Datawhale干货
作者:vaew,华中科技大学,博士二年级在读
简介
笔者vaew,21岁,现为华中科技大学机械科学与工程学院陶波教授课题组博士二年级学生。主要研究方向是基于视触融合的机器人灵巧操作。学业之余的研究兴趣包括图像分类,目标检测和AI攻防,获得2022年“移动云杯”算力网络大赛叉车周界行人检测专题第一名,2022 天池BMW Hackthon工业质检赛道第二名,2022 CCF-BDCI 基于TPU平台实现人群密度估计第三名等多个算法比赛top名次,相关的比赛方案后续有时间可能也会分享在Github上。本次主要分享在2022全球校园AI算法精英赛的车道线渲染质量评估赛道的Rank5方案。
个人Github地址:https://github.com/vaew
我们团队做这个比赛的时间有点靠后,差不多截止报名的时候才开始入场。我们刚开始做的时候,初赛只剩下一周的时间,因此整套方案的一些参数可能还没有很好的调整,初赛是A榜Rank3,B榜Rank7,后面决赛又调整了一些参数达到Rank5。个人认为针对此类问题的这套Pipeline应该是非常有效的,这也是我们能够卡在ddl弯道超车的重要原因。下面分享一下我们队伍对本次比赛的理解和详细方案。
赛题分析
本赛题为选手提供地图渲染数据及其部分标注。训练集包括车道渲染数据的图片集及部分标注,选手使用训练数据进行模型训练。测试集分为A/B两个测试集。测试集仅提供车道渲染数据图片集,选手使用模型预测测试图片是否存在问题。整个比赛的缺陷数据一共如下7类(中心线问题、停止线问题、引导面问题、路肩问题、路面问题、箭头问题、车道线问题),选手并不需要对这7类分别进行分类,只需要检测渲染的车道线图像数据是否存在问题即可。
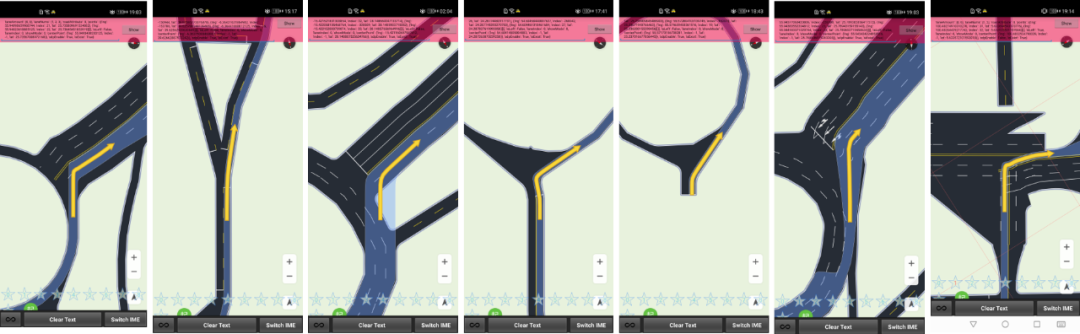
不同异常图像一览
这是一个很典型的异常图像分类问题,我们的第一想法是直接用图像分类模型+挖掘一些缺陷图像上明显的视觉特征,然后通过模板匹配之类的机器视觉方案来做。
