顺应“十四五”规划中关于“加快金融机构数字化转型”要求,中国人民银行印发了《金融科技发展规划(2022-2025年)》。近几年来,金融行业牢牢占据着国内产业数字化转型市场投入的榜首位置。IDC调查显示,2022上半年,中国金融云市场规模达到34.3亿美元,同比增长29.3%。
光大银行在数字化转型过程中积极应用云原生技术对业务系统进行了升级改造,大幅提升了底层技术平台对上层业务的支撑能力,不过伴随而来的全新的运维体系建设难题的解决也变得迫在眉睫。借助博睿数据在云原生复杂环境下的可观测性能力的突破,光大银行不仅实现了传统的全栈式数据采集与监测,同时通过多级融合方式将复杂的调用链与指标及日志数据进行了融合,进而实现了高效的数据分析能力,以及以AI为主的智能根因定位能力。最终,该方案不仅解决了客户现有运维体系改造建设的难题,其技术的前瞻性应用也让对应的案例发表在了中国人民银行主管的《金融电子化》杂志上。
以下为原文,共计4024字,预计阅读时间9min。
随着数字化转型的逐步深入,如何在保障业务稳定运行的同时,又能够快速高效地满足不断变化的业务需要,是银行行业IT支撑部门亟待解决的一个难题。当前,通过云原生等先进技术建设“数字化中台”,进一步提升对业务的快速支撑,推动业务技术深度融合,构建金融科技赋能业务的综合战略决策体系,已成为银行业IT技术的重要指引方向。云原生环境具有如下特点:
1、不可变基础设施
以镜像、容器为基础,通过编排系统下载更新镜像、只更新镜像不改变容器运行时等方式,构建基于容器化封装的云原生体系,确保基础实施的一致性与可靠性,从而实现“一次构建,到处运行”的能力。
2、弹性的服务编排
通过集中式的编排调度系统实现对计算、存储、网络等资源的自动化统一调度,构建业务的集群管理能力,提供负载均衡、资源自动调度、动态扩缩容、自动修复等能力。
3、微服务架构
在云原生应用设计中,通常采用微服务设计,传统单体应用的功能被拆解成大量独立、细粒度的分布式服务,实现服务的相互解耦。通过应用编排调度组装,进而实现等价于传统的单体应用,但却更加灵活、易于维护。
4、可管理性和可观测性
除了优点之外,云原生环境也存在应用调度可视化复杂,难以快速定位故障等困难。因容器漂移、自动扩缩容等特性,应用的调用关系通常难以清晰展示与分析,故障现场难以还原,为业务系统运维及故障排查带来了极大的挑战,因此需要有专业组件或工具提升监控管理能力。
光大银行十分重视金融科技创新工作,在各级工作会议中,集团与银行领导多次提到“要坚持把科技创新摆在发展全局的重要位置”,“要以科技创新为驱动,加速推进数字化转型”。光大银行金融科技部坚持贯彻科技引领的战略目标,以科技创新为驱动,打造自主可控的光大技术中台,并完成了全栈云平台建设,全面支持云原生技术,并遵循CNCF(云原生计算基金会)OpenTelemetry理念,构建全面的Trace(调用链)、Metric(指标)、Log(日志)数据分析维度,全面提升云原生环境下的可观测性,并融合稳态/敏态运维管理体系,为行内数字化转型战略护航,实现由大型主机运维向分布式架构运维的转型。
光大“全栈云”监控背景

图1:全栈云架构示意图

图2:运维监控体系架构图
光大银行通过开发测试云、生产云、金融生态云三朵云的全栈云体系建设,全面支持业务的敏捷开发、持续交付和稳定运行,技术栈全面兼容X86架构与国产化ARM架构,全面支持混合云架构,提供两地三中心及异地多活能力,逐步推进行内应用云原生改造步伐,实现以云原生应用为主,传统应用为辅的全栈云技术支撑体系,如图1所示。与此同时,光大还构建了完整的云原生监控体系,实现了从基础架构监控(ITIM)、到应用性能监控(APM)、网络性能监控(NPM)以及用户体验监控(DEM)的全链路监控体系,全面监控云原生环境以及稳态系统中业务运行的稳定性,如图2所示。
云原生应用监控实践
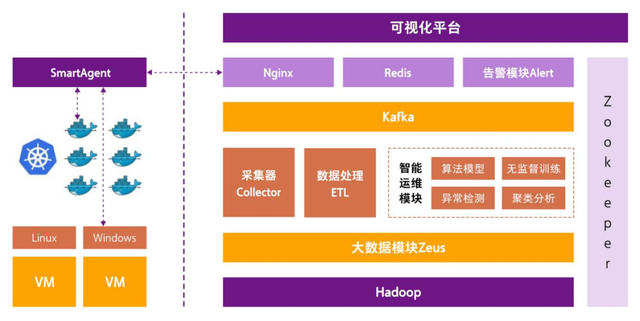
图3:APM技术架构图
