文章目录
- 1. 项目概述
- 2. 准备工作
- 2.1 数据库表格代码
- 2.2 前端代码
- 2.3 配置文件
- 3. 准备项目结构
- 3.1 拷贝前端模板
- 3.2 定义实体类
- 3.3 定义mapper接口和 xml 文件
- 3.4 创建其他包
- 4. 统一数据返回
- 4.1 Result 类
- 4.2 统一数据格式
- 5. 注册
- 5.1 逻辑
- 5.2 验证数据规范性
- 5.3 实现注册
- 5.4 前端代码完善
- 6. 登录
- 6.1 前端代码
- 6.2 后端代码
- 7. 拦截器
- 7.1 逻辑
- 7.2 拦截规则
- 7.3 拦截器所作用的范围
- 8. 博客编辑页
- 8.1 逻辑
- 8.2 触发登录验证
- 8.3 发布文章
- 8.4 保存至草稿箱
- 8.5 退出账号
- 9. 个人主页
- 9.1 获取用户信息栏
- 9.2 获取个人主页所有文章
- 9.3 删除文章
- 10. 博客详情页
- 10.1 获取 URL 中的参数
- 10.2 左侧作者信息
- 10.3 右侧文章详情
- 11. 修改文章页
- 11.1 加载文章内容
- 11.2 将文章保存为草稿
- 11.3 修改后发表
- 12. 博客主页
- 12.1 分页
- 12.2 前端
- 12.3 后端
- 12.4 实现剩下四个按钮
- 13. 密码加盐加密
- 13.1 加盐加密
- 13.2 验证
- 13.3 更新
- 14. Session 持久化
- 15. 实现定时发布功能
- 15.1 逻辑
- 15.2 建表
- 15.3 后端实现
- 15.3.1 时间戳问题
- 15.3.2 构造方法与小根堆
- 15.3.3 启动线程
- 15.3.4 运行过程中添加定时发布的文章
- 15.3.5 前端部分
- 16. 全代码
1. 项目概述
博客系统,可以说是非常经典的项目了。该博客系统是基于 SSM 框架所实现的,除了博客的游览,发布等功能,还实现了:分页查询,MySQL中用户密码的密文存储(使用MD5加密搭配加盐实现),草稿箱,定时发布等功能
本博客系统主要的页面有登录页,注册页,个人博客页,主页,博客详情页,博客编辑页,博客修改页。这些页面的具体工作,根据生活经验和页面名字也都能得知。
以下是各个页面的展示效果
登录页
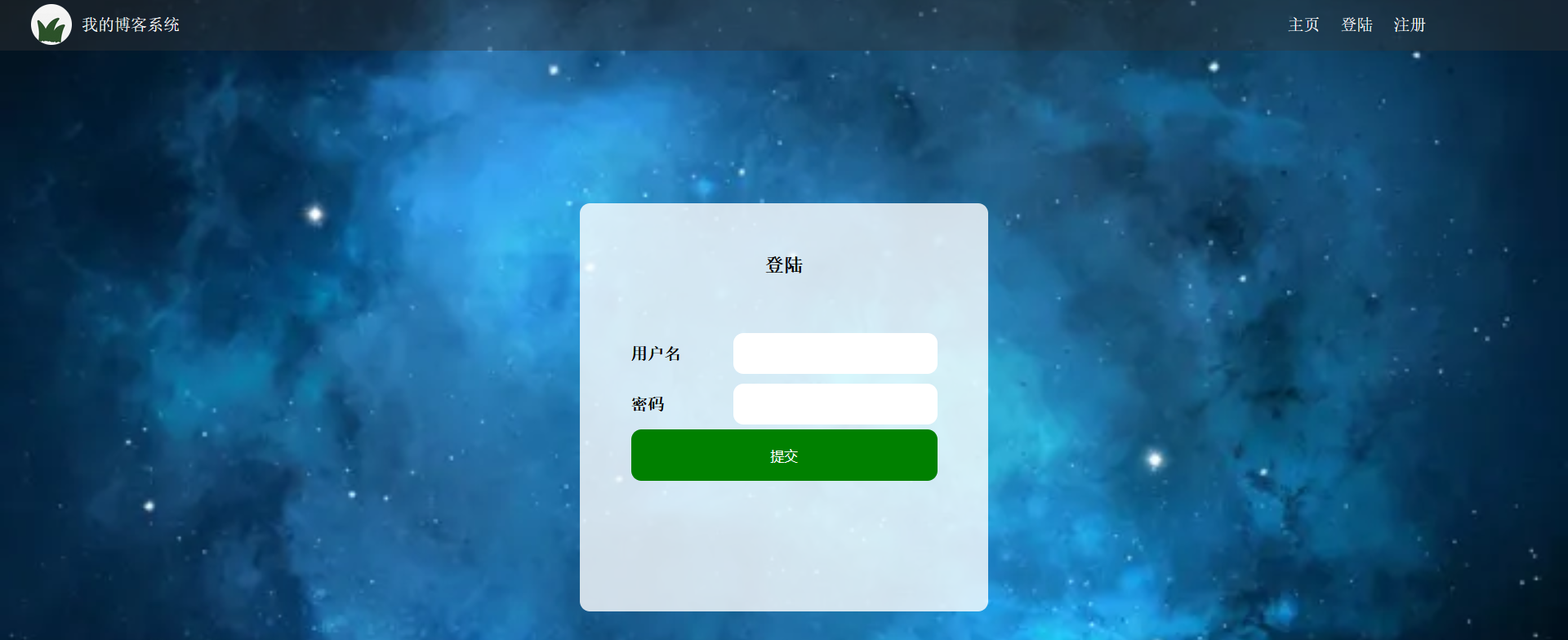 注册页(比登录页少了个注册)
注册页(比登录页少了个注册)
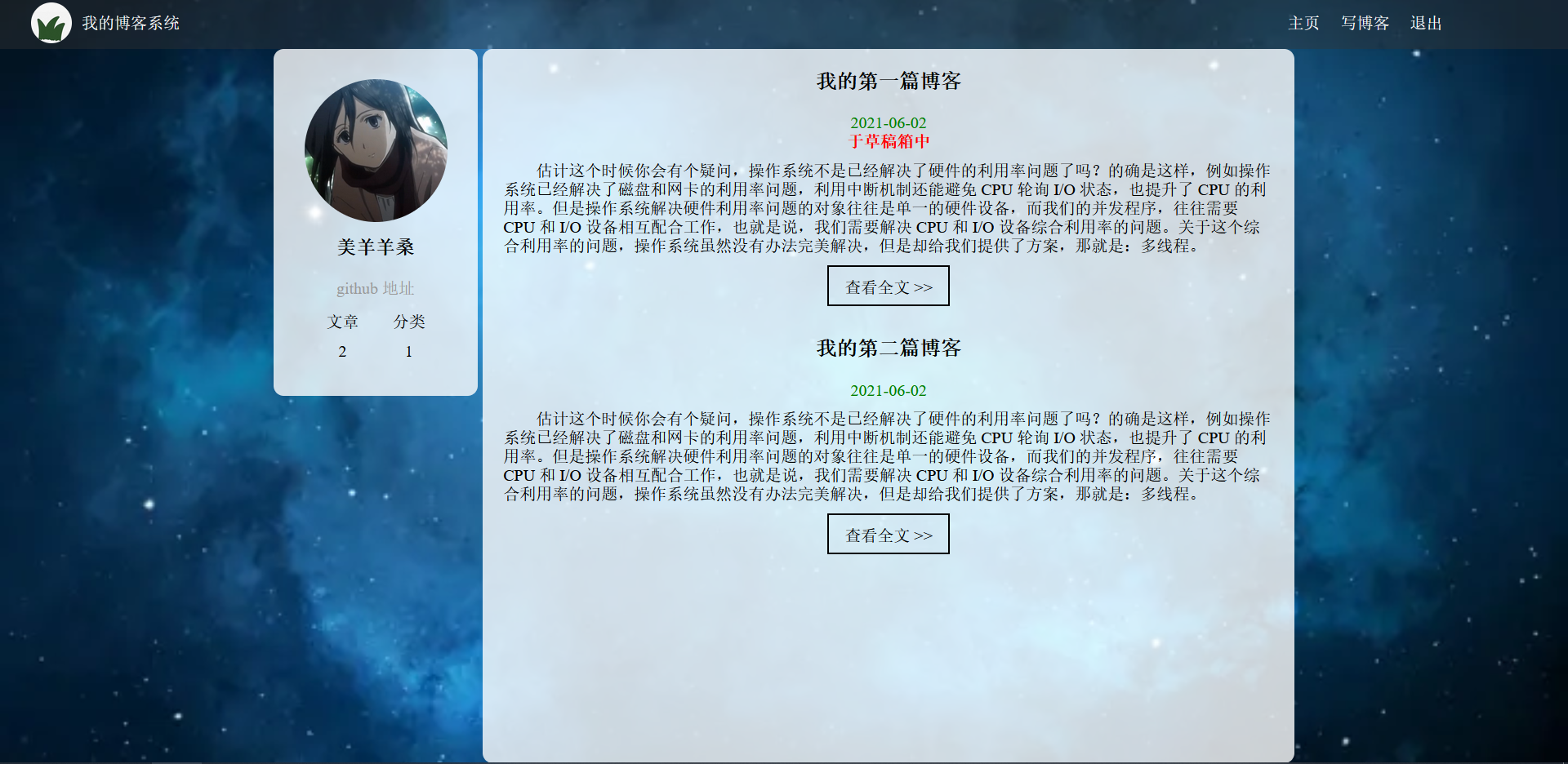
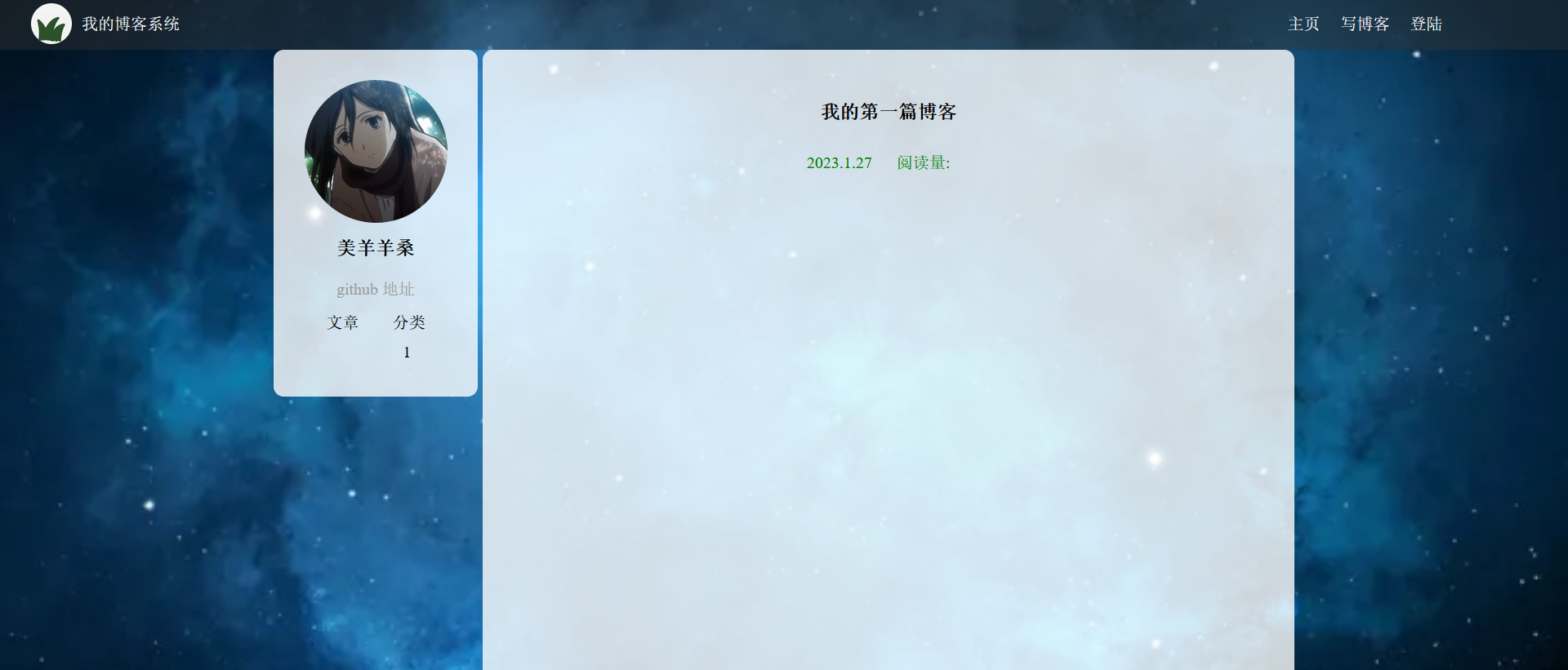
 个人博客页
个人博客页
主页

