一、系统文件配置
集群部署规划
NameNode和SecondaryNameNode不要安装在同一台服务器
ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode放在同一台机器上。
这里装了四台机器,ant151,ant152,ant153,ant154。
ant151 | ant152 | ant153 | ant154 |
NameNode | NameNode | ||
DataNode | DataNode | DataNode | DataNode |
NodeManager | NodeManager | NodeManager | NodeManager |
ResourceManager | ResourceManager | ||
JournalNode | JournalNode | JournalNode | |
DFSZKFController | DFSZKFController | ||
zk0 | zk1 | zk2 |
配置文件说明
Hadoop配置文件分为默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件。
core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml四个配置文件放在$HADOOP_HOME/etc/hadoop路径下。
3.配置集群
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://gky</value>
<description>逻辑名称,必须与hdfs-site.xml中的dfs.nameservices值保持一致</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/soft/hadoop313/tmpdata</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
<description>默认用户</description>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
<description></description>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
<description></description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>读写文件的buffer大小为:128K</description>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>ant151:2181,ant152:2181,ant153:2181</value>
<description></description>
</property>
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>10000</value>
<description>hadoop链接zookeeper的超时时长设置为10s</description>
</property>hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
<description>Hadoop中每一个block的备份数</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/soft/hadoop313/data/dfs/name</value>
<description>namenode上存储hdfs名字空间元数据目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/soft/hadoop313/data/dfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>ant151:9869</value>
<description></description>
</property>
<property>
<name>dfs.nameservices</name>
<value>gky</value>
<description>指定hdfs的nameservice,需要和core-site.xml中保持一致</description>
</property>
<property>
<name>dfs.ha.namenodes.gky</name>
<value>nn1,nn2</value>
<description>gky为集群的逻辑名称,映射两个namenode逻辑名</description>