于是我们提取了这7类缺陷中视觉上看有明显特征的路肩问题、路面问题,抽取了两个问题类别的10个样本中路肩突出区域/路面异常区域的10*10像素块,作为模板匹配的模板,但是匹配一轮后发现这样的匹配其实不能有效涨点。
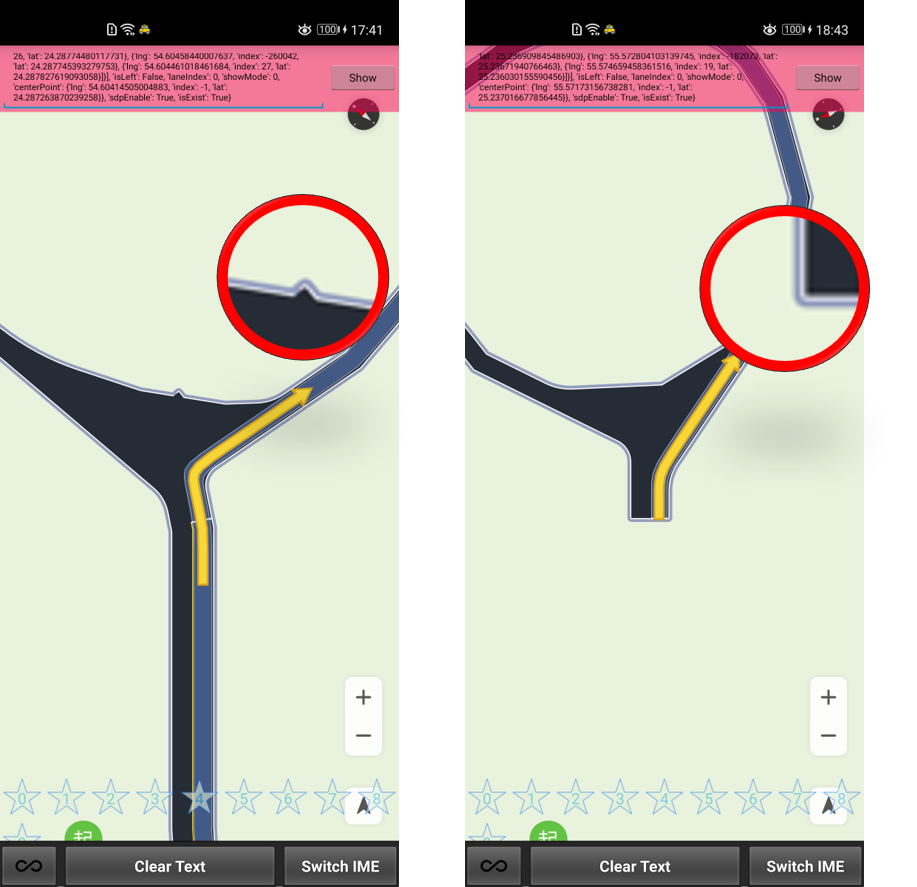
具有“显著特征”的路肩问题、路面问题
因此我们对数据进行了新一轮的分析,发现原因在于整个图像中出现问题的地方相对于整体的区域实际上特征是比较弱的。整个赛题有如下的难点:
1)图像特征弱:本赛题中车道线渲染数据变换复杂,不同缺陷类别图像没有明显的有区分性的特征,同时缺陷数据相比于正常数据而言也没有非常明显的有区分性的特征,因此难以实现鲁棒性高图像分类。
2)数据规模小:本赛题车道线渲染数据数据规模相对于传统图像分类数据集来说较小,保证模型收敛到最优精度困难。
3)语义理解难:本赛题标识较多,渲染问题复杂,分类模型对于图像的语义理解能力有限,难以对不同渲染问题进行高精度的判定。
同时,还有非常值得选手注意的一点是本次比赛中给出了一个相对于有标注训练数据集来说非常大的无标注数据集,如何对这样一个无标注数据集进行有效处理也是本次比赛的一大难点。
获取本文PPT可在后台回复“华为大赛ppt”
基本解题思路
确定了不能通过大量机器视觉中常见的特征工程手段来做之后,我们拿出了解决图像分类问题的一套经典的Pipeline,我们希望在这套Pipeline上进行深挖,最终实现比较好的分类效果。
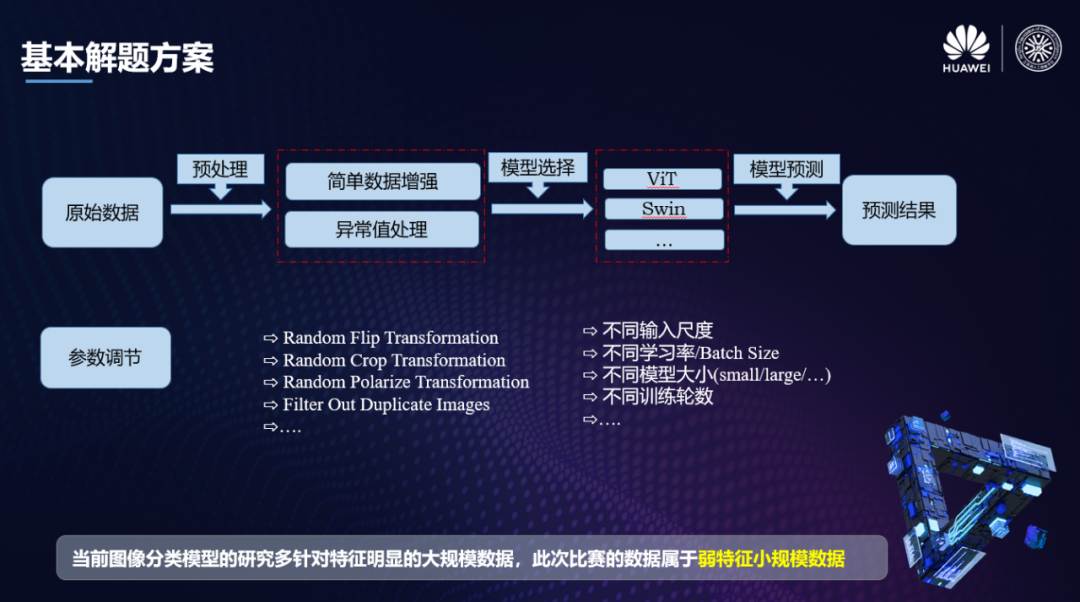
基本解题思路
诚如这张ppt上说的,这样一套pipeline在特征明显的大规模数据上是会取得非常好的效果的,但是本次比赛的数据属于弱特征小规模数据,我们需要进行更多的方案上的探索。
尝试思路&最终方案
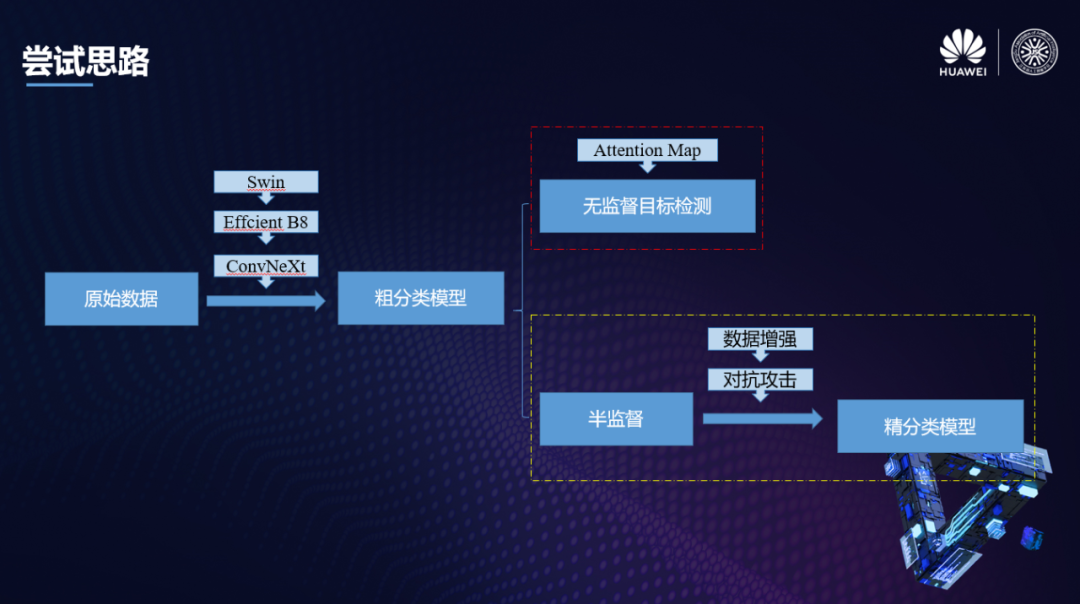
失败了一半的尝试思路 or 成功的数据增强方案
事实上,本次比赛给了一个相比于有标注训练集而言规模很大的无标注的训练集。因此,如何构建一套有效的方案赋予这些未标注的训练集合适的伪标签是很重要的。我们的第一个基本思路是首先基于Swin Transformer[1], EffcientNet-B8[2], ConvNeXt[3],Deit[4]等十分强劲的Backbone构建一个粗分类Ensemble模型,然后用这个Ensemble模型来做无监督的目标检测。
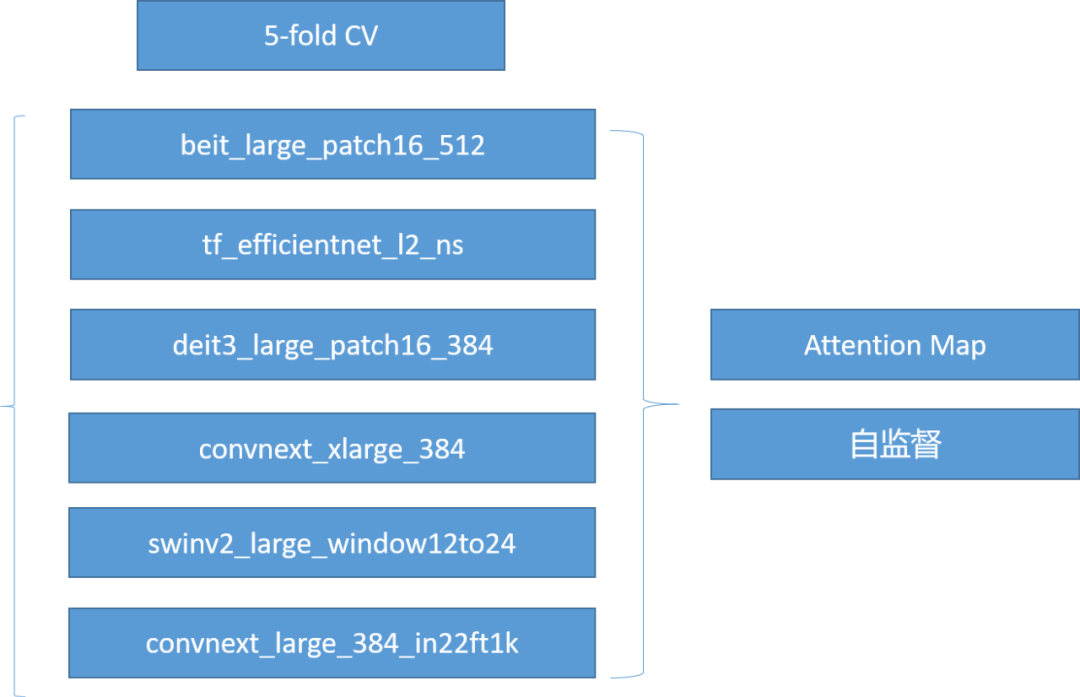
多模融合构建自监督模型
更具体的,我们提取粗分类Ensemble模型的Attention Map,使用非常经典的DDT[5]方法来对Attention Map进而得到一个注意力最集中的区域作为我们认为的伪缺陷区域。
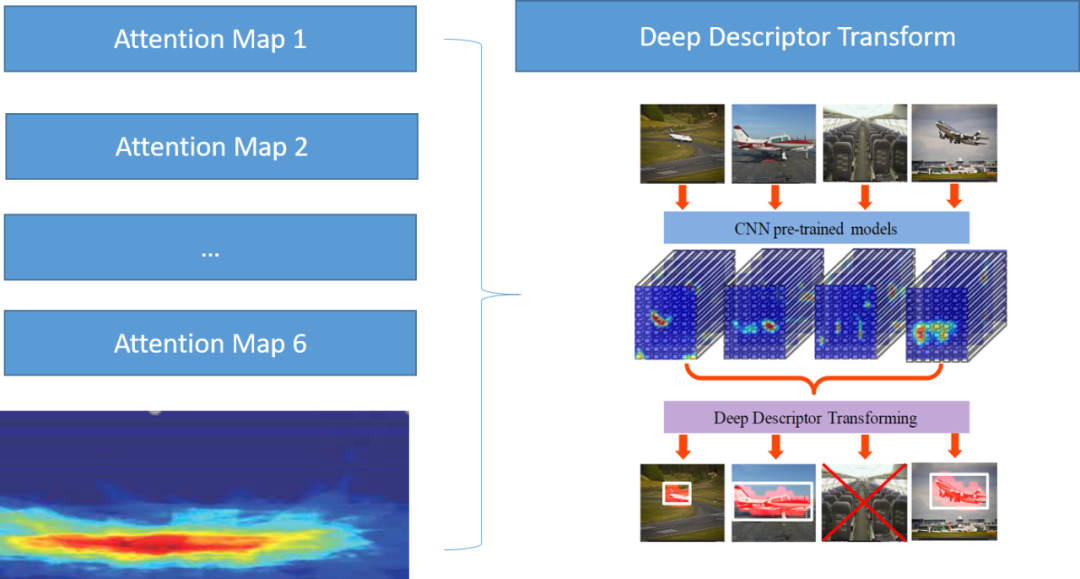
自监督目标检测
遗憾的是这样的尝试思路和之前我们尝试基于模板匹配等机器视觉方法的异常图像检测trick一样,没有取得非常好的效果。但是这条尝试思路严格来说失败了一半,因为它在后面的数据增强过程中实际上是非常有效的。
我们发现本题中1/3类缺陷图像数目较少,我们对1/3类原始图像进行这样的自监督目标检测,之后将DDT方法标注出来的缺陷框进行随机的Copy&Paste&Shift,最终实现了针对这两类数据的增强。
成功的尝试思路 and 最终的方案
尝试了上面说的自监督目标检测方案,发现行不通之后我们进行了黄框中的思路的尝试。我们使用之前说的粗分类模型来做半监督,赋予无标注数据一个比较准确的伪标签。然后用打了伪标签的数据和赛方给的有标注数据集进行训练。并在整个训练过程中加了很多的提分Trick,下面将会将所有的提分Trick列出分享。
提分亮点
这里我们将提分Tricks分为三个部分:数据增强,训练增强和推理优化。
