😄 花一个小时快速跟着 人生导师-李沐 过了一遍GPT, GPT-2, GPT-3。下面精简地总结了GPT系列的模型结构+训练范式+实验。
文章目录
- 1、GPT
- 1.1、模型结构:
- 1.2、范式:预训练 + finetune
- 1.3、实验部分:
- 2、GPT-2
- 2.1、模型结构
- 2.2、范式:预训练 + zero-shot
- zero-shot, one-shot, few-shot的区别:
- 2.3、实验
- 3、GPT-3
- 3.1、模型结构:
- 3.2、范式:预训练 + few-shot
- 3.3、实验
- 3.4、GPT-3局限性
1、GPT
论文:《Improving Language Understanding by Generative Pre-Training》, OpenAI
1.1、模型结构:
- GPT基于transformer的decoder结构。
1.2、范式:预训练 + finetune
也是自监督预训练 (语言模型)+微调的范式。
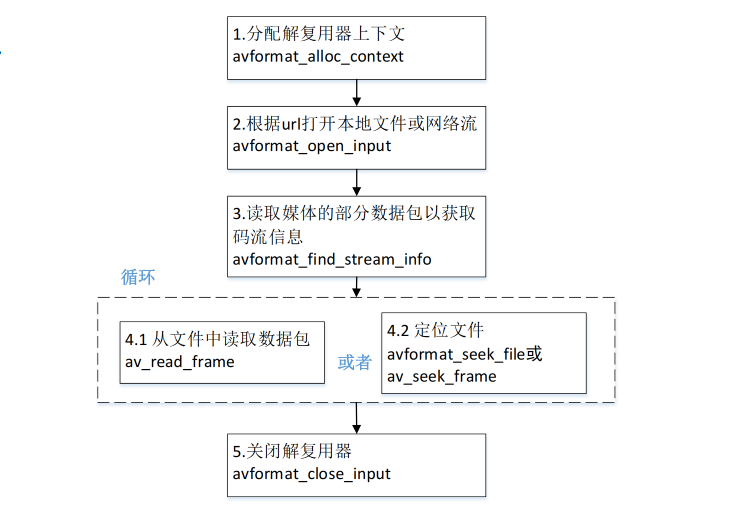
- 预训练:用的是标准的语言模型的目标函数,即似然函数,根据前k个词预测下一个词的概率。
- 微调:用的是完整的输入序列+标签。目标函数=有监督的目标函数+λ*无监督的目标函数。
- 改变输入形式,接上对应下游任务的层,就可实现不同下游任务。

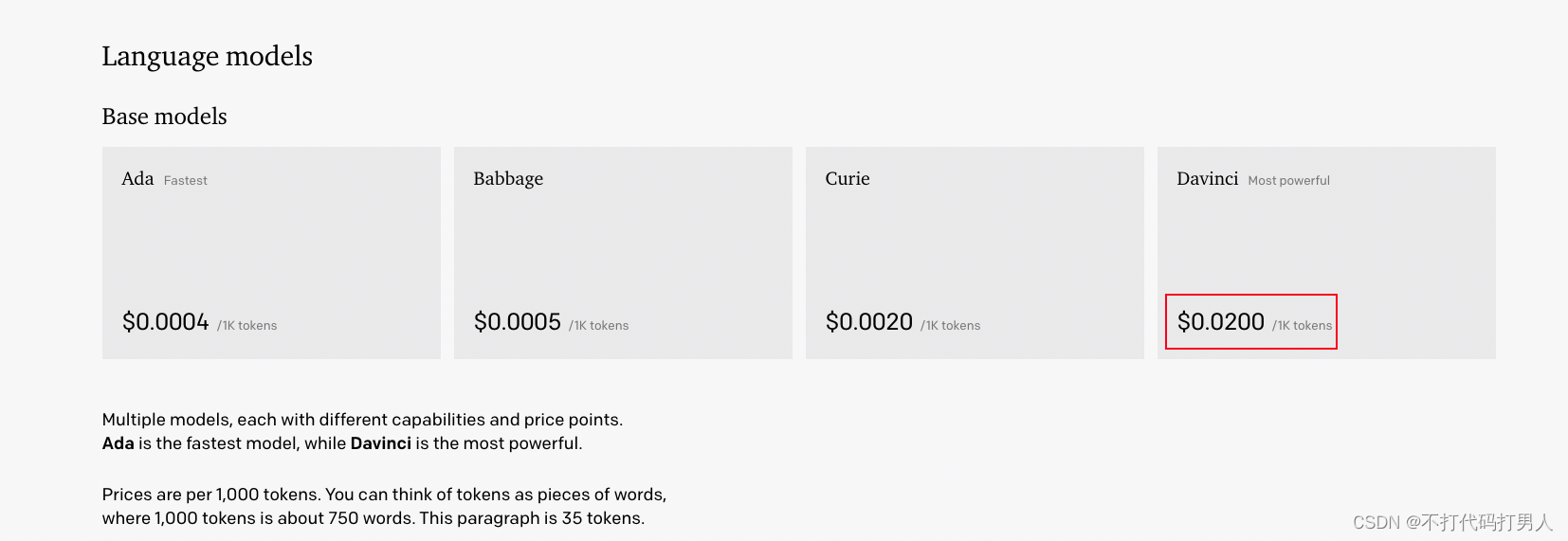
1.3、实验部分:
- 使用BookCorpus数据集训练,包括7000篇未发表的书
- 模型使用12层trm的解码器,每层维度768
2、GPT-2
《Language Models are Unsupervised Multitask Learners》, OpenAI
