限流算法
限流顾名思义,就是对请求或并发数进行限制;通过对一个时间窗口内的请求量进行限制来保障系统的正常运行。如果我们的服务资源有限、处理能力有限,就需要对调用我们服务的上游请求进行限制,以防止自身服务由于资源耗尽而停止服务
在限流中有两个概念需要了解。
- 阈值:在一个单位时间内允许的请求量。如 QPS限制为10,说明 1 秒内最多接受 10 次请求。
- 拒绝策略:超过阈值的请求的拒绝策略,常见的拒绝策略有直接拒绝、排队等待等。
限流就是控制网络接口发送或接收请求的速率,它可防止DoS攻击和限制Web爬虫。
1. 计数器(固定窗口)算法
计数器算法是使用计数器在周期内累加访问次数,当达到设定的限流值时,触发限流策略。下一个周期开始时,进行清零,重新计数。
此算法在单机还是分布式环境下实现都非常简单,使用redis的incr原子自增性和线程安全即可轻松实现。

这个算法通常用于QPS限流和统计总访问量,对于秒级以上的时间周期来说,会存在一个非常严重的问题,那就是临界问题
假设1min内服务器的负载能力为100,因此一个周期的访问量限制在100,然而在第一个周期的最后5秒和下一个周期的开始5秒时间段内,分别涌入100的访问量,虽然没有超过每个周期的限制量,但是整体上10秒内已达到200的访问量,已远远超过服务器的负载能力,由此可见,计数器算法方式限流对于周期比较长的限流,存在很大的弊端。
优缺点:
- 优点:简单粗暴,单机在 Java 中可用 Atomic 等原子类、分布式就 Redis incr。
- 缺点:假设我们允许的阈值是1万,此时计数器的值为0, 当1万个请求在前1秒内一股脑儿的都涌进来,这突发的流量可是顶不住的。缓缓的增加处理和一下子涌入对于程序来说是不一样的。
2. 滑动窗口算法
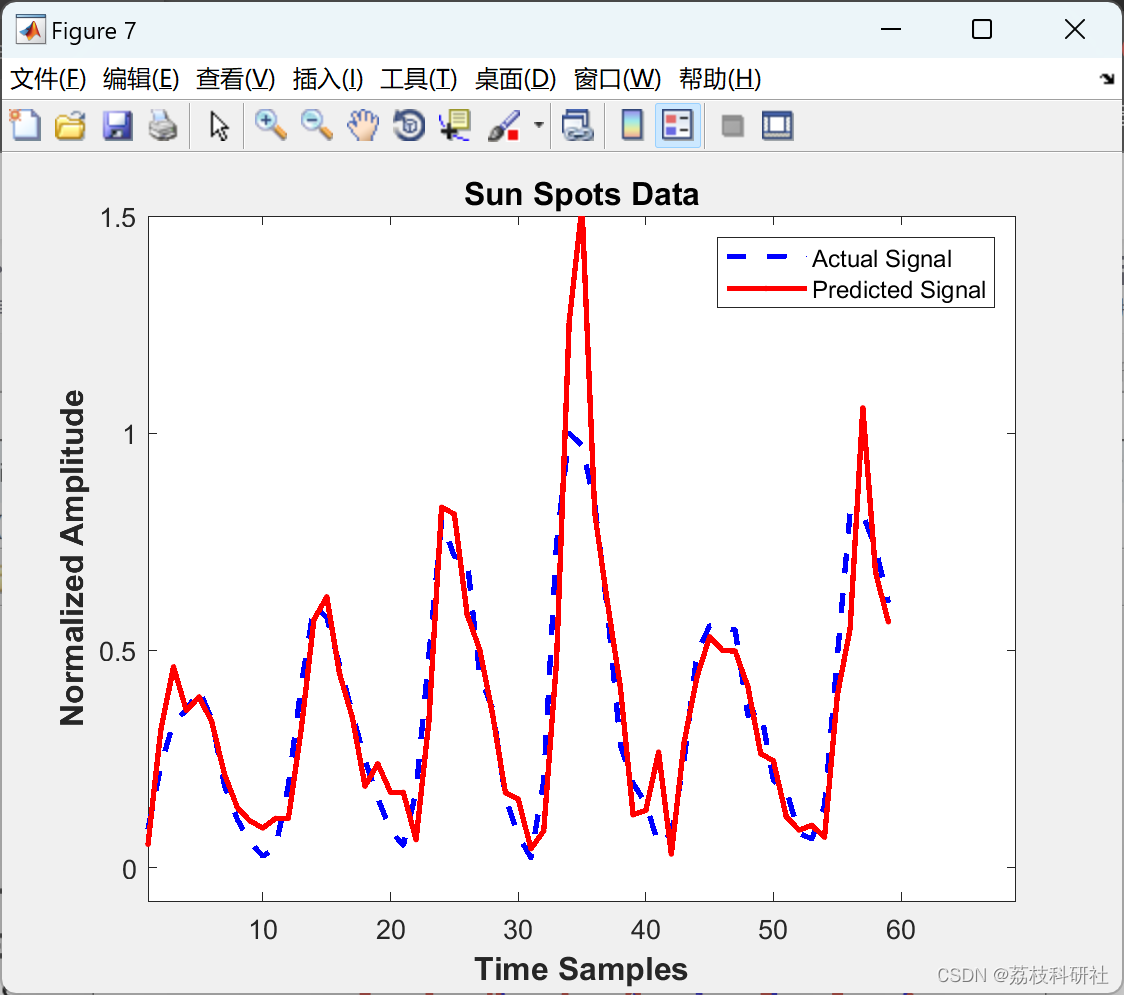
滑动时间窗口,又称rolling window.为了解决计数器法统计精度太低的问题,引入了滑动窗口算法,滑动窗口算法是将时间周期分为N个小周期,分别记录每个小周期内访问次数,并且根据时间滑动删除过期的小周期。下面这张图,很好地解释了滑动窗口算法:

由此可见,当滑动窗口的格子划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。
注:并没有完全解决临界问题,只是降低了临界问题的发生概率,提高了限流的准确率;
优缺点:
- 优点:一定程度上提高了限流的准确率,窗口越小,准确率越高;
- 缺点:但是滑动窗口和固定窗口都无法解决短时间之内集中流量的突击
3. 漏桶算法
接下来再说说漏桶,它可以解决时间窗口类的痛点,使得流量更加的平滑。
漏桶算法是访问请求到达时直接放入漏桶,如当前容量已达到上限(限流值),则进行丢弃(触发限流策略)。漏桶以固定的速率进行释放访问请求(即请求通过),直到漏桶为空。

优缺点:
- 优点:让流量处理平滑,无论任何时候都是按照固定速率处理请求
- 缺点:上面的优点是优点也是缺点,面对突发请求,服务的处理速度和平时是一样的,这其实不是我们想要的,在面对突发流量我们希望在系统平稳的同时,提升用户体验即能更快的处理请求,而不是和正常流量一样,循规蹈矩的处理
4. 令牌桶算法
令牌桶算法是对漏斗算法的一种改进,除了能够起到限流的作用外,还允许一定程度的流量突发
令牌桶算法是程序以r(r=时间周期/限流值)的速度向令牌桶中增加令牌,直到令牌桶满,请求到达时向令牌桶请求令牌,如获取到令牌则通过请求,否则触发限流策略

可以看出令牌桶在应对突发流量的时候,桶内假如有 100 个令牌,那么这 100 个令牌可以马上被取走,而不像漏桶那样匀速的消费。所以在应对突发流量的时候令牌桶表现的更佳。
5. 小结
计数器 VS 滑动窗口:
- 计数器算法是最简单的算法,可以看成是滑动窗口的低精度实现。
- 滑动窗口由于需要存储多份的计数器(每一个格子存一份),所以滑动窗口在实现上需要更多的存储空间。
- 也就是说,如果滑动窗口的精度越高,需要的存储空间就越大。
漏桶算法 VS 令牌桶算法:
- 漏桶算法和令牌桶算法最明显的区别是令牌桶算法允许流量一定程度的突发。
- 因为默认的令牌桶算法,取走token是不需要耗费时间的,也就是说,假设桶内有100个token时,那么可以瞬间允许100个请求通过。
