很多刚开始学习 Elasticsearch 的人经常会混淆 text 和 keyword 字段数据类型。 它们之间的区别很简单,但非常关键。 在本文中,我将讨论两者之间的区别、如何使用它们、它们的行为方式以及使用哪一种。
区别
它们之间的关键区别在于,Elasticsearch 会在将 text 存储到倒排索引之前对其进行分析,而不会分析 keyword 类型。 分析或不分析将影响它在被查询时的行为方式。有关文本分析的内容,请阅读 “Elasticsearch: analyzer”。
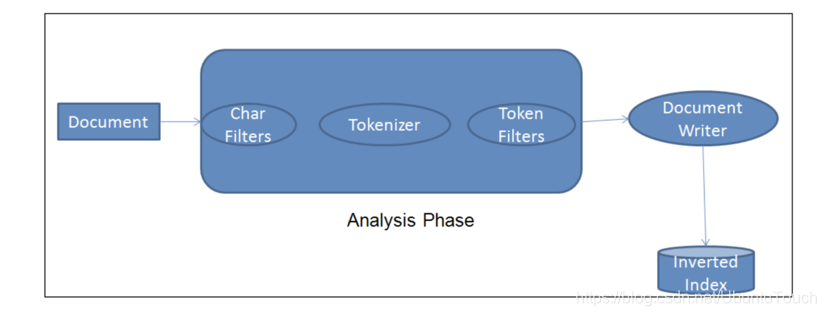
如果你刚开始学习 Elasticsearch,还不知道什么是 Inverted Index 和 Analyzer,我建议你先阅读文章 “Elasticsearch:inverted index,doc_values 及 source”。
如何使用它们
如果你将包含字符串的文档索引到 Elasticsearch 之前没有定义到字段的映射,Elasticsearch 将创建一个包含 text 和 keyword 数据类型的动态映射。 但即使它适用于动态映射,我建议你在索引任何文档之前根据用例定义映射设置,以节省空间并提高写入速度。
这些是 text 和 keyword 类型的映射设置示例,请注意,我将使用我之前为该示例创建的名为 text-vs-keyword 的索引。
keyword mapping
# Create index
PUT text-vs-keyword
# Create keyword mapping
PUT text-vs-keyword/_mapping
{
"properties": {
"keyword_field": {
"type": "keyword"
}
}
}text mapping
# Create text mapping
PUT text-vs-keyword/_mapping
{
"properties": {
"text_field": {
"type": "text"
}
}
}Multi Fields
PUT text-vs-keyword/_mapping
{
"properties": {
"text_and_keyword_mapping": {
"type": "text",
"fields": {
"keyword_type": {
"type":"keyword"
}
}
}
}
}运行上面的三个命令之后,我们可以看到 text-vs-keyword 的 mapping 为:
GET text-vs-keyword/_mapping上述命令的返回值为:
{
"text-vs-keyword": {
"mappings": {
"properties": {
"keyword_field": {
"type": "keyword"
},
"text_and_keyword_mapping": {
"type": "text",
"fields": {
"keyword_type": {
"type": "keyword"
}
}
},
"text_field": {
"type": "text"
}
}
}
}
}上面显示了三个字段,它们有不同的字段类型定义。特别值得指出的是:上面的 keyword_field 及 keyword_type 这些名称都是开发者可以自己定义的名称,但是在很大的情况下,我们把他们的名字都取为 keyword,如下:
{
"text-vs-keyword": {
"mappings": {
"properties": {
"keyword": {
"type": "keyword"
},
"text_and_keyword_mapping": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"text_field": {
"type": "text"
}
}
}
}
}他们是如何工作的
这两种字段类型在倒排索引中的索引方式不同。 索引过程的差异会影响你何时对 Elasticsearch 进行查询。
让我们索引一个文档,例如:
POST text-vs-keyword/_doc
{
"keyword_field": "The quick brown fox jumps over the lazy dog",
"text_field": "The quick brown fox jumps over the lazy dog"
}上述命令将将生成如一个文档。你可以通过如下的方式来进行搜索:
GET text-vs-keyword/_search{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "text-vs-keyword",
"_id": "fS95JoYBS2OSAePn1Qxh",
"_score": 1,
"_source": {
"keyword_field": "The quick brown fox jumps over the lazy dog",
"text_field": "The quick brown fox jumps over the lazy dog"
}
}
]
}
}keyword
让我们从更简单的 keyword 开始。 Elasticsearch 不会分析 Keyword 数据类型,这意味着你索引的 String 将保持原样。
那么,对于上面的例子,倒排索引中的字符串会是什么样子呢?
