背景
说起微服务,就需要用到SpringCloud,目前市面上主流的SpringCloud产品有这些:
SpringCloudNeflix、Spring Cloud Alibaba、Spring Cloud for AWS、Spring Cloud Azure 和 Spring Cloud Kubernetes。其中SpringCloudNeflix已经不在更新,只做维护,所以不再考虑。
因为我们的需求是一套架构能够快速的部署到不同的云上,为了避免日后不好在多个云之间移植,我们所使用的产品或工具就不能和云厂商做强制绑定,所以我们排除 Spring Cloud Alibaba、Spring Cloud for AWS、Spring Cloud Azure,我们自己选型每种工具,采用 Spring Boot + xxx产品工具 = Spring Cloud,来实现一套SpringCloud微服务框架。
还有一种方案就是使用Spring Cloud Kubernetes微服务框架,因为他是Spring官方推出的,不属于任何一个云厂商,它是利用Kubernetes的自身的特性来完成服务的发现、配置管理等,所以只要有Kubernetes环境就可以运行这一套架构,而每个云厂商都可以买到Kubernetes容器,这样的话一套架构多个云之间迁移,其实就是换了个Kubernetes容器,移植性就会很好。
两种选择
那下面我们就来比较下这两种方案的优缺点:
K8s + Spring Boot + xxx = Spring Cloud
Spring Cloud Kubernetes
K8s + Spring Boot + xxx = Spring Cloud
K8s非常适合微服务架构中千百上千个微服务的维护,现在很多微服务产品都部署在K8s容器里,他们的架构如下所示:
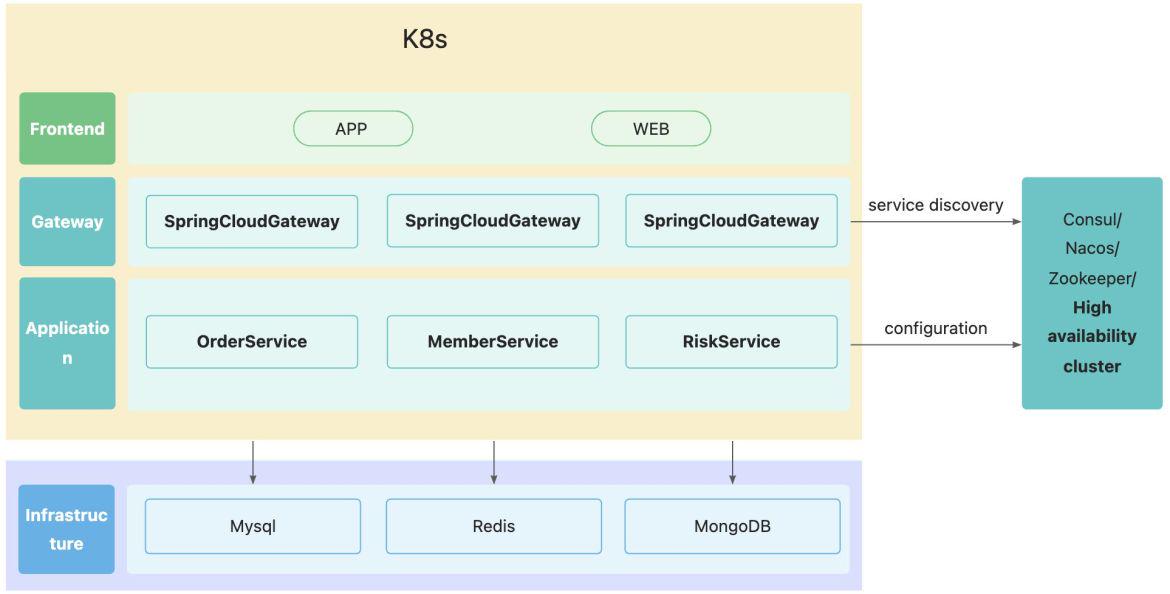
把Spring Cloud项目部署在K8s容器中,服务发现与配置管理借助Consul/Nacos/ZK来实现,SRE需要来维护注册中心的集群;网关层也使用了专门的组件SpringCloudGateway,所以这就增加了开发和运维的成本。
Spring Cloud Kubernetes
为了让Spring Cloud微服务更好的使用K8s的功能,Spring官方推出了Spring Cloud Kubernetes,利用K8s本身的功能与特性,让Spring Cloud 更加方便的部署在K8s容器中。架构如下所示:
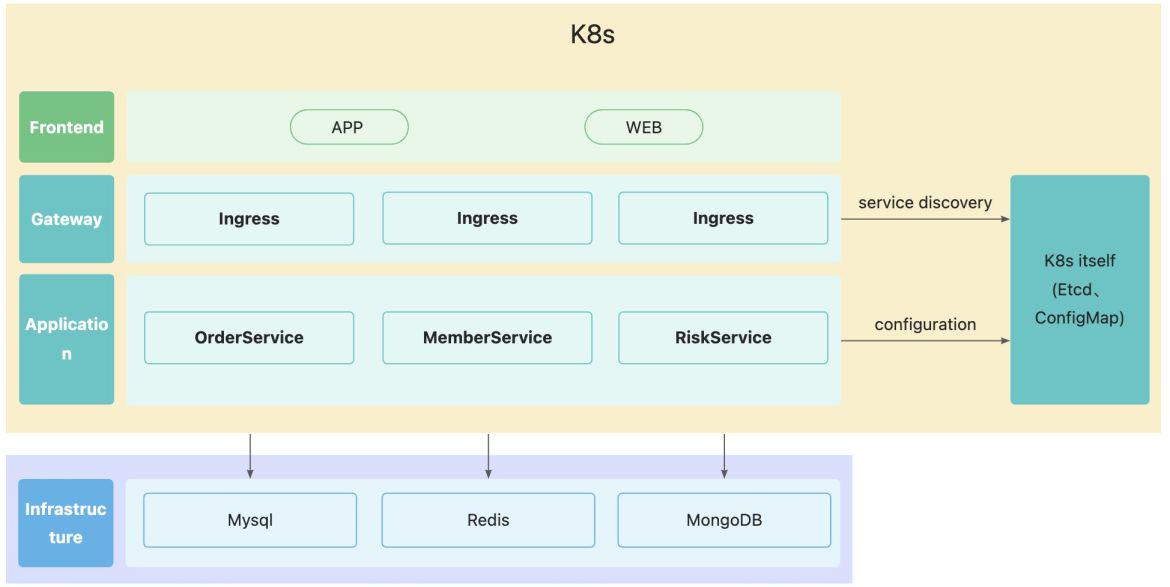
如果使用Spring Cloud Kubernetes作为微服务框架构,我们就不需要再额外引入Consul/Nacos/ZK/SpringCloudGateway组件,降低开发和运维的成本。
Kubernetes
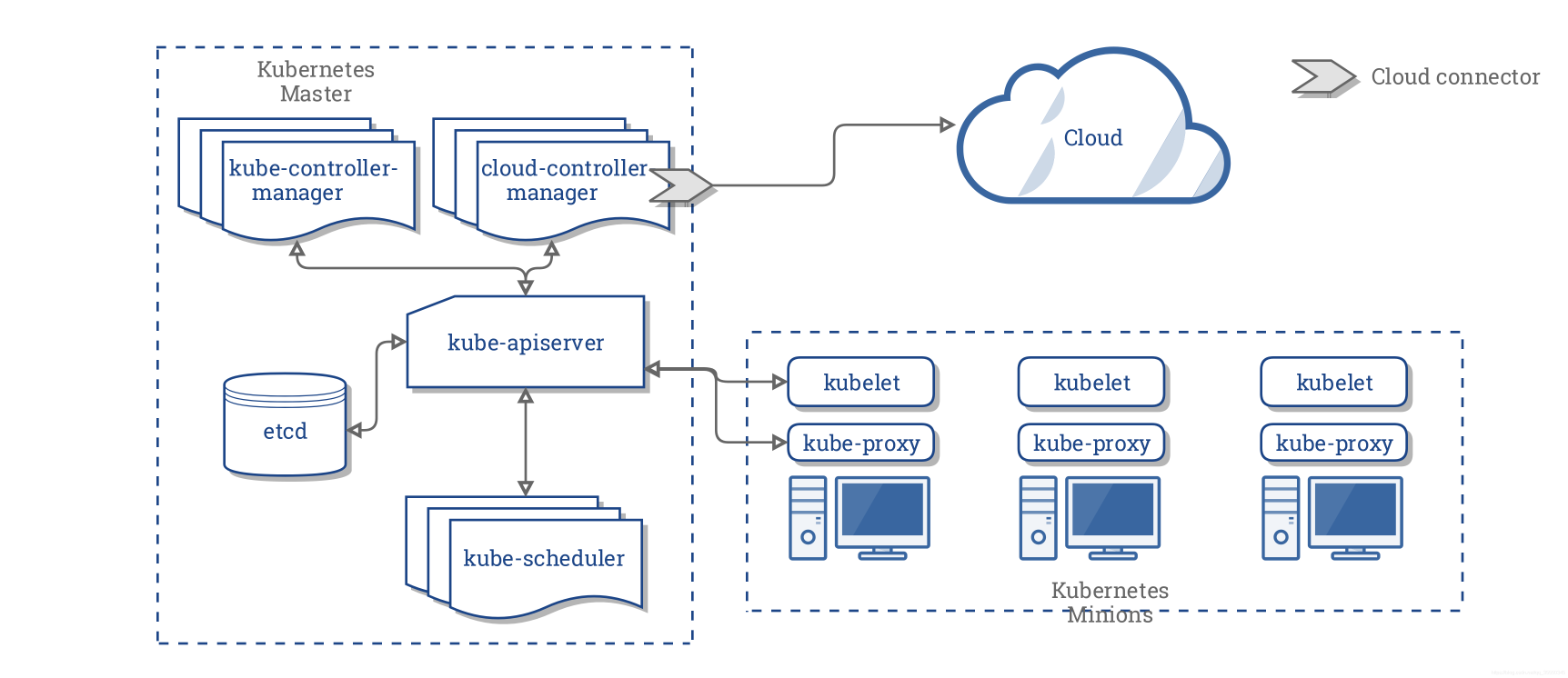
Kubernetes架构图
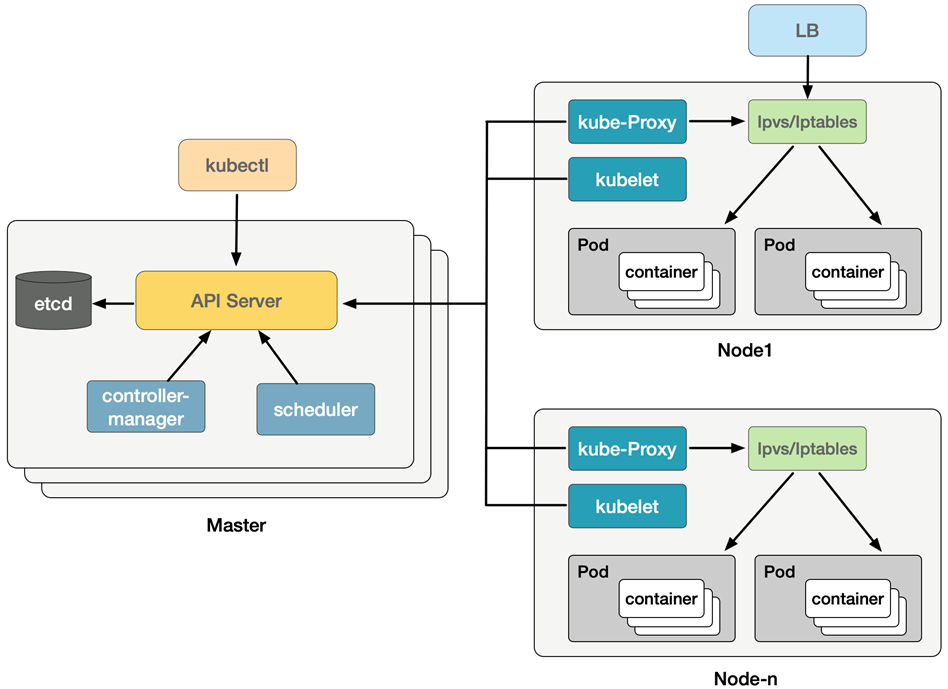
组件简介
整个系统由控制面(Master)与数据面(Worker Node)组成
master组件
API Server
集群控制的唯一入口,它是各个组件通信的中心枢纽
提供了集群管理的REST API接口,包括 认证、授权、数据检验、集群状态变更
提供了其他模块之间的数据交互和通信的枢纽,集群内各个功能模块通过API Server将信息存入etcd,当需要获取和操作这些数据时,通过API Server提供的REST接口(GET\LIST\WATCH方法)来实现,从而实现各模块之间的信息交互。
是资源配额控制的入口
/api/v1/namespaces
/api/v1/pods
/api/v1/namespaces/my-namespace/pods
/apis/apps/v1/deployments
/apis/apps/v1/namespaces/my-namespace/deployments
/apis/apps/v1/namespaces/my-namespace/deployments/my-deploymentcontroller-mananger
Controller Manager 由 kube-controller-manager 和 cloud-controller-manager 组成,是 Kubernetes 的大脑,它通过 apiserver 监控整个集群的状态,并确保集群处于预期的工作状态。
kube-controller-manager
内置了多种控制器(DeploymentController、ServiceController、NamespaceController、NodeController、HPAController等)是Kubernetes维护业务和集群状态的最核心组件
ReplicaSetController
DeploymentController
ServiceController
NodeController
cloud-controller-manager
在 Kubernetes 启用 Cloud Provider 的时候才需要,用来配合云服务提供商的控制,也包括一系列的控制器,如
RouteController
ServiceController
NodeController
Metrics
Controller manager metrics 提供了控制器内部逻辑的性能度量,如 etcd 请求延时、云服务商 API 请求延时、云存储请求延时等。
Controller manager metrics 默认监听在 kube-controller-manager 的 10252 端口,提供 Prometheus 格式的性能度量数据,可以通过 http://localhost:10252/metrics 来访问。
高可用和高性能
在启动时设置 --leader-elect=true 后,controller manager 会使用多节点选主的方式选择主节点。只有主节点才会调用 StartControllers() 启动所有控制器,而其他从节点则仅执行选主算法。
scheduler
集群的调度器,负责分配调度 Pod 到集群内的节点上,它监听 ApiServer,查询还未分配 Node 的 Pod,然后根据调度策略为这些 Pod 分配节点(更新 Pod 的 NodeName 字段)
scheduler 调度分为两个阶段,predicate 和 priority
1)predicate:过滤不符合条件的节点
2)priority:优先级排序,选择优先级最高的节点
etcd
Etcd 是 CoreOS 基于 Raft 开发的分布式 key-value 存储,可用于服务发现、共享配置以及一致性保障(如数据库选主、分布式锁等),用于存储Kubernetes集群的数据与状态信息。
work组件
kubelet
每个节点上都运行一个 kubelet 服务进程,默认监听 10250 端口,接收并执行 master 发来的指令,管理 Pod 及 Pod 中的容器。每个 kubelet 进程会在 API Server 上注册节点自身信息,定期向 master 节点汇报节点的资源使用情况,并通过 cAdvisor 监控节点和容器的资源
节点管理
Kubelet 可以通过设置启动参数 --register-node 来确定是否向 API Server 注册自己这个节点
Kubelet 在启动时通过 API Server 注册节点信息,并定时向 API Server 发送节点新消息,API Server 在接收到新消息后,将信息写入 etcd
ps:如果Kubelet 没有选择自注册模式,则需要用户自己配置 Node 资源信息,同时需要告知 Kubelet 集群上的 API Server 的位置
pod管理
获取pod & 创建pod
Kubelet 通过 API Server Client 使用 List-Watch 的方式监听 “/registry/nodes/$ 当前节点名” 和 “/registry/pods” 目录,将获取的信息同步到本地缓存中
Kubelet 监听 etcd,所有针对 Pod 的操作都将会被 Kubelet 监听到,如果发现有新的绑定到本节点 Node 的 Pod,则按照 Pod 清单的要求创建该 Pod
如果发现本地的 Pod 被修改,则 Kubelet 会做出相应的修改,比如删除本节点的Pod,则删除相应的 Pod,并通过 Docker Client 删除 Pod 中的容器。
容器健康检查
LivenessProbe 探针:用于判断容器是否健康,告诉 Kubelet 一个容器什么时候处于不健康的状态。如果 LivenessProbe 探针探测到容器不健康,则 Kubelet 将删除该容器,并根据容器的重启策略做相应的处理。如果一个容器不包含 LivenessProbe 探针,那么 Kubelet 认为该容器的 LivenessProbe 探针返回的值永远是 “Success”;
LivenessProbe 探针探测的方式包括三个:
ExecAction:在容器内部执行一个命令,如果该命令的退出状态码为 0,则表明容器健康;
TCPSocketAction:通过容器的 IP 地址和端口号执行 TCP 检查,如果端口能被访问,则表明容器健康;
HTTPGetAction:通过容器的 IP 地址和端口号及路径调用 HTTP GET 方法,如果响应的状态码大于等于 200 且小于 400,则认为容器状态健康。
重启策略包括三个:
Always:只要容器异常退出,kubelet就会自动重启该容器(默认)
OnFailure:当容器终止运行且退出码不为0时(失败),由kubelet自动重启该容器
Never:从不重启
ReadinessProbe:用于判断容器是否启动完成且准备接收请求。如果 ReadinessProbe 探针探测到失败,则 Pod 的状态将被修改。Endpoint Controller 将从 Service 的 Endpoint 中删除包含该容器所在 Pod 的 IP 地址的 Endpoint 条目。
cAdvisor资源监控
cAdvisor 是一个开源的分析容器资源使用率和性能特性的代理工具,已集成到 Kubernetes 代码中
自动查找所有在其所在节点上的容器,自动采集 CPU、内存、文件系统和网络使用的统计信息
cAdvisor 通过它所在节点机的 Root 容器,采集并分析该节点机的全面使用情况