2.1、模型结构
- GPT-2也是基于transformer的decoder结构。
2.2、范式:预训练 + zero-shot
- GPT-2可以在zero-shot设定下实现下游任务,即不需要用有标签的数据再微调训练。
- 为实现zero-shot,下游任务的输入就不能像GPT那样在构造输入时加入开始、中间和结束的特殊字符,这些是模型在预训练时没有见过的,而是应该和预训练模型看到的文本一样,更像一个自然语言。
- 可以通过做prompt模版的方式来zero-shot。例如机器翻译和阅读理解,可以把输入构造成,“请将下面的一段英语翻译成法语,英语,法语”。
zero-shot, one-shot, few-shot的区别:



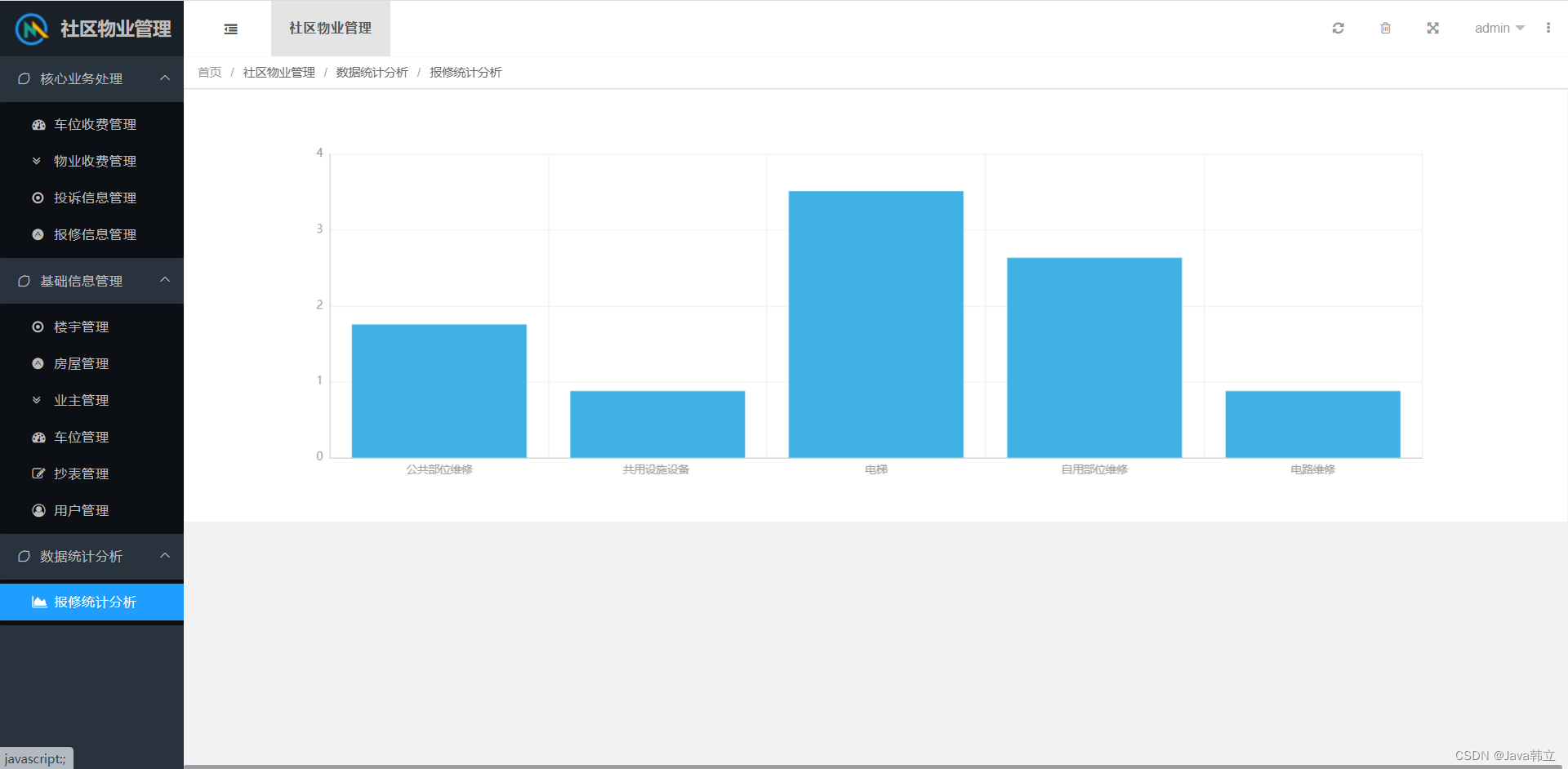
2.3、实验
- 数据从Reddit中爬取出来的优质文档,共800万个文档,40GB。
- GPT-2参数量1.5B,15亿。
- 模型越大,效果越好。
- 所以考虑用更多的数据,做更大的模型,于是GPT-3应运而生。
3、GPT-3
《Language Models are Few-Shot Learners》, OpenAI
- GPT-2虽然提出zero-shot,比bert有新意,但是有效性方面不佳。GPT-3考虑few-shot,用少量文本提升有效性。
- 总结:GPT-3大力出奇迹!
3.1、模型结构:
- GPT基于transformer的decoder结构。
- GPT-3模型和GPT-2一样,GPT-2和GPT-1区别是初始化改变了,使用pre-normalization,以及可反转的词元。GPT-3应用了Sparse Transformer中的结构。提出了8种大小的模型。
