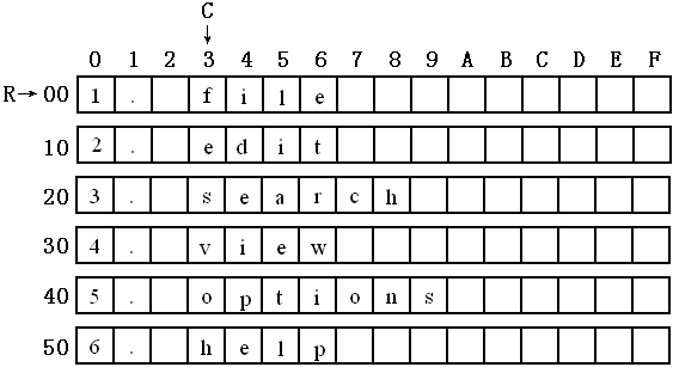
我们可以看到:
在datasg中定义了6个字符串,每个长度为16字节。
(注意,为了直观,每个字符串的后面都加上了空格符,以使它们的长度刚好为16字节)
我们需要进行6次循环,用一个变量R定位行,用常量3 定位列。处理的过程如下:
BX先存放第一行的地址
mov cx,6;因为总共有六行
s: 改变第BX行,第3列的字母为大写
改变BX的值是它指向下一行的地址
loop
我们用bx作变量,定位每行的起始地址,用3定位要修改的列,用[bx+idata]的方式来对目标单元进行寻址,
请看程序具体演示!
问题
编程:
将datasg段中每个单词改为大写字母。
assume cs:codesg,ds:datasg
datasg segment
db 'ibm '
db 'dec '
db 'dos '
db 'vax '
datasg ends
codesg segment
start: ……
codesg ends
end start问题分析
datasg中数据的存储结构,如图
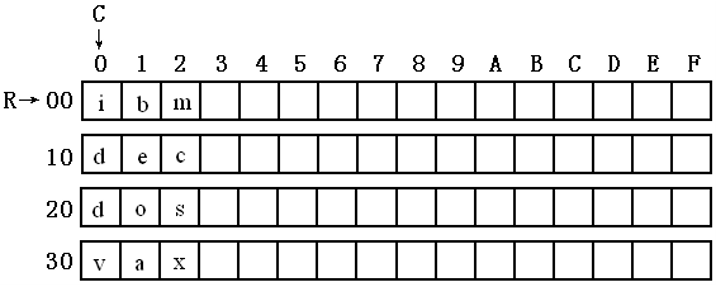
在datasg中定义了4个字符串,每个长度为16字节。
(注意,为了使我们在Debug 中可以直观地查看,每个字符串的后面都加上了空格符,以使它们的长度刚好为16byte)
因为它们是连续存放的,我们可以将这 4 个字符串看成一个 4行16列的二维数组。
按照要求,我们需要修改每一个单词,即二维数组的每一行的前3列。
我们需要进行4x3次的二重循环(循环嵌套),用变量R 定位行,变量C定位列。
外层循环按行来进行;
内层按列来进行。
我们首先用R 定位第1行,然后循环修改R行的前3列;
然后再用R定位到下一行,再次循环修改R行的前3列……,
如此重复直到所有的数据修改完毕。
处理的过程大致如下:
R=第一行的地址;
mov cx,4
s0: C=第一列的地址
mov cx,3
s: 改变R 行,C列的字母为大写
C=下一列的地址;
loop s
R=下一行的地址
loop s0
我们用bx来作变量,定位每行的起始地址,用si 定位要修改的列,用 [bx+si] 的方式来对目标单元进行寻址,
请看程序完整代码!(其实什么行啊列啊的,没啥用,都是比喻,整的反倒更加抽象了让人听不懂了,懂的不用听,不懂的也听不懂,云里雾里的,就是套两层循环,你不套第二层循环也可以 ,无非就是多写点代码)
*/