博客编辑页
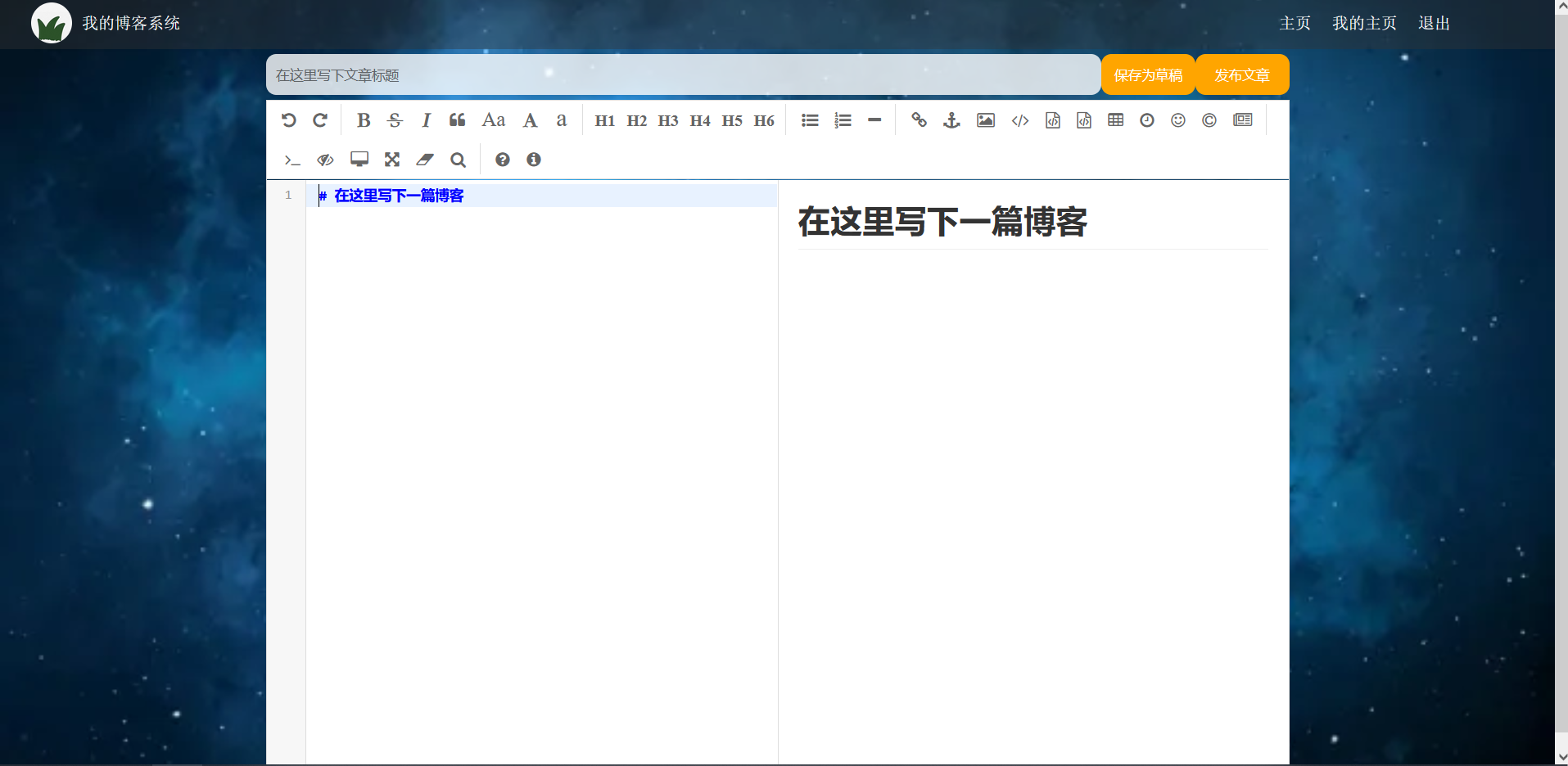
文章详情页
2. 准备工作
2.1 数据库表格代码
首先在自己的电脑上创建数据库,定义表格,可以直接复制粘贴以下代码:
创建了两个表格,用户表和文章表
-- 创建数据库
drop database if exists blog_system;
create database blog_system DEFAULT CHARACTER SET utf8mb4;
-- 使用数据数据
use blog_system;
-- 创建表[用户表]
drop table if exists userinfo;
create table userinfo(
id int primary key auto_increment,
username varchar(100) not null,
password varchar(64) not null,
photo varchar(500) default '',
createtime datetime default now(),
updatetime datetime default now(),
`state` int default 1
) default charset 'utf8mb4';
-- 创建文章表
drop table if exists articleinfo;
create table articleinfo(
id int primary key auto_increment,
title varchar(100) not null,
content text not null,
createtime datetime default now(),
updatetime datetime default now(),
uid int not null,
rcount int not null default 1,
`state` int default 1
)default charset 'utf8mb4';
-- 添加一个用户信息
INSERT INTO `blog_system`.`userinfo` (`id`, `username`, `password`, `photo`, `createtime`, `updatetime`, `state`) VALUES
(1, 'boy', 'boy', '', '2021-12-06 17:10:48', '2021-12-06 17:10:48', 1);
-- 文章添加测试数据
insert into articleinfo(title,content,uid)
values('blog_system','这个是正文',1);
2.2 前端代码
前端代码直接使用模板:
前端模板
2.3 配置文件
Spring 项目的创建不再赘述,以下是Spring项目的配置文件
spring:
datasource:
# 下面这行的 blog_system 是我数据库的名字,大家需要根据情况修改
url: jdbc:mysql://127.0.0.1:3306/blog_system?characterEncoding=utf8
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
mybatis:
mapper-locations: classpath:mapper/**Mapper.xml # 配置 MyBatis 中 xml 文件的格式
configuration: # 配置打印 MyBatis 执行的 SQL
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
# 配置打印 MyBatis 执行的 SQL
# 配置日志打印信息
logging:
level:
com:
example:
demo: debug
3. 准备项目结构
创建完项目,指令了配置信息之后,我们可以先将项目的结构先构建出来
3.1 拷贝前端模板
将前端模板的代码拷贝一份到 static 文件中
3.2 定义实体类
定义实体类,并且放在model包中。这里分别定义为User类和 Article类
⭐User 类和 Article类分别「对应」数据库中的userinfo和articleinfo两张表的一条数据,并且表的字段名需要和实体类的属性名一样(如果不一样,那么需要使用ResultMap进行重映射,本项目不涉及)代码如下
@Data // 减少代码冗余,内置 toString(), get(), set() 等常见方法
public class User {
private int id; // 用户 ID
private String username; // 用户名
private String password; // 用户密码
private String photo; // 头像 (可以用来拓展博客功能)
private String createtime; // 创建时间 (默认是当前时间)
private String updatetime; // 更新时间 (默认是当前时间)
private int state; // 状态
}
@Data
public class Article {
private int id; // 文章 ID
private String title; // 标题
private String content; // 正文
private String createtime; // 创建时间 (默认是当前时间)
private String updatetime; // 更新时间 (默认是当前时间)
private int uid; // 用户 ID
private int rcount; // 访问量 (阅读量)
private int state; // 状态
}
3.3 定义mapper接口和 xml 文件
创建 mapper目录,定义两个接口,来分别操作 MyBatis,并且注意加上@Mapper注解,这里不多说
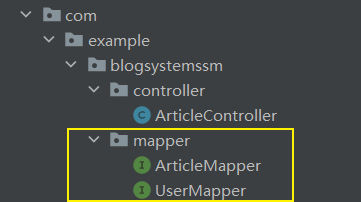
🍓创建这两个接口对应的 xml 文件,这里要根据配置文件中约定的格式来;而对于我上面所配置的约定,需要在 resources 下创建 mapper 文件夹,然后 xml 文件以 xxMapper.xml 的格式来命名👇:
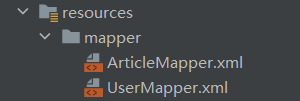
接着在 xml 文件中加上固定的代码块,并在namespace中填写指定的接口路径
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.demo.mapper.xxx"> <!-- 这里的namespace需要自己指定路径 -->
</mapper>
代码如下:
ArticleMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.blogsystemssm.mapper.ArticleMapper">
</mapper>
UserMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.blogsystemssm.mapper.UserMapper">
</mapper>
3.4 创建其他包
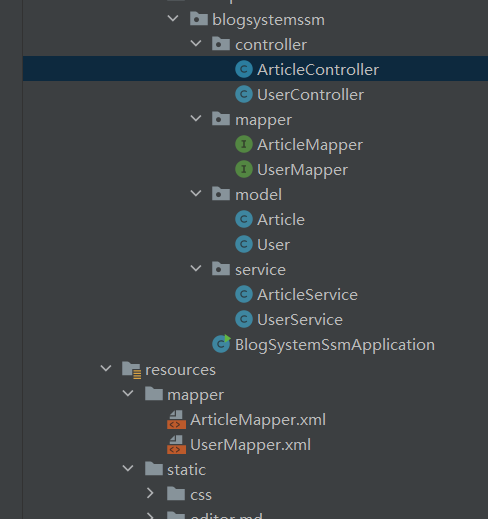
然后再分别创建controller, service, common 三个包,其中 common 表示公共的,这个包用来防放置一下大家都要可以用到的类,conroller 包中再创建ArticleController和UserController,service 包创建ArticleService和 UserService,并且加上相应的注解。
此次,项目的大致结构就完成了,目录结果大致如下:
4. 统一数据返回
在项目正式开始前,可以先利用 AOP 思想来处理所有返回给前端的数据。
4.1 Result 类
⭐如果想要达成一个目的:返回给前端的数据必须要有三个属性,状态码state,其他信息msg,业务执行完后返回给前端的数据data
那么我们无法保证每个程序员都能够对业务执行完成之后的结果data经过一层包装,具备上述三个属性之后,再返回给前端。
所以我们可以创建一个类Result,里面提供包装data的方法,大家看以下代码就懂了(结合注释理解):
/**
* 返回结果一定要有三个值: state(状态码), msg(传递给前端的消息), data(业务执行数据)
* 该方法专门用来包装返回结果(也就是data),包装成 HashMap
* 并且规定 state = 200 的时候,表示业务代码执行顺利
* state = -1 的时候,表示业务代码出现异常
*/
public class Result {
// 业务执行成功
public static HashMap<String, Object> succeed(Object data) {
HashMap<String, Object> result = new HashMap<>();
result.put("state", 200);
result.put("msg", "");
result.put("data", data);
return result;
}
// 业务出现有误
public static HashMap<String, Object> fail() {
HashMap<String, Object> result = new HashMap<>();
result.put("state", -1);
result.put("msg", "");
result.put("data", "");
return result;
}
}
所以后端程序员可以将返回给前端的结果再经过 Result.succeed() 或者 Result.fail()进行包装,前端就可以获取更清晰的结果。
当然,这里可以通过重载的方式来丰富 succeed 和 fail 中的参数
4.2 统一数据格式
虽然已经有了 Result 类,程序可以通过手动Result.succeed(data)或者Result.fail(data) 的方式向前端发送数据,但是为了保证没有漏网之鱼,可以添加一层保底 —— 统一数据格式
它可以在真正将数据返回给前端之前再进行一次处理:如果返回给前端的数据已经经过Result处理了,这时候就不需要再包装一层;而如果数据没有经过Result处理,而是直接返回 -1 等等,那么这时候我们就要「补救」
实现步骤:
Ⅰ. 创建一个类,该类使用@ControllerAdvice 注解修饰
Ⅱ. 该类需要实现ResponseBodyAdvice接口
Ⅲ. 重写supports 和 beforeBodyWrite方法,并且 supports方法直接返回 true
以上是「统一数据格式」的规范,代码如下
@ControllerAdvice
public class ResponseAdvice implements ResponseBodyAdvice {
@Override
public boolean supports(MethodParameter returnType, Class converterType) {
return true;
}
@Override
public Object beforeBodyWrite(Object body, MethodParameter returnType, MediaType selectedContentType, Class selectedConverterType, ServerHttpRequest request, ServerHttpResponse response) {
return null;
}
}
然后最后一层「保底」指的就是这个beforeBodyWrite方法了,而其中的参数Object body就是返回给前端的数据,在这个方法中,我们可以对这个数据进行处理。和前边所说的逻辑一样:如果数据已经被包装了,那就直接返回,如果还没,那就在这里进行包装。代码如下
public Object beforeBodyWrite(Object body, MethodParameter returnType, MediaType selectedContentType, Class selectedConverterType, ServerHttpRequest request, ServerHttpResponse response) {
// 如果已经经过 Result 包装了,那就是 HashMap 类型的,直接返回
if (body instanceof HashMap) {
return body;
}
// 如果返回的数据是 字符串类型的
if (body instanceof String) {
ObjectMapper objectMapper = new ObjectMapper();
return objectMapper.writeValueAsString(Result.succeed(body));
}
// 每经过处理,那就通过此处 进行包装
return Result.succeed(body);
}
但是大伙看到这可能会感觉有点奇怪,为什么上述代码要特殊处理 body 是 String类型的情况?大家感兴趣可以看这篇博客:
ResponseBodyAdvice、String返回值报cannot be cast to java.lang.String的解决办法
博客写的很好,介绍得很详细,我就不说什么了
5. 注册
接下来才是正文
5.1 逻辑
首先实现最简单的注册功能

这里实现的注册功能有几点要求:
Ⅰ. 三项数据都不能为空,否则提示用户
Ⅱ. 密码和确认密码要相等,前端可以进行验证
Ⅲ. 用户名唯一,如果后端已经存在这个用户名,则注册失败
Ⅳ. 满足上述要求,则将用户名和密码存储到数据库中
5.2 验证数据规范性
首先先引入 jQuery
<script src="js/jquery.min.js"></script>
对于 Ⅰ 和 Ⅱ,我们都可以在前端实现,而对于上面的所有步骤,都需要点击「提交」之后触发,所以我们在提交按钮上可以加个 onclick

通过点击这个提交,就可以触发onclick这个方法,然后编写 js 的代码:
function submit() {
var username = jQuery("#username");
var password = jQuery("#password");
var passwordagain = jQuery("#passwordagain");
if (username.val() == "") {
alert("账号为空")
username.focus();
return false;
}
if (password.val() == "") {
alert("密码为空");
password.focus();
return false;
}
if (passwordagain.val() == "") {
alert("确认密码为空");
passwordagain.focus();
return false;
}
if (password.val() != passwordagain.val()) {
alert("两次输入的密码不一致");
password.focus();
return false;
}
}
5.3 实现注册
通过了上面 js 代码的判断之后,就都满足Ⅰ和 Ⅱ 两个要求了,所以就可以将用户名和密码通过 Ajax 发送给后端,并约定路由为/user/registry
由刚刚的 onclick 方法继续下面 js 代码
jQuery.ajax({
url:"/user/registry",
type:"POST",
data:{
username:username.val(),
password:password.val()
},
success:function(result) {
// 等待
}
});
然后就可以在UserController中编写代码
Ⅰ. 后端对接收到的username 和 password仍然需要进行非空校验
Ⅱ. 检验用户名是否重复,这个很简单,只需要在数据库中查询 username,如果返回结果为空,说明没重复,将这个用户的用户名和密码存入数据库中;否则,约定后端返回状态码state为 -2的时候,表示用户名重复
这里涉及到的 sql 语句没什么难度,讲快一些,其中 StringUtils是字符串工具类,它的静态方法hasLength()可以用来判断字符串是否有长度
@RequestMapping("/registry")
public Object registry(String username, String password) {
// 非空检验, 如果两个任意一个为空,或者两个中任意一个没有内容
if (!StringUtils.hasLength(username) || !StringUtils.hasLength(password)) {
return Result.fail(-1, "账号密码为空");
}
// 根据用户名查询指定用户
User user = userService.selectByUsername(username);
if (user != null) { // 不为空,说明重复了,状态码返回 -2
return Result.fail(-2, "用户名重复");
}
// 新增(注册)一个用户
int result = userService.add(username, password);
if (result == 1) { // 如果受影响的行数为 1
return Result.succeed(1);
} else { // 受影响行数不为 1
return Result.fail(-1, "");
}
}
5.4 前端代码完善
刚刚是完成了后端逻辑,那么前端接收到响应之后,就要对数据的状态码进行处理,刚刚说到,state = -2说明账号被注册,state = 200 说明一切正常,注册成功,state = -1 表示注册过程中出现异常或者参数有误。
⭐而注册成功后,就可以将页面跳转到登录页
所以 Ajax 的回调函数代码如下
success:function(result) {
if (result.state == 200 && result.data == 1) { // 状态码正常, 并且数据库受影响行数 为1
alert("注册成功");
location.href = "login.html"; // 跳转到登录页
} else {
if (result.state == -2) {
alert("该用户名已经被注册!");
username.focus();
} else {
alert("注册参数有误, 请重新注册");
}
}
}
最简单的注册页面就完成了,但是还有点问题,在服务器中,密码是直接以明文的形式存储在 MySQL 中的,这就有一定的安全问题,我们可以对密码进行加密之后再进行存储,我们后面再提及
6. 登录
只需要用户将用户名和密码输入后,前端判断是否为空,如果不为空,那么将两个数据发送给后端,约定接口为/user/login,后端再根据用户名查询出这个用户,判断输入密码和真实密码是否一致,返回 1 表示一致,返回 0 表示登录失败。并且登录成功之后将页面跳转到「个人主页」
6.1 前端代码
首先让提交按钮能够触发 js 的方法,验证有效性之后,通过 Ajax 发送请求给后端,如果状态码正常并且 data 为1,表示登录成功,否则提示用户账号或者密码错误
<script>
function submit() {
var username = jQuery("#username");
var password = jQuery("#password");
if (username.val() == "") {
alert("用户名为空, 请重新输入");
username.focus();
return false;
}
if (password.val() == "") {
alert("密码为空, 请重新输入");
password.focus();
return false;
}
jQuery.ajax({
url:"/user/login",
type:"POST",
data:{
"username":username.val(),
"password":password.val()
},
success:function(result) {
if (result.state == 200 && result.data == 1) {
location.href = "myblog_list.html"; // 跳转到个人主页
} else {
alert("用户名或密码错误");
username.focus();
}
}
});
}
</script>
6.2 后端代码
接收到数据之后,如果登录成功,那么为了后续的用户体验,还需要添加会话,因此这个方法中的参数还需要HttpServletSession request,通过request.getSession() 来获取会话,并且设置参数为 true,表示如果不存在会话,那就为当前用户创建一个会话。
然后需要往会话中存储用户信息,可以设置 key 为一个固定值,key 对应的 value 就是用户信息。
这个固定值可以放在一个Constants(常量)类中进行管理
// 用来管理常量
public class Constants {
// 会话中 存储用户信息的 key 值
public static final String USER_SESSION_KEY = "user_session_key";
}
后端登录业务代码如下:
// 登录
@RequestMapping("/login")
public int login(HttpServletRequest request, String username, String password) {
// 其中一个为空
if (!StringUtils.hasLength(username) || !StringUtils.hasLength(password)) {
return 0;
}
User user = userService.selectByUsername(username);
if (user == null) {
return 0;
}
boolean isCorrect = user.getPassword().equals(password);
// 数据有效 并且 密码正确
if (user != null && user.getId() > 0 && isCorrect) {
// 获取会话,如果不存在会话,那么创建一个会话
HttpSession httpSession = request.getSession(true);
// 存储用户信息
httpSession.setAttribute(Constants.USER_SESSION_KEY, user);
return 1;
} else {
return 0;
}
}
7. 拦截器
为了后续的用户体验,拦截器可以通过配置的方式来拦截某一类页面。
Ⅰ. 如果用户没有登录,那么这些用户是没有无法访问「个人主页」,「编辑博客」这些页面的。
Ⅱ. 如果登录了,那么后续页面就不需要进行重复登录
Ⅲ. 拦截的规则很简单,就是在访问页面或者接口的时候,验证用户是否登录,可以判断是否存在会话,会话中是否存在用户信息来进行判断
7.1 逻辑
拦截器实现起来和统一数据格式一样,需要按照约定编写代码
Ⅰ. 自己定义一个类, 需要实现 HandleInterceptor 接口, 然后重写 preHandle 方法,这个类用来定义拦截的规则
Ⅱ. 再定义一个类, 再实现 WebMvcConfigurer 接口, 重写里面的 addInterceptors 方法,这用来定义需要拦截什么,不需要拦截什么
Ⅲ. 将第一个类对象作为参数来增加拦截器, 需要使用 addInterceptor 方法, 再用 addPathPatterns 和 excludePathPatterns 来选择拦截对象。(两个类都需要由 Spring 进行管理)
7.2 拦截规则
这也就是第Ⅰ步的代码,定义这个类为 LoginInterceptor ,拦截规则就是根据有没有登录(会话)来判断是否放行
@Component
public class LoginInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 这个方法用来定义拦截的规则
HttpSession session = request.getSession(false);
// 如果不存在会话,或者会话中的信息不存在
if (session == null || session.getAttribute(Constants.USER_SESSION_KEY) == null) {
response.setStatus(401);
return false; // 不能访问
}
return true; // 可以访问
}
}
7.3 拦截器所作用的范围
然后是第 Ⅱ 和 Ⅲ 步,第 Ⅱ 步中的类这里定义为InterceptorScope(拦截器范围),重写addInterceptors方法之后,这个方法里有个参数InterceptorRegistry registry,然后通过registry.addInterceptor(参数)方法,并将LoginInterceptor作为参数就可以构建一个构造器了
⭐再再再通过这个构造器的addPathPatterns 和 excludePathPatterns方法来添加和去除需要拦截器所需要过滤的页面或者接口
可以直接拦截所有的页面和路由,然后再去除掉一部分我们不拦截的:
Ⅰ. 所有的静态页面都不需要拦截
Ⅱ. markdown文本编辑器不需要拦截