cAdvisor 通过其所在节点机的 4194 端口暴露一个简单的 UI
Heapster 通过带着关联标签的 Pod 分组这些信息,这些数据将被推到一个可配置的后端,用于存储和可视化展示。支持的后端包括 InfluxDB(使用 Grafana 实现可视化) 和 Google Cloud Monitoring。
kube-proxy
每台机器上都以 DaemonSet 的形式运行一个 kube-proxy 服务,通过访问 apiserver 并 watch 相应资源 (Service 对象和 Endpoint 对象) 来动态生成各自节点上的 iptables 规则,并通过 iptables 等来为服务配置负载均衡(仅支持 TCP 和 UDP)。
当用户想要访问 Pod 服务时,iptables 会通过 NAT (网络地址转化) 等方式随机请求到任意一个 Pod。
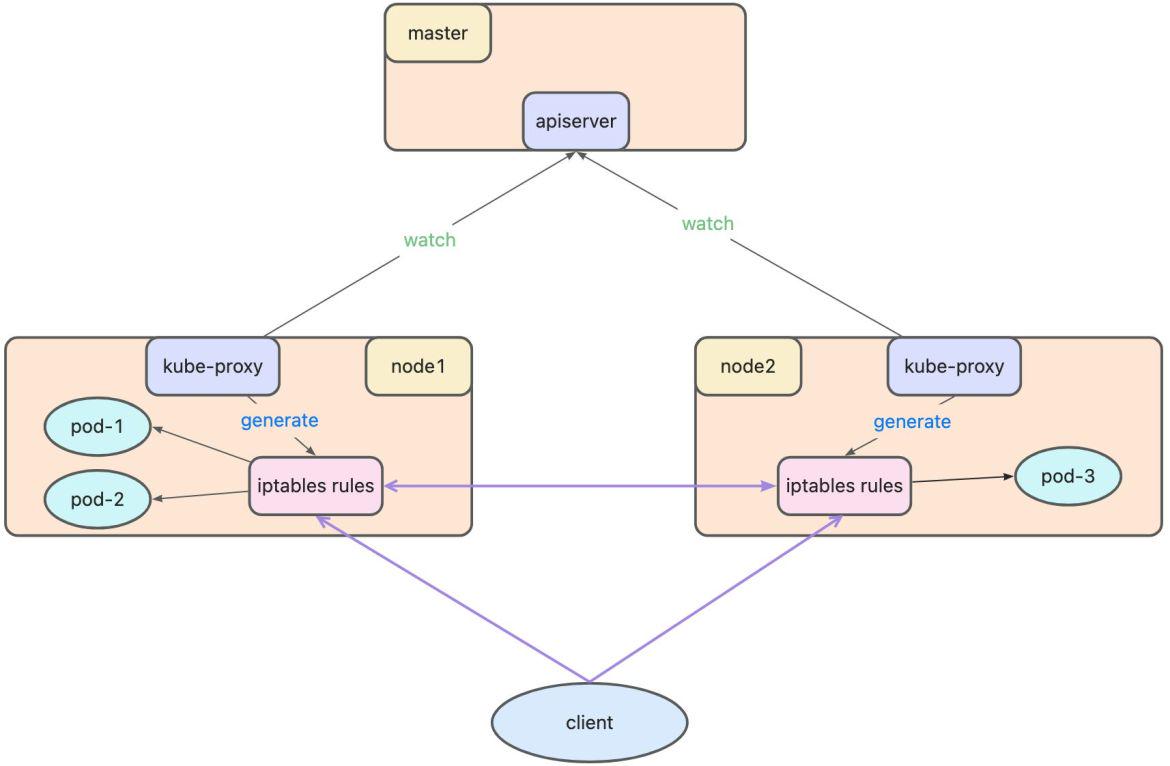
kube-proxy 当前支持以下几种实现:
userspace:最早的负载均衡方案,它在用户空间监听一个端口,所有服务通过 iptables 转发到这个端口,然后在其内部负载均衡到实际的 Pod。该方式最主要的问题是效率低,有明显的性能瓶颈。
iptables:目前推荐的方案,完全以 iptables 规则的方式来实现 service 负载均衡。该方式最主要的问题是在服务多的时候产生太多的 iptables 规则,非增量式更新会引入一定的时延,大规模情况下有明显的性能问题
ipvs:为解决 iptables 模式的性能问题,v1.11 新增了 ipvs 模式(v1.8 开始支持测试版,并在 v1.11 GA),采用增量式更新,并可以保证 service 更新期间连接保持不断开

Kubernetes工作流程
K8S工作流程分析
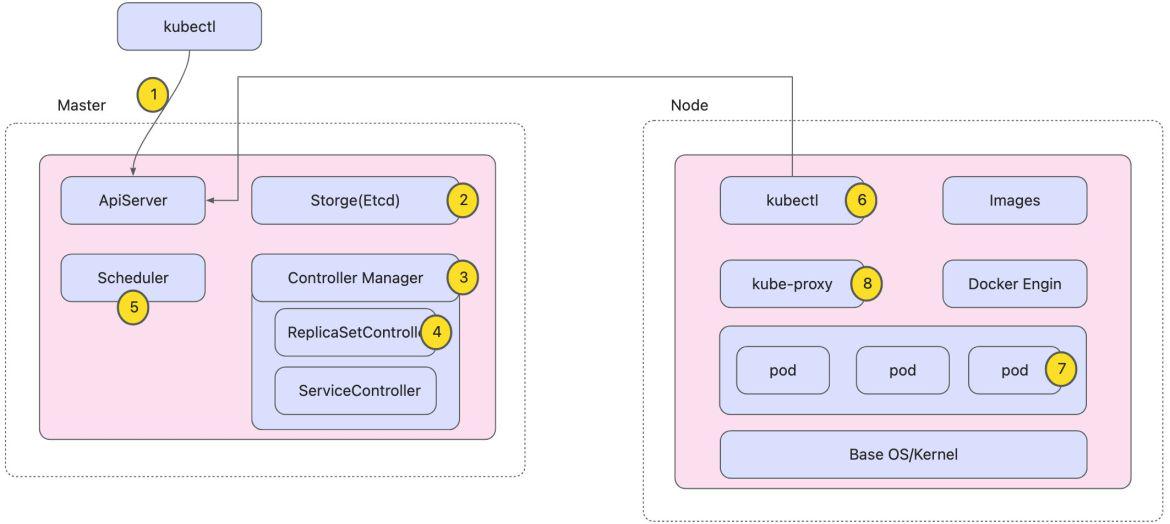
各个组件与API Server的流程交互
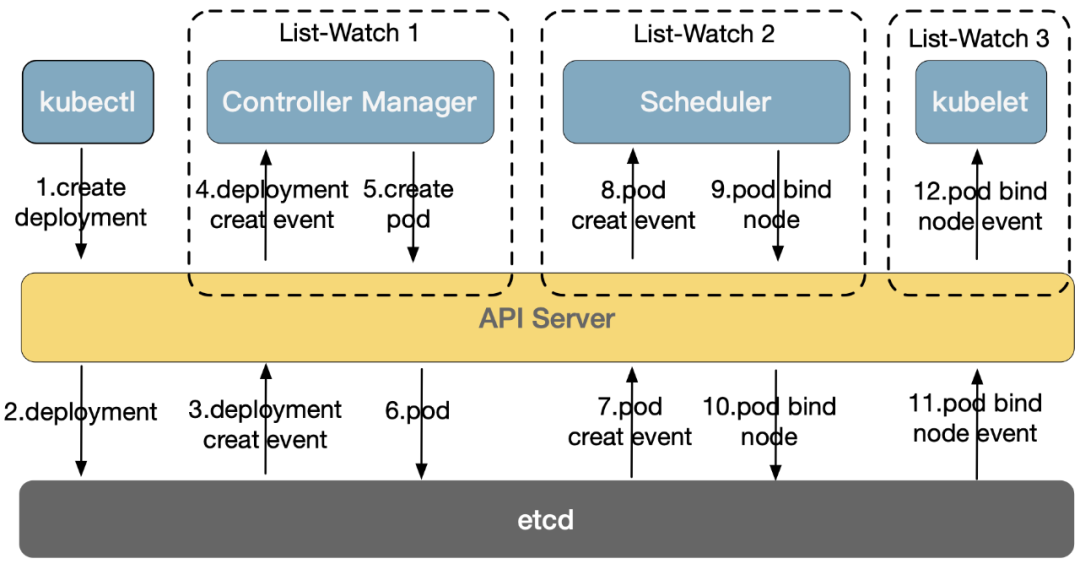
创建Pod流程
创建ReplicaSet流程
demo.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: kubernetes-dashboard
template:
metadata:
labels:
k8s-app: kubernetes-dashboard
spec:
securityContext:
seccompProfile:
type: RuntimeDefault
containers:
- name: kubernetes-dashboard
image: kubernetesui/dashboard:v2.5.0
imagePullPolicy: Always
ports:
- containerPort: 8443
protocol: TCP
args:
- --auto-generate-certificates
- --namespace=kubernetes-dashboard
volumeMounts:
- name: kubernetes-dashboard-certs
mountPath: /certs
# Create on-disk volume to store exec logs
- mountPath: /tmp
name: tmp-volume
livenessProbe:
httpGet:
scheme: HTTPS
path: /
port: 8443
initialDelaySeconds: 30
timeoutSeconds: 30
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsUser: 1001
runAsGroup: 2001
volumes:
- name: kubernetes-dashboard-certs
secret:
secretName: kubernetes-dashboard-certs
- name: tmp-volume
emptyDir: {}
serviceAccountName: kubernetes-dashboard
nodeSelector:
"kubernetes.io/os": linux
# Comment the following tolerations if Dashboard must not be deployed on master
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
---
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
ports:
- port: 443
targetPort: 8443
nodePort: 18443
selector:
k8s-app: kubernetes-dashboard
---
apiVersion: v1
kind: Namespace
metadata:
name: kubernetes-dashboard
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
---
apiVersion: v1
kind: Secret
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-key-holder
namespace: kubernetes-dashboard
type: Opaque
---
kind: ConfigMap
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-settings
namespace: kubernetes-dashboard
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
rules:
# Allow Dashboard to get, update and delete Dashboard exclusive secrets.
- apiGroups: [""]
resources: ["secrets"]
resourceNames: ["kubernetes-dashboard-key-holder", "kubernetes-dashboard-certs", "kubernetes-dashboard-csrf"]
verbs: ["get", "update", "delete"]
# Allow Dashboard to get and update 'kubernetes-dashboard-settings' config map.
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
rules:
# Allow Metrics Scraper to get metrics from the Metrics server
- apiGroups: ["metrics.k8s.io"]
resources: ["pods", "nodes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: kubernetes-dashboard
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubernetes-dashboard
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kubernetes-dashboard
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kubernetes-dashboardKubernetes的优势
除了Kubernetes本身拥有服务注册/服务发现/配置管理的功能以外,也有基于下面几点考虑。
背景硬
K8s是由Google开源的,是基于Google内部运行十多年的Borg系统的基础上,结合了社区中最优秀的想法和实践,已经成为了目前容器编排的事实标准。
是用于自动部署、扩缩和管理容器化应用程序的开源系统;目前由CNCF负责管理K8s,完全开源由社区驱动不受任何一家公司控制的,是继Linux之外增长最快的开源项目
性能强
https://github.com/etcd-io/dbtester/tree/master/test-results/2018Q1-02-etcd-zookeeper-consul
功能广
自动化上线和回滚
服务发现与负载均衡
自我修复
存储编排
Secret 和配置管理
自动装箱
批量执行
水平扩缩
为扩展性设计
Etcd
etcd is a distributed reliable key-value store for the most critical data of a distributed system, with a focus on being:
Simple: well-defined, user-facing API (gRPC)
Secure: automatic TLS with optional client cert authentication
Fast: benchmarked 10,000 writes/sec
Reliable: properly distributed using Raft
etcd is written in Go and uses the Raft consensus algorithm to manage a highly-available replicated log. etcd is used in production by many companies, and the development team stands behind it in critical deployment scenarios, where etcd is frequently teamed with applications such as Kubernetes, locksmith, vulcand, Doorman, and many others. Reliability is further ensured by rigorous testing.
