出品人:Towhee 技术团队 顾梦佳
半监督学习(SSL)的动作识别是一个关键的视频理解任务,然而视频标注的高成本加大了该任务的难度。目前相关的方法主要研究了卷积神经网络,较少对于视觉 Transformers(ViT)模型的探索。SVFormer 研究了如何将半监督 ViT 用于动作识别。它采用稳定的伪标签框架(即 EMA-Teacher)处理未标记的视频样本。它还针对视频数据提出了一种新颖的增强策略,Tube TokenMix,其中视频剪辑通过掩码混合,在时间轴上具有一致的掩码 token。另外,SVFormer 还利用一种时间扭曲增强来覆盖视频中复杂的时间变化,将所选帧拉伸到各种片段的持续时间段。通过在三个公开的视频数据集 Kinetics-400、UCF101 和 HMDB-51 上进行的大量实验,SVFormer 验证了其优势。
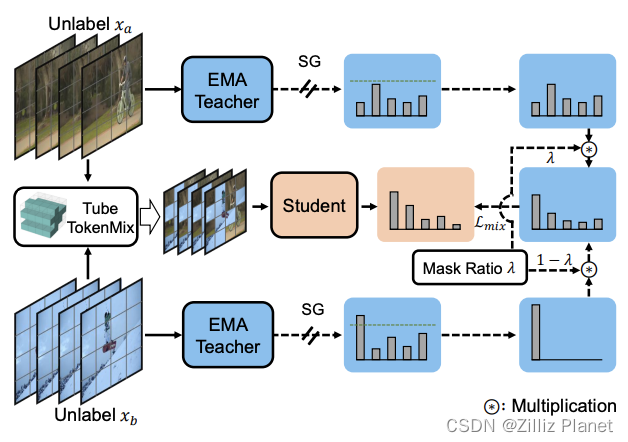
Tube TokenMix Training in SVFormer
SVFormer 是一种基于 Transformer 的半监督动作识别方法。它采用一致性损失,构建两个不同的增强视图并要求它们之间的一致预测。最重要的是,该方法提出使用 Tube TokenMix(TTMix),一种天然适用于视频 Transformer 的增强方法。与 Mixup 和 CutMix 不同,Tube TokenMix 在掩码token后就结合了 token 级别的特征,使得掩码在时间轴上具有一致的掩码 token。这样的设计可以更好地模拟 token 之间的时序相关性。为了帮助模型学习时序动态,SVFormer 进一步引入时序扭曲增强(TWAug),可以任意改变时间片段中每一帧的长度。
相关资料: