CasEE: A Joint Learning Framework with Cascade Decoding for Overlapping Event Extraction (用于重叠事件抽取的级联解码联合学习框架)

论文:CasEE: A Joint Learning Framework with Cascade Decoding for Overlapping Event Extraction (aclanthology.org)
代码:JiaweiSheng/CasEE: Source code for ACL 2021 finding paper: CasEE: A Joint Learning Framework with Cascade Decoding for Overlapping Event Extraction (github.com)
期刊/会议:ACL 2021
摘要
事件抽取(Event extraction, EE)是一项重要的信息抽取任务,旨在抽取文本中的事件信息。现有方法大多假设事件出现在句子中没有重叠,这不适用于复杂的重叠事件抽取。本文系统地研究了现实事件重叠问题,即一个词可能作为多种类型的触发词或具有不同作用的论元。为了解决上述问题,我们提出了一种新的联合学习框架,该框架具有级联解码,用于重叠事件抽取,称为CasEE。具体而言,CasEE依次执行类型检测、触发词抽取和论元抽取,其中重叠的目标根据前者的特定预测分别抽取。所有子任务都在一个框架中联合学习,以捕获子任务之间的依赖关系。对公共事件抽取基准FewFC的评估表明,CasEE在重叠事件抽取方面比以前的竞争方法取得了显著改进。
1、简介
事件抽取(EE)是自然语言理解中一个重要而又具有挑战性的任务。给定一个句子,事件抽取系统应该识别句子中出现的事件类型、触发词和论元。作为一个例子,图1(b)展示了一个Share Reduction类型的事件,由“reduced”触发。有几种说法,如“Fuda Industry”在事件中发挥了“subject”作用。
然而,事件经常在句子中复杂地出现,其中触发词和论点可能在句子中有重叠。这个文章聚焦在一个具有挑战性和现实意义的问题:重叠事件抽取。一般来说,我们将所有重叠的情况分为三种模式:1)一个词可以在多个事件中作为不同事件类型的触发词。图1(a)显示了“获得(acquire)”的token同时触发投资(Investment)事件和股份转让(Share Transfer)事件。2)一个词可以作为论元,在多个事件中扮演不同的角色。图1(a)显示,“盛悦网络(Shengyue Network)”在投资事件中扮演客体(object)角色,在股权转让(Share Transfer)事件中扮演主体(subject)角色。3)一个词可以作为论元在一个事件中扮演不同的角色。从图1(b)可以看出,“福达实业(Fuda Industry)”在一个事件中既是主体(subject)角色,又是目标(object)角色。为简单起见,在下文中,我们将模式1)称为重叠触发词问题,将模式2)和模式3)称为重叠论元问题。在中国金融事件抽取数据集中,FewFC (Zhou et al, 2021),约有13.5% / 21.7%的句子存在重叠的触发词/论元问题。

现有的大部分EE研究假设事件出现在句子中没有重叠,这并不适用于复杂的重叠场景。通常,目前的EE研究可以大致分为两个类别:1)传统联合方法(Nguyen等人, 2016;刘等人,2018;Nguyen和Nguyen, 2019),通过统一的解码器同时抽取触发词和论元,并且只标记一次句子。然而,由于标签冲突,它们无法抽取重叠的目标,其中一个token可能有多个类型化标签,但只能分配一个标签。2)管道方法(Chen等人, 2015;Yang等人,2019;Du和Cardie, 2020b),在不同的阶段依次抽取触发词和论元。Yang等人(2019)试图以管道方式解决重叠论元问题,但忽略了重叠触发词问题。然而,管道方法忽略了触发词和论元之间的特征级依赖关系,并受到错误传播的影响。据我们所知,现有的EE研究忽视了重叠问题或只关注一个重叠问题。很少有研究同时解决上述三种重叠模式。
为了解决上述问题,我们提出了CasEE,一种用于重叠事件抽取的Cascade解码联合学习框架。具体来说,CasEE通过一个共享的文本编码器和三个用于类型检测、触发词抽取和论元抽取的解码器来实现事件抽取。为了抽取跨事件的重叠目标,CasEE依次解码三个子任务,根据前者的预测进行触发词抽取和论元抽取。这种级联解码策略根据不同的条件抽取事件元素,使重叠的目标分阶段抽取。条件融合函数用于显式地模拟相邻子任务之间的依赖关系。所有的子任务解码器被联合学习,以进一步建立子任务之间的连接,从而通过下游子任务之间的特征级交互来改进共享文本编码器。