Raft 分布式一致性协议
英文版:https://ramcloud.atlassian.net/wiki/download/attachments/6586375/raft.pdf
中文版:https://github.com/maemual/raft-zh_cn/blob/master/raft-zh_cn.md
动画演示:http://thesecretlivesofdata.com/raft/
Raft is a consensus algorithm for managing a replicated log. It produces a result equivalent to (multi-)Paxos, and it is as efficient as Paxos, but its structure is different from Paxos; this makes Raft more understandable than Paxos and also provides a better foundation for building practical systems. In order to enhance understandability, Raft separates the key elements of consensus, such as leader election, log replication, and safety, and it enforces a stronger degree of coherency to reduce the number of states that must be considered. Results from a user study demonstrate that Raft is easier for students to learn than Paxos. Raft also includes a new mechanism for changing the cluster membership, which uses overlapping majorities to guarantee safety
Leader election(领导人选举)
Log replication(日志复制)
Safety(安全性)
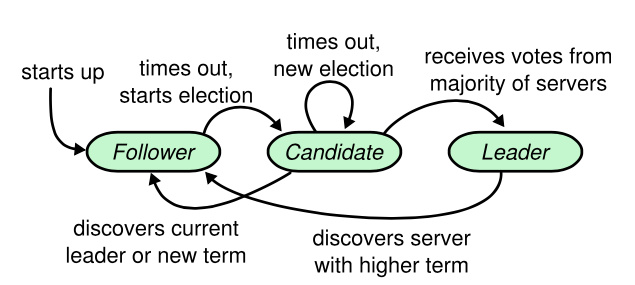
Leader (领导人): 在同一个任期(term)内,只会存在一个Leader节点,Leader需要给Follower发心跳,确保自己还在,维护自己的权威。
Follower(追随者): 接收Leader的指令保存数据,接收Candidate的投票请求,然后投票
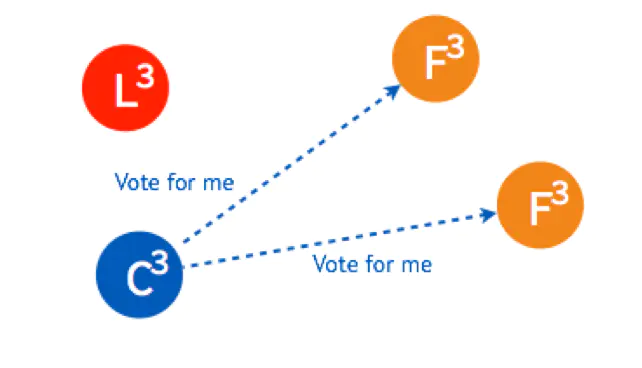
Candidate (候选人): 发拉票请求给Follower,请求选自己为Leader
在集群处于稳定状态时,只会存在Leader和Follower;当Leader宕机后,集群进入重新选举阶段,只会存在Follower和Candidate,一旦新的Leader被选出,没选上的Candidate就转成Follower。
选举 Leader Election
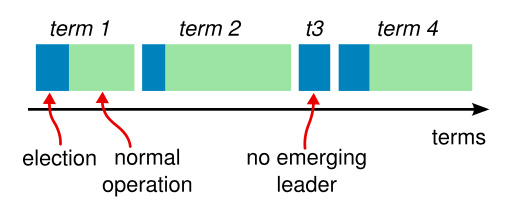
为什么选举?
Raft将整个集群的运行过程,分成一个个任期(term),任期通过任期号来标识,是一个自增的数字。Raft规定每个任期内只能有且只有一个Leader,所有发给集群的请求都由Leader来处理。就是说对于客户端来说,虽然我面对的是一个集群,但是我只需要跟Leader交互就可以了,虽然不同的任期内Leader可能变化,但是同一时间面对的仍然只有一个节点。这样做可以大大降低整个系统实现的复杂性,Zookeeper的ZAB协议也采用了同样的设计。而选举就是选Leader的过程,所以,每一个新的任期生成,一定伴随着一次重新选举。
什么时候触发选举?
首次启动时,所有节点默认都是Follower,自然不会有Leader发心跳,所以等待一段时间后,就会有Follower将自己转换成Candidate,给其它节点发请求投票RPC。
未收到Leader心跳,集群运行一段时间后,Leader因为宕机或者网络分区导致Follower收不到Leader的心跳,Follower会变成Candidate,给其它节点发请求投票RPC。
什么时候选举完成?
一个候选人收到了包括它自己在内的超过半数节点的选票就可以成功当选Leader
选举流程
首次启动
如果一个 follower 在一段时间内没有收到任何心跳,也就是选举超时,那么它就会主观认为系统中没有可用的 leader,把自己都变成Candidate,并发起新的选举;但是有没有可能,一开始启动时有5个节点,在一段时间之后都变成了Candidate,都发起了选举呢?因为同时选举会让整个集群会变得低效不堪,极端情况下甚至会一直选不出一个主节点。为了避免这个问题,Raft巧妙的使用了一个随机化的定时器(150ms - 300ms),让每个节点的超时时间在一定范围内生成且时间都不一样,这样 所有的follower就很大概率不会同时变成Candidate参与选举
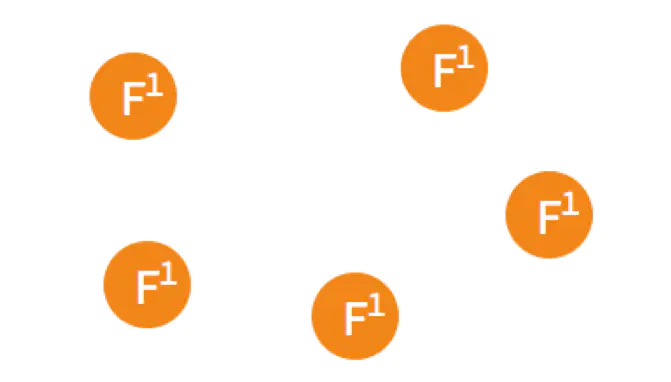
假设现在有如图5个节点,5个节点一开始的状态都是 Follower。
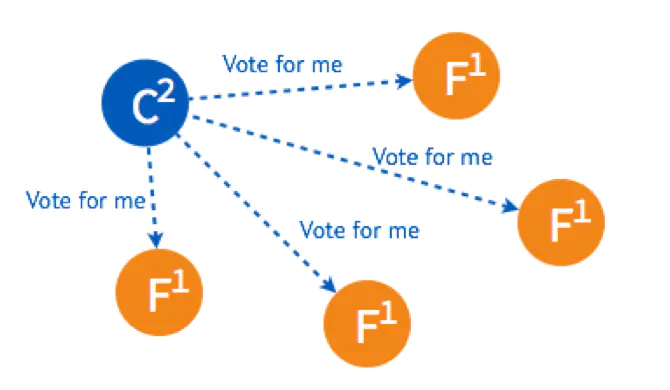
在一个节点倒计时结束 (Timeout) 后,这个节点的状态变成 Candidate 开始选举,它给其他几个节点发送选举请求 (RequestVote)
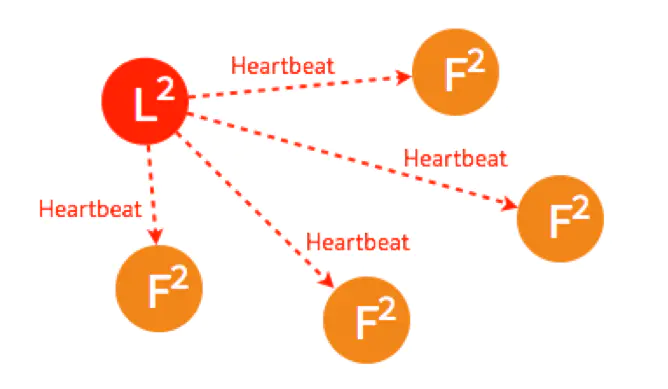
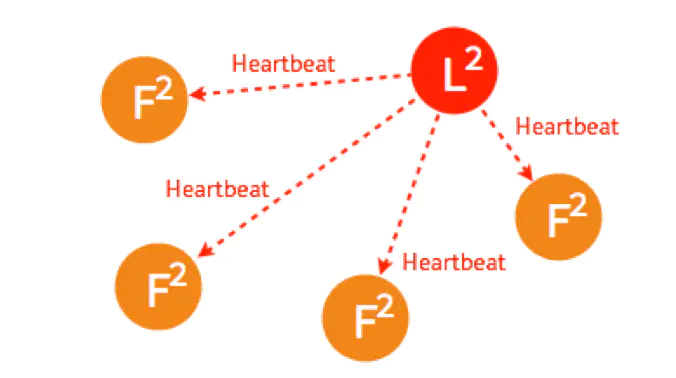
其他四个节点都返回成功,这个节点的状态由 Candidate 变成了 Leader,并在每个一小段时间后,就给所有的 Follower 发送一个 Heartbeat 以保持所有节点的状态,Follower 收到 Leader 的 Heartbeat 后重设 Timeout。
这是最简单的选主情况,只要有超过一半的节点投支持票了,Candidate 才会被选举为 Leader,5个节点的情况下,3个节点 (包括 Candidate 本身) 投了支持就行。
Leader故障
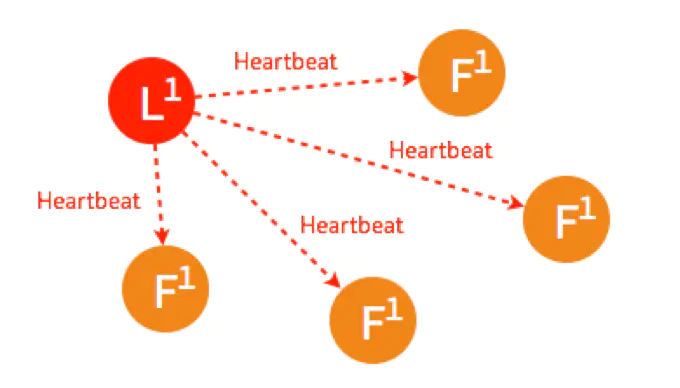
一开始已经有一个 Leader,所有节点正常运行
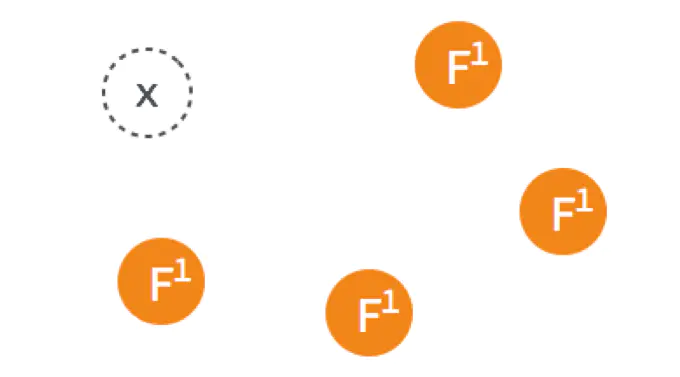
Leader 出故障挂掉了,其他四个 Follower 将进行重新选主。
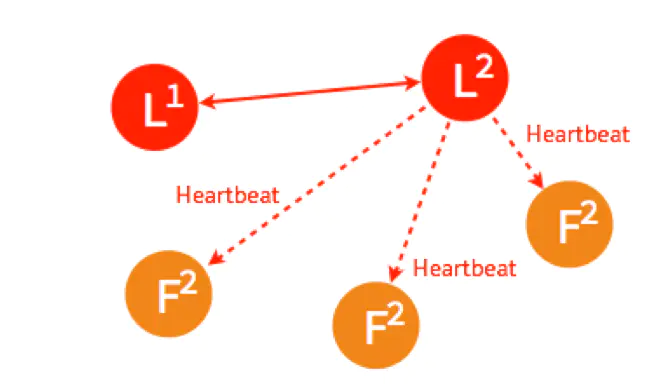
4个节点的选主过程和5个节点的类似,在选出一个新的 Leader 后,原来的 Leader 恢复了又重新加入了,这个时候怎么处理?在 Raft 里,第几轮选举是有记录的,重新加入的 Leader 是第一轮选举 (Term 1) 选出来的,而现在的 Leader 则是 Term 2,所有原来的 Leader 会自觉降级为 Follower
多个 Candidate 情况下的选主

假设一开始有4个节点,都还是 Follower。

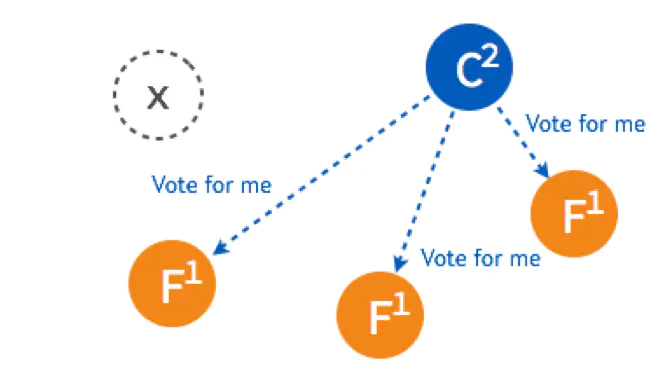
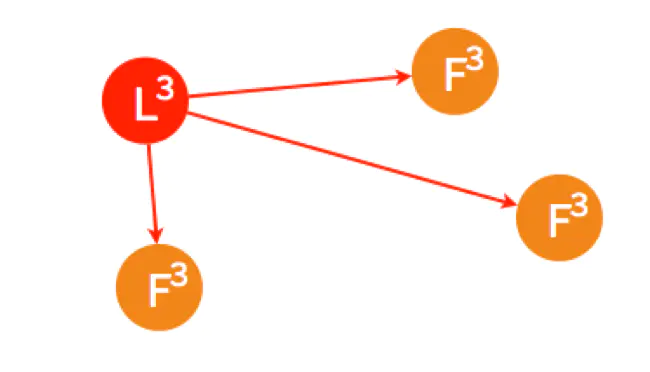
有两个 Follower(A和D) 同时 Timeout,都变成了 Candidate 开始选举,分别给其他的 Follower 发送了投票请求。
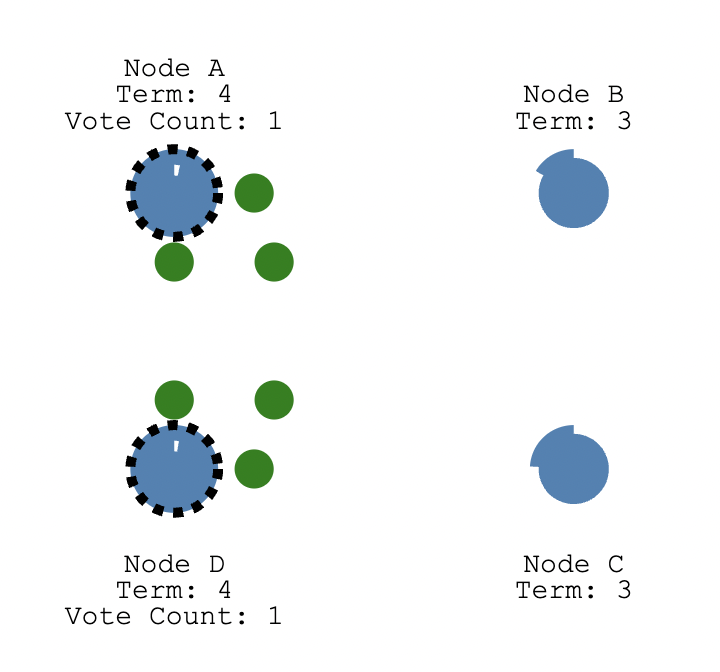
因为同一个term里,一个Follower只会投一次票,所以两个Candidate都获取到了两个投票,那么这个term里没选出来Leader,那么开始新一轮的选举
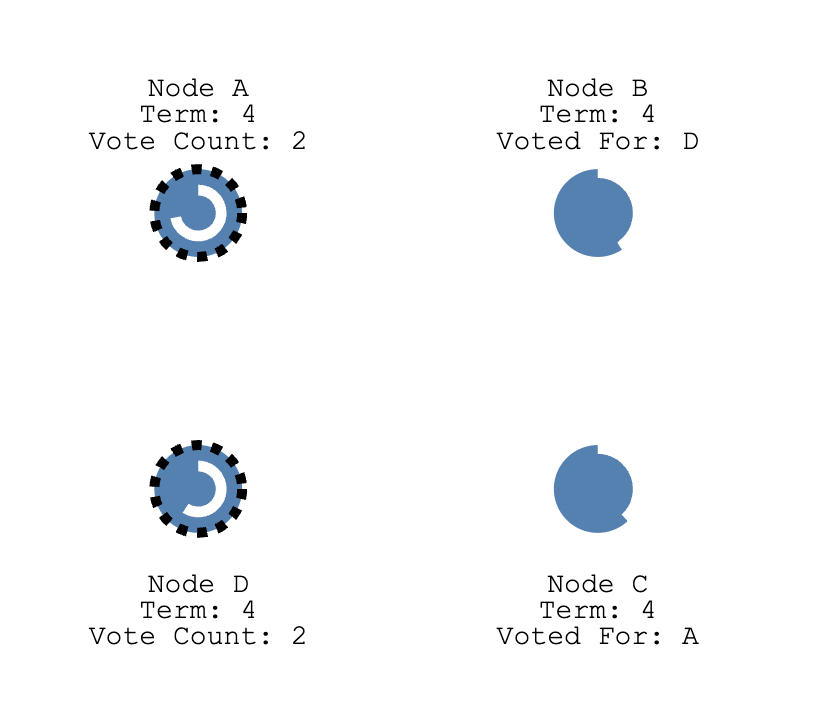
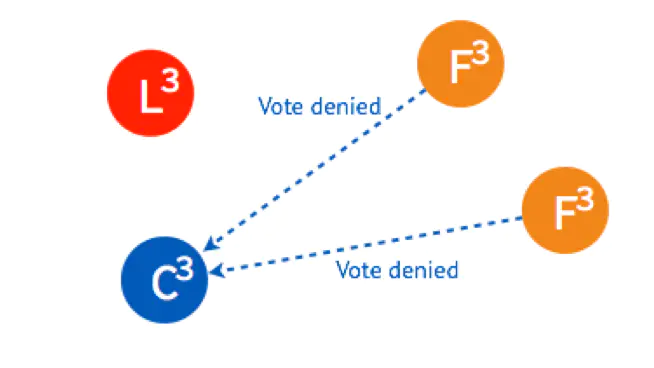
FollowerA明显比FollowerD要先到达选举超时,所以FollowerA会率先发起拉票请求
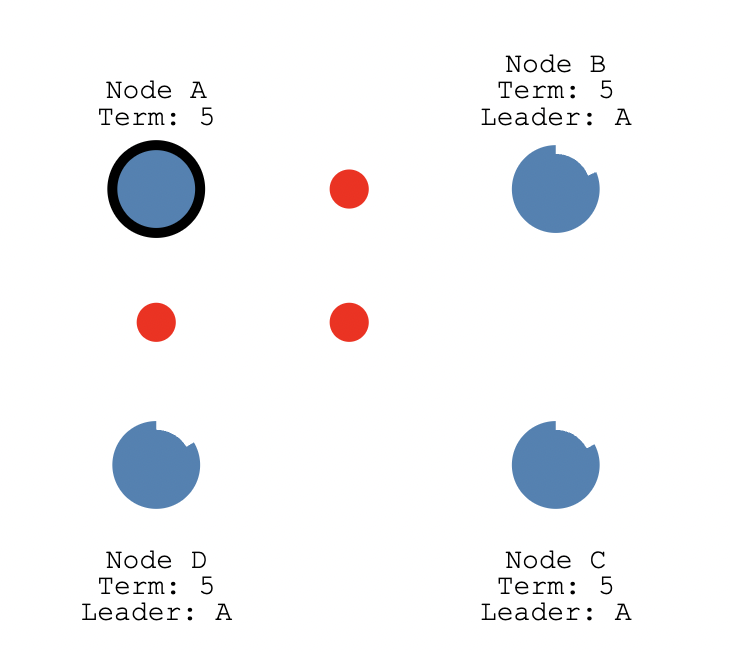
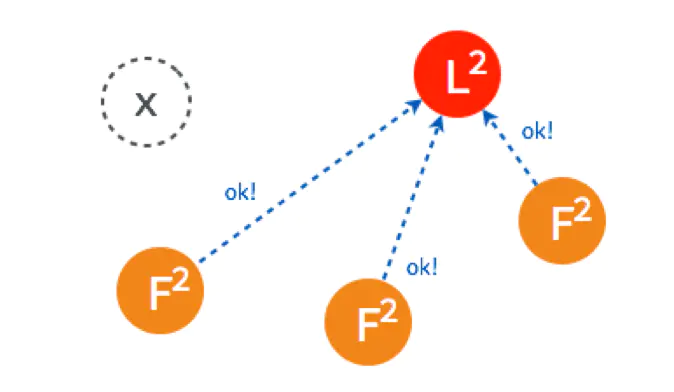
NodeB和NodeC在term5的时候还没投过票呢,都会响应CandidateA,超过半数,所以CandidateA当选Leader,且term变为5;
CandidateA当选Leader之后给NodeBCD发送心跳。
但是有一个情况,当发送给NodeD的心跳还没到的时候,NodeD这个时候还是Candidate,倒计时一结束就会给NodeB和NodeC发了拉票请求,
因为NodeB和NodeC在term5的时候已经投票给了A,所以会响应CandidateD拒绝,随后CandidateD收到来自Leader的心跳,那么CandidateD变为FollowerD。
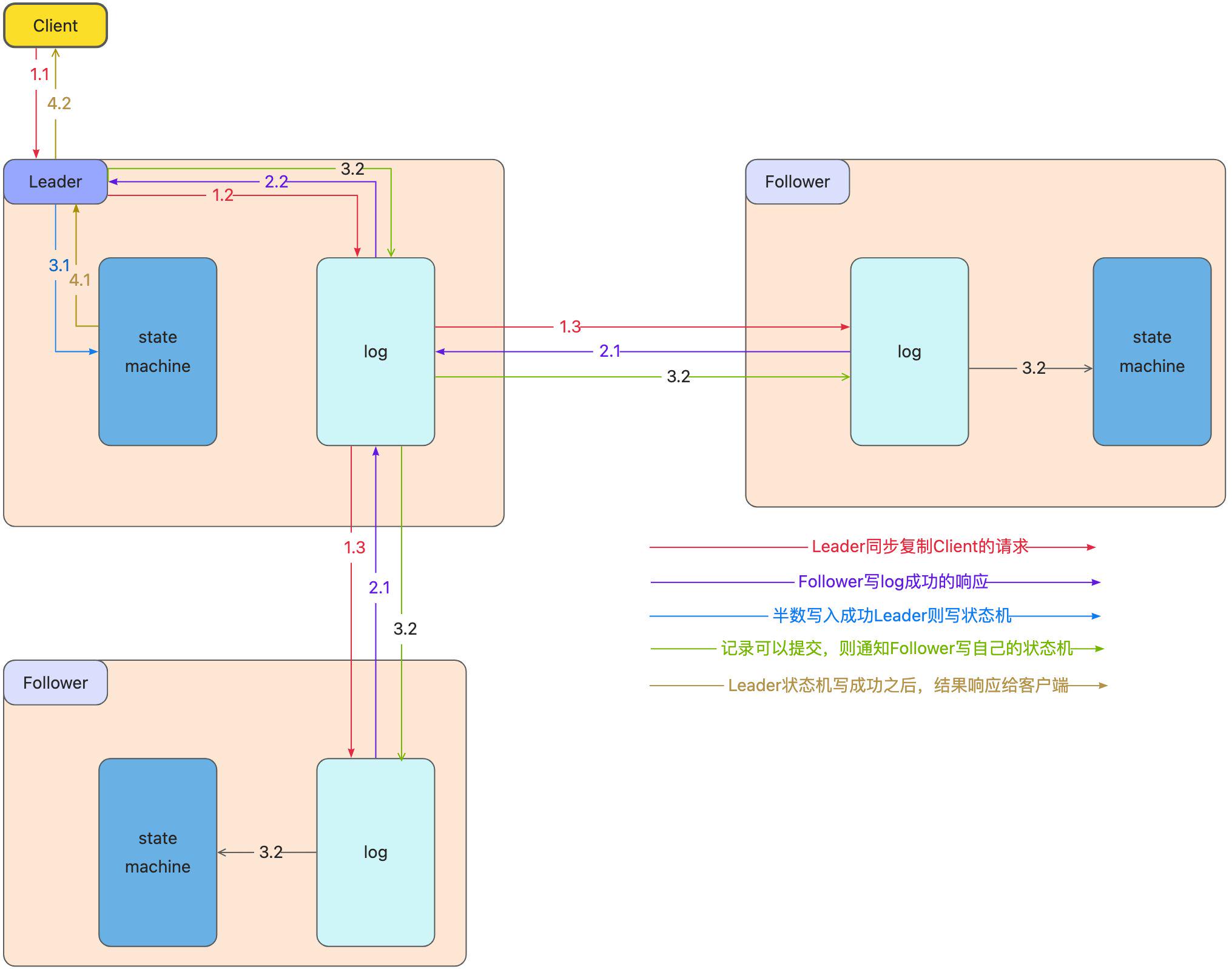
一旦一个领导人被选举出来,Leader就开始履行自己的职责,向Follower发送心跳确保自己的Leader地位,同时也开始为客户端提供服务;客户端将命令发送给Leader,Leader首先将命令写入它自己的log中,然后向所有其他的Follower发送 AppendEntries 的RPC。通常这些RPC会被同时发送所有Follower,以并行的方式执行,并等待这些消息的响应。一旦Leader收到足够多的响应,可以认为该条命令已经在多数服务器上处于已提交状态时,那么该条命令就可以被执行。领导者这时会将命令发送给状态机,当执行结束后,它会将结果返回给客户端。不仅如此,一旦服务器知道某个记录已经处于提交状态,它就会通过后续的 AppendEntries 远程调用告知其他的服务器。所以最终,每个Follower都会知道该记录已提交,并且将该命令发送至自己本地的状态机执行。如果跟随者崩溃了或处于慢响应状态,领导者会反复重试这个调用,直到跟随者恢复后,领导者就能重试成功。但是领导者并不需要等待每个跟随者的响应,它只需要等到足够数量的响应,保证记录已被大多数服务器存储即可。所以这样就能在一般情况下获得很好的性能提升。也就是说,在通常情况下,只需要获得大多数最快的服务器的应答,领导者就可以立即执行命令,并将结果返回至客户端。例如,如果某个服务器很慢,这并不能影响客户端获得响应的速度,因为领导者并不需要一直等待该台服务器。
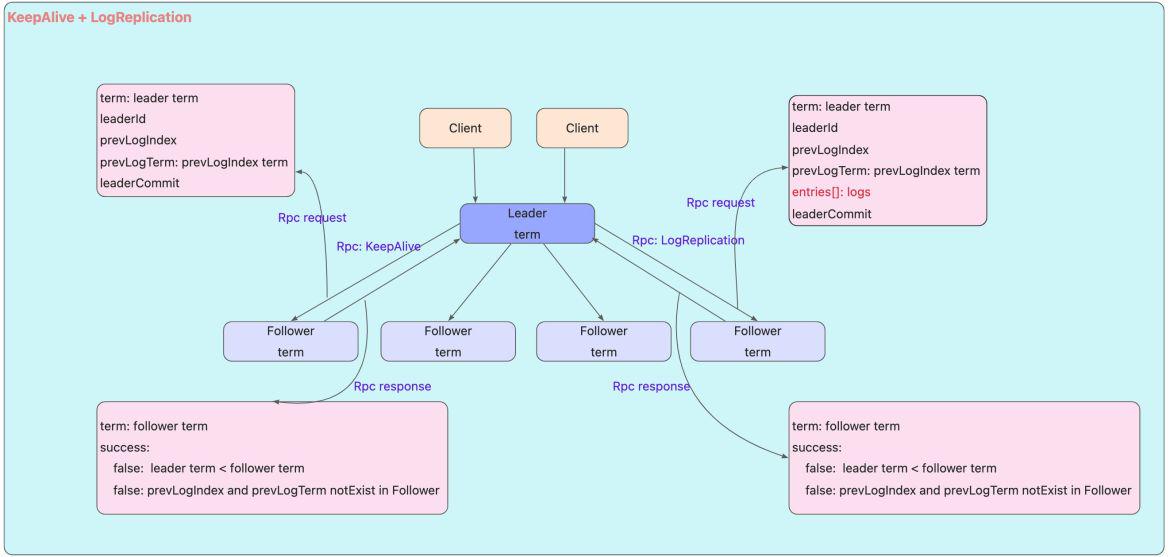
复制日志 Log Replication
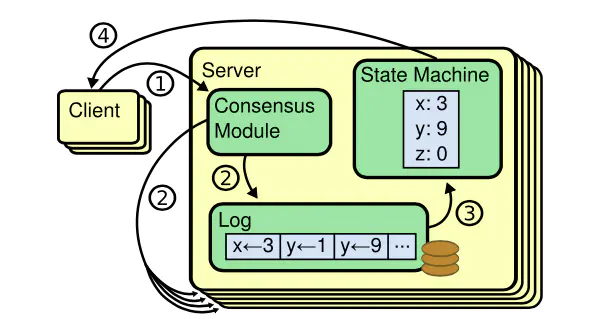
第①步,客户端把更新指令发给server(对应Raft中的Leader节点)
第②步,server把指令以log方式持久化(追加到日志队尾),然后发送到其他节点(Raft中的Follower)
第③步,日志被发送到所有节点后(Raft中超过半数节点即可),server将数据应用到状态机(提交)
第④步,回复客户端数据修改成功
因为Log日志队列是有序的,只要保证所有节点的队列数据一致,就可以按照先进先出的顺序执行相同的日志(通常里面存的是指令),状态机的最终状态肯定是一致的。
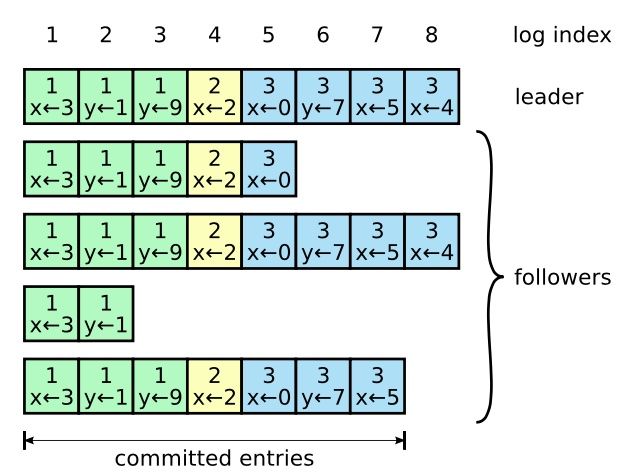
日志由有序序号标记的条目组成。每个条目都包含创建时的任期号(图中框中的数字),和一个状态机需要执行的指令。一个条目当可以安全地被应用到状态机中去的时候,就认为是可以提交了。
在正常的操作中,领导人和跟随者的日志保持一致性,所以附加日志 RPC 的一致性检查从来不会失败。然而,领导人崩溃的情况会使得日志处于不一致的状态(老的领导人可能还没有完全复制所有的日志条目)。这种不一致问题会在领导人和跟随者的一系列崩溃下加剧。下图展示了跟随者的日志可能和新的领导人不同。跟随者可能会丢失一些在新的领导人中存在的日志条目,他也可能拥有一些领导人没有的日志条目,或者两者都发生。丢失或者多出日志条目可能会持续多个任期。
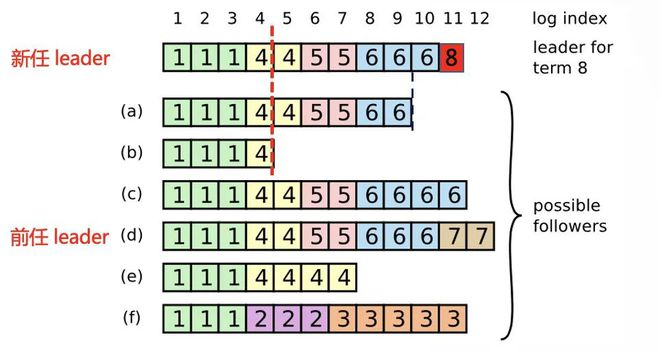
当一个领导人成功当选时,跟随者可能是任何情况(a-f),每一个盒子表示是一个日志条目;里面的数字表示任期号。
在term1的时候,所有节点的数据都正常复制,然后Leader崩溃触发选举,这时候(f)被选为新的Leader并开启新的term 2,写入了3条数据,在这些数据复制到其它节点之前(f)就崩溃了,但是因为恢复的快所以在term 3又被选为Leader。在term 3中(f)从客户端接收到5条数据后又崩溃了,请注意这时候term 2和3的数据都还没有复制到其它节点,所以客户端不可能收到提交成功的Response。在第4个任期(e)被选为Leader,先正常复制了2条数据之后,再提交了2条数据后(e)又崩溃了。随后是(a)在第5任期当选Leader,正常复制了2条数据之后崩溃,随后是(c)在第6任期当选Leader,先正常复制了3条数据之后,再提交了1条数据后(c)又崩溃了。(d)当选Leader,任期7收到2条指令后崩溃就出现了图中的状态。