3.2、范式:预训练 + few-shot
论文尝试了如下方案,评估方法:few-shot learning(10-100个小样本);one-shot learning(1个样本);zero-shot(0个样本);其中few-shot效果最佳。
- fine-tuning:预训练 + 训练样本计算loss更新梯度,然后预测。会更新模型参数
- zero-shot:预训练 + task description + prompt,直接预测。不更新模型参数
- one-shot:预训练 + task description + example + prompt,预测。不更新模型参数
- few-shot:预训练 + task description + examples + prompt,预测。不更新模型参数
3.3、实验
- GPT-3参数量1750亿。
- 爬取一部分低质量的Common Crawl作为负例,高质量的Reddit作为正例,用逻辑回归做二分类,判断质量好坏。接下来用分类器对所有Common Crawl进行预测,过滤掉负类的数据,留下正类的数据;去重,利用LSH算法,用于判断两个集合的相似度,经常用于信息检索;
- 加入之前gpt,gpt-2,bert中使用的高质量的数据
3.4、GPT-3局限性
- 生成长文本依旧困难,比如写小说,可能还是会重复;
- 语言模型只能看到前面的信息;
- 语言模型只是根据前面的词均匀预测下一个词,而不知道前面哪个词权重大;
- 只有文本信息,缺乏多模态;
- 样本有效性不够;
- 模型是从头开始学习到了知识,还是只是记住了一些相似任务,这一点不明确;
- 可解释性弱,模型是怎么决策的,其中哪些权重起到决定作用?
- 负面影响:可能会生成假新闻;可能有一定的性别、地区及种族歧视