| Term | count |
The quick brown fox jumps over the lazy dog | 1 |
是的,你没看错,就是你写的那样。
Text
与 keyword 字段数据类型不同,索引到 Elasticsearch 的字符串在存储到倒排索引之前会经过分词器过程。 默认情况下,Elasticsearch 的标准分词器将拆分并小写化我们索引的字符串。 你可以在 Elasticsearch 的文档中了解有关标准分析器的更多信息。
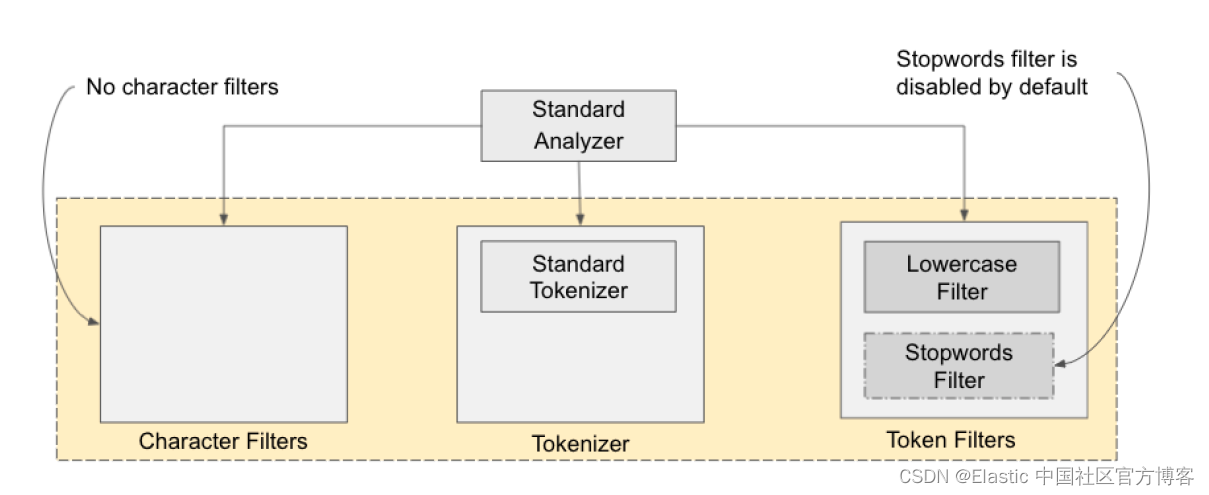
Elasticsearch 有一个 API 可以检查文本在分析过程后的样子,我们可以尝试一下:
GET _analyze
{
"text": "The quick brown fox jumps over the lazy dog",
"analyzer": "standard"
}我们可以看到如下的返回结果:
{
"tokens": [
{
"token": "the",
"start_offset": 0,
"end_offset": 3,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "quick",
"start_offset": 4,
"end_offset": 9,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "brown",
"start_offset": 10,
"end_offset": 15,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "fox",
"start_offset": 16,
"end_offset": 19,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "jumps",
"start_offset": 20,
"end_offset": 25,
"type": "<ALPHANUM>",
"position": 4
},
{
"token": "over",
"start_offset": 26,
"end_offset": 30,
"type": "<ALPHANUM>",
"position": 5
},
{
"token": "the",
"start_offset": 31,
"end_offset": 34,
"type": "<ALPHANUM>",
"position": 6
},
{
"token": "lazy",
"start_offset": 35,
"end_offset": 39,
"type": "<ALPHANUM>",
"position": 7
},
{
"token": "dog",
"start_offset": 40,
"end_offset": 43,
"type": "<ALPHANUM>",
"position": 8
}
]
}所以根据上面的回复,这就是 text_field 字段的倒排索引的样子:
| Term | Count |
|---|---|
| the | 1 |
| quick | 1 |
| brown | 1 |
| fox | 1 |
| jumps | 1 |
| over | 1 |
| the | 1 |
| lazy | 1 |
| dog | 1 |
与 keyword 略有不同,对吧? 但是你需要注意它在倒排索引中存储的内容,因为它会主要影响查询过程。
文本和关键字查询
现在我们了解了 text 和 keyword 在索引时的行为方式,让我们了解它们在被查询时的行为方式。
首先,我们必须知道字符串的查询有两种类型:
- Match query
- Term query
Match Query 和 Term Query 和 text 和 keyword 一样,区别在于 Match Query 中的 query 会先解析为 terms,而 Term Query 中的 query 不会。Term query 不分析搜索词。 Term query 仅搜索你提供的确切术语。 这意味着在搜索 text 字段时,术语查询可能返回较差的结果或没有返回结果。
查询 Elasticsearch 的工作原理是将查询的词与倒排索引中的词进行匹配,查询的词和倒排索引中的词必须完全相同,否则匹配不上。 这意味着在索引和查询结果中分析过的字符串和未分析过的字符串会产生截然不同的结果。
使用 Term Query 查询 keyword 字段
因为字段数据类型和查询都没有被分析,所以它们都需要完全相同才能产生结果。
如果我们尝试使用完全相同的查询:
GET text-vs-keyword/_search
{
"query": {
"term": {
"keyword_field": {
"value": "The quick brown fox jumps over the lazy dog"
}
}
}
}上述命令返回的结果为:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "text-vs-keyword",
"_id": "fS95JoYBS2OSAePn1Qxh",
"_score": 0.2876821,
"_source": {
"keyword_field": "The quick brown fox jumps over the lazy dog",
"text_field": "The quick brown fox jumps over the lazy dog"
}
}
]
}
}显然之前写入的文档被搜索到了。如果我们尝试一些不准确的东西,即使倒排索引中有这个词:
GET text-vs-keyword/_search
{
"query": {
"term": {
"keyword_field": {
"value": "The"
}
}
}
}它没有返回任何结果,因为查询中的术语与倒排索引中的任何术语都不匹配。
使用 Match Query 查询 keyword 字段
让我们首先尝试使用 Match Query 对 keyword_field 查询相同的字符串 “The quick brown fox jumps over the lazy dog”,看看会发生什么:
GET text-vs-keyword/_search
{
"query": {
"match": {
"keyword_field": "The quick brown fox jumps over the lazy dog"
}
}
}结果应该是:
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "text-vs-keyword",
"_id": "fS95JoYBS2OSAePn1Qxh",
"_score": 0.2876821,
"_source": {
"keyword_field": "The quick brown fox jumps over the lazy dog",
"text_field": "The quick brown fox jumps over the lazy dog"
}
}
]
}
}等等,它不应该产生任何结果,因为查询时,针对查询的文字 “The quick brown fox jumps over the lazy dog” 需要进行分词。如果按照使用 standard 分词器对它进行分析,它产生的术语与倒排索引中的 “The quick brown fox jumps over the lazy dog” (这是一整个术语)不完全匹配,但为什么它会产生结果呢?
没错,查询被分析是因为我们使用的是 Match Query,但 Elasticsearch 使用的不是 standard 分析器,而是 index-time 分析器,它被映射到 keyword 字段数据类型。 由于与 keyword 字段数据类型映射的分词器是 keyword Analyzer,因此 Elasticsearch 在查询中没有任何改变。我们尝试使用 term analyzer 来试试:
GET _analyze
{
"analyzer": "keyword",
"text": "The quick brown fox jumps over the lazy dog"
}上述命令将生成:
{
"tokens": [
{
"token": "The quick brown fox jumps over the lazy dog",
"start_offset": 0,
"end_offset": 43,
"type": "word",
"position": 0
}
]
}可以见得,它就是只有一个 term。
现在,让我们尝试使用 standard 分析器:
GET text-vs-keyword/_search
{
"query": {
"match": {
"keyword_field": {
"query": "The quick brown fox jumps over the lazy dog",
"analyzer": "standard"
}
}
}
}在上面,我们定义了 analyzer。这个实际上是 search_analyer。请详细阅读 “Elasticsearch: analyzer”。上述命令将不会返回任何的结果。其原因显而易见,查询字符串的倒排术语和 keyword_field 字段里的术语完全不同。
使用 Term Query 查询 text 类型
正如我们在上一节中看到的那样,text 类型的索引文档将包含许多术语。 为了显示查询如何与倒排索引中的术语匹配,让我们尝试两个查询,第一个查询将整个句子发送到 Elasticsearch:
GET text-vs-keyword/_search
{
"query": {
"term": {
"text_field": {
"value": "The quick brown fox jumps over the lazy dog"
}
}
}
}由于使用 Term query 时,它不会对搜索的字符串 “The quick brown fox jumps over the lazy dog” 进行任何的分词,而 text_field 的倒排索引中没有这么长的完整术语。所以上述的查询不会有任何的结果。
我们再进行如下的查询:
GET text-vs-keyword/_search
{
"query": {
"term": {
"text_field": "The"
}
}
}这两个查询都没有结果。
第一个查询没有产生结果,因为在倒排索引中,我们从未存储过整个句子,索引过程只存储已经从文本中分块的术语。
第二个查询也没有产生任何结果。 索引文档中有一个“The”,但记住分析器将单词小写,所以在 Inverted Index 中,它存储为 the
让我们用 the 再次尝试 Term 查询:
GET text-vs-keyword/_search
{
"query": {
"term": {
"text_field": "the"
}
}
}是的! 它产生了一个结果,因为查询的 the 与倒排索引中的 the 完全匹配。
使用 Match query 查询 text 类型
现在是使用 Match Query 进行 text 类型处理的时候了,因为它会分析这两种类型,所以很容易让它们产生结果。 让我们先尝试两个查询:
- 第一个查询会将 The 发送到 Elasticsearch,我们知道使用 term query 不会产生任何结果,但是 match query 呢?
- 第二个查询将发送 the LAZ dog tripped over the QUICK brown dog,有些词在倒排索引中,有些不在,Elasticsearch 会从中产生任何结果吗?
GET text-vs-keyword/_search
{
"query": {
"match": {
"text_field": "The"
}
}
}
GET text-vs-keyword/_search
{
"query": {
"match": {
"text_field": "the LAZ dog tripped over th QUICK brown dog"
}
}
}是的! 两者都产生了结果:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.8339733,
"hits": [
{
"_index": "text-vs-keyword",
"_id": "fS95JoYBS2OSAePn1Qxh",
"_score": 1.8339733,
"_source": {
"keyword_field": "The quick brown fox jumps over the lazy dog",
"text_field": "The quick brown fox jumps over the lazy dog"
}
}
]
}
}第一个查询产生结果是因为查询中的 The 被分析并成为与倒排索引中的完全匹配的 the。
第二个查询,虽然并非所有术语都在倒排索引中,但仍会产生一个结果。 Elasticsearch 将返回一个结果,即使只有一个查询的术语与倒排索引中的术语完全匹配。
如果你注意结果,有一个 _score 字段。 有多少查询词与倒排索引中的词完全匹配是影响分数的因素之一。请阅读我的另外文章 “Elasticsearch:分布式计分”。
该选 text 还是 keyword 呢?
在以下情况下使用 keyword 字段数据类型:
- 你想要一个完全匹配查询
- 你想让 Elasticsearch 像其他数据库一样运行
- 你想用它来进行通配符查询
在以下情况下使用 text 字段数据类型:
- 你想创建一个自动完成
- 你想创建一个搜索系统
结论
了解 text 和 keyword 字段数据类型的工作原理是你想要在 Elasticsearch 中学习的内容之一,区别看似简单但很重要。
你需要了解并选择适合您的用例的字段数据类型,如果你需要两种字段数据类型,则可以在创建映射时使用 multi fields 功能。比如在我们上面已经创建的 text_and_keyword_mapping 字段。
最后,希望本文能帮助大家学习 Elasticsearch,了解 Elasticsearch 中 text 和 keyword 字段数据类型的区别。 谢谢阅读!