Ⅲ. 所有的 js 代码和 css 代码也不需要拦截
Ⅳ. 图片不需要拦截
Ⅴ. 前端向后端发送的注册和登录请求也不需要拦截
综上,该部分代码暂时可以是:
@Configuration
public class InterceptorScope implements WebMvcConfigurer {
@Autowired
LoginInterceptor loginInterceptor ;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(loginInterceptor)
.addPathPatterns("/**") // 所有的一切 都拦截
.excludePathPatterns("/**/*.html") // 除了 ...
.excludePathPatterns("/editor.md/**")
.excludePathPatterns("/js/**")
.excludePathPatterns("/css/**")
.excludePathPatterns("/img/**")
.excludePathPatterns("/user/login") // 不拦截 登录 页面
.excludePathPatterns("/user/registry"); // 不拦截 注册 页面
}
}
8. 博客编辑页
8.1 逻辑
登录之后会跳到个人主页,但是个人主页晚点说,先说简单的。
博客编辑页,可以将写的文章存入草稿箱,也可以直接将将文章发布出去。
 实现逻辑:
实现逻辑:
Ⅰ. 由于刚刚拦截器一键放行了所有的静态页面,这里要写博客,一定要登录,所以这里可以往后端发送请求,在后端验证登录状态,如果没登录,前端就直接将页面跳转到登录页
Ⅱ. 前端检验数据有效性(标题不能为空,正文不能少于 100 个字符)
Ⅲ. 将标题和正文发送给后端,后端通过会话,将文章内容结合会话中的用户信息存入文章表中
8.2 触发登录验证
这实现起来很容易,约定一个接口/islogged,后端再获取会话,如果登录了,返回1,否则返回0
由于这个项目需要频繁验证登录状态,所以可以将会话的获取包装一下:
// 获取用户登录信息
public class SessionUtil {
// 获取登录用户
public static User getLoginUser(HttpServletRequest request) {
HttpSession session = request.getSession(false);
if (session == null || session.getAttribute(Constants.USER_SESSION_KEY) == null) {
return null;
}
return (User) session.getAttribute(Constants.USER_SESSION_KEY);
}
}
前端用 Ajax 发送请求:
// 检查是否已经登录了
function checkIsLogged() {
jQuery.ajax({
url:"/user/islogged",
type:"GET",
success:function(result) {
if (result.state == 200 && result.data == 1) {
return true; // 已经登录,就可以继续
}
},
error:function(result) {
alert("请您先登录账号");
location.href = "login.html"; // 没有登录,进行跳转
return false;
}
});
}
checkIsLogged();
后端:
/**
* 验证是否已经登录
* 已登录返回 1
* 未登录返回 0
* @return
*/
@RequestMapping("/islogged")
public int isLogged(HttpServletRequest request, HttpServletResponse response) {
User user = SessionUtil.getLoginUser(request);
if (user == null) {
response.setStatus(401);
return 0;
}
return 1;
}
8.3 发布文章
首先为这个标题加上一个 ID

前端验证完数据合法性之后点击「发表文章」触发 js 的方法,然后约定接口/article/submit发送给后端,但是需要注意:

本项目实现了草稿箱功能,其依赖于 userinfo 表中的 state 字段,视 state = 1 的时候,文章是发表状态,视 state = 2 的时候,视为是草稿箱状态。而表中的 state 字段默认是 1,所以直接插入即可
插入后返回受影响的行数,如果是 1,说明一切正常,文章发表完成,前端将页面跳转到个人主页,前端代码:
// 提交
function mysub() {
var title = jQuery("#title");
var content = editor.getValue();
if (title.val() == "" || title.length <= 0) {
alert("标题不能为空");
return false;
}
if (content == "" || content.length < 100) {
alert("文章内容不能少于100字");
return false;
}
jQuery.ajax({
url:"/article/submit",
type:"POST",
data: {
"title":title.val(),
"content":content
},
success:function(result) {
if (result.state == 200 && result.data == 1) { // 受影响的行数为 1
alert("文章上传成功");
location.href = "myblog_list.html"; // 跳转
} else {
alert("账号未登录或文章参数有误");
}
}
});
}
后端:
@RestController
public class ArticleController {
@Autowired
ArticleService articleService ;
// 发表一篇文章
@RequestMapping("/submit")
public int submit(HttpServletRequest request, String title, String content) {
User user = SessionUtil.getLoginUser(request);
if (user == null) {
return -1;
}
return articleService.submit(user.getId(), title, content);
}
}
8.4 保存至草稿箱
除了直接发表文章之外,也可以直接保存到草稿箱中,这里的逻辑和发表文章非常相似,只是插入的文章 state 设置为 2 即可。🍓约定接口为/artilce/draft

前端代码
// 保存为草稿项
function saveAsDraft() {
var title = jQuery("#title");
var content = editor.getValue();
if (title.val() == "" || title.length <= 0) {
alert("标题不能为空");
return false;
}
if (content == "" || content.length < 100) {
alert("文章内容不能少于100字");
return false;
}
jQuery.ajax({
url:"/article/draft",
type:"POST",
data: {
"title":title.val(),
"content":content
},
success(result) {
if (result.state == 200 && result.data == 1) {
alert("成功保存到草稿箱");
location.href = "myblog_list.html";
} else {
alert("账号未登录或者参数有误");
}
}
});
}
后端代码和刚刚的发表文章十分相似,如下是 xml 文件的的 sql 语句
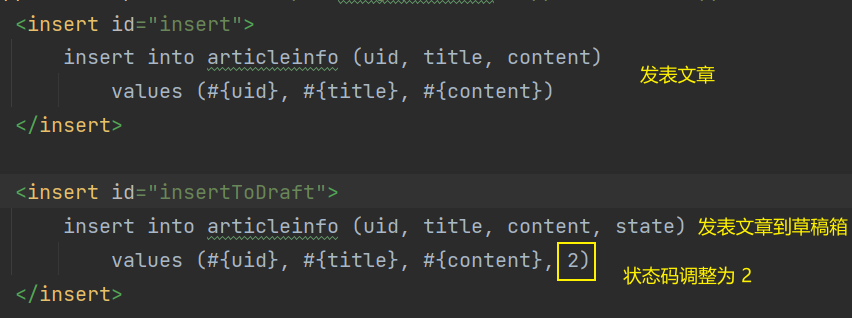
代码如下
/**
* 实现: 将文章保存到草稿箱中
* 相当于普通的插入文章, 但是 state = 2
* 前端返回两个参数: title, content
* @return 返回受影响的行数
*/
@RequestMapping("/draft")
public int saveAsDraft(HttpServletRequest request, String title, String content) {
User user = SessionUtil.getLoginUser(request);
if (user == null) {
return -1;
}
return articleService.submitToDraft(user.getId(), title, content);
}
8.5 退出账号
在博客编辑页中,如下,右上角中还有个退出功能

还是一样,为这个按钮添加一个 onclick

这个实现也非常简单,向约定的接口/user/logout发送一个请求,然后后端将相关的会话删除掉,前端再跳转到登录页就可以了
前端代码:
function exit() {
if (confirm("确定要退出账号吗?")) { // 来个确认按钮
jQuery.ajax({
url:"/user/logout",
type:"POST",
data:{}, // 不需要数据
success:function(result) {
alert("注销成功");
location.href = "login.html";
},
error:function(error) {
// 这种情况就是被拦截器锁拦截了
if (error != null && error.status == 401) {
alert("用户未登录")
location.href = "/login.html"; // 进行跳转
}
}
});
}
}
后端代码也很简单
// 退出账号
@RequestMapping("/logout")
public int logout(HttpServletRequest request) {
HttpSession session = request.getSession(false);
// 如果存在会话 并且 会话中有信息
if (session != null && session.getAttribute(Constants.USER_SESSION_KEY) != null) {
// 那就删除这个信息
session.removeAttribute(Constants.USER_SESSION_KEY);
}
// 退出成功
return 1;
9. 个人主页
 这个页面就是展示用户登录后的个人主页,展示所有文章,包括草稿箱中的文章,并且左侧的个人信息栏,需要显示用户的姓名和文章数量(头像也可以进行更新),⭐但是这里的文章数量是不包括草稿箱里面的文章的
这个页面就是展示用户登录后的个人主页,展示所有文章,包括草稿箱中的文章,并且左侧的个人信息栏,需要显示用户的姓名和文章数量(头像也可以进行更新),⭐但是这里的文章数量是不包括草稿箱里面的文章的
9.1 获取用户信息栏
这里需要将左侧信息渲染完整,向后端发送请求,约定路由为/user/myinfo,并且这个页面启动的时候就需要向前端发送请求
 并且后端需要返回两个数据:① 用户文章总数(已发布文章数) ② 用户名(也可以是这个用户对象),后端要把两个数据进行打包返回给前端
并且后端需要返回两个数据:① 用户文章总数(已发布文章数) ② 用户名(也可以是这个用户对象),后端要把两个数据进行打包返回给前端
所以前端拿到数据后,就可以对 以上两项数据 进行渲染,代码如下
// 加载左侧用户信息
function getMyInfo() {
jQuery.ajax({
url:"/user/myinfo",
type:"GET",
data:{},
success:function(result) {
if (result.state == 200 && result.data != null) {
// 对这两个标签的内容进行填充
jQuery("#username").text(result.data.user.username); // 用户姓名
jQuery("#articleCount").text(result.data.articleCount); // 用户文章总数
}
},
error:function(error) {
if (error != null && error.status == 401) {
// 被拦截了
alert("用户未登录");
location.href = "login.html";
}
}
});
}
getMyInfo(); // 页面在加载的时候就发送请求进行获取
后端代码如下

/**
* 获取个人主页的 用户名 以及创作总数
* @return
*/
@RequestMapping("/myinfo")
public Object getMyInfo(HttpServletRequest request) {
User user = SessionUtil.getLoginUser(request);
if (user == null) {
return null;
}
// 用来包装结果
HashMap<String, Object> result = new HashMap<>();
result.put("user", user); // 存放这个对象
// 获取文章总数
int sum = articleService.getArticleCountByUid(user.getId());
result.put("articleCount", sum);
return Result.succeed(result);
}
9.2 获取个人主页所有文章
左侧是显示用户的个人信息,右侧是该登录用户的所有文章了(包括已发表文章和保存在草稿箱中的文章),并且对于每一个文章,用户都可以进行「查看详细」,「修改」和「删除」
因此,我们就需要对这一段前端代码进行渲染
- 在①这个标签再加一个
id="articleListDiv",然后再将这个用户的所有文章通过 For 循环,添加到这个标签之中,每一个文章就相当于一个class=blog的标签 - 像②的标题,日期,摘要,就要重新调整具体的值,将每一篇博客的相关属性拼接上去
- ④和⑤也是同理,在游览器渲染的时候,就把这三个标签给构造好,④是构造好链接,⑤是为了点击删除的时候,能触发 js 中的方法
- 而像③这种,就要判断当前文章的state 是否为 2,来决定添加与否
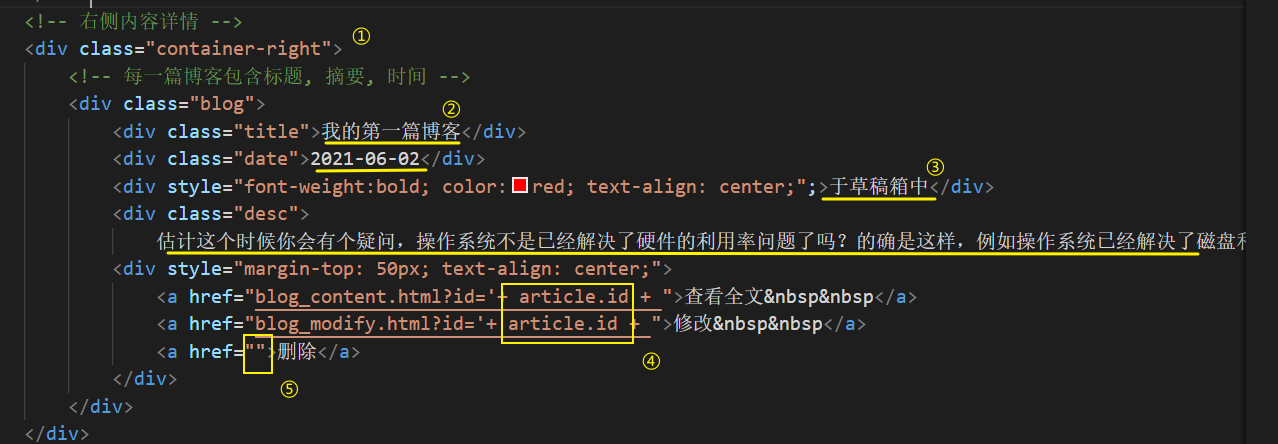
约定前端发送的路由为/article/mylist,并且后端必然是返回 List,然后前端遍历接收到的数据,没一个数据都重新组装成一个class=blog的 div 元素,并作为最外层Div(articleListDiv)的子元素。
但是在个人主页中,显示的每一篇文章,都不能完全展示正文,而应该展示摘要,所以还需要对正文进行提取,此处我们对该正文的前100个字符作为摘要
前端代码如下
// 获取文章的开头
function getBeginning(content) {
if (content.length < 100) { // 如果文章字符串长度小于 100
return content;
}
return content.substring(0, 100);
}
function getMyList() { // 初始化个人主页的博客信息
jQuery.ajax({
url:"/article/mylist",
type:"GET",
data:{},
success:function(result) {
// 状态码正常 && 后端有返回数据 && 返回的数据至少有 一篇文章
if (result.state == 200 && result.data != null && result.data.length > 0) {
var html = "";
result.data.forEach(function(article) {
html += '<div class="blog">';
html += '<div class="title">' + article.title +'</div>';
html += '<div class="date">' + article.createtime + '</div>';
if (article.state == 2) { // 如果该文章是草稿, 那么特殊备注一下
html += '<div style="font-weight:bold; color:red; text-align: center;";>于草稿箱中</div>';
}
html += '<div class="desc">' + getBeginning(article.content) + ' </div>';
html += '<div style="margin-top: 50px; text-align: center;">';
html += '<a href="blog_content.html?id='+ article.id + '">查看全文</a>  ';
html += '<a href="blog_modify.html?id='+ article.id + '">修改</a>  ';
html += '<a href="javascript:del('+ article.id + ')">删除</a>';
html += '</div>' + '</div>';
});
jQuery("#articleListDiv").html(html); // 全部加到 articleListDiv 中
} else { // 没有发表过文章
jQuery("#articleListDiv").html("<h1>暂无数据</h1>");
}
}
});
}
getMyList(); // 进入这个页面就需要执行
这里后端代码比前端代码简单多了,如下
/**
* 获取用户的所有文章
*/
@RequestMapping("/mylist")
public List<Article> getMyList(HttpServletRequest request) {
User user = SessionUtil.getLoginUser(request);
if (user == null) {
return null;
}
List<Article> articles = articleService.getAllByUid(user.getId());
return articles;
}
9.3 删除文章
上述页面测试效果如下👇,并且在这个页面中,每一篇文章都有三个标签,这里先实现删除功能。

这个实现也简单,约定接口为/article/delete,前端把这个 文章的 ID 发送给后端,然后后端进入数据库中进行删除,完事了之后前端再跳转到个人主页(相当于刷新)
前端代码:
// 通过点击删除按钮触发这个方法
function del(articleId) { // 删除文章
if (confirm("您确定要删除该文章吗")) {
jQuery.ajax({
url:"/article/delete",
type:"GET",
data:{
"articleId":articleId
},
success:function(result) {
if (result.state == 200 && result.data == 1) { // 删除的文章数量为 1
alert("删除成功");
location.href = "myblog_list.html";
} else {
alert("参数异常, 删除失败");
}
}
});
}
}
需要注意:由于是删除文章,所以会话用户的 ID 必须和待删除文章的 UID 一致,否则没有权限!
// 删除指定文章
@RequestMapping("/delete")
public Integer delete(HttpServletRequest request, Integer articleId) {
if (articleId == null || articleId <= 0) {
return null;
}
// 获取当前会话用户
User user = SessionUtil.getLoginUser(request);
// 获取这篇文章对象
Article article = articleService.getById(articleId);
// 两个都不为空,并且文章得是自己的, 才能删除
if (user != null && article != null && user.getId() == article.getUid()) {
return articleService.delete(articleId);
}
return null;
}
个人主页基本上就差不多了,但是右上角还有一个退出按钮,这里的逻辑代码都和之前的一样,直接复制过来就好了
10. 博客详情页
个人主页还有两个按钮没有实现:「修改」和「查看全文」
先实现「查看全文」,点开以后其实就是博客详情页
如下是博客详情页的结构
10.1 获取 URL 中的参数
回顾一下博客详情页是怎么进行跳转的?如下,其实就是一个拼接了文章 ID 的链接,而现在既要对左侧信息栏进行渲染,也要渲染右边的文章,就有了一个必要条件——需要获取 URL 中的 ID 发送给后端
 获取URL中指定的参数也不难,如下 js 代码,当我们传入一个 key 值,就可以获取这个 key 在 URL 中对应的 value 值
获取URL中指定的参数也不难,如下 js 代码,当我们传入一个 key 值,就可以获取这个 key 在 URL 中对应的 value 值
// 获取当前 url 中的某个参数
function getURLParam(key) {
var params = location.search;
if (params.indexOf("?") >= 0) { // 如果有查询字符串
params = params.substring(params.indexOf("?") + 1);
var ary = params.split("&"); // 获取 这个 url 中所有的键值对 数组
for (var i = 0; i < ary.length; i ++) {
var key_value = ary[i].split("="); // 获得键值对, key_value[0] 是键, key_value[1] 是值
if (key_value[0] == key) { // 如果找到了我们想要的 键
return key_value[1];
}
}
} else {
return "";
}
}
10.2 左侧作者信息
有了上述方法之后,就可以定义一个全局变量curId来接收当前页面的 文章 ID
var curId = getURLParam("id"); // 将当前页面的文章 id 赋值给全局变量 curId
接着就是处理左侧的用户信息,但是这里不一样了,刚刚是个人主页,显示自己的信息很正常,但是现在是博客详情页,显示该文章的作者相关信息会更加合理。但是前端的方法是一样的,我们稍作修改就可以正常使用了👇,然后约定路由是/user/userinfo
(注意这个页面的用户名和文章数的 div 加上 id)
// 然后当前文章作者的 个人信息 以及 个人创作总量
function getUserInfo() {
jQuery.ajax({
url:"/user/userinfo",
type:"GET",
data:{"articleId":curId}, // 发送该文章的 id
success:function(result) {
if (result.state == 200 && result.data != null) {
jQuery("#username").text(result.data.user.username); // 用户姓名
jQuery("#articleCount").text(result.data.articleCount); // 用户文章总数
} // 否则就是异常情况
}
});
}
getUserInfo();
后端就根据 文档 iD 获取用户对象,然后再获取用户对象返回给前端即可
/**
* 获取用户的左侧用户信息,以及已发布的文章总量
*/
@RequestMapping("/userinfo")
public Object getUserInfo(Integer articleId) {
// 数值无效
if (articleId == null || articleId <= 0) {
return null;
}
// 获取这个用户
Article article = articleService.getById(articleId);
if (article == null) {
return null;
}
// 在获取这个用户 对象
User user = userService.getById(article.getUid());
HashMap<String, Object> result = new HashMap<>();
result.put("user", user);
// 再获取这个 用户 的所有已经发布的文章
int sum = articleService.getArticleCountByUid(user.getId());
result.put("articleCount", sum);
return Result.succeed(result);
}
10.3 右侧文章详情
还是一样,在页面启动的时候就触发方法getArticleDetail,约定接口为/article/detail,后端返回一个 Article 对象,前端再依次对相应的标签进行操作:
//获取文章的详情页: 然后根据 url 中的参数向后端发送请求
function getArticleDetail() {
jQuery.ajax({
url:"/article/detail",
type:"GET",
data:{"articleId":curId},
success(result) {
if (result.state == 200 && result.data != null) { // 状态码正常, 并且后端返回的数据不为空
var title = jQuery("#title");
var date = jQuery("#date");
var content = jQuery("#editorDiv");
var rcount = jQuery("#rcount");
title.text(result.data.title);
rcount.text(result.data.rcount);
date.text(result.data.createtime);
// 写入的是 markdown 格式的文章, 这里需要特殊处理一下
editormd = editormd.markdownToHTML("editorDiv", {markdown : result.data.content, });
}
}
});
}
getArticleDetail(); // 调用这个方法, 显示出博客全文
后端的任务除了将这个文章返回之外,还有由于访问了这个文章详情,所以同时需要对这个文章阅读量 +1

但是
如果用户未登录,文章又是草稿箱状态,那么无权限访问
如果当前文章是草稿箱状态 并且 这个文章又不是自己的文章,还是没有权限访问。代码如下
@RequestMapping("/detail")
public Object detail(HttpServletRequest request, Integer articleId) {
if (articleId == null || articleId <= 0) {
return null;
}
User user = SessionUtil.getLoginUser(request);
// 获取这篇文章
Article article = articleService.getById(articleId);
// 如果没有这篇文章 或者 用户没登录并且文章是草稿箱状态 或者 文章是草稿箱状态并且文章不是自己的
if (article == null || (user == null && article.getState() == 2) ||
(article.getState() == 2 && article.getUid() != user.getId())) {
return null;
}
// 同时进行阅读量自增 1
articleService.rcountIncrease(articleId);
// 返回给前端的文章 阅读量也要更新
article.setRcount(article.getRcount() + 1);
return Result.succeed(article);
}
到这里,博客详情页基本就完成了,但是还有点细节
由于博客详情页是不需要登录状态也可以访问的,所以拦截器要为/article/detail和 /user/userinfo放行