- 当然我们需要具体情况具体分析,只有最合适的算法,没有最优的算法。
参考:http://t.csdn.cn/3Faw9
http://t.csdn.cn/GIJvN
CDN学习
1. 简介
CDN的全称是Content Delivery Network,即内容分发网络。CDN是构建在现有网络基础之上的智能虚拟网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。CDN的关键技术主要包括了节点调度、节点负载均衡和内容存储、分发、管理技术。
CDN的优势很明显:
- CDN节点解决了跨运营商和跨地域访问的问题,访问延时大大降低;
- 大部分请求在CDN边缘节点完成,CDN起到了分流作用,减轻了源站的负载。
2.工作流程
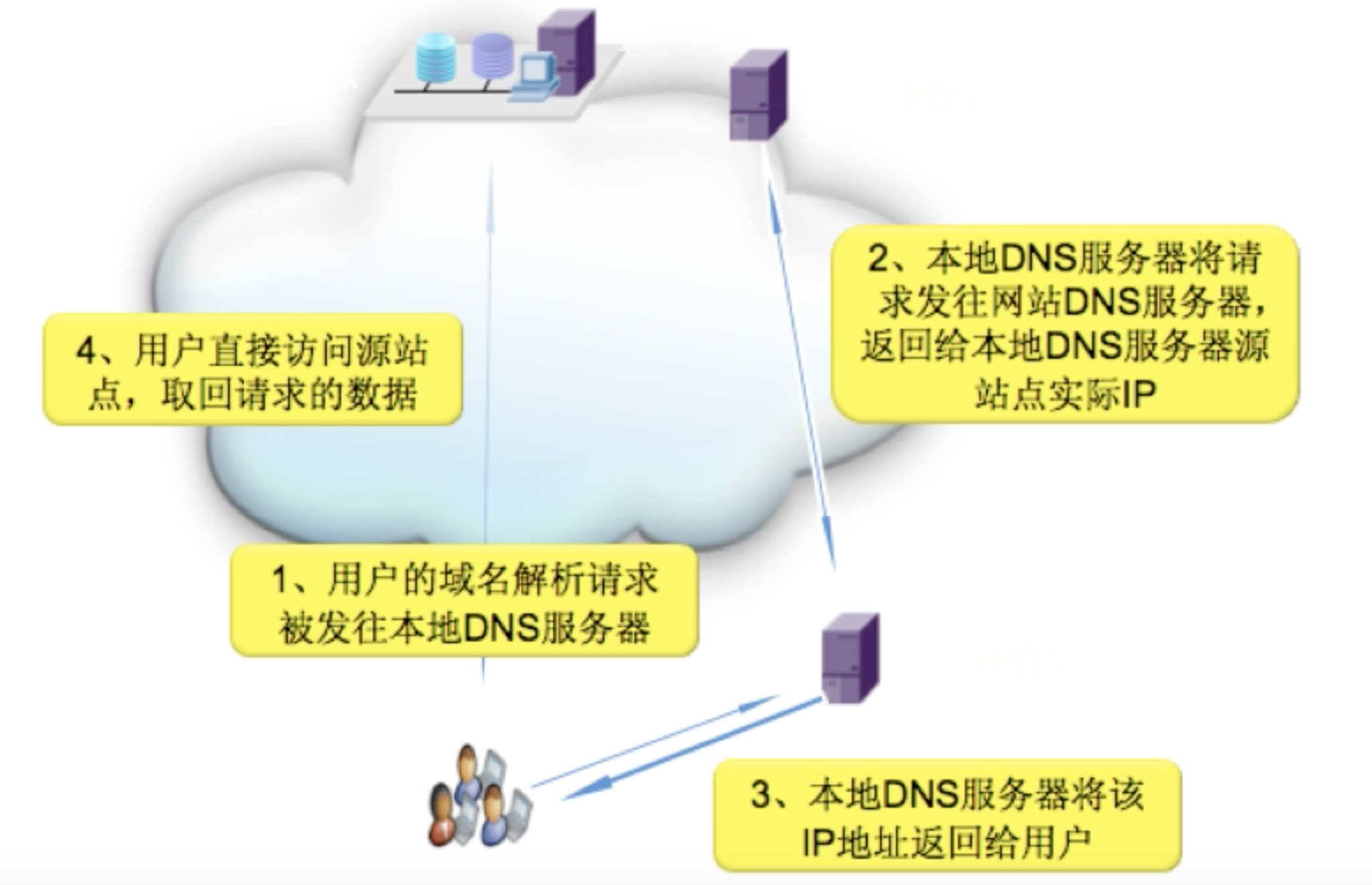
CDN加速前
使用CDN加速前,用户侧发起的请求通过用户侧DNS递归到网站DNS解析以后,最终用户侧直接请求网站服务器。这里可能会造成以下几种情况:
CDN加速后
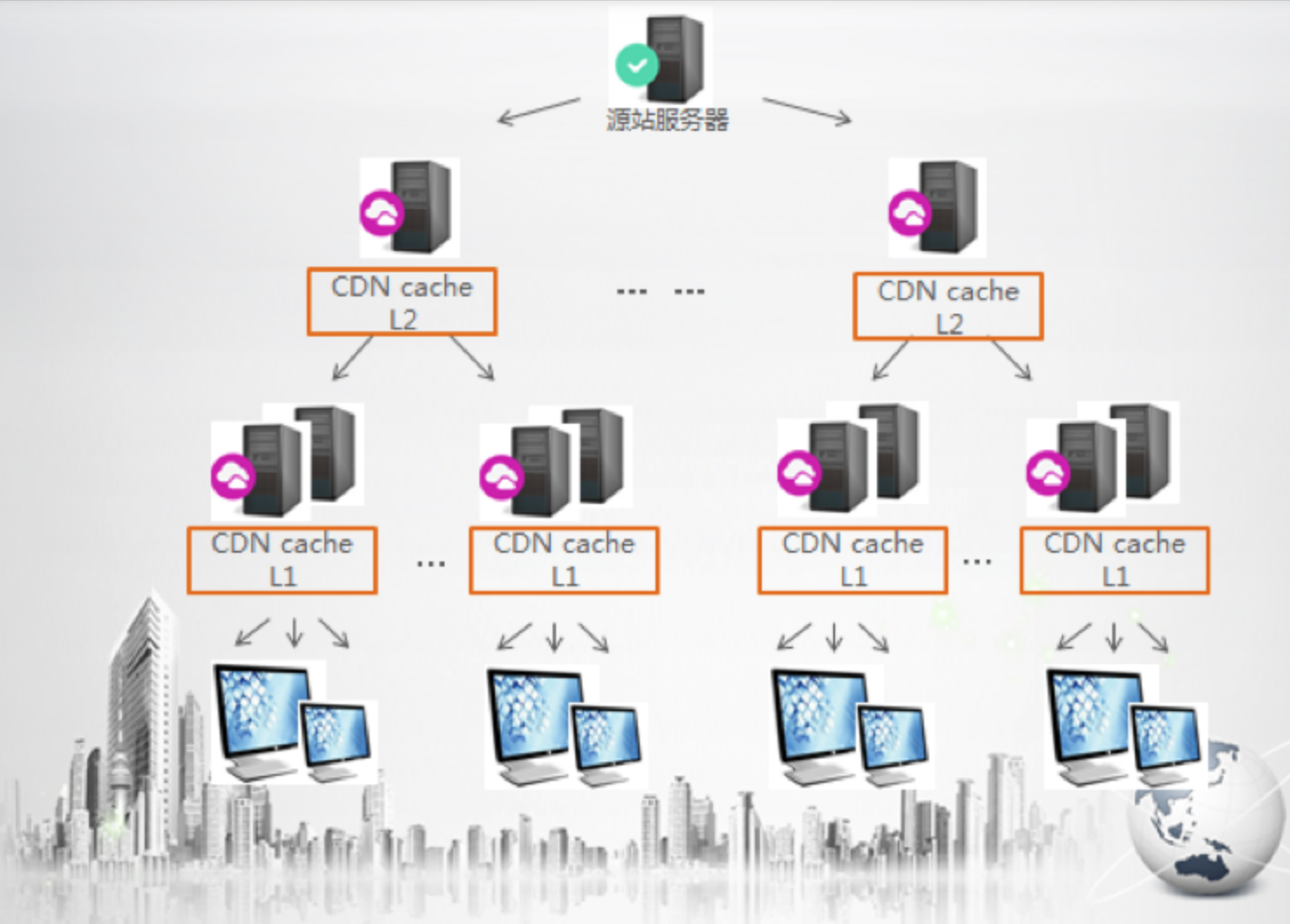
CDN通过在现有网络中增加一层新的缓存节点,将源站的资源发布到最接近用户的网络节点,使得客户端在请求时直接访问到就近的CDN节点并命中该资源,减少回源情况,提高网站访问速度。