之后第一个节点在 term 8 成功竞选成为 leader 并生成了一条新日志,这条新日志的 logTerm 为 8,logIndex 为 11。
这个新任 leader 在将这条新日志复制给其他节点的时候,会带上前一条日志的元数据,也就是 prevLogTerm 为 6,prevLogIndex 为 10。刚开始由于只有节点 c 和 d 包含这个前一条日志而复制成功,其他节点则会拒绝复制。leader 节点收到复制失败的回包后,需要往前移动待复制的日志列表然后重新发送日志复制请求。例如 leader 节点能够成功向节点 b 复制日志的请求,该请求体的内容为:前一条日志的 prevLogTerm 为 4,prevLogIndex 为 4,而待复制的日志列表则包含从 logIndex 为 5 开始的所有日志
Leader为每一个Follower维护一个nextIndex值。该值用于确定需要发送给该Follower的下一条日志的位置索引。该值在当前服务器成功当选Leader后会重置为本地日志的最后一条索引号+1。
当Leader了解到日志发生冲突之后,便递减nextIndex值,并重新发送AppendEntries RPC到该Follower,不断重复这个过程,一直到Follower接受该消息。
一旦Follower接受了AppendEntries RPC消息,Leader则根据nextIndex值可以确定发生冲突的位置,从而强迫Follower的日志重复自己的日志以解决冲突问题。
差异处理
Raft通过两个约定来保证Leader和Follower的数据最终会达成一致。
Leader节点只会追加log数据,不会修改、删除已有数据
如果Follower在指定的index上的log条目和Leader任期号不一致,则会删除Follower上的数据,重新同步Leader的数据
在相同的Index上,领导人的日志和Follower的日志不一样,Raft强制Follower上的日志必须和Leader相同,不同则用Leader上的日志覆盖Follower
Leader发送日志给Follower的时候,Follower同一个Index处的term号更大?因为Follower原来是Leader,日志后还没复制到超过半数节点就崩溃了。这种情况下,Follower收到Leader的日志复制包后就会删除自己的,不管term是大还是小
图形案例
正常情况下复制日志
Raft 在实际应用场景中的一致性更多的是体现在不同节点之间的数据一致性,客户端发送请求到任何一个节点都能收到一致的返回,当一个节点出故障后,其他节点仍然能以已有的数据正常进行。
在选主之后的复制日志就是为了达到这个目的。
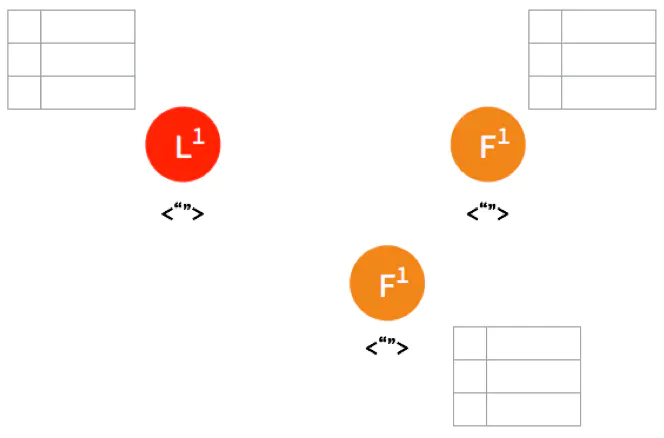
一开始,Leader 和 两个 Follower 都没有任何数据。
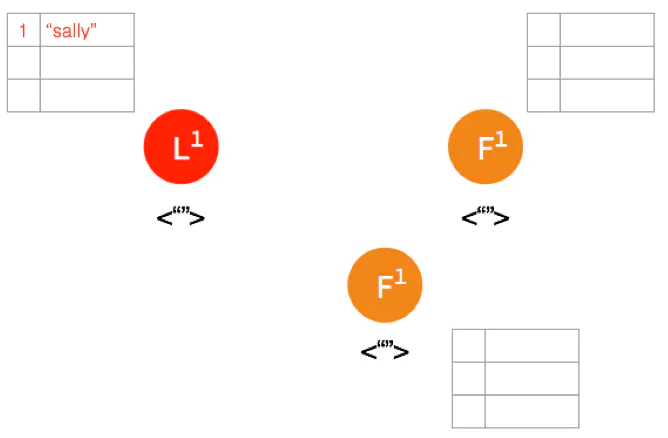
客户端发送请求给 Leader,储存数据 “sally”,Leader 先将数据写在本地日志,这时候数据还是 Uncommitted (还没最终确认,红色表示)
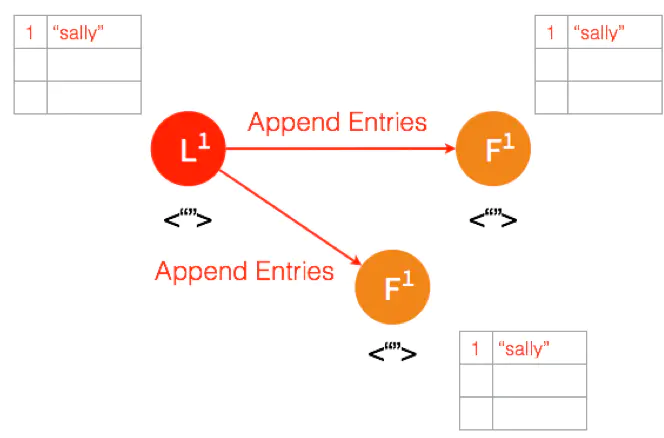
Leader 给两个 Follower 发送 AppendEntries 请求,数据在 Follower 上没有冲突,则将数据暂时写在本地日志,Follower 的数据也还是 Uncommitted。
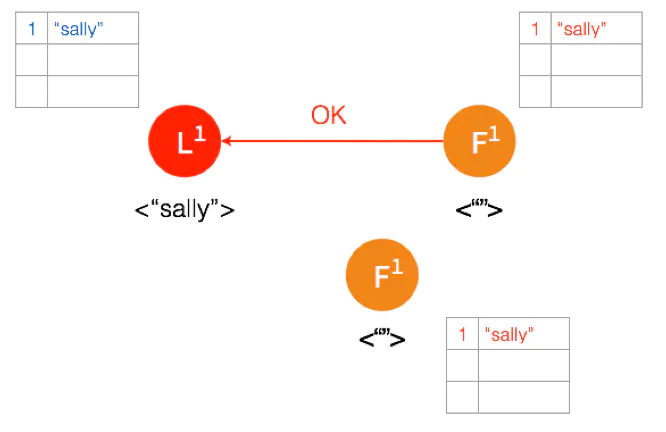
Follower 将数据写到本地后,返回 OK。Leader 收到后成功返回,只要收到的成功的返回数量超过半数 (包含Leader),Leader 将数据 “sally” 的状态改成 Committed。( 这个时候 Leader 就可以返回给客户端了)
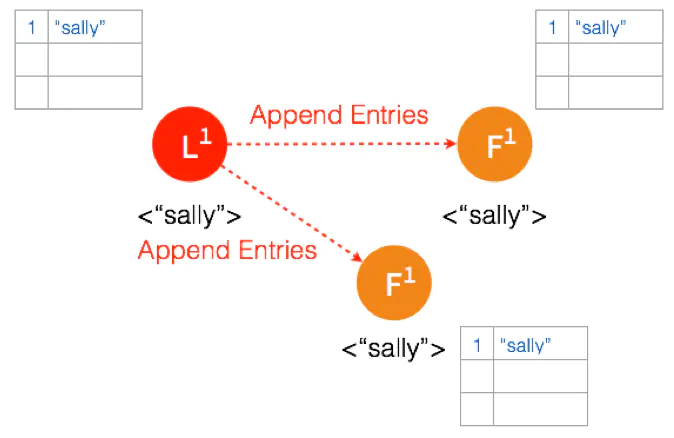
Leader 再次给 Follower 发送 AppendEntries 请求,收到请求后,Follower 将本地日志里 Uncommitted 数据改成 Committed。这样就完成了一整个复制日志的过程,三个节点的数据是一致的。
Network Partition情况下复制日志
在 Network Partition 的情况下,部分节点之间没办法互相通信,Raft 也能保证在这种情况下数据的一致性。
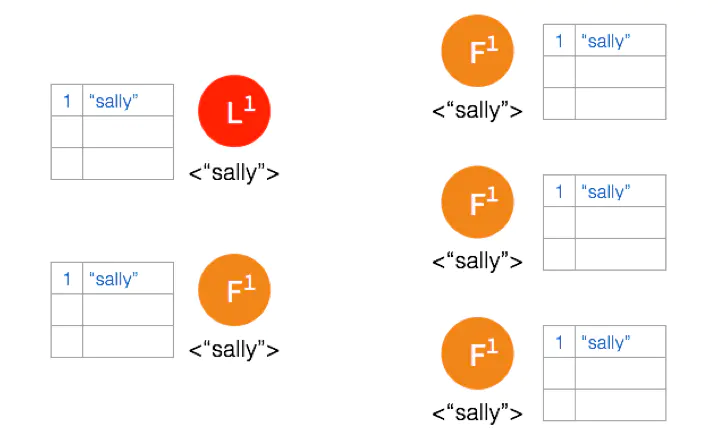
一开始有 5 个节点处于同一网络状态下。

Network Partition 将节点分成两边,一边有两个节点,一边三个节点。
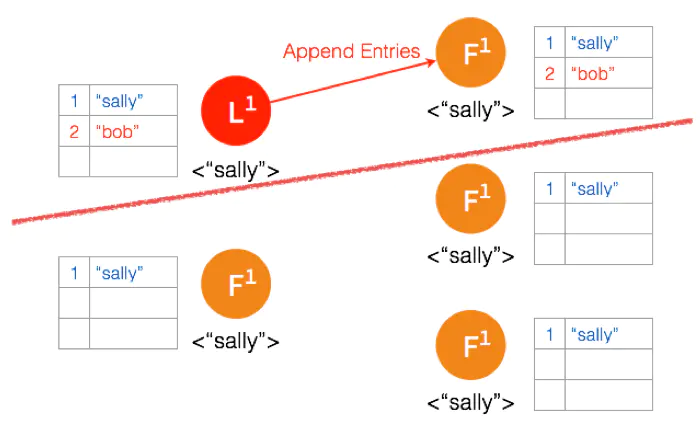
两个节点这边已经有 Leader 了,来自客户端的数据 “bob” 通过 Leader 同步到 Follower。
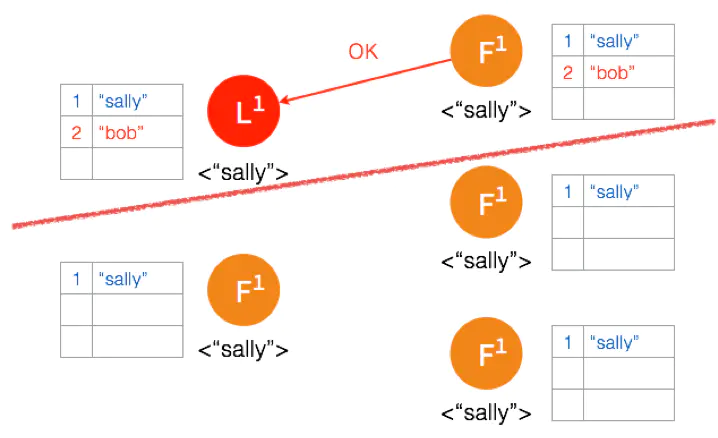
因为只有两个节点,少于3个节点,所以 “bob” 的状态仍是 Uncommitted。所以在这里,服务器会返回错误给客户端
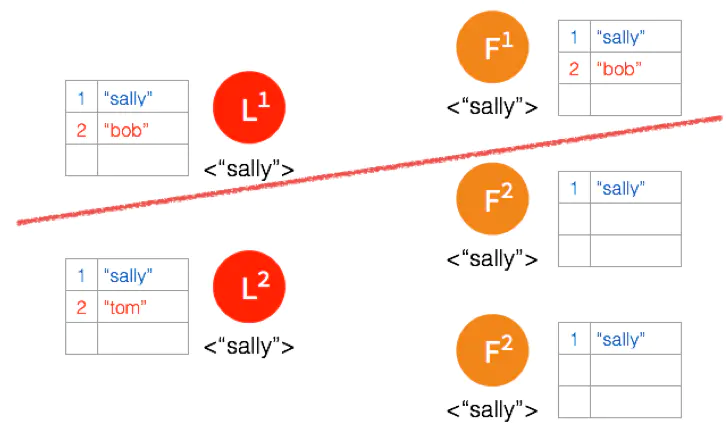
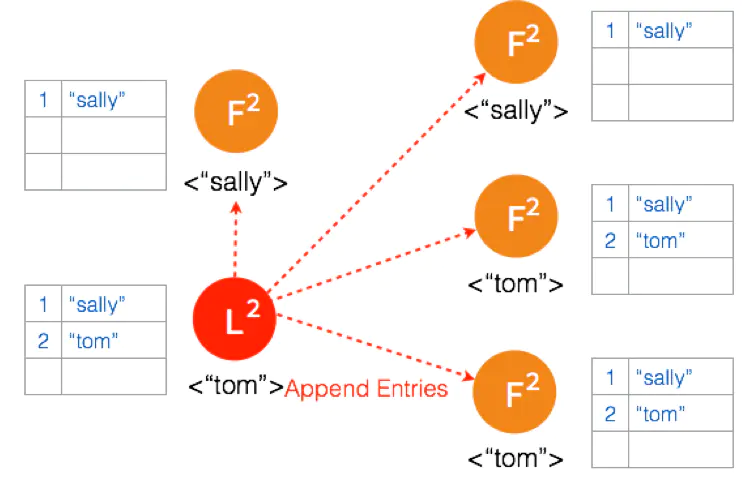
另外一个 Partition 有三个节点,进行重新选主。客户端数据 “tom” 发到新的 Leader,通过和上节网络状态下相似的过程,同步到另外两个 Follower。

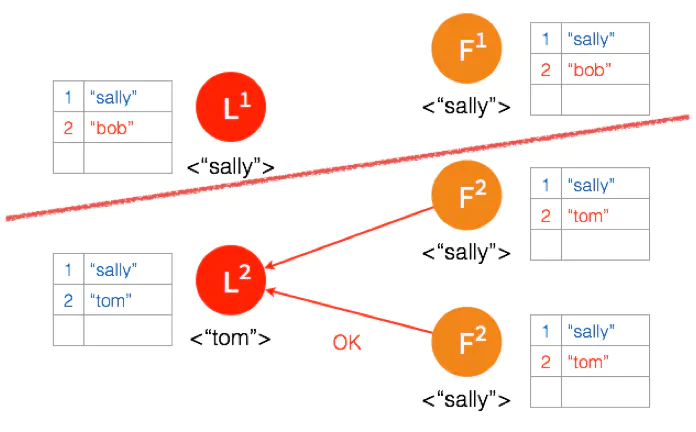
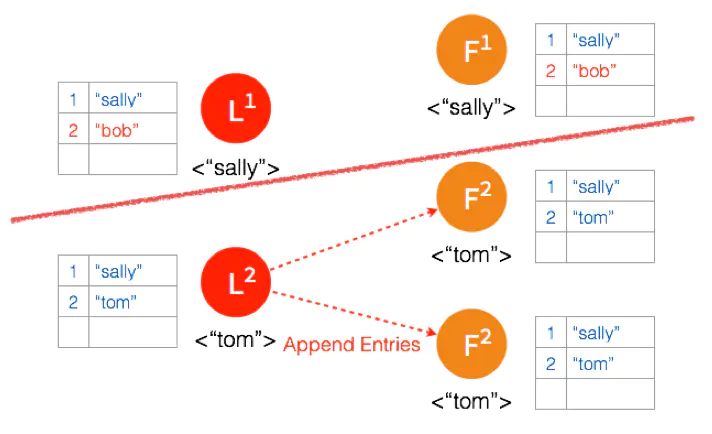
因为这个 Partition 有3个节点,超过半数,所以数据 “tom” 都 Commit 了。
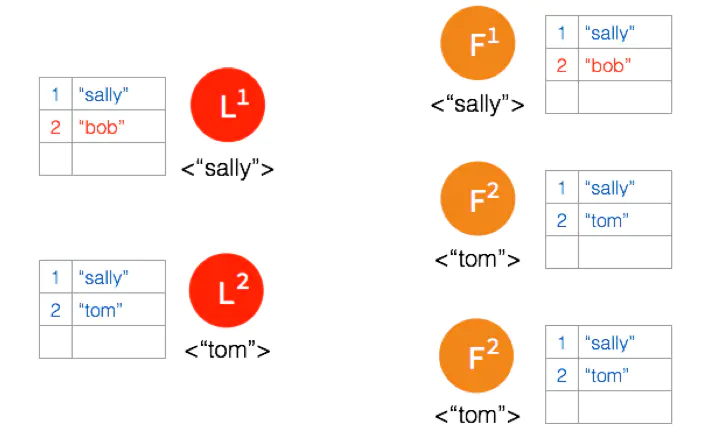
网络状态恢复,5个节点再次处于同一个网络状态下。但是这里出现了数据冲突 “bob" 和 “tom"
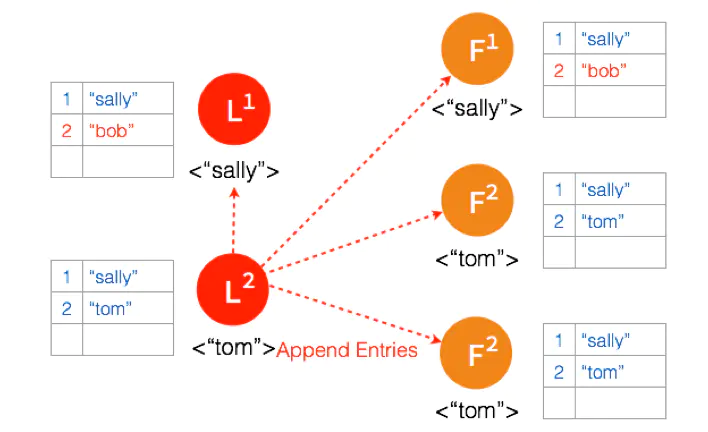
