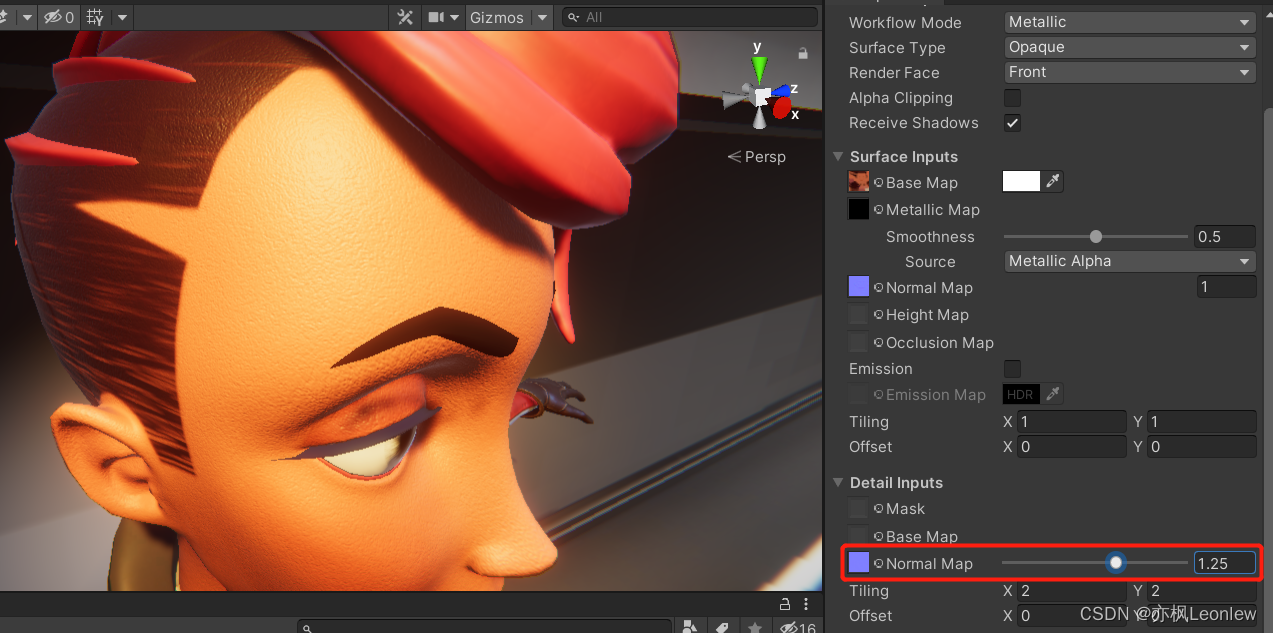
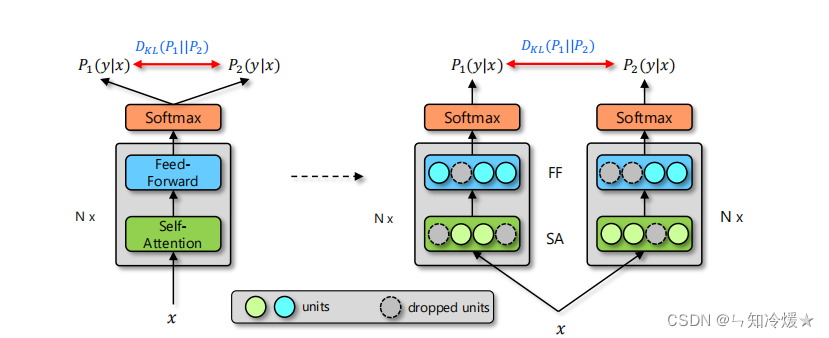
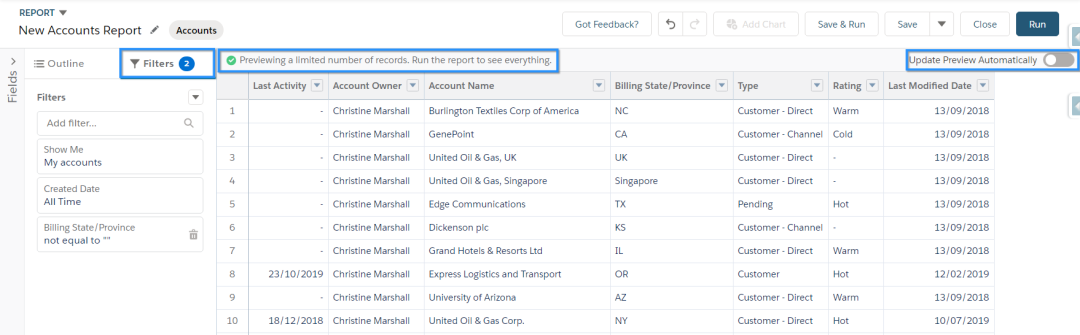
文章来源:NeurIPS
文章类别:IE(Information Extraction)
RadGraph主要基于dygie++,主要文件为inference.py。
inference.py:
1、get_file_list(data_path)
def get_file_list(path):
file_list = [item for item in glob.glob(f"{path}/*.txt")]
with open('./temp_file_list.json', 'w') as f:
json.dump(file_list, f)
该函数从data_path中读取所有的reports(txt文件)列表,然后保存到temp_file_list.json文件中。例如:
["data/s56075423.txt", "data/s59358936.txt", "data/s58951365.txt"]
2、preprocess_reports()
def preprocess_reports():
file_list = json.load(open("./temp_file_list.json"))
final_list = []
for idx, file in enumerate(file_list):
temp_file = open(file).read()
sen = re.sub('(?<! )(?=[/,-,:,.,!?()])|(?<=[/,-,:,.,!?()])(?! )', r' ',temp_file).split()
temp_dict = {}
temp_dict["doc_key"] = file
## Current way of inference takes in the whole report as 1 sentence
temp_dict["sentences"] = [sen]
final_list.append(temp_dict)
if(idx % 1000 == 0):
print(f"{idx+1} reports done")
print(f"{idx+1} reports done")
with open("./temp_dygie_input.json",'w') as outfile:
for item in final_list:
json.dump(item, outfile)
outfile.write("\n")
从temp_file_list.json中获取list,对每个report切分,形成单独的词,生成字典形式{“doc_key”: , “sentences”: },保存temp_dygie_input.json中。

3、run_inference(model_path, cuda)
此处使用的是allennlp。从temp_dygie_input.json中读取数据,然后保存到temp_dygie_output.json中。
def run_inference(model_path, cuda):
"""
Args:
model_path: Path to the model checkpoint
cuda: GPU id
"""
out_path = "./temp_dygie_output.json"
data_path = "./temp_dygie_input.json"
os.system(f"allennlp predict {model_path} {data_path} \
--predictor dygie --include-package dygie \
--use-dataset-reader \
--output-file {out_path} \
--cuda-device {cuda} \
--silent")
4、postprocess_reports(),生成final_dict
调用postprocess_individual_report(file, final_dict),单独处理每个report。
def postprocess_reports():