11. 修改文章页
在个人主页中的每个文章的三个按钮,现在就只剩一个没完成了——修改
修改博客的实现其实和 编辑博客 很相似,我们可以直接将 「文章编辑页」 拷贝一份,重命名为「文章修改页」,然后修改一部分代码就行
 如上,修改页面的网址也就包含了 文章 ID,所以这里还需要用到获取 URL 参数的 js 方法,同样是拷贝一份,然后使用全局变量接收当前页面的 文章 ID
如上,修改页面的网址也就包含了 文章 ID,所以这里还需要用到获取 URL 参数的 js 方法,同样是拷贝一份,然后使用全局变量接收当前页面的 文章 ID
var curId = getURLParam("id"); // 将当前页面的文章 id 赋值给全局变量 curId
11.1 加载文章内容
由于是修改页面,所以进入这个页面的时候,就需要将这个文章的标题和内容载入该页面,定义这个方法为showArticle(),约定路由/article/show。并且这个页面也需要登录才可以使用,而拦截器也会拦截这个 /artilce/show这个请求来验证登录状态,所以下边这个方法就可以删掉
checkIsLogged(); (多余的)
在 Markdown 编译器中载入正文的实现:这个 Markdown 提供了一个方法
initEdit("# 在这里写下一篇博客"); // 初始化编译器的值
将这个方法删掉,然后放到showArtilce()中,将initEdit()的参数替换成正文就可以实现
前端代码如下
// 然后将这篇文章的标题和内容进入注入
function showArticle() {
jQuery.ajax({
url:"/article/show",
type:"GET",
data:{"articleId":curId},
success:function(result) {
if (result.state == 200 && result.data != null) {
jQuery("#title").val(result.data.title); // 将标题重新输入
initEdit(result.data.content); // 将文章正文再输入到 markdown 编译器中
} else if (result.state == -1) {
// 参数有误
alert("参数有误")
location.href = "/blog_list.html"; // 跳转到主页
}
},
error:function(error) {
// 这种情况就是被拦截器锁拦截了
if (error != null && error.status == 401) {
alert("用户未登录")
location.href = "/login.html"; // 跳转到登录页
}
}
});
}
showArticle();
后端代码,和之前的代码很相似,要进入修改页,必须文章是自己的才可以
@RequestMapping("/show")
public Object show(HttpServletRequest request, Integer articleId) {
if (articleId == null || articleId <= 0) {
return null;
}
// 获取会话用户
User user = SessionUtil.getLoginUser(request);
// 获取文章信息
Article article = articleService.getById(articleId);
// 如果文章查不到,或者用户没登录 或者 文章不是会话用户的文章
if (article == null || user == null || (user.getId() != article.getUid())) {
return Result.fail(-1);
}
return Result.succeed(article); // 返回
}
11.2 将文章保存为草稿
当点击 「保存为草稿」的按钮的时候,触发 js 中的方法,发送请求给后端,然后后端进行修改的文章有两种可能:
Ⅰ. 是本来就在草稿箱,现在继续写,写完再放草稿箱
Ⅱ. 另一种是这个文章已经发表了,但是由于某种原因,修改完后放入草稿箱
但是两种情况本质都是一样的,state 统一设置为 2 即可
这里可以约定接口为 /article/draft,但是细心的可以会发现这个路由前面已经使用过了,前面使用的时候是「将文章放置到草稿箱中」,并且传入的参数是
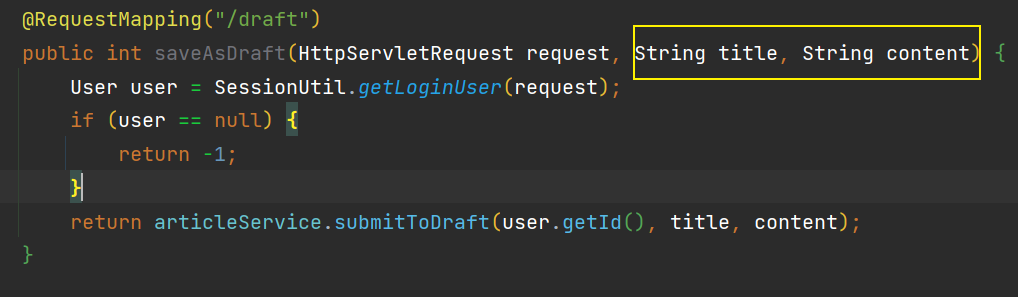 但是在这里,我们业务是修改文章,所以参数中会多一个
但是在这里,我们业务是修改文章,所以参数中会多一个 articleId⭐所以我们可以根据 articleId是否为空,来区分两种业务,就可以将两个业务合并到一起
前端代码:
// 保存为草稿项
function saveAsDraft() {
var title = jQuery("#title");
var content = editor.getValue();
if (title.val() == "" || title.length <= 0) {
alert("标题不能为空");
return false;
}
if (content == "" || content.length < 100) {
alert("文章内容不能少于100字");
return false;
}
jQuery.ajax({
url:"/article/draft",
type:"POST",
data: {
"title":title.val(),
"content":content,
"articleId":curId
},
success(result) {
if (result.state == 200 && result.data == 1) {
alert("成功保存到草稿箱");
location.href = "myblog_list.html";
} else {
alert("账号未登录或者参数有误");
}
}
});
}
在 xml 文件中更新文章的 sql 语句:

ArticleContoller的代码
/**
* 实现: 将文章保存到草稿箱中
* 相当于普通的插入文章, 但是 state = 2
* 前端返回两个参数: title, content
* @return 返回受影响的行数
*/
@RequestMapping("/draft")
public int saveAsDraft(HttpServletRequest request, Integer articleId, String title, String content) {
User user = SessionUtil.getLoginUser(request);
if (user == null) {
return -1;
}
// 存在 articlaId 说明是 修改文章并存入草稿箱
if (articleId != null) {
// 获取这篇文章
Article article = articleService.getById(articleId);
// 不存在这篇文章, 或者 文章作者 不是 会话用户
if (article == null || article.getUid() != user.getId()) {
return -1;
}
return articleService.updateToDraft(user.getId(), articleId, title, content);
}
// 否则就是 新增文章到草稿箱中
return articleService.submitToDraft(user.getId(), title, content);
}
11.3 修改后发表
这个逻辑就很容易实现了,无非就是更新文章的发布状态为 1,约定路由为/article/update
// 提交
function mysub(){
var title = jQuery("#title");
var content = editor.getValue();
if (title.val() == "" || title.length <= 0) {
alert("标题不能为空");
title.focus();
return false;
}
if (content == "" || content.length < 100) {
alert("文章正文字数需要超过100个字");
return false;
}
// 发送请求给后端
jQuery.ajax({
url:"/article/update",
type:"POST",
data: {
"articleId":curId,
"title":title.val(),
"content":content
},
success:function(result) {
if (result.state == 200 && result.data != null && result.data > 0) { // 后端返回的是受影响的行数
alert("修改成功");
// 跳转到 "我的主页"
location.href = "myblog_list.html";
} else {
alert("修改失败");
}
},
error:function(result) {
if (result.state == 401) {
alert("请先登录账号");
location.href = "login.html";
}
}
});
}
这里的后端代码和前面也是很相似了:
@RequestMapping("/update")
public Integer update(HttpServletRequest request, Integer articleId, String title, String content) {
User user = SessionUtil.getLoginUser(request);
if (user == null) {
return null;
}
Article article = articleService.getById(articleId);
// 文章不存在 或者 文章不是登录用户的
if (article == null || article.getUid() != user.getId()) {
return null;
}
return articleService.update(user.getId(), articleId, title, content);
}
12. 博客主页
首页这个页面用于就是展示所有用户的文章,如下并且有分页的按钮,也就是按照用户的页面展示该部分的文章,首先说以下这个分页:

12.1 分页
这个功能需要两个关键属性——第几页pageIndex,以及一页最多显示最少篇文章pageSize,为了测试方便和简单考虑,🍓此处将 一页最大文章数设置为 2
此外,pageIndex和 pageSize 这两个信息可以放在 URL 上,然后这个页面在加载的时候就可以根据 URL 上的这两个参数向后端发送请求,后端返回指定范围的文章交给前端渲染。并且如果 URL 上没有这两个信息,那么就默认是第一页
12.2 前端
首先定义两个全局变量,pageIndex 和 pageSize ,然后定义一个方法init在页面加载的时候完成以下工作:
Ⅰ. 从 URL 上获取参数并为 pageIndex 和 pageSize 赋值(别忘了拷贝 获取URL中参数 的方法)
Ⅱ. 发送请求给后端,约定路由是/article/all,接收到数据后展示给用户
接收到数据后,每一篇文章都是① id="blogs的 div 的子元素,并且按照②的格式来为组织每一个文章,将组织好的每一篇文章加到①这个大 div 中
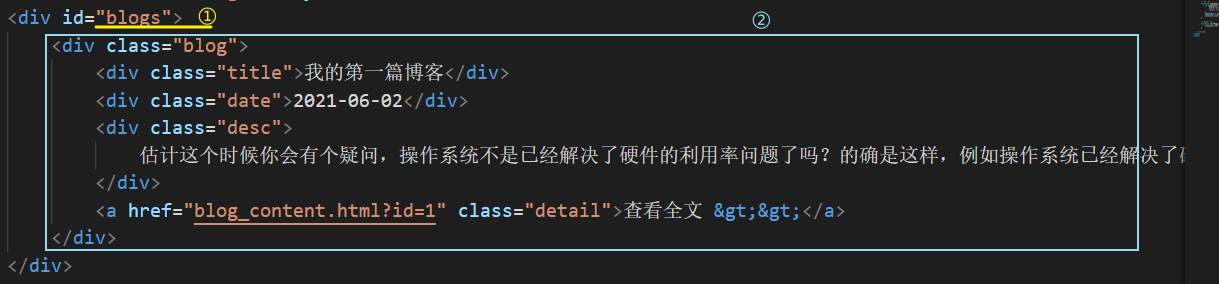 并且这里是展示所有的文章,展示的部分仍要是摘要,取文章的前 100 个字符
并且这里是展示所有的文章,展示的部分仍要是摘要,取文章的前 100 个字符
js 代码如下
var pageIndex; // 当前页面的索引, 第几页
var pageSize; // 当前页面最多可以显示多少篇文章
// 每次进入这个页面都要加载当前页面的效果
// 获取当前页面的 pageIndex 和 pageSize , 传递给前端, 并渲染
function init() {
var temp = getURLParam("pageIndex");
if (temp != null && temp > 0) { // "第几页"为有效值
pageIndex = temp;
} else { // 如果没有页数, 那么默认为首页
pageIndex = 1; // 默认为第一页
}
temp = getURLParam("pageSize");
if (temp != null && temp > 0) { // "最多显示多少片文章为有效值"
pageSize = temp;
} else { // 如果没有参数, 那么默认一页显示 2 篇文章
pageSize = 2;
}
jQuery.ajax({
url:"/article/all",
type:"GET",
data:{
"pageIndex":pageIndex,
"pageSize":pageSize
},
success:function(result) {
if (result.state == 200 && result.data != null && result.data.length > 0) { // 返回的数据是有效值
// 对 id 为 blogs 的标签进行拼接
var finalResult = "";
for (var i = 0; i < result.data.length; i ++) {
var cur = result.data[i]; // 当前文章
finalResult += '<div class="blog">';
finalResult += '<div class="title">' + cur.title +'</div>';
finalResult += '<div class="date">' + cur.createtime +'</div>';
finalResult += '<div style="margin-top: 10px; text-align: center;">访问量: ' + cur.rcount + '</div>';
finalResult += '<div class="desc">' + getBeginning(cur.content);
finalResult += '</div>';
finalResult += '<a href="blog_content.html?id='+ cur.id + '" class="detail">查看全文 >></a>';
finalResult += '</div>';
}
jQuery("#blogs").html(finalResult);
} else if (result.state == 200) { // 后端返回空,说明参数有误
alert("参数有误!");
// 跳转至首页
location.href = "blog_list.html";
}
}
});
}
init();
12.3 后端
而后端怎么显示所需要的部分?
可以使用 limit...offset...语句,从…开始返回…条数据(offset 表示要跳过的数量),返回 pageSize条数据,这个很明显,不多说。而从哪里开始,这个是有规律的,假设 pageSize = 5,那么要显示第3页的数据,显然就是跳过前两页的文章数(2 * pageSize),接着显示 5 条数据
⭐所以规律就是 limit pageSize offset (pageIndex - 1) * pageSize
但是在 MyBatis 中不能直接这么写,需要将计算结果传进入。并且还有个细节,只能显示已发表的文章(state = 1)
ArticleMapper.xml 中:
 后端代码:
后端代码:
@RequestMapping("/all")
public List<Article> getPage(Integer pageIndex, Integer pageSize) {
if (pageSize == null || pageIndex == null || pageIndex <= 0 || pageSize <= 0) {
return null;
}
// 提交计算 offset
int offset = (pageIndex - 1) * pageSize;
return articleService.getPage(pageSize, offset);
}
12.4 实现剩下四个按钮
首先先为这四个按钮,添加能够触发 js 方法的功能