三个节点的 Leader 广播 AppendEntries
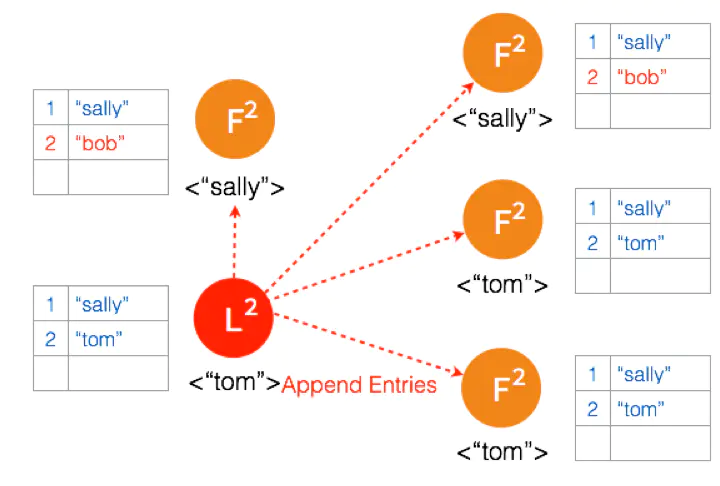
两个节点 Partition 的 Leader 自动降级为 Follower,因为这个 Partition 的数据 “bob” 没有 Commit,返回给客户端的是错误,客户端知道请求没有成功,所以 Follower 在收到 AppendEntries 请求时,可以把 “bob“ 删除,然后同步 ”tom”,通过这么一个过程,就完成了在 Network Partition 情况下的复制日志,保证了数据的一致性。
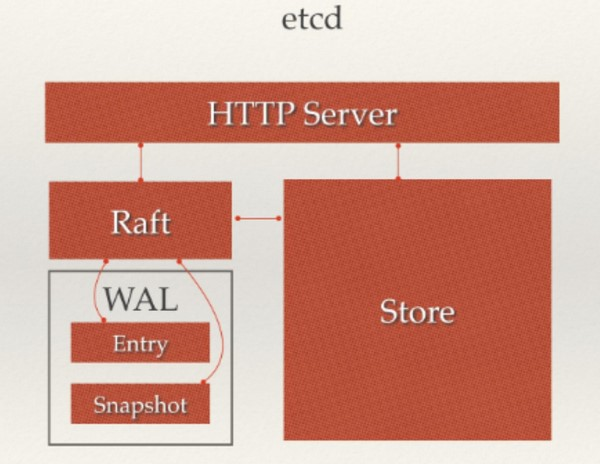
Etcd工作流程
架构图
工作流程
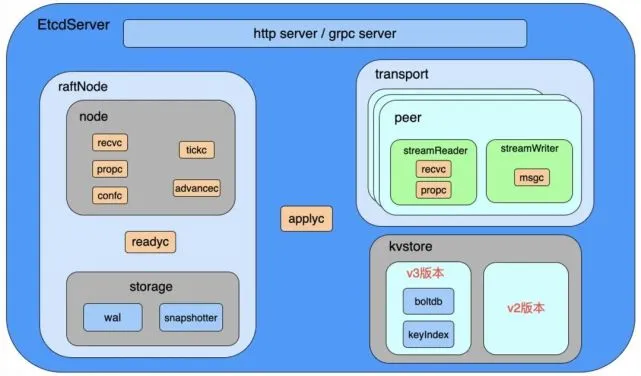
api
api 接口支持 http 协议和 grpc 协议,用于接收其他节点的请求
node
node 主要负责 raft 算法的实现
storage
storage 主要负责 raft 日志以及 snap 快照文件的存储
etcd 采用 wal 文件来保存日志,当wal日志量不断增大, 如果节点宕机需要重新恢复,那么则需要从头读取全部的WAL日志文件,这显然是非常耗时的。为了解决这些问题,etcd会定期创建快照并将其保存到本地磁盘中,在恢复节点状态时会先加载快照文件,使用该快照数据将节点恢复到对应的状态,之后从快照数据之后的相应位置开始读取WAL日志文件,最终将节点恢复到正确的状态。
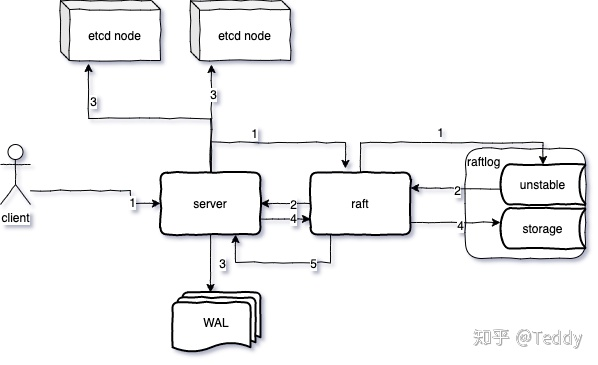
当etcd收到client的请求之后,请求中封装Entry交给raft模块处理,raft模块将entry保存到raftlog的unstable中;
raft模块封装entry成为一个ready实例,并放入readyC channel中等待server处理
server收到持久化的entry(pb序列化),写入WAL(发送到其他的etcd节点)
让raft模块把entry从unstable移动到storage中保存
收到半数以上节点响应,leader节点认为该entry应该被commit,封装到ready实例返回给server;
server把ready实例中的entry记录应用到状态机中。
transport
transport 主要负责集群节点间的通信
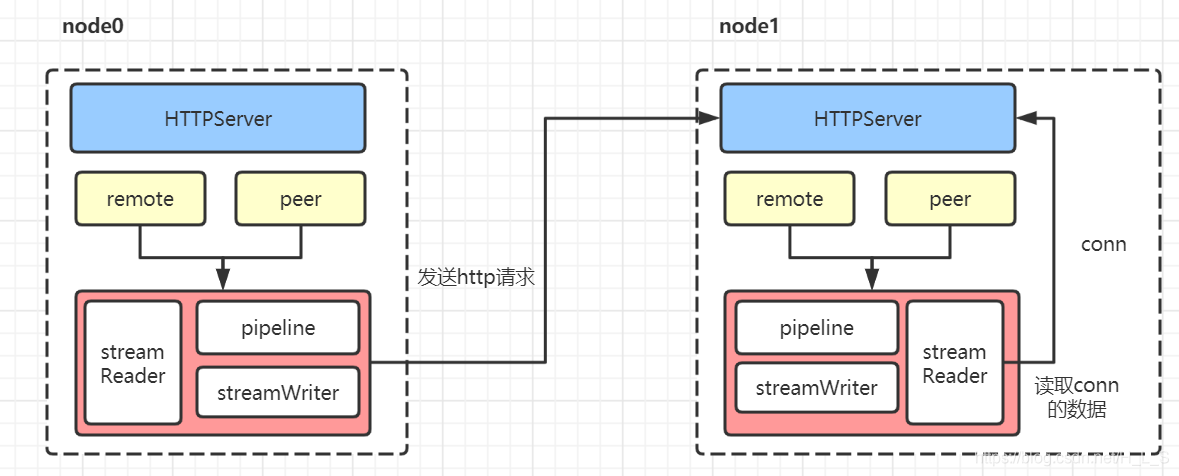
每个节点的 Transport 启动一个 HTTPServer 用来接收其他节点请求
每个节点会维护两个节点信息字段 remote 和 peer
remote 存储从远程节点获取的节点信息, peer 存储在 config 中配置的伙伴节点信息
remote/peer 会通过 pipeline 和 streamWriter 真实的调用 get、post 发起 http 请求/gRpc
peer 会通过 streamReader 读取请求的实体
kvstore
kvstore 分为 v2 和 v3 两个版本数据库,主要负责业务数据的存储,其中 v3 版本数据库的实现采用 lboltdb 和 keyIndex,支持 mvcc 机制。
mvcc
ETCD 主要通过版本 ID 实现多版本并发(revision),版本的组成包括一个 main 主版本 ID,在每次进行增删改操作(新事物)时,main+1, 另一个 sub 子版本 ID,在同一个事务中,每次修改一次,就会递增一次。
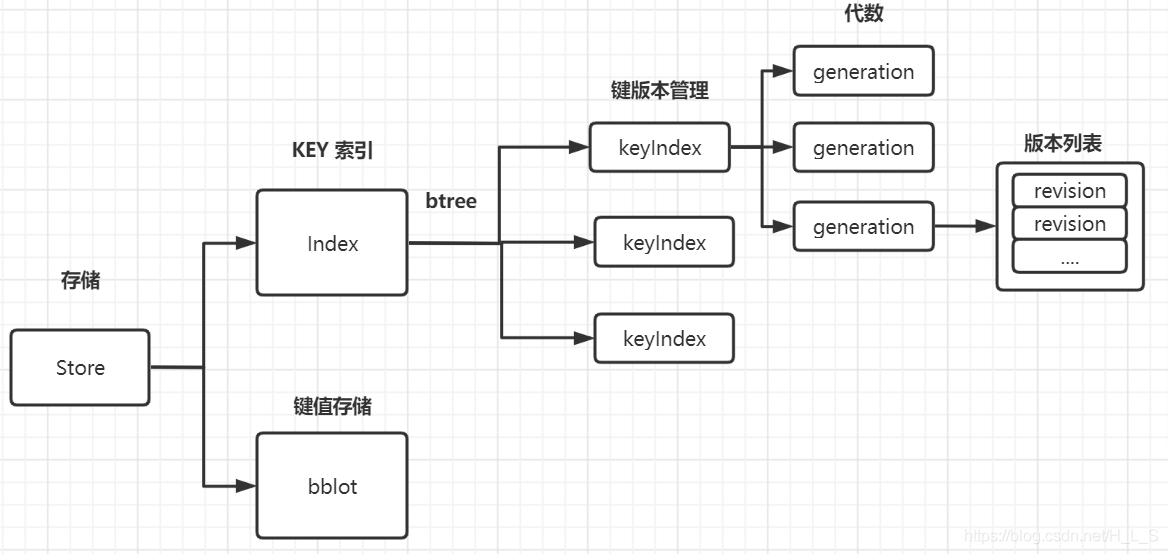
存储包括两部分,一是KV数据,二是索引数据。KV 数据通过 bbolt (键值对存储数据库)进行持久化存储。索引数据通过 btree 进行保存。在对 KV 进行操作时,首先操作 Index,再操作 bbolt。
索引
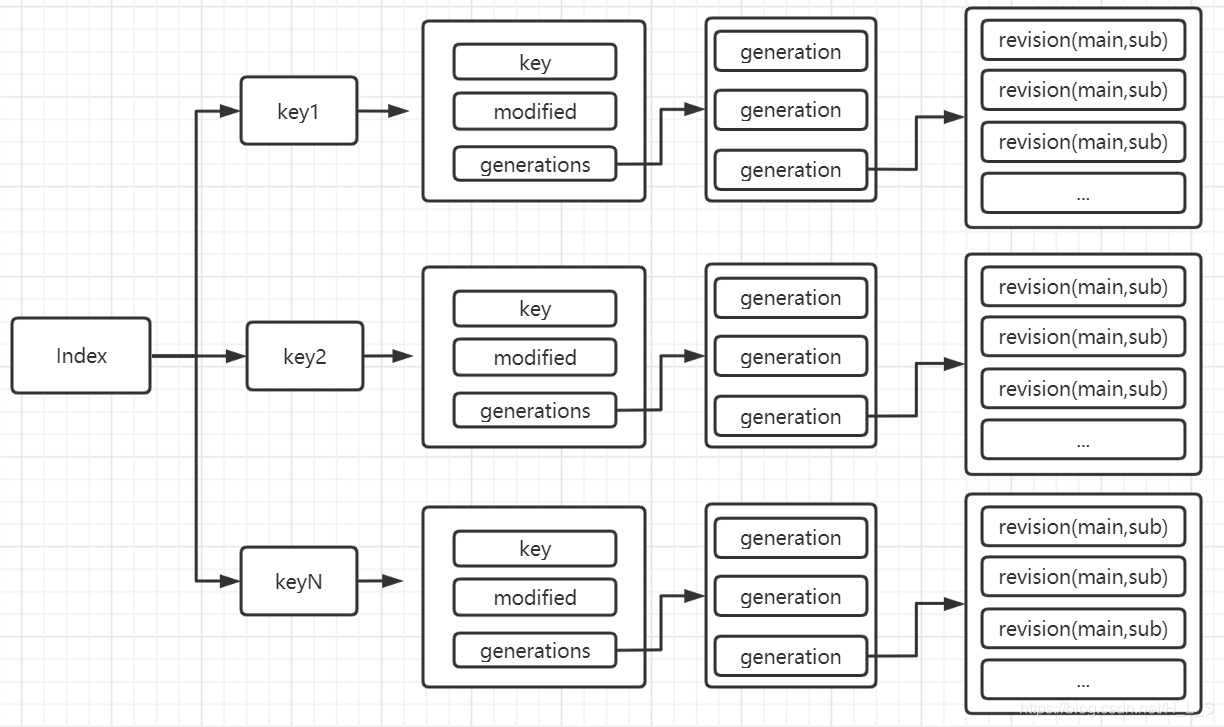
索引主要通过 btree 组成, key 值作为索引键, value 主要三部分组成:
key 原始键名。
modified 最近最新更新的 revision
generations 历史修改的版本记录值
KV存储
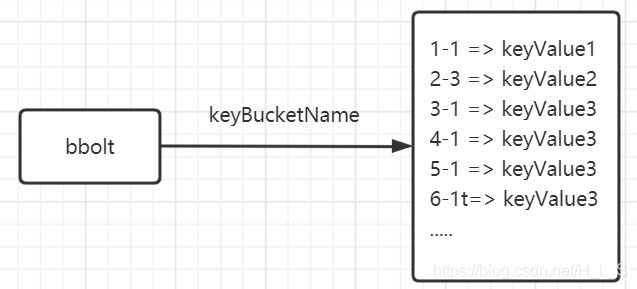
key 由 revision 组成的主版本号和副版本号组成,格式为 main_sub(t) (上图有-,代码中实际用_), 如果键值以t结尾表示删除。
数据变更
ETCD 以增加版本的方式进行数据变更,而不会去操作原有版本数据(同时维护索引数据和bbolt数据)。
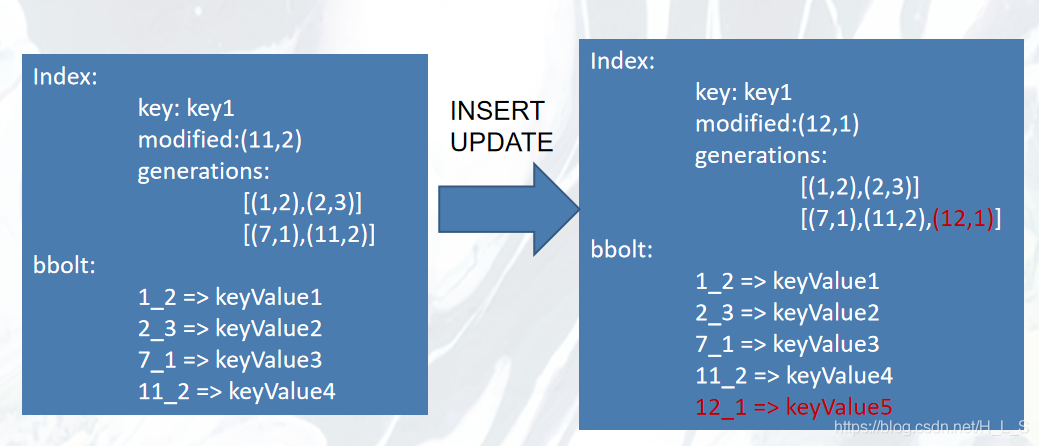
INSERT/UPDATE
对 key1 依次修改 value1->value5。
Index:通过generations 对 key1 的版本进行维护 (main,sub)。
bbolt:每操作一次就生成一个新的键值对。
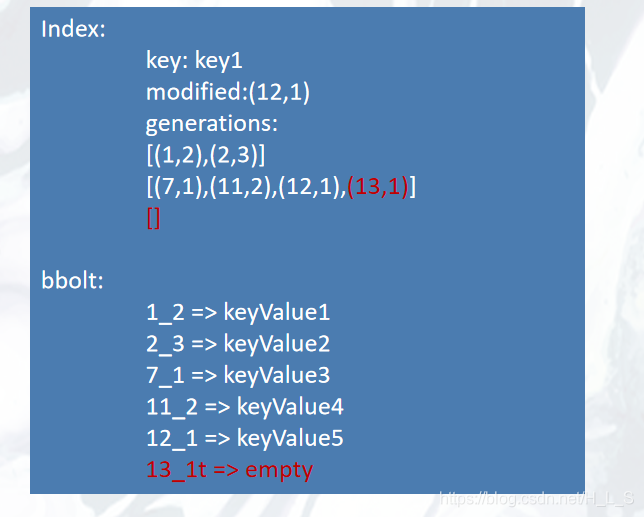
DELETE
Index:在 generations 最后一个 generation 中新增版本号(每个 generation 最后一个都是删除的版本号),并创建一个新的 generation。
bbolt:生成一个以t结尾的 key ,值为空。
RANGE(查找)
1.开启一个读事务,并获取当前系统最新的版本 ID(main) currRev。
2.根据 key 和 currRev 从 Index 中查找 key 中所有版本号中第一个小于等于 currRev 的 revision。 比如 main=3, 那么查找到的 revision 就是(2,3)。
3.根据 revision, 生成 bbolt key(2_3)值,并从 bbolt 中获取 keyValue 值。
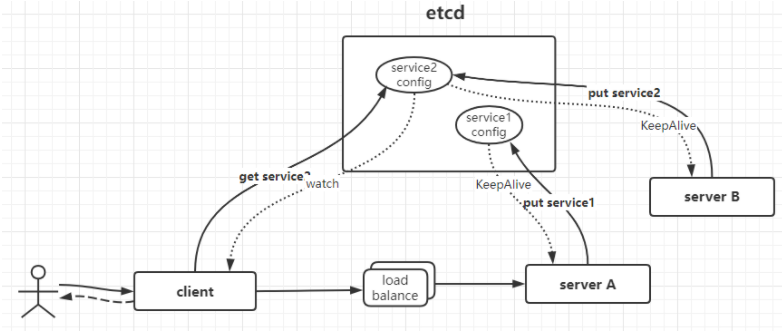
服务注册与发现
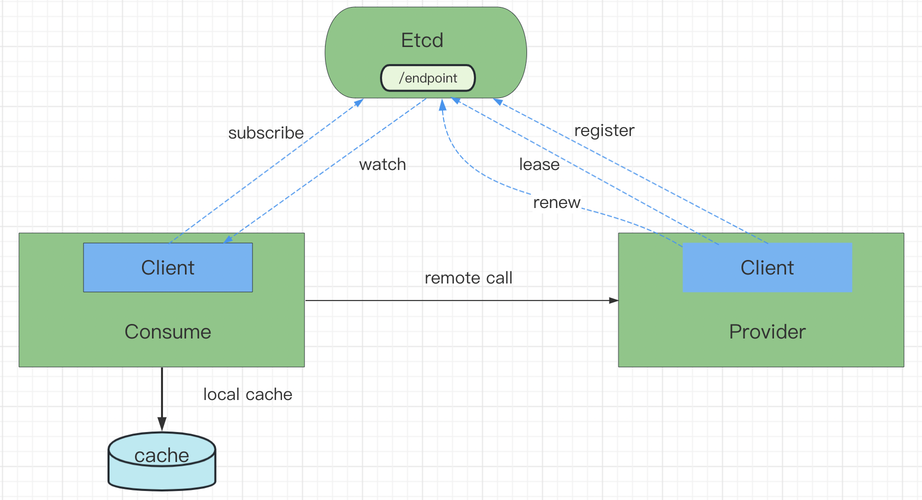
etcd 基于 Raft 算法,能够有力地保证分布式场景中的一致性。各个服务启动时注册到 etcd 上,同时为这些服务配置键的 TTL 时间。
注册到 etcd 上面的各个服务实例通过心跳的方式定期续租,实现服务实例的状态监控。
服务发现(Service Discovery)要解决的是分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务如何才能找到对方并建立连接。
存在一个高可靠、高可用的中心配置节点:基于 Ralf 算法的 etcd 天然支持。
服务提供方会持续的向配置节点注册服务:用户可以在 etcd 中注册服务,并且对注册的服务配置租约,定时续约以达到维持服务的目的(一旦停止续约,对应的服务就会失效)。
服务的调用方会持续地读取中心配置节点的配置并修改本机配置,然后 Reload 服务:服务提供方在 etcd 指定的目录(前缀机制支持)下注册服务,服务调用方在对应的目录下查询服务。
通过 watch 机制,服务调用方还可以监测服务的变化。
伪代码
服务注册
const schema = "etcdv3_resolver"
var (
serv = flag.String("service", "hello_service", "service name")
host = flag.String("host", "localhost", "listening host")
port = flag.String("port", "50001", "listening port")
reg = flag.String("reg", "http://localhost:2379", "register etcd address")
)
func main() {
flag.Parse()
lis, err := net.Listen("tcp", net.JoinHostPort(*host, *port))
if err != nil {
panic(err)
}
//调用注册 将服务注册到etcd中 并且添加续约时间
err = grpclb.Register(*reg, *serv, *host, *port, time.Second*10, 15)
if err != nil {
panic(err)
}
}
//注册
func Register(target, service, host, port string, interval time.Duration, ttl int) error {
// 以IP和Port作为etcd的value
serviceValue := net.JoinHostPort(host, port)
// 以schema+serviceName+value 作为etcd的key
serviceKey := fmt.Sprintf("/%s/%s/%s", schema, service, serviceValue)
// 将key和value存储到etcd中
if _, err := cli.Put(context.TODO(), serviceKey, serviceValue, clientv3.WithLease(resp.ID)); err != nil {
return err
}
}服务发现
var (
svc = flag.String("service", "hello_service", "service name")
reg = flag.String("reg", "http://localhost:2379", "register etcd address")
)
func main() {
flag.Parse()
// 实例化name命名解析器
r := grpclb.NewResolver(*reg, *svc)
resolver.Register(r)
ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second)
// 通过r.Scheme()+"://authority/"+*svc发现服务的IP+Port
// 设置负载均衡策略:轮循 roundrobin
conn, err := grpc.DialContext(ctx, r.Scheme()+"://authority/"+*svc, grpc.WithInsecure(), grpc.WithBalancerName(roundrobin.Name), grpc.WithBlock())
cancel()
if err != nil {
panic(err)
}
ticker := time.NewTicker(1000 * time.Millisecond)
for t := range ticker.C {
client := pb.NewGreeterClient(conn)
resp, err := client.SayHello(context.Background(), &pb.HelloRequest{Name: "world " + strconv.Itoa(t.Second())})
if err == nil {
logrus.Infof("%v: Reply is %s\n", t, resp.Message)
}
}watch机制
func (r *Resolver) watch(prefix string) {
// 根据name和schema拼接的前缀去匹配key,那么一定是一个列表,因为我们注册的key是schema+name+host:port 所以schema+name可以匹配多个key/value
resp, err := r.cli.Get(context.Background(), prefix, clientv3.WithPrefix())
if err == nil {
for i := range resp.Kvs {
addrDict[string(resp.Kvs[i].Value)] = resolver.Address{Addr: string(resp.Kvs[i].Value)}
}
}
//通知到grpc客户端地址列表
update := func() {
addrList := make([]resolver.Address, 0, len(addrDict))
for _, v := range addrDict {
addrList = append(addrList, v)
}
r.cc.UpdateState(resolver.State{Addresses: addrList})
}
}
update()
//监听etcd注册上来的服务变化(新增,修改或者删除)
rch := r.cli.Watch(context.Background(), prefix, clientv3.WithPrefix(), clientv3.WithPrevKV())
