前言
driver和executor心跳机制分为两种机制:
1、executor发送心跳机制
2、driver接受心跳机制
至于为何要分为两种,原因是在分布式场景中,服务的稳定性是无法保障的,例如executor宕机后无法发送心跳,故driver端需要有executor心跳超时机制,同样如果是driver端宕机或者GC导致executor无法成功发送心跳,那么executor也有自己的超时结束进程的机制
1、executor心跳机制
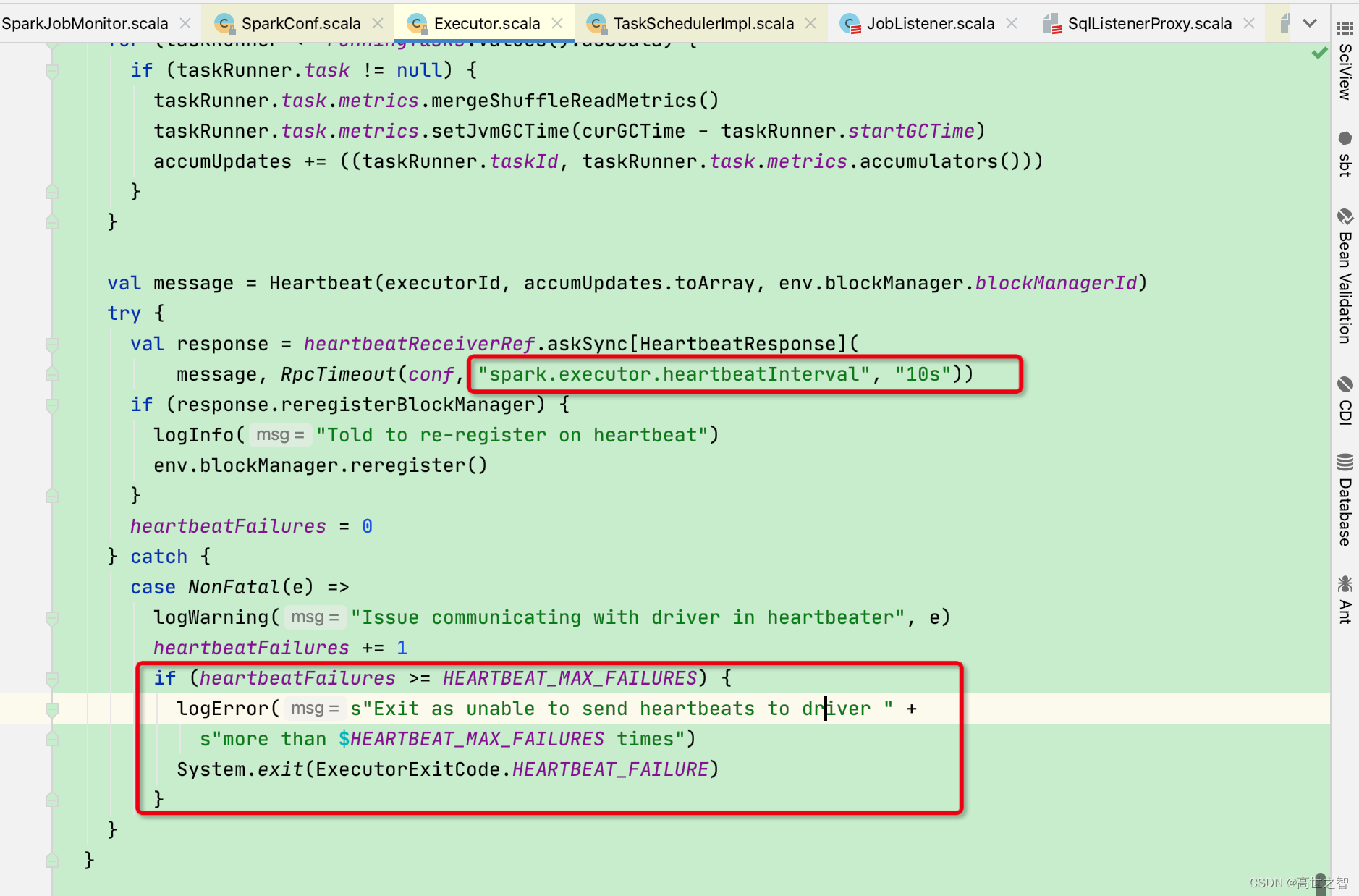
executor向driver发送心跳的间隔默认[spark.executor.heartbeatInterval]:10s
