筛选最佳参数:
# 对于max_depth和min_child_weight查找最好的参数
param_grid = { 'max_depth':range(3,10,2),'min_child_weight':range(1,6,2)}
model = XGBClassifier(learning_rate =0.1,n_estimators=100,max_depth=5,
use_label_encoder=False,min_child_weight=1,gamma=0,
subsample=0.8,colsample_bytree=0.8,
objective='binary:logistic',
nthread=4,scale_pos_weight=1,seed=27,verbosity = 0)
gsearch1 = GridSearchCV(estimator = model,param_grid = param_grid,
scoring='roc_auc',n_jobs=-1, cv=5)
gsearch1.fit(train[cols],train[target])
print('本次筛选最佳参数:',gsearch1.best_params_)
print('最佳得分是:',gsearch1.best_score_)
'''
本次筛选最佳参数: {'max_depth': 5, 'min_child_weight': 3}
最佳得分是: 0.8417229752667561
'''4、Xgboost模型使用
4.1、数据介绍
根据用户一些信息,进行算法建模,判断用户是否可以按时进行还款!
字段信息如下:
| 字段 | 说明 |
|---|---|
| Disbursed | 是否还款 |
| Existing_EMI | 每月还款金额 |
| Loan_Amount_Applied | 贷款金额 |
| Loan_Tenure_Applied | 贷款期限 |
| Monthly_Income | 月收入 |
| …… | …… |
4.2、导包
import pandas as pd
import numpy as np
import xgboost as xgb
from xgboost import XGBClassifier
from sklearn import model_selection, metrics
from sklearn.model_selection import GridSearchCV
import matplotlib.pylab as plt
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 12, 44.3、加载数据
train = pd.read_csv('train_modified.csv')
test = pd.read_csv('test_modified.csv')
# 删除ID字段,对建模没有实际意义
train.drop(labels = 'ID',axis = 1,inplace = True)
test.drop(labels = 'ID',axis = 1,inplace = True)
# 声明训练数据字段和目标值字段
target = 'Disbursed'
cols = [x for x in train.columns if x not in [target]]4.4、构建训练函数
def modelfit(model, dtrain, dtest, cols,useTrainCV=True, cv_folds=5, early_stopping_rounds=50):
# 训练数据交叉验证
if useTrainCV:
xgb_param = model.get_xgb_params()
xgb_train = xgb.DMatrix(dtrain[cols].values, label=dtrain[target].values)
xgb_test = xgb.DMatrix(dtest[cols].values)
cvresult = xgb.cv(xgb_param, xgb_train, num_boost_round = model.get_params()['n_estimators'],
nfold=cv_folds,early_stopping_rounds = early_stopping_rounds,
verbose_eval=False)
model.set_params(n_estimators=cvresult.shape[0])
# 建模
model.fit(dtrain[cols], dtrain['Disbursed'],eval_metric='auc')
# 对训练集预测
y_ = model.predict(dtrain[cols])
proba_ = model.predict_proba(dtrain[cols])[:,1] # 获取正样本
# 输出模型的一些结果
print('该模型表现:')
print('准确率 (训练集): %.4g' % metrics.accuracy_score(dtrain['Disbursed'],y_))
print('AUC 得分 (训练集): %f' % metrics.roc_auc_score(dtrain['Disbursed'],proba_))
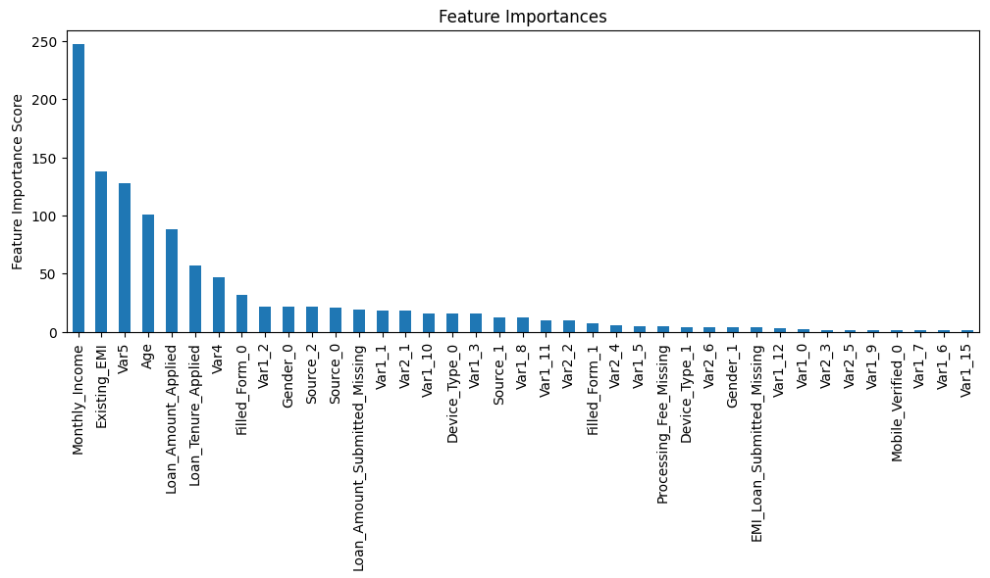
# 特征重要性
feature_imp = pd.Series(model.get_booster().get_fscore()).sort_values(ascending=False)
feature_imp.plot(kind='bar', title='Feature Importances')
plt.ylabel('Feature Importance Score')函数说明:
-
训练数据建模 交叉验证
-
根据Xgboost交叉验证更新 n_estimators
-
数据建模
-
求训练准确率
-
求训练集AUC二分类ROC-AUC 二分类ROC-AUC二分类ROC-AUC
-
画出特征的重要度
4.5、建模交叉验证筛选最佳参数 (n_estimators)
xgb1 = XGBClassifier(learning_rate =0.1,
use_label_encoder=False,
n_estimators=50,
max_depth=5,
min_child_weight=1,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
objective= 'binary:logistic',
nthread=4,
scale_pos_weight=1,
reg_alpha = 0,
verbosity = 0)
modelfit(xgb1, train, test, cols)该模型表现:
准确率 (训练集): 0.9854
AUC 得分 (训练集): 0.867372
4.6、条件筛选
4.6.1、参数筛选一
# 对于max_depth和min_child_weight查找最好的参数
param_grid = { 'max_depth':range(3,10,2),'min_child_weight':range(1,6,2)}
model = XGBClassifier(learning_rate =0.1,n_estimators=100,max_depth=5,
use_label_encoder=False,min_child_weight=1,gamma=0,
subsample=0.8,colsample_bytree=0.8,
