自动驾驶:BEV开山之作LSS(lift,splat,shoot)原理代码串讲
- 前言
- Lift
- 参数
- 创建视锥
- CamEncode
- Splat
- 转换视锥坐标系
- Voxel Pooling
- 总结
前言

目前在自动驾驶领域,比较火的一类研究方向是基于采集到的环视图像信息,去构建BEV视角下的特征完成自动驾驶感知的相关任务。所以如何准确的完成从相机视角向BEV视角下的转变就变得由为重要。目前感觉比较主流的方法可以大体分为两种:
- 显式估计图像的深度信息,完成BEV视角的构建,在某些文章中也被称为自下而上的构建方式;
- 利用transformer中的query查询机制,利用BEV Query构建BEV特征,这一过程也被称为自上而下的构建方式;
LSS最大的贡献在于:提供了一个端到端的训练方法,解决了多个传感器融合的问题。传统的多个传感器单独检测后再进行后处理的方法无法将此过程损失传进行反向传播而调整相机输入,而LSS则省去了这一阶段的后处理,直接输出融合结果。
Lift
参数
我们先介绍一下一些参数:
感知范围
x轴方向的感知范围 -50m ~ 50m;y轴方向的感知范围 -50m ~ 50m;z轴方向的感知范围 -10m ~ 10m;
BEV单元格大小
x轴方向的单位长度 0.5m;y轴方向的单位长度 0.5m;z轴方向的单位长度 20m;
BEV的网格尺寸
200 x 200 x 1;
深度估计范围
由于LSS需要显式估计像素的离散深度,论文给出的范围是 4m ~ 45m,间隔为1m,也就是算法会估计41个离散深度,也就是下面的dbound。
why dbound:
因为二维像素可以理解为现实世界中的某一个点到相机中心的一条射线,我们如果知道相机的内外参数,就是知道了对应关系,但是我们不知道是射线上面的那一个点(也就是不知道depth),所以作者在距离相机5m到45m的视锥内,每隔1m有一个模型可选的深度值(这样每个像素有41个可选的离散深度值)。
代码如下:
ogfH=128
ogfW=352
xbound=[-50.0, 50.0, 0.5]
ybound=[-50.0, 50.0, 0.5]
zbound=[-10.0, 10.0, 20.0]
dbound=[4.0, 45.0, 1.0]
fH, fW = ogfH // 16, ogfW // 16
创建视锥
什么是视锥?
代码:
def create_frustum(self):
# make grid in image plane
ogfH, ogfW = self.data_aug_conf['final_dim']
fH, fW = ogfH // self.downsample, ogfW // self.downsample
ds = torch.arange(*self.grid_conf['dbound'], dtype=torch.float).view(-1, 1, 1).expand(-1, fH, fW)
D, _, _ = ds.shape
xs = torch.linspace(0, ogfW - 1, fW, dtype=torch.float).view(1, 1, fW).expand(D, fH, fW)
ys = torch.linspace(0, ogfH - 1, fH, dtype=torch.float).view(1, fH, 1).expand(D, fH, fW)
# D x H x W x 3
frustum = torch.stack((xs, ys, ds), -1)
return nn.Parameter(frustum, requires_grad=False)
根据代码可知,它的尺寸是根据一个2dimage构建的,它的尺寸为D * H * W * 3,维度3表示:【 x,y,depth】。我们可以把这个视锥理解为一个长方体,长x,宽y 高depth,视锥中的每个点都是长方体的坐标。
CamEncode
这部分主要是通过Efficient Net来提取图像的features,首先看代码:
class CamEncode(nn.Module):
def __init__(self, D, C, downsample):
super(CamEncode, self).__init__()
self.D = D
self.C = C
self.trunk = EfficientNet.from_pretrained("efficientnet-b0")
self.up1 = Up(320+112, 512)
# 输出通道数为D+C,D为可选深度值个数,C为特征通道数
self.depthnet = nn.Conv2d(512, self.D + self.C, kernel_size=1, padding=0)
def get_depth_dist(self, x, eps=1e-20):
return x.softmax(dim=1)
def get_depth_feat(self, x):
# 主干网络提取特征
x = self.get_eff_depth(x)
# 输出通道数为D+C
x = self.depthnet(x)
# softmax编码,相理解为每个可选深度的权重
depth = self.get_depth_dist(x[:, :self.D])
# 深度值 * 特征 = 2D特征转变为3D空间(俯视图)内的特征
new_x = depth.unsqueeze(1) * x[:, self.D:(self.D + self.C)].unsqueeze(2)
return depth, new_x
def forward(self, x):
depth, x = self.get_depth_feat(x)
return x
起初与以往的相同,到了init函数的最后一句,把feature的channel下采样到了 D +C,D与上面的视锥的D一致,用来储存深度特征,C为图像的语义特征,然后对channel为D的那部分在执行softmax 用来预测depth的概率分布,然后把D这部分与C这部分单独拿出来让二者做外积,就得到了shape为BNDCHW的feature。
demo代码如下:
a = torch.ones(36*4).resize(4,6,6)+1
demo1 = a.unsqueeze(1)
print(demo1.shape)
b = torch.ones(36*4).resize(4,6,6)+3
demo2 = b.unsqueeze(0)
print(demo2.shape)
c = demo1*demo2
print(c.shape)
torch.Size([4, 1, 6, 6])
torch.Size([1, 4, 6, 6])
torch.Size([4, 4, 6, 6])
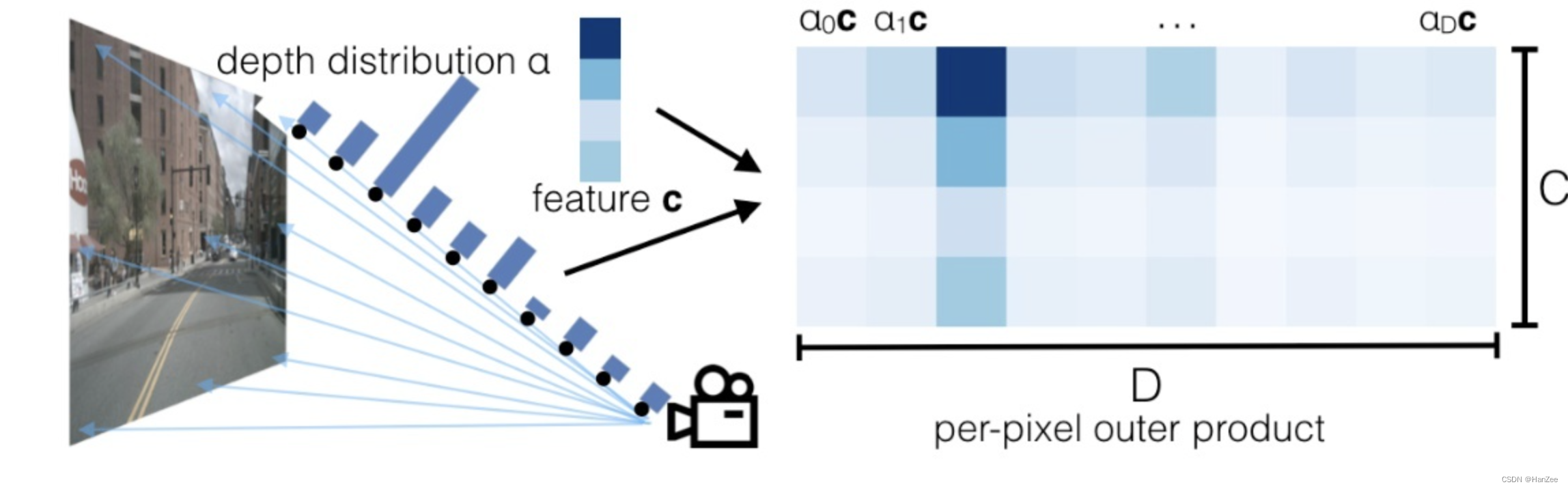
我们观察右面的网格图,首先解释一下网格图的坐标,其中a代表某一个深度softmax概率(大小为H * W),c代表语义特征的某一个channel的feature,那么ac就表示这两个矩阵的对应元素相乘,于是就为feature的每一个点赋予了一个depth 概率,然后广播所有的ac,就得到了不同的channel的语义特征在不同深度(channel)的feature map,经过训练,重要的特征颜色会越来越深(由于softmax概率高),反之就会越来越暗淡,趋近于0.