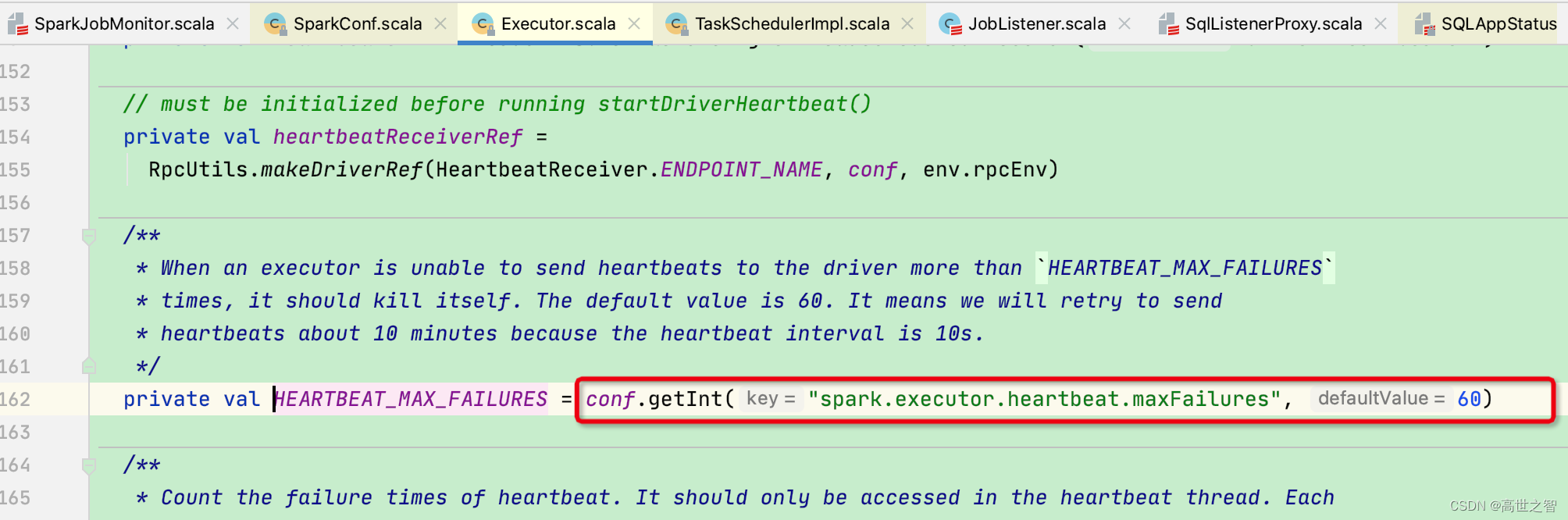
心跳异常次数超过默认阈值[spark.executor.heartbeat.maxFailures]:60次
当超过阈值后executor会自杀,意味着executor会重试发送大约10分钟的心跳,但大部分不会发送到10分钟
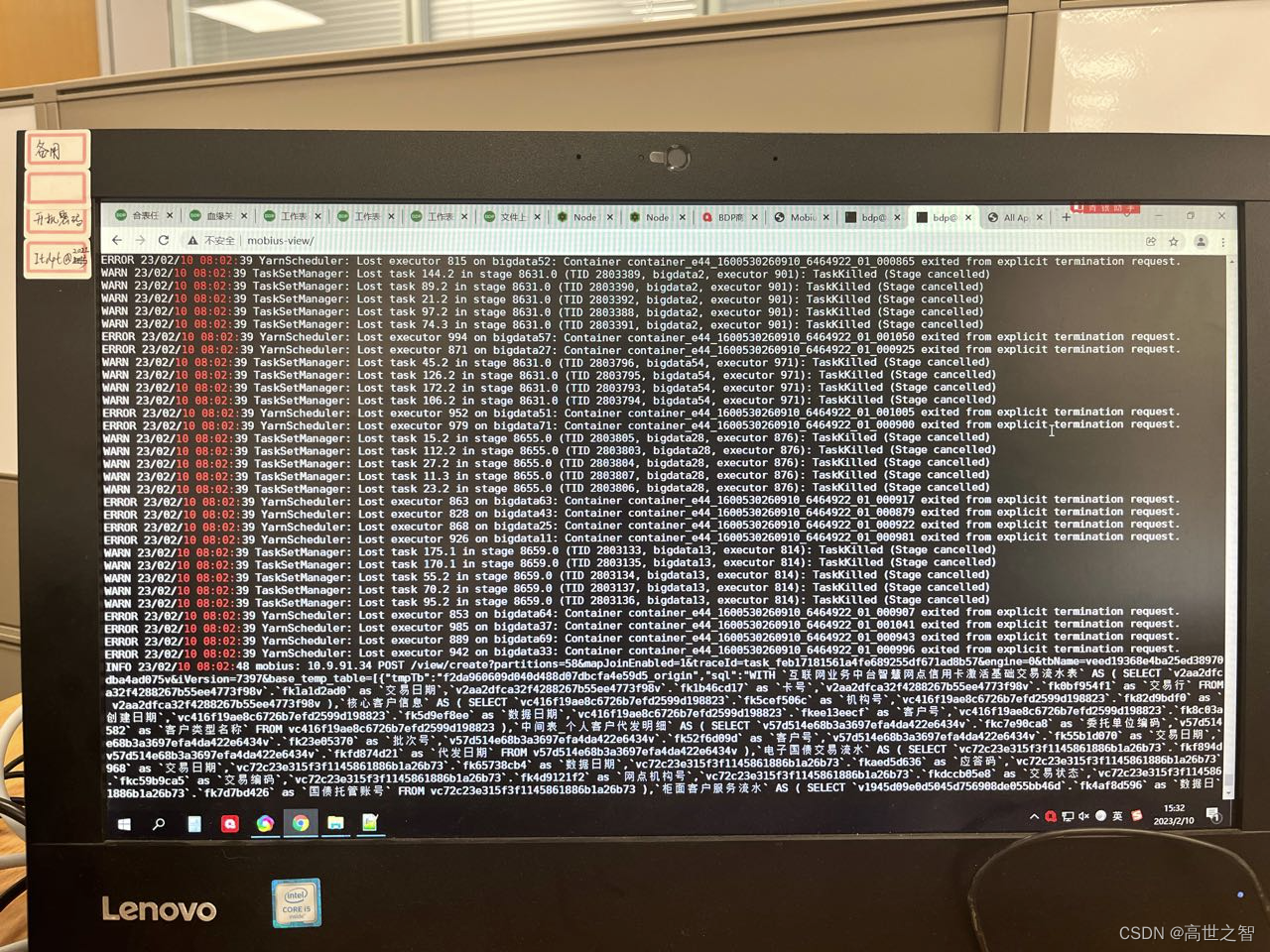
因为driver在120s内没有接收到executor的请求后就会主动杀死executor进程[dirver心跳机制],所以10分钟的场景适用于driver端挂掉的情况下executor自杀,退出错误码为56。
executor自动退出码:56

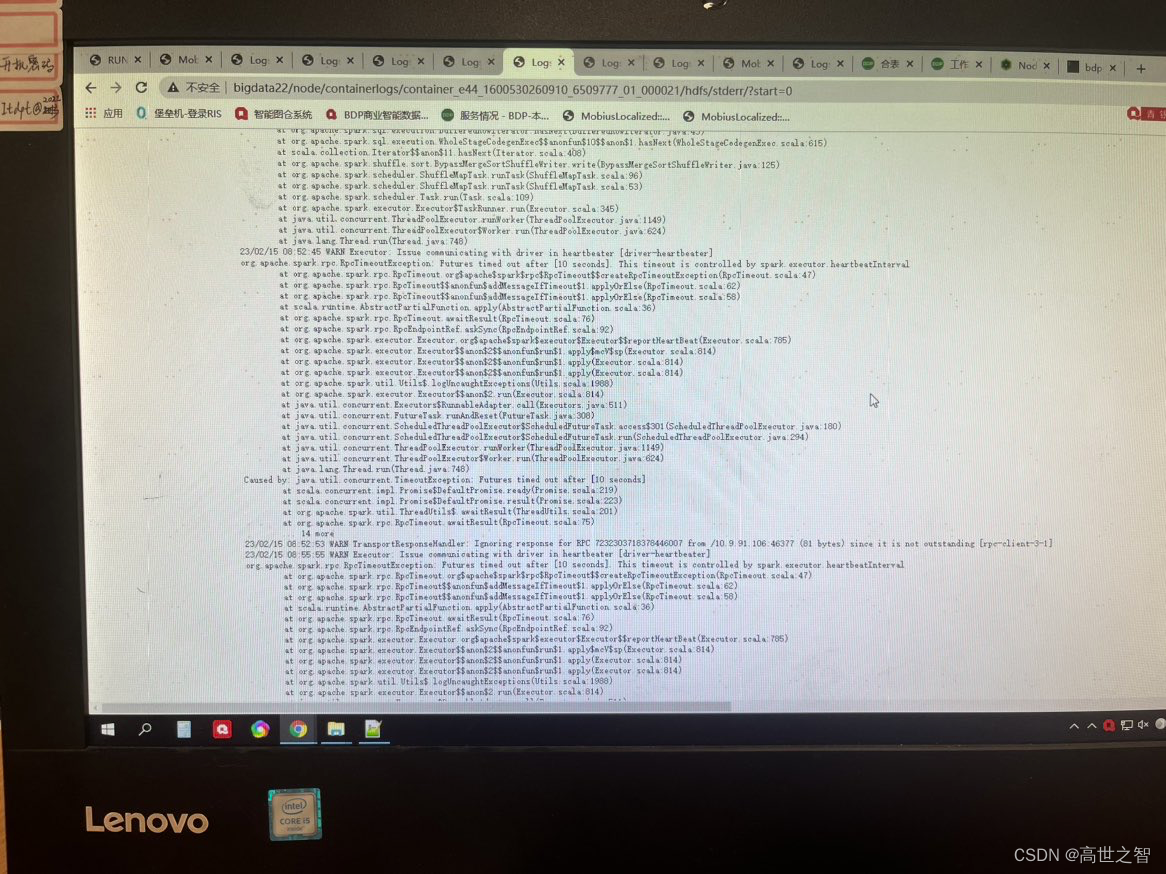