for n := range rch {
for _, ev := range n.Events {
switch ev.Type {
case mvccpb.PUT: //新增或者修改服务
addrDict[string(ev.Kv.Key)] = resolver.Address{Addr: string(ev.Kv.Value)}
case mvccpb.DELETE: //删除服务
delete(addrDict, string(ev.PrevKv.Key))
}
}
update()
}租约/续约
// 创建租约
resp, err := cli.Grant(context.TODO(), int64(ttl))
if err != nil {
return err
}
// 续约
if _, err := cli.KeepAlive(context.TODO(), resp.ID); err != nil {
return err
}清除过期租约
通过一个队列,定期检查并清除过期的租约
// lessor implements Lessor interface.
type lessor struct {
mu sync.RWMutex
...
leaseMap map[LeaseID]*Lease
leaseExpiredNotifier *LeaseExpiredNotifier
leaseCheckpointHeap LeaseQueue
itemMap map[LeaseItem]LeaseID
...
// When a lease's deadline should be persisted to preserve the remaining TTL across leader
// elections and restarts, the lessor will checkpoint the lease by the Checkpointer.
// 检查TTL
cp Checkpointer
...
}// LeaseExpiredNotifier is a queue used to notify lessor to revoke expired lease.
// Only save one item for a lease, `Register` will update time of the corresponding lease.
type LeaseExpiredNotifier struct {
m map[LeaseID]*LeaseWithTime
queue LeaseQueue
}// LeaseExpiredNotifier is a queue used to notify lessor to revoke expired lease.
// Only save one item for a lease, `Register` will update time of the corresponding lease.
type LeaseExpiredNotifier struct {
m map[LeaseID]*LeaseWithTime
queue LeaseQueue
}func (le *lessor) runLoop() {
defer close(le.doneC)
for {
// revokeExpiredLeases finds all leases past their expiry and sends them to expired channel for to be revoked.
// 找到所有过期的租约,并将它们发送到过期通道以进行撤销。
le.revokeExpiredLeases()
// checkpointScheduledLeases finds all scheduled lease checkpoints that are due and submits them to the checkpointer to persist them to the consensus log.
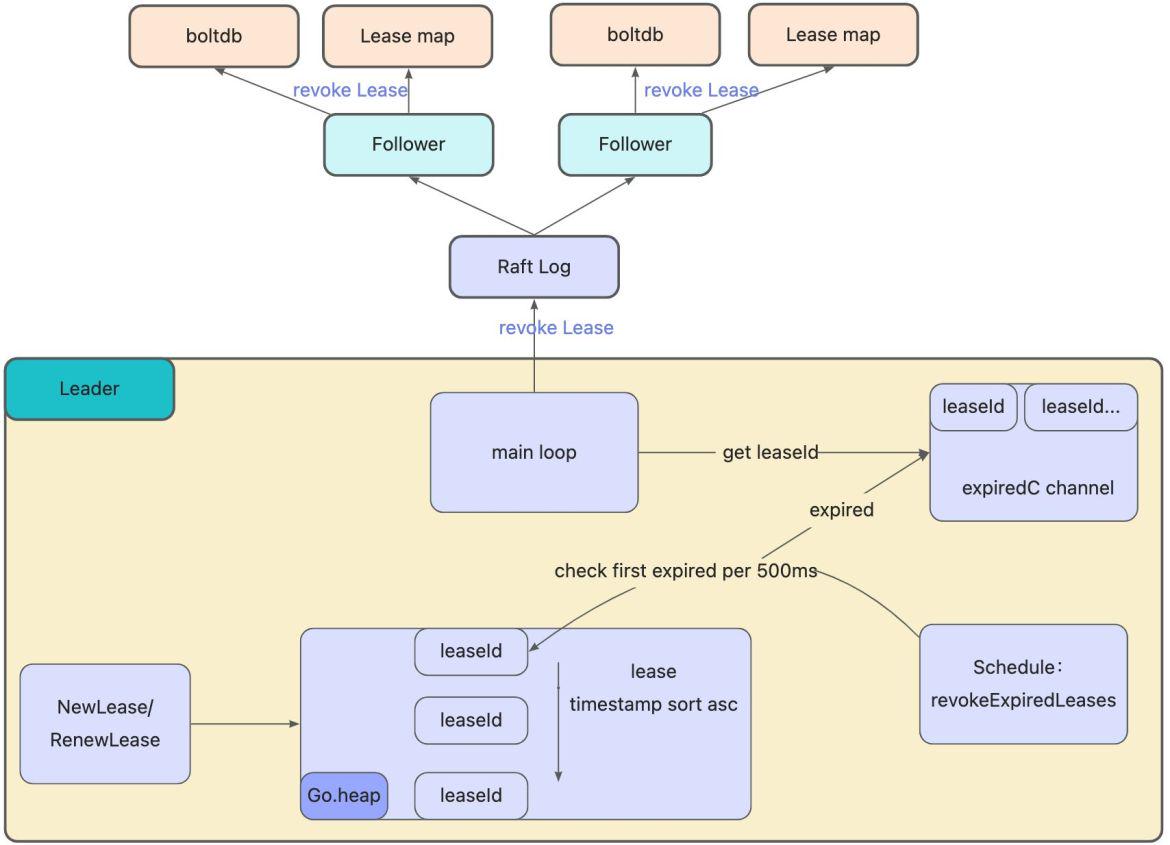
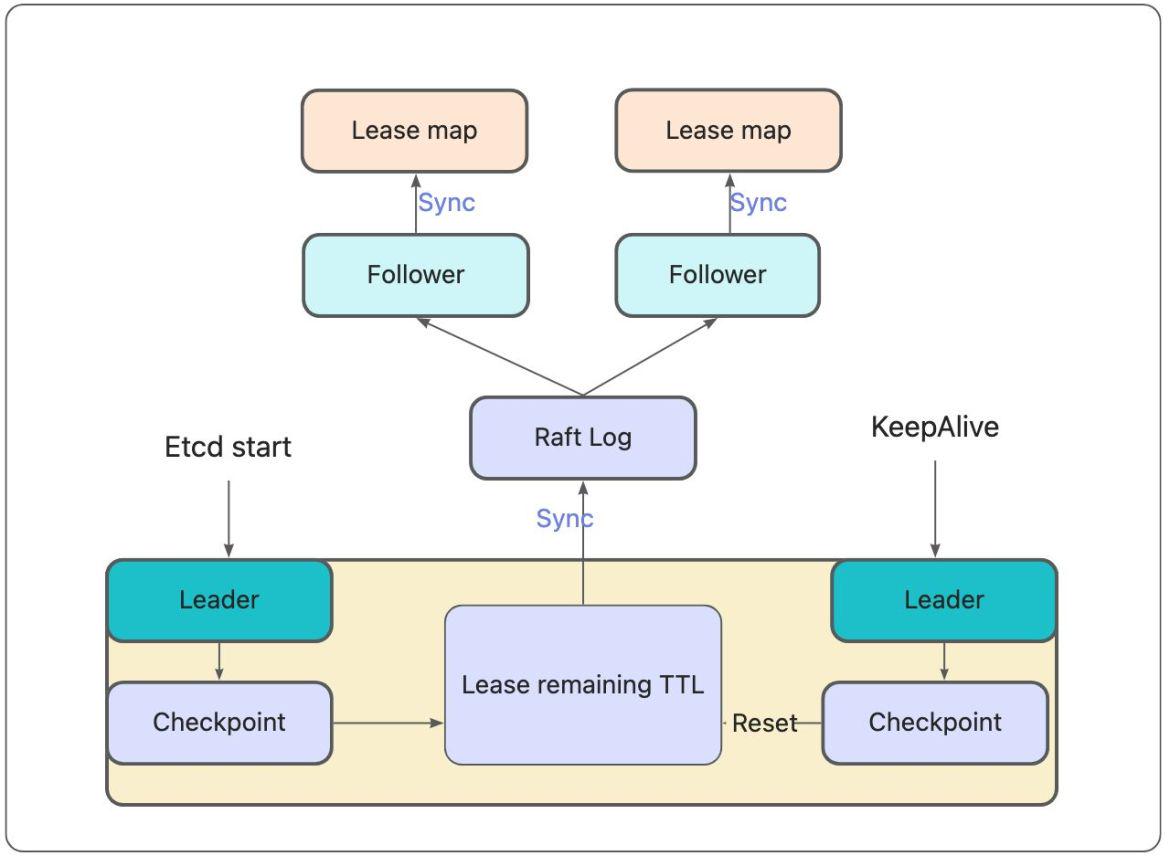
// 检查 Lease 是否过期、维护最小堆、针对过期的 Lease 发起 revoke 操作,都是 Leader 节点负责的,
// 如果Leader重启/宕机,选出了一个新的Leader,新Leader需要继续完成以上操作,但早期的etcd并未存储 Lease 剩余 TTL 信息,因此重建时就会自动给所有 Lease 自动续期了。
// 然而若频繁出现 Leader 切换,切换时间小于 Lease 的 TTL,这会导致 Lease 永远无法删除,大量 key 堆积,db 大小超过配额等异常,
// 为了解决此问题,etcd 引入了检查点机制,就是下面的 CheckpointScheduledLease 任务
le.checkpointScheduledLeases()
select {
case <-time.After(500 * time.Millisecond):
case <-le.stopC:
return
}
}
}
Reference Documents
https://www.ibm.com/topics/etcd
https://kubernetes.io//docs/home/
https://gist.github.com/yurishkuro/10cb2dc42f42a007a8ce0e055ed0d171
https://github.com/maemual/raft-zh_cn/blob/master/raft-zh_cn.md
http://thesecretlivesofdata.com/raft/
https://www.mianshigee.com/tutorial/etcd/documentation-op-guide-performance.md






![[python课程设计1]学生成绩管理系统](https://img-blog.csdnimg.cn/img_convert/9df01e0ab7be16ad3cebd79a47e5f824.png)

![【GO】K8s 管理系统项目[API部分--Workflow]](https://img-blog.csdnimg.cn/4cc12591e9d748888ac432d8a88fae08.png)