本文的贡献有三个方面:
(1)我们系统地研究了EE中的重叠问题,并将其分为三种模式。据我们所知,这篇论文是第一批同时处理所有三种重叠模式的论文之一。
(2)我们提出了一种新型的带有级联解码的联合学习框架CasEE,以同时解决所有三种重叠模式。
(3)我们在中国公开的金融事件抽取基准——FewFC上进行了实验。实验结果表明,与现有的竞争方法相比,CasEE在重叠事件抽取方面取得了显著的改进。
2、相关工作
目前的EE研究大致可以分为两类:1)传统的联合方法(Li等人, 2013;Nguyen等人,2016;Nguyen and Nguyen, 2019;刘等人,2018;Sha等人,2018),同时执行触发词抽取和论元抽取。它们以序列标记的方式解决任务,并通过只标记一次句子来抽取触发词和论元。但是,这些方法无法解决重叠事件抽取问题,因为当强制使用多个标签时,重叠的标记将导致标签冲突。2)管道方法(Chen等人, 2015;杨等人,2019;Wadden等人,2019;Li等人,2020;Du和Cardie, 2020b;刘等人,2020;Chen等人,2020),在不同的阶段执行触发词抽取和论元抽取。尽管管道方法具有解决重叠EE的潜在能力,但它们通常缺乏触发词和论元之间的显式依赖关系,并且受到错误传播的影响。其中Yang等人(2019)和Xu等人(2020)解决了论元重叠问题,但忽略了触发词重叠问题,从而无法识别正确的触发词进行论元抽取。以上方法都不能同时解决事件抽取中的所有重叠模式。
在事件抽取以外的其他信息抽取任务中,也探讨了重叠问题。Luo和Zhao(2020)利用二部平面网络解决了嵌套的命名实体识别问题。Zeng等人(2018)通过应用带有复制机制的序列到序列范式解决了重叠关系三元组抽取。Wei等人(2020)和Yu等人(2020)用一种新的级联标记策略抽取重叠的关系三元组,这启发我们在级联解码范式中解决重叠事件抽取。Wang等人(2020)进一步讨论了级联解码中的传播误差。以上研究都是针对其他任务提出的,由于事件抽取定义复杂,不能直接转移到重叠事件抽取中。
3、我们的方法
给定一个输入句子,EE的目标是识别触发词及其事件类型和论元及其对应的角色,在某些标记上,触发词和论元可能重叠。为了解决这个问题,我们在事件级别上提出了一个训练目标。形式上,根据预定义的事件模式,我们有一个事件类型集
C
C
C和一个论元角色集
R
R
R。总体目标是预测句子
x
x
x的标注级(gold set)
ε
x
\varepsilon_x
εx中的所有事件。我们的目标是使训练数据
D
D
D的联合似然最大化:
∏
x
∈
D
[
∏
(
x
,
t
,
a
r
)
∈
ε
x
p
(
(
c
,
t
,
a
r
)
∣
x
)
]
=
∏
x
∈
D
[
∏
c
∈
C
x
p
(
c
∣
x
)
∏
t
∈
T
x
,
c
p
(
t
∣
x
,
c
)
∏
a
r
∈
A
x
,
c
,
t
p
(
a
r
∣
x
,
c
,
t
)
]
\prod_{x \in D} \left[ \prod_{(x,t,a_r) \in \varepsilon_x} p((c,t,a_r)|x) \right ]=\prod_{x \in D} \left[ \prod_{c \in C_x} p(c|x) \prod_{t \in T_{x,c}} p(t|x,c) \prod_{a_r \in A_{x,c,t}} p(a_r|x,c,t) \right]
x∈D∏
(x,t,ar)∈εx∏p((c,t,ar)∣x)
=x∈D∏
c∈Cx∏p(c∣x)t∈Tx,c∏p(t∣x,c)ar∈Ax,c,t∏p(ar∣x,c,t)
其中
C
x
C_x
Cx表示在
x
x
x中出现的类型集,
T
x
,
c
T_{x,c}
Tx,c表示类型
c
c
c的触发词集,
A
x
,
c
,
t
A_{x,c,t}
Ax,c,t表示类型
c
c
c和触发词
t
t
t的论元集。注意,每个
c
c
c是
C
C
C中的一个类型,每个
t
t
t是一个触发词,每个
a
r
∈
A
x
a_r \in A_x
ar∈Ax是一个论元词,对应于它自己的角色
r
∈
R
r \in R
r∈R。Eq.(1)利用了类型、触发词和论元之间的依赖关系。实际上,它促使我们学习类型检测解码器
p
(
c
∣
x
)
p(c|x)
p(c∣x)来检测句子中发生的事件类型,触发词抽取解码器
p
(
t
∣
x
,
c
)
p(t|x, c)
p(t∣x,c)来抽取类型
c
c
c的触发词,论元抽取解码器
p
(
a
r
∣
x
,
c
,
t
)
p(a_r|x, c, t)
p(ar∣x,c,t)来抽取类型
c
c
c的特定角色论元和触发词
t
t
t。
这样的任务分解解决了Introduction(简介)中声称的所有事件重叠模式。具体来说,我们首先检测句子中发生的事件类型。在抽取触发词时,我们只预测具有特定类型的触发词,因此在多个事件中重叠的触发词将在不同阶段进行预测。类似地,在抽取论元时,我们预测具有特定类型和触发词的论元,因此在几个事件中重叠的论元也将在单独的阶段中预测。由于我们在论元抽取中采用了特定于角色的标记器,因此可以使用特定的标记器分别预测在一个事件中具有多个角色的重叠论元。类型检测、触发词抽取和论元抽取中的所有预测都形成最终的预测。

图2展示了CasEE的细节。CasEE采用一个共享的BERT编码器来捕获文本特征,三个解码器用于类型检测、触发词抽取和论元抽取。由于与之前的管道方法相比,所有子任务都是联合学习的(Yang等人,2019;Li等人,2020),CasEE可以捕获子任务之间的特征级依赖关系。对于预测,CasEE在级联解码过程中按顺序预测事件类型、触发词和论元。
3.1 BERT编码器
为了捕获子任务之间的特征级依赖关系,我们共享每个句子的文本表示。由于BERT已在多个NLP任务中显示出性能改进,我们采用BERT (Devlin et al, 2019)作为我们的文本编码器。BERT是一种基于Transformer架构的双向语言表示模型(Vaswani 167 et al, 2017),它根据token上下文生成文本表示,并保留丰富的文本信息。形式上,有 N N N个token的句子表示为 x = w 1 , w 2 , … , w N x = w_1, w_2,\ldots,w_N x=w1,w2,…,wN。我们将token输入BERT,然后得到隐藏状态 H = h 1 , h 2 , … , h N H = h_1, h_2,\ldots, h_N H=h1,h2,…,hN作为下列下游子任务的token表示。
3.2 类型检测解码器
由于我们通过基于类型预测抽取触发词来解决重叠触发词问题,因此我们设计了一种类型检测解码器来预测事件类型。受无触发词事件检测的启发(Liu等人,2019),我们采用注意力机制来检测事件类型,为每种可能的类型捕获最相关的上下文。具体来说,我们随机初始化嵌入矩阵
C
∈
R
∣
C
∣
×
d
C\in \mathbb{R}^{|C|×d}
C∈R∣C∣×d作为类型嵌入。我们定义了一个相似函数
δ
δ
δ来度量候选类型
c
∈
C
c∈C
c∈C和每个token表示
h
i
h_i
hi之间的相关性。为了充分捕捉不同方面的相似度信息,我们用一个表达性的可学习函数实现了
δ
δ
δ。根据相关性得分,我们得到了自适应于该类型的句子表示
s
c
s_c
sc。具体情况如下:
δ
(
c
,
h
i
)
=
v
τ
tanh
(
W
[
c
;
h
i
;
∣
c
−
h
i
∣
;
c
⊙
h
i
]
)
,
s
c
=
∑
i
=
1
N
exp
(
δ
(
c
,
h
i
)
)
∑
j
=
1
N
exp
(
δ
(
c
,
h
j
)
)
h
i
\delta(c,h_i)=v^\tau \tanh (W[c;h_i;|c-h_i|;c \odot h_i]),\\ s_c=\sum_{i=1}^{N} \frac{\exp(\delta(c,h_i))}{\sum_{j=1}^N \exp (\delta(c,h_j))} h_i
δ(c,hi)=vτtanh(W[c;hi;∣c−hi∣;c⊙hi]),sc=i=1∑N∑j=1Nexp(δ(c,hj))exp(δ(c,hi))hi
其中
W
∈
R
4
d
×
4
d
W∈\mathbb{R}^{4d×4d}
W∈R4d×4d,
v
∈
R
4
d
×
1
v \in \mathbb{R}^{4d×1}
v∈R4d×1为可学习参数,
∣
⋅
∣
|·|
∣⋅∣为绝对值算子,
⊙
\odot
⊙是逐元素生成,而
[
⋅
;
⋅
]
[·;·]
[⋅;⋅]表示表示的连接。
最后,我们通过测量自适应句子表示
s
c
s_c
sc和类型嵌入
c
c
c的相似度来预测事件类型,相似度函数
δ
δ
δ相同。那么句子中各事件类型
c
c
c发生的预测概率为:
c
^
=
p
(
c
∣
x
)
=
σ
(
δ
(
c
,
s
c
)
)
\hat c =p(c|x)=\sigma(\delta(c,s_c))
c^=p(c∣x)=σ(δ(c,sc))
σ
\sigma
σ表示sigmoid函数。我们选择了具有
c
^
>
ξ
1
\hat c > \xi_1
c^>ξ1的事件类型作为结果,其中
ξ
1
∈
[
0
,
1
]
\xi_1 \in [0,1]
ξ1∈[0,1]是一个标量阈值。句子
x
x
x中的所有预测类型形成事件类型集
C
x
C_x
Cx。解码器可学习参数