例如下图:生产中executor连接超时日志
2、driver心跳机制
driver对executor心跳的检测机制:当driver端检测到executor最后一次心跳时间距今超过了[spark.network.timeout]120s,则启动一个线程杀死executor进程[杀死的过程是请求集群管理器进行处理]
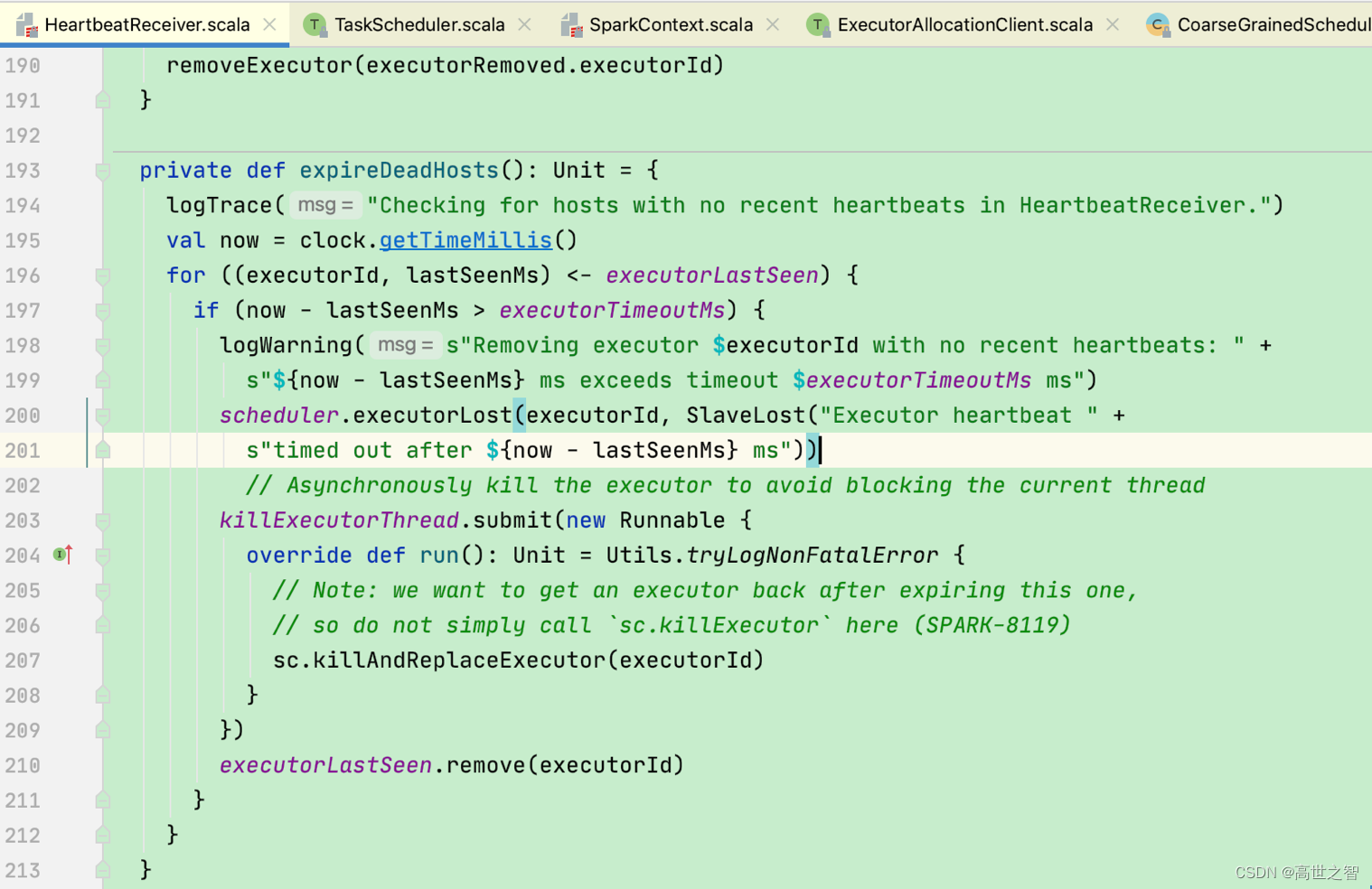
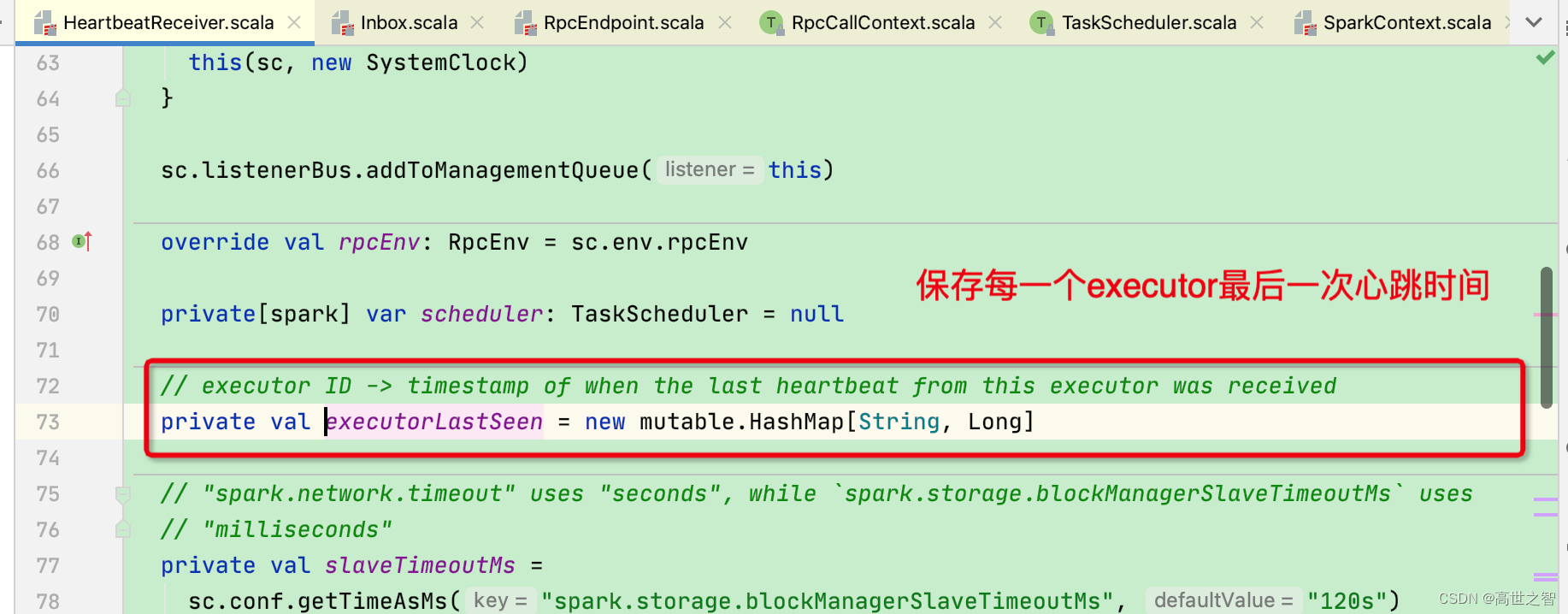
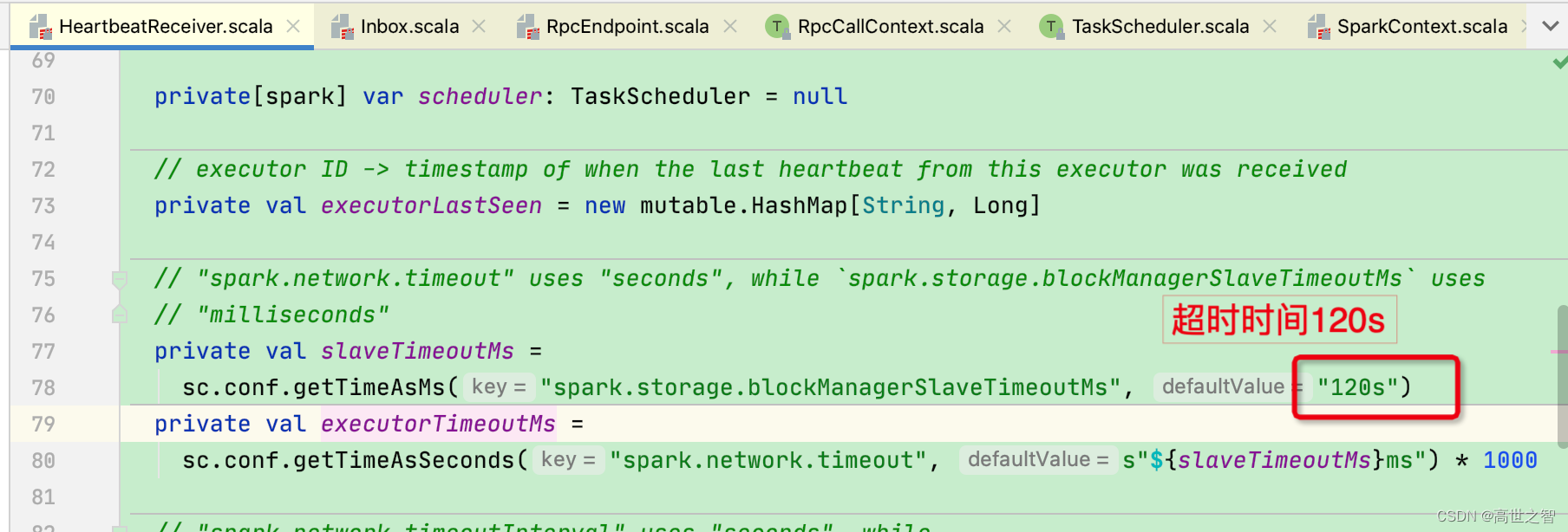
此时executor被杀死后的退出码应该是:143
生产中driver日志: