论文:fastpillars.pdf https://arxiv.org/abs/2302.02367
作者:东南大学,美团
代码:https://github.com/StiphyJay/FastPillars (暂未开源)
讲解:https://mp.weixin.qq.com/s/ocNH2QBoD2AeK-rLFK6wEQ
PointPillars简单地利用max-pooling操作来聚合所有在支柱中使用点特征,这会大量减少本地细粒度信息,尤其会降低性能对于小物体。基于特征金字塔网络(FPN [22]), PointPillars直接融合多尺度特征跨距为1×、2×、4×,但各层之间缺乏足够的特征交互作用。
Fastpillars提出了一种简单但有效的Max-and-Attention pillar encoding(MAPE)模块。MAPE几乎无需额外的耗时(仅4ms)就能提高每个pillar特征的表示能力,能够提升小目标的检测精度;设计了一个紧凑的全卷积主干网络CRVNet,它具有竞争性的特征学习能力和推理速度,而不需要稀疏卷积。
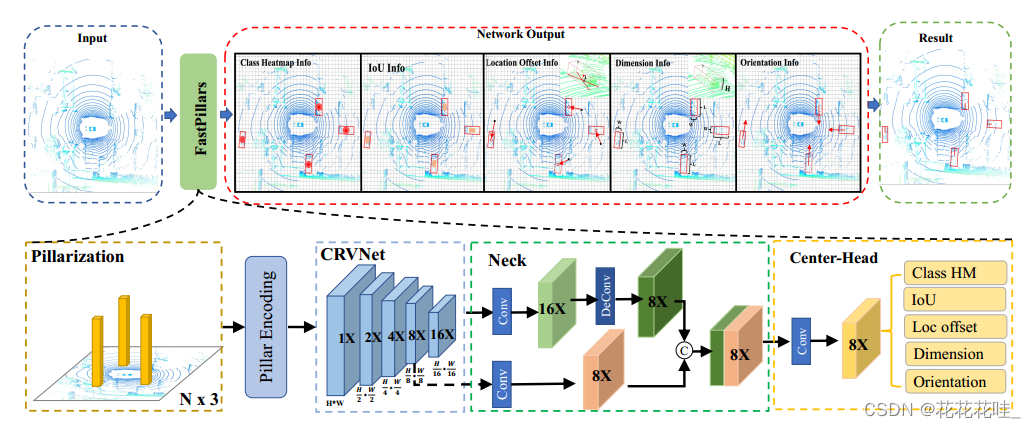
模块介绍
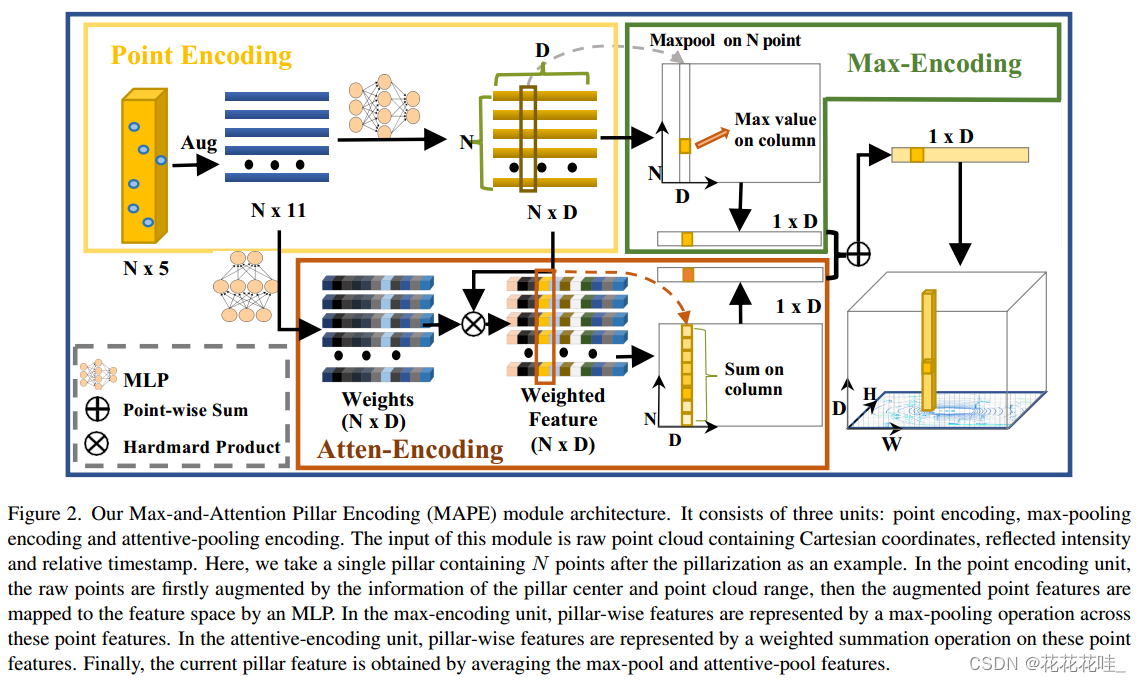
Pillar encoder: 我们提出一个简单的但是有效的最大和注意力柱编码(MAPE)模块,自动学习局部几何模式几乎没有额外的延迟(4毫秒)。MAPE模块将重要的局部特征整合在每个支柱中,大大提高了小物体的准确性。
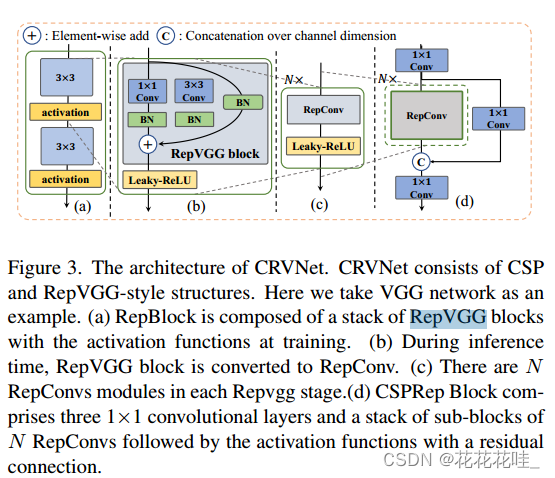
feature extraction:为增强模型的表示能力,减少计算量为了降低机载部署的延迟,我们设计了一种紧凑高效的骨干网,称为CRVNet(跨阶段-父系repvgg风格网络)。我们画我们从CSP (cross-stage-Patrial)结构和重新参数化的RepVGG网络中得到启发,并提出一个紧凑的网络,同时保持强大的特征提取能力.
特征融合块,通过分层融合不同层次和接受域的特征来丰富语义特征
回归模块,我们采用了一种高效的基于中心的头向分别对目标的分数、维度、位置、旋转和盒交比联合(IOU)信息进行回归。添加了一个IoU分支来预测预测框和地面真实框之间的3D IoU。
训练参数
-
优化器:one-cycel
-
Learning rete: 0.0001 40%个epch开始衰减
-
激活函数:leaky relu
-
检测范围:[-54,-54,-5,54,54,3]
-
Voxel size: [0.15, 0.15, 1]
数据增强
-
Flip: 随即沿X、Y轴翻转
-
旋转:随即绕Z旋转,[- 45, 45]
-
平移translated:[-0.5m,0.5m] (沿哪个维度???)
-
缩放:全局缩放[0.95,1.05]
-
copy-paste
代码复现
#MAPE模块
#====================by:liangyanyu=========================
if self.mape:
x_mape_max = self.maxpooling(x.permute(0, 2, 1))
x_mape_max = x_mape_max.permute(0,2,1)
x_attention = self.attention(x)
x_attention = torch.sum((x * x_attention) / torch.clamp(torch.sum(x_attention, dim=1, keepdim=True), min=1e-6), dim=1,keepdim=True) # [2,20,64] / [2,1, 64]==>[2,20,64] ==> [2,1,64]
x_out = (x_mape_max + x_attention) / 2
if self.last_vfe:
return x_out
else:
x_repeat = x_out.repeat(1, 20, 1)
x_concatenated = torch.cat([x, x_repeat],dim=2)
return x_concatenated
#=========================================================