目录
1 概述
2 原理
3 参数
1 概述
将企业生产系统产生的业务数据实时同步到大数据平台,通过对业务数据的联机实时分析,快速制定或调整商业计划,提升企业的核心竞争力。
依据同步数据是否需要加工处理,采用不同的技术方案:
如果数据需要清洗、聚合、标准化或其它加工处理,可采用ETL软件Beeload或BeeDI进行同步,详情可参考文章多源异构数据库实时同步解决方案,本文不做阐述。
如数据无需清洗转换,目标数据与源数据保持一致,可采用数据库复制软件Beedup进行同步。
Beedup除用于双活容灾外,凭借异构(主从库不同类型、主从对象不同属主模式)数据处理能力,也可应用于数据同步、数据迁移及数据汇聚项目,在同类或异类库间同步数据,目标数据可选择与源端不同的属主模式存储。
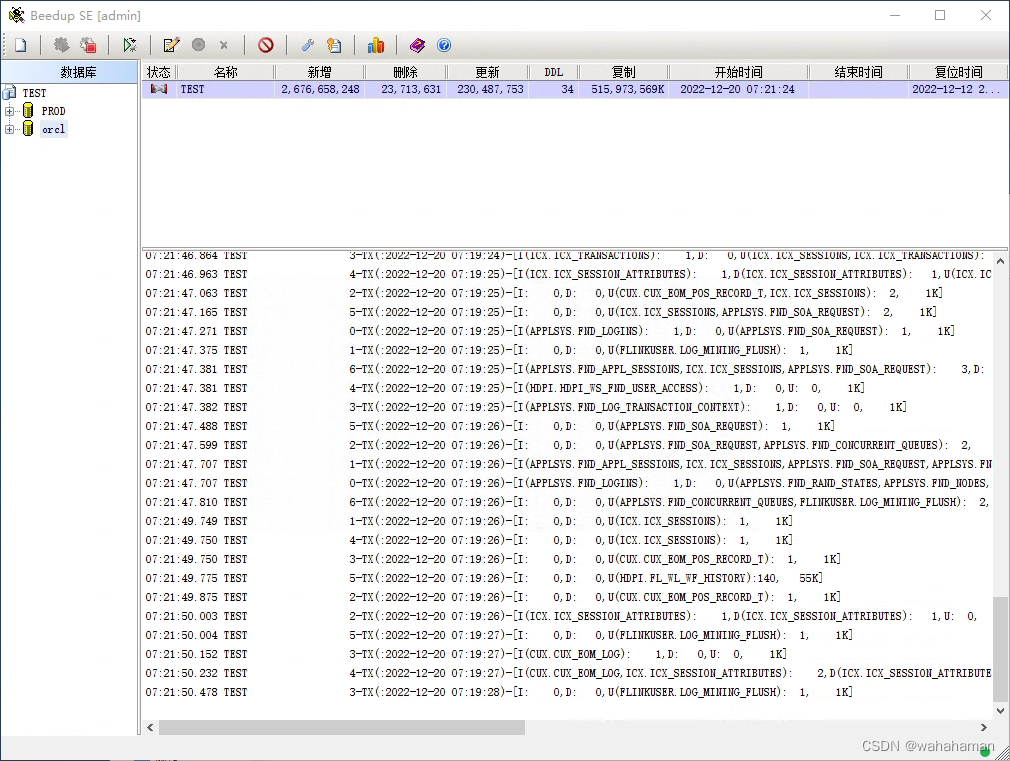
2 原理
采用Beedup实施数据库同步分为全量和增量二个过程:
全量过程遍历源库所有表,依次在目标库创建对应表并通过SQL读写方式同步表的历史数据。
增量过程采用日志解析方式,从某一时间点顺序读取数据库日志中的事务操作,解析还原为目标兼容的DML或DDL,以事务为单元在目标库重做操作。
全量过程开始时记录源库当前时间点,全量过程结束后,增量过程自动从该时间点开始解析日志。也可以跳过全量过程,直接指定某一时间点启动增量过程。
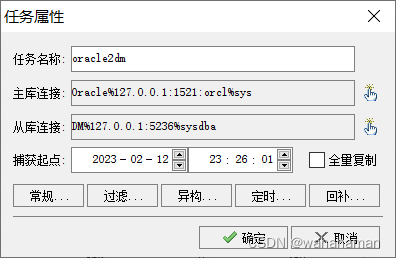
3 参数
| 工作方式 | 基于联机归档日志解析 |
| 目标库支持的操作 | Read-Write |
| 支持数据库 | Oracle 9i / 10g / 11g / 12c / 18c SQL Server 2005 / 2008 / 2012 / 2014 MySQL 5.6 / 5.7 / 8.0 DB2 9.5 / 9.7 / 10.5 / 11.1 Gbase 8a (8.3) PostgreSQL 10.5 / 11.8 / 12.3 DM 8.1 |
| 支持数据类型 | 所有 |
| 支持操作类型 | DML/ DDL |
| 可选择性复制 | 选择整库、用户模式、表为复制单位 |
| 支持的主从库平台 | 无限制 |
| 运行操作系统 | win7、win2008、win8、win2012、win10 |
| 支持多种复制结构 | 一对一,双向,一对多,多对一 |




![[TPAMI‘21] Heatmap Regression via Randomized Rounding](https://img-blog.csdnimg.cn/b0bb27f8ba1c47d79090725976527be3.png)