阿里云CDN缓存节点可分为L1节点(一级节点)和L2节点(二级节点),请求的流程是:客户端–>CDN_L1–>CDN_L2–>源站。CDN的L1节点分布在全国各省市,L2节点分布在几个大区下,可以把L2节点理解为汇聚式节点,简单架构如下图所示。
浏览器本地缓存失效后,浏览器会向CDN边缘节点发起请求。类似浏览器缓存,CDN边缘节点也存在着一套缓存机制。
CDN缓存策略(重点)
CDN边缘节点缓存策略因服务商不同而不同,但一般都会遵循http标准协议,通过http响应头中的Cache-control: max-age的字段来设置CDN边缘节点数据缓存时间。
当客户端向CDN节点请求数据时,CDN节点会判断缓存数据是否过期,若缓存数据并没有过期,则直接将缓存数据返回给客户端;否则,CDN节点就会向源站发出回源请求,从源站拉取最新数据,更新本地缓存,并将最新数据返回给客户端。
CDN缓存刷新
CDN边缘节点对开发者是透明的,相比于浏览器Ctrl+F5的强制刷新来使浏览器本地缓存失效,开发者可以通过CDN服务商提供的“刷新缓存”接口来达到清理CDN边缘节点缓存的目的。这样开发者在更新数据后,可以使用“刷新缓存”功能来强制CDN节点上的数据缓存过期,保证客户端在访问时,拉取到最新的数据。
CDN工作原理
通过以下案例,可以进一步了解CDN的工作原理。
假设加速域名为www.a.com, 接入CDN网络,开始使用加速服务后,当终端用户(北京)发起HTTP请求时,处理流程如下图所示。
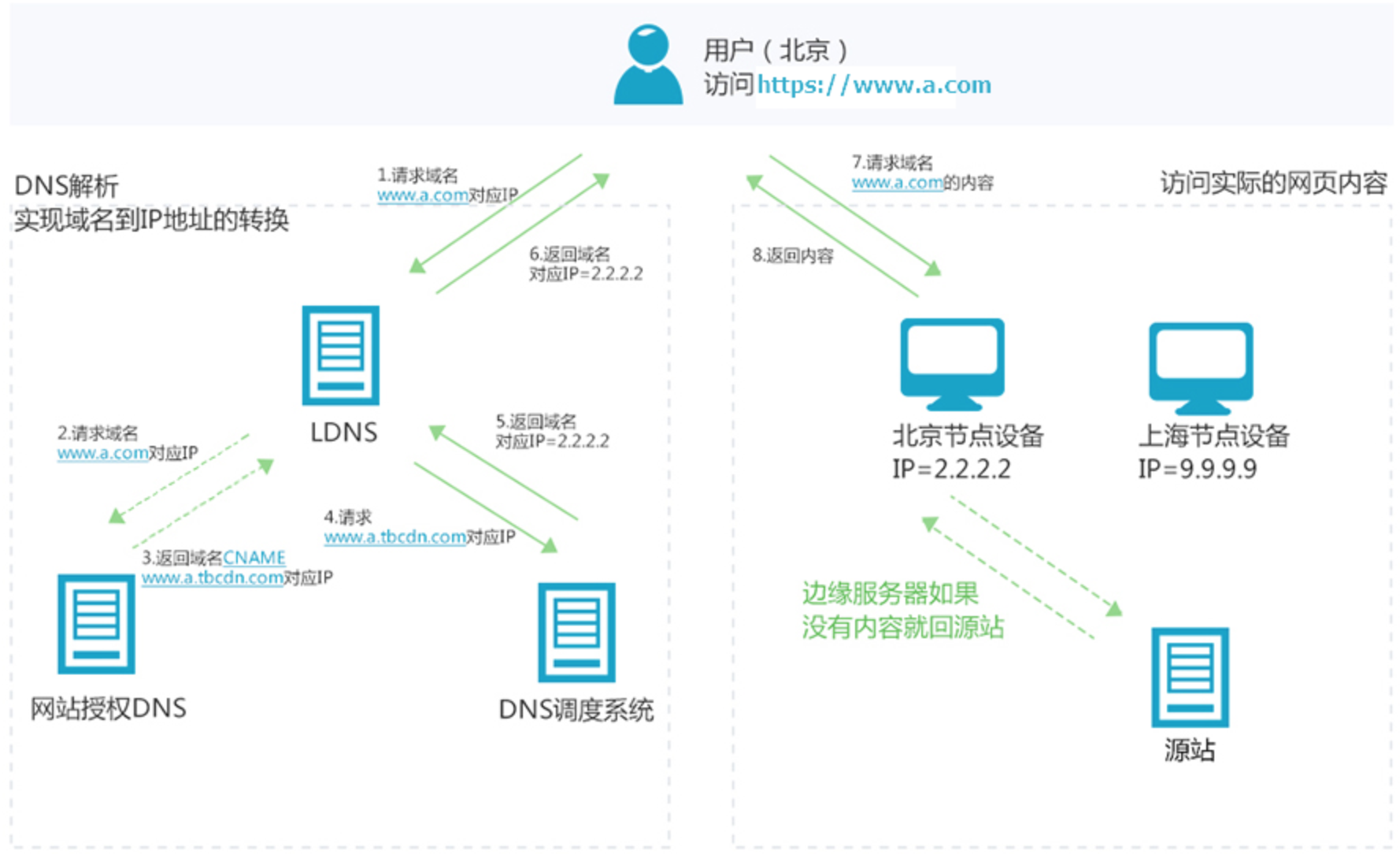
3. 什么资源可以被加速
在HTTP请求的资源,请求可以分为静态请求和动态请求。
静态请求
静态请求是指在不同请求中访问到的数据都相同的静态文件。例如:图片、视频、网站中的文件(html、css、js)、软件安装包、apk文件、压缩包文件等。
CDN加速的本质是缓存加速,将您服务器上存储的静态内容缓存在阿里云CDN节点上,当您访问这些静态内容时,无需访问服务器源站,就近访问阿里云CDN节点即可获取相同内容,从而达到加速的效果,同时减轻服务器源站的压力。
动态请求(不适用)
动态请求是指在不同请求中访问到的数据不相同的动态内容。例如:网站中的文件(asp、jsp、php、perl、cgi)、API接口、数据库交互请求等。
当客户端访问这些动态内容时,每次都需要访问用户的服务器,由服务器动态生成实时的数据并返回给客户端。因此CDN的缓存加速不适用于加速动态内容,CDN无法缓存实时变化的动态内容。对于动态内容请求,CDN节点只能转发回源站服务器,没有加速效果。
如果用户的网站或App应用有较多动态内容,例如需要对各种API接口进行加速,则需要使用阿里云全站加速产品。全站加速能同时加速动态和静态内容,加速方式如下:
- 静态内容使用CDN加速。
- 动态内容通过阿里云的路由优化、传输优化等动态加速技术以最快的速度访问您的服务器源站获取数据。从而达到全站加速的效果