光大银行在全栈云平台构建应用性能监控(APM)解决方案,通过智能探针技术(SmartAgent),实现对平台应用系统的自动安装与监控。探针监控使用字节码等相关技术,无需对程序代码进行修改,即可实现对应用程序的执行过程进行全面监控与追踪。APM平台服务端采用大数据处理架构,主要技术框架如图3所示。
通过APM产品中全栈(Full-Stack)探针的能力和平台的数据分析能力,实现了应用性能评分体系、调用链路追踪、代码级故障定位以及指标/日志关联分析等能力。
一、应用评分体系
通过对应用性能体验相关指标的综合评分,构建应用评分体系。评分体系通过对应用的Apdex评价、响应速度及错误率作为评价依据,通过100分制的权重计算,得出应用系统的性能评分。
Apdex为Application Performance Index的缩写,是Apdex 联盟开放的用于评估应用性能的工业标准,通过应用响应时间评估用户满意程度,并量化为0~1的满意度评价(数值越趋近于1代表用户越满意,应用的最终评分也就越高)。

响应速度为该应用业务请求的平均响应速度,响应速度越快,评分越高。
错误率是指应用调用过程中出现各类错误样本占总样本数的比率。错误包含常见的网络错误、程序执行报错、数据库错误等,这些错误都有可能会影响到用户使用业务的效果及性能体验。因此,错误率越低,最终评分越高。
通过掌握应用系统的横向评分对比以及历史得分参考,通过评分快速掌握当前应用系统的总体运行状况,由原来对应用运行好坏的主观评价,变为量化评估。
二、调用链路追踪
通过TraceID自动写入技术,实现对应用从程序入口到执行全链路进行监控与追踪,自动绘制程序调用拓扑。APM探针在应用调用的入口方法的Header中,自动注入唯一的TraceID及调用层级,随着应用的不断调用,将TraceID在不同调用的Header中进行传递,并记录每一个调用层级数据,通过探针将上述数据及性能监控数据进行回传,基于有向无环图(DAG)的原理,构建应用的调用链追踪拓扑。
在同步中,基于应用性能好坏,通过不同颜色标注,绿色表示优秀/正常,黄色表示缓慢,使用红色的圆环表示错误率的占比。从而直观发现应用性能问题,提升云原生环境下的可观测性,实现应用故障的快速定位及影响范围分析。
三、代码级故障定位
通过字节码、自研SuperTrace等技术,实现对应用程序在内存执行过程的全面监控。
以Java应用举例,字节码技术是指当被监控对象的类加载时,通过java.lang.instrument包提供的字节码增强技术,对所加载类进行动态修改,以获取各个方法执行开始时间、结束时间、返回状态等相关数据,可实现对常见数据库调用、消息中间件调用、远程RPC调用以及自定义方法调用等各种程序执行过程的全面监控,从而掌握应用程序缓慢根因,快速定位应用故障或缓慢是由哪个或者Class(类)、Method(方法)的问题所导致的,并可定位到故障/问题所在代码行号。
自研的SuperTrace技术则是通过JDK所提供的JVM监控技术,对内存堆栈中各方法的入栈、出栈时间进行实时扫描,并通过出入栈时间和各个方法相互访问调用关系,通过本地Agent进行数据上报。为节约探针端内存扫描的资源开销,探针会从服务端获取数据采集策略。平台可配置数据采集的触发阈值,只有当方法执行时间≥100ms时,才会对相关方法的明细数据进行采集,从而大幅降低了JVM扫描频次和系统资源占用。
上述相关方式抓取到的数据,支持以单次请求(以TraceID为唯一标识)维度进行查看,以快照形式进行存储与展示,在平台以程序调用瀑布图的方式进行展示,可以直观发现慢请求的发生位置以及各个方法的调用次序。
四、关联分析能力
通过将故障发生时的基础架构相关指标,如CPU、内存、JVM等数据进行联动分析,快速定位故障成因是基础设施资源问题导致还是程序本身问题导致。
当前探针在采集APM应用性能相关数据的同时,还会通过JNI接口(Java native interface,Java本地接口)中的相关API,同步获取操作系统的底层数据信息,如CPU、内存、磁盘IO、网络流量开销、系统IO、进程数据、内存数据等一系列基础架构监控的指标数据。
再通过基于事件、时间戳和节点信息的关联分析,将APM数据与基础架构指标数据进行联动,同步分析该应用发生性能问题时的基础架构监控指标变动情况,从而实现问题关联分析的能力。
五、智能探针技术
通过SmartAgent技术,全面兼容非容器/容器环境的各类应用,支持独立进程、DaemonSet、Image等多种方式进行探针安装,全面兼容K8S,从而实现了探针的简易部署、自动监控。
智能探针可支持通过守护进程对容器的调度情况进行监控,当发现有被监控容器生成时,将先判断该容器环境应适配哪个类型的探针(如Java、Python、Node.js等),然后自动将匹配好的探针进行自动装载和配置信息修改,实现探针的自动发现、自动注入的能力。
同时,在APM平台还可配置不同的监控策略和批量进行探针启停管理。可使用进程名称、镜像名称、环境变量、正则表达式等多种方式,进行服务进程的命名与合并,定义服务与应用的逻辑层级关系。
通过上述自动发现能力自动注入、探针统一调度策略管理等能力,实现了容器漂移或重启时自动监控的相关功能。
端到端监控实践
光大银行除了在应用服务端进行性能监控实践之外,还针对应用系统如网上银行、手机银行等前端应用进行了用户体验监控(DEM)实践。通过DEM的产品建设,掌握用户真实业务使用过程中的性能体验及问题,并通过端到端打通的方式,构建从用户到代码的全链路监控体系。
通过前后端关联分析的能力,可以通过平台快速了解当前系统的整体运行状态,分析主要问题是发生在网页端、手机APP端还是H5页面端。从数据中心内部看,问题是在哪个集群、哪一类应用上,主要问题是应用本身问题,还是远程调用,或是数据库问题导致。
前端监控分别通过主动模拟监控方式和JS/SDK注入方式,获取用户使用业务过程中的网络请求性能数据、页面加载性能数据及使用中遇到的慢卡顿等各类问题,全面掌握业务在各个区域、各类网络、各个机型和重要业务流程中的可用性与连续性。
平台具备端到端的关联分析能力,基于TraceID在Header中传导的原理,将前后端的性能数据进行关联,实现针对单一调用前后端关联分析的能力。举例来说,一个用户请求较慢,发现服务端处理用时偏高 :点击进入到快照分析中,找到相关快照记录,通过点击服务端快照的方式,当前端应用发现性能问题,定位为后端服务响应速度慢时,可以通过快照跳转的方式,跳转到APM平台进行关联分析,直至定位到问题的故障代码。
收益与展望
通过本期项目建设,构建了应用系统前后端的性能监测能力,全面兼容光大全栈云平台,实现对云原生业务的Trace、Metric和日志数据的收集分析,并通过前后端关联的方式,了解了应用可用性指标与运行状态,实现了问题代码级根因定位的能力。
按照Gartner对于IT运维系统建设步骤的建议,将IT建设过程分为5个阶段,从低到高可分为可用性监控阶段、指标体系建设阶段、故障根因定位阶段、业务洞察阶段和流程自动化阶段。当前光大银行系统建设已经完成了第一到三阶段中可用性监控、指标体系建设和事务追踪的初步监控能力,实现了故障的根因定位与诊断能力,基本完成了第三阶段的建设目标。后续项目建设将在现有基础上,实现以下内容 :首先,进一步完善指标体系和性能监控范围与标准,构建统一客观的评价体系。其次,基于现有监控指标数据,实现业务的商业洞察,了解用户的使用流程和轨迹,从性能和收入角度综合分析IT服务支撑效果和用户使用习惯,真正从运维入手,来促进和提升业务运营。第三,实现多维度数据的不断积累,为全面的自动化运维奠定良好的数据基础和实践基础,构建不同维度的AIOps落地场景,在奠定基础的同时提升运维及业务收益。
博睿数据作为中国领先的智能可观测平台代表厂商,目前也是对应产品方案能够落地四大行生产环境的重要厂商。博睿数据将近年优秀实践整理为《金融行业精选客户案例集》,在上一版收录建设银行、农业银行、泰康保险等客户的基础上,本次新增光大银行、平安银行、中银证券等优秀的行业案例,希望通过抛砖引玉,为行业提供一批可复制可操作的先进经验,同时希望能够促进更多业界的合作与交流。
扫描海报下方二维码,免费获取博睿数据最新版《金融行业精选客户案例集》。