Splat
得到了带有深度信息的feature map,那么我们想知道这些特征对应3D空间的哪个点,我们怎么做呢?
由于我们的视锥对原图做了16倍的下采样,而在上面得到feature map的感受野也是16,那么我们可以在接下来的操作把feature map映射到视锥坐标下。
转换视锥坐标系
首先我们之前得到了一个2D的视锥,现在通过相机的内外参数把它映射到车身(以车中心为原点)坐标系。
代码如下:
def get_geometry(self, rots, trans, intrins, post_rots, post_trans):
B, N, _ = trans.shape # B: batch size N:环视相机个数
# undo post-transformation
# B x N x D x H x W x 3
# 抵消数据增强及预处理对像素的变化
points = self.frustum - post_trans.view(B, N, 1, 1, 1, 3)
points = torch.inverse(post_rots).view(B, N, 1, 1, 1, 3, 3).matmul(points.unsqueeze(-1))
# 图像坐标系 -> 归一化相机坐标系 -> 相机坐标系 -> 车身坐标系
# 但是自认为由于转换过程是线性的,所以反归一化是在图像坐标系完成的,然后再利用
# 求完逆的内参投影回相机坐标系
points = torch.cat((points[:, :, :, :, :, :2] * points[:, :, :, :, :, 2:3],
points[:, :, :, :, :, 2:3]
), 5) # 反归一化
combine = rots.matmul(torch.inverse(intrins))
points = combine.view(B, N, 1, 1, 1, 3, 3).matmul(points).squeeze(-1)
points += trans.view(B, N, 1, 1, 1, 3)
# (bs, N, depth, H, W, 3):其物理含义
# 每个batch中的每个环视相机图像特征点,其在不同深度下位置对应
# 在ego坐标系下的坐标
return points
Voxel Pooling
代码:
def voxel_pooling(self, geom_feats, x):
# geom_feats;(B x N x D x H x W x 3):在ego坐标系下的坐标点;
# x;(B x N x D x fH x fW x C):图像点云特征
B, N, D, H, W, C = x.shape
Nprime = B*N*D*H*W
# 将特征点云展平,一共有 B*N*D*H*W 个点
x = x.reshape(Nprime, C)
# flatten indices
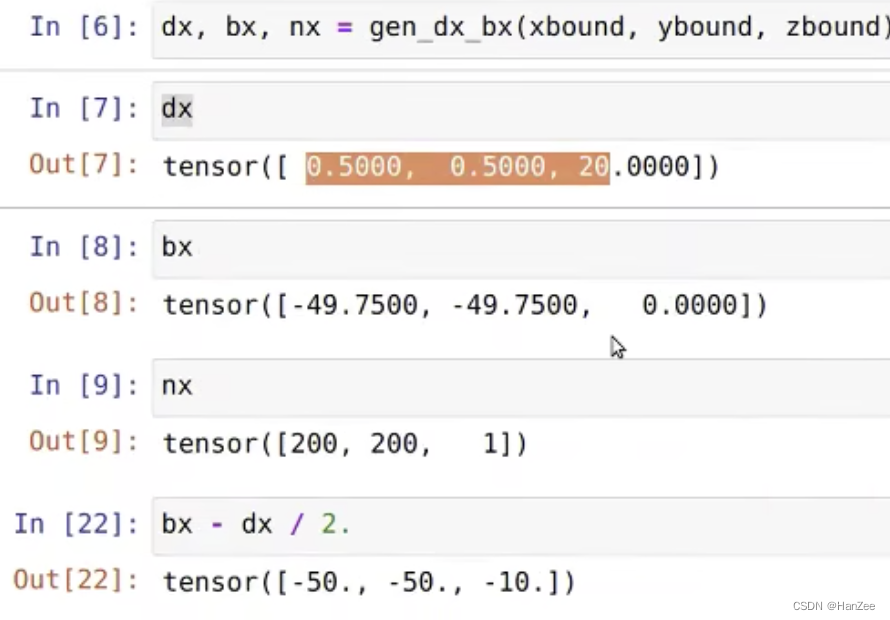
geom_feats = ((geom_feats - (self.bx - self.dx/2.)) / self.dx).long() # ego下的空间坐标转换到体素坐标(计算栅格坐标并取整)
geom_feats = geom_feats.view(Nprime, 3) # 将体素坐标同样展平,geom_feats: (B*N*D*H*W, 3)
batch_ix = torch.cat([torch.full([Nprime//B, 1], ix,
device=x.device, dtype=torch.long) for ix in range(B)]) # 每个点对应于哪个batch
geom_feats = torch.cat((geom_feats, batch_ix), 1) # geom_feats: (B*N*D*H*W, 4)
