不管是 Web 系统,还是移动 APP,前后端逻辑的分离设计已经是常态化,相互之间通过 API 调用进行数据交互。在基于 API 约定的开发模式下,如何加速请求 / 响应的 API 测试,让研发人员及早参与到调试中来呢?既然 API 是基于约定开发,为何不按照这个规范编写测试用例,直接进入待测试状态,使用自动化的方式来推进研发过程的质量改进呢?遵循:测试 -> 重构 -> 测试 -> 重构,这样的闭环,过程产出的质量会更加可控,在重构的同时进行快速的功能回归验证,大大提高效率。本文主要讲解基于 HTTP 协议的 API 测试,从手工测试到平台的演变过程。
手工测试带来的困惑
测试团队采用《敏捷脑图用例实践之路》的方式编写测试用例:
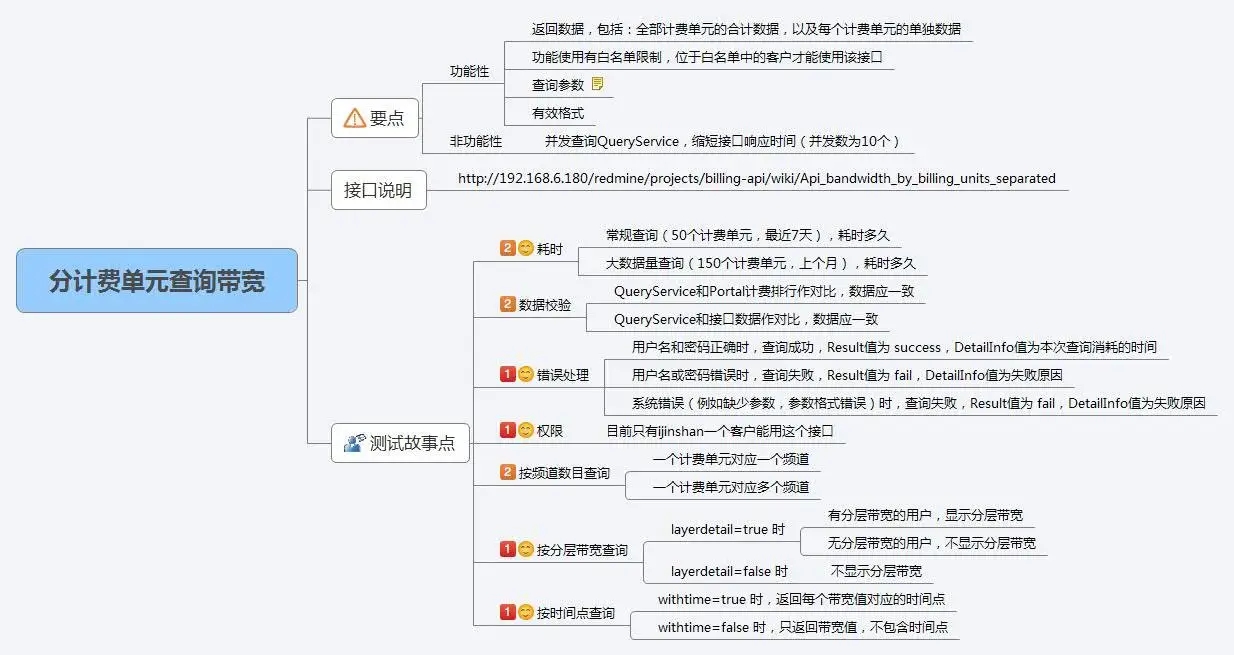
优点(文中已有详细介绍,这里简单列举):
-
要点清晰简洁展现
-
所有测试故事点经过用例评审,产生质量高,研发参与感强;
-
版本同步保持一份
API 测试脑图带来的问题:
-
脑图用例对测试人员的素质要求相当高
-
完善的脑图用例编写,需要有资深的测试人员,对业务精通、对测试技能精通,很强的思维能力;如果研发人员仅仅参考这个脑图用例进行测试,往往很多时候需要花费大量的沟通时间,其中有很多测试 API 的过程、措施,在脑图里面没有具体体现,造成一些信息丢失。
-
重复执行不变的是规则,变的只是参数,要消灭重复部分
-
还可以深度优化脑图用例,API 接口规范,再怎么天马行空,也得有个度,应当把重复思考的部分交给工具去做,需要发挥创造力、值得关注部分,交给人工完成;按照这个测试流程,,测试人员编写完用例,去验证 API 接口,如果失败了,打回给研发人员重新修改,但是下一次研发人员提交测试,测试人员又得重新验证一遍,这一遍中实际没有多少有价值的思考,是重复工作,要去挖掘测试价值。另外,如果测试人员请假了,那是不是测试就需要延期了呢?消除等待、消除单点作业,改变是唯一出路,尝试过如下方式:
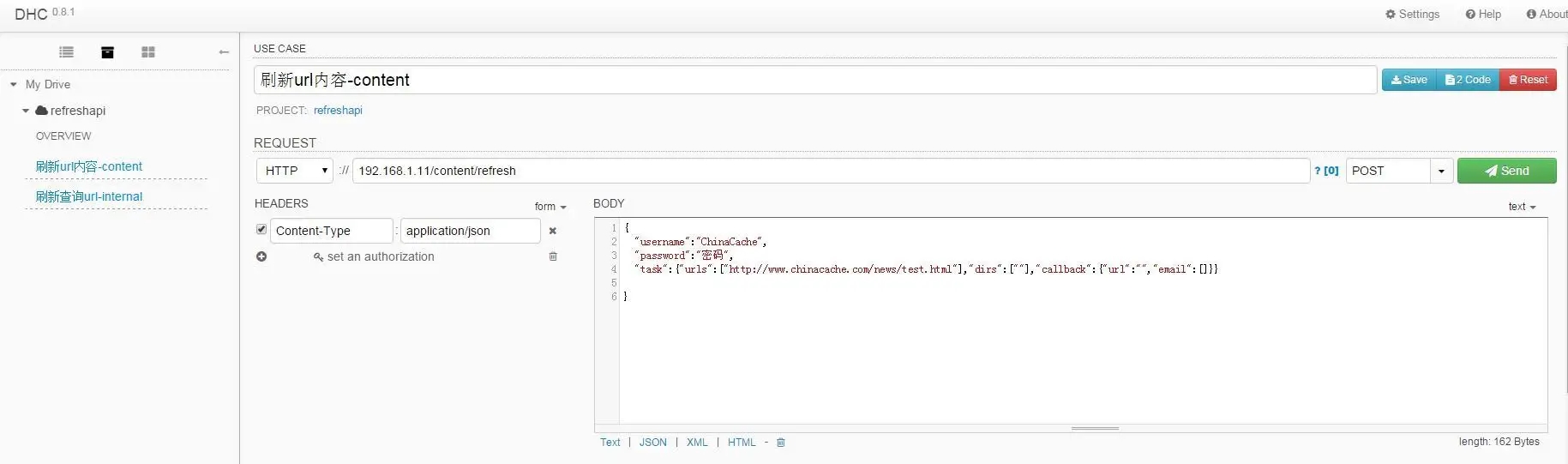
组员通过使用 Chrome DHC(是一款使用 chrome 模拟 REST 客户端向服务器发送测试数据的谷歌浏览器插件),进行 API 自动化测试,用例文件保存到本地并且同步到 svn,简单粗暴解决重复请求问题,注意强调的是解决重复请求,并没有包括参数和结果的自动化验证的过程,还是需要人工参与,至少前进了一步,当然我们也解决了单点问题,其他组员可以更新用例本地运行,还差参数校验,数据校验等等一堆关键业务点要用自动化去突破。
俗话说:术业有专攻,DHC 只是玩玩而已,并不擅长做那么多活,也做不好,更期望的是平台化。