数据增强
我们认为好的数据增强方案应该是能促进模型对于整个异常检测任务的现实意义的理解,同时我们也认为不产生真实生产环境下不可能出现的奇异图像的数据增强才可能让模型学到一些物理层面有用的东西,而非图像的噪声。所以与其他选手不同,我们最终使用的所有的数据增强方法都不会产生奇异的车道线渲染图像。如:使用MixUp[6]等方式将不同类别的两张图像生硬的叠加,我们认为是一种不太正确的策略,我们更倾向于使用能够保持图像语义特征的Mix方式。同样的RandomShuffle等对图像块的直接Shuffle操作也不在我们考虑的范围内,我们使用一些语义上的Shuffle或者Shift方式来对整个图像进行增强操作。
下面是我们具体采用的数据增强方式,我们通过这些数据增强手段来提高模型鲁棒性和泛化能力。
Texture Feature Transformation
为了在不改变数据语义特征的同时进一步提高模型的鲁棒性,我们首先想到的就是对图像的纹理特征进行增强。更具体的,这里我们使用HSV通道互换,对比度增强,亮度增强等方式对图像的纹理特征进行增强。
Shape Transformation
除了对图像的纹理特征进行增强,我们还考虑了一些不产生异常图像的形状变换增强思路。此处我们使用Random Flip Transformation,Elastic Shape Transformation进行图像形状增强,以期得到更多的不同结构的异常图像。
Image Shift
如前所述,由于本题中1/3类缺陷图像数目较少,我们基于DDT检测结果对1/3类原始图像做一定的随机shift,生成一些新的数据,用于模型的训练
TokenMix
此处为了不产生奇异的Mixup等方式混合生成的图像,我们引入TokenMix[7]方法。这是一种token级增强技术,可以很好地应用于训练各种基于transformer的架构。TokenMix在token级别直接混合两个图像,以促进输入token的交互,并在考虑图像语义信息的情况下生成更合理的目标
Auto Augmentation
此外,我们使用针对ImageNet的Auto data augmentation工具箱[8],进行数据增强。值得注意的是此处删掉了可能生成奇异图像的数据增强。
训练增强
在训练增强上,我们引入了多种训练技巧保证模型最终收敛到最优值。此处在具体的训练过程中我们发现有标注数据和无标注数据的分布、线上数据和线下数据的分布其实都是很不一致。我们还发现线上的数据其实是更接近于无标注数据的数据,因此我们的比较重要的一个训练增强手段就是进行模型的域适应学习,下面将从域适应学习方法开始,一一介绍我们的训练增强策略。
域适应学习
此处我们使用有标注数据作为源域,无标注数据作为目标域。使用Ganin[9]等人提出的经典的域适应学习网络来进行领域自适应。使用的网络结构如下图,由三部分组成:特征映射网络 ,标签分类网络和域判别网络。
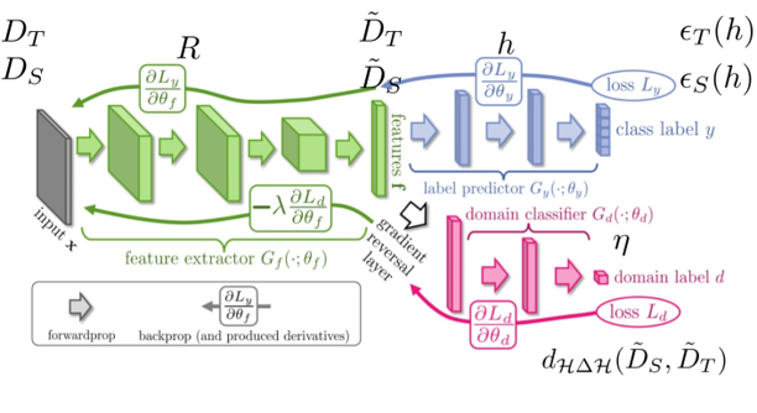
域适应学习Pipeline
交叉熵损失函数
这里我们其实使用了很多种不同的Loss进行模型的调优,最终发现还是使用分类模型中最为常见的交叉熵损失函数进行模型的训练,因为它在实际实验中效果较好。
Cosine Annealing Warm Restarts
这里我们采用的是等间隔的退火策略,验证准确率总是会在学习率的最低点达到一个很好的效果,而随着学习率回升,验证精度会有所下降。最终可以实现稳定的模型收敛。
Stochastic Weight Averaging
这里我们使用一个比较经典的随机权值平均策略。随机权值平均只需快速集合集成的一小部分算力,就可以接近其表现。随机权值平均可以用在任意架构和数据集上,都会有不错的表现。
Adaptive Adversarial Training
这个其实是我博士期间的一小部分工作,即通过自适应对抗攻击的方法对模型添加扰动[10]。目前文章已经投稿相关期刊,并挂在了Arxiv上,感兴趣的可以参阅 Adaptive adversarial training method for improving multi-scale GAN based on generalization bound theory
推理优化
由于我们使用的是一个多模型Ensemble的分类方案,而且由于线上线下数据分布不均,所以在最后的下游推理过程中其实是有很多的工作可以做的。
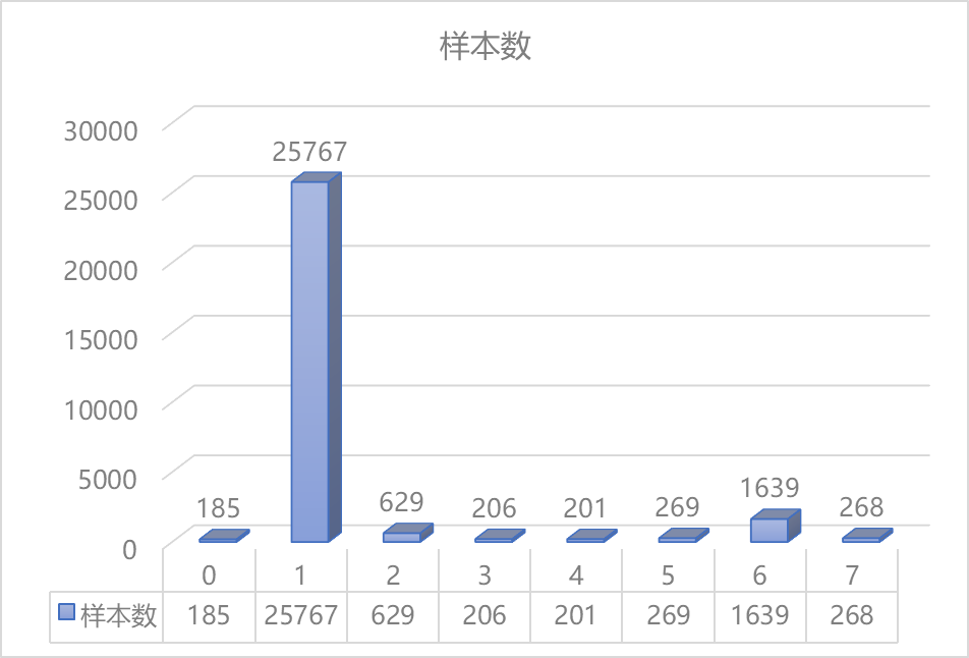
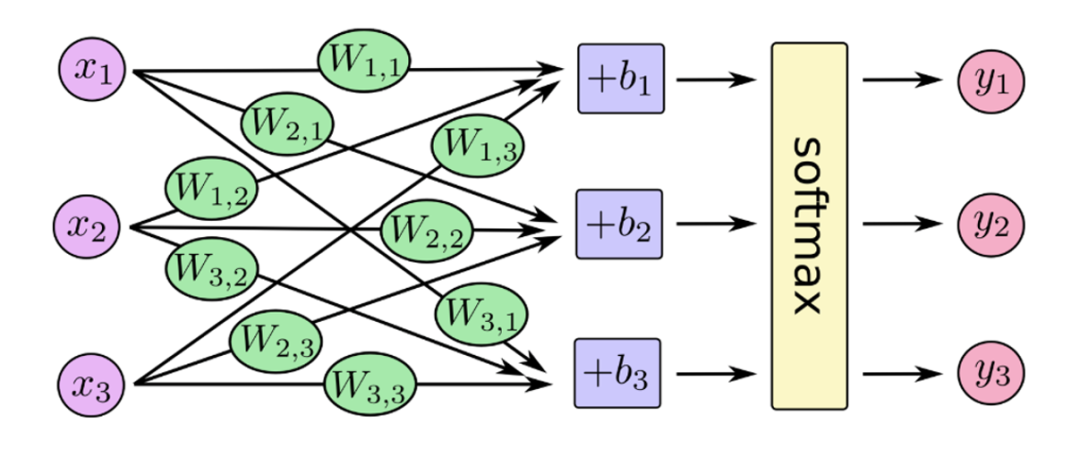
SoftMax加权输出
前面对类别数据进行统计我们发现其实每一类的分布是比较不均的,同时从线上线下以及有标注无标注数据的数据分布我们也可以发现数据分布不一致这个问题还是挺严重的。因此此处我们使用了一个非常简单粗暴的方法,我们固定训练好的模型的权重,然后直接根据数据分布不均的特点,对softmax层进行加权输出。
SoftMax加权输出
多模型反Sigmoid融合
比赛的评估指标是AUC,因此我们首先考虑了模型的加权融合和Rank融合,但是发现效果没有那么的理想。我们分析原因发现可能是不同模型预测的结果非常接近,因此这样的融合其实对整个预测结果精度的提升不会有那么大的帮助。此处我们首先对模型的预测结果进行rank排序,之后将排序结果进行归一化。我们将归一化后的值输入反Sigmoid函数进行映射,之后对映射的结果进行加权融合,得到最终的推理结果。
反Sigmoid函数的函数曲线如下图所示,可以看到这样的曲线可以极大地放大靠近预测概率位于0.5附近的预测值差距,进而实现对非常接近的预测结果的有效融合。
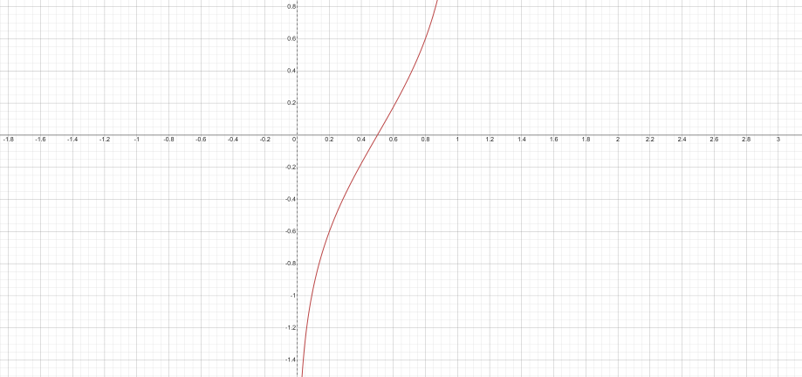
反Sigmoid函数曲线
方案总结
最后我们对整个方案进行总结的话,可以把我们的主要贡献概括为如下四点:
1 构建了一种针对车道线渲染数据半监督学习方法
2 设计了域适应方案用于车道线问题分类模型的增强
3 使用多模型Sigmoid融合进行车道线问题的估计
4 使用多种数据增强手段和训练技巧实现高精度、高鲁棒性的车道线渲染数据分类模型
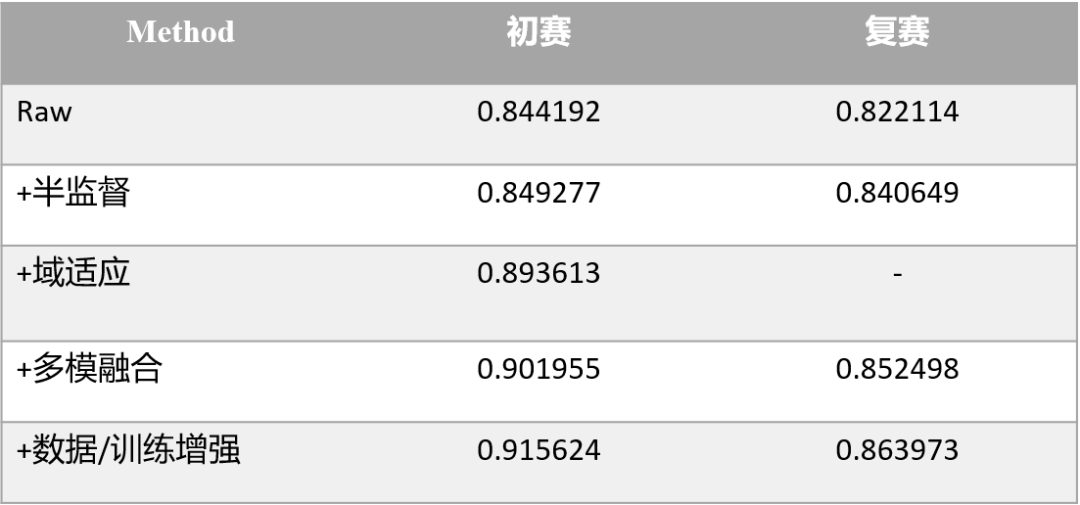
不同策略的效果
方案展望

后续优化思路展望
参考文献
[1] Liu, Ze, et al. "Swin transformer: Hierarchical vision transformer using shifted windows." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[2] Tan, Mingxing, and Quoc Le. "Efficientnet: Rethinking model scaling for convolutional neural networks." International conference on machine learning. PMLR, 2019.
[3] Liu, Zhuang, et al. "A convnet for the 2020s." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[4] Touvron, Hugo, et al. "Training data-efficient image transformers & distillation through attention." International Conference on Machine Learning. PMLR, 2021.
[5] Wei, Xiu-Shen, et al. "Deep descriptor transforming for image co-localization." arXiv preprint arXiv:1705.02758 (2017).
[6] Zhang, Hongyi, et al. "mixup: Beyond empirical risk minimization." arXiv preprint arXiv:1710.09412 (2017).
[7] Liu, Jihao, et al. "Tokenmix: Rethinking image mixing for data augmentation in vision transformers." European Conference on Computer Vision. Springer, Cham, 2022.
[8] Cubuk, Ekin D., et al. "Autoaugment: Learning augmentation policies from data." arXiv preprint arXiv:1805.09501 (2018).
[9] Ganin, Yaroslav, and Victor Lempitsky. "Unsupervised domain adaptation by backpropagation." International conference on machine learning. PMLR, 2015.
[10] Tang, Jing, et al. "Adaptive adversarial training method for improving multi-scale GAN based on generalization bound theory." arXiv preprint arXiv:2211.16791 (2022).
获取完整PPT请在后台回复“华为大赛ppt”
 开源分享,点赞三连↓
开源分享,点赞三连↓