# filter out points that are outside box
# 过滤掉在边界线之外的点 x:0~199 y: 0~199 z: 0
kept = (geom_feats[:, 0] >= 0) & (geom_feats[:, 0] < self.nx[0])\
& (geom_feats[:, 1] >= 0) & (geom_feats[:, 1] < self.nx[1])\
& (geom_feats[:, 2] >= 0) & (geom_feats[:, 2] < self.nx[2])
x = x[kept]
geom_feats = geom_feats[kept]
# get tensors from the same voxel next to each other
ranks = geom_feats[:, 0] * (self.nx[1] * self.nx[2] * B)\
+ geom_feats[:, 1] * (self.nx[2] * B)\
+ geom_feats[:, 2] * B\
+ geom_feats[:, 3] # 给每一个点一个rank值,rank相等的点在同一个batch,并且在在同一个格子里面
sorts = ranks.argsort()
x, geom_feats, ranks = x[sorts], geom_feats[sorts], ranks[sorts] # 按照rank排序,这样rank相近的点就在一起了
# cumsum trick
if not self.use_quickcumsum:
x, geom_feats = cumsum_trick(x, geom_feats, ranks)
else:
x, geom_feats = QuickCumsum.apply(x, geom_feats, ranks)
# griddify (B x C x Z x X x Y)
final = torch.zeros((B, C, self.nx[2], self.nx[0], self.nx[1]), device=x.device) # final: bs x 64 x 1 x 200 x 200
final[geom_feats[:, 3], :, geom_feats[:, 2], geom_feats[:, 0], geom_feats[:, 1]] = x # 将x按照栅格坐标放到final中
# collapse Z
final = torch.cat(final.unbind(dim=2), 1) # 消除掉z维
return final # final: bs x 64 x 200 x 200
总结
优点:
1.LSS的方法提供了一个很好的融合到BEV视角下的方法。基于此方法,无论是动态目标检测,还是静态的道路结构认知,甚至是红绿灯检测,前车转向灯检测等等信息,都可以使用此方法提取到BEV特征下进行输出,极大地提高了自动驾驶感知框架的集成度。
2.虽然LSS提出的初衷是为了融合多视角相机的特征,为“纯视觉”模型而服务。但是在实际应用中,此套方法完全兼容其他传感器的特征融合。如果你想融合超声波雷达特征也不是不可以试试。
缺点:
1.极度依赖Depth信息的准确性,且必须显示地提供Depth 特征。当然,这是大部分纯视觉方法的硬伤。如果直接使用此方法通过梯度反传促进Depth网络的优化,如果Depth 网络设计的比较复杂,往往由于反传链过长使得Depth的优化方向比较模糊,难以取得较好效果。当然,一个好的解决方法是先预训练好一个较好的Depth权重,使得LSS过程中具有较为理想的Depth输出。
2.外积操作过于耗时。虽然对于机器学习来说,这样的计算量不足为道,但是对于要部署到车上的模型,当图片的feature size 较大, 且想要预测的Depth距离和精细度高时,外积这一操作带来的计算量则会大大增加。这十分不利于模型的轻量化部署,而这一点上,Transformer的方法反而还稍好一些。