今天需求是用pandas的两张表格合并起来,其中重复的部分将数据进行相加。
用到的是combine()这个函数。
函数详细的使用可以看这个大佬的文章:
https://www.cnblogs.com/traditional/p/12727997.html
(这个文章使用的测试数据有个陷阱,后面会说。)
我想说的一个场景是这样的:
表一:

表二:

可以看到两个测试表的区别在于D列,表一的D列是没有数据的,而表二的有。
一开始直接使用这个语句进行合并:
def sum(a, b):
return a + b
final_df = df_one.combine(df_two, sum)

得到的结果是这样的,明明表二的D列有数据,但是没有合并。
跟了下代码,这里的a + b是实际上将两个Series进行加操作,应该是nan加上一个数字的时候会报错,但是pandas的处理将出现错误的格子的错误信息忽视掉了,所以导致没有合并。
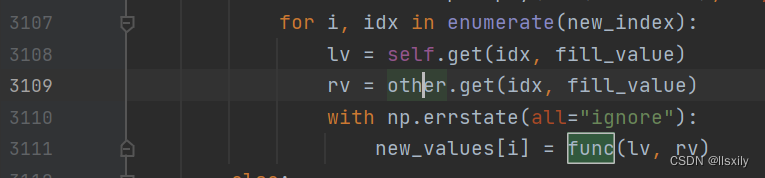
这里就要提到上面那个文章里面的陷阱,测试数据都是使用单行Series进行合并,所以combine后面的func实际上是对单个数值变量进行操作。
而如果你和我一样是用一个二维的dataframe表进行combine,他其实是对每个Series进行操作,所以简单的用+进行合并操作是会有问题的。这一点尤其是在使用lambda表达式这种匿名函数时更容易被忽视的。
那对于二维的Dataframe表格我提出的解决办法是:
def sum(a, b):
if pd.isna(a):
return b
elif pd.isna(b):
return a
else:
return a + b
def sum_s(a, b):
return a.combine(b, sum)
final_df = df_one.combine(df_two, sum_s)
对combine操作进行嵌套,我明白我这个代码非常丑,但是他能用。
如果你能把这个代码写的更漂亮,欢迎你在评论区指出,如果看到我会及时修改。
碎碎念:
可能比较少人直接用pandas做excel处理的库?我用的搜索引擎没有找到对pandas进行并表的操作。
挺奇怪的,我觉得pandas明明非常好用,对格式兼容很好。Dataframe的使用也非常舒服。





![[python课程设计1]学生成绩管理系统](https://img-blog.csdnimg.cn/img_convert/9df01e0ab7be16ad3cebd79a47e5f824.png)

![【GO】K8s 管理系统项目[API部分--Workflow]](https://img-blog.csdnimg.cn/4cc12591e9d748888ac432d8a88fae08.png)