强化学习的三种方法
基于价值(value-based)
基于策略(policy-based)
基于模型(model-based)
一 基于价值的方法
基于价值 (Value-Based)这种方法,目标是优化价值函数V(s)。
价值函数会告诉我们,智能体在每个状态里得出的未来奖励最大预期 (maximum expected future reward) 。
一个状态下的函数值,是智能体可以预期的未来奖励积累总值,从当前状态开始算。
智能体要用这个价值函数来决定,每一步要选择哪个行动。它会采取函数值最大的那个行动。
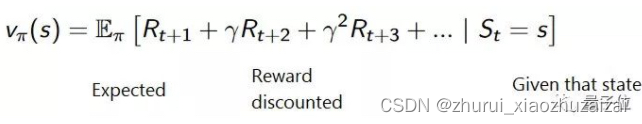
二 基于策略的方法
这种方式,会直接优化策略函数π(s),抛弃价值函数。
策略就是评判智能体在特定时间点的表现。把每一个状态和它所对应的最佳行动建立联系。
策略分为两种,
· 确定性策略:某一个特定状态下的策略,永远都会给出同样的行动。
· 随机性策略:策略给出的是多种行动的可能性分布。

从图中我们可以看到,策略直接指出了每一步的最佳行动。
三 基于模型的方法
这种方法是对环境建模。这表示,我们要创建一个模型,来表示环境的行为。
问题是,每个环境都会需要一个不同的模型 (马里奥每走一步,都会有一个新环境) 。这也是这个方法在强化学习中并不太常用的原因。
四 强化学习表示
S(State) = 环境, 例如迷宫的每一格是一个state
A(Actions) = 动作, 在每个状态下。有什么行动是允许的,例如迷宫中行走的方向{上,下,左,右}
R(Rewards) = 奖励, 进入每个状态时,能带来正面或负面的价值。
P(Policy) = 方案。由一个状态->行动的函数。
(S,A,R)是使用者设定的,P是算法自动计算出来的