θ
t
d
≜
{
W
,
v
,
C
}
\theta_{t d} \triangleq\{\mathbf{W}, \mathbf{v}, \mathbf{C}\}
θtd≜{W,v,C}。
3.3 触发词抽取解码器
为了识别具有多种类型的重叠触发词,我们抽取以特定类型 c ∈ C x c \in C_x c∈Cx为条件的触发词。该解码器包含一个条件融合函数、一个自注意层和一对用于触发词的二分类标记。
为了模拟类型检测和触发词抽取之间的条件依赖关系,我们设计了一个条件融合函数
ϕ
\phi
ϕ,将条件信息集成到文本表示中。具体来说,我们通过将类型嵌入
c
c
c集成到token表示
h
i
h_i
hi中来获得条件token表示
g
i
c
g^c_i
gic,如下:
g
i
c
=
ϕ
(
c
,
h
i
)
g_i^c=\phi(c,h_i)
gic=ϕ(c,hi)
实际上,
ϕ
\phi
ϕ可以通过级联、加法算子或门机制来实现。为了在统计方面完全生成条件表示,我们引入了一种有效且通用的机制,条件层归一化(CLN) (Su, 2019;Yu et al, 2021),得到
ϕ
\phi
ϕ。CLN大多基于众所周知的层归一化(Ba et al, 2016),但可以根据条件信息动态生成增益
γ
γ
γ和偏置
β
β
β。给定一个条件嵌入
c
c
c和一个标记表示
h
i
h_i
hi, CLN被表述为:
CLN
(
c
,
h
i
)
=
γ
c
⊙
(
h
i
−
μ
σ
)
+
β
c
,
γ
c
=
W
y
c
+
b
γ
,
β
c
=
W
β
c
+
b
β
\text{CLN}(c,h_i)=\gamma_c \odot (\frac{h_i - \mu}{\sigma})+\beta_c ,\\ \gamma_c=\mathbf{W}_y \mathbf{c} + \mathbf{b}_\gamma,\\ \beta_c=\mathbf{W}_\beta \mathbf{c} + \mathbf{b}_\beta
CLN(c,hi)=γc⊙(σhi−μ)+βc,γc=Wyc+bγ,βc=Wβc+bβ
其中,
μ
∈
R
\mu \in \mathbb{R}
μ∈R和
σ
∈
R
σ\in \mathbb{R}
σ∈R是
h
i
h_i
hi元素的平均值和标准方差,
γ
c
∈
R
d
γ_c \in \mathbb{R}^d
γc∈Rd和
β
c
∈
R
d
β_c \in \mathbb{R}^d
βc∈Rd分别是条件增益和偏差。通过这种方式,给定的条件表示被编码到增益和偏差中,然后集成到上下文表示中。
为了进一步细化触发词抽取的表示,我们在条件token表示上采用了自注意层。形式上,细化的token表示派生为:
Z
c
=
Self-Attention
(
G
c
)
\mathbf{Z}^c=\text{Self-Attention}(\mathbf{G}^c)
Zc=Self-Attention(Gc)
其中
G
c
\mathbf{G}^c
Gc是由
g
i
c
g^c_i
gic组成的表示矩阵。关于自我注意层的详细信息,请参见Vaswani et al(2017)。
为了预测触发词,我们设计了一对二分类标记器。对于每个token
w
i
w_i
wi,我们预测它是否对应于触发词的开始或结束位置,如下:
t
^
i
s
c
=
p
(
t
s
∣
w
i
,
c
)
=
σ
(
w
t
s
τ
z
i
c
+
b
t
s
)
,
t
^
i
e
c
=
p
(
t
e
∣
w
i
,
c
)
=
σ
(
w
t
e
τ
z
i
c
+
b
t
e
)
\hat t_i^{sc}=p(t_s|w_i,c)=\sigma(\mathbf{w}_{ts}^{\tau} \mathbf{z}_i^c +b_{t_s}),\\ \hat t_i^{ec}=p(t_e|w_i,c)=\sigma(\mathbf{w}_{t_e}^{\tau} \mathbf{z}_i^c +b_{t_e})
t^isc=p(ts∣wi,c)=σ(wtsτzic+bts),t^iec=p(te∣wi,c)=σ(wteτzic+bte)
其中
σ
σ
σ表示sigmoid函数,
z
i
c
z^c_i
zic表示
Z
c
\mathbf{Z}^c
Zc中的第
i
i
i个token表示。我们选择了以
t
^
i
s
c
>
ξ
2
\hat t_i^{sc} > \xi_2
t^isc>ξ2为起始位置的token,以
t
^
i
e
c
>
ξ
3
\hat t_i^{ec} > \xi_3
t^iec>ξ3为结束位置的token,其中
ξ
2
,
ξ
3
∈
[
0
,
1
]
ξ_2, ξ_3∈[0,1]
ξ2,ξ3∈[0,1]为标量阈值。为了获得触发词
t
t
t,我们枚举所有的开始位置,并搜索句子中最近的结束位置,开始位置和结束位置之间的token形成一个完整的触发词。这样就可以在不同阶段根据类型分别抽取重叠的触发词。句子
s
s
s中
c
c
c类型的所有预测触发词
t
t
t形成集合
τ
c
,
s
\tau_{c,s}
τc,s。解码器参数
θ
t
e
θ_{te}
θte包括条件融合函数、自注意层和触发词标记器中的所有参数。
3.4 论元抽取解码器
为了解决重叠论元问题,我们抽取了以特定事件类型 c ∈ C s c∈C_s c∈Cs和事件触发词 t ∈ T c , s t∈T_{c,s} t∈Tc,s为条件的特定于角色的论元。该解码器还包含一个条件融合函数、一个自注意层和一组用于论元的特定于角色的二分类标记符对。
我们进一步将触发词信息集成到Eq.(4)中的类型化文本表示
g
i
c
g^c_i
gic中,并通过CLN实现函数
ϕ
\phi
ϕ。这里我们取
t
t
t的起始位置和结束位置标token表示的平均值作为触发词嵌入。我们还采用了自注意层来派生出改进的文本表示
Z
c
t
′
Z^{ct'}
Zct′。为了了解触发词位置,我们采用Chen等人(2015)中使用的相对位置嵌入,它表示当前token到触发词边界token的相对距离。最后,导出用于论元抽取的token表示
Z
c
t
Z^{ct}
Zct为:
Z
c
t
=
[
Z
c
t
′
;
P
]
\mathbf{Z}^{ct}=[\mathbf{Z}^{ct'};\mathbf{P}]
Zct=[Zct′;P]
式中
P
∈
R
N
×
d
p
P∈\mathbb{R}^{N×d_p}
P∈RN×dp为相对位置嵌入,
d
p
d_p
dp为维数,
[
⋅
;
⋅
]
[·;·]
[⋅;⋅]表示表示的连接。
为了预测角色中的论元,我们设计了一组特定于角色的标记符对。对于每个token
w
i
w_i
wi,我们预测它是否对应于角色
r
∈
R
r\in R
r∈R的一个论元的开始位置或结束位置,如下:
r
^
i
s
c
t
=
p
(
a
r
s
∣
w
i
,
c
,
t
)
=
I
(
r
,
c
)
σ
(
w
r
s
τ
z
i
c
t
+
b
r
s
)
,
r
^
i
e
c
t
=
p
(
a
r
e
∣
w
i
,
c
,
t
)
=
I
(
r
,
e
)
σ
(
w
r
s
τ
z
i
c
t
+
b
r
e
)
\hat r_i^{sct}=p(a_r^s|w_i,c,t)=\mathbf{I}(r,c) \sigma(\mathbf{w}_{r_s}^\tau \mathbf{z}_i^{ct}+b_{r_s}),\\ \hat r_i^{ect}=p(a_r^e|w_i,c,t)=\mathbf{I}(r,e) \sigma(\mathbf{w}_{r_s}^\tau \mathbf{z}_i^{ct}+b_{r_e})
r^isct=p(ars∣wi,c,t)=I(r,c)σ(wrsτzict+brs),r^iect=p(are∣wi,c,t)=I(r,e)σ(wrsτzict+bre)
其中
σ
σ
σ表示sigmoid函数,
z
i
c
t
\mathbf{z}^{ct}_i
zict表示
Z
c
t
\mathbf{Z}^{ct}
Zct中的第
i
i
i个token表示。由于并非所有角色都属于特定类型
c
c
c,因此我们采用指标函数
I
(
r
,
c
)
\mathbf{I}(r, c)
I(r,c)根据预定义的事件方案来指示角色
r
r
r是否属于类型
c
c
c。为了使指标函数可导,我们将
I
(
r
,
c
)
\mathbf{I}(r, c)
I(r,c)参数化以学习模型参数。具体来说,给定类型嵌入
c
∈
C
c∈C
c∈C,我们将类型和角色之间的连接构建为:
I
(
r
,
c
)
=
σ
(
w
r
τ
c
+
b
r
)
\mathbf{I}(r,c)=\sigma(\mathbf{w}_r^\tau \mathbf{c} + b_r)
I(r,c)=σ(wrτc+br)
其中
σ
σ
σ表示sigmoid函数,
w
r
\mathbf{w}_r
wr,
b
r
b_r
br是与角色
r
r
r相关的参数。对于每个角色
r
r
r,我们选择以
r
^
i
s
c
t
>
ξ
4
\hat r^{sct}_i > ξ_4
r^isct>ξ4 为开始位置的token,以
r
^
i
e
c
t
>
ξ
5
\hat r^{ect}_i > ξ_5
r^iect>ξ5为结束位置的token,其中
ξ
4
,
ξ
5
∈
[
0
,
1
]
ξ_4, ξ_5∈[0,1]
ξ4,ξ5∈[0,1]为标量阈值。为了获得角色为
r
r
r的论元词
a
a
a,我们枚举所有的开始位置,并搜索句子中最近的结束位置,开始位置和结束位置之间的标记形成一个完整的论元。通过这种方式,可以使用特定于角色的标记器根据不同类型和触发词分别抽取重叠的论元。句子
x
x
x中所有类型
c
c
c的预测论元
a
r
a_r
ar和触发词
t
t
t形成集合
A
t
,
c
,
x
\mathcal{A}_{t,c,x}
At,c,x。解码器参数
θ
a
e
θ_{ae}
θae包括类型嵌入矩阵
C
C
C,以及条件融合函数、自注意层和论元标记器中的所有参数。
3.5 模型建模
为了训练模型,我们对Eq(1)取对数,总体目标
J
(
Θ
)
\mathcal{J}(\Theta)
J(Θ)部署为:
∑
x
∈
D
[
∑
c
∈
C
x
l
o
g
p
θ
1
(
c
∣
x
)
+
∑
t
∈
T
x
,
c
l
o
g
p
θ
2
(
t
∣
x
,
c
)
+
∑
a
r
∈
A
x
,
c
,
t
l
o
g
p
θ
3
(
a
r
∣
x
,
c
,
t
)
]
\sum_{x \in \mathcal{D}} \left[ \sum_{c \in \mathcal{C}_x} log\ p_{\theta_1}(c|x) + \sum_{t \in \mathcal{T}_{x,c}} log\ p_{\theta_2}(t|x,c) + \sum_{a_r \in \mathcal{A}_{x,c,t} } log \ p_{\theta_3}(a_r|x,c,t) \right]
x∈D∑
c∈Cx∑log pθ1(c∣x)+t∈Tx,c∑log pθ2(t∣x,c)+ar∈Ax,c,t∑log pθ3(ar∣x,c,t)
Θ
≜
{
θ
1
,
θ
2
,
θ
3
}
,
p
θ
1
(
c
∣
x
)
,
p
θ
2
(
t
∣
x
,
c
)
,
p
θ
3
(
a
r
∣
x
,
c
,
t
)
\Theta \triangleq \{ \theta_1,\theta_2,\theta_3 \},p_{\theta_1}(c|x),p_{\theta_2}(t|x,c),p_{\theta_3}(a_r|x,c,t)
Θ≜{θ1,θ2,θ3},pθ1(c∣x),pθ2(t∣x,c),pθ3(ar∣x,c,t)在子任务中被定义:
p
θ
1
(
c
∣
x
)
=
(
c
^
)
c
‾
(
1
−
c
^
)
1
−
c
‾
,
p
θ
2
(
t
∣
x
,
c
)
=
∏
z
∈
{
s
,
e
}
∏
i
=
1
N
(
t
^
i
z
c
)
t
‾
i
z
c
(
1
−
t
^
i
z
c
)
(
1
−
t
‾
i
z
c
)
,
p
θ
3
(
a
r
∣
x
,
c
,
t
)
=
∏
r
∈
R
∏
z
∈
{
s
,
e
}
∏
i
=
1
N
(
r
^
i
z
c
t
)
r
‾
i
z
c
t
(
1
−
r
^
i
z
c
t
)
(
1
−
r
‾
i
z
c
t
)
p_{\theta_1}(c|x)=(\hat c)^{\overline c}(1-\hat c)^{1-\overline c},\\ p_{\theta_2}(t|x,c)=\prod_{z\in \{ s,e\}} \prod_{i=1}^N (\hat t_i^{zc})^{\overline t_i^{zc}}(1-\hat t_i^{zc})^{(1-\overline t_i^{zc})},\\ p_{\theta_3}(a_r|x,c,t)=\prod_{r \in \mathcal{R}}\prod_{z\in \{ s,e\}} \prod_{i=1}^N (\hat r_i^{zct})^{\overline r_i^{zct}}(1-\hat r_i^{zct})^{(1-\overline r_i^{zct})}
pθ1(c∣x)=(c^)c(1−c^)1−c,pθ2(t∣x,c)=z∈{s,e}∏i=1∏N(t^izc)tizc(1−t^izc)(1−tizc),pθ3(ar∣x,c,t)=r∈R∏z∈{s,e}∏i=1∏N(r^izct)rizct(1−r^izct)(1−rizct)
其中:
c
^
\hat c
c^、
t
^
i
s
c
\hat t^{sc}_i
t^isc、
t
^
i
e
c
\hat t^{ec}_i
t^iec、
r
^
i
s
c
t
\hat r^{sct}_i
r^isct、
r
^
i
e
c
t
\hat r^{ect}_i
r^iect分别是Eq(3)、Eq(7)、Eq(9)中的预测概率,
c
‾
\overline c
c、
t
‾
i
s
c
\overline t^{sc}_i
tisc、
t
‾
i
e
c
\overline t^{ec}_i
tiec、
r
‾
i
s
c
t
\overline r^{sct}_i
risct、
r
‾
i
e
c
t
\overline r^{ect}_i
riect分别是训练数据的真实0/1标签。
θ
1
≜
{
θ
b
e
r
t
,
θ
t
d
}
\theta_1 \triangleq \{ \theta_{bert},\theta_{td} \}
θ1≜{θbert,θtd},
θ
2
≜
{
θ
b
e
r
t
,
θ
t
e
}
\theta_2 \triangleq \{ \theta_{bert},\theta_{te} \}
θ2≜{θbert,θte},
θ
3
≜
{
θ
b
e
r
t
,
θ
a
e
}
\theta_3 \triangleq \{ \theta_{bert},\theta_{ae} \}
θ3≜{θbert,θae},其中
θ
b
e
r
t
θ_{bert}
θbert,
θ
t
d
θ_{td}
θtd,
θ
t
e
θ_{te}
θte,
θ
a
e
θ_{ae}
θae分别表示BERT中的参数,类型检测,触发词抽取和论元抽取。我们通过在随机打乱的小批量上通过Adam随机梯度下降(Kingma和Ba, 2015)最大化
J
(
Θ
)
\mathcal{J}(Θ)
J(Θ)来训练模型。
4、实验
4.1 数据集和评估指标
我们在中国金融事件抽取基准FewFC上进行了实验2(Zhou et al, 2021)。我们以8:1:1的比例分割数据用于训练/验证/测试。表1显示了更多细节。

对于评估,我们遵循传统的评估指标(Chen et al, 2015;Du和Cardie, 2020b): 1)触发词识别(TI):如果预测的触发词跨度与标准正确跨度匹配,则正确识别触发词;2)触发词分类(TC):如果一个触发词被正确地识别并分配到正确的类型,那么它就被正确地分类;3)论元识别(AI):如果论元的事件类型被正确识别,并且预测的论元跨度与标准正确跨度匹配,则正确识别论元;4)论元分类(Argument Classification, AC):论元被正确识别,预测角色与标准正确角色匹配,则论元被正确分类。我们报告了精度§、召回率®和F measure(F1)。
4.2 对比其他方法
尽管近年来研究了各种EE模型,但针对重叠事件抽取的研究却很少。我们试图根据当前的解决方案制定以下基线。出于现实的考虑,之前没有已知的EE候选实体。
联合序列标注方法:这种方法将事件抽取转化为序列标记任务。BERT-softmax (Devlin et al, 2019) 虽然ACE 2005数据集通常用于评估传统的情感表达模型,但我们观察到它包含了低比例的重叠论点问题(Yang et al(2019)报告了近10%),并且不存在重叠触发词问题的句子。采用BERT学习文本表示,使用隐藏状态对事件触发词和论元进行分类。BERT-CRF采用条件随机场(CRF)来捕获标签依赖关系,在(Du and Cardie, 2020a)中用于文档级事件抽取。BERT-CRF-joint借鉴了实体和关系的联合抽取思想(Zheng et al, 2017),采用类型和角色的联合标签为B/I/O类型-角色。以上方法都不能解决标签冲突造成的重叠问题。
流水线事件抽取方法:这种方法用管道方式解决事件抽取。PLMEE (Yang et al, 2019)通过根据触发词抽取特定于角色的论元来解决重叠论元问题。受当前基于机器阅读理解(MRC)的EE研究的激励(Li等人,2020;Du和Cardie, 2020b;刘等,2020;Chen等人,2020),我们训练多个MRC bert用于重叠事件抽取。我们扩展了MQAEE (Li et al, 2020),用于多跨度抽取,并重新组装以下方法3,以考虑EE中的条件:1)方法首先预测类型,然后根据类型预测重叠的触发词/论元,称为MQAEE-1。2)该方法首先用类型预测重叠的触发词,然后根据类型化的触发词预测重叠的论元,称为MQAEE-2。3)该方法按顺序预测类型,根据类型预测重叠的触发词,根据类型和触发词预测重叠的论元,称为MQAEE-3。上述管道方法均可解决(或部分解决)重叠事件抽取问题。
4.3 实施细节
我们采用源代码的PLMEE,其最佳超参数报告在原始文献中。为了实现其他基线,我们基于变形金刚库实现代码(Wolf et al, 2020)。所有方法均采用中文BERT-Base模型4作为文本编码器,该模型有12层,768个隐藏单元和12个注意头。我们对这些方法中常见的超参数使用相同的值,包括优化器、学习率、批处理大小和训练轮次。对于所有超参数,我们采用网格搜索策略。我们用Adam权值衰减优化器训练所有的方法。对于BERT参数,初始学习率调整为[1e−5,5e−5],对于其他参数,初始学习率调整为[1e−4,3e−4]。学习率的热身比例为10%,最大训练epoch设置为20。批大小设置为8。对于CasEE,相对位置嵌入的维度 d p d_p dp被调整为{16,32,64}。为了避免过拟合,我们将dropout应用于BERT隐藏状态,并将速率调为[0,1]。并将用于预测的 ξ 1 ξ_1 ξ1, ξ 2 ξ_2 ξ2, ξ 3 ξ_3 ξ3, ξ 4 ξ_4 ξ4, ξ 5 ξ_5 ξ5的阈值调优为[0,1]。我们选择最好的模型,从而在验证数据上获得最高的性能。最佳超参数设置是通过网格搜索来调优的,在附录A中列出。
4.4 主要的结果

所有方法在FewFC数据集上的性能如表2所示。从表中可以看出:
(1)与联合序列标记方法相比,CasEE在F1分数上表现更好。CasEE在AC F1评分上分别比BERT-CRF提高4.5%和BERT-CRF-joint提高4.3%。此外,由于序列标记方法存在标签冲突,对于多标签token只能预测一个标签,CasEE在评价指标的召回率上有较高的结果。结果证明了CasEE在重叠事件抽取方面的有效性。
(2)与管道方法相比,我们的方法在F1分数上也优于管道方法。结果表明,与PLMEE相比,CasEE在TC和AC的F1评分上分别提高了3.1%和2.6%,说明解决EE重叠触发词问题的重要性。尽管基于MRC的基线可以抽取重叠的触发词和论元,但CasEE仍然取得更好的效果。具体来说,CasEE相对强基线MQAEE-2提高了4.1%。原因可能是CasEE共同学习子任务的文本表示,在子任务之间构建有用的交互和连接。结果表明,CasEE优于上述管线基线。
4.5 重叠/正常数据分析
为了进一步理解在测试中的表现,我们将原始测试数据分为两组:有重叠元素的句子和没有重叠元素的句子。
重叠句的表现。如表3所示,对于重叠句,我们的方法明显优于之前的方法。与序列标记方法相比,我们的方法避免了标签冲突,并且与管道方法相比,在子任务之间构建了更有效的特征级连接,这可能是改进的原因。

一般句子的表现。如表4所示,我们的方法在没有重叠事件元素的正常句子上仍然表现出可以接受的结果。序列标记方法在触发词抽取上的结果相似,但在论元抽取上的结果相对更好,其中它们避免了级联解码的潜在传播错误。此外,PLMEE在触发词抽取上的结果相似,但在论元抽取上的结果相对更好,这可能是因为它在原始文献中对不同的参数角色采用了详细的重加权损失。此外,MQAEE-2预测更准确的触发词,因为它与类型联合预测触发词,但不幸的是,它忽略了子任务之间的特征级连接,使得论元抽取结果与CasEE类似。即便如此,与基准相比,vanilla CasEE在正常句子上的表现仍然可以接受。我们将在未来的工作中进一步解决潜在的传播误差,并提高一般事件抽取的性能。

4.6 讨论和模型变体
检测模块变体。表5显示了类型检测变量的性能。具体来说,MaxP/MeanP通过在BERT隐藏状态上应用max/mean池化来聚合文本表示;CLS利用特殊标记的隐藏状态作为句子表示。结果表明,我们的方法在F1分数上优于上述所有变体,这表明学习自适应事件类型的句子表示可以产生更好的类型检测表示。

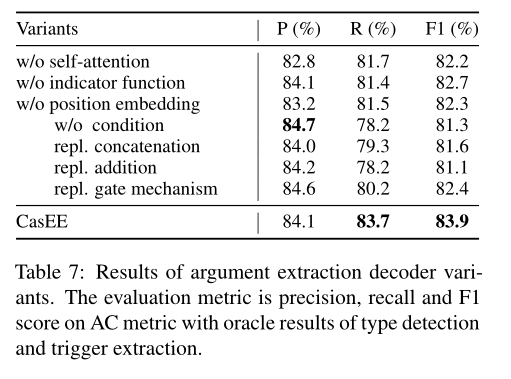
抽取模块变量。表6和表7分别显示了用于触发词抽取和论元抽取的解码器变体的性能。我们去掉了两种抽取解码词中的自注意层,去掉了论元抽取解码器中的相对位置嵌入和指示函数。实验结果验证了各模块的有效性。
此外,我们还进行了实验来探索条件融合函数 ϕ \phi ϕ的影响。实验包括:1)简单地去除条件积分函数;2)我们通过连接条件和token表示来实现 ϕ \phi ϕ;3)我们通过简单地将条件嵌入到token表示中来实现φ;4)通过gate机制实现 ϕ \phi ϕ,该机制根据一个可学习的权衡因子将条件嵌入添加到token表示中。结果表明,两种解码器在F1分数上的无条件融合函数性能明显下降,因为模型无法识别句子中要抽取的不同目标。此外,实证结果还表明,CLN在两种解码器的F1分数上表现优于其他融合函数,表明CLN可以为下游子任务生成更好的条件token表示。

5、总结
本文提出了一种用于重叠事件抽取的级联解码联合学习框架,称为CasEE。以往的研究通常假设事件出现在句子中没有重叠,这并不适用于复杂的重叠场景。CasEE依次执行类型检测、触发词抽取和论元抽取,其中重叠的目标根据先前的预测分别抽取。所有子任务都是联合学习的,以捕获子任务之间的依赖关系。在公共数据集上的实验表明,我们的模型在重叠事件抽取方面优于以前的竞争方法。我们未来的工作可能会进一步解决级联解码范式中潜在的错误传播问题,并提高一般事件抽取的性能。