文章目录
一、Mini Batch K-Means 算法原理与实现 二、DBSCAN 密度聚类基本原理与实践 1. K-Means 聚类算法的算法特性 2. DBSCAN 密度聚类基本原理 3. DBSCAN 密度聚类的 sklearn 实现
除了 K-Means 快速聚类意外,还有两种常用的聚类算法。 (1) 是能够进一步提升快速聚类的速度的 Mini Batch K-Means 算法. (2) 则是能够和 K-Means 快速聚类形成性能上互补的算法 DBSCAN 密度聚类。
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib. pyplot as plt
from ML_basic_function import *
from sklearn. cluster import KMeans
K-Means 算法作为最常用的聚类算法,在长期的使用过程中也诞生了非常多的变种,典型的如提高迭代稳定性的二分 K 均值法、能够显著提升算法执行速度的 Mini Batch K-Means。 由于聚类算法的稳定性可以通过 k-means++ 以及多次迭代选择最佳划分方式等方法解决,此处重点介绍 Mini Batch K-Means 算法。 顾名思义,所谓 Mini Batch K-Means 算法,就是在 K-Means 基础上增加了一个 Mini Batch 的抽样过程,并且每轮迭代中心点时,不在带入全部数据、而是带入抽样的 Mini Batch 进行计算。即每一轮的迭代操作更新为 (1) 从数据集中随机抽取一些数据形成小批量,把他们分配给最近的质心; (2) 根据小批量数据划分情况,更新质心。 此处可以用梯度下降和小批量(Mini Batch)梯度下降之间的差异进行类比。 在梯度下降的过程中,我们带入全部数据构造损失函数,相当于带入全部数据进行参数的更新,就类似于 K-Means 带入每个簇的全部数据进行中心点位置计算。 而在小批量梯度下降的过程中,实际上我们是借助小批数据构造损失函数并对参数进行更新,就类似于 Mini Batch K-Means 中利用小批数据更新中心点。 而 Mini Batch K-Means 的有效性,其实也和小批量梯度下降的有效性类似,那就是对于一组规律连贯的数据集来说,小批量数据能够很大程度反映整体数据集规律,因此带入小批量数据进行计算是有效的。 此外,Mini Batch K-Means 相比 K-Means 的优劣势,也和小批量梯度下降对比梯度下降过程类似,采用小批数据带入进行计算能够极大缩短单次运算时间,因此迭代速度会更快,但由于小批量数据还是和整体数据之间存在差异,因此每次计算结果的精度不如带入整体数据的计算结果。 不过对于 K-Means 是否会落入局部最小值陷阱,我们可以通过 k-means++ 以及重复多次训练模型来解决,因此 Mini Batch K-Means 并不用承担跨越局部最小值陷阱的职责,所以 Mini Batch K-Means 对比 K-Means,其实就相当于牺牲了部分精度来换取聚类速度。 而聚类算法毕竟不是有监督学习算法,因此如果是面对海量数据的聚类,我们是可以考虑牺牲部分精度来换取聚类执行的速度的(当然这也要视情况而定)。 此处所谓小批量聚类精度不足,指的是小批量聚类和 K-Means 聚类结果上的差异,一般我们会认为 K-Means 聚类是精准的,而小批量聚类如果出现了和 K-Means 聚类不同的结果,则说明小批量聚类出现了误差,也就是精度不足。 接下来尝试调用相关评估器进行 Mini Batch K-Means 聚类: from sklearn. cluster import MiniBatchKMeans
我们发现,MiniBatchKMeans 中部分参数和 K-Means 中参数不同,我们针对这些不同的参数来进行解释。 MiniBatchKMeans?