</property>
<property>
<name>dfs.namenode.rpc-address.gky.nn1</name>
<value>ant151:9000</value>
<description>namenode1的RPC通信地址</description>
</property>
<property>
<name>dfs.namenode.http-address.gky.nn1</name>
<value>ant151:9870</value>
<description>namenode1的http通信地址</description>
</property>
<property>
<name>dfs.namenode.rpc-address.gky.nn2</name>
<value>ant152:9000</value>
<description>namenode2的RPC通信地址</description>
</property>
<property>
<name>dfs.namenode.http-address.gky.nn2</name>
<value>ant152:9870</value>
<description>namenode2的http通信地址</description>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://ant151:8485;ant152:8485;ant153:8485/gky</value>
<description>指定NameNode的edits元数据的共享存储位置(JournalNode列表)</description>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/soft/hadoop313/data/journaldata</value>
<description>指定JournalNode在本地磁盘存放数据的位置</description>
</property>
<!-- 容错 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
<description>开启NameNode故障自动切换</description>
</property>
<property>
<name>dfs.client.failover.proxy.provider.gky</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<description>失败后自动切换的实现方式</description>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
<description>防止脑裂的处理</description>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
<description>使用sshfence隔离机制时,需要ssh免密登陆</description>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
<description>关闭HDFS操作权限验证</description>
</property>
<property>
<name>dfs.image.transfer.bandwidthPerSec</name>
<value>1048576</value>
<description></description>
</property>
<property>
<name>dfs.block.scanner.volume.bytes.per.second</name>
<value>1048576</value>
<description></description>
</property>mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>job执行框架: local, classic or yarn</description>
<final>true</final>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/soft/hadoop313/etc/hadoop:/opt/soft/hadoop313/share/hadoop/common/lib/*:/opt/soft/hadoop313/share/hadoop/common/*:/opt/soft/hadoop313/share/hadoop/hdfs/*:/opt/soft/hadoop313/share/hadoop/hdfs/lib/*:/opt/soft/hadoop313/share/hadoop/mapreduce/*:/opt/soft/hadoop313/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop313/share/hadoop/yarn/*:/opt/soft/hadoop313/share/hadoop/yarn/lib/*</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>ant151:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>ant151:19888</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1024</value>
<description>map阶段的task工作内存</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
<description>reduce阶段的task工作内存</description>
</property>
yarn-site.xml
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
<description>开启resourcemanager高可用</description>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrcabc</value>
<description>指定yarn集群中的id</description>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
<description>指定resourcemanager的名字</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>ant153</value>
<description>设置rm1的名字</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>ant154</value>
<description>设置rm2的名字</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>ant153:8088</value>
<description></description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>ant154:8088</value>
<description></description>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>ant151:2181,ant152:2181,ant153:2181</value>
<description>指定zk集群地址</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>运行mapreduce程序必须配置的附属服务</description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/opt/soft/hadoop313/tmpdata/yarn/local</value>
<description>nodemanager本地存储目录</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/opt/soft/hadoop313/tmpdata/yarn/log</value>
<description>nodemanager本地日志目录</description>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
<description>resource进程的工作内存</description>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
<description>resource工作中所能使用机器的内核数</description>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>256</value>
<description></description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description></description>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