objective='binary:logistic',
nthread=4,scale_pos_weight=1,seed=27,verbosity = 0)
gsearch1 = GridSearchCV(estimator = model,param_grid = param_grid,
scoring='roc_auc',n_jobs=-1, cv=5)
gsearch1.fit(train[cols],train[target])
print('本次筛选最佳参数:',gsearch1.best_params_)
print('最佳得分是:',gsearch1.best_score_)
'''
本次筛选最佳参数: {'max_depth': 5, 'min_child_weight': 3}
最佳得分是: 0.8417229752667561
'''4.6.2、参数筛选二
%%time
# 筛选合适的gamma:惩罚项系数,指定节点分裂所需的最小损失函数下降值
param_grid = {'gamma':[i/10.0 for i in range(0,5)]}
model = XGBClassifier(learning_rate =0.1,n_estimators=100,max_depth=5,
use_label_encoder=False,min_child_weight=3,gamma=0,
subsample=0.8,colsample_bytree=0.8,
objective= 'binary:logistic',nthread=4,
scale_pos_weight=1,seed=27,verbosity = 0)
gsearch2 = GridSearchCV(estimator = model,param_grid = param_grid,
scoring='roc_auc',n_jobs=4, cv=5)
gsearch2.fit(train[cols],train[target])
print('本次筛选最佳参数:',gsearch2.best_params_)
print('最佳得分是:',gsearch2.best_score_)
'''
本次筛选最佳参数: {'gamma': 0.0}
最佳得分是: 0.8417229752667561
Wall time: 37.9 s
'''4.7.3、参数筛选三
%%time
# 对subsample 和 colsample_bytree用grid search寻找最合适的参数
param_grid = {'subsample':[i/10.0 for i in range(6,10)],
'colsample_bytree':[i/10.0 for i in range(6,10)]}
model = XGBClassifier(learning_rate =0.1,
n_estimators=100,max_depth=5,use_label_encoder=False,
min_child_weight=3,gamma=0,subsample=0.8,
colsample_bytree=0.8,
objective= 'binary:logistic',
nthread=4,scale_pos_weight=1,seed=1024,
verbosity = 0)
gsearch3 = GridSearchCV(estimator = model,param_grid = param_grid,
scoring='roc_auc',n_jobs=-1,cv=5)
gsearch3.fit(train[cols],train[target])
print('本次筛选最佳参数:',gsearch3.best_params_)
print('最佳得分是:',gsearch3.best_score_)
'''
本次筛选最佳参数: {'colsample_bytree': 0.8, 'subsample': 0.8}
最佳得分是: 0.8427440100917339
Wall time: 2min 10s
'''4.6.4、参数筛选四
%%time
# 对reg_alpha用grid search寻找最合适的参数
param_grid = {'reg_alpha':[1e-5, 1e-2, 0.1, 1, 100]}
model = XGBClassifier(learning_rate =0.1,n_estimators=100,
max_depth=5,use_label_encoder=False,
min_child_weight=3,gamma=0,subsample=0.8,
colsample_bytree=0.8,
objective= 'binary:logistic',nthread=4,
scale_pos_weight=1,seed=1024,verbosity = 0)
gsearch4 = GridSearchCV(estimator = model,param_grid = param_grid,
scoring='roc_auc',n_jobs=-1,cv=5)
gsearch4.fit(train[cols],train[target])
print('本次筛选最佳参数:',gsearch4.best_params_)
print('最佳得分是:',gsearch4.best_score_)
'''
本次筛选最佳参数: {'reg_alpha': 1}
最佳得分是: 0.8427616879925267
Wall time: 39.9 s
'''最佳条件是:
- max_depth = 5
- min_child_weight = 3
- gamma = 0
- subsample = 0.8
- colsample_bytree = 0.8
- reg_alpha = 1
4.7、建模验证新参数效果
xgb2 = XGBClassifier(learning_rate =0.1,
use_label_encoder=False,
n_estimators=100,
max_depth=5,
min_child_weight=3,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
reg_alpha = 1,
objective= 'binary:logistic',
nthread=4,
scale_pos_weight=1,
eval_metric=['error','auc'],
verbosity = 0)
modelfit(xgb2, train, test, cols)
'''
该模型表现:
准确率 (训练集): 0.9854
AUC 得分 (训练集): 0.879929
'''4.7.1 调整学习率
xgb3 = XGBClassifier(learning_rate =0.2,
use_label_encoder=False,
n_estimators=100,
max_depth=5,
min_child_weight=3,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
reg_alpha = 1,
objective= 'binary:logistic',
nthread=4,
scale_pos_weight=1,
eval_metric=['error','auc'],
verbosity = 0)
modelfit(xgb3, train, test, cols)
'''
该模型表现:
准确率 (训练集): 0.9855
AUC 得分 (训练集): 0.907529
'''