Name Description batch_size 小批量抽样的数据量 compute_labels 在聚类完成后,是否对所有样本进行类别计算 max_no_improvement 当SSE不发生变化时,质心最多再迭代多少次 init_size 用于生成初始中心点的样本数量 reassignment_ratio 某比例,数值越大、样本数越少的簇被重新计算中心点的概率就越大
能够发现,MiniBatchKMeans 在参数设置上和 K-Means 有两方面差异: (1) 是在迭代收敛条件上,通过查看说明文档我们不难发现,MiniBatchKMeans 主要通过 max_no_improvement 和 max_iter 两个参数来控制收敛,在默认情况下不采用 tol 参数。其根本原因在于小批量聚类往往需要迭代很多轮,因而出实际未收敛、但现两次相邻的迭代结果中 SSE 变化值小于 tol 的情况的概率会显著增加,因此此时我们不能以 tol 条件作为收敛条件; (2) 是在控制结果精度上,尽管小批量聚类是用精度换速度,但仍然提供了可以提升聚类精度的参数,也就是 reassignment_ratio,当发现聚类结果不尽如人意时,可以适当提升该参数的取值。 接下来,尝试调用相关评估器进行建模: mbk = MiniBatchKMeans( n_clusters= 2 )
np. random. seed( 23 )
X, y = arrayGenCla( num_examples = 20 , num_inputs = 2 , num_class = 2 , deg_dispersion = [ 2 , 0.5 ] )
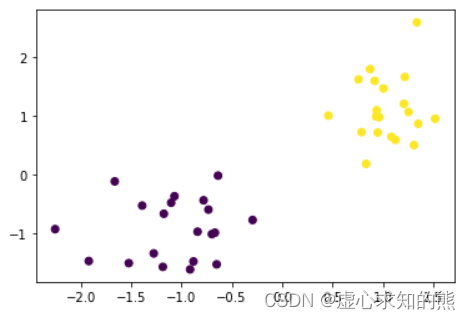
plt. scatter( X[ : , 0 ] , X[ : , 1 ] , c= y)
mbk. fit( X)
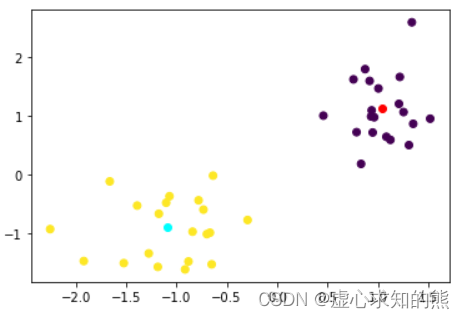
plt. scatter( X[ : , 0 ] , X[ : , 1 ] , c= mbk. labels_)
plt. plot( mbk. cluster_centers_[ 0 , 0 ] , mbk. cluster_centers_[ 0 , 1 ] , 'o' , c= 'red' )
plt. plot( mbk. cluster_centers_[ 1 , 0 ] , mbk. cluster_centers_[ 1 , 1 ] , 'o' , c= 'cyan' )
我们发现,在简单数据集的聚类过程中,MiniBatchKMeans 和 KMeans 并没有太大差异,接下来我们尝试在更大的数据集上来进行聚类,测试二者的精度和运算速度: np. random. seed( 23 )
X, y = arrayGenCla( num_examples = 1000000 , num_inputs = 10 , num_class = 5 , deg_dispersion = [ 4 , 1 ] )
km = KMeans( n_clusters= 5 , max_iter= 1000 )
mbk = MiniBatchKMeans( n_clusters= 5 , max_iter= 1000 )
import time
t0 = time. time( )
km. fit( X)
t_batch = time. time( ) - t0
t_batch
t0 = time. time( )
mbk. fit( X)
t_batch = time. time( ) - t0
t_batch
能够发现,MiniBatchKMeans 聚类速度明显快于 K-Means 聚类,接下来查看二者 SSE 来对比其精度: km. inertia_
mbk. inertia_
能够发现,MiniBatchKMeans 精度略低于 K-Means,但整体结果相差不大,基本可忽略不计,当然这也是因为当前数据集分类性能较好的原因。 不过经此也可验证 MiniBatchKMeans 聚类的有效性。一般来说,对于 2 万条以上的数据集,MiniBatchKMeans 聚类的速度优势就会逐渐显现。 当然,如果希望更进一步提高迭代速度,可以适度减少 batch_size、减少 reassignment_ratio、max_no_improvement 这三个参数,不过代价就是聚类的精度可能会进一步降低,而如果希望提高精度,则可以提升 reassignment_ratio 参数,不过相应的,运行时间将会有所提升。 尽管 MiniBatchKMeans 能够有效提高聚类速度、提升聚类效率,但从最终聚类效果上来看,MiniBatchKMeans 和 K-Means 聚类算法仍然属于同一类聚类——假设簇的边界是凸形的聚类。 换而言之,就是这种聚类能够较好的捕捉圆形/球形边界(直线边界可以看成是大直径的圆形边界),而对于非规则类边界,则无法进行较好的聚类,当然这也是和 K-Means 聚类的核心目的:让更相近同一个中线点的数据属于一个簇,息息相关。 但有些时候,更接近同一个中心点的数据却不一定应该属于一个簇,例如如下情况: from sklearn. datasets import make_moons
X, y = make_moons( 200 , noise= 0.05 , random_state= 24 )
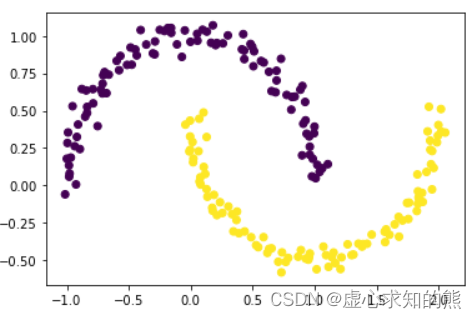
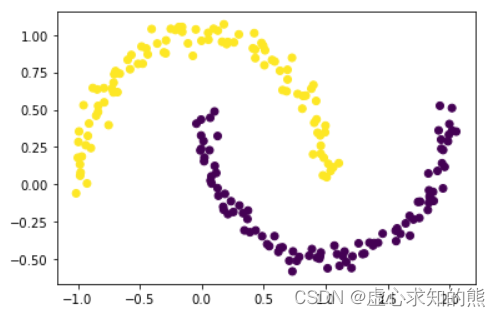
plt. scatter( X[ : , 0 ] , X[ : , 1 ] , c = y)
其中 make_moons 函数是 datasets 模块中创造数据集的函数,默认创建月牙形数据分布的数据集,并且 noise 参数取值越小、数据分布越贴近月牙形状。 当然此时我们发现,上述数据集明显可分为两个簇,但两个簇的边界却不是凸型的。此时如果我们用 K-Means 对其进行聚类,则会得到如下结果: km = KMeans( n_clusters= 2 )
km. fit( X)
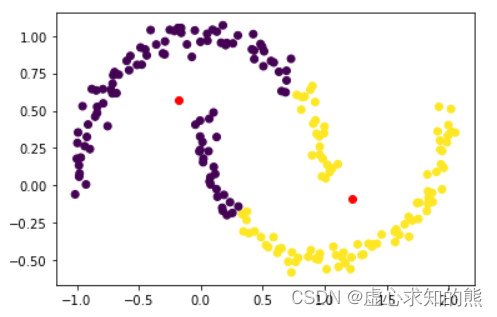
plt. scatter( X[ : , 0 ] , X[ : , 1 ] , c = km. labels_)
plt. plot( km. cluster_centers_[ : , 0 ] , km. cluster_centers_[ : , 1 ] , 'ro' )
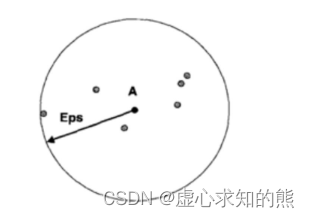
从上述结果中也能很明显的看出 K-Means 聚类的凸型边界,但很明显,此时聚类结果并不合理,上图中有多处彼此相邻但却不属于同一类的情况出现。 此时如果我们希望捕获上述非凸的边界,则需要使用一种基于密度的聚类方法,也就是我们将要介绍的 DBSCAN 密度聚类。 不过此处需要强调的是,尽管上述情况主观判断不太合理,但最终上述结果是否可用,还是需要结合实际业务进行考虑,这也是无监督学习算法没有统一的评价标准的具体表现。 此处我们只能说 K-Means 算法性能使得其无法捕获不规则边界,但这个特性导致的结果好坏无法直接通过数据结果进行得出。 和 K-Means 依据中心点划分数据集的思路不同,DBSCAN 聚类则是试图通过寻找特征空间中点的分布密度较低的区域作为边界,并进一步以此划分数据集。 正是因为以低密度区域作为边界,DBSCAN 最终对数据的划分边界很有可能是不规则的,从而突破了 K-Means 依据中心点划分数据集从而使得边界是凸型的限制。 当然对于给予密度的聚类算法,最重要的是给出密度的相关的定义。在 DBSCAN 中,我们通过两个概念和密度密切相关:分别是半径(eps)与半径范围内点的个数(num_samples)。 对于数据集中任意一个点,只要给定一个 eps,就能算出对应的 num_samples,例如对于下述 A 点,在一个 eps 范围内,num_samples 为 7(包括自己)。
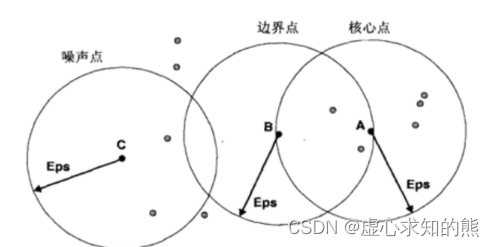
当然,eps 越小、num_samples 越大,则说明该点所在区域密度较高。 当然,我们可以据此设置一组参数,即半径(eps)和半径范围内至少包含多少点(min_samples)作为评估指标,来对数据集中不同的点进行密度层面的分类。 例如我们令 eps=Eps(某个数),min_samples=6,并且如果某点在一个 Eps 范围内包含的点的个数大于 min_samples,则称该点为核心点(core point),如下图中的 A 点。 而如果某个点不是核心点,但是在某个核心点的一个 eps 领域内,则称该点为边界点,例如下图 B 点。 而如果某点既不是核心点也不是边界点,则成该点为噪声点,如下图的 C 点。
当我们对数据集中的所有点完成上述三类的划分之后,接下来,我们一个 eps 范围内的核心点化为一个簇,并且将边界点划归到一个临近的核心点所属簇中,并且抛弃噪声点,最终完成数据集整体的划分。 而实际上 DBSCAN 整体划分过程,就是在将高密度区域划分成一个簇,将低密度区域视作不同簇的分界线。 很明显,在 DBSCAN 聚类中,核心参数就是 eps 和 min_samples,其不仅可以控制高低密度区域的划分,并且可以实际控制聚成几类的结果: 当 eps 较小而 min_samples 较大时,核心点的定义较为严格、同一个簇对簇内的密度要求更高,此时更容易划分出多个簇;反之,划分成的簇的个数可能会更少。 接下来我们尝试在 sklearn 进行 DBSCAN 建模试验。 from sklearn. cluster import DBSCAN
DBSCAN?
其中核心参数就是上面介绍的 eps 和 min_samples,其他参数都是距离计算相关和最近邻计算相关的参数,暂时可以不做考虑。接下来围绕上述月牙型数据进行建模:
DB = DBSCAN( eps= 0.3 , min_samples= 10 )
DB. fit( X)
plt. scatter( X[ : , 0 ] , X[ : , 1 ] , c = DB. labels_)
能够发现,DBSCAN 通过捕获低密度区域作为聚类划分的边界线,使得最终聚类结果和预想中的情况更加接近。接下来我们尝试在上一小节定义的数据集中执行 DBSCAN 聚类: np. random. seed( 23 )
X, y = arrayGenCla( num_examples = 20 , num_inputs = 2 , num_class = 2 , deg_dispersion = [ 2 , 0.5 ] )
plt. scatter( X[ : , 0 ] , X[ : , 1 ] , c= y)
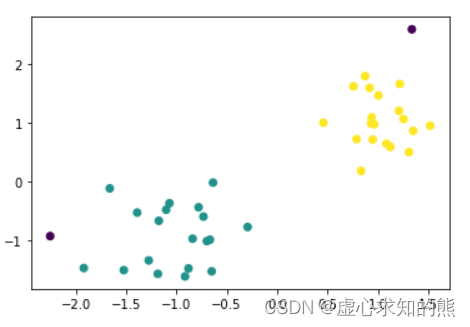
DB = DBSCAN( eps= 0.5 , min_samples= 5 ) . fit( X)
plt. scatter( X[ : , 0 ] , X[ : , 1 ] , c = DB. labels_)
DB. labels_
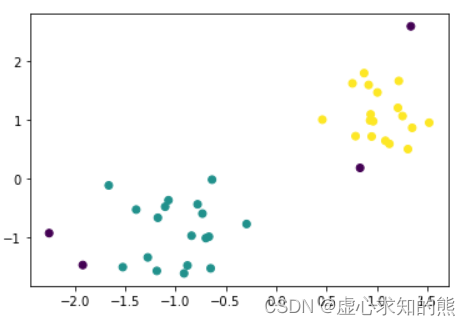
能够发现,DBSCAN 舍弃了一些点(噪声点,标签为 -1),并且将数据聚成两类。 当然我们也可以尝试减少 eps、提高 min_samples: DB = DBSCAN( eps= 0.4 , min_samples= 6 ) . fit( X)
plt. scatter( X[ : , 0 ] , X[ : , 1 ] , c = DB. labels_)
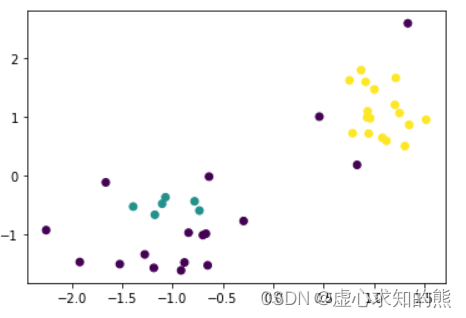
此时出现了更多的噪声点,而如果降低密度要求,则会有更多的点被划分到不同的簇中。 DB = DBSCAN( eps= 0.6 , min_samples= 4 ) . fit( X)
plt. scatter( X[ : , 0 ] , X[ : , 1 ] , c = DB. labels_)
至此,我们就完成了 DBSCAN 算法从理论到实践的全过程。 还是需要值得一提的是,由于聚类算法的特殊性,导致聚类算法本身的原理和应用难度都远低于有监督学习算法,并且在实际进行聚类的过程中,选择算法的过程要重于调参的过程,而且该过程需要加入实际业务背景作为聚类效果好坏评估的更加具体的指导意见。 目前介绍的 K-Means 和 DBSCAN,能够在实际分类性能上形成很好的互补,建议在使用的过程中先尝试 K-Means,如效果不佳,则可考虑尝试使用 DBSCAN 进行聚类。