"""Post processes all the reports and saves the result in train.json format
"""
final_dict = {}
file_name = f"./temp_dygie_output.json"
data = []
with open(file_name,'r') as f:
for line in f:
data.append(json.loads(line))
for file in data:
postprocess_individual_report(file, final_dict)
return final_dict
5、postprocess_individual_report( )
def postprocess_individual_report(file, final_dict, data_source=None):
"""
Args:
file: output dict for individual reports
final_dict: Dict for storing all the reports
"""
try:
temp_dict = {}
temp_dict['text'] = " ".join(file['sentences'][0])
n = file['predicted_ner'][0]
r = file['predicted_relations'][0]
s = file['sentences'][0]
temp_dict["entities"] = get_entity(n,r,s)
temp_dict["data_source"] = data_source
temp_dict["data_split"] = "inference"
final_dict[file['doc_key']] = temp_dict
except:
print(f"Error in doc key: {file['doc_key']}. Skipping inference on this file")
6、get_entity(n,r,s)
def get_entity(n,r,s):
"""Gets the entities for individual reports
Args:
n: list of entities in the report
r: list of relations in the report
s: list containing tokens of the sentence
Returns:
dict_entity: Dictionary containing the entites in the format similar to train.json
"""
dict_entity = {}
rel_list = [item[0:2] for item in r]
ner_list = [item[0:2] for item in n]
for idx, item in enumerate(n):
temp_dict = {}
start_idx, end_idx, label = item[0], item[1], item[2]
temp_dict['tokens'] = " ".join(s[start_idx:end_idx+1])
temp_dict['label'] = label
temp_dict['start_ix'] = start_idx
temp_dict['end_ix'] = end_idx
rel = []
relation_idx = [i for i,val in enumerate(rel_list) if val== [start_idx, end_idx]]
for i,val in enumerate(relation_idx):
obj = r[val][2:4]
lab = r[val][4]
try:
object_idx = ner_list.index(obj) + 1
except:
continue
rel.append([lab,str(object_idx)])
temp_dict['relations'] = rel
dict_entity[str(idx+1)] = temp_dict
return dict_entity