这四个按钮实现起来也不难:
⭐Ⅰ. 首页
这个实现起来最简单,没啥好说的
// 首页
function firstPage() {
location.href = "blog_list.html?pageIndex=1&pageSize=" + pageSize; // 默认跳到第一页
}
⭐Ⅱ. 上一页
这个也简单,特殊判断以下是不是第一页,如果是,那就刷新一下
// 上一页
function pageUp() {
if (pageIndex == 1) {
location.href = "blog_list.html?pageSize=" + pageSize; // 相当于刷新一次
return true;
}
pageIndex = parseInt(pageIndex) - 1;
location.href = "blog_list.html?pageIndex=" + pageIndex + "&pageSize=" + pageSize;
}
⭐Ⅲ. 下一页
实现这个功能就需要我们知道最后一页的页码是多少,向后端发送请求,然后后端直接将计算结果返回,前端使用一个全局变量finalIndex接收,并且也在页面加载的时候就构造好(约定路由/article/final)。所以直接放在上述的init()方法之后就可以了,在init()构造好页面的时候获取 finalIndex
init();
// 获取最后一页的页码
function getFinalIndex() {
jQuery.ajax({
url:"/article/final",
type:"GET",
data: {
"pageSize":pageSize
},
success: function(result) {
if (result.state == 200 && result.data != null) {
// 赋值 最后一页的 页码
finalIndex = result.data;
return true;
}
}
});
}
getFinalIndex();
后端要计算这个值也非常简单,只需要统计一下所有已发表文章的个数,然后除以 pageSize,向上取整即可。
🍓向上取整可以使用Math.ceil(double) ,但是不推荐,可以会有精度问题,存在潜在隐患,可以结合数学思想,使用
(
a
−
1
)
/
b
+
1
(a - 1)/b + 1
(a−1)/b+1(分母是 b,不是 b + 1)
代码如下
// 获取最后一页的页码
@RequestMapping("/final")
public Integer getFinalPage(Integer pageSize) {
if (pageSize == null || pageSize <= 0) {
return null;
}
Integer total = articleService.getCount(); // 获取文章总个数
int result = (total - 1) / pageSize + 1;
return result;
}
有了最后一页的页码后,这就好实现了,特殊判断现在是不是最后一页
function pageDown() {
if (pageIndex == finalIndex) { // 如果已经是最后一页了
alert("已经是最后一页了");
return true;
}
pageIndex = parseInt(pageIndex) + 1; // 下一页
location.href = "blog_list.html?pageIndex=" + pageIndex + "&pageSize=" + pageSize;
}
⭐Ⅳ. 末页
直接跳最后一页
// 最后一页
function lastPage() {
location.href = "blog_list.html?pageIndex=" + finalIndex + "&pageSize=" + pageSize;
}
并且博客主页,以及申请获取最后一页的请求都是非登录状态下也能完成的,所以拦截器需要为这两个接口放行:
.excludePathPatterns("/article/all")
.excludePathPatterns("/article/final");
13. 密码加盐加密
用户注册的时候,将用户名和密码存入数据库的时候是采用明文存储的,这就伴随着安全隐患,后果不必多说
使用传统的 MD5 加密,虽然加密之后是不可逆的,但是还有个缺陷,一个字符串固定会被转化成一个 32 位的字符串,也就存在暴力破解的可能
但是不可否定的是,MD5是一个不错的工具,我们可以使用加盐算法搭配 MD5 进行加密,具体点,生成一个随机不重复的盐值(salt)和真正的密码进行拼接,再对这个结果使用 MD5 加密,然后将这个值存入数据库中,即便数据库被盗也会因为盐值的干扰从而保护密码
⭐用代码表示比较好理解: MD5(salt + password)(为了方便陈述,记这个结果为 P,它是长度32位的字符串)
但是上述方法还有点问题,如果只是将MD5(salt + password)存入数据库的话,用户登录的时候,我们无法验证密码是否正确,因为加密后不可逆,盐值也无法获取。所以 P 还不能是最终的密码,我们需要知道盐值才能验证登录,⭐所以我们可以:「以内部某种约定好的格式」来将盐值和 P 进行拼接,来作为 最终存入数据库中的结果。
例如:为了方便描述,我们称 最终存入数据库中的密码为:Final
假设我们生成的盐值也是 32 位的,⭐那么可以约定:Final = 盐值 + P,也就是前面 32 位是盐值,后面 32 位是 P
这样做的好处就是可以验证用户登录:可以按照这个规则获取到 盐值,然后将 盐值和「待验证的密码」进行拼接后 MD5 加密(也就是MD5(salt + toProvePassword)),然后拿着这个结果和 Final 的后 32 位(即 P)进行比较即可。(同样的字符串,MD5加密后的结果完全一致,所以通过同样的盐值加密后的结果如果一样,也就验证通过了)
🍓但是如果别人知道了规律,也就可以获取盐值,可这样密码破解的成本也是很大的
假设坏人获得了盐值,知道了规则,需要从 MD5(salt + password)中来获取密码,就需要根据这个盐值来单独生成一个彩虹表进行破解,并且只能破解一个密码,下一个密码又要重新生成彩虹表,而彩虹表的生成是一个费时又费力的事,有多费力,可以参考这篇博客
13.1 加盐加密
有了思路,实现就可以拿捏了
首先,盐值的获取可以用过 String salt = UUID.randomUUID().toString();来随机获取一个盐值字符串,如下
 但是这个盐值有一点特征,就是
但是这个盐值有一点特征,就是 '-' 这个 字符,所以可以「去掉这个特征」,通过replace("-", "")。
这样就可以得到一个刚好长度是 32 的没有规律的盐值,然后salt + md5(salt + password)作为最终密码存入数据库(长度 64)。
MD5 加密的使用方法如下

代码如下
public class Security {
// 对数据的加密
public static String encrypt(String password) {
// 数据无效
if (!StringUtils.hasLength(password)) {
return null;
}
// 得到盐值的字符串, 并且将其 格式 进行消除, 最终 salt.length = 32
String salt = UUID.randomUUID().toString().replace("-", "");
// salt + password 进行加密后 就可以得到 「临时的最终密码」
// 但是为了验证, 我们需要知道盐值, 于是将盐值 和 上者 按照某种规则进行拼接,
String finalPassword = salt + DigestUtils.md5DigestAsHex((salt + password).getBytes());
return finalPassword;
}
}
13.2 验证
用户将密码传入,我们获取该用户密码对应的密文,然后通过自定义的规则(此处是前32位是盐值)获取密文中的盐值,然后按同样的加密规则将「salt + 待验证密码」进行 md5 加密,判断和密文中后 32 位是否一致即可验证,代码如下
/**
* 验证 密码 是否正确
* @param toProvePassword 等待验证的密码
* @param finalPassword 数据库中的密码(密文)
* @return
*/
public static boolean prove(String toProvePassword, String finalPassword) {
if (!StringUtils.hasLength(toProvePassword) || !StringUtils.hasLength(finalPassword)
|| finalPassword.length() != 64) {
return false;
}
// 获取盐值
String salt = finalPassword.substring(0, 32);
// 按照同样的规律
toProvePassword = salt + DigestUtils.md5DigestAsHex((salt + toProvePassword).getBytes());
return toProvePassword.equals(finalPassword); // 返回是否一致
}
13.3 更新
然后把注册的逻辑和登录的逻辑更新一下:
注册逻辑更新:
// 新增(注册)一个用户
String finalPassword = Security.encrypt(password);
int result = userService.add(username, finalPassword);
登录逻辑更新:
// 获取该用户在数据库中的信息
User user = userService.selectByUsername(username);
if (user == null) {
return 0;
}
// 获取数据库中的密文
String finalPassword = user.getPassword();
boolean isCorrect = Security.prove(password, finalPassword); // password 是用户输入的密码
14. Session 持久化
目前会话是存储在内存中,重启服务器或者服务器断电之后会话就无了,为了提高用户的体验,可以将 Session 进行持久化存储,存于 MySQL 也行,但是不如存在 Redis 中。
注意:这里涉及到了云服务上 Redis 的安装以及远程连接的问题,需要自行配置 Redis 以及开放端口。
会话是一个很常用的功能,所以在 SpringBoot 项目中,只要正确导入依赖和配置 Redis 了,其他代码基本没变,只需要加一个小改动,在存 Session 的时候,就会自动持久化到 Redis 中
首先这个玩意是肯定要导入的
然后有两个依赖不能少(主要是看第二个依赖有没有少):
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
最后就是配置 远程连接云服务器上的 Redis 相关信息,代码如下,🍓并且是 yml 格式的配置文件
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/name?characterEncoding=utf8
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
# 配置 Redis 填写自己相关的信息 --
redis:
host: IP
post: 端口
password: 密码
session:
store-type: redis
redis:
flush-mode: on_save
namespace: spring:session
server:
servlet:
session:
timeout: 1800
# 配置 Redis --
由于是将用户数据存入到 Redis,涉及到了对象的网络传输,所以需要对象需要实现序列化接口
public class User implements Serializable { // java.io 包中的序列化接口
至此就完成了 Session 持久化,如下,在登录一次后,重启服务器,还是存在相关的会话:

15. 实现定时发布功能
这个功能实现起来比较复杂
15.1 逻辑
在项目启动的同时启动一个线程,这个线程专门负责扫描是否存在可以发布的文章
Ⅰ. 创建一个存储定时文章的数据库表格,并且预期:该表中的文章理论上应该都是还没有发布的,并且发布后的文章,就需要从这个表中删除。但是为了数据安全性和效率着想,使用伪删除的方式:其中定义一个字段isdel,0 表示没删除,1 表示已经删除
Ⅱ. 这个线程在一开始,就扫描这个表格中所有还没有发布的文章(id = 0),并且存入堆中(这个步骤只有在项目启动的时候执行一次)
Ⅲ. 堆是一个小根堆,按照文章的发布时间的 [ 时间戳 ] 进行排序
Ⅳ. 每隔一段时间,就对这个堆进行扫描,如果堆顶元素的时间戳比当前时间戳要大,那就还不需要发布;如果堆顶元素的时间戳比当前时间戳小,那就发布该文章,然后将定时任务表中的文章删除(伪删除)
Ⅴ. 后端提供一个接口,来为服务器运行过程中提供添加定时任务的服务
Ⅵ. 而后续服务器运行过程中所加入的定时任务,不仅要写入到定时任务表中,还要再加入到内存中的堆即可
15.2 建表
drop table if exists scheduledtasks;
create table scheduledtasks(
id int primary key auto_increment,
title varchar(100) not null,
content text not null,
publishtime datetime default now(),
uid int not null,
isdel int default 0
)default charset 'utf8mb4';
有了这个表,还需要再创建一个相应的 Java 实体类
// 定时文章 实体类
@Data
public class ScheduledTask {
private int id;
private String title;
private String content;
private int uid;
private String publishtime; // 文章定时发表时间
private int isdel; // 表示是否被删除,属性名和数据库字段名保持一致
public ScheduledTask() {}
public ScheduledTask(String title, String content, int uid, String publishtime) {
this.title = title;
this.content = content;
this.uid = uid;
this.publishtime = publishtime;
}
}
15.3 后端实现
15.3.1 时间戳问题
首先约定一个发布时间的格式:yyyy-MM-dd HH:mm:ss
然后需要将这个格式的数据转化成时间戳,在 Java 中的实现方式如下(参考博客Java 日期和时间戳互转)
public class Tool {
public static Long dateToStamp(String s) throws ParseException {
String res;
SimpleDateFormat simpleDateFormat = new SimpleDateFormat( "yyyy-MM-dd HH:mm:ss" );
Date date = simpleDateFormat.parse(s);
long ts = date.getTime();
return ts;
}
}
15.3.2 构造方法与小根堆
刚刚在实现逻辑说到在项目启动的时候启动一个线程,那这个时机可以是:一个类的构造方法中
创建一个类ScheduledTaskController,这个类负责定时发布文章的业务。并且加上@RestController 注解,让 Spring 启动的时候也加载这个类,然后在构造方法中启动线程即可。
在这个线程中,需要对 [ 到达指定时间点 ] 的文章进行发布 和 [ 伪删除 ] 定时文章,所以在构造方法中需要 articleService 和 scheduledTaskService 这两个对象,但是由于注入时机的问题,这两个对象需要使用构造方法注入,不建议使用属性注入
小根堆按照时间戳进行构造,构造方法前部分代码如下:
@Autowired
public ScheduledTaskController(ScheduledTaskService scheduledTaskService, ArticleService articleService) {
// 注入
this.scheduledTaskService = scheduledTaskService;
this.articleService = articleService;
// 创建一个 小根堆
this.heap = new PriorityQueue<>((ScheduledTask x, ScheduledTask y) -> {
try {
return (int) (Tool.dateToStamp(x.getPublishtime()) - Tool.dateToStamp(y.getPublishtime()));
} catch (ParseException e) {
throw new RuntimeException(e);
}
});
15.3.3 启动线程
线程启动后,先将所有还没发布的文章载入到内存中(这个行为只会执行一次),然后开始进入死循环,每一次循环都要判断是否有可以发布的任务,然后睡眠一段时间(这里设定为 30 s一轮)
⭐还需要注意,这个线程会持续判断定时任务的发布,所以会持续扫描堆的状态,并且可能将堆中的元素弹出。而实现逻辑处说到:还需要为前端提供一个接口提供后续的定时文章发布服务,要往 定时任务表 中以及 堆中添加元素,也就是可能存在两个线程同时操作 heap,这就涉及到了线程安全问题,所以需要在合适的地方加锁,锁对象在常量池中创建一个 Object 对象就行
紧接上述代码,后续启动线程的代码如下:
// 启动一个线程
new Thread() {
@SneakyThrows
@Override
public void run() {
// 初始化 小根堆
// 读取出所有的 未发表文章,并载入
List<ScheduledTask> scheduledTasks = scheduledTaskService.getAll();
for (ScheduledTask task : scheduledTasks) {
heap.offer(task);
}
// 然后开始循环判断是否有符合条件的
while (true) {
// 获取当前时间戳
long curMills = System.currentTimeMillis();
while (!heap.isEmpty()) {
ScheduledTask task ;
synchronized (Constants.scheduledLock) {
task = heap.peek();
}
// 获取堆顶任务的 时间戳
long taskMills = Tool.dateToStamp(task.getPublishtime());
if (curMills < taskMills) { // 还早,不能发
break;
} else { // 可以发
synchronized (Constants.scheduledLock) {
heap.poll(); // 弹出这个任务
}
// 将这个文章发表出去,然后使用伪删除的方式 删除 定时任务表 中的记录
articleService.submit(task.getUid(), task.getTitle(), task.getContent());
System.out.println("成功发布文章");
// 伪删除
scheduledTaskService.delete(task.getId());
System.out.println("伪删除成功");
}
}
// 睡眠 30 秒
Thread.sleep(30000);
System.out.println("进入睡眠");
}
}
}.start();
15.3.4 运行过程中添加定时发布的文章
约定一个路由/schedule/add ,前端需要发送指定格式的时间日期 yyyy-MM-dd HH:mm:ss,然后构造成一个 ScheduledTask 对象,加入数据库中,加入内存堆中。
这里还有个细节:在时间到了之后发布的文章,需要在 定时文章表 中进行伪删除,而伪删除需要知道文章的 id。因此这里加入到内存堆中之前,就需要为 ScheduledTask 对象提前设定好 id。
这里可以在插入到定时任务表的时候设置自增主键的获取,可以实现在插入表中之后,这个对象的 ID 就会被自动赋值。xml 文件中的插入代码以及 Controller 代码如下

// 往数据库中添加定时任务,然后再往内存中的堆添加元素
@RequestMapping("/add")
public Integer add(HttpServletRequest request, String title, String content, String publishTime) {
User user = SessionUtil.getLoginUser(request);
if (user == null) {
return null;
}
// 构造一个定时任务
ScheduledTask task = new ScheduledTask(title, content, user.getId(), publishTime);
// 先存入数据库中, 同时会设置 自增主键
scheduledTaskService.add(task);
// 然后再存入堆中
synchronized (Constants.scheduledLock) {
this.heap.offer(task);
System.out.println("成功添加一个任务");
}
return 1;
}
}
15.3.5 前端部分
然后后端代码就完成了,然后是前端代码

当点击这个按钮的时候,触发 schedule 方法, 然后通过以下方法触发一个弹窗,然后让用户输入时间
var date = prompt("请输入日期", "请按指定格式填写日期 yyyy-MM-dd HH:mm:ss");
并且要验证一下是不是指定格式的日期,可以通过正则表达式判断
// 验证一下格式是否正确
var reg = /^((\d{2}(([02468][048])|([13579][26]))[\-\/\s]?((((0?[13578])|(1[02]))[\-\/\s]?((0?[1-9])|([1-2][0-9])|(3[01])))|(((0?[469])|(11))[\-\/\s]?((0?[1-9])|([1-2][0-9])|(30)))|(0?2[\-\/\s]?((0?[1-9])|([1-2][0-9])))))|(\d{2}(([02468][1235679])|([13579][01345789]))[\-\/\s]?((((0?[13578])|(1[02]))[\-\/\s]?((0?[1-9])|([1-2][0-9])|(3[01])))|(((0?[469])|(11))[\-\/\s]?((0?[1-9])|([1-2][0-9])|(30)))|(0?2[\-\/\s]?((0?[1-9])|(1[0-9])|(2[0-8]))))))(\s((([0-1][0-9])|(2?[0-3]))\:([0-5]?[0-9])((\s)|(\:([0-5]?[0-9])))))?$/;
// 验证是否是指定格式的日期
var flg = reg.test(date);
// 日志不复合规范
if (flg == false) {
alert("日期格式有误,请重新填写");
return false;
}
有了这个格式的日期之后,就可以将这个时间作为参数构造出 Date 对象,并且可以通过这个对象的 getTime()获取时间戳,也可以通过 toLocaleString() 来获取 yyyy/MM/dd HH:mm:ss 的日期。这个格式的日期再通过字符串替换,将 / 替换成 - 就行了
这里可以要求用户的文章至少在当前时间 + 5 分钟后发表,详细见前端代码,如下:
// 定时发布功能
function schedule() {
// 验证数据的有效性
var title = jQuery("#title");
var content = editor.getValue();
if (title.val() == "" || title.length <= 0) {
alert("标题不能为空");
return false;
}
if (content == "" || content.length < 100) {
alert("文章内容不能少于100字");
return false;
}
// 开始定时发布的流程
var date = prompt("请输入您的名字", "请按指定格式填写日期 yyyy-MM-dd HH:mm:ss");
// 验证一下格式是否正确
var reg = /^((\d{2}(([02468][048])|([13579][26]))[\-\/\s]?((((0?[13578])|(1[02]))[\-\/\s]?((0?[1-9])|([1-2][0-9])|(3[01])))|(((0?[469])|(11))[\-\/\s]?((0?[1-9])|([1-2][0-9])|(30)))|(0?2[\-\/\s]?((0?[1-9])|([1-2][0-9])))))|(\d{2}(([02468][1235679])|([13579][01345789]))[\-\/\s]?((((0?[13578])|(1[02]))[\-\/\s]?((0?[1-9])|([1-2][0-9])|(3[01])))|(((0?[469])|(11))[\-\/\s]?((0?[1-9])|([1-2][0-9])|(30)))|(0?2[\-\/\s]?((0?[1-9])|(1[0-9])|(2[0-8]))))))(\s((([0-1][0-9])|(2?[0-3]))\:([0-5]?[0-9])((\s)|(\:([0-5]?[0-9])))))?$/;
// 验证是否是指定格式的日期
var flg = reg.test(date);
// 日志不复合规范
if (flg == false) {
alert("日期格式有误,请重新填写");
return false;
}
var curTime = new Date();
// 加上 4 分钟,后的 dateTime
curTime.setMinutes(curTime.getMinutes() + 4);
// 发布时间 的 DateTime
var publishTime = new Date(date);
// 该 else 语句用于测试, 提交成功,那么展示一下时间
// 具体的 目标 发送日期+时间
var tar = publishTime.toLocaleString();
tar = tar.replace("/", "-"); // 替换成指定格式
tar = tar.replace("/", "-");
console.log(tar);
// 获取两个时间段的时间戳
var curMills = curTime.getTime();
var publishMills = publishTime.getTime();
if (curMills >= publishMills) {
alert("发布时间至少在 5 分钟后发布");
return false;
}
// 否则成功发布
jQuery.ajax({
url:"/schedule/add",
type:"POST",
data: {
"title":title.val(),
"content":content,
"publishTime":tar
},
success:function(result) {
if (result.state == 200 && result.data != null && result.data == 1) {
alert("定时发布成功");
location.href = "myblog_list.html";
}
}
});
}
这个定时发布功能就完成了,这里采用的是使用 堆 来进行维护。但是实际上堆这部分代码可以使用 Java 内置的定时器 Timer 来完成,思路是类似的,代码量会少点。想学习 Timer 的使用,可以看看这篇文章Timer
16. 全代码
完结