<description>日志保留多少秒</description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description></description>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/opt/soft/hadoop313/etc/hadoop:/opt/soft/hadoop313/share/hadoop/common/lib/*:/opt/soft/hadoop313/share/hadoop/common/*:/opt/soft/hadoop313/share/hadoop/hdfs/*:/opt/soft/hadoop313/share/hadoop/hdfs/lib/*:/opt/soft/hadoop313/share/hadoop/mapreduce/*:/opt/soft/hadoop313/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop313/share/hadoop/yarn/*:/opt/soft/hadoop313/share/hadoop/yarn/lib/*</value>
<description></description>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
<description></description>
</property>hadoop-env.sh
export JAVA_HOME=/opt/soft/jdk180
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
workers
ant151
ant152
ant153
ant154二、集群首次启动
启动zk集群
可以直接运行脚本文件
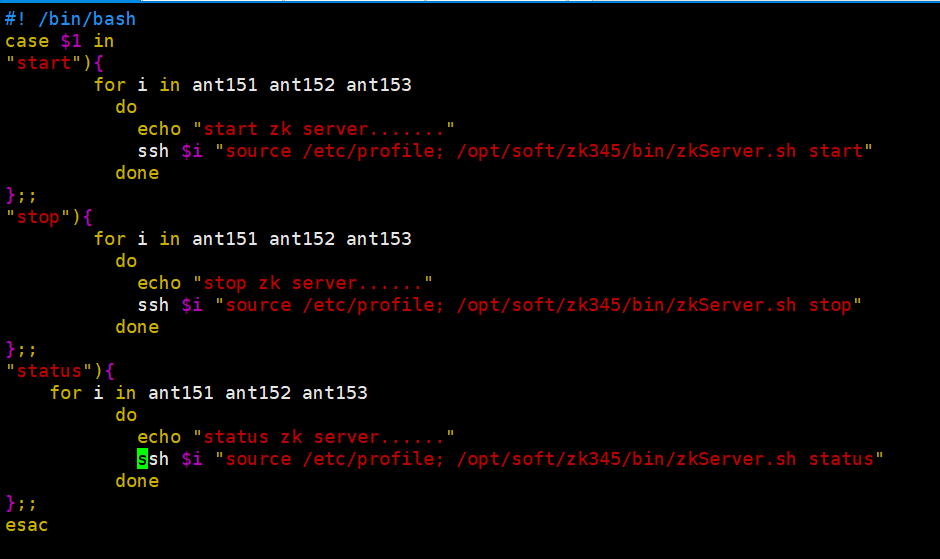
代码:
[root@ant151 shell]# ./zkop.sh start 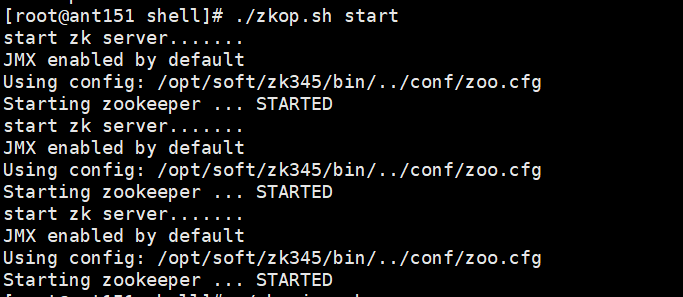
启动ant151,ant152,ant153的journalnode服务:
[root@ant151 shell]# hdfs --daemon start journalnode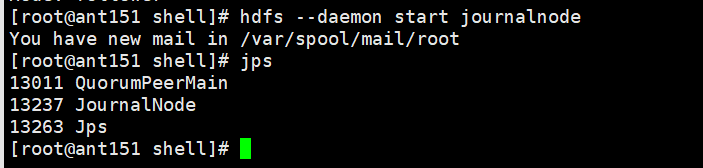
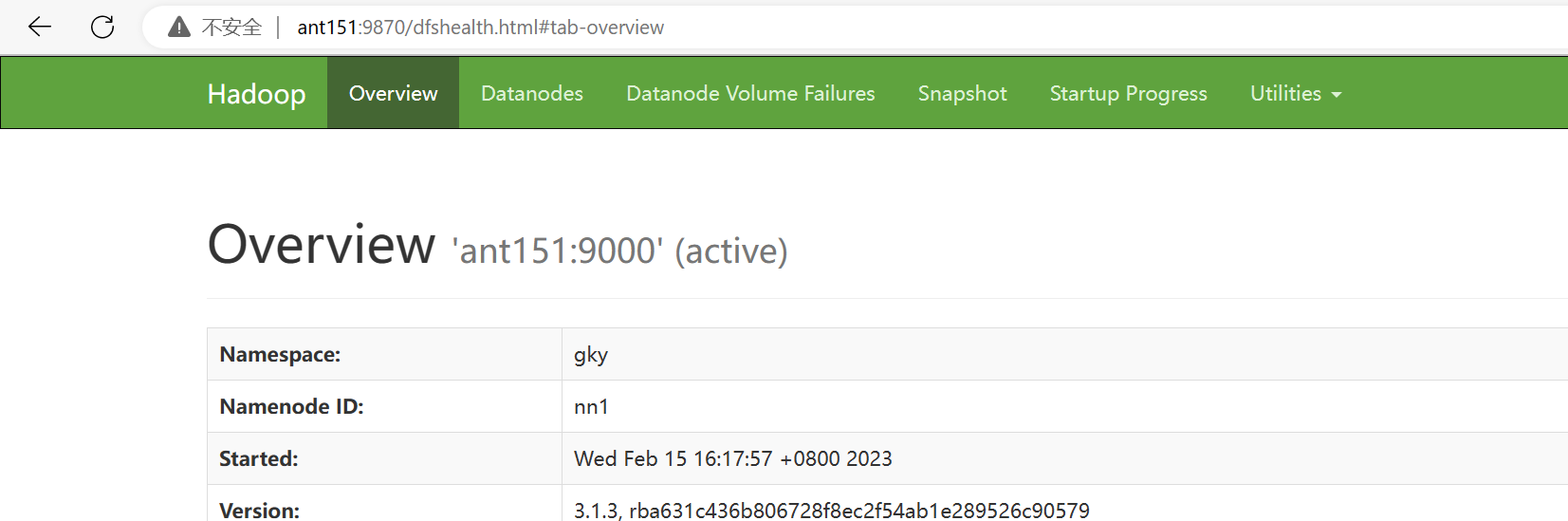
在ant151格式化hfds namenode:
[root@ant151 shell]# hdfs namenode -format在ant151启动namenode服务:hdfs --daemon start namenode
[root@ant151 shell]# hdfs --daemon start namenode
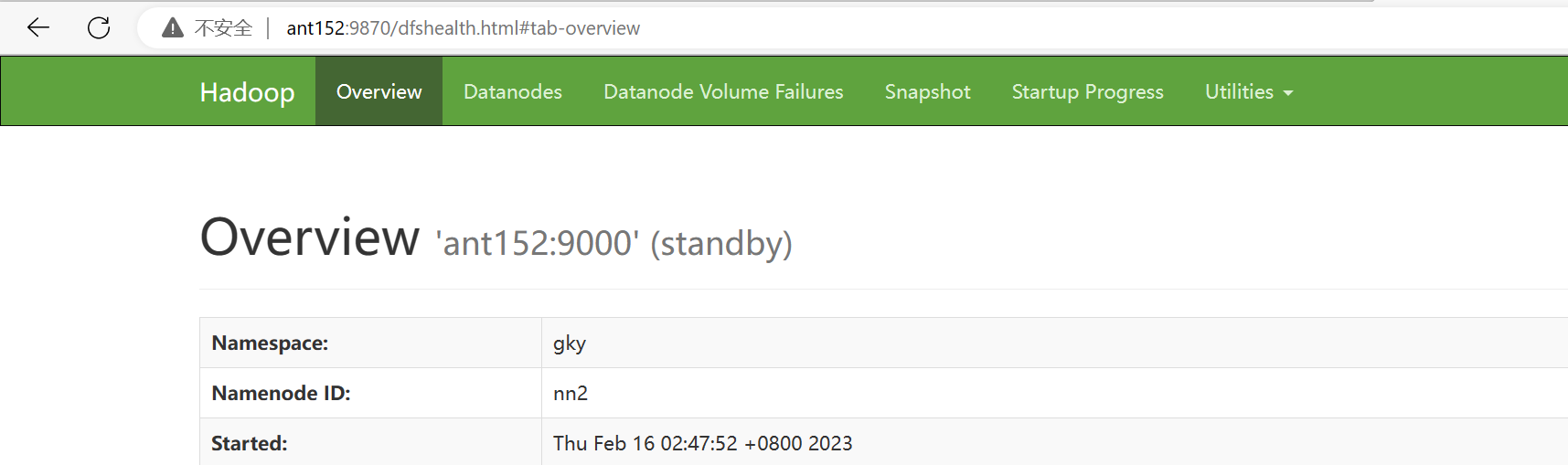
在ant152机器上同步namenode信息
[root@ant151 shell]# hdfs namenode -bootstrapStandby
在ant152启动namenode服务:hdfs --daemon start namenode
[root@ant152 soft]# hdfs --daemon start namenode查看namenode节点状态:hdfs haadmin -getServiceState nn1|nn2
[root@ant152 soft]# hdfs haadmin -getServiceState nn1
关闭所有dfs有关的服务
[root@ant151 soft]# stop-dfs.sh
格式化zk
[root@ant151 soft]# hdfs zkfc -formatZK
启动dfs
[root@ant151 soft]# start-dfs.sh
启动yarn: [root@ant151 soft]# start-yarn.sh
[root@ant151 soft]# start-yarn.sh
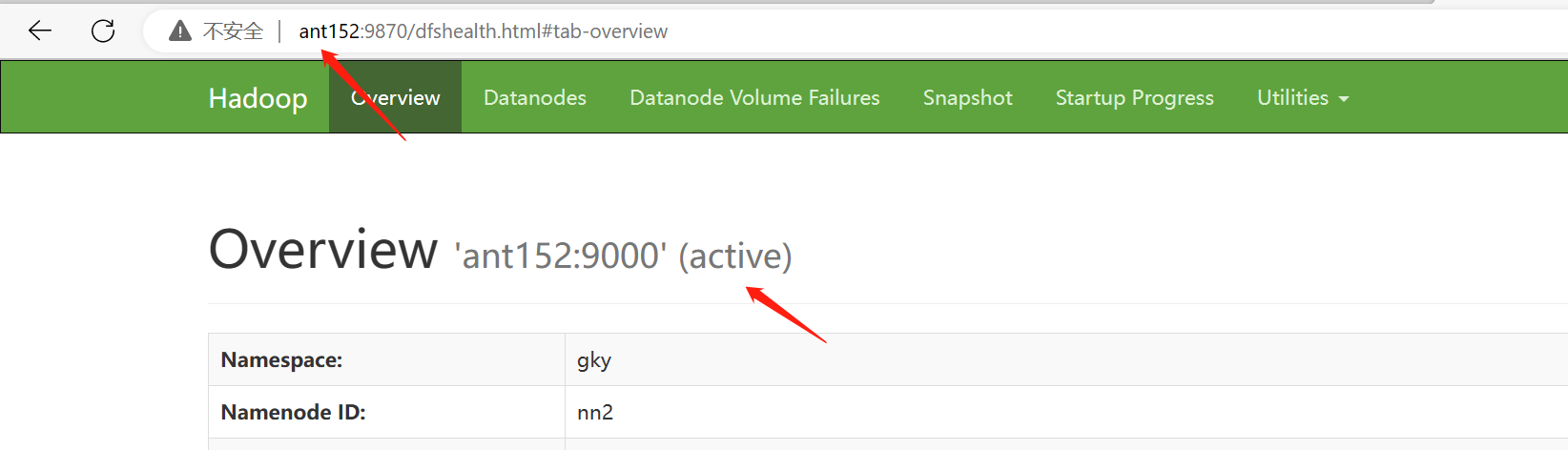
查看resourcemanager节点状态
[root@ant151 soft]# yarn rmadmin -getServiceState rm1
rm1状态:standby

rm2状态:active
当前进程状态:
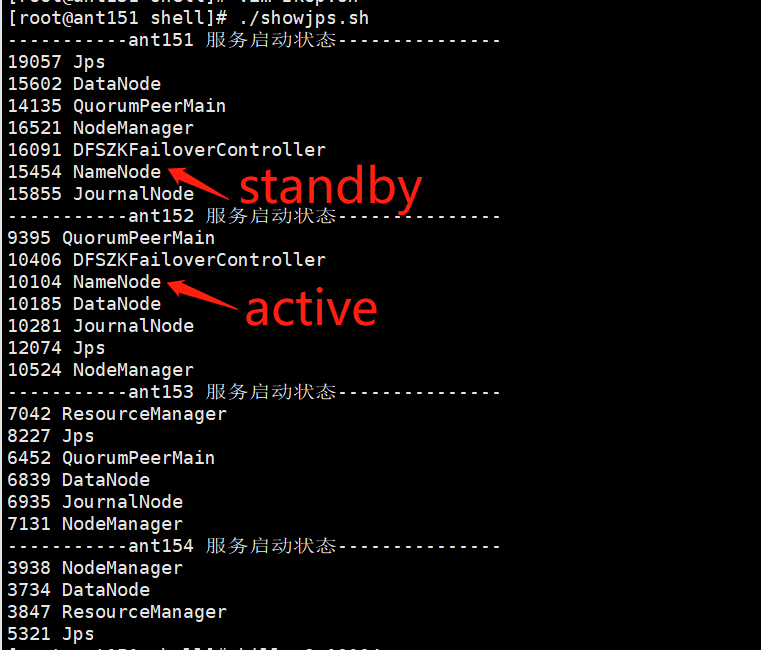
kill掉active进程

尝试访问,无法链接

恢复ant152的namenode进程