平台雏形:没有经验,多么痛的领悟
经历了手工测试的繁琐操作,丢弃了简单的 DHC,决定另寻新路,API 测试最简单的场景请求参数组合产生各类别的测试用例。思路很简单,做一个 WEB 平台,登记 API 接口,填写请求参数,对响应结果进行校验,初期进行了技术选型,使用 Django 做 Python Web 开发,后台脚本执行使用开源框架 RobotFramework,RF 优点如下:
-
是一个通用的关键词驱动自动测试框架;
-
易于使用的表格数据展现形式,采用关键字驱动的测试方法,使用在测试库中实现的关键词来在测试中运行程序。
-
是灵活和可扩展的,适合用于测试用户接口;
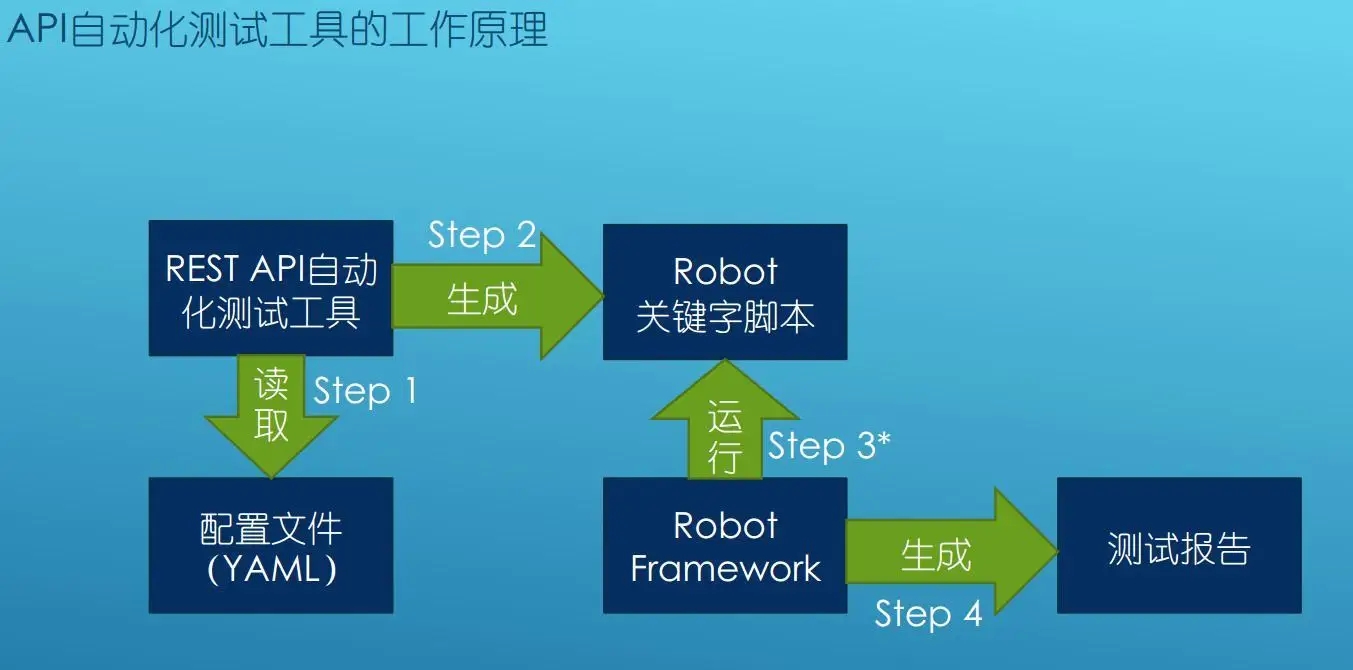
在这个平台中,RobotFramework 主要用于后台执行 Robot 关键字脚本,而关键字脚本,是平台通过读取 YAML 文件生成,该文件是通过笛卡尔乘积产生的用例,工作原理如图所示:
那话说回来,YAML 干什么呢?为什么不是 XML 呢?
-
YAML 的可读性好
-
YAML 和脚本语言的交互性好
-
YAML 使用实现语言的数据类型
-
YAML 有一个一致的信息模型
-
YAML 易于实现
听起来 YAML 试图用一种比 XML 更敏捷的方式,来完成 XML 所完成的任务。下面通过一段实际例子说明配置生成的 YAML 代码段:
被测接口通过web 界面配置
主接口配置界面:
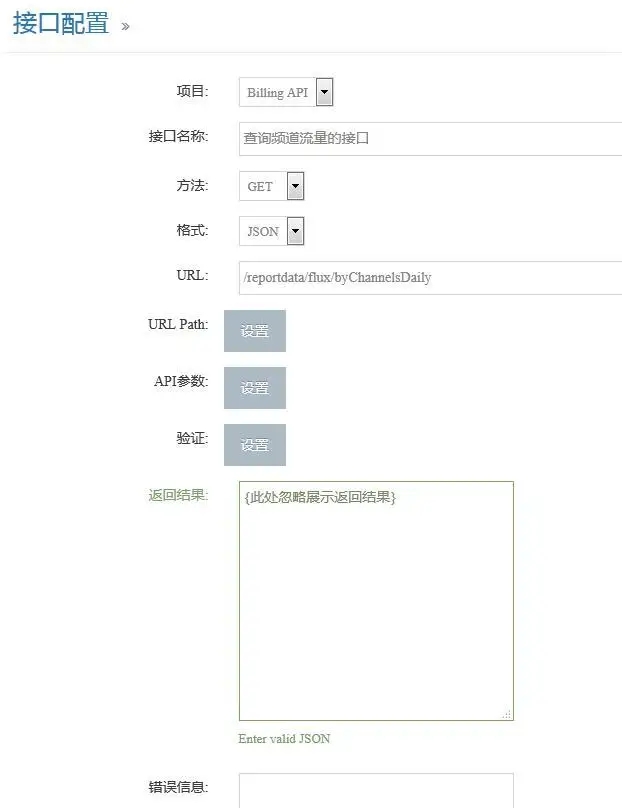
设置API 参数:
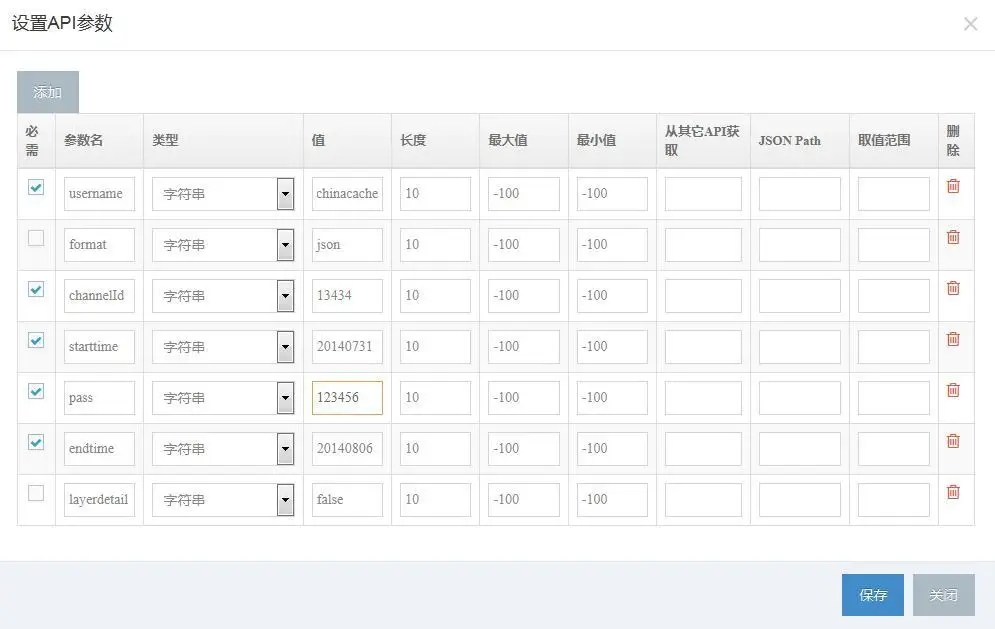
配置文件 byChannelsDaily.yaml(列举一个参数示例):
- byChannelsDaily: #接口名称
method: get #与服务器交互的方法
format: json #API 数据格式
url: /reportdata/flux/byChannelsDaily #API 的 URL,与奇台配置文件里面的 host 变量组成整个 URL 的前半部分。
url_path:
url_params: #URL 参数部分,固定写法。
username: #API 的参数名。
required: true #该参数是否必须(true/false)。
value: chinacache #该参数的值。如此值是从另一个接口获取的,可在 from_api 设置,此处可不填。如果值是 Boolean,必须加双引号。
type: string #该参数值的类型。
len: 10 #该参数值的长度。
max: -100 #该参数值的最大值。-100 相当于忽略此参数
min: -100 #该参数值的最小值。-100 相当于忽略此参数
from_api: #如参数的值是从另一个接口、global.yaml 中获取的,请设置 from_api,如 global
jsonpath: #可通过 jsonpath 来指定取值范围,如 $.version[2:4]
range:
response: #期望结果
verification:
success: [] #success 是一个 list, 它的元素也是 list,success[0] = [ RF 关键字 ,验证字段,正则匹配]
failure: []
error_msg: [] #错误信息集合
测试报告:

按照这个思路做下来,得到什么收益呢?

说到这里,其实,真没有带来多少收益,思路对了,但是方向有偏差了,主要体现在:
- 使用了笛卡尔乘积来生成不同参数的测试用例,发现一堆的测试用例生成文件是 M 的单位,而且也给测试服务器带来性能问题,数量 4980 个中占 95% 的用例都是没有实际意义的,对服务器频繁请求造成压力;
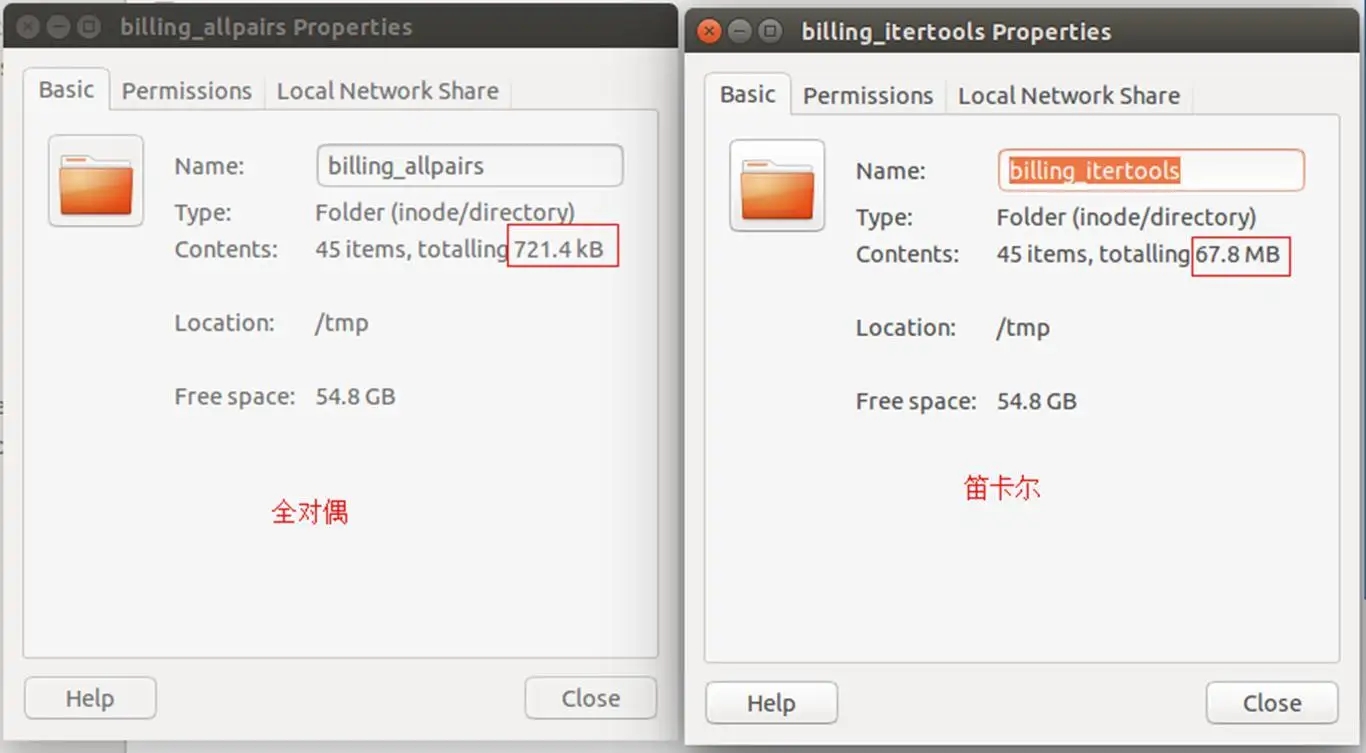
2. 通过 WEB 配置将 YAML 文件转为 robot 可以识别的,这种做法坑太深、维护难,参数越多, 文件越臃肿,可读性差;
- 后来尝试将笛卡尔乘积换成全对偶组合算法,效果改进显著,无效用例数明显下降,有效用例数显著提升;
败了,就是败了,没什么好找借口,关键问题是:
有效的测试用例占比例很低,无效的占了大部分;
没有化繁为简,前端隐藏了配置,复杂的配置还是需要在后端处理;
没有实际测试参与动脑过程,测试人员不会穷举,会根据业务编写实际用例;
平台易用性很重要:需要测试人员直接在上面编写,合理的逻辑步骤,有利于引导测试参与
重构:发现测试的价值
回到起点,测试要解决什么问题,为什么要做 API 自动化测试平台?做这个平台,不是为了满足老板的提倡全民自动化的口号,也不是为了浮夸的 KPI,更不是宣传自动化可以解决一切问题,发现所有 bug。叔本华说过一句话:由于频繁地重复,许多起初在我们看来重要的事情逐渐变得毫无价值。如果 API 测试仅仅依靠纯手工的执行,很快将会面临瓶颈,因为每一个功能几乎都不能是第一次提交测试后就测试通过的,所以就需要反复 bug 修复、验证,以及回归的过程。另外,很多的 API 测试工作手工做起来非常的繁琐,甚至不便,比如针对接口协议的验证、针对返回数据格式的验证,这些都依赖于测试自动化的开展。因此,真正的目的是解放测试人员重复的手工生产力,加速回归测试效率,同时让研发人员在开发过程及早参与测试(自测、冒烟测试),驱动编码质量的提升。
回顾以往,重新梳理头绪,更加清晰的展现:
-
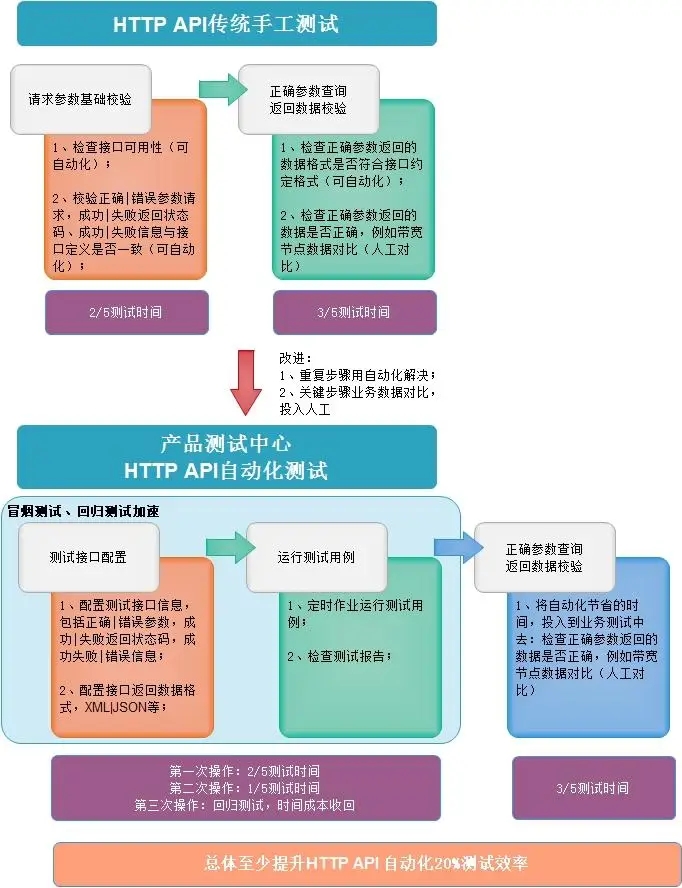
HTTP API 传统手工测试
-
重复请求参数基础校验、正确参数查询返回数据校验,测试工程师没有新的创造价值,不断重复工作,甚至可能压缩其中的测试环节,勉强交付;
-
HTTP API 自动化测试
-
重复步骤(请求接口是否有效、参数校验可以作为冒烟测试,研发参与自测)用自动化解决,关键业务步骤数据对比人工参与和 schema 自动化校验;
最大的收益,重复步骤自动化后,不管是研发人员自测,还是执行功能回归测试,成本可以很快收回(前提是你这个项目周期长,构建频繁;如果仅仅是跑几个月的项目,真没那个必要凑热闹去自动化,当然有平台的另当别论),测试的关注点会落实到更加关键的业务环节去;
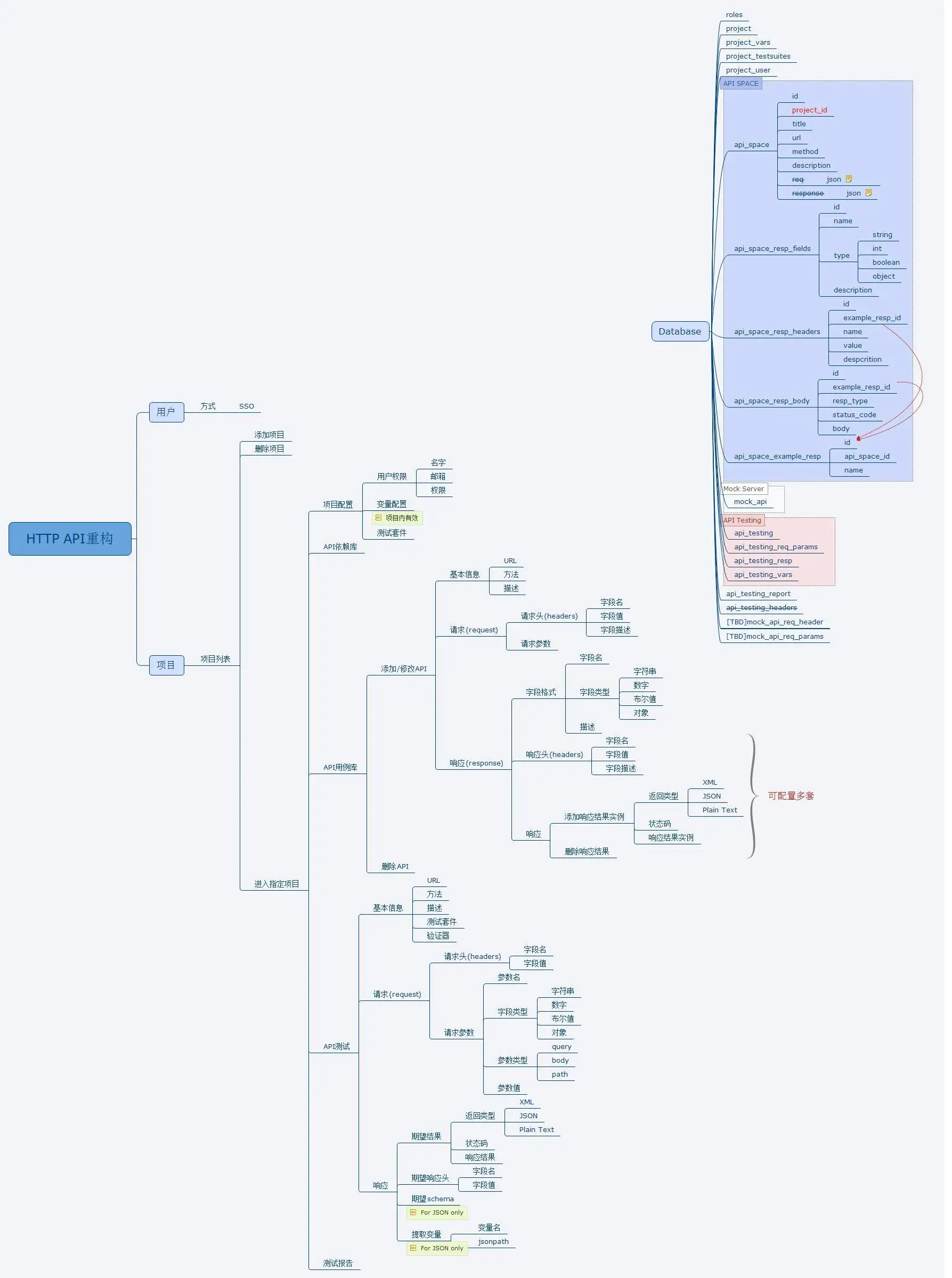
总体规划如下:
-
技术选型 由于原来的测试平台使用 Python 编写,为了保持风格一致,从界面录入到文件生成处理依然采用 Python、Django,去掉了全对偶组合算法,改为根据测试人员思维去产生用例;去掉了后台 RobotFramework 框架,采用 Python 的 HTTP 类库封装请求。
-
HTTP API 项目管理 Web 前台 使用 Python+Django+MySQL 进行开发,分为项目首页、项目配置、API 配置、全局配置四大部分

项目首页
介绍:列出 API 规范、API 测试用例、定时任务数量,以及某段时间内的测试结果趋势图形。

项目配置 重点介绍:全局变量、常用方法、验证器。
全局变量
设计思路:在 API 测试过程中,可以切换生产、测试环境进行对比校验,如果写两套测试用例是冗余,全局变量功能,是一种在执行测试用例时动态改变用例属性的方法。
作用范围:当前项目内
使用方法:{变量名}
能在以下测试用例属性中使用:URL、请求头、请求参数
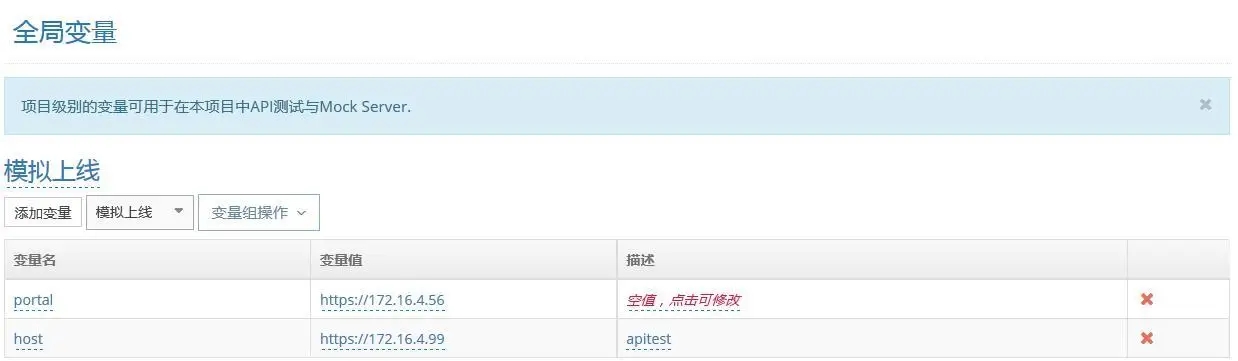
在 API 用例库的 URL 可以直接填写:{host}/reportdata/monitor/getChannelIDsByUserName;当运行测试用例的时候,可以选择不同的参数套件,后台代码执行会直接替换,这样子可以分别快速验证生产环境和测试环境的 API 接口执行结果的差异。
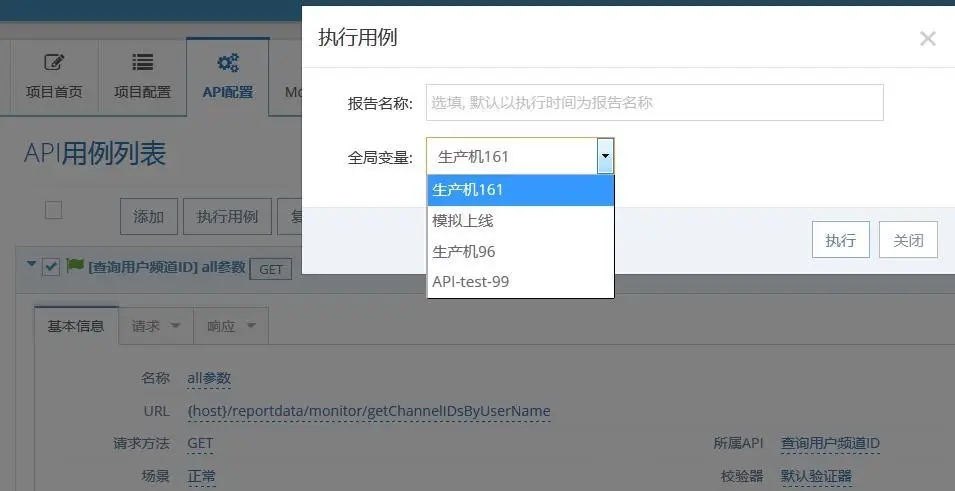
常用方法
(点击放大图像)
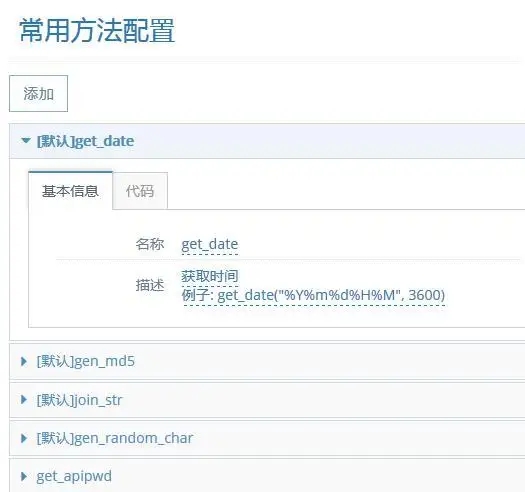
√ 设计思路:常用方法是一个 Python 函数,对入参进行处理并且返回结果,例如:
gen_md5 作用是生成 MD5,对应代码直接填写:
import hashlib
def gen_md5(raw_str):
m = hashlib.md5()
m.update(raw_str)
md5_str = m.hexdigest()
return md5_str
√ 应用场景:
在 API 请求中,有些参数例如 pass 需要加密处理,可以通过引入 [常用方法] 来解决。
在参数 pass 的值中直接填写:、
{{get_apipwd("{123456}","ChinaCache")}}
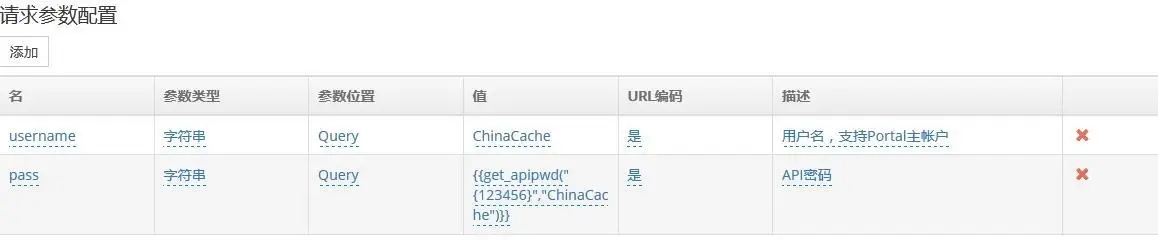
> 验证器
√ 设计思路
验证器是一个Python 函数,如果函数返回True,则测试通过;返回False,则测试失败。平台默认提供一个默认验证器。
默认验证器是验证期望结果与实际结果(response body)是否完全一致。如果结果不一致则判断为失败,默认验证器只适用于静态的响应结果对比。
自义定验证器,如果默认验证器不能满足某些特殊的测试需求,用户可以在“项目配置- 验证器”中添加自定义的验证器。
√ 应用场景:在API 测试的返回结果中,可以添加自定义验证器对数据进行校验,判断测试是否通过。
(点击放大图像)
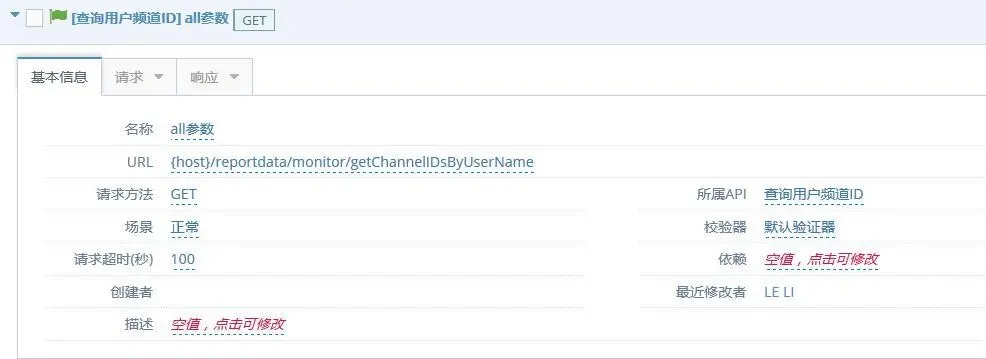
图 -17- 测试用例验证展示页
API 配置 重点介绍:通用响应配置、API 依赖库、API 用例库、定时任务、测试报告
通用响应配置
(点击放大图像)
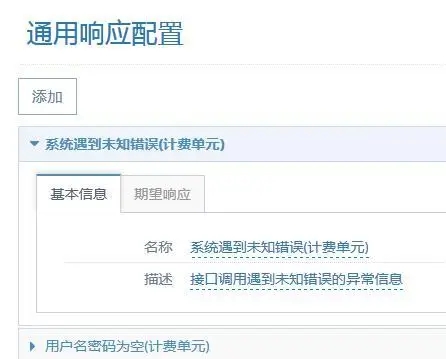
图 -18- 通用响应配置列表页
√ 设计思路
在合理的 API 设计中,存在通用的错误响应码,[用户名错误,返回期望响应内容],如果所有 API 的响应结果中都需要重复写是相当繁琐的,作为共同配置调用即可。
(点击放大图像)
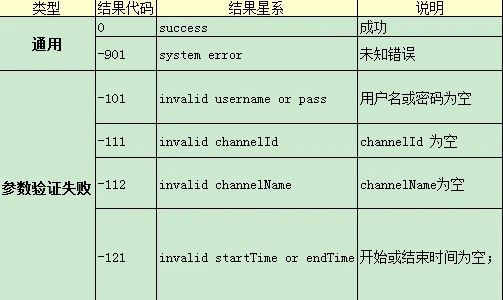
√ 应用场景
查询接口遇到用户名密码为空,可以自定义写返回内容,以及选择 [通用响应配置] 下的相关错误类型,例如:用户名密码为空 (计费单元),自动填充期望的返回值:
<BillingIDs>
<Result>fail</Result>
<DetailInfo>invalid userName or password</DetailInfo>
</BillingIDs>
(点击放大图像)

图-19- 期望返回值校验页
API 依赖库
√ 设计思路 & 应用场景
API-A 的参数 r_id 依赖与 API-B 返回结果的某个参数(多个参数同样道理),这里登记 API-B,并且提取返回参数。除了特有的变量提取器,基本信息与请求,与后面提到的 API 接口一致的
填写方式 :
(点击放大图像)

图 -20- 变量提取器展示页
该接口返回数据如下;
{
"r_id": "567bbc3f2b8a683f7e2e9436"
}
通过 [变量提取器],可以获取 r_id 的值,以供依赖 API-A 作为参数使用。
(点击放大图像)

图-21- 用例中参数包含r_id 变量展示页
其中请求参数的获取如下:
(点击放大图像)
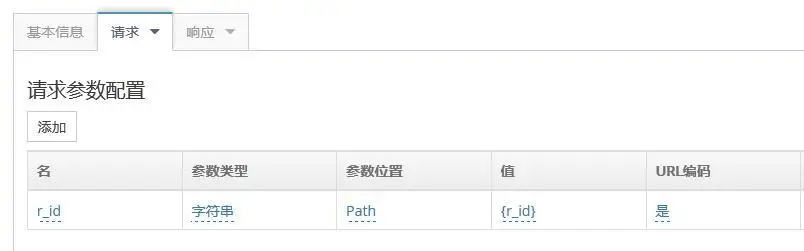
图-22- 请求参数变量提取设置
测试结果:
1- 显示依赖接口;2- 显示为需要测试的接口,依赖接口返回的 r_id 会传入作为测试接口的参数;
(点击放大图像)
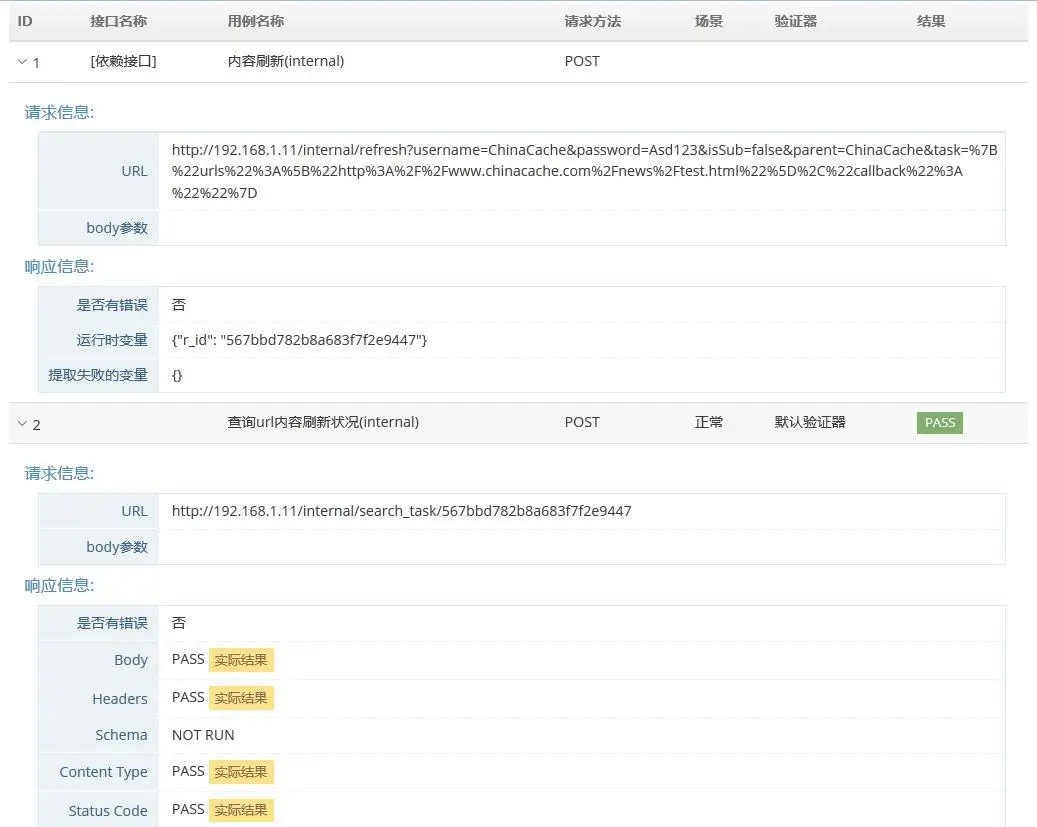
图 -23- 测试结果中展示运行时变量提取结果
API 用例库 (点击放大图像)
-24- 用例库设计脑图
√ 设计思路
通过自助配置:请求头、请求参数,响应头、响应结果校验,来聚合测试人员日常思考产生的测试用例。
√ 应用场景
支持 HTTP1.1 协议的 7 种请求方法:GET、POST、HEAD、OPTIONS、PUT、DELETE 和 TARCE。最常用的方法是 GET 和 POST:
支持 query(问号后)带参数、path 的 GET|POST 请求 Query: http://192.168.1.11/internal/refresh?username=ChinaCache&password=123456
Path: http://192.168.1.11/internal/refresh/username/password
POST 请求支持 application/json、text/xml 示例如下:
请求头设置:Content-Type:application/json
请求体设置:保存为 JSON 格式
{
"username": "ChinaCache",
"password": "123456",
"task": {
"dirs": [
""
],
"callback": {
"url": "",
"email": []
},
"urls": [
"http://www.chinacache.com/news/test.html"
]
}
}
结果如下:
(点击放大图像)
[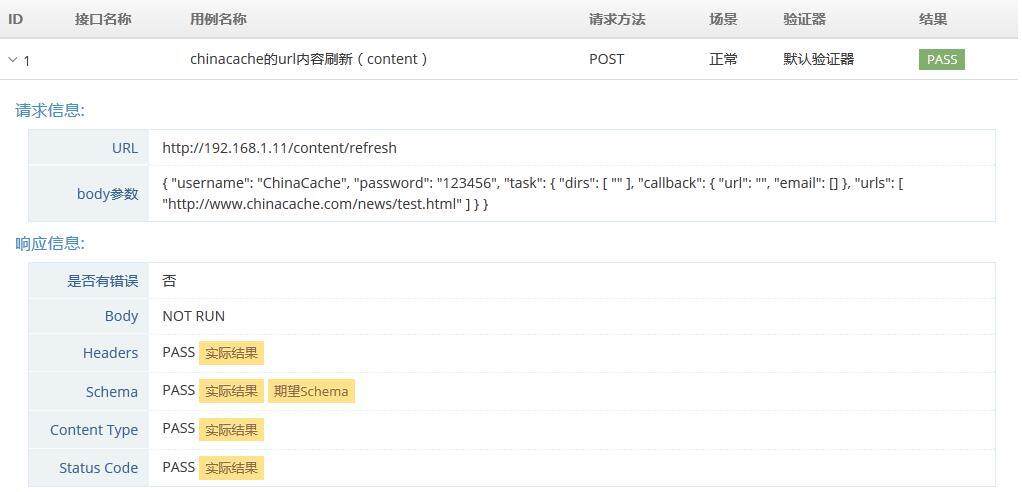](/mag4media/repositories/fs/articles//zh/resources/0215036.jpg)
图 -25-body 参数展示页
支持返回结果的 schema 验证 在返回大量数据的场景下,把数据格式的正确性交给程序去判断,通过之后进行人工干预的数据对比,假如返回几百 K 的数据,你不知道格式是否正确,就开始去做数据对比,这个方向是不对的。
{
"r_id": "567cfce22b8a683f802e944b"
}
Schema 验证如下:
{
"$schema": "http://json-schema.org/draft-04/schema#",
"required": [
"r_id"
],
"type": "object",
"id": "http://jsonschema.net",
"properties": {
"r_id": {
"type": "string",
"id": "http://jsonschema.net/r_id"
}
}
}
定时任务 √ 设计思路 & 应用场景
定时任务是在计划好的时间点自动执行指定的测试用例。一个项目支持多个定时任务,如果同一时间点有多个测试任务,将依次执行。定时任务有两种类型:定时、循环(间隔:秒,
分钟,小时,天,周)。通过定时任务,可以做到晚上运行,早上查看结果报告分析。
(点击放大图像)
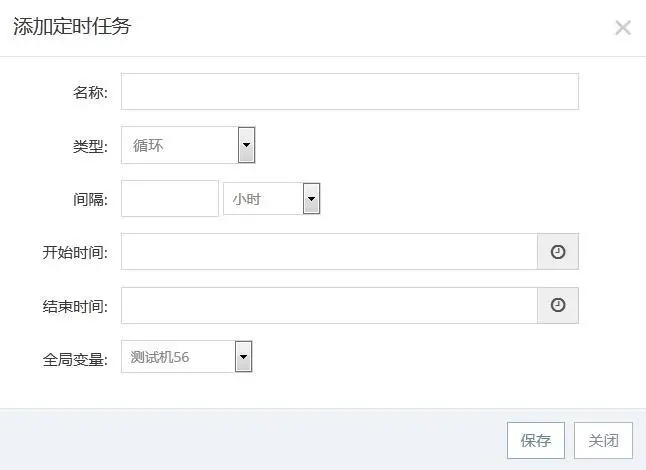
图 -26- 添加定时任务
测试报告 & 邮件通知 √ 设计思路 & 应用场景
每次执行测试用例(包括手动执行和定时任务)之后,都会生成一份测试报告。
报告会详细列出每个接口的基本信息(名称,请求方法,验证器等),请求信息(URL 和 body 参数),响应信息包括 headers, body, schema, content type, status code 5 部分的测试结果,每一部分都有实际结果、期望结果(失败时显示)以及 DIFF 对比(失败时显示),当在
执行测试时出现错误,也会把错误信息显示出来 。
(点击放大图像)
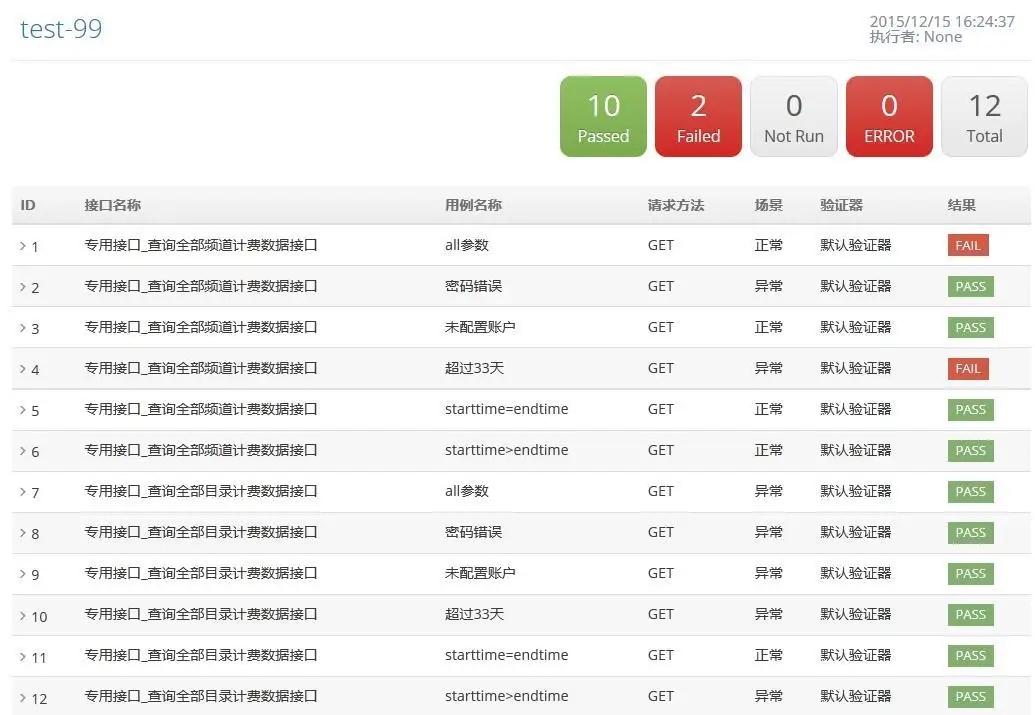
图 -27- 测试报告列表页
(点击放大图像)
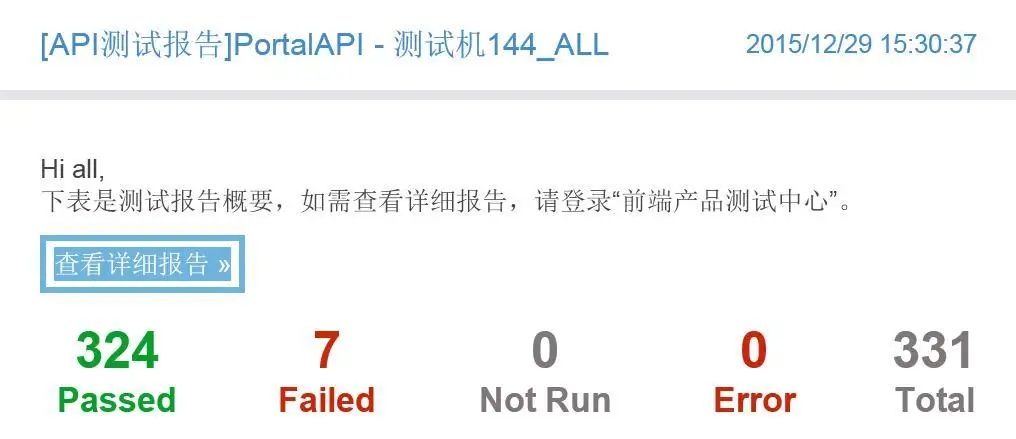
图 -28- 邮件通知
API 实战:324 个用例(包括 GET|POST 请求,参数有加密、依赖场景,返回结果有简单验证数据、错误码验证、schema 验证),运行耗时:8min,猜想下,如果人工去跑,需要多久呢?
提速:研发测试流程改进
(点击放大图像)
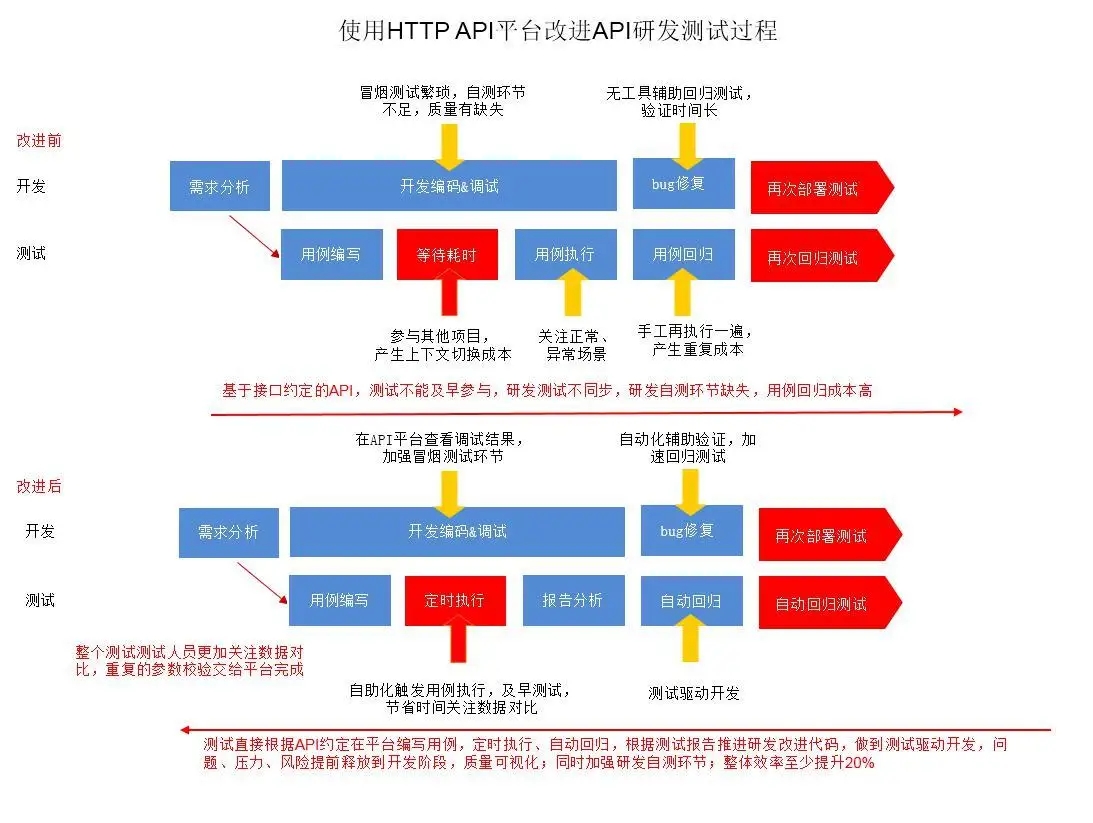
图 -29- 使用 HTTP API 平台改进 API 研发测试过程
改进前:传统手工测试 测试用例掌握在测试人员手里,研发人员无法运行,修复 bug 之后,只能等待测试人员验证,交付过程繁琐、效率低;
改进后:HTTP API 自动化测试 研发、测试协作同步,研发人员可以及早通过平台执行用例,验证功能可用性、正确性,测试人员可以释放部分劳动力,重点关注业务数据正确性;修复 bug 之后,研发人员无需等待,可以自助配置用例执行、查看结果,驱动过程质量的提升,同时做到夜间构建、邮件通知,工作时间 review、bug fix。
问题:何时收回投入成本? API 项目周期不超过半年的,不建议做自动化,有自动化平台基础的另当别论,因为在最初 API 测试用例编写需要投入大量的时间;这种投入,只有不断进行回归验证、多次运行,成本才可以回收,往后都是收益,这个道理浅显易懂。
总结
“由于频繁地重复,许多起初在我们看来重要的事情逐渐变得毫无价值”,在提测过程有个重要环节:冒烟测试,但是频繁的去做的话,就是重复性的工作了。
那 HTTP API 接口测试痛点是什么?研发人员提测之后,需要等待测试人员进行验证;测试人员发现 bug,需要等待研发人员 bug fix;这里就产生大量的等待成本(当然,测试人员可以切换到其他项目中去,但是这种上下文的切换成本很高)。通过 HTTP API 自动化测试平台,研发人员在提测之前,首先进行一轮冒烟测试,根据自动化测试用例检查结果,提升提测之前的功能质量;一旦提测之后,测试人员的关注重点落到返回结果对比上,这种研发测试过程的效率会得到很大的提升,或许有人要问,到底提升多少呢?这个每个团队的痛点不同,研发、测试人员磨合程度不同,不能一概而论,大胆迈出一步去尝试,就会发现价值;当然,往深处去想,下一步可以接入性能的自动化测试,喝杯咖啡的时间,等到自动化运行结果报告产出,是有可能的场景。
最后:下方这份完整的软件测试视频学习教程已经整理上传完成,朋友们如果需要可以自行免费领取 【保证100%免费】